
Витрина данных — это простая форма хранилища данных, ориентированная на одно направление деятельности или тему. С витриной данных сотрудники могут быстрее получать доступ к данным и статистическим показателям, потому что не нужно тратить время на поиск по более сложному хранилищу данных или вручную собирать данные из разных источников.
Зачем создавать витрину данных?
Витрина данных обеспечивает более простой доступ к данным, необходимым для определенного отдела или производственного направления внутри организации. Например, если ваш отдел маркетинга ищет данные, которые помогут ему повысить эффективность рекламной кампании в период праздников, просматривать и выбирать нужные данные из нескольких разрозненных систем довольно затратно и с точки зрения времени, и с точки зрения денег, причем невозможно обеспечить точность.
Сотрудники подразделений, которые вынуждены искать данные в разных источниках, как правило, пользуются таблицами для обмена информацией и сотрудничества. Это часто приводит к человеческим ошибкам, путанице, сложным согласованиям и появлению нескольких источников достоверных данных — так называемому «табличному кошмару». Витрины данных стали довольно популярны как централизованные хранилища, в которых собираются и упорядочиваются нужные данные, после чего могут создаваться отчеты, информационные панели и визуализации.
Бизнес-аналитика для банковской и финансовой сфер на примере Tableau. Витрины данных за 10 минут
Различия между витриной данных, озером данных и хранилищем данных
Витрины данных, озера данных и хранилища данных используются в разных ситуациях и для разных целей.
Хранилище данных — это система управления данными, которая поддерживает анализ бизнес-данных и выполнение аналитики для всей организации. Хранилища данных часто содержат большие объемы данных, в том числе исторических. Обычно данные поступают в хранилище из многочисленных источников, таких как журналы приложений и транзакционные приложения. В хранилище данных хранятся структурированные данные с определенными целями.
Озеро данных позволяет организациям хранить большие объемы структурированных и неструктурированных данных (например, из социальных сетей или данных о посещениях) и мгновенно предоставлять к ним доступ для выполнения в реальном времени аналитики, углубленной аналитики данных и построения сценариев использования машинного обучения. Данные поступают в озеро данных в своей исходной форме, без изменений.
Основное различие между озером данных и хранилищем данных состоит в том, что в озере хранятся большие объемы необработанных данных без заранее определенной структуры. Организациям не нужно определять заранее, как будут использоваться эти данные.
Витрина данных — это простая форма хранилища данных, которое ориентировано на определенную тему или направление деятельности, например на продажи, финансы или маркетинг. С учетом этой узкой специализации получается, что витрины данных собирают данные из меньшего количества источников, чем хранилища данных. Источниками для витрины данных могут служить внутренние операционные системы, центральное хранилище данных и внешние данные.
Анализ данных на языке SQL ч.4. Хранилища и витрины данных
Преимущества витрины данных
Витрина данных, созданная для определенного отдела или направления деятельности, дает ряд преимуществ:
- Единый источник достоверных данных. Централизованный характер витрины данных гарантирует, что все в отделе или организации принимают решения, опираясь на одни и те же данные. Это важное преимущество, потому что данным и основанным на них прогнозам можно доверять, так что заинтересованные лица могут сосредоточиться на принятии решений и выполнении действий, а не на обсуждении данных.
- Более быстрый доступ к данным. Конкретные бизнес-отделы или пользователи могут быстро получать доступ к нужному им подмножеству данных из корпоративного хранилища данных, и объединять эту информацию с данными из других источников. Когда связи с источниками нужных данных будут установлены, сотрудники смогут получать оперативные данные из витрины данных по мере необходимости, а не обращаться в отдел ИТ, чтобы запросить периодически собираемую информацию. В результате повышается производительность как бизнес-отделов, так и ИТ.
- Быстрое получение статистических данных ускоряет принятие решений. Хранилище данных помогает принимать решения на уровне предприятия, а витрина данных предоставляет аналитику данных на уровне отделов и подразделений. Аналитики могут сосредоточиться на определенных проблемах и возможностях в таких сферах, как финансы и HR, и быстрее переходить от просмотра данных к статистическим показателям, которые позволяют быстрее принимать более взвешенные решения.
