
Из этого руководства вы узнаете о базовых встроенных типах данных Python: числовых, строковых и логических (булевых).
Целые числа
В Python 3 фактически нет предела длины целочисленного значения. Конечно, оно ограничено объемом доступной в системе памяти (как и любые другие типы данных), но в остальном — может быть таким длинным, как нужно:
>>> print(123123123123123123123123123123123123123123123123 + 1) 123123123123123123123123123123123123123123123124
Python интерпретирует последовательность десятичных цифр без префикса как десятичное число:
>>> print(10) 10
Следующие строки могут быть добавлены к значению числа, чтобы обозначить основание отличное от 10:
| 0b (ноль + «b» в нижнем регистре) 0B (ноль + «b» в верхнем регистре) |
Двоичное | 2 |
| 0o (ноль + «o» в нижнем регистре) 0O (ноль + «O» в верхнем регистре) |
Восьмеричное | 8 |
| 0x (ноль + «x» в нижнем регистре) 0X (ноль + «X» в верхнем регистре) |
Шестнадцатеричное | 16 |
Уроки Python — Типы данных, переменные
>>> print(0o10) 8 >>> print(0x10) 16 >>> print(0b10) 2
Чтобы больше узнать о значениях целых чисел с основанием не равным 10, обратитесь к следующим статьям в Википедии: двоичная, восьмеричная, шестнадцатеричная.
Базовый тип целого числа в Python, вне зависимости от используемого основания, называется int :
>>> type(10) class ‘int’> >>> type(0o10) class ‘int’> >>> type(0x10) class ‘int’>
Примечание: отличный момент, чтобы напомнить, что функцию print() не нужно использовать при работе в командной строке. Просто вводите значения после >>> и нажимайте Enter для отображения:
>>> 10 10 >>> 0x10 16 >>> 0b10 2
Многие примеры будут использовать эту особенность интерпретатора.
Но это не работает с файлами скриптов. Значение в строке файла со скриптом не делает ничего само по себе.
Числа с плавающей точкой
Тип float в Python означает число с плавающей точкой. Значения float определяются с десятичной точкой. По желанию можно добавить символ e или E после целого числа, чтобы обозначить, что это экспоненциальная запись.
>>> 4.2 4.2 >>> type(4.2) class ‘float’> >>> 4. 4.0 >>> .2 0.2 >>> .4e7 4000000.0 >>> type(.4e7) class ‘float’> >>> 4.2e-4 0.00042
Подробнее: представление float
Далее следует более подробная информация о том, как Python изнутри представляет числа с плавающей точкой. Вы без проблем можете пользоваться этим типом данных, не понимая этот уровень, так что не волнуйтесь, если описанное здесь покажется чересчур сложным. Информация представлена для особо любопытных.
Почти все платформы представляют числа с плавающей точкой Python как 64-битные значения двойной точности в соответствии со стандартом IEEE 754. В таком случае максимальное значение числа с плавающей точкой — это приблизительно 1.8 х 10308. Числа больше Python будет помечать в виде строки inf :
>>> 1.79e308 1.79e+308 >>> 1.8e308 inf
Ближайшее к нулю ненулевое значение — это приблизительно 5.0*10**-342 . Все что ближе — это уже фактически ноль:
>>> 5e-324 5e-324 >>> 1e-325 0.0
Числа с плавающей точкой представлены в виде двоичных (с основанием 2) фракций. Большая часть десятичных фракций не может быть представлена в виде двоичных, поэтому в большинстве случаев внутреннее представление — это приближенное к реальному значение. На практике отличия представленного и реального значения настолько малы, что это не должно создавать проблем.
Дальнейшее чтение: для получения дополнительной информации о числах с плавающей точкой в Python и возможных проблемах, связанных с этим типом данных, читайте официальную документацию Python.
Комплексные числа
Сложные числа определяются следующим образом: + j . Например:
>>> 2+3j (2+3j) >>> type(2+3j) class ‘complex’>
Строки
Строки — это последовательности символов. Строковый тип данных в Python называется str .
