
Многофункциональный PDF — редактор ABBYY FineReader 15, OCR программа
- Контакты
- Интернет-магазин
- Выберите регион
Global
Global Web Site English
North America
Canada English Mexico Español United States English
South America
Brazil Português South America Español
Europe
Easy Screen OCR для Windows и macOS распознает текст с картинок или прямо с экрана
Предположим, вам нужно извлечь откуда-нибудь печатный текст. Из защищённого PDF, с изображения, со скриншота, с сайта, где копирование текста отключено — да откуда угодно. Вы можете, конечно, установить громоздкий и мощный ABBYY FineReader, но в большинстве случаев его возможности избыточны. Крошечная утилита Easy Screen OCR распознает любой текст быстрее, чем Fine Reader запустится.
Скачайте и установите Easy Screen OCR. Приложение имеет версии для Windows и macOS. После установки и запуска в трее вашей операционной системы появится значок программы. Щёлкните по нему правой кнопкой мыши и откройте настройки (Preferences).
Распознавание текста с изображения на Python | EasyOCR vs Tesseract | Компьютерное зрение
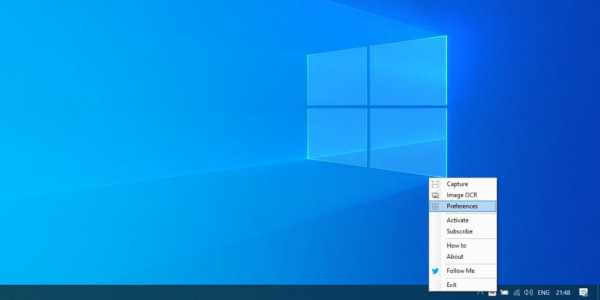
В настройках можно включить запуск программы вместе с системой. Кроме того, на вкладке «Язык» (Language) присутствует важная опция — язык распознаваемого текста.
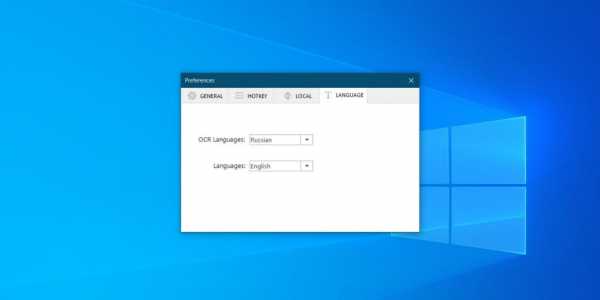
Переключившись на эту вкладку, выберите в выпадающем списке OCR Languages русский язык, а затем закройте настройки. Всего Easy Screen OCR поддерживает около сотни языков.
Теперь программа готова к работе. Чтобы распознать любой текст на экране, щелкните по значку Easy Screen OCR в трее правой кнопкой мыши и выберите пункт Capture. Вы сможете выбрать область экрана с некопируемым текстом.
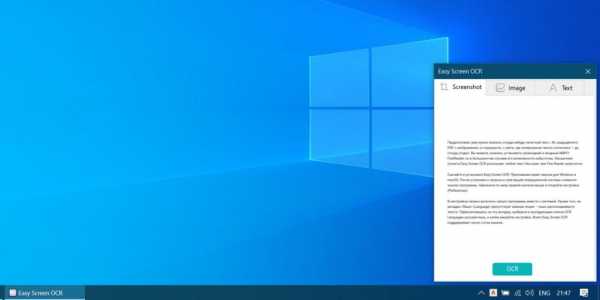
Затем внизу появится всплывающее окно с захваченной областью. Нажмите кнопку OCR, и программа покажет вам готовый текст. Его можно будет скопировать и отредактировать.
