
Apache Zookeeper — open source проект Apache Software Foundation, cервис-координатор, который обеспечивает распределенную синхронизацию небольших по объему данных (конфигурационная информация, пространство имен) для группы приложений. Zookeeper представляет из себя распределенное хранилище ключ-значение (key-value store), гарантирующий надежное консистентное (consistency) хранение информации за счет синхронной репликации между узлами, контроля версий, механизма очередей (queue) и блокировок (lock). За счет использования оперативной памяти и масштабируемости обладает высокой скоростью
Сценарии использования Зукипер:
- Распределенный сервер имен (namespace — topics для Kafka)
- Распределенная конфигурация (Hadoop, Kafka)
- Распределенный членство в группах (распределенные сервисы Kafka, Hadoop)
- Выбор главного в распределенных системах с арбитражом (Leader election).
Как устроен Apache Zookeeper
Архитектурно Зукипер организован по клиент-серверной технологии, когда клиентские приложения обращаются к одному из узлов, объединенных в ансамбль. Среди ансамбля серверов выделяется главный узел — лидер, который выполняет все операции записи и запускает автоматическое восстановление при отказе любого из подключенных серверов. Остальные узлы — подписчики или последователи, реплицируют данные с лидера и используются клиентскими приложениями для чтения.
Apache Zookeeper часть 1
ZooKeeper имитирует виртуальную древовидную файловую систему из взаимосвязанных узлов, которые представляют собой совмещенное понятие файла и директории. Каждый узел этой иерархии может одновременно хранить данные и иметь подчиненные узлы-потомки.
Достоинства и недостатки Зукипер
Ключевыми преимуществами Zookeeper в распределенных Big Data системах считаются следующие:
- отказоустойчивость кластера;
- синхронизация распределенных сервисов;
- автоматическая синхронизация данных;
- упорядоченность сообщений;
- транзакционность передачи даннных.
Обратной стороной этих достоинств являются следующие недостатки:
- зависимость от оперативной памяти узла;
- избыточное количество серверов;
- особенности ZAB-протокола синхронизации данных в ансамбле серверов;
- ограниченность пространства имен и числа потомков каждого узла.
Подробнее, зачем Apache Zookeeper используется в кластерах Hadooop, Kafka и HBase, а также чем можно его заменить, мы писали здесь. А об архитектуре, основных принципах работы и главных проблемах Зукипер читайте в этой статье.
Источник: bigdataschool.ru
Apache Zookeeper, что это, установка, запуск

Apache Zookeeper — централизованная служба для поддержки информации о конфигурации, именования, обеспечения распределенной синхронизации и предоставления групповых услуг. Все эти виды услуг используются в той или иной форме распределенными приложениями.
What is Zookeeper?
Apache ZooKeeper — это волонтерский проект с открытым исходным кодом в рамках Apache Software Foundation.
Не будем вдаваться в технические подробности, но стоит отметить, что для работы таких приложений, как HBase, Kafka (ими мы и займемся далее), необходим Zookeeper.
Установка Apache Zookeeper.
При ОДНОНОДОВОЙ конфигурации установка не должна вызывать затруднения.
1. Качаем архив с нужной версией (в моей конфигурации это версия 3.4.13) с официального сайта.
2. Распаковываем его в каталог /usr/local.
3. Назначаем владельцем каталога zookeeper-3.4.13 пользователя hduser.
4. Создаем новый каталог zookeeper-3.4.13/data .
5. Создаем из шаблона и редактируем файл zookeeper-3.4.13/conf/zoo.cfg:
Должно быть так:
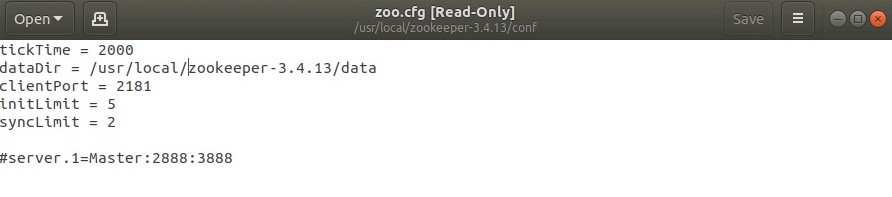
6. Все готово, запускаем сервер (zookeeper-3.4.13/bin) ./zkServer.sh start