- Более простое и быстрое применение. Настройка корпоративного хранилища данных для обслуживания всей компанией может потребовать немало времени и усилий. А витрине данных, настроенной на обслуживание потребностей определенного отдела, достаточно доступа к гораздо меньшему количеству множеств данных. Поэтому витрину данных проще создавать и быстрее можно начать использовать.
- Создание гибкого и масштабируемого решения для управления данными. Витрины данных предлагают гибкие системы по управлению данными, которые работают с учетом потребностей компании, в том числе могут использовать информацию, собранную при выполнении прошлых проектов, чтобы способствовать решению текущих задач. Отделы и подразделения могут обновлять и изменять свои витрины данных, опираясь на новые и недавно запущенные проекты по аналитике.
- Анализ переходных процессов. Некоторые проекты по аналитике данных выполняются в сжатые сроки. Например, нужно провести анализ онлайн-продаж по результатам двухнедельной рекламной акции, чтобы представить его на совещании отдела. И отдел может быстро настроить витрину данных для выполнения такого проекта.
Перенос витрин данных в облако
Рабочие группы и отделы стараются действовать более гибко и опираться на данные при внедрении общей стратегии и принятии повседневных решений. Но, как правило, бывает непросто превратить постоянно растущий объем данных в статистические показатели. Финансовые директора проводят в среднем по 2,24 часа в день, анализируя таблицы данных. Рабочие группы обычно обращаются за помощью в отдел ИТ, и ИТ-специалистам приходится тратить немало сил, чтобы соответствовать запросам пользователей и предоставлять данные из разнообразных источников в больших объемах, а также быстрее реагировать на запросы.
Создание витрин данных также может осложнить задачи и без того загруженному работой отделу ИТ, потому что им нужно будет постоянно контролировать эти витрины данных и обеспечивать их безопасность. Перенос витрин данных в облако может решить многие проблемы как рабочих групп, так и отделов ИТ, потому что администрированием и обеспечением безопасности в облаке будет заниматься поставщик облачных решений. Таким образом значительно сокращается число задач, которые нужно выполнять вручную, и снижаются операционные расходы.
Как Oracle Autonomous Database обеспечивает работу облачных витрин данных
Oracle предлагает готовое комплексное решение самообслуживания, которое позволяет рабочим группам и отделам пользоваться надежными статистическими показателями, полученными в результате глубокого анализа данных. Эти показатели помогут им быстрее принимать решения.
Сотрудники и отделы могут быстро объединять все нужные данные из разных источников и в разных форматах, включая пространственные объекты и графы, в единую базу данных, которая способствует налаживанию сотрудничества в защищенном режиме благодаря тому, что витрины данных предоставляют единственный источник достоверных данных. Аналитики могут с легкостью использовать инструменты самообслуживания для работы с данными и возможности машинного обучения (не занимаясь самостоятельно написанием программного кода), чтобы ускорить загрузку данных, их преобразование и подготовку, автоматически выявлять шаблоны и тенденции, делать прогнозы и получать статистические показатели на основе данных известного проиcхождения.
Контролируемые и безопасные решения Oracle позволяют снизить нагрузку на отделы ИТ. Отделы ИТ могут полагаться на простые, надежные и воспроизводимые методы при любых запросах на аналитику данных от различных подразделений организации, и таким образом значительно повышать производительность.
Oracle Autonomous Database для аналитики и хранилища данных автоматизирует инициализацию, настройку, обеспечение безопасности, отладку, масштабирование, внесение исправлений, создание резервных копий и ремонт. Он практически полностью устраняет потребность в ручном выполнении сложных задач, которые могут вести к человеческим ошибкам.
Встроенные инструменты для работы с данными позволяют в режиме самообслуживания с легкостью выполнять загрузку данных, их преобразование, бизнес-моделирование и автоматическое вычисление статистических показателей для витрин данных. Администраторы баз данных могут не тратить силы на решение рутинных задач, а вместо этого заняться проектированием новых приложений и помогать другим отделам в достижении поставленных целей. Специалисты из сферы финансов, HR и маркетинга получают безопасный доступ к данным и могут рассчитывать на неизменно быстрые и качественные ответы на запросы даже в периоды пиковых нагрузок независимо от того, сколько пользователей одновременно обращаются за информацией. Autonomous Database выполняет масштабирование автоматически в зависимости от рабочей нагрузки без простоев в работе.