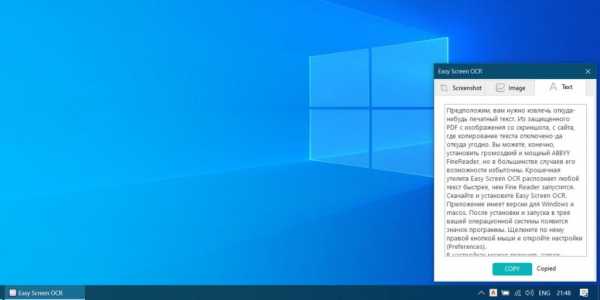
Кроме того, Easy Screen OCR способна копировать текст с картинок. Для этого выберите в меню пункт Image OCR и перетащите нужную картинку в появившееся окно. Программа умеет сканировать не только печатный текст, но даже рукописный.
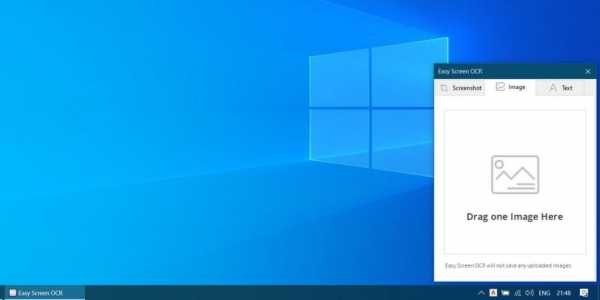
Easy Screen OCR можно попробовать бесплатно в течение трёх дней, потом придётся оформить подписку за 9 долларов в месяц (или 49 в год). Если, узнав о таких условиях, вы решили, что не так уж оно вам и надо, то вот вам список бесплатных онлайн-инструментов для распознавания текста.
Загрузить Easy Onscreen OCR →

Распознавание текста. Перевести картинку и пдф в ворд. Лучшие методы
lifehacker.ru
OCR Online: бесплатное распознавание текста
Если у вас изредка возникает необходимость распознать текст из картинок или файлов PDF, то вы знаете, что это не так уж и просто. Нет, с технической частью все в порядке — современное программное обеспечение с успехом справляется с этой задачей. Проблема в том, что бесплатное ПО в этой области практически отсутствует, а коммерческие системы довольно дороги. На выручку могли бы прийти онлайновые сервисы, но у многих из них весьма ограниченные возможности и драконовские ограничения. Однако, не все так плохо и имеются все же приятное исключение.
Сервис OCROnline позволяет бесплатно распознавать текст из изображений JPG, PNG, GIF, TIFF и файлов в формате PDF. Файлы должны быть не более 10 Мб и содержать не более 100 страниц. Поддерживается более 150 языков. На выходе вы можете получить файл в формате DOC, PDF, RTF или TXT.
Работа с сервисом очень проста и состоит всего из нескольких операций: указание языка и формата вывода, загрузка исходного документа, обработка и сохранение результата. При тестировании OCROnline показал весьма приличные результаты распознавания и даже сохранил форматирования в довольно сложном документе.
К достоинствам сервиса можно отнести прежде всего бесплатность, не плохое качество распознавания и скорость работы. Недостатком является то, что нельзя добавить более одного языка распознавания, поэтому если ваш документ содержит слова на иностранном языке, то результаты будут не удовлетворительными.
Разумеется, данный сервис нельзя рекомендовать для серьезных OCR-работ, но как палочка-выручалочка при разовой необходимости вполне сгодится, поэтому однозначно заслуживает место в закладках. На всякий случай.
Попробовать OCROnline
lifehacker.ru
Программы для распознавания текста

Утомительное перепечатывание текста для приведения его в электронный вид давно уже отошло в прошлое, ведь сейчас существуют довольно продвинутые системы распознавания, работа с которыми требует минимального вмешательства пользователя. Программы для оцифровки текста востребованы как в офисе, так и дома. В настоящее время существует довольно большое разнообразие различных приложений для распознавания текста, но какие из них действительно лучшие? Попробуем разобраться в этом вопросе.
ABBYY FineReader
Эбби Файн Ридер – самая популярная программа для сканирования и распознавания текста в России, а, возможно, и в мире. Данное приложение имеет в своем арсенале все необходимые инструменты, что и позволило ему достичь такого успеха.
