
Недостатки Big Data, о которых нельзя забывать
Анализ больших данных — удивительная штука. Но, как и любая другая новая технология, он несовершенен. Рассказываем о рисках, связанных с Big Data.


Alex Drozhzhin
В последние несколько лет везде только и говорят, что о Big Data. Чаще всего в центре внимания оказываются удивительные преимущества, которые может принести использование этой технологии. Однако у всего этого есть и обратная сторона. Мы согласны с тем, что большие данные — это очень многообещающая технология. Но нельзя закрывать глаза на ряд возможных проблем, к которым запросто приведет повсеместное внедрение аналитического ПО.
Многопоточность (С++)

Ничего личного!
Первый недостаток, который обычно приходит в голову критикам больших данных, — это вопрос сохранения собственной конфиденциальности.
Программы для анализа больших данных работают с огромными массивами информации. Чем эти данные уникальнее, а следовательно, «приватнее», тем более интересные выводы может из них сделать алгоритм. Другими словами, личные данные — это та самая «волшебная пыль», на которой работает Магия больших данных. Нередко эта пыль рассыпается и оседает в разных темных углах, тем самым нарушается чья-то конфиденциальность.
Однако важно понимать, что на этом возможные негативные последствия не заканчиваются: есть целый список менее очевидных проблем, тесным и запутанным образом связанных между собой.
Это наука, детка (на самом деле — нет)
Одна из проблем состоит вот в чем: люди считают, что анализ больших данных — это наука. Однако в действительности аналитические алгоритмы куда ближе к инженерному делу, а не к науке, и это вовсе не одно и то же.
Попробуйте сравнить физику и ракеты. Физика — это, без сомнения, наука, в которой каждая гипотеза исследуется и доказывается как теоретически, так и на практике. И после этого выводы обязательно выдаются на суд научного сообщества, просто потому, что наука работает именно так.
Более того, наука всегда открыта — любой желающий может проверить каждый закон и каждую теорему. И стоит кому-то обнаружить весомый изъян в расчетах или выдвинуть новую, более убедительную теорию, как она тут же становится частью активного обсуждения, в которое вовлекаются все мэтры научного мира.
Ракеты же — это всего лишь инженерно-технические сооружения, созданные на базе определенных физических знаний. И, как вы наверняка знаете, если дизайн ракеты несовершенен, это может с легкостью привести к неприятностям, что регулярно и происходит.
Гамма-функция и бета-функция: вывод основных соотношений
С математикой не поспоришь. Правда ведь?
Из предыдущего пункта есть одно важное следствие: ложное чувство непогрешимости выводов компьютера. Вы же не можете спорить с «математически обоснованным» выводом, не так ли?
Не зная математику, использованную в алгоритме, невозможно оспорить справедливость сделанных расчетов. В теории провести независимую оценку могли бы профессиональные математики — если бы им дали доступ. Но могут ли они это сделать в действительности? Зачастую нет.
Черный ящик такой черный
Даже если у вас есть знания, опыт и время, которое вы готовы потратить на проверку того, как работает тот или иной алгоритм, вам вряд ли дадут это сделать. В большинстве случаев технологии анализа больших данных — это коммерческая тайна. Их исходный код закрыт.
В своем выступлении «Оружие математического поражения» математик и борец за права человека Кэти О’Нейл рассказала о том, как она пыталась исследовать методику оценки эффективности преподавателей на основе Big Data, которую применяют в США.
«Моя подруга, которая владеет средней школой в Нью-Йорке, решила изучить этот алгоритм. Это специализированная школа с углубленным изучением естественных наук и математики, потому она была уверена, что разберется с алгоритмом. Она запросила данные в министерстве образования — и знаете, что они сказали? «Ой, да вы ничего не поймете, это же математика!»
«Она настаивала и наконец получила брошюру, а после показала ее мне. Документ оказался слишком абстрактным для того, чтобы прояснить ситуацию. Так что я отправила запрос, опираясь на закон США о свободном доступе к информации, но получила отказ. Позднее я узнала, что научно-исследовательский центр в Мэдисоне, штат Висконсин, который разрабатывает эту аналитическую модель, заключил контракт, согласно условиям которого ни у кого нет права заглянуть внутрь алгоритма».
