
4. Порядок разработки, экспертизы, регистрации и ведения ИПТ.
1. ГОСТ 7.74 – 96. Информационно-поисковые языки. Термины и определения [Текст]. – Введ. 1997-07-01. – Минск: Межгосударственный совет по стандартизации, метрологии и сертификации, 1997. – 34 с. (Система стандартов по информации библиотечному и издательскому делу) ТК 191.
2. ГОСТ 7.25-2001. Тезаурус информационно-поисковый одноязычный. Правила разработки, структура, состав и форма представления [Текст]. – Взамен ГОСТ 7.25-80; Введ. 2002-07-01. – М.: ИПК Изд-во стандартов, 2001. – 16 с. МТК 191.
3. ГОСТ 7.24-2007 Тезаурус информационно-поисковый многоязычный. Состав, структура и основные требования к построению. – Взамен ГОСТ 7.24-90; введ. 2008-07-01. / Межгосударственный совет по стандартизации, метрологии и сертификации. – М.: Стандартинформ, 2008. – 7 с. (Система стандартов по информации, библиотечному и издательскому делу)
4. Баранов, О. С. Идеографический словарь русского языка [Текст] / О. С. Баранов. – М.:Издательство ЭТС, 1995. – 820 c
Что такое Тезаурус и как им пользоваться в Microsoft Word
5. Жмайло, С. В. К вопросу об определении тезауруса [Текст] / С. В. Жмайло // НТИ. Сер. 1 Организация и методика информационной работы. – 2003. – №12. – С.20 – 25.
6. Жмайло, С. В. К разработке современных информационно-поисковых тезаурусов [Текст] / С. В. Жмайло // НТИ. Сер. 1 Организация и методика информационной работы. –2004. – №1. – С.23 – 31.
7. Пробст, М. А. Тезаурус и информационный поиск [Текст] / М. А. Пробст // НТИ. Сер. 2. Информационные процессы и системы – 1979. – №9. – С. 14 – 20.
1. Тезаурус как способ систематизированного представления знаний и разновидность идеографического словаря
Тезаурус (от греч. Thesauros – клад, сокровище, сокровищница) – многозначное слово, имеющее, как минимум, два значения:
1) тезаурус как идеальный объект – это «совокупность знаний, накопленных человеком или некоторым коллективом. Это упорядоченный и отраженный в сознании человека «лексикон», «мир» отдельной личности. В русском языке наиболее адекватный перевод слова «тезаурус» – это «мир знаний и интересов». Например, «мир знаний и интересов ребенка – тезаурус ребенка» и «мир знаний и интересов взрослого – тезаурус взрослого»; «мир знаний и интересов художника – тезаурус художника», «мир знаний и интересов бизнесмена – тезаурус бизнесмена» и т.п. В теории информации тезаурусом называют запас знаний (понятий, суждений), размещенных в памяти воспринимающего информацию субъекта. Это структурированное знание в виде понятий и смысловых отношений между ними,
2) тезаурус как материально существующий объект – словарь. Тезаурус – это словарь особого типа или идеографический словарь, в котором слова располагаются не по алфавиту, а по степени смысловой близости. Лексика языка представлена в них в виде систематизированных групп слов, в той или иной степени близких в смысловом отношении (синонимы, гиперонимы, гипонимы, антонимы, паронимы и др.). Тезаурус представляет собой упорядоченную совокупность лексических единиц, в которой в явном виде с помощью специальных помет отражены смысловые отношения (синонимические, родовидовые и ассоциативные) между лексическими единицами. Иными словами, упорядочение лексики в тезаурусе осуществляется не по алфавитному или другому формальному признаку, а по смысловому (семантическому).
Использование Тезауруса
В основе построения идеографических словарей лежит логическая классификация всего понятийного содержания лексики. Систематизация слов в таких словарях основана на психологических ассоциациях предметов и понятий, называемых какой-либо лексической единицей. Лексические единицы группируются в поля, в центре каждого из которых стоит слово, объединяющее другие слова, в той или иной степени близкие ему по значению или ассоциирующиеся с ним по смыслу (например: насекомое – муха, пчела, муравей, бабочка; ползать, летать, прыгать…). Как правило, слова и словосочетания внутри поля кратко толкуются таким образом, чтобы было видно, чем каждое из них отличается от всех других членов поля. Слова или словосочетания группируются на основании общности обозначаемых ими явлений действительности по определённым темам, например, «Животные», «Насекомые», «Дом», «Театр», «Улица», «Транспорт» и т. д.
Так, в идеографическом словаре русского языка О. С. Баранова (4) выделены 12 высших разделов идеографического словаря, среди которых: «порядок, природа, человек, деятельность, общество, культура» и др., каждый из которых делится на группы, подгруппы, отделы, разделы. Все слова в этом словаре собраны в гнезда по смыслу и группируются вокруг некоторого понятия, с которым они связаны чаще всего видовыми отношениями. Гнезда в свою очередь группируются в подразделы и т.д. На данный момент в словаре 5923 гнезд, 7 уровней деления (по данным www.rifmovnik.ru/thesaurus.htm на 16.02.2010 г.). Приведем пример словарной статьи из этого словаря:
178.4.7 аромат
аромат — приятный запах (например, запах цветов, травы, сена. нежный #. пьянящий #).