Кроме сканирования и распознавания, ABBYY FineReader позволяет производить расширенное редактирование полученного текста, а также выполнять ряд других действий. Программа отличается очень качественным распознаванием текста и быстротой работы. Мировую популярность она заслужила также благодаря возможности оцифровки текстов на многих языках мира, а также мультиязычному интерфейсу. Среди немногих недостатков FineReader можно, разве что, выделить большой вес приложения и необходимость платить за пользование полноценной версией.
Скачать ABBYY FineReader
Урок: Как распознать текст в ABBYY FineReader
Readiris
Главным конкурентом Эбби Файн Ридер в сегменте оцифровки текста является приложение Readiris. Это функциональный инструмент для распознавания текста как со сканера, так и с сохраненных файлов различных форматов (PDF, PNG, JPG и др.). Хотя по функционалу данная программа несколько уступает ABBYY FineReader, она значительно превосходит большинство других конкурентов. Главной же фишкой Readiris является возможность интеграции с целым рядом облачных сервисов для хранения файлов. Недостатки у Readiris практически те же, что и у ABBYY FineReader: большой вес и необходимость платить немалые деньги за полноценную версию.

VueScan
Разработчики VueScan главное внимание сконцентрировали все-таки не на процессе распознавания текста, а на механизме сканирования документов с бумажных носителей. Причем программа хороша именно тем, что работает с очень большим перечнем сканеров. Для ее взаимодействия с устройством не требуется установка драйверов.
Более того, VueScan позволяет работать с дополнительными возможностями сканеров, которые даже родные приложения этих устройств не помогают раскрыть в полной мере. Также у программы есть инструмент распознавания сканируемого текста. Но данная функция пользуется популярностью только в связи с тем, что ВуеСкан – отличное приложение для сканирования. Собственно, функционал по оцифровке текста довольно слаб и неудобен, поэтому распознавание в VueScan используется для решения несложных задач.
CuneiForm
Приложение CuneiForm – отличное решение для распознавания текста с фото, изображений, сканера. Популярность оно приобрело благодаря применению особой технологии оцифровки, совмещающей шрифтонезависимое и шрифтовое распознавание. Это позволяет максимально точно распознавать текст, учитывая даже элементы форматирования, но при этом сохранять высокую скорость работы.
В отличии от большинства программ для распознавания текста, эта абсолютно бесплатна. Но у данного продукта имеется и целый ряд недостатков. Так, он не работает с одним из самых популярных форматов – PDF, — а также имеет плохую совместимость с некоторыми моделями сканеров. Кроме того, приложение на данный момент разработчиками официально не поддерживается.
WinScan2PDF
В отличии от CuneiForm, единственной функцией WinScan2PDF является оцифровка полученного со сканера текста в формат PDF. Главное преимущество этой программы – простота использования. Она подойдет тем людям, которые очень часто сканируют бумажные документы и распознают текст в формате PDF. Главный недостаток ВинСкан2ПДФ связан с очень ограниченным функционалом.
Собственно, больше ничего данный продукт не умеет делать, кроме указанной выше процедуры. Он не может сохранять результаты распознавания в другой формат, кроме PDF, а также не предоставляет возможности оцифровки файлов изображений, которые уже хранятся на компьютере.
RiDoc
РиДок является универсальным офисным приложением для сканирования документов и распознавания текста. Его функционал все-таки немного уступает ABBYY FineReader или Readiris, но и стоимость заметно меньше. Поэтому по соотношению «цена – качество» RiDoc выглядит даже предпочтительнее.
В то же время, существенных ограничений по функционалу программа не имеет, и одинаково хорошо выполняет как задачу сканирования, так и распознавания. Фишкой РиДок является возможность уменьшения изображений без потери качества. Единственный существенный недостаток – не совсем корректная работа по распознаванию мелкого текста.
Безусловно, среди перечисленных программ любой пользователь сможет отыскать ту, которая ему придется по душе. Выбор будет зависеть как от конкретных задач, которые приходится чаще всего решать, так и от финансового состояния.
