
Юникод: необходимый практический минимум для каждого разработчика
Юникод — это очень большой и сложный мир, ведь стандарт позволяет ни много ни мало представлять и работать в компьютере со всеми основными письменностями мира. Некоторые системы письма существуют уже более тысячи лет, причём многие из них развивались почти независимо друг от друга в разных уголках мира. Люди так много всего придумали и оно зачастую настолько непохоже друг на друга, что объединить всё это в единый стандарт было крайне непростой и амбициозной задачей.
Чтобы по-настоящему разобраться с Юникодом нужно хотя бы поверхностно представлять себе особенности всех письменностей, с которыми позволяет работать стандарт. Но так ли это нужно каждому разработчику? Мы скажем, что нет. Для использования Юникода в большинстве повседневных задач, достаточно владеть разумным минимумом сведений, а дальше углубляться в стандарт по мере необходимости.
В статье мы расскажем об основных принципах Юникода и осветим те важные практические вопросы, с которыми разработчики непременно столкнутся в своей повседневной работе.
Понимание Юникода и UTF-8
Зачем понадобился Юникод?
До появления Юникода, почти повсеместно использовались однобайтные кодировки, в которых граница между самими символами, их представлением в памяти компьютера и отображением на экране была довольно условной. Если вы работали с тем или иным национальным языком, то в вашей системе были установлены соответствующие шрифты-кодировки, которые позволяли отрисовывать байты с диска на экране таким образом, чтобы они представляли смысл для пользователя.
Если вы распечатывали на принтере текстовый файл и на бумажной странице видели набор непонятных кракозябр, это означало, что в печатающее устройство не загружены соответствующие шрифты и оно интерпретирует байты не так, как вам бы этого хотелось.
У такого подхода в целом и однобайтовых кодировок в частности был ряд существенных недостатков:
- Можно было одновременно работать лишь с 256 символами, причём первые 128 были зарезервированы под латинские и управляющие символы, а во второй половине кроме символов национального алфавита нужно было найти место для символов псевдографики (╔ ╗).
- Шрифты были привязаны к конкретной кодировке.
- Каждая кодировка представляла свой набор символов и конвертация из одной в другую была возможна только с частичными потерями, когда отсутствующие символы заменялись на графически похожие.
- Перенос файлов между устройствами под управлением разных операционных систем был затруднителен. Нужно было либо иметь программу-конвертер, либо таскать вместе с файлом дополнительные шрифты. Существование Интернета каким мы его знаем было невозможным.
- В мире существуют неалфавитные системы письма (иероглифическая письменность), которые в однобайтной кодировке непредставимы в принципе.
Основные принципы Юникода
Все мы прекрасно понимаем, что компьютер ни о каких идеальных сущностях знать не знает, а оперирует битами и байтами. Но компьютерные системы пока создают люди, а не машины, и для нас с вами иногда бывает удобнее оперировать умозрительными концепциями, а затем уже переходить от абстрактного к конкретному.
Unicode: как это работает
Важно! Одним из центральных принципов в философии Юникода является чёткое разграничение между символами, их представлением в компьютере и их отображением на устройстве вывода.
Вводится понятие абстрактного юникод-символа, существующего исключительно в виде умозрительной концепции и договорённости между людьми, закреплённой стандартом. Каждому юникод-символу поставлено в соответствие неотрицательное целое число, именуемое его кодовой позицией (code point).
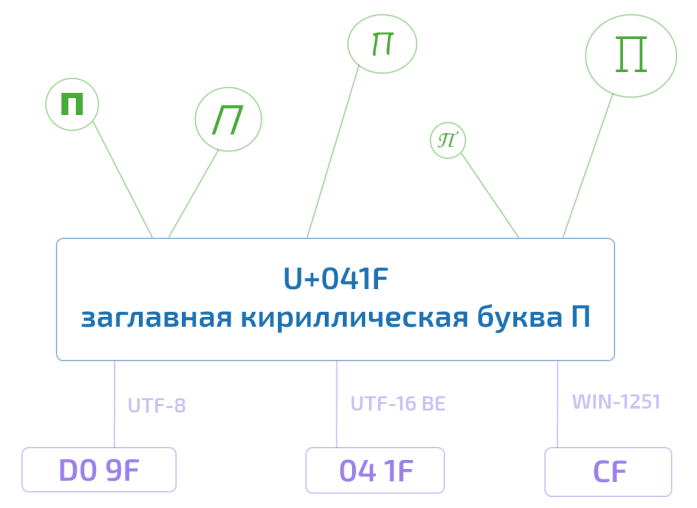
Так, например, юникод-символ U+041F — это заглавная кириллическая буква П. Существует несколько возможностей представления данного символа в памяти компьютера, ровно как и несколько тысяч способов отображения его на экране монитора. Но при этом П, оно и в Африке будет П или U+041F.
Это хорошо нам знакомая инкапсуляция или отделение интерфейса от реализации — концепция, отлично зарекомендовавшая себя в программировании.
