
Вопрос: Как мне найти свой Android UUID?
ANDROID_ID — предпочтительный идентификатор устройства. ANDROID_ID идеально подходит для версий Android = 2.3. … Когда у устройства есть несколько пользователей (доступно на определенных устройствах под управлением Android 4.2 или выше), каждый пользователь отображается как полностью отдельное устройство, поэтому значение ANDROID_ID уникально для каждого пользователя.
Что такое UUID в мобильном приложении?
Класс, представляющий неизменный универсальный уникальный идентификатор (UUID). UUID представляет собой 128-битное значение. Существуют разные варианты этих глобальных идентификаторов. … Существует четыре различных основных типа UUID: основанные на времени, безопасности DCE, основанные на имени и случайно сгенерированные UUID.
Как мне найти свой мобильный ID номер?
Перейдите в «Настройки»> «О телефоне». Ваш идентификатор телефона (IMEI) должен быть одним из первых, что вы увидите. Как и в случае с недавно приобретенным iPhone, вы можете найти его на задней стороне коробки вашего телефона.
14 — Уникальные Идентификаторы UUID — Уроки PostgreSQL
Что такое идентификационный номер Android?
Android ID — это уникальный идентификатор для каждого устройства. Он используется для идентификации вашего устройства для рыночных загрузок, определенных игровых приложений, которые должны идентифицировать ваше устройство (чтобы они знали, что это устройство использовалось для оплаты приложения) и т. Д.
Как мне найти свой UUID на моем телефоне?
Есть несколько способов узнать свой идентификатор устройства Android,
- Введите * # * # 8255 # * # * в номеронабирателе вашего телефона, вам будет показан идентификатор вашего устройства (как «помощь») в GTalk Service Monitor. …
- Другой способ узнать идентификатор — перейти в Меню> Настройки> О телефоне> Статус.
Как мне узнать имя моего устройства Android?
Самый простой способ узнать название и номер модели вашего телефона — это использовать сам телефон. Перейдите в меню «Настройки» или «Параметры», прокрутите список до конца и отметьте «О телефоне», «Об устройстве» или аналогичные. Должны быть указаны название устройства и номер модели.
Что такое пример UUID?
Формат. В каноническом текстовом представлении 16 октетов UUID представлены в виде 32 шестнадцатеричных (base-16) цифр, отображаемых в пяти группах, разделенных дефисами, в форме 8-4-4-4-12, всего 36 символов. (32 шестнадцатеричных символа и 4 дефиса). Например: 123e4567-e89b-12d3-a456-426614174000.
Как мне найти свой UUID?
Вы можете найти UUID всех разделов диска в вашей системе Linux с помощью команды blkid. Команда blkid доступна по умолчанию в большинстве современных дистрибутивов Linux. Как видите, отображаются файловые системы с UUID.
Как мне получить UUID?
Процедура создания UUID версии 4 следующая:
- Сгенерировать 16 случайных байтов (= 128 бит)
- Отрегулируйте определенные биты в соответствии с разделом 4122 RFC 4.4 следующим образом:…
- Закодируйте скорректированные байты как 32 шестнадцатеричные цифры.
- Добавьте четыре символа дефиса «-», чтобы получить блоки из 8, 4, 4, 4 и 12 шестнадцатеричных цифр.
Как мне узнать уникальный идентификатор своего телефона Android?
TelephonyManager telephonyManager; telephonyManager = (TelephonyManager) getSystemService (Context. * GetDeviceId () возвращает уникальный идентификатор устройства. * Например, IMEI для GSM и MEID или ESN для телефонов CDMA.
Роман Букин «Uuid — большая история маленькой структуры»
Какой минимальный номер на моем телефоне Android?
Мобильный идентификационный номер (MIN) или идентификационный номер мобильной подписки (MSIN) относится к 10-значному уникальному номеру, который оператор беспроводной связи использует для идентификации мобильного телефона, который является последней частью международного идентификатора мобильного абонента (IMSI). … MIN используется для идентификации мобильной станции.
Как мне найти информацию об устройстве Android?
Как получить информацию об устройстве в Android
Что такое идентификационный номер устройства?