Источник: www.oracle.com
Простор для данных
Если коротко, то витрины (витрина от англ. data mart) – это набор структурированных данных. Обычно это данные по определенной теме или задаче в компании. Например, витрина с данными о заказчиках для отдела маркетинга может содержать подробные данные по договорам, истории заказов и поставок, оплатах, звонках и адресах доставки. Ничего лишнего, только нужные и актуальные очищенные данные, полученные из других ИС предприятия. Таких витрин даже на одном предприятии может быть множество.

Чаще всего с помощью витрин анализируют данные и строят ML-модели. Также витрины могут использоваться на предприятиях в качестве мастер-данных, например как справочники. Помимо этого, витрина может выступать периферическим узлом в сетях обмена данными между различными участниками. Примером концепции построения таких сетей для обмена данными является Data mesh (вот тут есть хороший перевод статьи по теме Хабр).
Типовой проект внедрения витрин состоит из технологической и прикладной частей. Если для решения технологических задач брать готовый инструмент, а не писать систему с нуля, то можно заложить больше ресурсов на прикладные задачи, которым зачастую уделяют незаслуженно мало внимания. Для B2B и других проектов, предполагающих внедрение множества витрин у различных заказчиков, готовый инструмент позволит существенно снизить технические риски, уменьшить затраты и сократить сроки внедрения.
Что требуется от витрины?
Сразу хотелось бы ответить на вопрос: а почему нельзя просто взять любую из существующих СУБД и сразу закрыть технологические задачи?

На самом деле, можно, но, как обычно, всё дело в деталях, а точнее в требованиях к витринам, которые нередко упускаются из вида и могут болезненно проявиться уже на поздних этапах, например при ОПЭ:
- Изоляция данных. Обновление данных, например загрузка справочника, может быть растянуто во времени, при этом до окончания загрузки текущая версия справочника должна быть полностью доступна с исключением «грязного чтения» загружаемой версии.
- Гарантии атомарности операций при обновлении данных. В случае сбоев и ошибок загрузки данных витрина остаётся в состоянии, которое предшествовало сбойному процессу. Другими словами, или данные обновляются полностью, или не обновляются вовсе, не оставляя следов сбойных операций.
- Устойчивость к дубликатам изменений. Весьма сложно и дорого реализовывать во всех ИС-источниках данных выгрузку по принципу exactly-once. Наличие дублей одинаковых изменений объектов не должно приводить к нарушению логической целостности состояния витрин.
- Системная темпоральность. Мало какая реляционная СУБД имеет функцию системной темпоральности «из коробки». Ведение системного времени и версионирование записей по системному времени позволяет сравнивать состояние данных витрины между двумя разными моментами времени или проводить «расследование», основываясь на данных, которые были в витрине в определенный момент в прошлом. Одним из вариантов обеспечения темпоральности является реализация SCD2 с ведением диапазонов сроков действия для версий записи.
- Эффективное выполнение различных видов запросов: сравнительно редких и тяжелых аналитических запросов, затрагивающих большой объем данных (OLAP-нагрузка), и множества одновременных простых запросов (OLTP-нагрузка). Как правило, СУБД заточены на какой-то один вариант нагрузки: OLAP или OLTP.
Концепция
С середины 2020 года наша команда разрабатывает Систему, предназначенную для построения витрин данных. Начав с разработки прототипа, мы продолжили развивать функционал в рамках той же архитектуры. Сейчас это открытое программное обеспечение, которое мы используем при внедрениях витрин данных.
У нас в тех. проекте записано: «Простор – интеграционная система, обеспечивающая унифицированный интерфейс темпоральной реляционной СУБД к гетерогенному хранилищу данных». Гетерогенное хранилище позволяет использовать сильные стороны каждой из СУБД, входящих в состав хранилища, и не быть заложником недостатков одной из них.
В Просторе гетерогенное хранилище представлено такими СУБД:
- Greenplum – аналитическая СУБД, предназначенная для OLAP-нагрузки. Хорошо горизонтально масштабируется, имеет высокий уровень поддержки стандарта SQL.
- Clickhouse – аналитическая СУБД. Демонстрирует одни из лучших в классе показатели выполнения агрегационных запросов. Не полностью поддерживает SQL и имеет ряд иных ограничений при эксплуатации, например при изменении или удалении записей.
