
Выделяют три типа ошибок: ошибки компиляции, ошибки времени выполнения и логические ошибки.
Ошибки компиляции являются синтаксическими ошибками. Они выдаются при компиляции программы. Программа с синтаксическими ошибками не может быть выполнена.
Ошибки времени выполнения связаны с невозможностью по какой-либо причине выполнить очередное действие, что приводит к аварийному останову программы. Такие ошибки возникают, например, при делении на 0, вычислении логарифма с отрицательным аргументом, переполнении стека при выполнении рекурсивной подпрограммы и т.п.
Логические ошибки возникают при неправильном проектировании алгоритма или по невнимательности при записи или наборе программы. Программа с логическими ошибками может быть выполнена до конца, возможно даже, что при некоторых наборах исходных данных результаты будут правильными.
В процессе устранения логических ошибок можно выделить три этапа:
1. установление факта существования ошибки;
2. локализация ошибки;
Обнаружение и исправление ошибок
3. устранение ошибки.
Существуют 2 метода обнаружения ошибок:
1. статическая (ручная) проверка, которая заключается в анализе программы без выполнения ее на ЭВМ;
2. тестирование — прогон на ЭВМ.
Оба метода требуют наборов тестовых данных, которые должны подбираться параллельно с разработкой алгоритма. В число наборов тестовых данных рекомендуется включить несколько типичных, среди них должны быть корректные и некорректные данные. Тестовые данные должны охватывать предельные случаи. Если в программе есть разветвления, то необходимы наборы тестовых данных для каждой ветви. Если в программе есть циклы, то данные нужно подобрать так, чтобы цикл выполнялся минимально и максимально возможное число раз.
При отладке программ для практического использования нужно подобрать дополнительные тестовые данные:
1. Получить реальные данные у потенциального пользователя.
2. Породить случайным образом наборы тестовых данных.
Ручная проверка
Нужно руководствоваться правилом: чем раньше обнаружена ошибка, тем легче ее исправить. Поэтому при разработке алгоритма и записи программы необходимо следить за инициализацией всех переменных в программе, необходимо устанавливать правильное завершение циклов, избегать зацикливания. Какой бы простой ни была программа, рекомендуется выполнить трассировку с записью результатов на каждом шаге.
Статистика утверждает, что 70% ошибок можно устранить на этапе ручного тестирования.
Машинное тестирование
Известный специалист в области программирования Дейкстра считает, что тестирование доказывает наличие ошибок, а не их отсутствие.
Выделяют два вида тестирования: разрушающее и диагностическое:
1. Разрушающее тестирование производится над программой, которая считается правильной, с целью заставить ее дать сбой.
2. Диагностическое тестирование выполняется с целью локализации ошибки, если известно о ее существовании.
В ТР существуют системные средства для отладки программ. Они позволяют выполнить трассировку с выводом значений интересующих переменных и выражений, устанавливать точки останова, точки прерывания (контрольные точки).
Как исправить ошибки в Excel. Примеры исправления + виды ошибок
Проверка правильности данных
Правильно написанная программа должна:
1. при вводе некорректных данных выдавать сообщение, указывающее на некорректный элемент данных и сообщать о причине некорректности;
2. произвести как можно больше правильных вычислений;
3. встретив некорректный элемент данных, проверить остальные данные.
Исправление ошибок
1. Перед всяким устранением ошибки нужно подумать, к чему это приведет.
2. После того как в программу внесены изменения, нужно заново ее протестировать.
Устойчивая программа — это программа, которая порождает правильные результаты во всех случаях, когда это возможно, иначе — указывает причину, по которой программа не может быть выполнена. Всякая практически используемая программа меняется в течение своей жизни.
Изменения включают в себя исправление логических ошибок, выявленных при эксплуатации программы, и модификацию программы в соответствии с новыми требованиями. На эту деятельность, которая называется сопровождением, программисты тратят больше времени, чем на создание программы. Правильная программа, после внесения в нее изменений, может перестать быть правильной. Поэтому программа должна быть предельно ясной и понятной тому, кто занимается сопровождением, структура программы должна быть такой, чтобы ее легко было модифицировать, не лишая устойчивости.
19. РЕГУЛЯРНЫЙ ТИП (МАССИВ)
Чтобы хранить и обрабатывать сложные виды информации, нужно научиться строить нетривиальные структуры данных. Такие структуры создают путем объединения данных, в конечном итоге, простых типов. Составные части структурированных типов называются их компонентами.