«Никто в министерстве образования Нью-Йорка не понимает, как работает эта модель. Учителя не знают, на каком основании им ставят те или иные оценки и что нужно сделать, чтобы их повысить, — им никто ничего не может и не хочет объяснить».
Что-то попадает внутрь, что-то другое — наружу
Поскольку механизм работы алгоритма непрозрачен, неясно и то, какие именно данные обрабатываются, а какие — остаются за бортом. Причем непонятно это не только нам с вами, но и оператору, который работает с программой и действует в соответствии с тем, какие она делает выводы.
Поэтому одни и те же данные могут повлиять на суждения человека дважды: когда они попадают в программу и когда оператор принимает решение. Кроме того, какая-то информация может никак не повлиять на результат, если оператор подумал, что она уже была использована в анализе, а алгоритм на самом деле этого не сделал.
К примеру, представьте, что полицейский попадает в криминальный район. Алгоритм предупреждает его, что человек перед ним с вероятностью 55% взломщик. В руках у этого человека подозрительный чемодан. Но учла ли программа при анализе этот факт? Возникает вопрос: делает ли наличие чемодана этого человека более подозрительным или нет?
Следует также учесть еще то, что в исходных данных может содержаться ошибка или вообще отсутствовать информация, критически важная для принятия правильного решения.
Стакан наполовину пуст или наполовину полон?
Выводы программы также не являются полностью прозрачными и могут быть неверно интерпретированы. Одни и те же цифры разные люди поймут по-разному. К примеру, вероятность в 30% — это много или мало? Ответ зависит от множества разных факторов, о которых мы можем даже и не подозревать.
Что еще хуже, этот процент вероятности может использоваться в конкурентной борьбе. К примеру, даже невысокая вероятность того, что тот или иной человек способен совершить преступление, конечно, не отправит его в тюрьму, но вполне может закрыть ему карьеру в некоторых учреждениях.
Похожие алгоритмы используют в госслужбах США, чтобы узнать, с какой вероятностью соискатель может допустить утечку. Так как за место борются множество людей, никого не обеспокоит тот факт, что некоторым кандидатам откажут просто потому, что для них эта вероятность оказалась чуть-чуть выше среднего.
Без предубеждений?
Все сказанное выше позволяет смело говорить, что одно из самых разрекламированных преимуществ больших данных — беспристрастность — на самом деле не работает. Решение, принятое человеком на базе расчетов, выполненных созданным людьми алгоритмом, все равно остается решением человека.
На него могли влиять те или иные предубеждения, а могли и не влиять. Проблема в том, что секретный алгоритм и непонятно какие вводные данные не позволяют вам точно сказать, было ли решение беспристрастным. И изменить ничего нельзя, ведь порядок жестко прописан в программном коде.
Недостатки больших данных, о которых нельзя забывать #BigData
Tweet
Добро пожаловать на темную сторону, Энакин
Еще один недостаток алгоритмов прогнозирования — это самосбывающиеся пророчества. К примеру, полиция Чикаго использует алгоритм, который определяет потенциально опасных подростков.
Полицейские решают за таким подростком «присматривать», навещают его дома и оказывают всякие другие «знаки внимания» со всей присущей им любезностью. Подросток понимает, что полиция уже относится к нему как к преступнику, хотя он ничего такого не делал, и начинает вести себя в соответствии с ожиданиями. В результате он действительно становится членом банды.
Конечно, проблема тут в большей степени в некорректном поведении сотрудников полиции. Но не будем забывать о том, что это алгоритмы дают им «научные основания» для подобных действий.
Или, как отметила Уитни Меррилл в своем докладе «Прогнозирование преступлений в мире больших данных», который прозвучал на Chaos Communication Congress 32: «Полицейский отправляется патрулировать, и алгоритм ему подсказывает, что в этом районе он с вероятностью 70% встретит взломщика. Найдет ли он взломщика только потому, что ему сказали: «Ты найдешь взломщика»?»