Проверим состояние сервера командой (zookeeper-3.4.13/bin) ./zkServer.sh status

Подключим клиент к серверу: (zookeeper-3.4.13/bin) ./zkCli.sh -server master:2181

Если у вас все также, поздравляю, однонодовый (standalone) кластер готов!
При МНОГОНОДОВОЙ конфигурации:
1. Создать каталог zookeeper-3.4.13/logs.
2. Прописать данный каталог в файле zoo.cfg:

3. Удалить все содержимое из каталога zookeeper-3.4.13/data .
Создать в каталоге zookeeper-3.4.13/data файл myid и записать в него уникальный идентификатор, у нас будет 1.
4. Добавить строки с уникальными идентификаторами, именами и портами для каждой ноды в файл zoo.cfg:

После долгих мучений мой файл приобрел следующий вид:
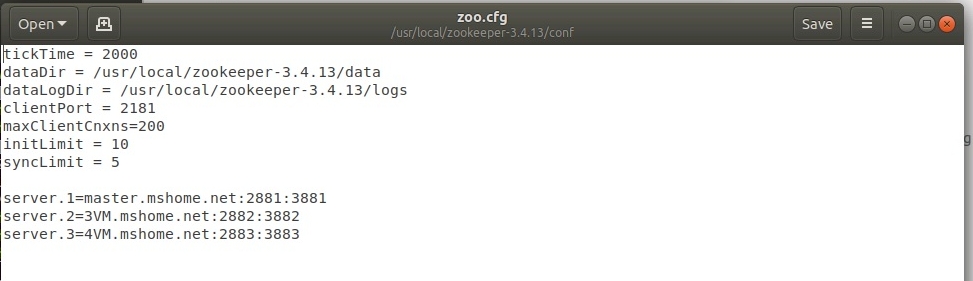
Пришлось поменять номера портов хотя вроде бы это не должно влиять на результат./p>
5. Копируем каталог zookeeper-3.4.13 на все ноды кластера, например так:
Целевой каталог на ноде предварительно нужно создать и назначить владельца hduser.
6.Запускаем сервер (zookeeper-3.4.13/bin) ./zkServer.sh start на каждой ноде.
Проверяем: ./zkServer.sh status на каждой ноде.
Один из трех будет избран лидером а остальные — подчиненными:
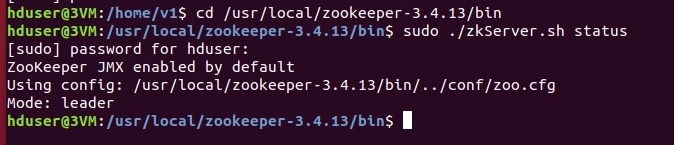

Если все так, то мы настроили zookeeper-кворум! Далее займемся Kafkoй и HBase.
Комментарии
Комментировать могуть только зарегистрированные пользователи
Источник: xn—57-qdd4aqo.xn--p1ai
Незаслуженно забытый ZooKeeper
Несмотря на наличие работающего решения немалой части распределенных проблем о нем мало пишут и создается впечатление, что это что-то устаревшее и не заслуживающее внимания.
Это не так. Начинать новый проект с Зукипером или встраивать его в существующий проект в 2021 году можно и нужно.
Зукипер просто работает
Он на самом деле умеет работать с несколькими датацентрами, вам не надо думать кто там сейчас мастер, не надо что-то делать если одна из нод исчезла, вообще не надо ни о чем заботится. Его даже не надо как-то по-особенному конфигурить, вам скорее всего подойдет конфигурация из коробки. Да, она будет держать вашу нагрузку. Вы записали данные и сможете их прочитать пока работает хотя бы одна из нод. При включении новой ноды она сама загрузит актуальное состояние и продолжит работать.
Производительность
Зукипер держит большой RPS. О производительности, как правило, можно не думать. С большой вероятностью ее вам хватит для любого разумного применения.
Оптимальная конфигурация для любых разумных применений это 3 средние ноды. Постарайтесь расположить эти ноды так чтобы все три вместе упасть никак не могли. Разные датацентры — идеальное расположение. Конфигурация серверов на картинке «dual 2Ghz Xeon and two SATA 15K RPM drive».