В ТР существует ограничение на объем памяти, занимаемой значением любого структурированного типа. Этот объем не должен превышать 65520 байтов.
Одним из структурированных типов во многих алгоритмических языках является регулярный тип (тип массив). Массив представляет собой совокупность фиксированного числа компонентов одного типа. Тип компонентов массива называется базовым типом.

Количество типов индекса, перечисленных в квадратных скобках, определяет размерность массива. Размер массива — это общее число его компонентов.
Тип индекса должен быть упорядоченным типом. Чаще всего для типа индекса используют интервальный тип, реже — перечисляемый или стандартный. Тип индекса не может быть четырехбайтовым.
Базовый тип может быть любым.
Одномерные массивы
Если указан только один тип индекса, массив является одномерным.
Примеры описаний одномерных массивов:
type t_vect =array[1.. MAXLEN] of integer;
c, d: array[1.. MAXLEN] of integer;
flag: array[‘A’..‘Z’] of boolen;
Массивы a, b, c, d имеют одинаковые размеры (=100). Размер массива poin t равен 3, flag — 26.
Компоненты (элементы) массива занимают последовательные ячейки памяти. Объем памяти, выделяемой массиву, равен произведению размера массива на объем, занимаемый элементом. Переменная а занимает 100*2=200 байтов, point — 3*6=18 байтов, flag — 26*1=26 байтов.
Следует обратить внимание на то, что типы переменных a и с компилятор считает разными. Важным понятием в Паскале является понятие тождественности типов. Переменные имеют тождественные типы, если они определены в одной секции или через одно и то же имя типа.
Согласно приведенным выше описаниям, типы переменных a и b тождественны, так как переменные описаны с использованием имени типа t_vect. Переменные с и d тоже имеют тождественные типы, так как описаны в одной секции.
Над массивами любой размерности как над едиными целыми не определены никакие операции. Разрешено присваивание переменной типа массив значения переменной тождественного типа, то есть для совместимости массивов по присваиванию требуется тождественность типов.
Если массивы a и d инициализированы, то допустимы операторы b:= a и c:= d.
Имя массива является общим именем совокупности компонентов (элементов) массива. Обращение к отдельным компонентам массива осуществляется с помощью переменных с индексами:

Выражение в квадратных скобках должно иметь тип индекса. Например, a[1], d[MAXLEN div 2], point[x], point[y], flag[‘X’], flag[succ(‘G’)].
Переменные с индексами можно использовать в любом месте программы, где допустим базовый тип. Ввод и вывод массива производится покомпонентно, обычно в цикле for.
Пример. Составим программу для определения максимального члена данной целочисленной последовательности, длиной не больше 100, и номера этого элемента:
var v: array [1.. MAXLEN] of integer;
imax, i: 1.. MAXLEN;
write(‘Введите длину последовательности £ ‘, MAXLEN);
write(‘Введите члены последовательности ‘);
for i:=1 to n do read(v[i]);
if v[i] > max then
writeln(‘ Максим. член последовательности — v[’, imax, ‘] = ’, max)
Упакованные массивы
Если в одном машинном слове можно разместить несколько элементов массива, то для экономии памяти можно использовать упакованный массив. Для этого при описании массива перед ключевым словом array следует указать ключевое слово packed.
Например, при описании
в двухбайтовом машинном слове размещается 5 элементов, для массива потребуется 2 слова, то есть 4 байта.
При работе с упакованными массивами усложняется доступ к отдельным элементам массива. В ТР массивы упаковываются автоматически, слово packed можно не указывать.
Многомерные массивы
Если количество типов индекса в описании массива равно n, то массив называют n -мерным. Формально размерность массива не ограничена, но фактически она зависит и от размера базового типа, и от ограничения на объем памяти структурированных типов.
Для представления матриц используются двумерные массивы. Тип первого индекса определяет число строк, а тип второго индекса — число столбцов матрицы. Например,
type t_matr=array[1..ROW, 1..COL] of word;
d: array[1..2, 1..3, (x, y)] of real;
Тип t_matr — двумерный массив размером 20х10. Его можно использовать для работы с матрицами порядка не больше чем 20×10. Переменная d — трехмерный массив.