На Android идентификатором устройства является GPS ADID (или идентификатор сервисов Google Play для Android). Пользователь может получить доступ к своему GPS ADID в меню настроек в разделе «Google — Реклама», а также сбросить идентификатор и отказаться от персонализации рекламы.
Как узнать идентификатор моего устройства Android 10?
getInstance (). getId (); . В соответствии с последней версией Android 10, ограничение на не сбрасываемые идентификаторы устройств. pps должен иметь привилегированное разрешение READ_PRIVILEGED_PHONE_STATE для доступа к не сбрасываемым идентификаторам устройства, которые включают как IMEI, так и серийный номер.
Идентификатор устройства и IMEI совпадают?
getDeviceId () API. Телефоны CDMA имеют ESN или MEID, которые имеют разную длину и форматы, даже если они извлекаются с использованием одного и того же API. Устройства Android без модулей телефонии — например, многие планшеты и телевизоры — не имеют IMEI.
Источник: frameboxxindore.com
Что такое UUID в отчете СЗВ-ТД
С 2020 года в ПФР подается отчетность по форме СЗВ-ТД на каждого сотрудника, в отношении которого зафиксировано какое-либо кадровое событие. Электронный формат отчета предполагает обязательное проставление UUID мероприятия в СЗВ-ТД. Разъясним, что это такое и для чего требуется.
Что такое UUID в отчете СЗВ-ТД и как он присваивается
Формат сведений, иначе говоря, порядок отражения данных в формируемом электронном файле, закреплен в Приложении № 3 к Постановлению ПФР от 25.12.2019 № 730п. О том, что для СЗВ-ТД UUID является необходимым атрибутом при записи кадрового события, упоминается в таблице 6 приложения (позиция 1.1 таблицы).
Используемое значение также контролируется при проверке файла на соответствие требованиям ПФР. В таблице 14 приложения № 3 в списке проверок указывается, что повторы UUID в пределах формы недопустимы. Если обнаружится несоответствие, ошибке присваивается код «30» (ЭТК.СЗВ-ТД.1.16). В отчет в этом случае потребуется вносить исправления.
Фактически UUID (Universally Unique Identifier) – это уникальный код, который присваивается программой каждому кадровому блоку при создании и отправке отчета в электронном виде.
Кадровых мероприятий в одной форме у сотрудника может быть несколько (к примеру, перевод и увольнение), при этом каждому событию автоматически будет присвоен собственный многозначный шифр, состоящий из букв и цифр. В примере из разъяснений ПФР по формату сведений код выглядит так: 1b9f753e-8a76-4016-ae9c-b5b3f5654548. Значение генерируется случайным образом.
Идентификатор UUID в СЗВ-ТД: для чего нужен
Идентификатор UUID в отчете СЗВ-ТД указывается при уточнении, отмене ранее поданных сведений в электронном формате. В документе необходимо проставить код события, нуждающегося в исправлении.
Присвоенный код позволит идентифицировать нужную запись при поиске данных, к примеру, при корректировке или отмене ранее поданных сведений. Указания в электронном отчете только персональных данных при подаче уточняющей формы на сотрудника недостаточно, так как кадровых событий по человеку в общей информационной базе ПФР может быть записано очень много. По шифру система быстрее найдет необходимую запись, нуждающуюся в корректировке.
Также программа ссылается на UUID, если мероприятие, указанное в форме, «задваивается» — то есть, когда работодатель повторно указывает в СЗВ-ТД кадровое событие, уже имеющееся в базе ПФР.
Где найти код события
Не все программы позволяют выбрать нужный код автоматически, поэтому возникает необходимость его поиска вручную. Где можно найти нужный шифр:
- в файле выгрузки (это основной вариант для определения кода);
- в отправленном ранее электронном отчете;
- в регистре программы, где был создан документ для автоматической отправки (например, в ЗУП «Мероприятия трудовой деятельности переданные»).
Искомый код копируется и вставляется в соответствующую строку.
Для документов, поданных ранее на бумажных носителях, или для полностью удаленных пользователями отчетов идентификатор самостоятельно не найдется, потребуется обращение к сторонним специалистам — из ПФР или из организации, осуществившей передачу данных через интернет.
В самой форме данный код не отображается.