Получается, что руководствуясь стандартом, любой текст можно закодировать в виде последовательности юникод-символов
Привет U+041F U+0440 U+0438 U+0432 U+0435 U+0442
записать на листочке, упаковать в конверт и переслать в любой конец Земли. Если там знают о существовании Юникода, то текст будет воспринят ими ровно так же, как и нами с вами. У них не будет ни малейших сомнений, что предпоследний символ — это именно кириллическая строчная е (U+0435), а не скажем латинская маленькая e (U+0065). Обратите внимание, что мы ни слова не сказали о байтовом представлении.
Хотя юникод-символы и называются символами, они далеко не всегда соответствуют символу в традиционно-наивном понимании, например букве, цифре, пунктуационному знаку или иероглифу. (Подробнее смотри под спойлером.)
Примеры различных юникод-символов
- U+0000: нулевой символ;
- U+D800–U+DFFF: младшие и старшие суррогаты для технического представления кодовых позиций в диапазоне от 10000 до 10FFFF (читай: за пределами БМЯП/BMP) в семействе кодировок UTF-16;
- и т.д.
- U+0020 (пробел);
- U+00A0 (неразрывный пробел, в HTML);
- U+2002 (полукруглая шпация или En Space);
- U+2003 (круглая шпация или Em Space);
- и т.д.
- U+0300 и U+0301: знаки основного (острого) и второстепенного (слабого) ударений;
- U+0306: кратка (надстрочная дуга), как в й;
- U+0303: надстрочная тильда;
- и т.д.
Что такое символ, чем отличается графемный кластер (читай: воспринимаемое как единое целое изображение символа) от юникод-символа и от кодового кванта мы расскажем в следующий раз.
Кодовое пространство Юникода
Кодовое пространство Юникода состоит из 1 114 112 кодовых позиций в диапазоне от 0 до 10FFFF. Из них к девятой версии стандарта значения присвоены лишь 128 237. Часть пространства зарезервирована для частного использования и консорциум Юникода обещает никогда не присваивать значения позициям из этих специальный областей.
Ради удобства всё пространство поделено на 17 плоскостей (сейчас задействовано шесть их них). До недавнего времени было принято говорить, что скорее всего вам придётся столкнуться только с базовой многоязыковой плоскостью (Basic Multilingual Plane, BMP), включающей в себя юникод-символы от U+0000 до U+FFFF. (Забегая немного вперёд: символы из BMP представляются в UTF-16 двумя байтами, а не четырьмя). В 2016 году этот тезис уже вызывает сомнения. Так, например, популярные символы Эмодзи вполне могут встретиться в пользовательском сообщении и нужно уметь их корректно обрабатывать.
Кодировки
Если мы хотим переслать текст через Интернет, то нам потребуется закодировать последовательность юникод-символов в виде последовательности байтов.
Стандарт Юникода включает в себя описание ряда юникод-кодировок, например UTF-8 и UTF-16BE/UTF-16LE, которые позволяют кодировать всё пространство кодовых позиций. Конвертация между этими кодировками может свободно осуществляться без потерь информации.
Также никто не отменял однобайтные кодировки, но они позволяют закодировать свой индивидуальный и очень узкий кусочек юникод-спектра — 256 или менее кодовых позиций. Для таких кодировок существуют и доступны всем желающим таблицы, где каждому значению единственного байта сопоставлен юникод-символ (см. например CP1251.TXT). Несмотря на ограничения, однобайтные кодировки оказываются весьма практичными, если речь идёт о работе с большим массивом моноязыковой текстовой информации.
Из юникод-кодировок самой распространённой в Интернете является UTF-8 (она завоевала пальму первенства в 2008 году), главным образом благодаря её экономичности и прозрачной совместимости с семибитной ASCII. Латинские и служебные символы, основные знаки препинания и цифры — т.е. все символы семибитной ASCII — кодируются в UTF-8 одним байтом, тем же, что и в ASCII. Символы многих основных письменностей, не считая некоторых более редких иероглифических знаков, представлены в ней двумя или тремя байтами. Самая большая из определённых стандартом кодовых позиций — 10FFFF — кодируется четырьмя байтами.
Обратите внимание, что UTF-8 — это кодировка с переменной длиной кода. Каждый юникод-символ в ней представляется последовательностью кодовых квантов с минимальной длиной в один квант. Число 8 означает битовую длину кодового кванта (code unit) — 8 бит. Для семейства кодировок UTF-16 размер кодового кванта составляет, соответственно, 16 бит. Для UTF-32 — 32 бита.
Если вы пересылаете по сети HTML-страницу с кириллическим текстом, то UTF-8 может дать весьма ощутимый выигрыш, т.к. вся разметка, а также JavaScript и CSS блоки будут эффективно кодироваться одним байтом. К примеру главная страница Хабра в UTF-8 занимает 139Кб, а в UTF-16 уже 256Кб. Для сравнения, если использовать win-1251 с потерей возможности сохранять некоторые символы, то размер, по сравнению с UTF-8, сократится всего на 11Кб до 128Кб.
Для хранения строковой информации в приложениях часто используются 16-битные юникод-кодировки в силу их простоты, а так же того факта, что символы основных мировых систем письма кодируются одним шестнадцатибитовым квантом. Так, например, Java для внутреннего представления строк успешно применяет UTF-16. Операционная система Windows внутри себя также использует UTF-16.
