
Для создания электронных библиотек и архивов путем перевода книг и документов в цифровой вариант и при необходимости редактирования полученного по факсу документа используются специальные системы распознавания символов.
С помощью сканера можно получить изображение страницы с текстом в графическом формате.
Но работать с этим текстом невозможно, потому что любое сканирование – это всего лишь изображение
Текст можно будет читать, распечатывать, но только не редактировать.
Для перевода графического документа в текстовый файл необходимо провести распознавание текста.
Преобразование графического изображения в текст занимаются программы оптического распознавания текста (Optical Character Recognition, OCR).
Современные OCR умеют:
- распознавать тексты, набранные не только разными шрифтами, но и самыми экзотическими, в том числе и рукописных
- корректно работать с текстами, содержащими слова на нескольких языках
- распознавать таблицы
- распознавать нечетко набранные или написанные тексты
Само собой, распознать текст — это еще полдела. После этого нужно обеспечить сохранение результата в файле текстового формата, например Microsoft Word.
Распознавание текста. Перевести картинку и пдф в ворд. Лучшие методы
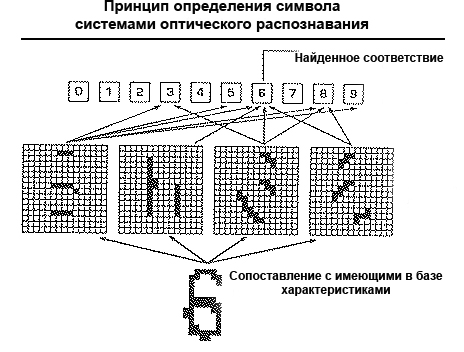
В процессе распознавания документов в плохом качестве (машинописный текст, факс) используется метод распознавания символов по наличию определенных структурных элементов — отрезков, колец, дуг.
Любой символ легко описывается с помощью набора значений, определяющих расположение его частей. Например, обе буквы «Н» и буква «И» состоят из трех отрезков. Два из них расположены параллельно друг другу, а третий их соединяет. А различие – лишь в величине углов отрезков.
Самые распространенные системы оптического распознавания текста — ABBYY FineReader и CuneiForm.
FineReader является омнифонтовой системой распознавания текстов. Это значит, что она позволяет распознавать тексты, набранные практически любыми шрифтами.
Одним из козырей FineReader является поддержка огромного (для таких программ) количества языков распознавания — более 176 (экзотические, древние языки, популярные языки программирования).
Для запуска процесса распознавания достаточно положить лист бумаги в сканер и нажать кнопку Scan Сократ Персональный» и Pragma. Первая была специально разработана для перевода электронных текстов, вторая стала популярна благодаря своей компактности и простоте в использовании, последняя владеет широкими возможностями и вариантами перевода.
Параметры машинных переводчиков должны удовлетворять четырем основным требованиям:
- оперативность
- гибкость
- скорость
- точность
Оперативность заключается в возможности постоянного обновления словарного запаса и тематических разделов.
Гибкость рассчитана на конкретную предметную область.
Скорость — возможность автоввода и обработки текстовой информации с бумаги. Одна такая система (OCR-System) ежедневно заменяет больше десяти опытных машинисток.
Точность заключается грамотности и адекватной передачи смысла переводимого текста на язык перевода.
Улучшение качества перевода
Существуют способы улучшения результатов машинного перевода:
1. Перед началом перевода, нужно определить тип текста, то есть из какой области жизнедеятельности человека он представлен (экономика, спорт, наука и т.д.). Ведь каждая сфера имеет свои нюансы и термины.
2. Часто причиной неправильного перевода являются опечатки переводимом тексте. Это касается и распознанных текстов. Слова с ошибками помечаются переводчиками как незнакомые, потому что в таком виде их нет в словарях. Хуже, если есть ошибки в пунктуации — одна неправильно поставленная запятая способна исказить перевод всего предложения.