- Tarantool – In-memory СУБД с персистентным хранением данных. Отличные показатели при OLTP-нагрузке (чтение отдельных записей). В кластерном режиме имеет ограничения по исполнению SQL-запросов.
- PostgreSQL – всеми любимая реляционная СУБД. Хорошо держит OLTP-нагрузку, но горизонтально не масштабируется и, соответственно, не подходит для аналитических запросов с действительно большим объемом данных.
Состав СУБД хранилища данных можно изменять в зависимости от характера предполагаемой нагрузки или уже в процессе эксплуатации. Для небольших витрин можно использовать одну СУБД, например PostgreSQL. Для крупных витрин, содержащих большие объемы данных и предполагающих разнородные запросы, можно использовать различные сочетания, например Greenplum + Tarantool или Greenplum + Tarantool + Clickhouse.
Ядро системы – сервис, выполняющий роль координатора и диспетчера. Обеспечивает единый интерфейс доступа, маршрутизирует запросы, управляет процессами загрузки и выгрузки данных, контролирует целостность данных. Также ядро парсит входящие SQL-запросы и обогащает их до вида, готового к исполнению в той или иной СУБД. Непосредственно выполнением запросов занимаются СУБД хранилища.

Обмен большими объемами данных между витриной и поставщиками/потребителями этих данных выполняется через Kafka. Но если речь идет о небольших объемах данных (сотни записей), то загружать или читать данные можно напрямую через Ядро.
Ядро управляет специальными компонентами – коннекторами, предназначенными для массивно-параллельной загрузки данных из Kafka в СУБД хранилища и массивно-параллельной выгрузки данных в Kafka из СУБД хранилища.
С точки зрения пользователя
Если пользователем называть поставщика или потребителя данных, то с точки зрения такого «пользователя» Простор выглядит так:

- Единый интерфейс доступа – JDBC 4.2. Подключиться к Простору можно как к обычной реляционной СУБД, например, используя SQL-клиент, в котором доступны все элементы логической модели и запросы к ним.
- Единая логическая реляционная модель данных, скрывающая «под капотом» реальные физические модели данных СУБД хранилища. При изменении логической модели данных автоматически изменяются и соответствующие физические модели в СУБД хранилища. Логическая модель – внешнее пользовательское представление модели данных витрины. Включает следующие логические сущности: a. Логическая таблица (table) – для «пользователя» это обычная таблица, но с возможностью указать момент времени в прошлом, относительно которого требуется «наблюдать» данные таблицы.
SELECT * FROM customers FOR SYSTEM_TIME AS OF ‘2021-12-01 15:00:00’

Также для логической таблицы можно ограничить СУБД хранилища, в которых она будет физически расположена. b. Логическое представление (view) – сохраненный именованный SQL-запрос, к которому можно выполнять запросы, также с возможностью указания момента времени «наблюдения» данных. c. Логическое материализованное представление (materialized view) – необычная логическая таблица, новые или измененные данные в которую попадают автоматически на основании сохраненного запроса к другим логическим таблицам, расположенным в других СУБД хранилища. Особой возможностью запросов к логическим материализованным представлениям является автоматическое перенаправление такого запроса к исходным логическим таблицам, если отставание данных материализованного представления больше заданного предела. Материализованные представления позволяют реализовать более интересные варианты топологии витрины, в которых одна из СУБД исполняет роль отказоустойчивого мастера, а другая — содержит материализованные read-only-представления. d. Логическая внешняя таблица – виртуальная таблица, по сути являющаяся указателем на источник или приёмник данных. Записывая или считывая данные из этой таблицы, можно управлять загрузкой и выгрузкой данных.
— открыть новую дельту BEGIN DELTA; — загрузка данных в логическую таблицу customers из Kafka INSERT INTO customers SELECT * FROM customers_kafka_ext; — загрузка данных в логическую таблицу calls из Kafka INSERT INTO calls SELECT * FROM calls_kafka_ext; — загрузка данных в логическую таблицу balance из Kafka INSERT INTO balance SELECT * FROM balance_kafka_ext; — закрыть дельту COMMIT DELTA;

Все изменения, выполненные в одной дельте, помечаются единой меткой времени комита дельты. Изменения данных, производимые в рамках открытой дельты, изолированы от пользовательских запросов с целью исключения «грязного чтения». Можно утверждать, что изменения в рамках дельты доступны для пользователя целиком и одномоментно или не доступны вовсе. Если необходимо, то открытую дельту можно откатить.