В любом случае, пока мы остаёмся в пространстве Юникода, не так уж и важно, как хранится строковая информация в рамках отдельного приложения. Если внутренний формат хранения позволяет корректно кодировать все миллион с лишним кодовых позиций и на границе приложения, например при чтении из файла или копировании в буфер обмена, не происходит потерь информации, то всё хорошо.
Для корректной интерпретации текста, прочитанного с диска или из сетевого сокета, необходимо сначала определить его кодировку. Это делается либо с использованием метаинформации, предоставленной пользователем, записанной в тексте или рядом с ним, либо определяется эвристически.
В сухом остатке
Информации много и имеет смысл привести краткую выжимку всего, что было написано выше:
- Юникод постулирует чёткое разграничение между символами, их представлением в компьютере и их отображением на устройстве вывода.
- Юникод-символы не всегда соответствуют символу в традиционно-наивном понимании, например букве, цифре, пунктуационному знаку или иероглифу.
- Кодовое пространство Юникода состоит из 1 114 112 кодовых позиций в диапазоне от 0 до 10FFFF.
- Базовая многоязыковая плоскость включает в себя юникод-символы от U+0000 до U+FFFF, которые кодируются в UTF-16 двумя байтами.
- Любая юникод-кодировка позволяет закодировать всё пространство кодовых позиций Юникода и конвертация между различными такими кодировками осуществляется без потерь информации.
- Однобайтные кодировки позволяют закодировать лишь небольшую часть юникод-спектра, но могут оказаться полезными при работе с большим объёмом моноязыковой информации.
- Кодировки UTF-8 и UTF-16 обладают переменной длиной кода. В UTF-8 каждый юникод-символ может быть закодирован одним, двумя, тремя или четырьмя байтами. В UTF-16 — двумя или четырьмя байтами.
- Внутренний формат хранения текстовой информации в рамках отдельного приложения может быть произвольным при условии корректной работы со всем пространством кодовых позиций Юникода и отсутствии потерь при трансграничной передаче данных.
Краткое замечание про кодирование
С термином кодирование может произойти некоторая путаница. В рамках Юникода кодирование происходит дважды. Первый раз кодируется набор символов Юникода (character set), в том смысле, что каждому юникод-символу ставится с соответствие кодовая позиция. В рамках этого процесса набор символов Юникода превращается в кодированный набор символов (coded character set). Второй раз последовательность юникод-символов преобразуется в строку байтов и этот процесс также называется кодирование.
В англоязычной терминологии существуют два разных глагола to code и to encode, но даже носители языка зачастую в них путаются. К тому же термин набор символов (character set или charset) используется в качестве синонима к термину кодированный набор символов (coded character set).
Всё это мы говорим к тому, что имеет смысл обращать внимание на контекст и различать ситуации, когда речь идёт о кодовой позиции абстрактного юникод-символа и когда речь идёт о его байтовом представлении.
В заключение
В Юникоде так много различных аспектов, что осветить всё в рамках одной статьи невозможно. Да и ненужно. Приведённой выше информации вполне достаточно, чтобы не путаться в основных принципах и работать с текстом в большинстве повседневных задач (читай: не выходя за рамки BMP). В следующих статьях мы расскажем о нормализации, дадим более полный исторический обзор развития кодировок, побеседуем о проблемах русскоязычной юникод-терминологии, а также сделаем материал о практических аспектах использования UTF-8 и UTF-16.
Источник: habr.com
Что такое Юникод?
Юникод (Unicode), это многоязычный, основанный на ASCII стандарт кодирования символов, а также, связанное с ним, семейство многобайтных кодировок. Если некоторые слова из предыдущего предложения вам не понятны, давайте рассмотрим их подробнее.
Что такое кодировка
Современные компьютеры всё ещё достаточно глупые и, в большинстве своём, не умеют работать ни с чем, кроме чисел. Мы рассматриваем на своих мониторах фотографии, смотрим фильмы, играем в игры. Но для компьютеров всё это лишь безликий поток нулей и единичек. Так же и текст — для компьютера это просто набор байтов. Буквы и любые другие символы представляются в машинной памяти, как числа.
Поэтому программистам при работе с текстом приходится делать подобные соглашения: «А давайте каждому символу будет соответствовать один байт. Причём, если в байте будет число 43, то будем считать, что это цифра ноль. А если число 66, то пусть это будет заглавная латинская буква B».
Подобный список всех используемых символов и соответствующих им чисел и называется кодировкой. Вы, скорее всего, уже слышали названия многих кодировок: Windows-1251, KOI-8, ну и, конечно, Unicode.
Крякозябры
Наверное, часто бывала ситуация, когда вы открываете страницу в браузере, а там вместо текста какая-то мешанина из чудных символов. Или просто сплошные вопросительные знаки. Или вы пишете любовное письмо своей девушке, а она звонит вам и говорит «что за нечитаемый бред ты мне прислал? Я обиделась».
Это всё из-за того, что в мире наплодилось слишком много разных кодировок. И текст в одной из них выглядит совершенно не так, как в другой. Дело в том, что компьютер не знает какую кодировку вы используете для текста. Для него это просто последовательность каких-то чисел.