Обращение к элементам многомерных массивов:

Идентификатор — имя массива. Число выражений (индексов) в квадратных скобках должно быть равно размерности массива. Например, a[3, 4], d [2, 1, y].
В памяти двумерные массивы располагаются по строкам. В общем случае элементы многомерных массивов размещаются так, что чем правее индекс, тем быстрее он меняется. Так, элементы массива d размещаются в памяти в следующей последовательности:
Для ввода и вывода многомерных массивов используются вложенные циклы. В качестве примера приведем фрагмент программы вывода в виде таблицы описанного выше массива a (i и j — целочисленные переменные):
Источник: infopedia.su
Типы ошибок в алгоритмах. Основные этапы проектирования (алгоритмизации)
Типы ошибок в алгоритмах. Если программа только что составлена, то она в очень редких случаях не содержит ошибок.
Различают три типа ошибок: синтаксические ошибки, ошибки выполнения и ошибки в алгоритме программы.
Синтаксические ошибки – возникает при нарушении правил языка QBasic. Такие ошибки сравнительно безобидны, поскольку причина ошибки описывается и программная строка с ошибкой выводится на экран. При наличии определенных навыков исправляются они достаточно быстро. Примером такой ошибки может служить неправильный набор ключевого слова PRITN вместо PRINT.
Ошибки выполнения – это такие ошибки, которые не нарушают синтаксиса языка, но приводят к ошибочным операциям в процессе выполнения. Примерами таких ошибок могут быть ошибка — индекс, ошибка – значение, деление на нуль, неправильное обращение к подпрограмме и т.д.
Ошибки в алгоритме программы – это такие ошибки, которые при верных исходных данных и безошибочной работе программы приводят к неправильным результатам. Такие ошибки должен обнаруживать сам программист. Поэтому, избавившись от синтаксических ошибок и ошибок выполнения, необходимо проверить работу программы на данных, охватывающих по возможности все случаи, которые могут встретиться при реальном счете. Для этого создаются и «прокручиваются» различные тесты (контрольные примеры).
Существует несколько методик отладки программы. Один из приемов отладки называется «проследить трассу». Он заключается в том, что в процессе работы программы на экране дисплея выдаются сообщения о ходе вычислений. Желательно одновременно с этим последовательно выводить на экран номера выполняемых строк. Использование отладочных строк с оператором PRINT для выдачи промежуточных результатов в совокупности с трассировкой позволяет быстро локализовать ошибку и исправить ее.
Другой часто применяемый способ отладки программы состоит в следующем: в критических точках расставляются вспомогательные команды STOP. При выполнении STOP вычисления приостанавливаются, и пользователь может вывести значения интересующих его переменных в режиме непосредственного исполнения на экран. После остановки вычисления возобновляют командой CONT. Анализ выведенных значений переменных позволяет делать выводы о правильности хода вычислительного процесса и принимать соответствующие решения.
Если же за дисплеем найти ошибку не удалось, нужно сесть за стол и применить очень действенный метод – выполнить программу вручную. Для этого необходимо представить, что вы машина, и начав с первого оператора программы, выполнять оператор за оператором, пока не будет обнаружена причина неправильной работы программы.
Эту работу нужно выполнять методично и терпеливо. Имитируя работу программы, мы должны иметь текст программы, список переменных с их текущими значениями и лист бумаги для отслеживания изменений. Выполняя программу вместо машины, нужно все время задавать себе вопрос: «Тот ли получен результат, которого я ожидал?». Если — да, то продолжите выполнение программы. Если — нет, то нужно думать, почему программа работает неправильно.
Следует иметь в виду, что в процессе отладки могут быть обнаружены и устранены не все ошибки. Более того, в процессе исправления обнаруженных ошибок могут быть допущены новые. Поэтому после каждого исправления требуется вновь произвести тестирование.
Основные этапы проектирования (алгоритмизации). Рассмотрим процесс решения задачи на конкретном примере:
Задача: Определить дальность полета тела, брошенного под углом к горизонту.
На первом этапе обычно строится описательная информационная модель объекта или процесса. В нашем случае с использованием физических понятий создается идеальная модель движения объекта. Из условия задачи можно сформулировать следующие основные предложения:
1) размеры тела малы по сравнению с траекторией полета, поэтому тело можно считать материальной точкой,
2) скорость бросания тела мала, поэтому:
— ускорение свободного падения считать постоянной величиной;
— сопротивлением воздуха можно пренебречь.