ароматизация
благоухание. благоухать.
амбре. фимиам.
Код слова «аромат» отражает принятую в данном словаре идеографическую классификацию, в частности, соотнесенность данного слова с категорией «178- Ощущения».
Таким образом, термины «тезаурус», «идеографический словарь», «словарь типа тезаурус», в первую очередь означают, что совокупность слов языка в них представлена таким образом, что в одну группу слов входят слова, близкие по смыслу. Основное назначение идеографических словарей — описать совокупности лексических единиц, объединённых общим понятием; это облегчает читателю выбор наиболее подходящих средств для адекватного выражения мысли и способствует активному владению языком.
Из истории тезаурусов
История появления и развития тезаурусов рассматривается в работах (5,7). В них отмечается, что история возникновения тезаурусов восходит к великим мыслителям древности и, прежде всего, к Аристотелю. Ему принадлежат слова, возраст которых 2,5 тыс. лет: «Из слов, высказываемых без какой-либо связи, каждое означает или сущность, или качество, или количество, или отношение, или обладание, или действие, или страдание» (Аристотель, Аналитики. – М.:Госполитиздат, 1952. – 438 с.).
Одной из наиболее древних попыток идеографических классификаций является труд Аристофана Византийского (директор Александрийской библиотеки, умер в 180 г. до н.э.). Во 11 в. н.э. появляется работа Юлия Поллукса «Ономастикон», составленная на материале греческого языка. Это словарь, состоящий из 10 книг. Каждая книга содержала слова, относящиеся к определенной теме.
Например, в первой – слова, относящиеся к богам и царям; в седьмой – к теме «торговля», в десятой – к теме «утварь». Слова в этом словаре сопровождались краткими толкованиями.
Между II и III в н.э. появляется санскритский словарь «Амарокоша», который содержал около 10 тыс. слов и состоял из трех книг, каждая из которых делилась на главы, главы – на секции. Так, первая книга была посвящена небу, богам и всему тому, что с ними связано. В ней имелись секции «времена года», «небесный свод» и т.п. Вторая книга содержала слова, относящиеся к земле, растительному и животному миру и человеку. Для лучшего запоминания толкования давались в стихотворной форме.
Сам термин «тезаурус» был применен впервые в ХIII в. флорентийским ученым Брунето Латини, который использовал его в заголовке своего труда – систематизированной энциклопедии, назвав ее «Книга о сокровище». Это вполне соответствовало семантике употребленного слова «Thesauros», т.е. «сокровище», «богатство», «запас».
Современный этап истории идеографических словарей открывается работой П.М.Роже «Тезаурус английских слов и выражений» (1852 г.) Его тезаурус – это глубоко структурированная система, восходящая к самым общим категориям: абстрактные отношения, пространство, материя, дух. Всю понятийную область английского языка Роже разбивает на 4 класса: абстрактные отношения, пространство, материя и дух (разум, воля, чувства).
Далее эти категории делятся на 24 класса, классы – на подклассы и т.д. Классы распадаются на категории, категории – на секции, секции – на группы. Всего у Роже 1000 понятийных групп, в каждую из которых он собирает слова, близкие по смыслу. Так, есть понятийные группы «рождение», «житель», «помещение», «удовлетворение».
Почти в то же время (1862 г.) появился «Аналогический словарь французского языка» Буасьера. Отобрав две тысячи слов французского языка, которые составляют активный словарь (слова повседневного употребления), и, взяв каждое такое слово за основу, Буасьер собирает все слова, семантически с ним связанные.
Следует подчеркнуть, что первые тезаурусы составлялись без всякой связи с особенностями информационной деятельности, они были органически связаны с фундаментальными проблемами познания, отображая представление о мире в целом и закономерностях его постижения средствами естественного языка. В дальнейшем, при проникновении идей тезауруса в автоматизированные ИПС, тезаурус стал рассматриваться как словарь для построения поисковых образов документов и запросов, качество которых существенно влияло на качество поиска информации.
2. Информационно-поисковые тезаурусы: сущность и назначение
Среди тезаурусов, понимаемых как идеографические словари, в особую группу выделяются информационно-поисковые тезаурусы (ИПТ), появление и развитие которых связано с автоматизацией информационного поиска в середине ХХ в.
ГОСТ 7.74-96 «Информационно-поисковые языки. Термины и определения» определяет ИПТ следующим образом: «Информационно-поисковый тезаурус (ИПТ) – нормативный словарь дескрипторного ИПЯ с зафиксированными в нем парадигматическими отношениями».
ИПТ не следует путать с дескрипторным словарем. ГОСТ 7.74-96 «Информационно-поисковые языки. Термины и определения» дает следующее разграничение этих понятий: «Дескрипторный словарь – словарь дескрипторного ИПЯ, в котором приведены в общем алфавитном ряду дескрипторы и их синонимы без указания других отношений лексических единиц. Дескрипторный словарь является упрощенным вариантом ИПТ, в котором зафиксированы преимущественно или только синонимические связи».