Таким образом, любому кадровому событию в СЗВ-ТД будет присвоен идентификатор UUID. При исправлении сведений в электронном виде в корректирующей форме указывается код из первичного отчета.
Полный путеводитель по кадровым вопросам и по электронной трудовой книжке вы можете посмотреть бесплатно в системе КонсультантПлюс.
Более полную информацию по теме вы можете найти в КонсультантПлюс.
Пробный бесплатный доступ к системе на 2 дня.
Источник: spmag.ru
Русские Блоги
UUID — это аббревиатура универсального уникального идентификатора, который представляет собой уникальный идентификатор, сгенерированный машиной в определенном диапазоне (от определенного пространства имен до мира). UUID имеет следующие значения:
- Генерируется определенной машиной алгоритма
Чтобы гарантировать уникальность UUID, спецификация определяет элементы, включая MAC-адрес сетевой карты, временную метку, пространство имен (Namespace), случайное или псевдослучайное число, время и другие элементы, а также алгоритм для генерации UUID из этих элементов. Сложные характеристики UUID означают, что он может быть сгенерирован только компьютером, обеспечивая его уникальность.
- Обозначение без ручного управления, идентификация без ручного управления
UUID нельзя указать вручную, если вы не рискуете дублировать UUID. Сложность UUID определяет, что «нормальные люди» не могут напрямую знать, какой объект связан с UUID.
- Возможность повторения в определенном диапазоне крайне мала.
Основная цель алгоритма, определенного спецификацией генерации UUID, — обеспечить его уникальность. Но эта уникальность ограничена и может быть гарантирована только в пределах определенного диапазона, который связан с типом UUID (см. Версию UUID).
UUID — это 16-байтовое 128-битное число, обычно представленное 36-байтовой строкой. Примеры:
Буквы в нем в шестнадцатеричной системе счисления, независимо от регистра.
Универсальный уникальный идентификатор (UUID) сВосемь классиковизRFC спецификация, Является 128-битным числом, также может быть выражено 32 шестнадцатеричными символами, разделенными знаком «-» посередине.
-Timestamp + номер версии UUID, разделенный на три сегмента, занимающих 16 символов (60 бит + 4 бит),
— Порядковый номер часов и зарезервированное поле, занимающее 4 символа (13 бит + 3 бит),
— идентификатор узла занимает 12 символов (48 бит),
GUID (глобальный уникальный идентификатор) — это псевдоним UUID; но в практических приложениях GUID обычно относится к UUID, реализованному Microsoft.
UUID имеет несколько версий, и каждая версия имеет разные алгоритмы и разные диапазоны приложений.
Во-первых, это особый случай — Nil UUID — обычно мы его не используем, он состоит из всех 0 чисел, как показано ниже:
UUID, версия 1: UUID на основе времени
Поскольку метка времени имеет полные 60 бит, вы можете потратить ее столько, сколько захотите, со 100 наносекундами как 1, считая с 15 октября 1582 года (может длиться 3655 лет, действительно сжечь больше цифр, 1582 интересно)
Идентификатор узла также имеет 48 битов, обычно выражаемых MAC-адресом, если есть несколько сетевых карт, просто используйте одну. Если у вас нет сетевой карты, используйте случайные числа, чтобы составить числа, или возьмите кучу другой информации, например имена хостов, и хешируйте их вместе.
16-битный порядковый номер используется только во избежание предыдущего изменения метки узла (например, смены сетевой карты), проблем с системой часов (например, замедления часов после перезапуска), пусть он будет случайным, чтобы избежать дублирования.
Но похоже, что в версии 1 не учитывалась ни проблема двух процессов на одной машине, ни параллелизм одной и той же временной метки, поэтому строгая версия 1 не была реализована, поэтому давайте рассмотрим каждый вариант.
Спящий режимCustomVersionOneStrategy.java, Что решает две проблемы версии 1 до
-Timestamp (6 байтов, 48 бит): уровень миллисекунд, начиная с 1970 года, может длиться 8925 лет .
-Последовательный номер (2 байта, 16 бит, максимум 65535): не существует такой вещи, как отметка времени, которая возвращается к нулю через одну секунду. У каждого свой путь. Когда короткое переполнение достигает отрицательного числа, оно возвращается к нулю.