Зукипер это дерево
Вы можете легко на одном кластере держать все ваши микросерсивисы и операции. Просто аккуратно разложите их по разным поддеревьям. Об этом лучше подумать сразу и организовать хранение так что любой сервис живет только в своем поддереве.
Конкретные примеры использования Зукипера
Все примеры написанны с помощью Apache Curator Framework. Большая часть взята прямо с https://curator.apache.org/curator-recipes/index.html
Код всех примеров подразумевает что вы его запускаете на нескольких нодах. Минимум две ноды, практика говорит что три ноды надежнее.
Выбор мастера
Иногда встречаются master-slave системы. В них есть 2-3 ноды. Одна из них мастер и работает, остальные ждут пока мастер станет недоступен. При недоступности мастера проходят выборы и одна из slave нод становится новым мастером. Шардирование обычно лучше, но иногда оно просто не нужно.
Одного работающего мастера хватает на все про все с запасом.
Очередь
Отлично подходит для случая когда вам нужна распределенная отказоустойчивая очередь, но использование полноценных решений вроде Кафки выглядит оверкилом. Например, у вас немного данных в очереди и поток событий небольшой.
И простейшие данные для примера
public static class Data < byte i; public Data(byte i) < this.i = i; >>
Распределенные семафоры
К вам пришли из соседней команды и поругались на пиковую нагрузку от вас. И вы теперь не хотите со всех 100 ваших нод одновременно ходить в соседний сервис за данными, которые вам нужны не очень срочно. А хотите ходить не более чем с 10 нод одновременно.
InterProcessSemaphoreV2 semaphore = new InterProcessSemaphoreV2(client, «/someService/semaphoreToSmallExternalService», 10); Lease lease = semaphore.acquire(); try < callToExternalService(); >finally
Метаинформация
Вам надо хранить метаинформацию о каких-то ваших объектах. Чтобы она была доступна другим инстансам вашего сервиса. Допустим информацию о пачке данных которую вы сейчас обрабатываете. Записи много, чтения много, данных не очень много. Обычные SQL БД такой паттерн нагрузки не любят.
Просто запишите в Зукипер. И используйте в любой админке для показа, управления или любых других действий. Иметь возможность наблюдать за распределенной обработкой это очень хорошая практика. Без наблюдения системы иногда переходят в непонятное состояние, куда бежать смотреть что где происходит непонятно.
PersistentNode node = new PersistentNode(client, CreateMode.EPHEMERAL, false, «/someService/serviceNodeGroup/» + data.hashCode(), «any node data you need».getBytes()); node.start(); try
Распределенный счетчик
Регулярно бывает нужна самая обычная последовательность интов с автоинкрементом. Сиквенсы из БД по какой-либо причине не подходят. И как обычно есть кучка инстансов вашего сервиса, которые должны быть согласованы.
Например, простой счетчик вызовов внешнего сервиса нужный для мониторинга и отчетов. Графана такие счетчики хорошо рисует на графиках и по ним можно наблюдать за активность использования внешнего сервиса вами. Сиквенс из БД не очень хорошо подходит, а счетчик хочется. Как обычно, просто возьмите Зукипер.
DistributedAtomicLong externalServiceCallCount = new DistributedAtomicLong(client, «/someService/externalServiceCallCounter», new RetryOneTime(1)); externalServiceCallCount.increment(); //В любом другом сервисе читаем DistributedAtomicLong externalServiceCallCount = new DistributedAtomicLong(client, «/someService/externalServiceCallCounter», new RetryOneTime(1)); externalServiceCallCount.get();
Конфиги
В Зукипере можно хранить ваши конфиги.
Минусы: Конфиги сложно наблюдаемы и нетривиально редактируемы.
Плюсы: Ваше приложение подписывается на изменение и получает новые значения без рестарта. И, как обычно, никакого специального кода для этого писать не нужно.
Получается что в Зукипере есть смысл хранить ту часть конфига которую надо применять в риалтайме без рестарта приложения. Например, настройки рейт лимитера. Может быть их придется крутить в момент максимальной нагрузки когда рестартовать ноды совсем не хочется. Пока кеши прогреются, пока код правильно прогреется.
Да и при старте приложение может подтягивать много данных и это может занимать значимое время. Лучше бы без рестартов в момент пиковой нагрузки жить.
Пример подписки на события изменения данных:
CuratorCache config = CuratorCache.builder(client, «someService/configuration»).build(); config.start(); config.listenable().addListener((type, oldData, data1) -> < updateApplicationProperties(. ); >);