Таким образом, термин «информационно-поисковый тезаурус» используется для обозначения словаря-справочника, в котором перечислены все лексические единицы дескрипторного ИПЯ с указанием их синонимов, а также явно выражены важнейшие смысловые отношения между дескрипторами».
Следует подчеркнуть, что на практике, в инструктивно-методической литературе существует большая путаница в понятийном аппарате. Тезаурусом подчас называют любую классификацию, любой рубрикатор или даже список. Тем не менее, следует отличать ИПТ от словарей синонимов, антонимов и ассоциативных; от компьютерных словарных списков взаиморасположения терминов в документах, которые часто в литературе называют автоматизированными тезаурусами; от списков предметных заголовков и ключевых слов, если в них не выражены семантические отношения между терминами.
ИПТ – это структурированный словарь для контроля лексики, в котором явно и системно определяются основные семантические отношения (эквивалентности, иерархические и ассоциативные) между терминами естественного языка. В соответствии с ГОСТ 7.25-2001 ИПТ ориентированы, прежде всего, на использование в рамках автоматизированных информационных систем и сетей научно-технической информации.
Появление ИПТ неразрывно связано с развитием автоматизированных информационных систем (АИС). Первоначально целью создания ИПТ являлось повышение показателей качества поиска информации в АИС. В соответствии с этой целью назначение ИПТ заключалось в следующем:
1. Обеспечивать индексирование документов и запросов средствами дескрипторного языка путем замены ключевых слов соответствующими дескрипторами, а также осуществлять избыточное индексирование документов и/или информационных запросов за счет использования вышестоящих, нижестоящих и ассоциативных понятий;
2. Отражать парадигматические отношения, существующие между лексическими единицами какой-либо отрасли науки или техники.
3. Служить средством контроля и нормализации лексики конкретной отрасли знания, обеспечивать единое и формализованное представление информации в ИПС.
Кроме того, ИПТ использовались и используются при традиционном (ручном) информационном поиске как средство терминологического контроля, позволяющее на основе эксплицитного представления парадигматических отношений между дескрипторами сужать или расширять область поиска, уточнять информационные запросы пользователей, осуществлять корректировку поисковых предписаний.
3. Структура ИПТ
В соответствии с ГОСТ 7.25-2001 «Тезаурус информационно-поисковый одноязычный. Правила разработки, структура, состав и форма представления» в состав ИПТ входят следующие элементы:
1) вводная часть;
2) основная часть (лексико-семантический указатель);
3)дополнительные части (систематический, пермутационный, иерархический и другие указатели и списки специальных категорий лексических единиц).
Обязательными составными частями являются вводная часть и лексико-семантический указатель.
Допускается в состав ИПТ вводить приложения, содержащие дополнительные сведения о разработке и использовании ИПТ.
Вводная часть включает титульный лист и введение.
На титульном листе должны быть приведены:
— наименование ИПТ, включающее термин «информационно-поисковый тезаурус» и указывающее область его применения;
— наименование организации-разработчика и дополнительные сведения об авторстве ИПТ;
— сведения о переиздании;
— место и год создания или издания ИПТ.
— цель создания и область применения тезауруса, описанные кодами
и наименованиями рубрик Межгосударственного рубрикатора НТИ;
— ссылки на источники, использованные для сбора лексики ИПТ;
— ссылки на нормативные и методические документы, использованные при составлении ИПТ;
— описание порядка составления тезауруса, включая обоснование
представительности использованных источников лексики;
— описание состава и структуры;
— перечень отношений между лексическими единицами и методические основания для их установления;
— перечень всех символов и специальных сокращений, допущенных
— порядок алфавитного расположения (расположение букв разных
алфавитов, небуквенных символов и др.);
— количественные характеристики тезауруса (общее число статей, число дескрипторов, аскрипторов и др.);
— описание состава и формы представления дополнительных данных в словарных статьях;
— абзац следующего содержания: «Тезаурус подготовлен в соответствии с ГОСТ 7.25».
Введение к последующим изданиям (версиям) ИПТ дополнительно должно содержать:
— обоснование необходимости составления новой версии тезауруса;
— указание на характер внесенных изменений.
Лексико-семантический указатель – это упорядоченная последовательностью словарных статей ИПТ, сформированная я путем расположения их в алфавитном порядке заглавных лексических единиц. Представляет собой алфавитный перечень всех дескрипторов и аскрипторов с их словарными статьями.
Приведем фрагмент лексико-семантического указателя из ИПТ по швейной промышленности:
Источник: pandia.ru
Назначение, структура и использование информационно-поисковых тезаурусов
Для уменьшения количества терминов в ПО вводят ИПТ (тезаурус — синоним), в котором отражаются устойчивые связи между понятиями данной предметной области.
Тезаурус – семантическая сеть, в которой понятия связаны регулярными и устойчивыми семантическими отношениями: иерархическими (например целое-часть, имеет место нарушение правильной структуры дерева), ассоциативными, эквивалентности. Тезаурус является лексическим инструментом ИПС для осуществления поиска.