Не хотите участвовать? Не получится
Если какая-либо правительственная или коммерческая организация внедряет аналитическое ПО и вам это не нравится, вы не сможете просто сказать: «Мне надоело, я выхожу из игры». Никто не станет вас спрашивать, согласны ли вы стать частью такого исследования или нет. Более того, вам вообще вряд ли расскажут, что вы в нем участвуете.
Поймите меня правильно: я не говорю, что все эти недостатки должны заставить нас отказаться от продвинутых аналитических алгоритмов. Технологии Big Data сейчас в самом начале пути — они точно никуда не денутся и останутся с нами надолго. Тем не менее сейчас самое время обдумать все эти проблемы, пока не стало слишком поздно.
Нам нужны хорошо защищенные алгоритмы с прозрачными механизмами обработки данных. Необходимо допускать независимых исследователей к исходному коду, правительствам следует создать соответствующие законы. Также не помешает рассказывать людям, какие такие «математические штуки» за ними присматривают. И всем участникам процесса, конечно же, следует учиться на уже сделанных ошибках.
Источник: www.kaspersky.ru
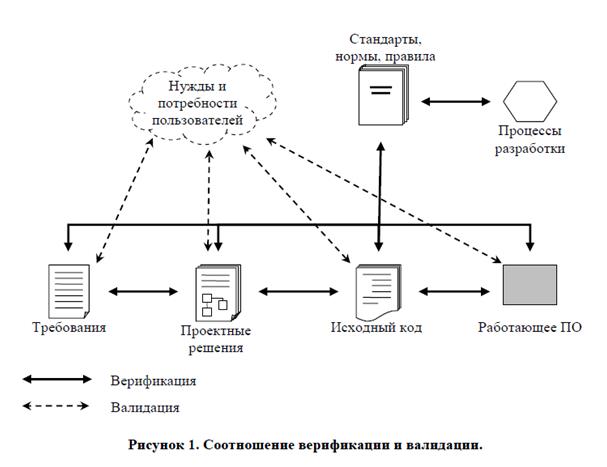
Верификация – это ответ на вопрос «Выполнено ли программное обеспечение правильно?», а валидация – «Сделано ли правильное программное обеспечение?».

При поиске ответа на поставленные вопросы можно обнаружить, что валидация (или аттестация) по содержанию имеет значение несколько шире, чем проверка (верификация). Однако верификация достаточно тесно связана с обеспечением контроля качества программного продукта.
Например, верификация компьютерной программы предусматривает процесс, в котором за основу ставится цель по обеспечению удовлетворения требований данных, полученных в определенном жизненном цикле продукта, тем, которые были получены на предыдущей стадии.
Если же вести речь о верификации модели, то здесь речь пойдет о проверке правильности отображения данной вычислительной модели необходимой концептуальной либо математической моделям. При верификации системного кода проводится анализ кодировки источника и проверка соответствия его документальному описанию. В процессе верификации могут включаться операции, содержащие альтернативные расчеты. Проводится сравнение технической и научной документаций нового проекта с соответствующей документацией уже существующего проекта, обязательное тестирование, апробация нового программного продукта и демонстрация результатов.
1. Каково назначение этапа тестирования в жизненном цикле разработки программного продукта?
2. Что подвергается тестированию?
3. Какие существуют принципы тестирования?
4. Перечислите аксиомы тестирования.
5. Перечислите виды тестирования. Каково их назначение?
6. Какие стратегии тестирования вы знаете?
7. В чем суть метода «черного ящика»?
8. Какова цель тестирования документации?
9. Что является программной ошибкой?
10. Какие существуют категории программных ошибок?
11. Какими характеристиками должен обладать хороший тест?
12. Охарактеризуйте понятие «верификация».
13. Охарактеризуйте понятие «валидация».
НАДЕЖНОСТЬ ПРОГРАММНЫХ ПРОДУКТОВ
При определении надежности ПП пользуются следующими принятыми терминами.