Строковые литералы могут выделяться одинарными или двойными кавычками. Все символы между открывающей и закрывающей кавычкой являются частью строки:
>>> print(«Я строка.») Я строка. >>> type(«Я строка.») class ‘str’> >>> print(‘Я тоже.’) Я тоже. >>> type(‘Я тоже.’) class ‘str’>
Строка может включать сколько угодно символов. Единственное ограничение — ресурсы памяти устройства. Строка может быть и пустой.
А что, если нужно использовать символ кавычки в строке? Первой идеей может быть нечто подобное:
Но, как видите, такой подход не работает. Строка в этом примере открывается одинарной кавычкой, поэтому Python предполагает, что следующая закрывает ее, хотя она задумывалась как часть строки. Закрывающая кавычка в конце вносит неразбериху и приводит к синтаксической ошибке.
Если нужно включить кавычки одного типа в строку, то стоит выделить ее целиком кавычками другого типа. Если строка содержит одинарную кавычку, просто используйте в начале и конце двойные или наоборот:
>>> print(‘Эта строка содержит одну кавычку (‘).’) SyntaxError: invalid syntax
Как видите, это не так хорошо работает. Строка в этом примере открывается одиночной кавычкой, поэтому Python предполагает, что следующая одинарная кавычка, та, которая в скобках является закрывающим разделителем. Окончательная одинарная кавычка тогда лишняя и вызывает показанную синтаксическую ошибку.
Если вы хотите включить любой тип символа кавычки в строку, самый простой способ — разделить строку с другим типом. Если строка должна содержать одну кавычку, разделите ее двойными кавычками и наоборот:
>>> print(«Эта строка содержит одну кавычку (‘).») Эта строка содержит одну кавычку (‘). >>> print(‘Эта строка содержит одну кавычку («).’) Эта строка содержит одну кавычку («).
Управляющие последовательности (исключенные последовательности)
Иногда нужно, чтобы Python по-другому интерпретирован символ или последовательность нескольких символов в строке. Этого можно добиться двумя способами:
- Можно «подавить» специальное значение конкретных символов в этой строке;
- Можно создать специальную интерпретацию для символов в строке, которые обычно воспринимаются буквально;
Для этого используется обратный слэш ( ). Обратный слэш в строке указывает, что один или несколько последующих символов нужно интерпретировать особым образом. (Это называется исключенной последовательностью, потому что обратный слэш заставляет последовательность символов «исключаться» из своего привычного значения).
Посмотрим, как это работает.
Подавление значения специальных символов
Вы видели, к каким проблемам приводит использовать кавычек в строке. Если она определена одиночными кавычками, просто так взять и использовать такую же кавычку как часть текста, нельзя, потому что она имеет особенное значение — завершает строку:
>>> print(‘Эта строка содержит одну кавычку (‘).’) SyntaxError: invalid syntax
Обратный слэш перед одинарной кавычкой «освобождает» ее от специального значения и заставляет Python воспринимать буквальное значение:
>>> print(‘Эта строка содержит символ одинарной кавычки (‘).’) Эта строка содержит символ одинарной кавычки (‘).
То же работает и со строками, определенными двойными кавычками:
>>> print(«Эта строка содержит символ одинарной кавычки («).») Эта строка содержит символ одинарной кавычки («).