Системы распознавания текста под Linux

OCRFeeder позволяет выбирать предпочтительную систему, управлять ею и просматривать окончательный результат, используя графический интерфейс, понятный любому пользователю.
erid: LjN8KXX2o
ООО «ИТ Медиа»

В наше время обычному пользователю нет необходимости распознавать отсканированные тексты офлайн – все делопроизводство давным-давно ведется в цифре. Однако если такая потребность возникнет, реализовать ее нужно срочно. Желательно вчера. Что делать в таком случае юному линуксоиду? Расскажу одну историю. Помнится, начиналось все чинно-благородно.
Дед Мороз прибывший к нам на праздник прямиком с детского утренника, с выражением читал детские письма, и некоторые чувствительные дамы одобрительно кивали в знак согласия со всеми требованиями малолетних вымогателей. Тем временем Снегурочка развлекала народ конкурсами и одаривала конфетами в награду за участие в них.
Ну а благодарные зрители весело уминали салатики, жевали бутерброды с «настоящей» черной икрой (по 50 рублей за 200 грамм в ближайшем магазинчике) и запивали все это клюквенным морсом. Ничто не предвещало беды. Подозреваю, что основной причиной дальнейших событий стали те самые шоколадные конфеты, подаренные Снегурочкой, – скорее всего, они были просроченные.
Впрочем, многое как в тумане. Помню только, что борода у Деда Мороза была белая и длинная, а потом стала короткая, рыжая и кудрявая и сам он стал похож на эрдельтерьера в красной шапочке. А Снегурочка, начав праздник молоденькой застенчивой блондинкой в кокошнике, ближе к финалу щеголяла с выбритым виском и фиолетовой шевелюрой.
Еще они вместе орали: «Панки, хой!» и вели себя очень неприлично. Мы все решили, что эту парочку попросту подменили. Короче, третьего января я очнулся в постели с дичайшей головной болью и твердой уверенностью, что во всем виноват вирус гриппа, который я мог подхватить от Снегурочки – она на меня дышала как-то подозрительно.
И, когда ртутный градусник показал 35 С°, стало ясно: болезнь берет свое и времени осталось мало, нужно успеть уладить незаконченные дела до того момента, пока моя тушка не остыла совсем и не приняла температуру окружающей среды. Первым делом решил утрясти финансовые вопросы.  «Главному редактору журнала “IT-Expert”. Я, Храмов Евгений, находясь в нетрезвом уме и нетвердой памяти, прошу Вас все невыплаченные мне гонорары перевести в фонд помощи престарелым LOLCODE-программерам.
«Главному редактору журнала “IT-Expert”. Я, Храмов Евгений, находясь в нетрезвом уме и нетвердой памяти, прошу Вас все невыплаченные мне гонорары перевести в фонд помощи престарелым LOLCODE-программерам.
30 сребреников, которые я, если верить слухам, должен был получить за обзоры отечественного ПО и ОС, прошу вложить в дальнейшую разработку российского программного обеспечения (подпись)». После создания сего шедевра эпистолярного жанра встал вопрос: как отправить его адресату?
Классический вариант с почтовым голубем был отклонен по причине банальности, а более прогрессивная пересылка Почтой России – по причине чрезмерных рисков. Усталый мозг наконец выдал единственно верный ответ: отправить e-mail, или, как выразился неведомый мне гений, электропочтой. Конечно же, отправлять простенький скан было не совсем удобно.
Во-первых, кто там будет разбираться в моих бледных каракулях? Во-вторых, всегда есть возможность описки, а это не очень хорошо – все, что было заработано честным и нечестным трудом, пойдет прахом! Про все долгосрочные инвестиции и надежды на многомиллионные доходы можно будет забыть. Следовательно, необходимо продублировать документ в более удобном для чтения формате.
Распознать отсканированный текст и добавить к телу письма показалось неплохой идеей. А зря. …Через пару-тройку часов, проведенных в проверках работоспособности и сравнения характеристик, на первый план вышли два варианта: CuneiForm и Tesseract. Обе разработки предназначены для оптического распознавания текста. История Tesseract началась еще в восьмидесятых годах прошлого столетия.