Надежность — состояние, позволяющее избежать повреждений в момент совершения ошибки. Ошибки ПП происходят в силу дефектов или ошибок проекта, кодирования, организационных ошибок, неадекватной отладки и ошибок тестирования.
Ошибка классифицируется как проблема, обнаруженная на этапе ее зарождения.
Дефектом называется проблема, которая была обнаружена не на этапе ее появления, а лишь на некотором более позднем этапе жизненного цикла разработки.
Отказоустойчивость ПП — свойство ПП, заключающееся в возможности коррекции отдельных ошибок при сохранении возможности продолжения выполнения программы.
Проблема — отклонение от заданных технических характеристик или ожидаемых результатов.
Ошибка при обработке — вывод некорректных результатов при выполнении процесса обработки.
Процесс — ограниченный ряд взаимосвязанных действий, в ходе осуществления которых используются один или больше типов исходных продуктов, а затем с помощью одного или нескольких преобразований создается конечный продукт, который представляет ценность для заказчика.
Отказ при выполнении процесса — событие, посредством которого ошибка в исходном продукте, используемом в процессе, порождает ошибку на выходе, которая в конечном итоге становится явной.
Сбой при выполнении процесса — сбой, имеющий отношение к используемым в процессе некорректным входным данным и вызывающий неправильное состояние процессе или системы, к которой относится процесс.
Устойчивость — это свойство объекта существовать во времени (независимо от процесса, породившего данный объект) и (или) в пространстве (при перемещении объекта из адресного пространства, в котором он был создан).
Основные источники ошибок
Ошибки могут возникнуть на любом из этапов разработки программного продукта. В целом процесс разработки программного продукта является процессом реализации некоторой модели, описывающей реальную задачу. Ниже перечислены основные причины возникновения ошибок на разных этапах.
При определении требований пользователь может неадекватно выразить свои требования, они могут быть неверно поняты или реализованы не в полном объеме. Ошибки этого этапа – наиболее дорогостоящие.
На этапе анализа возможны ошибки при определении целей продукта, которые вытекают из требований к нему; требования могут быть неверно интерпретированы; принятые решения могут оказаться неверными, а также могут быть не сформулированы цели необходимые, но не выраженные явно в требованиях. Кроме того, классы, отражающие концепции реальной предметной области, могут быть смоделированы неадекватно.
На этапе проектирования цели программы преобразуются в ее внешние спецификации, т.е. точное описание поведения всей системы с точки зрения пользователя. По объему перевода это самый значительный этап разработки программного обеспечения. Так что он большего всего подвержен ошибкам ¾ они бывают и наиболее серьезными, и наиболее многочисленными. На этой стадии разработки ошибки могут быть допущены при разработке модели данных: неверно определены объекты, их свойства или связи между ними. Для информационных систем очень серьезными могут оказаться ошибки, допущенные при нормализации.
При проектировании модели представления осуществляется несколько процессов перевода ¾ от внешнего описания готового продукта до получения детального проекта, описывающего множество составляющих программу предложений, выполнение которых должно обеспечить поведение системы, соответствующее внешним спецификациям. Этот шаг включает такие процессы, как создание модели представления данных и перевод внешнего описания в структуру компонент программы (модель управления данными). Здесь могут быть допущены ошибки, связанные во — первых, с неточным или неполным отображением данных, во-вторых, с неприемлемым или неудобным для пользователя интерфейсом, в-третьих, неправильно спроектированной архитектурой комплекса.
Следующая стадия проектирования ¾ разработка внутренней структуры классов и алгоритмов отдельных модулей. Поскольку приходится иметь дело со все большими объемами информации, шансы внесения ошибок становятся чрезвычайно высокими.
Последний процесс проектирования ¾ перевод описания логики программы в предложения языка программирования. Хотя на этом шаге часто делается много ошибок, они, как правило, относительно мелкие, легко обнаруживаются и корректируются, однако это не всегда так.