Следующая таблица управляющих последовательностей описывает символы, которые заставляют Python воспринимать отдельные символы буквально:
| ’ | Завершает строку, открытую одинарной кавычкой | Символ одинарной кавычки |
| » | Завершает строку, открытую двойными кавычками | Символ двойных кавычек |
| newline | Завершает строку ввода | Новая строка игнорируется |
| \ | Показывает исключенную последовательность | Символ обратного слэша |
Обычно символ новой строки ( newline ) заменяет enter. Поэтому он в середине строки заставит Python думать, что она неполная:
>>> print(‘a SyntaxError: EOL while scanning string literal
Чтобы разбить строку на несколько строк кода, добавьте обратный слэш перед переходом на новую строку и newline будет игнорироваться:
>>> print(‘a b c’) abc
Для включения буквального значения обратного слэша, исключите его с помощью еще одного:
>>> print(‘foo\bar’) foobar
Добавление специального значения символам
Предположим, что необходимо создать строку, которая будет содержать символ табуляции. Некоторые текстовые редакторы вставляют его прямо в код. Но многие программисты считают, что это не правильный подход по нескольким причинам:
- Компьютер видит разницу между символом табуляции и последовательностью пробелов, но программист — нет. Человек, читающий код, не способен отличить пробелы от символа табуляции.
- Некоторые текстовые редакторы настроены так, чтобы автоматически удалять символы табуляции и заменять их на соответствующее количество пробелов.
- Некоторые REPL-среды Python не будут вставлять символы табуляции в код.
В Python (и большинстве других распространенных языков) символ табуляции определяется управляющей последовательностью t :
>>> print(‘footbar’) foo bar
Она заставляет символ t терять свое привычное значение и интерпретируется как символ табуляции.
Вот список экранированных последовательностей, которые заставляют Python использовать специальное значение вместе буквальной интерпретации:
| a | ASCII: символ Bell (BEL) |
| b | ASCII: символ возврата на одну позицию (BS) |
| f | ASCII: символ разрыва страница (FF) |
| n | ASCII: символ перевода строки (LF) |
| N | Символ из базы Unicode с именем |
| r | ASCII: символ возврата каретки (CR) |
| t | ASCII: символ горизонтальной табуляции (TAB) |
| uxxxx | Символ Unicode с 16-битным шестнадцатеричным значением |
| Uxxxxxxxx | Символ Unicode с 32-битным шестнадцатеричным значением |
| v | ASCII: символ вертикальной табуляции (VT) |
| ooo | Символ с восьмеричным значением ooo |
| xhh | Символ с шестнадцатеричными значением hh |
>>> print(«atb») a b >>> print(«a141x61») aaa >>> print(«anb») a b >>> print(‘u2192 N’) → →
Такой тип исключенной последовательности обычно используется для вставки символов, которые не легко ввести с клавиатуры или вывести.
«Сырые» строки
Литералу «сырой» строки предшествует r или R , которая подавляет экранирование, так что обратный слэш выводится как есть:
>>> print(‘foonbar’) foo bar >>> print(r’foonbar’) foonbar >>> print(‘foo\bar’) foobar >>> print(R’foo\bar’) foo\bar
Строки в тройных кавычка
Есть и другой способ объявления строк в Python. Строки в тройных кавычках определяют группами из трех одинарных или двойных кавычек. Исключенные последовательности в них все еще работают, но одинарные и двойные кавычки, а также новые строки могут использоваться без управляющих символов. Это удобный способ создавать строки, включающие символы одинарных и двойных кавычек:
>>> print(»’Эта строка содержит одинарные (‘) и двойные («) кавычки.»’) Эта строка содержит одинарные (‘) и двойные («) кавычки.
Таким же образом удобно создавать строки, разбитые на несколько строк кода:
>>> print(«»»Это cтрока, которая растянута на несколько строк»»») Это cтрока, которая растянута на несколько строк
Наконец, этот способ используется для создания комментариев кода Python.
Булев тип, Булев контекст и «истинность»
В Python 3 три типа Булевых данных. Объекты булевого типа принимают одно из двух значений, True или False :
>>> type(True) class ‘bool’> >>> type(False) class ‘bool’>
Многие выражения в Python оцениваются в булевом контексте. Это значит, что они интерпретируются как истинные или ложные.
«Истинность» объекта типа Boolean самоочевидна: объекты равные True являются истинными, а те, что равны False — ложными. Но не-Булевы объекты также могут быть оценены в Булевом контексте.
Источник: pythonru.com
3 основных типа данных в Python, с которыми начнем работать сразу: int, float, str (Урок №6)
В уроке №4 я рассказывал про переменные и кратко упомянул, что существует такое понятие, как «тип данных».
