
В этой статье мы рассмотрим, что такое Apache Zeppelin, как он полезен для интерактивной аналитики и визуализации больших данных (Big Data), а также чем этот инструмент отличается от популярного среди Data Scientist’ов и Python-разработчиков Jupyter Notebook.
Что такое Apache Zeppelin и чем он полезен Data Scientist’у
Начнем с определения: Apache Zeppelin — это интерактивный веб-блокнот (или «ноутбук» от notebook) с открытым исходным кодом, который поддерживает практически все этапы работы с данными в Data Science, от извлечения до визуализации, в т.ч. интерактивный анализ и совместное использование документов. Он интегрирован с Apache Spark, Flink, Hadoop, множеством реляционных и NoSQL-СУБД (Cassandra, HBase, Hive, PostgreSQL, Elasticsearch, Google Big Query, Mysql, MariaDB, Redshift), а также поддерживает различные языки программирования, популярные в области Big Data: Python, PySpark, R, Scala, SQL. Такая многофункциональность обеспечивается за счет интерпретаторов — плагинов для поддержки языка программирования, базы данных или фреймворка.
040. Apache Zeppelin интерактивный анализ больших данных — Наталья Притыковская
С точки зрения работы с большими данными, отдельного упоминания заслуживает встроенная интеграция с Apache Spark, что дает общие контексты (SparkContext и SQLContext), загрузку jar-зависимостей из локальной файловой системы или репозитория maven во время выполнения задачи, а также возможность отмены задания и отображение хода его выполнения. Также Цеппелин поддерживает работу с REST-API Apache Spark — Livy, о котором мы подробно писали здесь.
Благодаря интерпретатору Python, Apache Zeppelin предоставляет все возможности этого языка, ориентированные на Data Science, например, специализированные библиотеки (Matplotlib, Conda, Pandas и пр.) для аналитики больших данных и визуализации. Это позволяет автоматически построить круговые, столбчатые и прочие наглядные диаграммы, чтобы визуализировать статистику датасета или результатов исследования. Также в Zeppelin можно создавать интерактивные дэшборды с формами ввода данных, которые будут выглядеть как веб-страницы, чтобы поделиться их URL-адресами для совместной работы. Для многопользовательского режима Zeppelin поддерживает LDAP-авторизацию с настройками доступа [1].
Впрочем, при всех этих достоинствах, на практике можно столкнуться со следующими ограничениями Apache Zeppelin, которые могут рассматриваться как недостатки [2]:
· нестабильная работа под высокой нагрузкой;
· интерактивный веб-интерфейс требует много оперативной памяти;
· отсутствие полного набора возможностей современных специализированных IDE;
· меньшая «зрелость» и популярность по сравнению с Jupyter Notebook.
Тем не менее, Apache Zeppelin завоевывает свою нишу, конкурируя с Jupyter Notebook в некоторых кейсах работы с большими данными. В каких случаях аналитику Big Data или Data Scientist’у следует предпочесть Apache Zeppelin вместо Jupyter Notebook, мы рассмотрим далее.
Apache Zeppelin vs Jupyter Notebook: что и когда выбирать для аналитики Big Data
Прежде всего, отметим, что оба инструмента относятся к open-source и являются веб-блокнотами для разработки и визуализации данных. Однако, Jupyter позиционируется как многоязычная интерактивная вычислительная среда, с поддержкой кода, уравнений, текстов, графиков и интерактивных дэшбордов. Apache Zeppelin не претендует на лавры IDE, хотя и включает некоторые функции для разработки ПО, фокусируясь на возможностях для интерактивного анализа больших данных. Разберем, как оба блокнота отличаются по следующим критериям, важных с точки зрения работы с Big Data [3]:
Обзор Zeplin за 15 минут для верстальщиков и веб-дизайнеров
· безопасность и многопользовательские возможности, которые Jupyter не поддерживает по умолчанию, в отличие от Zeppelin. Кроме того, в Jupyter нет возможности обеспечения конфиденциальности конечных пользователей. Zeppelin позволяет гибко настраивать конфигурации безопасности, включая конфиденциальность программного кода, через LDAP/Active Directory и специально определенные группы безопасности. Он использует только один серверный процесс, аутентифицируя пользователей в настроенной системе, прежде чем разрешить дальнейший доступ, чтобы делиться информацией только с ограниченным кругом лиц с определенными правами.
· визуализация — благодаря возможности использовать разные интерпретаторы в одном блокноте, Zeppelin выигрывает по сравнению с Jupyter, в котором нет параметров построения диаграмм. В Jupyter есть библиотека plotly, которая выводит диаграмму в блокнот, тогда как Zeppelin поддерживает только содержимое Matplotlib — Python-библиотеку построения двумерных графиков, которая просто сохраняет вывод в HTML-файл.