Например, ваш текстовый редактор настроен на кодировку Windows-1251. И вы пишете «Здравствуйте, дорогая Маша!». Вы нажимаете первую букву и программа думает: «ага, русская заглавная буква Зэ — код 199». И записывает число 199 в файл. Маша получает ваше письмо, но в её почтовом клиенте стоит кодировка KOI8-R (потому что Маша любит старый Unix).
А в этой кодировке числу 199 соответствует строчная буква «г». И Маша читает: «гДПЮБЯРБСИРЕ, ДНПНЦЮЪ лЮЬЮ!». Маша обиделась!
Чтобы подобного не происходило, нужно каким-то образом указывать кодировку в которой набран текст. Например, в HTML это делается с помощью тега:
ASCII
В определённый момент времени распространение получила кодировка ASCII (American Standard Code for Information Interchange). В ней определены 128 символов с кодами от 0 до 127. Сюда включён латинский алфавит, цифры и основные знаки препинания (
Практически все современные кодировки, использующиеся на персональных компьютерах являются ASCII-совместимыми. То есть первые 128 символов у них кодируются одинаково, а различия начинаются с кода 128 и выше. Вышеупомянутые Windows-1251 и KOI8-r также основаны на ASCII и если бы письмо начиналось бы с «Hello, my dear Maria!», то недопонимания не возникло бы.
Основан на ASCII и Юникод.
Однобайтные кодировки
Одна из причин, по которой появилось такое большое количество кодировок, это то, что вначале каждая компания придумывала свои стандарты, не обращая внимания на другие. Вторая причина заключается в том, что старые кодировки были однобайтными. То есть каждому символу в тексте соответствует один байт в памяти компьютера.
Однобайтные кодировки всем хороши: они компактны, с ними легко работать (нужно достать пятый символ — просто берём пятый байт от начала). Единственная проблема: в них помещается мало символов. Ровно столько, сколько значений может принимать один байт, то есть обычно, это 256. Например, в Windows-1251 мы отдали 128 символов под ASCII, добавили 66 букв русского алфавита (строчные и заглавные), несколько знаков препинания и вот у нас уже остаётся не так много свободных позиций. Даже на псевдографику не хватает.
То есть свести в одну кодировку все возможные символы даже европейских алфавитов достаточно сложно. А уж для китайцев с их тысячами иероглифов вообще всё тоскливо. А о всяких смайликах, эмоджи и иконках самолётиков и думать нечего. Поэтому для кириллицы приходилось изобретать свою кодировку, а для греческого языка другую.
Впрочем, такая ситуация сохранялась достаточно долго. Потому что проблемы англоязычных пользователей и программистов решила ASCII, а до китайских проблем им не было дела. С ростом же глобального интернета вдруг оказалось, что в мире говорят не только на английском языке, поэтому с кодировками нужно что-то менять.
Многобайтные кодировки
Самым простым решением было взять два байта вместо одного. Плюс такого решения: теперь можно в рамках одной кодировки использовать 65 тысяч символов. Минусы тоже есть:
- Для всех возможных символов, иероглифов и смайликов даже 65 тысяч символов мало.
- Текстовые файлы стали занимать вдвое больше места, даже тексты на английском. Слишком расточительно.
- Кодировки перестали быть ASCII-совместимыми и многие программы не могли с ними работать.
Стандарт Unicode
В конечном итоге всё вылилось в стандарт Юникода, который худо-бедно, но решает практически все стоявшие перед кодировками проблемы.
С одной стороны, Юникод позволяет кодировать практически неограниченное количество символов. В последнем стандарте определено более 100 000 различных символов всех современных и многих уже мёртвых языков, а также различные иконки и пиктограммы. С другой стороны, некоторые способы кодирования позволяют Юникоду оставаться ASCII-совместимыми. Что позволяет работать, как и раньше многим программам, а также американским и другим англоязычным пользователям, многие из которых появления Юникода даже не заметили. В Юникоде также собраны все символы из всех популярных стандартов кодирования, что позволяет преобразовать в него любой текст из старой кодировки.
Практически все современные программы, работающие с текстом, понимают Юникод. Более того, обычно они в нём и работают. Например, даже когда вы открываете сайт в старой доброй Windows-1251, браузер сначала внутри у себя перекодирует все тексты в Юникод, а потом отображает их. В общем, Юникод, это светлое будущее интернета и всей компьютерной индустрии.
Отличие набора символов от кодировки
Термины «кодировка», «стандарт кодирования», «набор символов» обычно используются, как синонимы, но между ними есть и тонкие различия. Важно понимать разницу между «стандартом» и, собственно, «кодировкой». Некий стандарт просто говорит, что буква «A», это число 65, а буква «B» — 66. Кодировка же отвечает за то, как эти числа представить в памяти компьютера.
В эпоху однобайтных кодировок, это различие было практически неуловимо. Число 65 — байт со значением 65 или последовательность битов 01000001 . Для многобайтных же уже возникают вопросы: сколько байтов использовать, в каком порядке, фиксированное число байтов или нет?