-Идентификатор машины (4 байта, 32 бита): возьмите IP-адрес localHost, IPV4 составляет ровно 4 байта, но если это IPV6, 16 байтов, берутся только первые 4 байта.
— Идентификатор процесса (4 байта, 32 бита): используйте текущую временную метку, чтобы переместить 8 бит вправо, а затем используйте целое число, чтобы справиться с этим. Я не верю, что два потока будут запускаться одновременно.
Стоит отметить, что 64-битный Long, состоящий из машинного процесса и идентификатора процесса, почти не изменился, и достаточно другого Long.
Вариант версии 1-MongoDB
-Timestamp (4 байта, 32 бита): находится на втором уровне и может длиться 136 лет с 1970 года.
-Последовательность инкремента (3 байта 24 бита, максимум 16 миллионов): это Int, который начинается со случайного числа (свидетель) и непрерывно увеличивается на единицу, и не существует такой вещи, как отметка времени, которая вернется к нулю через одну секунду. . Поскольку имеется только 3 байта, 4 байта Int необходимо усечь на 3 байта.
-Machine ID (3 байта 24 бит): соедините Mac-адреса всех сетевых карт вместе, чтобы получить HashCode, и тот же int должен быть усечен, а затем 3 байта. Если вы не можете получить сетевую карту, используйте случайное число, чтобы смешать ее.
-Process ID (2 байта 16 бит): получить номер процесса из JMX. Если вы его не получили, используйте хэш или случайное число имени процесса, чтобы смешать его.
Видно, что дизайн каждого поля MongoDB немного разумнее, чем Hibernate, например, временная метка находится на втором уровне. Общая длина также была уменьшена до 12 байтов 96 бит, но если вы используете 64 бит Long для сохраненияНе могу встать, Может быть выражено только как массив байтов или шестнадцатеричная строка.
Вдобавок, похоже, есть ошибка в последовательности автоматического увеличения для Java-версии драйвера.
Диспетчер снежинок Twitter
Snowflake также является диспетчером, сервисом на основе Thrift, но вместо простого самоприращения с помощью redis он похож на UUID версии 1.
Есть только одна длинная 64-битная длина, поэтомуIdWorkerРаспределены по:
-Timestamp (42bit) Количество миллисекунд с 2012 года (по сравнению с 1970 годом) может длиться 139 лет.
— последовательность автоинкремента (12 бит, максимум 4096), автоинкремент в миллисекундах и сброс на 0 через одну миллисекунду.
-DataCenter ID (5 бит, максимум 32), значение конфигурации.
— ID рабочего (5 бит, максимум 32), значение конфигурации. Поскольку это идентификатор диспетчера, достаточно 32 диспетчеров в центре обработки данных. Зарегистрируйтесь в ZK.
Можно видеть, что, поскольку это диспетчер чисел, идентификатор машины и идентификатор процесса опускаются, поэтому он может быть выражен только одним Long.
Кроме того, для диспетчера этого типа клиент может иметь только один идентификатор за раз и не может быть получен пакетами, поэтому дополнительная задержка является проблемой.
UUID версии 2: защищенный UUID DCE
Безопасный UUID DCE (распределенной вычислительной среды) и алгоритм UUID на основе времени одинаковы, но первые 4 позиции временной метки будут заменены на POSIX UID или GID. Эта версия UUID редко используется на практике.
UUID версии 3: UUID на основе имени (MD5)
UUID на основе имени получается путем вычисления хеш-значения MD5 имени и пространства имен. Эта версия UUID гарантирует: уникальность UUID, сгенерированных разными именами в одном пространстве имен; уникальность UUID в разных пространствах имен; повторное создание UUID с одним и тем же именем в одном пространстве имен одинаково.
UUID версии 4: случайный UUID
Сгенерировать UUID на основе случайного числа или псевдослучайного числа. Вероятность повторения этого UUID можно рассчитать, но случайные вещи похожи на покупку лотерейного билета: вы не можете рассчитывать на то, что он принесет вам целое состояние, но дерьмовая удача обычно приходит случайно.
UUID версии 5: UUID на основе имени (SHA1)
похож на алгоритм UUID версии 3, за исключением того, что при вычислении значения хеш-функции используется алгоритм SHA1 (алгоритм безопасного хеширования 1).
