
П роцесс – это исполняемая копия приложения. Например, когда вы открываете приложение MS Word, то запускаете процесс, исполняющий программу MS Word. Поток – отдельное исполняемое задание внутри процесса. Процесс может содержать множество исполняемых потоков. После запуска приложения исполняется главный поток, который далее может порождать другие потоки.
Каждый процесс обладает собственной памятью. Потоки же, которые запущены внутри процесса, разделяют память между собой. Процесс внутри операционной системы обладает собственным идентификатором. Потоки существуют внутри процесса и обладают идентификатором внутри работающего приложения.
Каждый из потоков имеет свой собственный стек (он не делит его с другими потоками и другие потоки не могут в него залезть) и собственный набор регистров (поток не изменит значения регистра другого потока во время работы). Часто потоки называют «легковесными» процессами, так как они требуют гораздо меньше ресурсов для работы, чем новый процесс. В зависимости от реализации, обычный настольный компьютер может эффективно использовать от единиц, до десятков тысяч потоков.
Онлайн Планировщик Участка — как просто создать план дачного участка вашей мечты
- Идентификатор процесса
- Окружение
- Рабочая папка
- Регистры
- Стек
- Куча
- Файловый дескриптор
- Общие библиотеки (dll, so)
- Инструменты межпроцессорного взаимодействия (пайпы, очереди сообщений, семафоры или обобщённая память)
- Специфические для операционной системы ресурсы
- Stack Pointer (указатель на вершину стека, на самом деле «своего» стека, как у процесса, у потока нет)
- Регистры
- Свойства (необходимые для планировщика, такие как приоритет или политики)
- Специфичные для потока данные
- Специфические для операционной системы ресурсы
Многозадачность и параллелизм
М ногозадачные системы позволяют запускать несколько задач одновременно. Многозадачность не обязательно обозначает истинную параллельность выполнения задач: такие системы существуют достаточно давно и появились тогда, когда процессоры были одноядерными. Все задачи получают от планировщика временной промежуток, в течение которого выполнять работу. После чего задача переходит в состояние ожидания. Все задачи имеют свой приоритет, соответственно, чем выше приоритет, тем больше времени задача может работать.
Многозадачные системы на однопоточном процессоре создают иллюзию синхронного выполнения нескольких процессов. Пусть у нас есть три процесса. Если каждый из них работает время t1, t2 и t3, то общее время выполнения будет равно t1+ t2 + t3.
Последовательное выполнение трёх процессов на однопоточном процессоре
Если теперь мы разобьём каждую из задач на N частей, то общее время выполнения будет dt1*N+dt2*N+dt3*N+dts*N*N, где dts – это время, затрачиваемое на восстановление контекста выполнения задачи (на работу планировщика).
Работа каждого процесса на однопоточном процессоре разбита на временные промежутки
Зонирование участка. Планировка участка. Правильное расположение дома на участке
С одной стороны, последовательное выполнение трёх задач без накладных расходов на переключение между задачами должно быть гораздо быстрее. Однако на практике часто бывает иначе. Если процесс выполняет много операция ввода-вывода или работает с внешними ресурсами, то большую часть времени он простаивает, ожидая данные. Это время простоя занимает другая задача. Таким образом, общее время выполнения становится меньше.
Когда процесс большую часть своего времени простаиват в ожидании ресурсов, то параллельное выполнение нескольких задач может происходить быстрее, чем последовательное
Если у нас имеется одна «числодробительная» задача, то никакого преимущества не будет. Но стоит помнить, что в ряде случаев даже на одноядерном процессоре такая искусственная параллелизация может существенно ускорить выполнение.
Для многоядерных систем всё яснее: если задача разбита на несколько потоков, то каждый из них может выполняться реально параллельно. То есть, если решать задачу в 4 потока вместо одного, то потенциально она станет работать в 4 раза быстрее. Очевидно, что где-то есть подвох…
Во-первых, ускорение работы с увеличением числа процессоров и ядер растёт нелинейно и имеет для данной задачи какой-то потолок (см. закон Амдала). А во-вторых, задача сильно усложняется при наличии общих ресурсов.
Совместный доступ к ресурсам
К огда несколько потоков делают каждый своё дело, не разделяя память, то они могут сильно ускорить работу. Дополнительные издержки потребуются только для выделения ресурсов под эти потоки и для передачи им необходимых данных. Когда несколько потоков должны общаться друг с другом, передавать данные, обрабатывать один объект, то есть совместно обращаться к одному ресурсу (обычно это общий участок памяти), то возникают так называемые race conditions – состояния гонки – когда результат работы зависит от порядка доступа к ресурсам.