То есть в стандарте Юникода определено, что кириллической букве «А» соответствует абстрактное число 1040. Как представить это число в виде последовательности байтов решает уже конкретная кодировка — UTF-8, UTF-16, UTF-32.
То есть текстовый файл не может быть в кодировке «Юникод», а только в конкретной кодировке «UTF-8» или «UTF-16».
Кодировки и шрифты
Юникод, как и любая другая кодировка не описывает того, как следует отрисовывать символы. Для него число 1040, это «кириллическая заглавная буква А». А какая она, печатная, прописная, наклонная, жирная или с завитушками, это не его дело.
За изображение символа отвечают шрифты. Поэтому один и тот же символ в разных шрифтах может выглядеть по разному, а то и вообще отсутствовать.
Мы используем cookie, чтобы сделать сайт максимально удобным для вас. Подробнее
Источник: unicode-table.com
Кодировка символов и Юникод: что нужно знать разработчику
Перевод статьи «What Every Developer Must Know About Encoding and Unicode».

Если вы пишете международное приложение, в котором будут использоваться разные языки, вы должны разбираться в кодировке символов. Впрочем, эту статью стоит почитать, даже если вам просто любопытно, как слова выводятся на экран.
Я расскажу краткую историю кодировки символов (и о том, сколь мало она была стандартизирована), а затем чуть подробнее остановлюсь на том, чем мы пользуемся в настоящее время.
Введение в кодирование символов
Компьютер понимает только двоичный код. То есть только нули и единицы. Каждая из этих цифр — один бит. Восемь таких цифр (нулей и/или единиц) — один байт.
В конечном итоге все в компьютере сводится к двоичному коду: языки программирования, движения мыши, ввод текста и все слова на экране.
Но если весь текст, который вы читаете, тоже был в форме нулей и единиц, то как же произошло его превращение в понятные человеку слова? Чтобы в этом разобраться, давайте вернемся к истокам.
Краткая история кодировки
На заре интернета в нем все было исключительно на английском. Нам не приходилось беспокоиться о символах, которых в английском языке просто нет. Для сопоставления всех нужных символов с числовыми кодами использовалась таблица ASCII (American standard code for information interchange).
Получаемый компьютером двоичный код:
01001000 01100101 01101100 01101100 01101111 00100000 01110111 01101111 01110010 01101100 01100100
при помощи ASCII переводился в «Hello world».
Одного байта (8 бит) вполне хватало, чтобы уникально закодировать любой символ английского языка, а также некоторое количество управляющих символов. Часть этих управляющих символов использовалась для телетайпов, которые были довольно распространены в то время. Сейчас, впрочем, не используются ни телетайпы, ни эти символы.
Что из себя представляют управляющие символы? Например, управляющий символ с кодом 7 (111 в двоичной системе) служит для подачи компьютером звукового сигнала. Символ с кодом 8 (1000 в двоичной системе) перемещает позицию печати на один символ назад (например, для наложения одного символа на другой или для стирания предшествующего символа). Символ с кодом 12 (1100 в двоичной системе) отвечает за очистку экрана терминала.
В то время компьютеры использовали 8 бит для одного байта (хотя так было не всегда), так что проблем не было. Это позволяло закодировать все управляющие символы, все цифры и буквы английского алфавита, да еще и свободные коды оставались! Дело в том, что 1 байт может принимать 256 (0 — 255) разных значений. То есть потенциально можно было закодировать 255 символов, а в ASCII их было всего 127. Так что 128 кодов оставались неиспользованными.
Давайте посмотрим на саму таблицу ASCII. Все символы алфавита в верхнем и нижнем регистре, а также цифры получили двоичные коды. Первые 32 символа таблицы — управляющие, они не имеют графического отображения.

Как видите, символы кончаются кодом 127. У нас осталось свободное место в таблице.
Проблемы с ASCII
При помощи кодов 128-255 можно было бы закодировать еще какие-нибудь символы. Люди задумались, какими именно символами лучше заполнить таблицу. Но у всех были разные идеи на этот счет.
Американский институт национальных стандартов (American national standards institute, ANSI) разметил, за какие символы должны отвечать коды 0-127 (т. е., те, которые уже были размечены ASCII). Но остальные коды остались открытыми.
Примечание: не путайте ANSI (институт) и ASCII (таблица).
Назначение кодов 0-127 никто не оспаривал. Проблема была в том, что делать с оставшимися.
В первых компьютерах IBM коды ASCII 128-255 представляли следующие символы:

Но в других компьютерах было по-другому. И буквально каждый производитель стремился по-своему применить свободные коды из конца таблицы ASCII.
Эти разные варианты концовок таблицы ASCII назывались кодовыми страницами.
Что такое кодовые страницы ASCII?
Пройдя по ссылке, вы найдете коллекцию из более чем 465 различных кодовых страниц! Как видите, даже для одного языка существовали разные кодовые страницы. Например, для греческого и китайского есть по нескольку кодовых страниц.
Но как же, черт побери, все это стандартизировать? Как работать с несколькими языками? А с одним языком, но разными кодовыми страницами? А с не-английским языком?
В китайском языке больше 100 тысяч различных символов. Даже если бы мы договорились отдать под символы китайского языка все оставшиеся коды, их бы все равно не хватило.