· описание отчетов — оба инструмента поддерживают markdown-разметку, но Zeppelin быстрее создает интерактивные формы и визуализацию результатов. Кроме того, Цеппелин-отчеты более доступны для конечных пользователей и могут быть экспортированы в формат CSV или TSV. Zeppelin позволяет скрыть код, предоставляя читаемые интерактивные отчеты конечным пользователям.
· кластерная интеграция — Zeppelin является частью экосистемы Apache Hadoop и хорошо интегрируется со Spark, Pig, Hive и другими ее компонентами.
· удобство разработки — в отличие от Jupyter, Zeppelin позволяет комбинировать несколько параграфов в одну строку, однако, редактор кода и параграфов в Jupyter кажутся более эффективными, поскольку имеют больше быстрых комбинаций (т.н. «горячих клавиш») и функцию автозаполнения.
· производственная эксплуатация (production) — поскольку Zeppelin зависит от емкости кластера, то при недостатке ресурсов или большом количестве пользователей (более 10), возможны сбои и зависания, которые не характерны для Jupyter.
Подводя итоги, отметим, что Apache Zeppelin — отличный инструмент для аналитики больших данных в экосистеме Hadoop. Он упрощает разработку Spark-приложений и ориентирован на корпоративных пользователей, обеспечивая интеграцию с LDAP, управление разрешениями и интерактивную визуализацию при достаточном количестве ресурсов кластера. Поэтому неслучайно, отечественный разработчик Big Data решений для корпоративных целей, компания Аренадата Софтвер, включила Apache Zeppelin в свой новый продукт — Arenadata Analytic Workspace (AAW), который представляет собой самообслуживаемый сервис (Self-Service) DataScience и BI [4].
В свою очередь, Jupyter Notebook требует меньше накладных расходов на настройку и создание разработанных шаблонов благодаря автономному характеру. А благодаря большому количеству IDE-функций, расширений и поддержке фреймворков машинного обучения (Machine Learning) и других методов искусственного интеллекта, он стал весьма популярным среди индивидуальных Data Science-исследователей [3].
Как на практике эффективно использовать Apache Zeppelin со Spark и другими компонентами экосистемы Hadoop для аналитики больших данных в проектах цифровизации своего бизнеса, а также государственных и муниципальных предприятий, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
Источник: medium.com
Допинг для аналитики: почему стоит обратить внимание на Apache Zeppelin
Все рано или поздно приходят к аналитике за данными. В больших многопользовательских играх (да и синглплеере) без этого уже вообще никуда. Сколько пользователей предпочитают новый режим; где слабые места монетизации; куда смотреть геймдизайнерам, чтобы повысить вовлеченность игроков; и еще миллион вещей — подсчитывается вообще всё. И всё это влияет на решения, которые потом принимают разработчики.
А вот внедряют аналитику все по-разному: кто-то покупает сторонние решения (просто, но негибко), кто-то пишет под себя (долго и дорого), а кто-то пока просто считает несколько базовых метрик силами программистов и не заморачивается.

Поэтому я расскажу об инструменте, который будет полезен для всех. Кто только начинает выстраивать аналитику — сможет «на коленке» создать систему с нуля, а компании с уже готовыми решениями — «бустануть» свой подход.
Речь пойдет об Apache Zeppelin. Это многофункциональная интерактивная оболочка, которая позволяет выполнять запросы к различным источникам данных, обрабатывать и визуализировать результаты.
Достаточно близкий аналог — Jupyter Notebook, но Zeppelin несколько более заточен под работу с базами данных. Он использует концепцию «интерпретаторов» — плагинов, которые обеспечивают бэкэнд для какого-либо языка и/или БД.
Zeppelin, как и Jupyter, для пользователя выглядит как набор файлов-ноутбуков, состоящий из параграфов, в которых пишутся и исполняются запросы. С помощью встроенных визуализаторов ноутбук с набором запросов легко превратить в полноценный дашборд с данными.