Информационно-поисковые тезаурусы.(ИПТ) позволяют решить проблему соотнесения:
• авторской терминологии (понятий и слов естественного языка, которые автор использует для обозначения этих понятий);
• терминологии системы (понятий и терминов, которые используются для выражения этих понятий при вводе документов в ИПС);
• терминологии потребителя (понятий и терминов, которые потребитель использует для представления этих понятии при формировании запросов).
Тезаурус состоит из контролируемого, но изменяемого словаря терминов, между которыми указаны смысловые связи, представляет собой перечень лексических единиц, упорядоченных по систематическому и алфавитному принципам. Лексические единицы обычно делятся на дескрипторы и аскрипторы.
Дескриптор— лексическая единица, предназначенная для использования в поисковых образах документов и/или запросов. Аскриптор — лексическая единица, которая в поисковых образах документов (запросов) при поиске или обработке информации подлежит замене на дескриптор. ИПТ подразделяют на два типа:
• тезаурусы, выделяющие среди своих лексических единиц дескрипторы и аскрипторы;
• тезаурусы, все лексические единицы которых являются дескрипторами.
Лексические единицы тезауруса поделены на дескрипторы (выделены прописными буквами) и ключевые слова— не дескрипторы (строчными буквами) и нормализованы следующим образом:
• имена существительные, обозначающие исчисляемые объекты, представлены в форме именительного падежа множественного числа;