Из различных версий UUID видно, что версия 1/2 подходит для использования в распределенной вычислительной среде и имеет высокую степень уникальности; версия 3/5 подходит для уникальных имен в определенном диапазоне. И в средах, где UUID требуются или могут генерироваться повторно; что касается версии 4, я лично рекомендую не использовать ее (хотя это самый простой и удобный вариант).
Обычно мы рекомендуем использовать UUID для идентификации объектов или постоянных данных, но лучше не использовать UUID в следующих ситуациях:
- Объект типа отображения. Например, кодовая таблица только с кодами и названиями.
- Обслуживаемые вручную несистемные объекты. Например, некоторые основные данные в системе.
Для объектов с естественными характеристиками неповторяющихся имен лучше всего использовать UUID версии 3/5. Например, пользователи в системе. Если UUID пользователя версии 1, если вы случайно удалите его, а затем перестроите пользователя, вы обнаружите, что этот человек по-прежнему является этим человеком, а пользователь больше не является этим пользователем. (Хотя отметка как удаленная также является решением, это усложняет реализацию.)
- Java UUID Generator (JUG): генератор UUID с открытым исходным кодом, протокол LGPL, поддержка MAC-адресов.
- UUID: Специальная лицензия с исходным кодом.
- Встроенный генератор UUID в Java 5 и выше: кажется, что можно сгенерировать только UUID версии 3/4.
Кроме того, в Hibernate есть также генератор UUID, но это не UUID какой-либо (стандартной) версии, и это настоятельно не рекомендуется.
Метод генерации
Собраны некоторые методы генерации UUID, организованные следующим образом
Shell
- В большинстве сред Unix / Linux есть небольшой инструмент под названием uuidgen, который может генерировать UUID для стандартного вывода, запустив
- Прочитать файл /proc/sys/kernel/random/uuid Получите UUID, например:
cat /proc/sys/kernel/random/uuid
libuuid
libuuid — это библиотека C, используемая для генерации UUID, конкретной ссылки на использованиеhttp://linux.die.net/man/3/libuuid, Пример следующий:
Необходимо связать библиотеку uuid при компиляции под Linux
gcc -o uuid uuid.c -luuid
В Ubuntu libuuid можно установить с помощью следующей команды:
sudo apt-get install uuid-dev
boost uuid
Библиотека BoostЭто переносимая библиотека C ++ с открытым исходным кодом, которая обеспечивает реализацию UUID.
Следующий код может генерировать UUID
Qt QUuid
Qt — этоКроссплатформенностьВ среде программирования C ++ класс QUuid реализует такие функции, как генерация, сравнение и преобразование UUID.
функция QUuid createUuid(); Может использоваться для генерации случайного UUID. Примеры следующие
CoCreateGuid
Функция CoCreateGuid предоставляется под Windows для генерации GUID. Используемый заголовочный файл — objbase.h, связываемая библиотека — ole32.lib, а прототип функции:
HRESULT CoCreateGuid(GUID *pguid);
Java
UUID поддерживается выше JDK 1.5, использование выглядит следующим образом:
Источник: russianblogs.com
Как генерируются UUID

Вы наверняка уже использовали в своих проектах UUID и полагали, что они уникальны. Давайте рассмотрим основные аспекты реализации и разберёмся, почему UUID практически уникальны, поскольку существует мизерная возможность возникновения одинаковых значений.
Современную реализацию UUID можно проследить до RFC 4122, в котором описано пять разных подходов к генерированию этих идентификаторов. Мы рассмотрим каждый из них и пройдёмся по реализации версии 1 и версии 4.
Теория
UUID (universally unique IDentifier) — это 128-битное число, которое в разработке ПО используется в качестве уникального идентификатора элементов. Его классическое текстовое представление является серией из 32 шестнадцатеричных символов, разделённых дефисами на пять групп по схеме 8-4-4-4-12.
3422b448-2460-4fd2-9183-8000de6f8343
Информация о реализации UUID встроена в эту, казалось бы, случайную последовательность символов:
xxxxxxxx-xxxx-Mxxx-Nxxx-xxxxxxxxxxxx
Значения на позициях M и N определяют соответственно версию и вариант UUID.