В результате работы над программным проектом создаются документы, описывающие его использование. Если в этих документах будут допущены ошибки, то они также снижают надежность программы. Такого рода ошибки связаны с неточным описанием поведения программы и, соответственно, неправильной реакцией пользователя. Кроме того, если документация написана так, что пользователь не может понять, как выполнить ту или другую функцию, он может начать экспериментировать с системой, что приведет к непредсказуемым результатам.
Еще одним источником ошибок является неправильное истолкование спецификаций аппаратуры или документации по базовому программному обеспечению.
Непонимание синтаксиса и семантики языка программирования также является причиной ошибок.
Если пользовательский интерфейс разработан без учета психологии пользователя, то увеличивается вероятность ошибок пользователя, которые ставят систему в непредвиденные обстоятельства, тем самым, повышая шансы проявления оставшихся в программном обеспечении ошибок.
При устранении ошибки или изменении программы в связи с увеличением ее функциональности, возникает вопрос чтения и понимания текста программы. Если текст не прокомментирован, использованы слишком сложные алгоритмы и т. д., то могут возникнуть ошибки, связанные с неправильным пониманием текста программы.
Психологические факторы программной системы ¾ это степень легкости ее понимания и удобства использования, защищенности от неправильного употребления и, как результат, частоты ошибок пользователя. Несмотря на то, что удобный пользовательский интерфейс увеличивает сложность программы, он повышает ее надежность за счет того, что учет психологических факторов позволяет свести к минимуму возможность непредусмотренных действий пользователя. Основными моментами, обеспечивающими удобство работы пользователя с программным продуктом, являются следующие:
1) Цветовое решение пользовательского интерфейса. Во-первых, оно должно быть единообразным для всех компонентов системы, т. е. элементы интерфейса, несущие однотипную смысловую нагрузку (например, текст подсказки или аварийные сообщения), должны быть оформлены одинаково. Во-вторых, цвета и размер шрифта должны быть подобраны так, чтобы они не утомляли пользователя.
2) Содержание сообщений. Пользовательский интерфейс должен содержать подсказки на экране, поясняющие смысл элементов управления; сообщения, которые объясняют пользователю его ошибки; аварийные сообщения при сбоях программного или аппаратного обеспечения. Текст этих сообщений должен быть кратким, но максимально содержательным. Желательно также организовать работу справки (в т. ч. контекстной), которая описывает возможности системы и способы их реализации.
3) Полнота документации. Программный продукт должен сопровождаться комплектом документации, в которой подробно описано назначение системы, ее функции, средства их выполнения, соответствие входных и выходных данных, необходимая программная и аппаратная конфигурация. Все сообщения, которые выдает программа, должны быть пояснены. Должна быть указана реакция программы на аварийные ситуации (программные и аппаратные сбои) и на ошибочные действия пользователя. Документация должна быть написана кратко, четким и понятным языком.
Сложность является одной из главных причин ненадежности программного обеспечения. В общем случае сложность объекта является функцией взаимодействия между его компонентами. Например, сложность проекта программной системы в некоторой степени определяется связями между командами пользователя и соотношениями между входной и выходной информацией системы. Сложность архитектуры системы определяется связями между подсистемами, сложность подсистемы ¾ функция связей между модулями, сложность модуля ¾ функция связи между его командами.
Существует три основных принципа, позволяющих минимизировать сложность системы:
1) Максимальная независимость компонент системы. Наиболее полно эта концепция реализована в объектно-ориентированных языках. Определение объекта как экземпляра класса позволяет рассматривать его как замкнутый объект, обладающий заданными свойствами и позволяющий применять определенные методы. Тем самым система рассматривается как набор компонент, доступ к внутренней структуре которых невозможен.
2) Иерархическая структура. Иерархия позволяет распределить систему по уровням понимания. Каждый уровень представляет собой совокупность структурных отношений между элементами нижних уровней. Концепция уровня позволяет понять систему, скрывая несущественные уровни детализации. В частности, определение класса позволяет работать с его экземплярами, не уточняя их внутренней структуры.