• существительные, обозначающие неисчисляемые объекты, представлены в форме именительного падежа единственного числа;
• для всех словосочетаний-дескрипторов, включая словосочетания с именем собственным, используется естественный (прямой) порядок слов.
Лексические единицы в тезаурусе организованы в виде словарных статей. Словарная статья дескриптора состоит из собственно дескриптора (заглавного дескриптора) и списка дескрипторов и ключевых слов, связанных с заглавным дескриптором по смыслу.
Общеупотребительные аббревиатуры входят в тезаурус в качестве дескрипторов. Каждая из них снабжена расшифровкой, которая приводится в косых скобках строчными буквами.
В дескрипторной статье лексические единицы располагаются в следующем порядке:
• ключевые слова, условно синонимичные заглавному дескриптору (с);
• вышестоящие дескрипторы(в) (включают в себя заглавный);
• нижестоящие дескрипторы(н) (наоборот);
• дескрипторы, связанные с заглавным дескриптором одним из ассоциативных отношений(а).
Понравилась статья? Добавь ее в закладку (CTRL+D) и не забудь поделиться с друзьями:
Источник: studopedia.ru
Что такое тезаурус и как определить семантическое сходство слов
При разработке чат-ботов и голосовых ассистентов часто возникает задача нахождения семантического сходства слов. Причина тому – наличие в языке большого количества схожих по смыслу слов и выражений. Так, пользователь может задать один и тот же вопрос как минимум двумя способами:
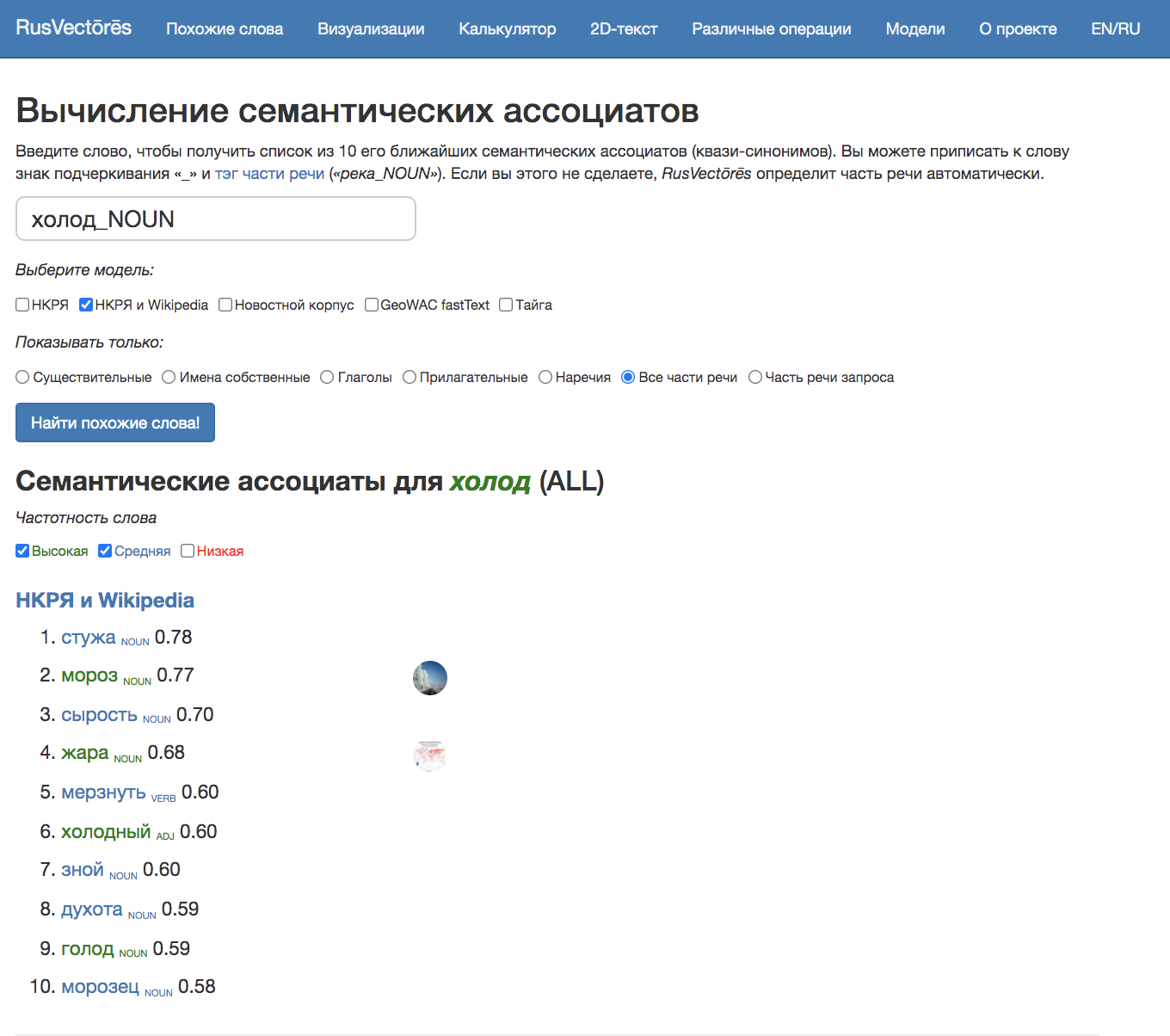
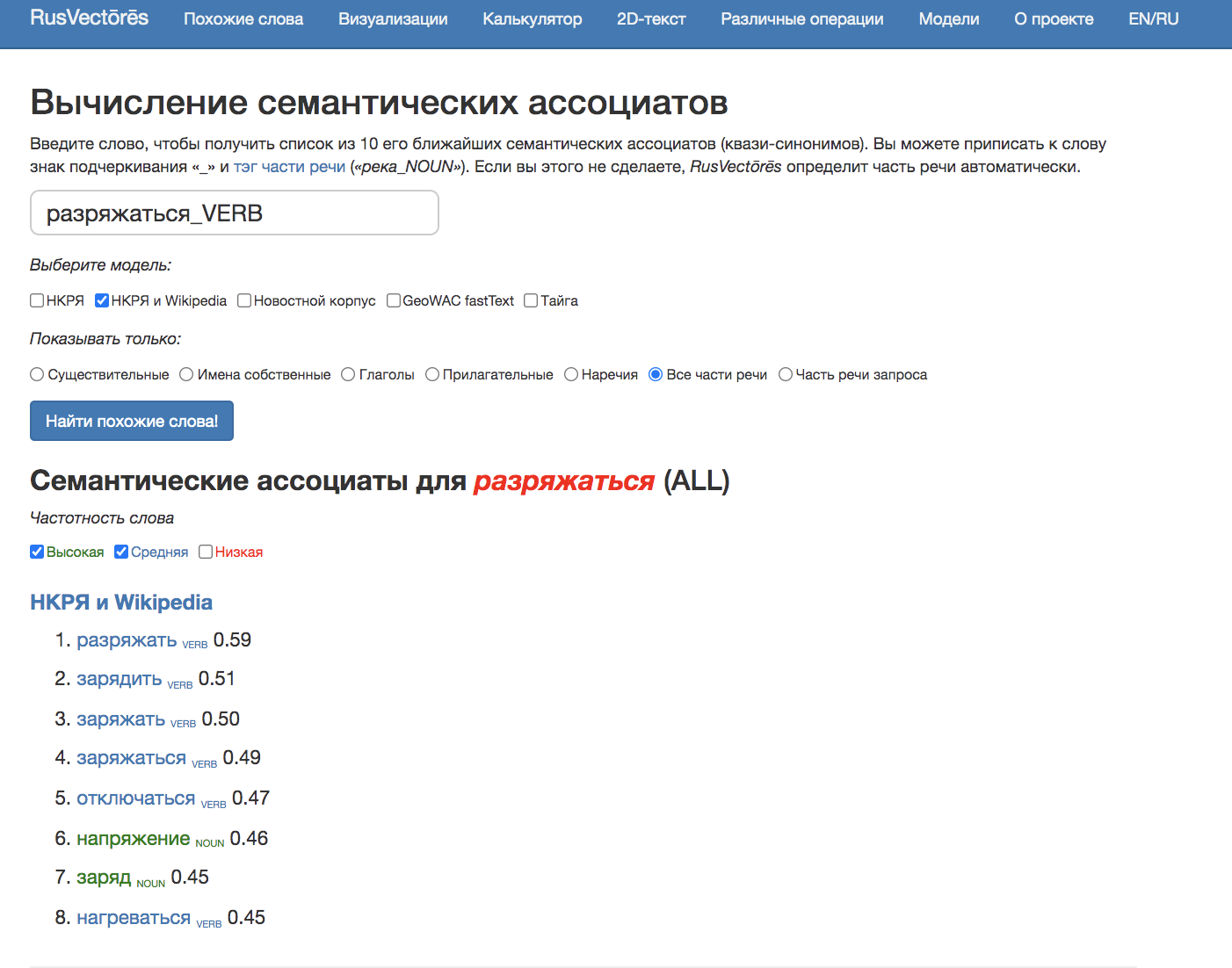
- Почему электрические батареи быстрее разряжаются на холоде?