Разработчики из Hewlett-Packard, наверное, и не ожидали столь долгого жизненного пути своего детища – спустя 40 лет система Tesseract вполне способна распознавать тексты, написанные более чем на сотне языков мира. Благодарить за это нужно руководство компании, которое сделало общедоступными исходники программы в 2005 году, и корпорацию Google, которая с 2006 года поддерживает дальнейшую работу над OCR Tesseract.
В свою очередь OCR CuneiForm не так монументальна – ей «всего-то» около 30 лет. Однако, говоря о OCR-системах, не упомянуть ее невозможно, – это один из первых успешных проектов в постсоветской России. Разработанная маленькой скромной Cognitive Technologies, OCR CuneiForm уже в 1994-м использовалась в сканерах Hewlet-Packard. А в 1995-м Epson заключила контракт о комплектации своих сканеров этой системой.
Да что там говорить, культовый CorelDraw еще в 1993 году включал в себя библиотеку распознавания текста Cognitive. С той поры прошло достаточно времени и уже вряд ли у кого повернется язык назвать создателей CuneiForm «маленькой компанией» – сегодня это лидер в разработке решений для беспилотного управления транспортом и техникой.
В 2008 году исходные тексты CuneiForm были опубликованы под лицензией BSD, что позволяло независимым программистам улучшать и поддерживать ПО в рабочем состоянии. Судя по всему, через несколько лет интересы сообщества изменились, и на сегодняшний день последней датой обновления CuneiForm for Linux указан апрель 2011-го.
Для того чтобы оценить возможности распознавания текста в Tesserasct и CuneiForm, решено было воспользоваться GUI-приложением OCRFeeder. Оно позволяет выбирать предпочтительную систему, управлять ею и просматривать окончательный результат, используя графический интерфейс, понятный любому пользователю.
Для установки в Ubuntu и производных от нее достаточно ввести в терминале несколько команд: sudo apt update, вводим пароль sudo, sudo apt install ocrfeeder. Для тех, у кого темный экран терминала вызывает жгучее неприятие, есть еще более простое решение: запускаем менеджер приложений и в поисковой строке вводим аббревиатуру OCR. Обычно приложение появляется в списке и предлагается к установке.
 Оказалось, что вместе с приложением устанавливается только движок Tesseract, и, как выяснилось далее, для этого есть веские причины. Пока же добавим к нему CuneiForm: Sudo apt install cuneiform
Оказалось, что вместе с приложением устанавливается только движок Tesseract, и, как выяснилось далее, для этого есть веские причины. Пока же добавим к нему CuneiForm: Sudo apt install cuneiform 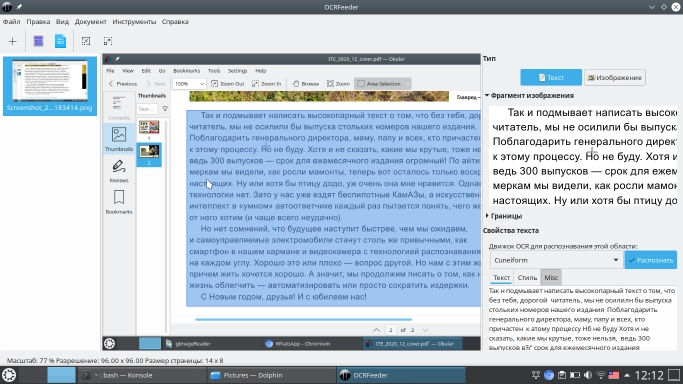 Интерфейс приложения прост до примитивности. В меню «Файл» выбирается необходимая опция и загружается изображение. Мышкой можно выделить область, которую необходимо распознать. Справа от текста находятся меню выбора системы OCR и клавиша «Распознать», запускающая процесс.
Интерфейс приложения прост до примитивности. В меню «Файл» выбирается необходимая опция и загружается изображение. Мышкой можно выделить область, которую необходимо распознать. Справа от текста находятся меню выбора системы OCR и клавиша «Распознать», запускающая процесс.
Идеальное изображение
На следующих фото можно сравнить результаты работы с качественным изображением. Образец для теста, напечатанный кириллицей, выбран с определенной целью. Прежде всего кириллический алфавит наиболее часто использовался и используется в любых документах на территории нашего государства и велика вероятность, что именно его придется распознавать.