Версия
Номер версии определяется четырьмя старшими битами на позиции М. На сегодняшний день существуют такие версии:

Вариант
Это поле определяет шаблон информации, встроенной в UUID. Интерпретация всех остальных битов в UUID зависит от значения варианта.
Мы определяем его по первым 1-3 старшим битам на позиции N.

Сегодня чаще всего используют вариант 1, при котором MSB0 равняется 1 , а MSB1 равняется 0 . Это означает, что с учётом подстановочных знаков — битов, отмеченных х — единственными возможными значениями будут 8 , 9 , A или B .
1 0 0 0 = 8
1 0 0 1 = 9
1 0 1 0 = A
1 0 1 1 = B
Так что если вы видите UUID с такими значениями на позиции N, то это идентификатор в варианте 1.
Версия 1 (время + уникальный или случайный идентификатор хоста)
В этом случае UUID генерируется так: к текущему времени добавляется какое-то идентифицирующее свойство устройства, которое генерирует UUID, чаще всего это MAC-адрес (также известный как ID узла).
Идентификатор получают с помощью конкатенации 48-битного МАС-адреса, 60-битной временной метки, 14-битной «уникализированной» тактовой последовательности, а также 6 битов, зарезервированных под версию и вариант UUID.
Тактовая последовательность — это просто значение, инкрементируемое при каждом изменении часов.
Временная метка, которая используется в этой версии, представляет собой количество 100-наносекундных интервалов с 15 октября 1582 года — даты возникновения григорианского календаря.
Возможно, вы знакомы с принятым в Unix-системах исчислением времени с начала эпохи. Это просто другая разновидность Нулевого дня. В сети есть сервисы, которые помогут вам преобразовать одно временное представление в другое, так что не будем на этом останавливаться.
Хотя эта реализация выглядит достаточно простой и надёжной, однако использование MAC-адреса машины, на которой генерируется идентификатор, не позволяет считать этот метод универсальным. Особенно, когда главным критерием является безопасность. Поэтому в некоторых реализациях вместо идентификатора узла используется 6 случайных байтов, взятых из криптографически защищённого генератора случайных чисел.
Сборка UUID версии 1 происходит так:
- Берутся младшие 32 бита текущей временной метки UTC. Это будут первые 4 байта (8 шестнадцатеричных символов) UUID [ TimeLow ].
- Берутся средние 16 битов текущей временной метки UTC. Это будут следующие 2 байта (4 шестнадцатеричных символа) [ TimeMid ].
- Следующие 2 байта (4 шестнадцатеричных символа) конкатенируют 4 бита версии UUID с оставшимися 12 старшими битами текущей временной метки UTC (в которой всего 60 битов) [ TimeHighAndVersion ].
- Следующие 1-3 бита определяют вариант версии UUID. Оставшиеся биты содержат тактовую последовательность, которая вносит небольшую долю случайности в эту реализацию. Это позволяет избежать коллизий, когда в одной системе работает несколько UUID-генераторов: либо системные часы переводятся назад для генератора, либо изменение времени замедляется [ ClockSequenceHiAndRes ClockSequenceLow ].
- Последние 6 байтов (12 шестнадцатеричных символов, 48 битов) — это «идентификатор узла», в роли которого обычно выступает MAC-адрес генерирующего устройства [ NodeID ].
TimeLow + TimeMid + TimeHighAndVersion + (ClockSequenceHiAndRes ClockSequenceLow) + NodeID
Поскольку эта реализация зависит от часов, нам нужно обрабатывать пограничные ситуации. Во-первых, для минимизации коррелирования между системами по умолчанию тактовая последовательность берётся как случайное число — так делается лишь один раз за весь жизненный цикл системы. Это даёт нам дополнительное преимущество: поддержку идентификаторов узлов, которые можно переносить между системами, поскольку начальное значение тактовой последовательности совершенно не зависит от идентификатора узла.