- Из-за чего батарейки быстрее садятся на морозе?
Для человека не составит труда понять, что предложения имеют схожий смысл, несмотря на различие в лексике. Мы знаем, что слова электрические батареи и батарейки, разряжаются и садятся, холод и мороз – синонимы, они имеют практически одинаковое значение и могут быть взаимозаменяемы.

Но как компьютеру понять, что под разными словами подразумевается одно и то же? Решение этой задачи состоит в вычислении меры семантического сходства слов: для синонимов она близка к единице, для совершенно непохожих слов – к нулю.
Дистрибутивные модели
Сейчас подавляющее большинство решений основано на моделях дистрибутивной семантики. Идея в следующем: если слова встречаются в похожих контекстах, то они имеют похожие значения. Для этого метода не требуются предварительно подготовленные данные, вся семантическая информация извлекается из неструктурированных текстов на основе совместной встречаемости слов.
Однако вот в чем проблема: подобный подход не учитывает, что отношения между словами из одной семантической области могут иметь различный характер. В качестве «синонимов», то есть близких по смыслу слов, будут определены как синонимы в традиционном понимании, так и противоположные по смыслу слова, хоть и относящиеся к той же семантической области, которые со школы мы привыкли называть антонимами: например, жара для слова холод и заряжаться для слова разряжаться.
Словари с иерархической структурой
Решением проблемы мог бы стать лингвистический ресурс, содержащий: а) большое количество слов и словосочетаний, б) семантические отношения между ними.
Нам повезло, и такие ресурсы придуманы уже давно – они имеют названия тезаурусов. Первый тезаурус (конечно, в бумажном виде) был создан в 1805 году. Наиболее современная и полная лексическая база знаний разработана Принстонским университетом под названием WordNet. Эти тезаурусы включают слова и словосочетания английского языка. Существует также тезаурус для русского языка – RuWordNet.
В тезаурусе между словами установлена иерархическая структура: выделены наиболее общие понятия (гиперонимы) и наиболее частные (гипонимы), а также похожие по смыслу слова (синонимы). Например, для слова собака гиперонимами являются слова млекопитающее и домашнее животное, гипонимами – конкретные породы собак, как бульдог, пудель, лабрадор и другие.

Иерархическая структура тезауруса позволяет рассчитывать семантическое сходство между словами. Для этого существуют различные метрики, некоторые из них имеют программную реализацию на основе тезауруса WordNet для английского языка. На примере данного ресурса мы рассмотрим методы нахождения семантического сходства слов по тезаурусу и приведем примеры подсчета метрик с помощью пакета WordNet библиотеки NLTK.
Тезаурус WordNet для английского языка
Доступ к тезаурусу WordNet возможен из библиотеки NLTK на Python, для этого необходимо импортировать соответствующий пакет:
from nltk.corpus import wordnet as wn
В тезаурусе слова представлены в виде так называемых синсетов: это объединение слов с похожими понятиями, их лексические значения вместе формируют лексическое значение самого слова. К примеру, синсет слова hand tool ‘ручной инструмент’ состоит из одного понятия.
wn.synsets(‘hand_tool’)
Синсет слова hammer ‘молоток’ включает нескольких синонимичных понятий, где malleus переводится как ‘молоточек’, слуховая косточка среднего уха, mallet обозначает ‘молоток для игры в крокет’, а forge имеет значение ‘кузница’.