Транзакции
При построении конвейера обработки данных хочется иметь возможность обрабатывать данные транзакционно. В идеале exactly once. И как обычно писать сложный код не хочется.
Такие вещи сложно отлаживать и поддерживать. Да и баги в них постоянно встречаются.
Как и в других случах Зукипер вам поможет. Просто прочитайте данные, обработайте их, переложите дальше по конвейеру и закомитьте изменение атомарно.
byte[] readedData = client.getData().forPath(«/someService/collection1/data1»); byte[] data2 = processData(); CuratorOp createOp = client.transactionOp().create().forPath(«/someService/collection2/data2», data2); CuratorOp deleteOp = client.transactionOp().delete().forPath(«/someService/collection1/data1»); Collection results = client.transaction().forOperations(createOp, deleteOp); for ( CuratorTransactionResult result : results )
Стоит следить за записываемыми в сторонние БД данными.
Если processData() из примера что-то куда-то пишет, то это что-то должно быть удалено даже при откате транзакции Зукипера. Базы с поддержкой TTL зарекомендовали себя лучше всего. Данные удалят сами себя. Если у вас не такая, то нужно придумать как-то другой механизм для очистки неконсистентных данных.
Мониторинг, как обычно, обязателен. По TTL можно случайно удалить нужные данные, стоит это мониторить и избегать такого.
Особенности использования Зукипера
У зукипера есть не только плюсы. Есть и особенности о которых надо знать перед как вводить его в продакшен системы.
Зукипер не риалтайм
Можно прочитать не то что записали. Не прочитать только что записанные данные это абсолютно нормальная ситуация. Системы надо строить с учетом этого.
Если очень надо, то можно попробовать записать в ту же ноду что-то. При провале этого действия мы будем точно знать что нода существует, несмотря на то что она не прочиталась. И можно попробовать снова ее прочитать через небольшое время. Disclamer: Так не стоит делать, это один из рецептов на крайний случай. Когда код уже в проде и надо срочно доделать чтобы работало.
Зукипер не база данных
Зукипер хорошо работает с базой размером в единицы гигабайт. Не надо в нем хранить ваши данные. Храните их в БД, или в S3, или в любом другом предназначенном для хранения данных месте которое вам нравится. А в Зукипер пишите метаинформацию и указатель на ваши данные.
Разумный предел для одного значения — 1 килобайт. Запас из документации до мегабайта лучше оставить на экстренные случаи.
Зукипер не самое лучшее kv хранилище
Зукипер можно использовать в роли kv хранилища. Обычно это горячий кеш.
Но лучше посмотреть в сторону более специализированного софта. Redis/Tarantul удобнее для использования в этой роли и более эффективно утилизируют железо при чистой kv нагрузке.
zxcid
У Зукипера есть архитектурная проблема — zxcid.
zxcid это внутренний 32 битный счетчик операций Зукипера. Когда он переполняется кластер разваливается на время единиц секунд до десятков минут. Надо быть к этому готовым и мониторить текущее значение zxcid. Хорошее решение будет в версии 3.8.0 https://issues.apache.org/jira/browse/ZOOKEEPER-2789 Ждем, верим, надеемся.
Переходить на новую версию сразу после ее выхода не стоит. Выждите хотя бы квартал.
Забытые данные
В древовидной структуре можно легко насоздавать сотни тысяч и даже миллионы нод в далеком и заброшенном узле дерева. И забыть их удалить. Чтобы этого избегать стоит писать код без багов(шутка) и мониторить размер базы Зукипера и общее число нод в нем. Если эти цифры начали подозрительно расти, то стоит что-то с этим сделать.
Софт изначально стоит проектировать так что любая созданная нода точно удалится.
Никогда неудаляемые ноды (например конфиг) стоит создавать очень аккуратно и ни в коем случае не массово.
Ноды со сложным жизненным циклом стоит покрыть отдельными мониторингами.
Например: одно приложение создает неудаляемую автоматически ноду, а второе ее читает обрабатывает и удаляет потом. Стоит сделать мониторинг на общее количество и на самую старую ноду. Тогда в случае любых проблем вы сразу это увидите.
Типовые удобства 2021 года
Все, как полагается.
WEB-UI чтобы быстренько что-то посмотреть или поправить пару значений есть на любой вкус. Можно выбрать вот отсюда или просто из Гугла по своему вкусу. Мне нравится старенький и похоже что мертвый zk-web, но это дело вкуса. Поставить любой UI очень рекомендую. Они помогают решить множество мелких и регулярных проблем.
Клиенты для всех распространенных языков тут
Источник: habr.com