Выглядело все это довольно плохо. Для этой проблемы даже придумали отдельный термин: mojibake (на японском это слово означает «трансформация символа»).
Это неправильно декодированный текст, в котором символы систематически заменяются другими, причем часто — даже из других систем письменности.

С ума сойти…
Вот именно! У нас не было ни единого шанса надежно обмениваться данными.
Интернет — всего лишь огромная сеть компьютеров по всему миру. Представьте, что было бы, если бы каждая страна самостоятельно определяла стандарты кодировки. Тогда компьютеры в Греции нормально выводили бы только греческий язык, а в США — только английский.
ASCII не подходила для использования в реальном мире. Чтобы интернет был всемирным, нам нужно было что-то менять. Ну, или вечно работать с сотнями кодовых страниц.
���Если только вам������, конечно, не ���нравится ��� расшифровывать такие абзацы.�֎֏0590��׀ׁׂ׃ׅׄ׆ׇ
И тут пришел Юникод
Юникод (Unicode) иногда называют UCS — универсальным набором символов (Universal Coded Character Set), и даже ISO/IEC 10646. Но Юникод — наиболее распространенное название.
Юникод состоит из множества кодовых пунктов (code points, по сути — шестнадцатеричные числа), связанных с символами. Коллекция кодовых пунктов называется набором символов. Вот этот набор — и есть Юникод.
Люди проделали огромную работу, назначив коды всем символам всех языков, а мы можем просто пользоваться результатами их труда. Отображение кодов выглядит так:
«Hello World» U+0048 : LATIN CAPITAL LETTER H U+0065 : LATIN SMALL LETTER E U+006C : LATIN SMALL LETTER L U+006C : LATIN SMALL LETTER L U+006F : LATIN SMALL LETTER O U+0020 : SPACE [SP] U+0057 : LATIN CAPITAL LETTER W U+006F : LATIN SMALL LETTER O U+0072 : LATIN SMALL LETTER R U+006C : LATIN SMALL LETTER L U+0064 : LATIN SMALL LETTER D
U+ указывает на то, что это стандарт Unicode, а номер — число, в которое переведен двоичный код для данного символа. В Юникоде используется шестнадцатеричная система — просто потому, что в нее проще переводить двоичный код. Впрочем, вам не придется делать это вручную, так что можно не волноваться.
Вот ссылка на ресурс, где вы можете впечатать в форму любой символ и получить его кодировку в Юникод. Или же можете просмотреть все 143859 символов здесь. В таблице можно увидеть, из какой части света происходит каждый символ!
Просто для ясности подобью итоги. В настоящее время у нас есть большой словарь кодовых пунктов с отображением на символы. Это очень большое множество символов. Н
Наконец, переходим к последнему ингредиенту.
Unicode Transform Format (UTF)
UTF («Формат преобразования Юникода») — это способ представления Юникод. Кодировки UTF определены стандартом Юникод и позволяют закодировать любой нужный нам кодовый пункт Юникод.
Есть несколько разных видов UTF-стандартов. Они отличаются количеством байтов, используемых для кодирования одного кодового пункта. В UTF-8 используется один байт на кодовый пункт, в UTF-16 — 2 байта, в UTF-32 — 4 байта.
Поскольку кодировок так много, как понять, какую использовать? Есть такая вещь как маркер последовательности байтов (англ. Byte order mark, BOM) Это двубайтный маркер в начале файла, который говорит о том, какая кодировка используется в этом файле.
UTF-8 — самая распространенная кодировка в интернете. В HTML5 она определена как предпочтительная для новых документов. Поэтому я уделю ей особое внимание.


Что такое кодировка UTF-8 и как она работает?
UTF-8 кодирует кодовые пункты Юникод 0-127 в одном байте (т. е. так же, как в ASCII). Это значит, что если вы для своей программы использовали кодировку ASCII, а ваши пользователи используют UTF-8, они не заметят никакой разницы. Все будет нормально работать.
Просто обратите внимание, насколько это классно. Нам нужно было начать внедрять и повсеместно использовать UTF-8 и при этом сохранить обратную совместимость с ASCII. Это удалось сделать, UTF-8 ничего не ломает.
В названии кодировки заложено указание на количество бит (8 бит = 1 байт), которые используются для одного кодового пункта. Но есть символы Юникод, для хранения которых требуется по нескольку байтов (раньше было до 6, теперь — до 4, в зависимости от символа). Именно это имеется в виду, когда говорят, что UTF-8 — кодировка переменной длины (см. UTF-32, — прим. ред.).
Тут все зависит от языка. Символ английского алфавита — 1 байт. Европейская латиница, иврит, арабские символы представляются 2 байтами. Для китайских, японских, корейских символов и символов других азиатских языков используются 3 байта.
Чтобы символ мог занимать больше одного байта, есть битовая комбинация, идентифицирующая знак продолжения. Она сообщает о том, что этот символ продолжается в нескольких последующих байтах. Таким образом, для английского языка вы по-прежнему будете использовать по одному байту на символ, но сможете составить и документ, содержащий символы на других языках.
Радостно сознавать, что теперь у нас полное согласие по части того, как кодировать шумерскую клинопись, а также смайлики!