Вторая немаловажная причина – локализация. У англоязычных пользователей все может быть замечательно, но это не означает отсутствия проблем у других. 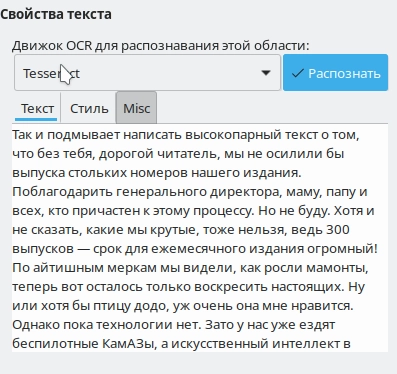
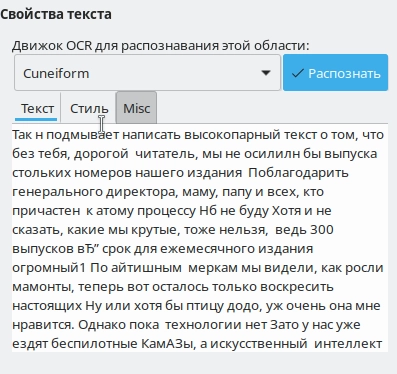 Как видим, при идеальном изображении (без каких-либо артефактов, пыли, грязи и оптических искажений) Tesseract верно распознал 100% текста. С CuneiForm ситуация иная – есть ошибочные символы и неточности, все-таки десять лет без поддержки дают о себе знать. Вполне возможно, за столь долгий срок сменились и сами алгоритмы распознавания текста. В любом случае при использовании качественного изображения у нас получилось распознать весь текст вместе со знаками препинания без каких-либо ошибок.
Как видим, при идеальном изображении (без каких-либо артефактов, пыли, грязи и оптических искажений) Tesseract верно распознал 100% текста. С CuneiForm ситуация иная – есть ошибочные символы и неточности, все-таки десять лет без поддержки дают о себе знать. Вполне возможно, за столь долгий срок сменились и сами алгоритмы распознавания текста. В любом случае при использовании качественного изображения у нас получилось распознать весь текст вместе со знаками препинания без каких-либо ошибок.
Сканы низкого качества
Какой результат мы получим, если исходное изображение будет с низким разрешением, мусором и оптическими искажениями? В качестве примера можно использовать лист из отсканированных вручную СНиПов (строительных норм и правил). 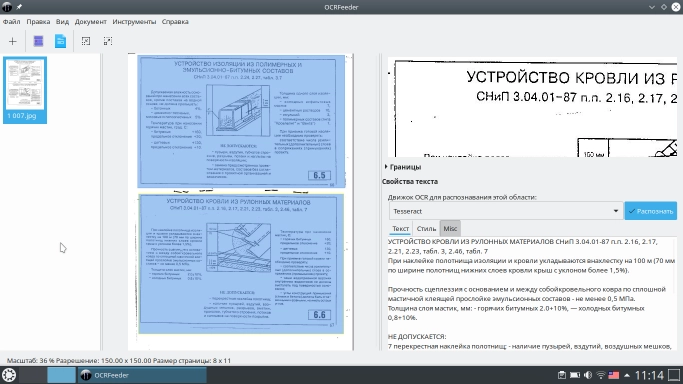
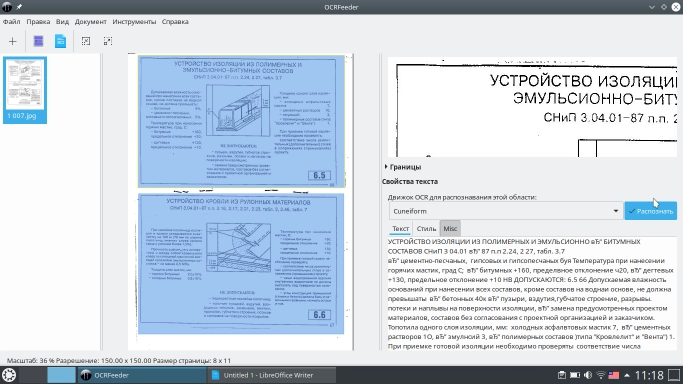 Как видим, Tesseract сработал без ошибок, текст отформатирован, знаки препинания и спецсимволы распознаны верно.
