
Всегда старайтесь выйти за рамки шаблонного мышления и помните, что время – один из наиболее ценных ресурсов.
Основное наше внимание будет приковано на колонке «word» поскольку, исходя из названия, там как раз хранятся слова. Хотя остальные колонки и другие таблицы в той же базе также будут доступны.
Технические детали уязвимости
В старых версиях Android доступ к пользовательскому словарю управляется следующими константами:
- android.permission.READ_USER_DICTIONARY (права на чтение).
- android.permission.WRITE_USER_DICTIONARY (права на запись).
В новых версиях эта тема уже не работает. Согласно официальной документации [1] (см. раздел Ссылки): «Начиная с API 23, пользовательский словарь доступен только через IME и корректор орфографии». Вышеупомянутые константы были заменены внутренними проверками, и теоретически доступ к пользовательскому словарю (content://user_dictionary/words) стал разрешен только привилегированным учетным записям (например, root и system), подключенным IME и корректорам орфографии.
NEW 2022! Как Установить Root Права на Любой Android Смартфон | ВСЕ СПОСОБЫ
Если посмотреть код репозитория AOSP (Android Open Source Project) на предмет изменений [2], то можно обнаружить новую функцию canCallerAccessUserDictionary, которая стала вызываться внутри стандартных методов query, insert, update и delete класса UserDictionary, предназначенного для работы со пользовательским словарем, и не допускает неавторизованный вызов этих методов.
В методах query и insert нововведение работает эффективно, однако в случае с функциями update и delete та же самая проверка выполняется слишком поздно. Тем самым у нас возникает уязвимость, позволяющая любому приложению успешно обойти проверку авторизации и запустить соответствующие функции через доступный провайдер контента.
Если обратить внимание на выделенные фрагменты в коде класса UserDictionaryProvider [3], то можно увидеть, что проверки авторизации выполняются после того, как запрос к базе данных уже выполнен:
public int delete(Uri uri, String where, String[] whereArgs)
SQLiteDatabase db = mOpenHelper.getWritableDatabase();
count = db.delete(USERDICT_TABLE_NAME, where, whereArgs);
String wordId = uri.getPathSegments().get(1);
count = db.delete(USERDICT_TABLE_NAME, Words._ID + » line-height: 90%»> + (!TextUtils.isEmpty(where) ? » AND (» + where + ‘)’ : «»), whereArgs);
throw new IllegalArgumentException(«Unknown URI » + uri);
// Only the enabled IMEs and spell checkers can access this provider.
public int update(Uri uri, ContentValues values, String where, String[] whereArgs)
SQLiteDatabase db = mOpenHelper.getWritableDatabase();
count = db.update(USERDICT_TABLE_NAME, values, where, whereArgs);
String wordId = uri.getPathSegments().get(1);
count = db.update(USERDICT_TABLE_NAME, values, Words._ID + » line-height: 90%»> + (!TextUtils.isEmpty(where) ? » AND (» + where + ‘)’ : «»), whereArgs);
Лучшие переводчики для смартфона (ТОП от The Phrase Of The Day) — Голосовой переводчик или классика?
throw new IllegalArgumentException(«Unknown URI » + uri);
// Only the enabled IMEs and spell checkers can access this provider.
Также заметьте, что в файле AndroidManifest.xml не предусмотрено никаких дополнительных мер защиты (например, intent-фильтры или права доступа) для экспортируемого явным образом провайдера контента.
Злоумышленнику не составит особого труда обновить содержимое пользовательского словаря через запуск следующего кода из любого приложения и без специальных прав доступа:
ContentValues values = new ContentValues();
getContentResolver().update(UserDictionary.Words.CONTENT_URI, values,
Схожим образом, можно удалить отдельные строки или весь пользовательский словарь:
getContentResolver().delete(UserDictionary.Words.CONTENT_URI, null, null);
Оба метода (update и delete) возвращают количество строк, участвующих в операции, однако в случае с нелегитимными вызовами, эти методы всегда возвращают 0, что немного затрудняет работу с информацией, которая выдается провайдером контента.
На первый взгляд, кажется, что вышеуказанные операции – единственное, что доступно злоумышленнику. Конечно, удаление или обновление произвольных записей может навредить пользователю, однако намного интереснее получить доступ к персональным данным.