Простор – система для построения витрин данных, доступная под лицензией Apache 2.0. Для тестирования и ознакомления с возможностями системы можно развернуть минимальную конфигурацию, где Простор использует в качестве хранилища только PostgreSQL. Инструкция по развертыванию доступна тут. Если объем данных для витрины не очень большой, то такая конфигурация может использоваться и для PROD.
Источник: habr.com
Как быстро развернуть хранилище и аналитику данных для бизнеса
Сегодня хочу рассказать историю проекта по запуску небольшого хранилища данных DWH одной из известных российских инвестиционных площадок по финансированию малого и среднего бизнеса.
Два года назад в России стал довольно активно развиваться рынок краудлендинга. Краудлендинг — это процесс, при котором группа инвесторов дает займы компаниям. Но изюминка заключается в том, что в роли инвесторов выступают обычные люди, такие как мы с вами. А заемщиками выступают обычные организации типа ИП или ООО, которые в основном управляют либо розничным бизнесом, либо e-commerce. Соответственно была запущена инвестиционная платформа, которая сводила вместе инвесторов и заемщиков.
Не стоит и говорить, что сразу после запуска площадки руководству потребовалась управленческая и аналитическая отчетность для управления бизнесом. Была поставлена цель быстро настроить предоставление ежедневных оперативных ключевых показателей для кампании.
Full-stack аналитик (системный и бизнес-анализ) Открытие , Гибрид , По итогам собеседования
Сам WEB-сайт инвестиционной площадки и все его внутренние процессы, или так называемый «кредитный конвейер», крутились на БД PostgreSQL. Кредитный конвейер — это собирательное понятие, описывающее весь процесс выдачи компаниями кредитов, начиная от подачи заемщиком заявки на займ и заканчивая погашением кредита.
Стек технологий, который был выбран для внедрения этого проекта, был БД MS SQL + SQL Server Analysis Service + сводные таблицы OLAP в Excel (BI система) для разработки ежедневных кубов OLAP.

27 распространённых вопросов по SQL с собеседований и ответы на них
Перед дальнейшим рассказом хотел бы расшифровать некоторые термины:
- OLAP — это online analytical processing, он же — оперативный анализ данных. Для обычного потребителя отчета это выглядит как сводная таблица в Excel. Но подключается она к SQL Server Analysis Service для отбора данных и отображения их в Excel.
- DWH – аббревиатура от Data Warehouse, т.е. хранилище данных. Некая база данных, где собирается вся информация о нашем проекте.
- ETL-процесс — Extraction-Transformation-Loading т.е. Извлечение, Обработка, Загрузка. Подразумевается процесс загрузки данных из одной или нескольких исходных систем в DWH. Этот процесс извлекает информацию из внешних систем-источников, трансформирует ее, очищают и загружают в единое хранилище.
- BI-система – инструмент аналитики и визуализации показателей. Business Intelligence (BI) позволяет компаниям собрать информацию из различных источников, проанализировать ее и представить в наиболее понятном и удобном для восприятия виде. С помощью различных программ и инструментов BI специалисты анализируют большие массивы данных, на основании которых разрабатывают и автоматизируют отчетность и дашборды. На основе полученных данных сотрудники принимают ключевые для развития компании решения
Важно понимать, что под сводными таблицами в Excel понимается не просто статичный отчет, а полноценная BI-система для аналитики данных. Набор показателей и фильтров, которыми можно «вращать» в реальном времени. Добавлять/удалять показатели, настраивать фильтры и смотреть статистику в различных разрезах — все это называется общим термином аналитика показателей.
Круг задач, которые нужно решить, был следующим:
- Настроить ежедневную выгрузку данных из БД PostgreSQL в хранилище DWH.
- Собрать структуры данных и детальные витрины показателей Data Marts.
- На основе этих витрин собрать кубы на MS Analysis Service и при этом посчитать порядка 30 показателей и измерений.