На втором этапе создается формальная модель, т.е. описательная информационная модель записывается с помощью какого-либо формального языка.
Из курса физики известны следующие формулы
Vx=V0*cos(A) – горизонтальная проекция вектора скорости
Vy=V0*sin(A) – вертикальная проекция вектора скорости
L=Vx*t – дальность полета, t- время полета
0=Vy*t-gt 2 /2 – координата точки падения
g=9,81 м/с 2 — ускорение свободного падения

Органичения:
Как видно из этой системы неравенств, бросание тела не должно происходить вправо и вверх, и начальная скорость не должна быть отрицательной.
Таким образом, метод решения данной задачи описывается следующей последовательностью формул:
На третьем этапе необходимо формализованную информационную модель преобразовать в компьютерную модель, т.е. выразить ее на понятном для компьютерном языке. Существуют два принципиально различных пути построения компьютерной модели:
— создание алгоритма решения задачи и его кодирование на одном из языков программирования;
— формирование компьютерной модели с использованием одного из приложений (электронных таблиц, СУБД и т.д.)
Для реализации первого пути надо построить алгоритм определения координаты тела в определенный момент времени и закодировать его на одном из языков программирования, например на языке QuickBasic.
Второй путь требует создания компьютерной модели, которую можно исследовать в электронных таблицах.
Собственно алгоритм решения данной задачи состоит из последовательного решения наших уравнений:
- Ввести начальную скорость (V0) и угол бросания (А)
- Присвоить переменной Vy значение V0*sin(A)
- Присвоить переменной Vx значение V0*cos(A)
- Присвоить переменной t (время полета) значение 2*Vy/g
- Присвоить переменной L (дальность полета) значение Vx*t
- Вывести ответ на экран (L).
Четвертый этап — составление программы, т.е. запись задачи на понятном компьютеру языке. В качестве примера выбран язык QuickBasic.
Пятый этап исследования информационной модели состоит в проведении компьютерного эксперимента. Если компьютерная модель существует в виде программы на одном из языков программирования, ее нужно запустить на выполнение и получить результаты.
На шестом этапе выполняется анализ полученных результатов и при необходимости корректировка исследуемой модели. В нашем случае можно попробовать запустить программу с различными исходными данными.
Таким образом, технология решения задач с помощью компьютера состоит из следующих этапов: построение описательной модели – формализация – построение компьютерной модели – компьютерный эксперимент – анализ результатов и корректировка модели.
Воспользуйтесь поиском по сайту:

studopedia.org — Студопедия.Орг — 2014-2023 год. Студопедия не является автором материалов, которые размещены. Но предоставляет возможность бесплатного использования (0.008 с) .
Источник: studopedia.org
Основные типы ошибок в программировании
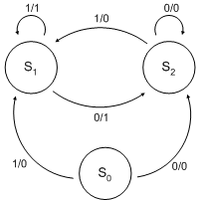
Автомат Мили (англ. Mealy machine) — конечный автомат, выходная последовательность которого (в отличие от автомата Мура) зависит от состояния автомата и входных сигналов. Это означает, что в графе состояний каждому ребру соответствует некоторое значение (выходной символ). В вершины графа автомата Мили записываются выходящие сигналы, а дугам графа приписывают условие перехода из одного состояния в другое, а также входящие сигналы.
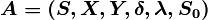
Автомат Мили — совокупность , где
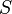
· — конечное непустое множество состояний автомата;
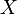
· — конечное непустое множество входных символов;
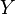
· — конечное непустое множество выходных символов;
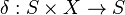
· — функция переходов, отображающая пары состояние/входной символ на соответствующее следующее состояние;
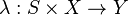
· — функция выходов, отображающая пары состояние/входной символ на соответствующий выходной символ;
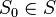
· — начальное состояние.
a(t + 1) = δ(a(t), z(t)) (переходов)
ω(t) = λ(a(t), z(t)) (выходов)
Таким образом, в автомате Мили выходной сигнал (буква выходного алфавита) и момент автоматного времени t зависит как от внутреннего состояния автомата в момент t, так и от входного сигнала (буквы входного алфавита) в момент t.
Понравилась статья? Добавь ее в закладку (CTRL+D) и не забудь поделиться с друзьями:
Источник: studopedia.ru