Даже если упомянутая уязвимость отсутствует в функции query, полная выгрузка содержимого словаря все еще возможна через реализацию атак, сочетающих эксплуатацию временных характеристик и сторонних каналов. Поскольку аргументы условия where полностью контролируется злоумышленником и тот факт, что запрос на обновление выполняется дольше, если строки изменяются, чем тот же самый запрос, который никак не влияет на содержимое таблицы, мы можем реализовать вполне эффективную атаку.
Концепция атаки
Рассмотрим следующий фрагмент кода, запускаемого локально из вредоносного приложения:
ContentValues values = new ContentValues();
long t0 = System.nanoTime();
«_id = 1 AND word LIKE ‘a%'», null);
long t1 = System.nanoTime();
Если выполнять один и тот же запрос достаточное количество раз (например, 200 раз, хотя все зависит от устройства), временной интервал (t1-t0) между вычислением SQL-условия, результатом которого является «истина», и тем же самым условием, результатом которого является «ложь», становится заметным. В этом случае злоумышленник может извлечь всю информацию из базы данных, реализуя классическую Boolean Blind SQL-инъекцию в связке с эксплуатацией временных характеристик.
Таким образом, если первое слово в пользовательском словаре начинается с символа «a», результатом проверки условия станет «истина» и код, показанный выше, будет выполняться дольше (допустим, 5 секунд). Тот же самый запрос, у которого результатом проверки условия станет «ложь», будет выполняться быстрее (например, 2 секунды), поскольку в этом случае ни одна строка задействована не будет. Если в результате выполнения запроса мы сразу же получим «ложь», пробуем то же самое с символами «b», «c» и т. д. Если в результате мы получим «истину», значит, первый символ в слове обнаружен, и можно переходить к вычислению второго, используя ту же самую технику. Далее переходим к следующему слову и так до тех пор, пока не выгрузится весь словарь или отфильтрованное множество строк и полей.
Чтобы избежать реального изменения содержимого базы, обновляем колонку «_id» на то же самое значение. В итоге запрос будет выглядеть так:
UPDATE words SET _id=N WHERE _id=N AND (condition)
Если условие истинно, строка с идентификатором N будет обновлена таким образом, что никакие изменения не произойдут, поскольку в колонку «_id» будет занесено первоначальное значение. Этот метод извлечения данных называется неинтрузивным, когда время выполнения используется в качестве стороннего информационного канала.
Поскольку мы можем заменить условие выше на любой вложенную выборку (запрос select), в этой атаке доступны любые SQL-выражения, которые поддерживаются в SQLite, например:
· Содержится ли конкретное слово в словаре?
· Получить все 16-символьные слова (например, номера кредитных карт).
· Получить все слова, к которым привязана короткая последовательность (ярлык).
· Получить все слова с точкой.
Схема реализации атаки
Процедура, описанная выше, может быть полностью оптимизирована и автоматизирована. Я написал простейшее Android-приложение с целью доказательства своей концепции.
Приложение базируется на том обстоятельстве, что мы можем вслепую обновить произвольные строки в базе UserDictionary через вышеуказанного провайдера контента. Если запрос UPDATE затрагивает одну или более строк, время на выполнение требуется больше. По сути, у нас есть все, что нужно, чтобы узнать результат проверки SQL-условия («истина» или «ложь»).
Однако поскольку на данный момент у нас нет никакой информации относительно содержимого словаря (и даже о внутренних идентификаторах), вместо перебора всех возможных идентификаторов мы начнем со строки с наименьшим идентификатором и заменим значение колонки «frequency» на произвольное число. Эту задачу можно решить несколькими корректными способами.
Поскольку в Android будут запущены одновременно несколько разделяемых процессов общая продолжительность выполнения будет варьироваться во время разных запусков. Кроме того, время выполнения будет зависеть от производительности устройства. С другой стороны, можно вычислить среднее значение после многократных запусков. Нам лишь нужно подобрать количество итераций в зависимости от устройства и текущей конфигурации (например, если используется режим энергосбережения).