- Собрать сводную таблицу с помощью которого можно смотреть показатели и проводить аналитику. Добавлять показатели, фильтры и разрезы для получения нужной статистики.
Архитектура для данного проекта была принята следующая:
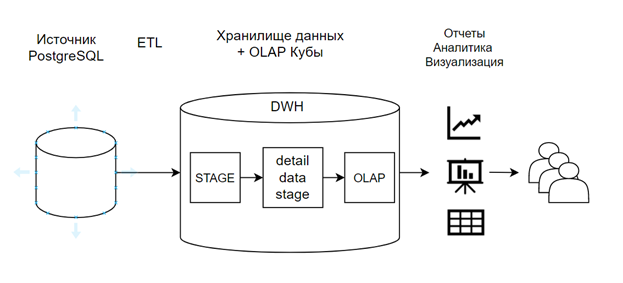
Схема движения потоков данных в DWH
Поскольку во всем проекте было вовлечено минимум сотрудников, то процесс разработки протекал максимально эффективно. Два бизнес-заказчика предоставляли требования к отчетности, а владелец источника предоставлял доступы и описания как к различным таблицам, так и к структурам данных. Я же выполнял роль и разработчика, и аналитика в одном лице. За счет того, что каждый сотрудник выполнял свою роль по максимуму, коммуникация внутри данного круга лиц была очень быстрой и эффективной. А сам процесс разворачивания хранилища протекал очень продуктивно.
Что было сделано в первую очередь?
В первую очередь был настроен обмен данными с хранилищем через ETL-процессы. В MS SQL были созданы коннекторы, которые могли подключаться источнику данных. Под источником понимается другая БД PostgreSQL. Также при создании коннектора установили драйверы для PostgreSQL и настроили системный DSN.

Пример создания подключения к базе

Создание «связного сервиса» в MS SQL
В MS SQL есть возможность прямого подключения к другим БД, так называемый «Связный сервис». В других базах она может называться по-разному (например, в oracle — это db-link), но суть одна и та же. Установив на сервере драйверы для подключения к PostgreSQL можно напрямую из MS SQL выполнять запросы в другую БД и выгружать данные. Соответственно, создав небольшую SQL-процедуру очистки и загрузки данных, как на примере ниже, можно выгружать по линкам любые таблицы из любых источников.
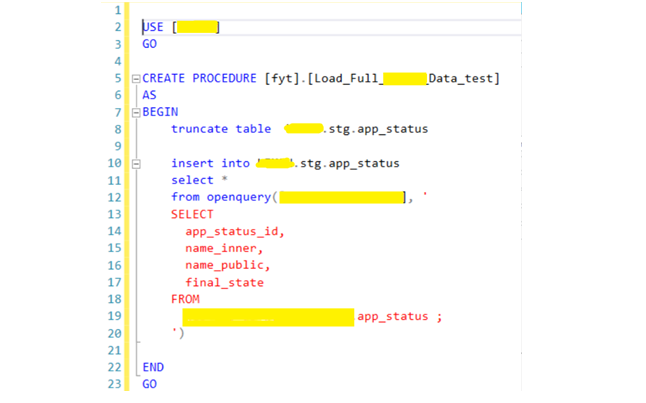
Пример самой простой процедуры полной загрузки таблицы из источника
Также стоит рассказать, про так называемый, сервис «Агент SQL сервер» в MS SQL позволяющий создавать планировщик заданий, запускающийся по расписанию (обычно ночью) и запускающий эти процедуры для загрузки данных в хранилище. Таким образом мы получили набор таблиц, структура которых идентична источнику, на основе которых далее можно выполнять обработку и строить витрины.

Пример создания планировщика заданий на MS SQL c запуском процедур и кубов OLAP
Витрины данных (Data Marts)
Следующим большим шагом проекта было создание витрин данных. В самой базе было создано всего 3 основные смысловые схемы:
stg — от слова STAGE. В ней лежат таблицы структура данных приближенная к источникам. Туда загружаются данные напрямую из источника.
dim — от слова dimensions. Схема, в которой хранятся справочники.
dds — от слова detail data stage т.е. детальный слой данных. В ней собираются уже обработанные данные взятые из stg.