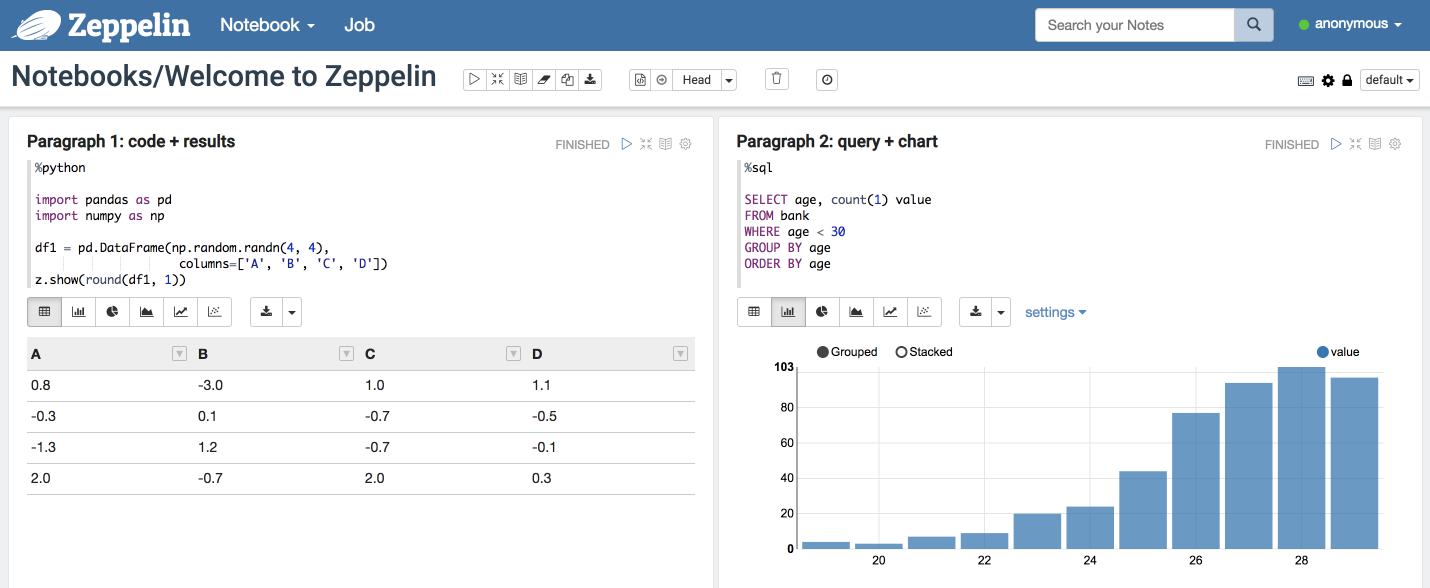
Намеренно не будем касаться вопросов установки и настройки — это есть и в документации на сайте, и в сети можно найти несколько туториалов под разные БД. Цель статьи — рассказать о пользовательской стороне вопроса, интересных применениях инструмента (в том числе не самых очевидных) и преимуществах, которые аналитики могут из него извлечь, вне зависимости от того, каким решением они уже пользуются.
В качестве примеров расскажу, для чего мы используем его в Pixonic (как раз тот кейс, когда в компании уже есть собственная производительная система аналитики).
Итак, пойдем по порядку.
Всеядность Zeppelin
Комбинирование различных источников данных — в рамках одного дашборда
— одно из его ключевых преимуществ. В рамках стандартной сборки включено внушительный набор интерпретаторов (к NoSQL и реляционным базам).
На практике это дает следующее:

- Большинство компаний с уже работающими БД и системами аналитики могут использовать его «из коробки» (насколько это применимо к опенсорсным продуктом, хех). Энтузиасты же с более экзотичными БД могут написать интерпретатор самостоятельно, о чем на сайте продукта есть статья.
- Небольшие компании, при желании, могут построить свою систему аналитики исключительно из БД и Zeppelin в качестве интерфейса.
- Как показывает опыт общения с коллегами — у многих данные могут стекаться из разных источников, храниться в разных базах (ле-е-егаси!), кто-то может пользоваться дополнительно сторонними сервисами аналитики. Соответственно, перед аналитиками порой встают задачи «подружить» такой зверинец между собой. Zeppelin же позволяет внутри одного ноутбука использовать свой интерпретатор для каждого параграфа, что позволит выводить результаты запросов к разным источникам в одном месте.
Zeppelin + Python/R
Zeppelin — это не только веб-интерфейс для различных баз данных, но и может выступать интерактивной оболочкой для выполнения скриптов на языках программирования. В него входят интерпретаторы для R и Python, потому он вполне может выступать альтернативой привычным RStudio и Jupyter. Да, он предоставляет меньше возможностей, чем специализированные IDE (например, нет автоподстановки), но это компенсируется преимуществами, о которых поговорим ниже.
В связке с тем же Python’ом могущество Zeppelin многократно возрастает: тут тебе и возможность получения данных по API из сторонних сервисов (привет предыдущему пункту), и возможность производить обработку данных помимо обычных запросов к БД, а также автоматизация этих процессов. Zeppelin поддерживает обновление дашбордов по крону без лишних телодвижений (опять же, беглый взгляд на решения коллег показывает, что эту, вроде бы тривиальную задачу, порой приходится решать весьма хитровыдуманными способами). Ну и на сладкое: в нем есть встроенная система контроля версий — примитивная, но достаточная для большинства задач аналитиков.