Если описать весь процесс в общих чертах, то:
- сначала вы читаете BOM, чтобы узнать кодировку,
- затем расшифровываете файл в кодовые пункты Юникод,
- затем представляете символы из набора Юникод в символы, которые отрисовываются на экране.
Еще немного о UTF
Помните, что кодировка это ключ. Если я пошлю совершенно неправильную кодировку, вы не сможете ничего прочесть. Имейте это в виду, отсылая или получая данные. Зачастую в постоянно используемых нами инструментах это абстрагировано, но программист должен понимать, что происходит под капотом.
Как мы указываем кодировку? Поскольку HTML написан на английском и практически все кодировки прекрасно справляются с английскими символами, мы можем указать кодировку прямо сверху, в разделе .
Это важно сделать в самом начале , потому что если будет использована не та кодировка, парсинг HTML может начаться заново.
Мы также можем получить кодировку из заголовка Content-Type в HTTP-запросе или ответе.
В спецификации HTML5 есть любопытный способ угадать кодировку, если HTML-документ не содержит соответствующего тега, — BOM sniffing («вынюхивание BOM»). В этом случае кодировка определяется по маркеру последовательности байтов, который мы упоминали ранее.
Это все?
Работа над Юникодом продолжается. Как в любом стандарте, мы можем что-то добавлять, удалять, вносить предложения. Никакая спецификация никогда не считается окончательно завершенной.
Обычно бывает 1-2 релиза Юникода в год, найти их можно здесь.
Недавно мне попалась статья об очень интересном баге: Twitter неверно рендерил русские символы Юникода.
Если вы дочитали до сюда, — снимаю шляпу. Я знаю, информации много.
Советую также выполнить «домашнее задание».
Посмотрите, как могут ломаться сайты из-за неправильной кодировки. Я использовал вот это расширение Google Chrome для смены кодировки и пробовал читать разные страницы. Текст был совершенно непонятен. Попробуйте прочесть эту статью, например. Зайдите на Википедию.
Посмотрите на Mojibake своими глазами.
Это поможет вам проникнуться важностью кодировок.

Название этой статьи — дань уважения статье Джоела Спольски, которая познакомила меня с кодировкой и многими концепциями, о которых я и не подозревал. Именно после прочтения этой статьи я углубился в тему кодировки. Также я очень многое почерпнул из этого источника.
Изучая информацию и пытаясь упростить свою статью, я узнал о Майкле Эверсоне. С 1993 года он предложил больше 200 изменений в Юникод и добавил в стандарт тысячи символов. В 2003 году он был одним из ведущих контрибьюторов предложений в Юникод. Своим современным видом Юникод (а значит, и вообще интернет) во многом обязан именно Майклу Эверсону.
Надеюсь, у меня получилось сделать хороший обзор того, зачем нам нужны кодировки, какие проблемы они решают и что случается, если с кодировкой происходит сбой.
Источник: techrocks.ru
Unicode: визуализация занятого пространства и объяснение тех аспектов, которые должен знать каждый программист
Unicode — это слово вызывает страх и трепет в сердцах миллионов программистов по всему миру. Несмотря на то, что все мы пытаемся «поддерживать Unicode» в нашем софте, Unicode — это не просто использование wchar_t для строк, это стандарт из тысячи страниц и десятки дополнений к нему. Поэтому спустя 30 лет после появления Unicode многие программисты всё ещё понятия не имеют, что же это на самом деле такое.
Разнообразие и сложность
Как только вы начинаете изучать Unicode, сразу же становится понятно, что это «явление» намного сложнее, чем та же таблица ASCII, с которой вы уже можете быть знакомы. Дело не только в том, что Unicode содержит намного больше символов. Unicode имеет сложную внутреннюю структуру, фичи и набор разноцветных костылей, и это явно не те вещи, которые вы ожидаете от простой таблицы символов.
Но во многом именно благодаря этому Unicode поддерживает все или почти все системы письменности, которые существуют в мире: на сегодня этот стандарт поддерживает более чем 1100 языков. Но его задача не только в том, чтобы вместить все возможные языки, но и в том, чтобы позволить им сосуществовать в одном тексте — это делает задачу ещё сложнее.
Тем не менее, разбираться в особенностях Unicode всё-таки следует любому программисту: подумайте о миллионах людей, которые смогут использовать ваше ПО на своем родном языке.
Кодовое пространство
Начнем с основ. Базовые элементы — это символы, хотя правильнее будет всё же использовать термин «кодовые точки». Кодовые точки определяются по шестнадцатеричному номеру и префиксу «U+». Например, U+0041 это латинская буква «A», а U+03B8 — греческая «θ». Каждая кодовая точка также имеет собственное название и ещё несколько характеристик, указанных в базе данных символов Unicode.
Множество всех возможных кодовых точек называется кодовым пространством. Кодовое пространство Unicode состоит из 1 114 112 кодовых точек. Но лишь 128 237 (12%) из них на самом деле являются занятыми: более чем достаточно места для роста. Юникод также резервирует 138 468 кодовых точек для «приватного использования», то есть для внутренних нужд различных приложений.