3. Работайте с фрагментами текста. Никогда не переводите весь текст сразу. В нем всегда найдутся слова, отсутствующих в словаре и такие, которые система переводит неправильно.
Вопросы
1. Зачем нужны программы распознавания текста?
2. Как происходит распознавание текста?
3. Какие программы распознания текста вы знаете?
4. Требования к параметрам машинных переводчиков.
5. Методы улучшения качества перевода текста
Список использованных источников
1. Журавлев Ю.И. Об алгебраическом подходе к решению задач распознавания или классификации // Проблемы кибернетики. М.: Наука, 2005. — Вып. 33. С. 5-68
2. Растригин Л. А., Эренштейн Р. Х. Метод коллективного распознавания. 79 с. ил. 20 см., М. Энергоиздат, 2006. – 80 с.
3. Потапов А.С. Распознавание образов и машинное восприятие. — С-Пб.: Политехника, 2007 г.
4. А. Васильев. Компьютер на месте переводчика // Подводная лодка. – № 6.
5. Система перевода текста PROMT Internet. Руководство пользователя. — С.-Петербург, фирма «ПРОМТ.
6. www.free-ocr.сom
7. img2txt.ru
8. www.translate.ru
Отредактировано и выслано преподавателем Киевского национального университета им. Тараса Шевченко Соловьевым М. С.
Над уроком работали
Поставить вопрос о современном образовании, выразить идею или решить назревшую проблему Вы можете на Образовательном форуме, где на международном уровне собирается образовательный совет свежей мысли и действия. Создав блог, Вы не только повысите свой статус, как компетентного преподавателя, но и сделаете весомый вклад в развитие школы будущего. Гильдия Лидеров Образования открывает двери для специалистов высшего ранга и приглашает к сотрудничеству в направлении создания лучших в мире школ.
Источник: edufuture.biz
Зачем нужны программы распознавания текста что это такое
Для создания электронных библиотек и архивов путем перевода книг и документов в цифровой вариант и при необходимости редактирования полученного по факсу документа используются специальные системы распознавания символов (Optical Character Recognition, OCR).
С помощью сканера можно получить изображение страницы с текстом в графическом формате.
Но работать с этим текстом невозможно, потому что любое сканирование – это всего лишь изображение
Текст можно будет читать, распечатывать, но только не редактировать.
Для перевода графического документа в текстовый файл необходимо провести распознавание текста.
Программное обеспечение для распознавания текста
Преобразование графического изображения в текст занимаются программы, используюшие принцип оптического распознавания.
Современные программы с OCR умеют:
- распознавать тексты, набранные не только разными шрифтами, но и самыми экзотическими, в том числе и рукописных
- корректно работать с текстами, содержащими слова на нескольких языках
- распознавать таблицы
- распознавать нечетко набранные или написанные тексты
Видео YouTube
Само собой, распознать текст — это еще полдела. После этого нужно обеспечить сохранение результата в файле текстового формата, например Microsoft Word.
В процессе распознавания документов в плохом качестве (машинописный текст, факс) используется метод распознавания символов по наличию определенных структурных элементов — отрезков, колец, дуг.
Любой символ легко описывается с помощью набора значений, определяющих расположение его частей. Например, обе буквы «Н» и буква «И» состоят из трех отрезков. Два из них расположены параллельно друг другу, а третий их соединяет. А различие – лишь в величине углов отрезков.
Самые распространенные системы оптического распознавания текста — ABBYY FineReader и CuneiForm.