Я начал со сложного подхода, помогающего определить, соответствует ли время ответа значениям «истина» и «ложь», но в итоге реализовал более простой метод, дающий вполне точные и надежные результаты. Суть заключается в том, что нужно выполнить одинаковое количество запросов, которые всегда и истинны (например, с конструкцией «WHERE 1=1») и ложны (например, с конструкцией «WHERE 1=0»). Затем нужно вычислить среднее значение, которое будет использоваться в качестве порога. Если время выполнение больше порогового значения, значит, в результате получаем «истину», в противном случае – «ложь». Как вы понимаете, мы не использовали искусственный интеллект, биг дату, блокчейн или облачные вычисления, но часто простейшие алгоритмы могут давать вполне рабочие результаты.
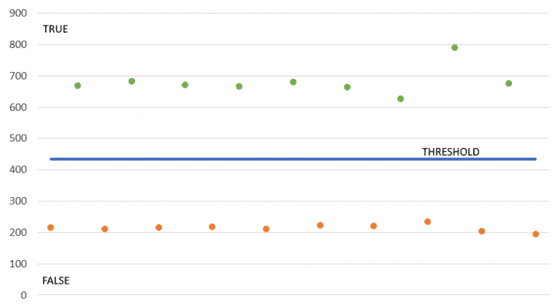
Рисунок 3: Распределение времени выполнения относительно порогового значения
Как только у нас появился метод дифференциации между истинными и ложными запросами, выгрузить всю базу не составит особого труда. В примере, рассмотренном в предыдущем разделе, легко разобраться, но в целом этот способ не самый эффективный. Вместо числовых запросов мы воспользуемся алгоритмом бинарного поиска [4]:
· Определяем количество строк в таблице (необязательная операция)
o SELECT COUNT(*) FROM words
· Определяем наименьший идентификатор
o SELECT MIN(_id) FROM words
· Определяем длину слова, к которому привязан наименьший идентификатор
o SELECT length(word) FROM words WHERE _id=N
· Извлекаем все символы найденного слова (в формате ASCII/Unicode)
o SELECT unicode(substr(word, i, 1)) FROM words WHERE _id=N
· Определяем следующий наименьший идентификатор, который больше найденного, и повторяем вышеуказанные шаги
o SELECT MIN(_id) FROM words WHERE _id > N
Помните о том, что мы не можем извлечь цифровые и буквенные значения напрямую, и нам нужно преобразовать выражения в булевые запросы, которые затем будут вычисляться как истинные или ложные на основе времени выполнения. Так работает алгоритм бинарного поиска. Вместо перебора всех символов напрямую формируется запрос: «больше ли код символа значения X». Этот запрос выполняется повторно, а значение X меняется в каждой итерации до тех пор, пока мы не найдем корректное значение, выполнив log(n) запросов. Например, если код текущего значения 97, итерации алгоритма будут следующими:
Источник: www.securitylab.ru
User Dictionary Manager (UDM)
User Dictionary Manager (UDM) Программа, которая позволяет редактировать, экспортировать, импортировать, удалять и очищать пользовательский словарь мобильного устройства на базе Android. По словам разработчика, программа НЕ РАБОТАЕТ на следующих устройствах:
- HTC Tatoo
- HTC Hero
- HTC Sense
- HTC Eris
- HTC Desire
- HTC с root-доступом
Источник: freesoft.ru
User Dictionary Plus
Вы устали исправлять слова с ошибками при составлении текстов, а также вручную вставлять их в пользовательский словарь? User Dictionary Plus будет персонализировать ваше устройство со словами, которые вы используете наиболее из приложений обмена сообщений, социальных сетей, SMS и электронных писем. Вам не нужно будет покупать новую клавиатуру!
User Dictionary Plus будет наполнять ваш пользовательский словарь Android словами из:
* Facebook;
* WhatsApp (Premium);
* Twitter;
* Gmail;
* SMS (отправленные, полученные);
* Текстовый файл (Premium).
Источник: droidoff.com
User Dictionary Manager (UDM) 8.6


User Dictionary Manager — утилита для Android-коммуникаторов для работы с пользовательским словарем смартфона. Приложение дает возможность создавать резервную копию словаря на карте памяти, восстанавливать данные из резервной копии, удалять выбранные записи из пользовательского словаря или полностью его очищать.
Telegram-канал создателя Трешбокса про технологии
Источник: trashbox.ru