Как видим, Tesseract сработал без ошибок, текст отформатирован, знаки препинания и спецсимволы распознаны верно.
CuneiForm же в распознанном тексте не оставил форматирования – весь текст слипся в один кусок, многие символы подменены другими, а дефис и вовсе заменен на неизвестные кракозябры. Видимо, это и есть основная причина, по которой OCRFeeder по умолчанию устанавливается только с движком Tesseract. Для чего искать что-то еще, если имеется отличный и полностью рабочий вариант? С такими мыслями я и приступил к распознаванию документа, написанного от руки.
Распознавание рукописного текста
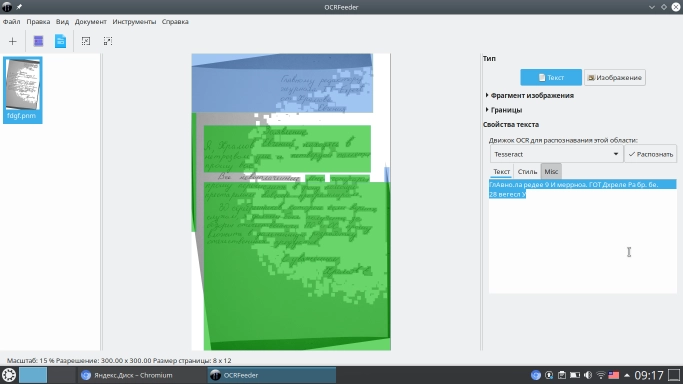
Как ни печально сознавать, но завышенные ожидания наивного юноши не оправдались. Совсем. То, что появилось на мониторе, я и сам-то прочитал с большим трудом. CuneiForm после долгих размышлений вынес лаконичный вердикт всей смысловой нагрузке документа – «ОЮ». Tesseract добавил к этому, видимо, что-то о моей скромной персоне: «ГлАвно.ла редее 9 И меррноа. ГОТ». Ну что же, гот так гот.
Спорить с искусственным интеллектом себе дороже. Поэтому замечательную идею распознавать рукописные тексты в Linux пришлось отложить на неопределенный срок.
Выводы
Итак, на что можно рассчитывать, устанавливая OCRFeeder в Linux? В конечном итоге мы имеем вполне комфортный графический интерфейс, позволяющий любому пользователю загружать, распознавать и импортировать печатные тексты. Свободная лицензия приложения допускает использование его в коммерческих целях без требования каких-либо выплат, подписок и ограничений.
Кроме того, оно позволяет работать офлайн, не требуя выгрузки конфиденциальных данных в Сеть. Такой вариант ПО подойдет как для личного необременительного использования, так и для больших тяжеловесных проектов в офисе. P. S. Процесс установки OCRFeeder можно использовать как средство для нормализации температуры и отвлечения внимания больных простудой и ОРЗ. В моем случае это сработало. Смотреть все статьи по теме «OS Linux (ОС Линукс)»
Опубликовано 01.03.2021
Источник: www.it-world.ru
Распознавание текста онлайн с jpg, pdf и других картинок
Сервис позволяет бесплатно распознать текст онлайн с картинок и pdf файлов. После распознавания можно проверить текст на уникальность и орфографические ошибки. Результаты распознавания доступны по секретной ссылке, которой можно поделиться. Ссылка на результаты OCR хранится 7 дней.
Рекомендации
Для лучшего распознавания используйте картинки с разрешением не менее 300 dpi.
Старайтесь, чтобы строки текста располагались горизонтально, поправьте предварительно картинки в графическом редакторе, если строки слишком завалены.
Желательно обрезать ненужные края, особенно если там есть элементы, похожие на текст.
Оптимальным для распознавания являются картинки, сканированные планшетным сканером.
![]()
![]()
![]() Подпишитесь!
Подпишитесь!
Источник: progaonline.com