ABBYY Finereader является омнифонтовой системой распознавания текстов. Это значит, что она позволяет распознавать тексты, набранные практически любыми шрифтами.
Одним из козырей FineReader является поддержка огромного (для таких программ) количества языков распознавания — более 176 (экзотические, древние языки, популярные языки программирования)
Для запуска процесса распознавания достаточно положить лист бумаги в сканер и нажать кнопку Scan https://www.sites.google.com/site/8sch1167/urok-30″ target=»_blank»]www.sites.google.com[/mask_link]
Системы распознавания текста
![]()



 Технология обработки текстовой
Технология обработки текстовой 


 информации
информации
Е.А. Тулаева МОУ СОШ №18 г.Пензы
Необходимость в системах распознавания символов

С помощью сканера достаточно просто получить изображение страницы текста в графическом файле. Однако работать с таким текстом невозможно: как любое сканированное изображение, страница с текстом представляет собой графический файл — обычную картинку. Текст можно будет читать и распечатывать, но нельзя будет его редактировать и форматировать. Для получения документа в формате текстового файла необходимо провести распознавание текста, то есть преобразовать элементы графического изображения в последовательности текстовых символов.
Программы распознавания текста
Преобразованием графического изображения в текст занимаются специальные программы распознавания текста (Optical Character Recognition — OCR ).
Наиболее распространенные системы оптического распознавания символов:
 BBYY FineReader
BBYY FineReader  CuneiForm от Cognitive
CuneiForm от Cognitive
Получение электронного документа
1. Отсканировать изображение (с помощью ПО сканера);
2. Распознать структуру размещения текста на странице: выделить колонки, таблицы, изображения и т.д.
3. Выделенные текстовые фрагменты графического изображения страницы необходимо преобразовать в текст;
4. Проверка орфографии (если необходимо);
5. Сохранение в файл или передача текста в другое приложение, например в Word.
Методы распознавания символов

Если исходный документ имеет типографское качество то задача распознавания решается
методом сравнения с растровым шаблоном .

При распознавании документов с низким качеством печати используется метод распознавания символов по наличию в них
определенных структурных элементов
(отрезков, колец, дуг и др.).
ABBYY FineReader
FineReader — омнифонтовая система оптического распознавания текстов. Это означает, что она позволяет распознавать тексты, набранные практически любыми шрифтами, без предварительного обучения. Особенностью программы FineReader является высокая точность распознавания и малая чувствительность к дефектам печати.
FineReader имеет массы дополнительных функций и удобный интерфес.
Оптимальное разрешение при сканировании
Оптимальным разрешением для обычных текстов является — 300 dpi и 400-600 dpi для текстов, набранных мелким шрифтом (9 и менее пунктов).
Сканирование в сером является оптимальным режимом для системы распознавания. В случае сканирования в сером режиме осуществляется автоматический подбор яркости. Если Вы хотите, чтобы содержащиеся в документе цветные элементы (картинки, цвет букв и фона) были переданы в электронный документ с сохранением цвета, необходимо выбрать цветной тип изображения. В других случаях используйте серый тип изображения.
Вопросы:

Зачем нужны программы распознавания текста?

Как происходит распознавание текста?

Какие программы распознания текста вы знаете? Какими пользовались?

Какое разрешение является оптимальным для сканирования текста, изображений?
Источник: studfile.net
Методы распознавания текста
Буквально вчера прошла 61-я студенческая научная конференция в Южном Федеральном Университете в городе Таганроге, на которой я представлял доклад по методам распознавания текста на графических изображениях. И хотелось бы поделиться этим с еще большим количеством слушателей и читателей. Кому интересно почитать про велосипеды студента-новичка в этой области, прошу под кат.
Картинки и кусочки кода присутствуют.
Немного теории
Тема распознавания текста попадает под раздел распознавания образов. И для начала коротко о самом распознавании образов.
Распознавание образов или теория распознавания образов это раздел информатики и смежных дисциплин, развивающий основы и методы классификации и идентификации предметов, явлений, процессов, сигналов, ситуаций и т. п. объектов, которые характеризуются конечным набором некоторых свойств и признаков. Данное определение нам дает Wikipedia.
- Изучение способностей к распознаванию, которыми обладают живые существа, объяснение и моделирование их;
- Развитие теории и методов построения устройств, предназначенных для решения отдельных задач в прикладных целях.
Итак, моя тема — это распознавание текста на графических изображениях и сейчас говорить о важности данного подраздела не приходиться. Всем давно известно, что существуют миллионы старых книг, которые хранятся в хранилищах строгого режима, доступ к которым имеет только специализированный персонал. Использование этих книг запрещено по причине их ветшалости и дряхлости, так как возможно, что они могут рассыпаться прямо в руках читателя, но знания которые они хранят, представляют, несомненно, большой клад для человечества и поэтому оцифровка этих книг столь важна. Именно этим в частности занимаются специалисты в области обработки данных.
- Сравнение с заранее подготовленным шаблоном;
- Распознавание с использованием критериев, распознаваемого объекта;
- Распознавание при помощи самообучающихся алгоритмов, в том числе при помощи нейронных сетей.
Теперь о самой работе. Было написано приложение, способное распознавать текст при использовании изображений высокого либо среднего качества, со слабым шумом либо без него. Приложение способно распознавать буквы английского алфавита, верхнего и нижнего регистра. Изображение подается для распознавания непосредственно из самого приложения.
Фильтрация и обработка
Так как этап обнаружения был опущен и вставлен этап предобработки то изображение в большинстве своем выглядит следующим образом.