Для общего понимания обработка dds выглядит как набор процедур и функций порядка 2000 строк чистого SQL кода. Важно заметить, что динамический SQL не использовался, что сильно упрощало жизнь.
Ну и один из последних шагов — создание кубов на MS SQL Analysis Service. Выполнялось все это с помощью инструмента Visual Studio. В них создается физическая и логическая структура сущностей на основе витрин DDS. А также настраиваются показатели и измерения с бизнес понятными переводом для потребителей отчетов.
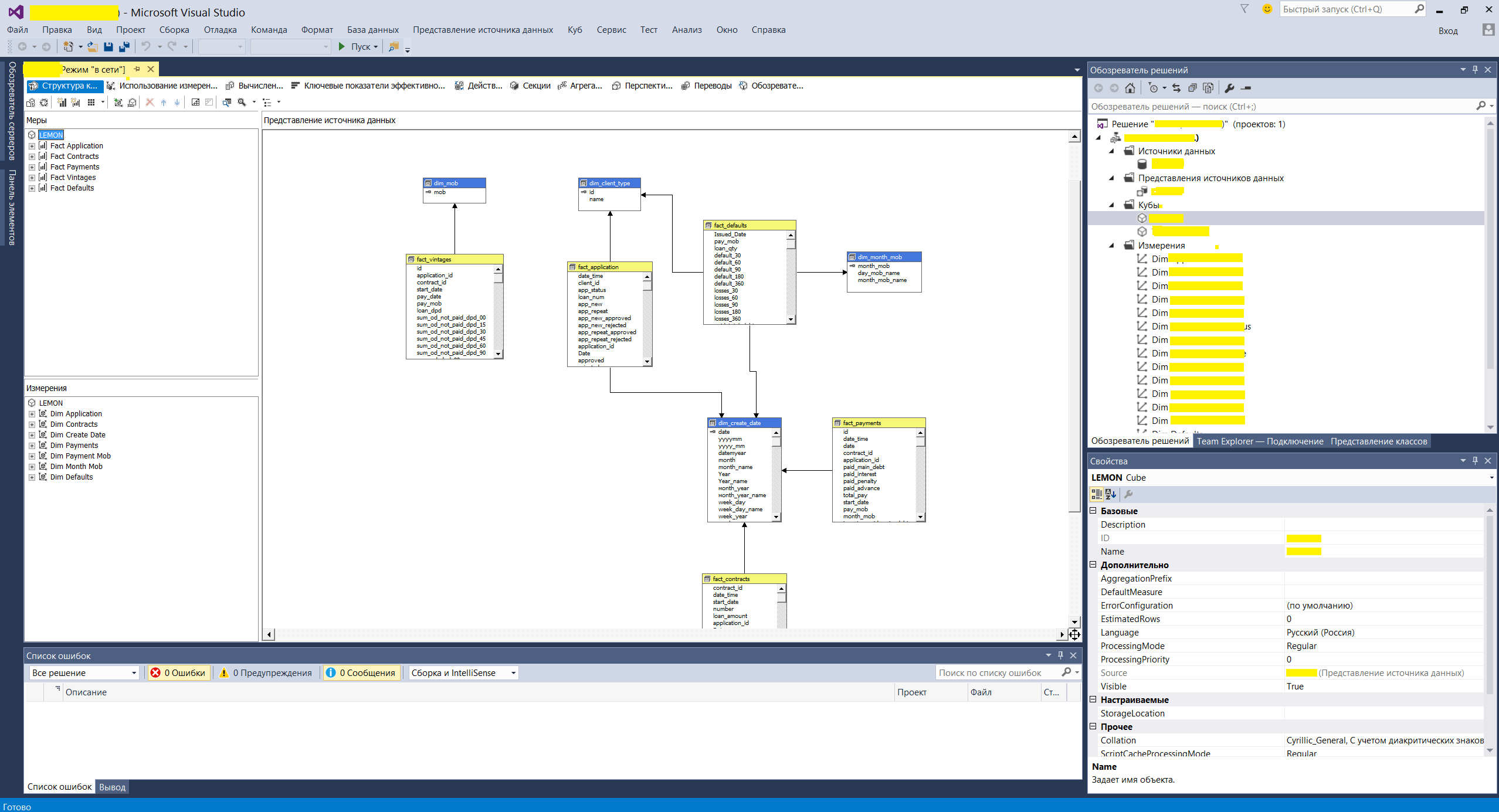
Пример формы создания логической структуры данных OLAP кубов
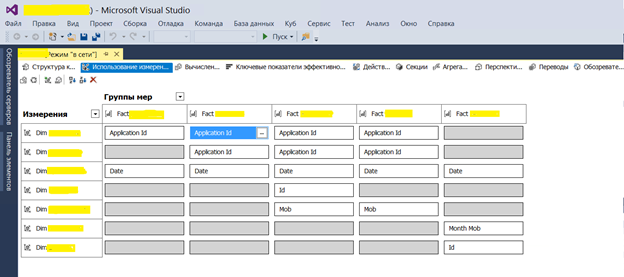
Пример настройки связей для фактовых сущностей в кубах
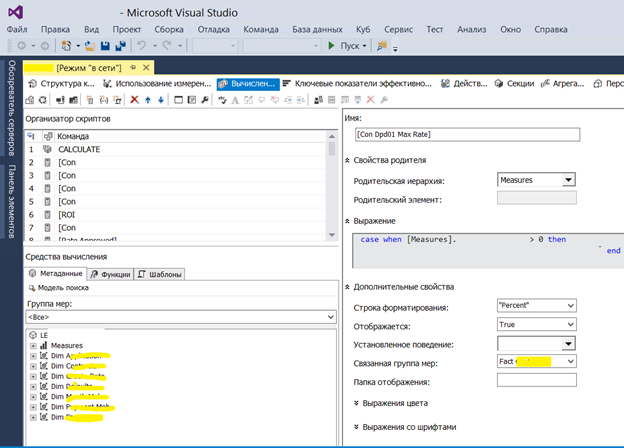
Пример настройки вычисляемых полей в OLAP
Важно заметить, что при построении таких хранилищ и отчетности очень важным моментом является стабилизация отчетности в плане качества данных. Тестирование показателей и устранение расхождений также отнимает большое количество времени и трудозатрат при построении витрин и показателей. Несмотря на тот факт, что вся настройка OLAP выполняется в интерфейсах, сам инструмент является очень простыми и удобным в разработке.