3) Проявление связей всюду, где они возникают. Основная проблема многих программных систем ¾ огромное количество независимых побочных эффектов, создаваемых компонентами системы. Кроме того, если в системе существуют скрытые связи, т. е. один компонент неявно зависит от другого, то при внесении изменений невозможно отследить, каким образом они повлияют на систему в целом.
К защитному программированию относятся функции программного обеспечения, которые предназначены для выявления и исправления ошибок или их последствий. Устойчивость к ошибкам ¾ это мера способности системы продолжать функционировать при наличии ошибок. Устойчивость к ошибкам является одним из основных факторов, обеспечивающих надежность системы. Методы защитного программирования предназначены для того, чтобы выявить ошибки пользователя, аппаратные и программные сбои и обеспечить адекватную реакцию программы. Основными принципами поиска ошибок являются:
1) Взаимное недоверие. Когда модуль получает данные от другого модуля или из источника вне системы (клавиатура, файл и т. д.), он должен пытаться найти в них ошибки.
2) Немедленное обнаружение. Ошибки необходимо обнаруживать как можно раньше.
3) Избыточность. Все средства обнаружения ошибок основаны на некоторой форме избыточности, явной или неявной.
Действия, предпринимаемые при обнаружении ошибок, должны быть единообразными для всех компонент системы. Возможными решениями являются: выдать сообщение и повторить попытку, если ошибка связана с вводом данных, завершить выполнения программы, регистрировать ошибки в отдельном файле.
Защитное программирование основано на предпосылке: худшее, что может сделать модуль ¾ это принять неправильные входные данные и затем вернуть неверный, но правдоподобный результат. Чтобы избежать этого, в начале каждого модуля следует помещать проверки входных данных на соответствие их свойств атрибутам и диапазонам измерения, на полноту и осмысленность. При выборе надлежащих проверок важно по тексту программы модуля выявить все предположения, которые в нем сделаны относительно входных данных, а затем рассмотреть возможность проверки входных данных на соответствие этим предположениям при каждом вызове модуля.
«Подводным камнем» защитного программирования является то, что программа усложняется, увеличивается время работы и требуемый объем памяти. Поэтому важно принять компромиссное решение по определению того минимума защитной части программы, который обеспечивает максимально возможный уровень обнаружения ошибок.
При разработке информационных систем для повышения надежности рекомендуется максимально использовать возможности работы в интерактивном режиме (создание таблиц, форм, элементов управления, отчетов, запросов), а также по возможности организовать ввод данных на основе списков.
В процессе разработки программного обеспечения заранее планируются возможности внесения изменений в проект. Спиральная модель разработки предполагает увеличение функциональной полноты продукта для каждой последующей версии, поэтому необходимо заранее планировать внесение изменений. Такое планирование нужно еще и потому, что при обнаружении ошибок также вносятся изменения в программу. Есть несколько основных правил работы с изменениями:
1) в течение всего цикла работы над проектом поддерживать документацию на уровне последних решений.
2) в определенный момент результаты каждого этапа «замораживаются», т. е. любые изменения должны проходить формальную процедуру утверждения, поскольку на принятом ранее решении основаны и другие решения. Таким образом, процедура внесения изменений принимает каскадный характер.
3) внесение изменений часто ведет к появлению новых ошибок, особенно когда сроки разработки истекают и возникает стрессовая ситуация, поэтому правильность всякого изменения надо проверять в той же степени, что и правильность исходного решения.
4) следует убедиться, что нужные изменения сделаны на всех уровнях. В частности, программист, планирующий внутреннюю логику, может сделать изменения, которые приведут к изменению внешних спецификаций. Рассогласование программного обеспечения и спецификаций означает ошибку в программном продукте.
1. Дайте определение понятия «надежность программного продукта».
2. Перечислите основные источники ошибок.
3. Какие психологические факторы влияют на надежность?
4. В чем суть защитного программирования?
5. Почему сложность программного продукта влияет на его надежность?
6. Почему необходимо заранее планировать возможность изменения программного продукта?
Источник: megaobuchalka.ru