Например, нам нужно сложить два массива a и b одинаковой длины и поместить результат в массив c. Каждое значение c[i] зависит от a[i] и b[i] и не зависит от остальных. Мы можем разделить массивы на несколько участков, и каждый из потоков будет заниматься сложением только этих участков, не пересекаясь с остальными потоками. У них всех будут общие переменные a, b и c, но они будут всегда независимо обращаться только к отдельным областям памяти.
Второй типичный пример: банковский счёт. Пусть два человека имеют доступ до одного счёта. На счету 10000. Пользователь A снимает со счёта 8000. Второй пользователь запрашивает остаток. Операция первого пользователя не успела завершиться и на счету указано 10000. Второй пользователь снимает 5000.
В тот момент, когда он отправил заявку на снятие денег со счёта, деньги уже снялись, и на счету осталось 2000. В данном случае возможно несколько исходов. Самый лучший, когда у второго пользователя выпадет ошибка, и он ничего не получит. Ситуация, когда второй пользователь снимет деньги и счёт станет -3000. А также ситуация, когда оба снимут деньги и на счету останется 2000 или 5000.
POSIX threads
И сторически сложилось, что каждый производитель железа реализовывал свою проприетарную версию потоков. Эти реализации сильно отличались друг от друга, создавая большие проблемы для программистов и не давая возможности писать переносимое программное обеспечение.
В связи с этим, появилась необходимость в стандарте для потоков. Для UNIX-подобных операционных систем был принят стандарт IEEE POSIX 1003.1c (1995). Реализация библиотеки для работы с потоками в соответствии с этим стандартом и называется POSIX threads, или pthreads.
В настоящее время большинство производителей совместно со своими собственными интерфейсами для работы с потоками предлагают Pthreads. Pthreads обычно представляет собой набор типов и функций на языке си, описанных в файле pthread.h и реализованных в .h, .lib, .dll и т.д. файлах, поставляемых с библиотекой. Иногда pthread входит в состав другой библиотеки (например, libc).

Всё ещё не понятно? – пиши вопросы на ящик
Источник: learnc.info
Концепция процессов и потоков. Задание, процессы, потоки (нити), волокна
Одним из основных понятий, связанных с операционными системами, является процесс – абстрактное понятие, описывающее работу программы [10]. Все функционирующее на компьютере программное обеспечение, включая и операционную систему, можно представить набором процессов.
Задачей ОС является управление процессами и ресурсами компьютера или, точнее, организация рационального использования ресурсов в интересах наиболее эффективного выполнения процессов. Для решения этой задачи операционная система должна располагать информацией о текущем состоянии каждого процесса и ресурса. Универсальный подход к предоставлению такой информации заключается в создании и поддержке таблиц с информацией по каждому объекту управления.
Общее представление об этом можно получить из рис. 5.1, на котором показаны таблицы, поддерживаемые операционной системой: для памяти, устройств ввода-вывода, файлов (программ и данных) и процессов. Хотя детали таких таблиц в разных ОС могут отличаться, по сути, все они поддерживают информацию по этим четырем категориям. Располагающий одними и теми же аппаратными ресурсами, но управляемый различными ОС, компьютер может работать с разной степенью эффективности. Наибольшие сложности в управлении ресурсами компьютера возникают в мультипрограммных ОС.
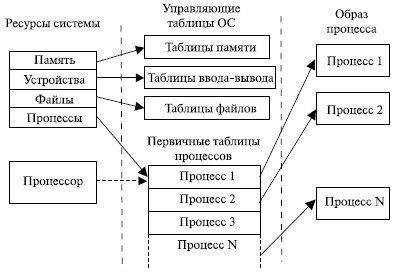
Рис. 5.1. Таблицы ОС
Мультипрограммирование (многозадачность, multitasking) – это такой способ организации вычислительного процесса, при котором на одном процессоре попеременно выполняются несколько программ. Чтобы поддерживать мультипрограммирование, ОС должна определить для себя внутренние единицы работы, между которыми будут разделяться процессор и другие ресурсы компьютера. В ОС пакетной обработки, распространенных в компьютерах второго и сначала и третьего поколения, такой единицей работы было задание. В настоящее время в большинстве операционных систем определены два типа единиц работы: более крупная единица – процесс, или задача, и менее крупная – поток, или нить. Причем процесс выполняется в форме одного или нескольких потоков.