Помните, что главная цель использования тактовой последовательности — внести долю случайности в наше уравнение. Биты тактовой последовательности помогают расширить временную метку и учитывать ситуации, когда несколько UUID генерируются ещё до того, как изменяются процессорные часы. Так мы избегаем создания одинаковых идентификаторов, когда часы переводятся назад (устройство выключено) или меняется идентификатор узла. Если часы переведены назад, или могли быть переведены назад (например, пока система была отключена), и UUID-генератор не может убедиться, что идентификаторы сгенерированы с более поздними временными метками по сравнению с заданным значением часов, тогда нужно изменить тактовую последовательность. Если нам известно её предыдущее значение, его можно просто увеличить; в противном случае его нужно задать случайным образом или с помощью высококачественного ГПСЧ.
Версия 2 (безопасность распределённой вычислительной среды)
Главное отличие этой версии от предыдущей в том, что вместо «случайности» в виде младших битов тактовой последовательности здесь используется идентификатор, характерный для системы. Часто это просто идентификатор текущего пользователя. Версия 2 используется реже, она очень мало отличается от версии 1, так что идём дальше.
Версия 3 (имя + MD5-хэш)
Если нужны уникальные идентификаторы для информации, связанной с именами или наименованием, то для этого обычно используют UUID версии 3 или версии 5.
Они кодируют любые «именуемые» сущности (сайты, DNS, простой текст и т.д.) в UUID-значение. Самое важное — для одного и того же namespace или текста будет сгенерирован такой же UUID.
Обратите внимание, что namespace сам по себе является UUID.
let namespace = “digitalbunker.dev” let namespaceUUID = UUID3(.DNS, namespace) // Ex: UUID3(namespaceUUID, “/category/things-you-should-know-1/”) 4896c91b-9e61-3129-87b6-8aa299028058 UUID3(namespaceUUID, “/category/things-you-should-know-2/”) 29be0ee3-fe77-331e-a1bf-9494ec18c0ba UUID3(namespaceUUID, “/category/things-you-should-know-3/”) 33b06619-1ee7-3db5-827d-0dc85df1f759
В этой реализации UUID namespace преобразуется в строку байтов, конкатенированных с входным именем, затем хэшируется с помощью MD5, и получается 128 битов для UUID. Затем мы переписываем некоторые биты, чтобы точно воспроизвести информацию о версии и варианте, а остальное оставляем нетронутым.
Важно понимать, что ни namespace, ни входное имя не могут быть вычислены на основе UUID. Это необратимая операция. Единственное исключение — брутфорс, когда одно из значений (namespace или текст) уже известно атакующему.
При одних и тех же входных данных генерируемые UUID версий 3 и 5 будут детерминированными.
Версия 4 (ГПСЧ)
Самая простая реализация.
6 битов зарезервированы под версию и вариант, остаётся ещё 122 бита. В этой версии просто генерируется 128 случайных битов, а потом 6 из них заменяется данными о версии и варианте.
Такие UUID полностью зависят от качества ГПСЧ (генератора псевдослучайных чисел). Если его алгоритм слишком прост, или ему не хватает начальных значений, то вероятность повторения идентификаторов возрастает.
В современных языках чаще всего используются UUID версии 4.
Её реализация достаточно простая:
- Генерируем 128 случайных битов.
- Переписываем некоторые биты корректной информацией о версии и варианте:
- Берём седьмой бит и выполняем c 0x0F операцию AND для очистки старшего полубайта. А затем выполняем с 0x40 операцию OR для назначения номера версии 4.
- Затем берём девятый байт, выполняем c 0x3F операцию AND и с 0x80 операцию OR.
Версия 5 (имя + SHA-1-хэш)
Единственное отличие от версии 3 в том, что мы используем алгоритм хэширования SHA-1 вместо MD5. Эта версия предпочтительнее третьей (SHA-1 > MD5).
Практика
Одним из важных достоинств UUID является то, что их уникальность не зависит от центрального авторизующего органа или от координации между разными системами. Кто угодно может создать UUID с определённой уверенностью в том, что в обозримом будущем это значение больше никем не будет сгенерировано.
Это позволяет комбинировать в одной БД идентификаторы, созданные разными участниками, или перемещать идентификаторы между базами с ничтожной вероятностью коллизии.
UUID можно использовать в качестве первичных ключей в базах данных, в качестве уникальных имён загружаемых файлов, уникальных имён любых веб-источников. Для их генерирования вам не нужен центральный авторизующий орган. Но это обоюдоострое решение. Из-за отсутствия контролёра невозможно отслеживать сгенерированные UUID.