Распределение кодового пространства
Лучший способ что-то понять — использовать визуализацию. (Кстати, если вы хотите понять суть каких-нибудь алгоритмов, у нас есть для вас подборка сервисов с визуализацией алгоритмов.) Ниже представлена карта всего кодового пространства, каждый пиксель соответствует одной кодовой точке. Для удобства карта поделена на поля (маленькие квадраты) размером 16×16 = 256 кодовых точек. Каждое большое поле содержит 65 536 кодовых точек. Всего существует 17 больших полей.

Белым цветом помечено незанятое пространство, синим — уже определенные символы, а зеленым — приватные кодовые точки. Красным цветом обозначены суррогатные точки, которые являются результатом особенностей кодирования в UTF-16, о них мы поговорим позже.
Первое большое поле называется «Базовое мультиязычное поле». Оно содержит почти все символы, которые используются в современных текстах, включая латинские буквы, кириллицу, греческий, китайский, японский, корейский и так далее. В своей первой версии Unicode состоял только из этого поля и был расширен лишь в 1996 году.
Второе поле содержит исторические и специальные символы, например, сумерийскую клинопись, египетские иероглифы и эмодзи. Третье поле содержит небольшое количество менее известных китайских символов. Остальные поля остаются пустыми, не считая небольшого количества редко используемых символов форматирования в 15 поле. Поля 16-17 целиком в приватном использовании.
Языки, поддерживаемые Unicode
Давайте сосредоточимся на первых трех полях, именно там происходит всё самое интересное:

Эта цветная карта обозначает 135 различных языков юникода. Китайский (бирюзовый) и корейский (коричневый) занимают основную часть базового поля (левый большой квадрат). Для сравнения, все европейские, средневосточные и южноазиатские языки вместились в первую строку базового поля.
По частоте использования в реальном мире лидирует первое поле, исключением являются эмодзи — они завоевали наши сердца, находясь во втором поле.
Кодировки
Как вы узнали раньше, кодовые точки задаются номерами с U+0000 по U+10FFFF. Но как эти номера хранятся в реальной памяти компьютера? Использование первого, что приходит в голову — обычного 32-битного целочисленного типа — было бы очень ресурсоемким и не оправданным. Нам понадобилось бы по 4 байта на каждую кодовую точку. Поэтому тут на помощь нам приходят стандарты кодирования UTF — Unicode Transformation Format.
Некоторые программисты считают, что Unicode и UTF — это разные вещи, но на самом деле UTF-8, UTF-16 и UTF-32 являются лишь стандартами преобразования UTF, которые позволяют значительно сэкономить память и повысить скорость обработки.
Например, в UTF-8 символы с кодами меньше 128 представляются всего одним байтом, а так как в Юникоде они повторяют ASCII, то текст, написанный только этими символами, будет являться текстом в ASCII — это позволяет избежать лишних конвертаций. Символы же с кодами от 128 до 65536 кодируются 2-мя байтами, аналогично существуют 3-байтные и 4-байтные коды.
Смысл UTF-16 и UTF-32 в том, чтобы представить ещё большую часть Unicode как обычную таблицу, подобную ASCII. Например, UTF-32 — это и есть большая таблица ASCII для всего юникода, но в 99% случаев хватает и UTF-8.
Комбинации знаков
До этого мы обсуждали только кодовые точки, но в юникоде символ может быть больше, чем одной кодовой точкой. Комбинации созданы для экономии памяти: именно с их помощью ставятся ударения и другие крючочки под и над буквами.
Например, букву под ударением (Á) можно описать таким образом: U+0041 (A) + U+0301 (`).
Видели в интернете м̵͉̪̫̳̖͌͋͗͌̑̎а̬̜ͣͤг̘͎̹̜͕̤͊̊̽и͕̽͌ͮͬ͡ю͉͑̏ ̛̹̬̜̪̳̹̙̿̄͋̏т̹̫͚̱̩ͅи̼̬̤̓͒ͨ̅́́̚̚п̗̔̒ͧ̇ͩ̐̔а̺̄͆ͭ ̢̜͉̮̭͚ͬ͒͐̈̚т̛̦̖͎̪̭͇̓а̛͙̳̼̺̲̜̂ͮͦ̈́̃̈́ͣк̳̘̝̔́о͉̜̆̈́й͉͍̜͛͆́̀? Она создается именно с помощью комбинации знаков.
И это только начало
Эта статья содержит более 5 000 символов, но на самом деле является лишь верхушкой айсберга. Юникод полон других сложных вещей: чего стоят одни только применения (mapping), сопоставления (collation) и двунаправленный текст. Но и это далеко не всё.
Юникод — очень сложная система. И хотя для работы программистом вам не обязательно понимать её полностью, некоторые знаний всё-таки станут полезными на практике.
Если хотите узнать больше, то можете прочитать следующие материалы:
- Стандарт;
- Манифест «UTF-8 везде»;
- Темная сторона юникода;
- Google Noto Fonts — шрифты, покрывающие весь спектр Unicode.
Но что вы точно обязаны сделать, так это поблагодарить юникод за то, что мы больше никогда не вернемся в старые времена несовместимых кодировок.
Источник: tproger.ru