Также очень важно понимать, что кубы OLAP очень удобно использовать на небольших хранилищах не более чем в несколько терабайт. Если речь идет о построении больших хранилищ, например для ритейла, телекоммуникаций или банковской сферы, то объемы данных начинают исчисляться десятками терабайт. Большие объемы требуют полноценные BI-решения с наличием высокопроизводительных серверов. Например, такие продукты как Oracle BI, SAS BI являются полноценными Enterprise решениями стоимость которых начинаются с цифры с нескольким количеством нулей и исчисляется в долларах.
В общем была создана система аналитики на основе OLAP со стартовым набором показателей, которая сильно помогла в принятии дальнейших управленческих решений для развития бизнеса.
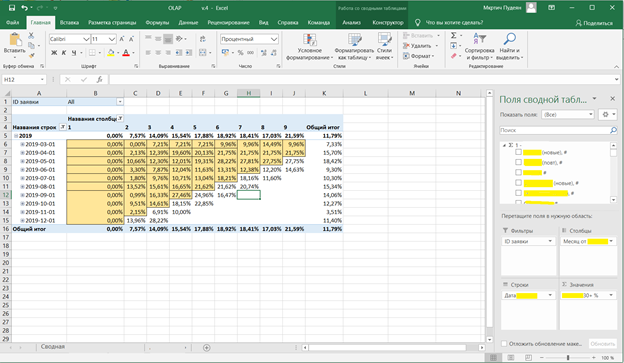
Пример сводной таблицы, который подключается к Analysis Service для вращения кубов
В заключение, скажу, что это был только первый этап построения аналитической отчетности. На текущий момент хранилище очень сильно выросло и в объемах, и в количестве источников. Но базис, заложенный в начале, очень сильно помог в развитии дальнейшего бизнеса. А смысл всей истории в том, что не обязательно тратить месяцы на разработку и моделирование архитектуры для построения DWH, как обычно это бывает. При запуске бизнеса или стартапа, можно пожертвовать техническим долгом для быстрого достижения бизнес целей и делать это можно вполне успешно.
Источник: tproger.ru