Сегодня мы кратко рассмотрим три основных типа данных, с которыми сразу же сталкиваются начинающие программисты. Подчеркну, что в Python типов данных, разумеется, больше.
Чтобы не запутать начинающих, мы рассмотрим три главных типа, с которыми и будем работать с первых же дней. А с другими типами данных, будем знакомиться, как говорится, по ходу пьесы =)
Но прежде чем продолжить далее, отмечу, что можете посмотреть видео (в нем больше информации, по понятным причинам), или прочитать текстовую версию чуть ниже.
Не забудьте подписаться на мой Видеоканал в Яндекс.Дзен.
Так вот. Когда мы разбирались с понятием переменных в Python, то нетрудно заметить, что переменная может принимать разные значения. Это может быть текст, целые числа, числа с плавающей точкой (например, 4.56).
x = 8 # переменной присвоено целое число y = 45.78 # переменной присвоено число с плавающей точкой (число с дробной частью) my_name = «dmitry» # переменной присвоено строковое значение
Давайте кратко разберемся с этим вопросом.
1. Целые числа — int
Предположим, мы задали переменную
a = 5
Нетрудно догадаться, что число 5 является целым (без дробной части).
Такой тип данных (целые числа) в Python относится к типу данных int (integer).
Интересно, что целое число в Python может быть сколь угодно большим. Единственное ограничение — это объем оперативной памяти компьютера (разрядность).
2. Числа с плавающей точкой — float
Зададим другую переменную:
b = 5.678
Это число уже не является целым и содержит дробную часть после точки.
Такой тип данных относится к типу данных float.
Тонкий момент
Обратите внимание на один нюанс:
- 42 — целое число (integer)
- 42.0 — не является целым числом, так как Python воспримет это число как тип float
Хотя, с точки зрения обычного человека обе записи обозначают целые числа.
3. Строковые данные — str
Этот тип данных используется для хранения в оперативной памяти строковых данных.
my_site = «it-robionek.ru» first_name = «Дмитрий»
Стоит отметить, что Python является языком с динамической типизацией.
И Python самостоятельно определяет тип данных переменной исходя из того, какое значение было присвоено переменной.
Если переменной Z присвоить значение 56, то Python автоматически определит, что переменная имеет тип данных int.
Но если далее м присвоим переменной z значение «город», то тип переменной z изменится на str
z = 67 # присваиваем переменной иное значение z = «город» # проверяем тип переменной при помощи функции type print(type(z))
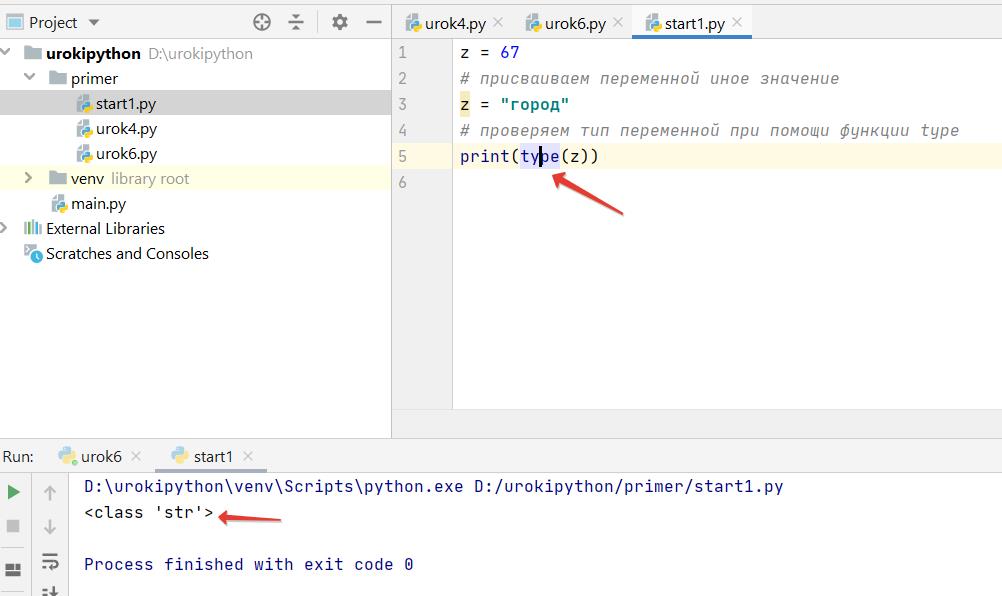
Как узнать тип переменной, которая используется в программе?