Данное изображение обрабатывается двумя фильтрами. Медианным и монохромом. В приложении использовалась измененная версия медианного фильтра с увеличением значения компоненты красного цвета.
Медианный фильтр
public static void Median(ref Bitmap image) < var arrR = new int[8]; var arrG = new int[8]; var arrB = new int[8]; var outImage = new Bitmap(image); for (int i = 1; i < image.Width — 1; i++) for (int j = 1; j < image.Height — 1; j++) < for (int i1 = 0; i1 < 2; i1++) for (int j1 = 0; j1 < 2; j1++) < var p = image.GetPixel(i + i1 — 1, j + j1 — 1); arrR[i1 * 3 + j1] = ((p.R + p.G + p.B) / 3) arrG[i1 * 3 + j1] = ((p.R + p.G + p.B) / 3) >> 8 arrB[i1 * 3 + j1] = ((p.R + p.G + p.B) / 3) >> 16 > Array.Sort(arrR); Array.Sort(arrG); Array.Sort(arrB); outImage.SetPixel(i, j, Color.FromArgb(arrR[3], arrG[4], arrB[5])); > image = outImage; >
Данный фильтр применятся для минимизации шума и смазывания острых краев букв (засечек и т.п.). После этого изображение обрабатывает монохром. То есть происходит четкая бинаризация, при этом границы букв четко фиксируются.
Монохром
public static void Monochrome(ref Bitmap image, int level) < for (int j = 0; j < image.Height; j++) < for (int i = 0; i < image.Width; i++) < var color = image.GetPixel(i, j); int sr = (color.R + color.G + color.B) / 3; image.SetPixel(i, j, (sr < level ? Color.Black : Color.White)); >> >
Сегментация
После предобработки в процессе распознавания происходит сегментация изображения. Опять-таки, так как этап обнаружения опущен, то для процесса сегментации принята следующая эвристика. Предполагается, что предложения текста расположены горизонтально и не создают пересечений друг с другом. Тогда задача сегментации не составляет труда.
Задается среднее значение расстояния между двумя буквами в слове. После этого изображение делится на строки путем поиска полных белых полос. Далее эти полосы делятся на слова путем поиска белых полос определенной ширины. После всего этого выделенные слова передаются на заключительный этап, и они делятся на буквы. Таким образом на выходе модуля сегментации мы имеет весь текст представленный изображениями букв этого текста.