wn.synsets(‘hammer’)
[Synset(‘hammer.n.01’), Synset(‘hammer.n.02’), Synset(‘malleus.n.01’), Synset(‘mallet.n.02’), Synset(‘hammer.n.05’), Synset(‘hammer.n.06’), Synset(‘hammer.n.07’), Synset(‘hammer.n.08’), Synset(‘hammer.v.01’), Synset(‘forge.v.01’)]
Как мы упоминали ранее, тезаурус имеет иерархическую структуру. Следовательно, для каждого слова можно узнать как более общие понятия – гиперонимы, так и более конкретные понятия – гипонимы. Так, слово hand tool ‘ручной инструмент’ имеет только один гипероним – tool ‘инструмент’ и много гипонимов, среди которых уже знакомый hammer ‘молоток’ с индексом «02», а также awl ‘шило’, saw ‘пила’, wrench ‘гаечный ключ’ и другие названия ручных инструментов:
hand_tool = wn.synset(‘hand_tool.n.01’) print(hand_tool.hypernyms()) print(hand_tool.hyponyms())
[Synset(‘awl.n.01’), Synset(‘bevel.n.02’), Synset(‘bodkin.n.03’), Synset(‘bodkin.n.04’), Synset(‘crank.n.04’), Synset(‘dibble.n.01’), Synset(‘file.n.04’), Synset(‘float.n.05’), Synset(‘graver.n.01’), Synset(‘gutter.n.04’), Synset(‘hammer.n.02’), Synset(‘hand_shovel.n.01’), Synset(‘marlinespike.n.01’), Synset(‘miter_box.n.01’), Synset(‘opener.n.03’), Synset(‘pallet.n.03’), Synset(‘pestle.n.03’), Synset(‘pick.n.06’), Synset(‘pincer.n.01’), Synset(‘pipe_cutter.n.01’), Synset(‘pitchfork.n.01’), Synset(‘plane.n.05’), Synset(‘pliers.n.01’), Synset(‘plumber’s_snake.n.01’), Synset(‘plunger.n.03’), Synset(‘ravehook.n.01’), Synset(‘sandblaster.n.01’), Synset(‘saw.n.02’), Synset(‘scraper.n.01’), Synset(‘screwdriver.n.01’), Synset(‘shovel.n.01’), Synset(‘soldering_iron.n.01’), Synset(‘spatula.n.02’), Synset(‘spreader.n.01’), Synset(‘square.n.08’), Synset(‘straightedge.n.01’), Synset(‘tire_iron.n.01’), Synset(‘trowel.n.01’), Synset(‘weeder.n.02’), Synset(‘wire_stripper.n.01’), Synset(‘wrench.n.03’)]
Несложно догадаться, что гиперонимом для слова hammer ‘молоток’ с индексом «02» будет понятие hand tool ‘ручной инструмент’, а гипонимами – различные виды молотков, как ball-peen hammer ‘шариковый молоток’, maul ‘кувалда’ и другие:
hammer = wn.synset(‘hammer.n.02’) print(hammer.hypernyms()) print(hammer.hyponyms())
[Synset(‘ball-peen_hammer.n.01’), Synset(‘bricklayer’s_hammer.n.01’), Synset(‘carpenter’s_hammer.n.01’), Synset(‘mallet.n.03’), Synset(‘maul.n.01’), Synset(‘plexor.n.01’), Synset(‘tack_hammer.n.01’)]
Интересно, что понятие power tool ‘электрический инструмент’ имеет два гиперонима: это не только слово tool ‘инструмент’, но и слово machine ‘механизм’. Гипонимами этого понятия также являются названия конкретных инструментов: buffer ‘амортизатор’, power drill ‘дрель’, power saw ‘электропила’, а также снова hammer, только уже в значении ‘электромолоток’, о чем говорит изменившийся индекс «07»:
power_tool = wn.synset(‘power_tool.n.01’) print(power_tool.hypernyms()) print(power_tool.hyponyms())
[Synset(‘buffer.n.05’), Synset(‘burr.n.04’), Synset(‘drum_sander.n.01’), Synset(‘hammer.n.07’), Synset(‘plane.n.04’), Synset(‘power_drill.n.01’), Synset(‘power_saw.n.01’), Synset(‘router.n.03’), Synset(‘stamping_machine.n.01’)]
Иерархическая структура тезауруса позволяет довольно точно рассчитывать семантическое сходство между понятиями с помощью специальных мер, которые мы рассмотрим в следующем разделе.
Меры семантического сходства по тезаурусу
Попробуем рассчитать семантическое сходство между парами слов, обозначающими различные строительные инструменты: hand tool ‘ручной инструмент’ и power tool ‘электрический инструмент’, hammer ‘молоток’ и saw ‘пила’. Для наглядности представим их иерархическое расположение в тезаурусе в виде графической схемы:
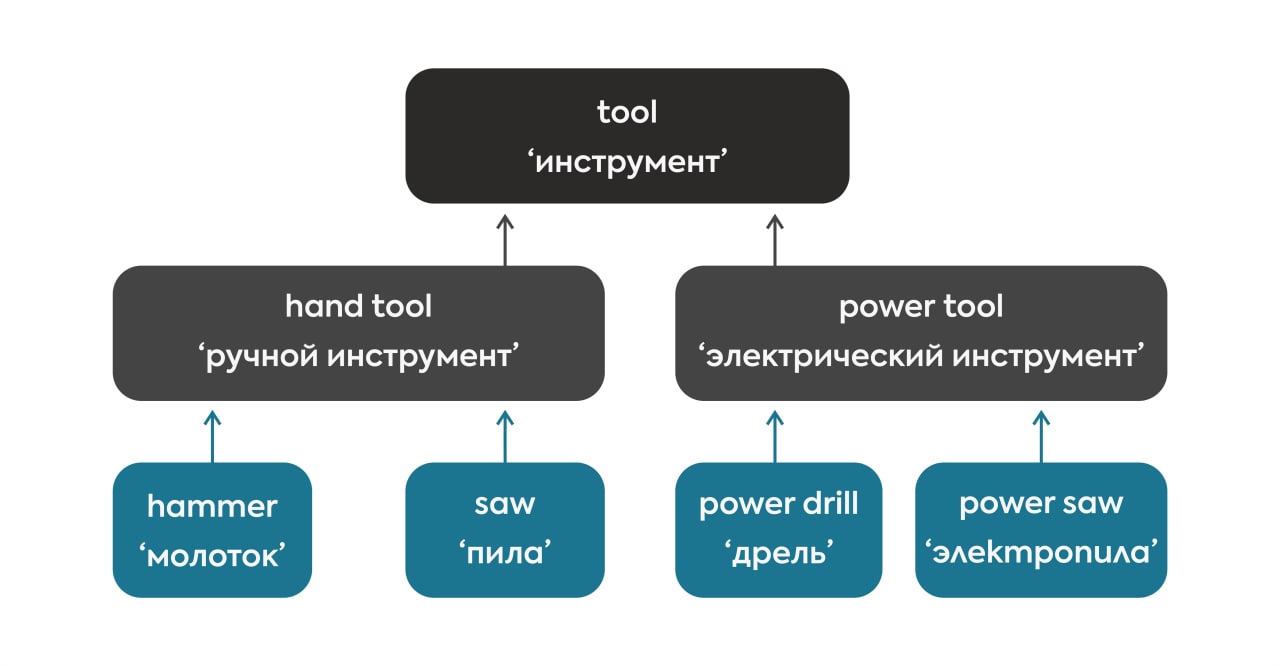
Можно выделить два метода подсчета семантической схожести.
Первая мера сходства основана на длине пути между парой понятий. Интуитивно кажется правильным подсчитывать расстояние между узлами в иерархии для вычисления меры семантической схожести. Данная мера имеет название PATH (с английского ‘путь’) и учитывает длину кратчайшего пути между двумя понятиями А и В (shortest path (А,В)). Отметим, что при подсчете учитываются именно узлы, а не переходы между узлами:
Рассчитаем меру сходства PATH между парами слов hand tool ‘ручной инструмент’ и power tool ‘электрический инструмент’, hammer ‘молоток’ и saw ‘пила’. Кратчайший путь между понятиями для обоих пар равен 3. Автоматический подсчет меры PATH показывает, что семантическое сходство между словами является одинаковым:
hand_tool.path_similarity(power_tool)
hammer.path_similarity(saw)
При подсчете этой меры предполагается, что все расстояния между узлами имеют одинаковый вес. Однако это не совсем так — понятия, лежащие ниже в иерархии, являются более специфичными, и семантическое расстояние между такими понятиями кажется меньшим, нежели расстояние между более общими понятиями.
Поэтому эффективно использовать не только расстояние между узлами, но и глубину узлов в иерархи: PATH + DEPTH (с английского ‘глубина’). Под глубиной подразумевается длина кратчайшего пути между целевым понятием А и корневым понятием.
Данная мера имеет название WUP по фамилиям исследователей Z. Wu и M. Palmer, предложивших использовать ее в статье 1994 года. Она учитывает глубину наименее общего родового понятия, то есть ближайшего понятия, которое является общим для обоих целевых слов (Least Common Subsumer, сокращенно LCS):
Подсчитаем семантическое сходство по мере WUP между уже известными парами слов. Результат показывает, что для слов hammer ‘молоток’ и saw ‘пила’ значение меры сходства оказывается выше, чем для пары hand tool ‘ручной инструмент’ и power tool ‘электрический инструмент’:
hand_tool.wup_similarity(power_tool)
hammer.wup_similarity(saw)
Это соответствует нашим интуитивным ожиданиям: конкретные понятия, как названия типов ручных инструментов, кажутся семантически более близкими, чем общие понятия, как названия групп инструментов. Таким образом, мера семантического сходства, учитывающая не только расстояние между узлами, но и глубину вложения, является более показательной и надежной.
Некоторые итоги
В статье мы рассмотрели меры нахождения семантического сходства по тезаурусу. Дистрибутивные методы, так распространенные сейчас, показывают высокое качество в задачах понимания текста, но обладают важным недостатком: они не учитывают семантические отношения между словами, такие как синонимия, антонимия, отношения гипоним-гипероним. Эту проблему решают словари с иерархической структурой – тезаурусы. Мы познакомились с устройством тезауруса WordNet для английского языка и рассчитали семантическое сходство между понятиями с помощью библиотеки NLTK. Оказалось, что более достоверные результаты показывают меры, которые учитывают не только на расстояние между узлами (PATH), но и глубину узлов в иерархии (DEPTH).
В заключение добавим, что семантическое сходство слов по тезаурусу может использоваться во многих задачах понимания текста, среди которых построение вопросно-ответных систем, разрешение неоднозначности слов, нахождении сходства между предложениями, расширение поискового запроса и нахождение связей между частями текста.
- Блог компании Unistar Digital | Юнистар Диджитал
- Python
- Семантика
- Natural Language Processing
- Голосовые интерфейсы
Источник: habr.com