Для этого можно использовать функцию type()
Вместо итога
В первую очередь именно с этими тремя типами данных мы столкнемся при дальнейшем изучении материала. Но подчеркну, что в Python существует больше типов данных, с которыми мы познакомимся далее, когда будем рассматривать конкретные примеры.
А в следующем уроке мы напишем первую простую программу, в которой используем все три типа данных, которые рассмотрели выше и рассмотрим некоторые особенности по работе с ними.
Уроки по Python 3:
- Урок №1. Стоит ли изучать Python? Почему он стал лучшим «первым» языком программирования для начинающих?
- Урок №2: Как установить Python 3 в Windows и проверка установки в Linux
- Урок №3: PyCharm: пошаговая инструкция по установке IDE для изучения Python
- Урок №4: Переменные в Python: что это такое, как их называть и использовать?
- Урок №5: Комментирование кода в Python
- Урок №6: 3 основных типа данных в Python, с которыми начнем работать сразу: int, float, str
- Урок №7: Числа и операции с ними в Python
- Урок №8: Ввод и вывод данных в Python. Пишем первую программу
Источник: it-robionek.ru
Типы данных Python

Основы
Автор Иван Душенко На чтение 14 мин Просмотров 4.3к. Опубликовано 11.06.2021
Введение в тему
Данные не однородны. Информация, записанная на естественном языке, к примеру, это предложение, сильно отличается от данных, состоящих из чисел. Слова можно склонять, а числа – умножать. Для того, чтобы удобнее было работать с такими разными данными, создатели языков программирования разделяют их на различные типы. Типы данных Python не исключение.
О них мы и поговорим в этом уроке.
Что такое динамическая типизация
Python, как уже говорилось, является типизированным языком программирования. Естественно, у такого языка должен быть механизм определения типа данных. Если бы этого не было, возникали бы ситуации, когда логика программы будет нарушена, а код выполнится некорректно.
Этим механизмом является типизация.
В процессе её выполнения выполняется определение используемых. Типизация бывает статической и динамической. При статической проверка выполняется во время компиляции программы, а при динамической — непосредственно во время выполнения программного кода.
У Пайтона типизация динамическая. Благодаря этому одну и ту же переменную можно использовать много раз с данными разных типов, и она при этом будет каждый раз менять свой тип чтобы код исполнялся корректно:
example_variable = ‘Eggs’ print(type(example_variable)) example_variable = 500 print(type(example_variable)) example_variable = print(type(example_variable)) #Вывод:
Но, увлекаться этим не стоит – для улучшения читаемости кода, в большинстве случаев, лучше ввести дополнительные переменные для данных с другими типами. Это полезно ещё и тем, что переменные с хорошо выбранными названиями являются альтернативой комментариям и объясняют, что за данные они хранят.
Существует давний спор между сторонниками разных языков о том, какая типизация лучше: статическая или динамическая. Так как у обоих подходов есть и минусы, и плюсы, то правильным ответом будет: лучше, та типизация, которая больше подходит под Ваши задачи. В среднем, программы, написанные на языках со статической типизацией, более надёжны, но разработка на языках с динамической типизацией происходит быстрее. Часто встречается комбинированный подход, когда на динамическом языке пишут прототип программы, а потом, критически важные места переписывают на статический язык.