Есть и ещё несколько недостатков, которые нужно устранить. Неотъемлемая случайность повышает защищённость, однако она усложняет отладку. Кроме того, UUID может быть избыточным в некоторых ситуациях. Скажем, не имеет смысла использовать 128 битов для уникальной идентификации данных, общий размер которых меньше 128 битов.
Уникальность
Может показаться, что если у вас будет достаточно времени, то вы сможете повторить какое-то значение. Особенно в случае с версией 4. Но в реальности это не так. Если бы вы генерировали один миллиард UUID в секунду в течение 100 лет, то вероятность повторения одного из значений была бы около 50 %. Это с учётом того, что ГПСЧ обеспечивает достаточное количество энтропии (истинная случайность), иначе вероятность появления дубля будет выше. Более наглядный пример: если бы вы сгенерировали 10 триллионов UUID, то вероятность появления двух одинаковых значений равна 0,00000006 %.
А в случае с версией 1 часы обнулятся только в 3603 году. Так что если вы не планируете поддерживать работу своего сервиса ещё 1583 года, то вы в безопасности.
Впрочем, вероятность появления дубля остаётся, и в некоторых системах стараются это учитывать. Но в подавляющем большинстве случаев UUID можно считать полностью уникальными. Если вам нужно больше доказательств, вот простая визуализация вероятности коллизии на практике.
- uuid
- никто не читает теги
- Блог компании VK
- Программирование
- Проектирование и рефакторинг
- Алгоритмы
- Терминология IT
Источник: habr.com
Универсальный уникальный идентификатор UUID.
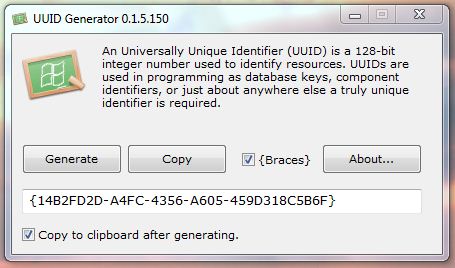
UUID генератор маленькая программа для генерации UUID. Универсальный уникальный идентификатор (UUID) является стандартным идентификатором, используемым в программном обеспечении,стандартизованный Open Software Foundation (OSF) как часть распределенной вычислительной среды (DCE). Цель UUID, является обеспечение распределенных систем для однозначной идентификации информации без существенной центральной координации.
Таким образом, любой пользователь может создать UUID и использовать его для выявления с достаточной уверенностью, что идентификатор никогда не будут непреднамеренно использоваться кем угодно. Информация помечена UUID, поэтому может быть сделано объединение в единую базу данных без необходимости разрешать конфликты имён. Наиболее широкое использование этого стандарта используется в глобальных уникальных Microsoft идентификаторах (GUID), которые осуществляют этот стандарт. Другие пользователи включают в файловую систему Linux ext2/ext3, шифрованные разделы LUKS, GNOME, KDE, и Mac OS X, которые используют реализацию, извлечённого из библиотеки UUID найденного пакета e2fsprogs.
UUID по существу 16-байтное (128-бит) число. В своей канонической форме UUID может выглядеть следующим образом:
7DBC2E8E-AE02-4829-81C4-251694F61707
Эти 32 символов (без дефиса) занимают только 16 байт, поскольку каждому шестнадцатеричному символу нужно только 4 бита (половина байта), чтобы задать его. Число теоретически возможных UUID 2128 = 25 616 или около 3,4 × 10/38. Это означает, что 1 трлн UUID, должны быть созданы каждой наносекундой в течение 10 миллиардов лет, чтобы получилось число UUID.
UUID генератор запоминает скобки выбора,имеет новые горячие клавиши и новые функции «Копировать в буфер обмена после выработки вариантов».
Portable: Yes (Run from USB drive) Platforms: Windows XP, Windows 2003, Windows Vista, Windows 2008, Windows 7.Утилита бесплатна и её можно найти по следующей ссылке UUID Generator .
P.P.S. Если у Вас есть вопросы, желание прокомментировать или поделиться опытом, напишите, пожалуйста, в комментариях ниже.
Источник: kompkimi.ru