Непосредственно перед распознаванием изображение нормализуется и приводится до размеров шаблонов, подготовленных заранее.
Далее наступает сам процесс распознавания. Для пользователя имеется два выбора, при помощи метрик и при помощи нейронной сети.
Распознавание
Рассмотрим первый случай — распознавание при помощи метрик.
Метрика – некоторое условное значение функции, определяющее положение объекта в пространстве. Таким образом, если два объекта расположены близко друг от друга, то есть похожи (например, две буквы А написанные разным шрифтом), то метрики для таких объектов будут совпадать или быть предельно похожими. Для распознавания в этом режиме была выбрана метрика Хэмминга.
Метрика Хэмминга – метрика которая показывает, как сильно объекты не похожи между собой.
Данную метрику часто используют при кодировании информации и передаче данных. Например, после сеанса передачи на выходе имеется следующая последовательность бит (1001001), также нам известно, что должна прийти другая последовательность бит (1000101). Мы вычисляем метрику путем сравнения частей последовательности с соответствующими местами из другой последовательности. Таким образом метрика Хэмминга в нашем случае равна 2. Так как объекты отличаются в двух позициях. 2- это степень непохожести, чем больше, тем хуже в нашем случае.
Следовательно, чтобы определить какая буква изображена нужно найти ее метрику со всеми готовыми шаблонами. И тот шаблон, чья метрика окажется наиболее близкой к 0 будет ответом.
Но как показала практика подсчет одной лишь метрики не дает положительного результата, так многие буквы похожи между собой. например «j» «i», что приводит к ошибочному распознаванию.
Тогда было принято решение придумать новые метрики, позволяющие разграничить некоторое множество букв в отдельный класс. В частности, были реализованы метрики (Отражения горизонтального и вертикального, преобладания веса горизонтального и вертикального).
Экспериментом было выяснено, что такие буквы как «H» «I» «i» «O» «o» «X» «x» «l» обладают суперсимметрией (полностью совпадают со своими отражениями и значимые пиксели распределены равномерно по всему изображению), поэтому они были вынесены в отдельный класс, что сокращает перебор всех метрик примерно в 6 раз. Аналогичные действия были проведены в отношении других букв. В среднем уменьшение перебора достигает примерно 3 раза.
Также есть уникальная буква такая как «J», которая находится в своем классе одна, и значит идентифицируются однозначно. Далее, для каждого класса высчитывается метрика Хэмминга, которая на данном этапе дает лучшие показатели чем при прямом применении.
При создании шаблонов использовался шрифт «consolas», поэтому, если распознаваемый текст написан этим шрифтом, распознавание имеет точность порядка 99 процентов. При изменении шрифта, точность падает до 70 процентов.
Второй способ распознавания – при помощи нейронной сети.
Что такое нейронная сеть и в биологическом понимании, и в математическом я рассказывать не буду, так как данного материала полно в интернете и повторять его не хочется. Сказать лишь можно то, что в математическом смысле нейронная сеть — это лишь модель биологического определения.
Существуют также множества разновидностей этих моделей. В своей работе я использовал однослойную сеть Кохонена.
Принцип работы нейронной сети таков, что поучив на входной слой нейронов новое изображение сеть реагирует импульсом того или иного нейрона. Так как все нейроны поименованы значениями букв, следовательно, среагировавший нейрон и несет ответ распознавания. Углубляясь в терминологию сетей можно сказать, что нейрон помимо выхода имеет также множество входов. Данные входы описывают значение пикселя изображения. То есть, если имеется изображение 16х16, входов у сети должно быть 256.
Каждый вход воспринимается с определенным коэффициентом и в результате, по окончанию распознавания на каждом нейроне скапливается определенный заряд, чем заряд будет больше тот нейрон и испустит импульс.
Но что бы коэффициенты входов были правильно настроены необходимо сначала обучить сеть. Этим занимается отдельный модуль обучения. Данный модуль берет очередное изображение из обучающей выборки и скармливает сети. Сеть анализирует все позиции черных пикселей и выравнивает коэффициенты минимизируя ошибку совпадения методом градиента, после чего определенному нейрону сопоставляется данное изображение.
Обучение
public void Teach(Bitmap img, Neuron correctNeuron) < var vector = GetVector(img); for (int i = 0; i < vector.Length; i++) < vector[i] *= 10; correctNeuron.Weigths[i] = correctNeuron.Weigths[i] + 0.5 * (vector[i] — correctNeuron.Weigths[i]); >>
По окончанию обучения каждый нейрон похож на холст художника, где на местах в которых чаще всего встречались черные пиксели наиболее темная краска (значение заряда больше), а там, где реже совсем светлый тон.

Все коэффициенты выровнены и готовы воспринимать изображения.
Точность распознавания при этом методе достигает 80 процентов. Следует заметить, что точность распознавания зависит от обучающей выборки, как от количества, так и от качества.
P.S. Хотелось бы услышать конструктивную критику по поводу стиля написания, манеры представления и полноты освещения.
- распознавание образов
- распознавание текста
- метрики
- нейронные сети
Источник: habr.com