В последнее время набирает популярность «смешанная типизация». Самым ярким примером этого подхода является язык Rust: статическая типизация при входе и выходе из блока кода, но динамическая внутри этого блока. В последних версиях Питон тоже делает шаг в эту сторону: появился такой инструмент, как аннотирование типов или type hinting, но это тема отдельной статьи.
К основным плюсам динамической типизации относятся:
- Создание гетерогенных коллекций. Благодаря тому, что в Python 3 типы данных определяются во время run time (выполнения программы), можно создавать наборы данных, состоящие их элементов различных типов. Делается это не сложно:
example_variable = (‘Eggs’, 500, )
- Абстрагирование в алгоритмах. Благодаря тому, что тип данных определяется «на лету», можно создавать универсальные алгоритмы, которые будут работать с любыми данными.
- Длина кода. Если не описывать тип каждой переменной, код, конечно же получается короче и становится более высокоуровневым, читаемым.
- Простота изучения. Поскольку преобразование типов – отдельная сложная тема, а в этих языках вся работа с типами происходит без участия программиста, то, естественно, на динамических языках проще писать и их легче учить.
К основным минусам динамической типизации относятся:
- Ошибки. Ошибки типизации и логические ошибки на их основе – это главная проблема динамических языков. Суть в том, что получая данные не того типа, который предполагал программист, программа преобразует их и исполнится без ошибок. Результат, конечно, будет не верным. Вот здесь и начнётся ад дебаггинга.
- Оптимизация. Статически типизированные языки, как правило, более быстрые, так как им не нужно тратить вычислительные ресурсы на определение типа. Статические языки являются более низкоуровневыми и позволяют лучше контролировать происходящее.
Разница между атомарными и структурными типы данных
Все типы данных в Python можно разделить на атомарные и ссылочные.
- списки;
- множества;
- кортежи;
- словари;
- функции;
- классы;
Разница между этими типами в том, что атомарные объекты, при их присваивании переменным, передаются по значению, а ссылочные передаются по ссылке.
example_variable1 = ‘Eggs’ example_variable2 = example_variable1 example_variable1 = 500 print(example_variable1) print(example_variable2) #Вывод: 500 Eggs
Из вывода видно, что переменной example_variable2 было передано значение, содержащееся в example_variable1, а не ссылка, указывающая на область памяти.
Для ссылочных типов это работает иначе:
example_variable1 = [‘Eggs’] example_variable2 = example_variable1 example_variable1[0] = 500 print(example_variable1) print(example_variable2) #Вывод: [500] [500]
Поскольку списки – это структурные (ссылочные) объекты, то, после присваивания переменной example_variable1 переменной example_variable2 передалась ссылка на объект списка и, при печати, на экран были выведены две идентичные надписи.
В этом и заключается разница.
Числовые типы
Данные, представленные как числа, являются одними из наиболее важных в программировании. В Python для работы с такими данными создано несколько типов данных:
Int целое число
Понять целые числа очень просто. Самое простое определение: целые числа — это числа без дробной части. Могут быть нулём, положительными или отрицательными.
example_variable1 = 500 example_variable2 = example_variable1 — 43 example_variable3 = 2+2 print(example_variable1, example_variable2, example_variable3) #Вывод: 500 457 4
Если есть числа, то к ним применимы математические операции. Целочисленные данные используются для исчисления разных математических выражений. Также int используется для описания количественных характеристик объектов.
Float число с плавающей точкой
Действительные или вещественные числа (числа с плавающей точкой) созданы для измерения непрерывных величин. Языки программирования не способы реализовать иррациональные или бесконечные числа, поэтому всегда есть место приближению с определенной точностью, а значит, и некоторые неточности, из-за чего возможны следующие ситуации:
print(0.11 + 0.11 + 0.11) print(0.1 + 0.1 + 0.1) print(0.2 * 6) print(0.3 * 3 == 0.9) #Вывод: 0.33 0.30000000000000004 1.2000000000000002 False
Объявление float ничем не отличаются от int:
Источник: pythoninfo.ru