Вместе с тем, в некоторых современных ОС вновь вернулись к такой единице работы, как задание (Job), например, в Windows. Задание в Windows представляет собой набор из одного или нескольких процессов, управляемых как единое целое. В частности, с каждым заданием ассоциированы квоты и лимиты ресурсов, хранящиеся в соответствующем объекте задания. Квоты включают такие пункты, как максимальное количество процессов (это не позволяет процессам задания создавать бесконтрольное количество дочерних процессов), суммарное время центрального процессора, доступное для каждого процесса в отдельности и для всех процессов вместе, а также максимальное количество используемой памяти для процесса и всего задания. Задания также могут ограничивать свои процессы в вопросах безопасности, например, получать или запрещать права администратора (даже при наличии правильного пароля).
Процессы рассматриваются операционной системой как заявки или контейнеры для всех видов ресурсов, кроме одного – процессорного времени. Это важнейший ресурс распределяется операционной системой между другими единицами работы – потоками, которые и получили свое название благодаря тому, что они представляют собой последовательности (потоки выполнения) команд. Каждый процесс начинается с одного потока, но новые потоки могут создаваться (порождаться) процессом динамически. В простейшем случае процесс состоит из одного потока, и именно таким образом трактовалось понятие «процесс» до середины 80-х годов (например, в ранних версиях UNIX). В некоторых современных ОС такое положение сохранилось, т.е. понятие «поток» полностью поглощается понятием «процесс».
Как правило, поток работает в пользовательском режиме, но когда он обращается к системному вызову, то переключается в режим ядра. После завершения системного вызова поток продолжает выполняться в режиме пользователя. У каждого потока есть два стека, один используется в режиме ядра, другой – в режиме пользователя.
Помимо состояния (текущие значения всех объектов потока) идентификатора и двух стеков, у каждого потока есть контекст (в котором сохраняются его регистры, когда он не работает), приватная область для его локальных переменных, а также может быть собственный маркер доступа (информация о защите). Когда поток завершает работу, он может прекратить свое существование. Процесс завершается, когда прекратит существование последний активный поток.
Взаимосвязь между заданиями, процессами и потоками показана на рис. 5.2.
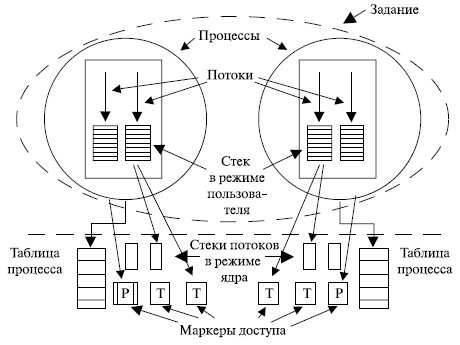
Рис. 5.2. Задания, процессы, потоки
Переключение потоков в ОС занимает довольно много времени, так как для этого необходимы переключение в режим ядра, а затем возврат в режим пользователя. Достаточно велики затраты процессорного времени на планирование и диспетчеризацию потоков. Для предоставления сильно облегченного псевдопараллелизма в Windows 2000 (и последующих версиях) используются волокна (Fiber), подобные потокам, но планируемые в пространстве пользователя создавшей их программой. У каждого потока может быть несколько волокон, с той разницей, что когда волокно логически блокируется, оно помещается в очередь блокированных волокон, после чего для работы выбирается другое волокно в контексте того же потока. При этом ОС «не знает» о смене волокон, так как все тот же поток продолжает работу.
Таким образом, существует иерархия рабочих единиц операционной системы, которая применительно к Windows выглядит следующим образом (рис. 5.3).
Возникает вопрос: зачем нужна такая сложная организация работ, выполняемых операционной системой? Ответ нужно искать в развитии теории и практики мультипрограммирования, цель которой – в обеспечении максимально эффективного использования главного ресурса вычислительной системы – центрального процессора (нескольких центральных процессоров).
Поэтому прежде чем переходить к рассмотрению современных принципов управления процессором, процессами и потоками, следует остановиться на основных принципах мультипрограммирования.
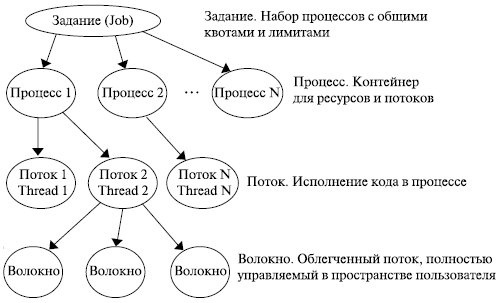
Рис. 5.3. Иерархия рабочих единиц ОС
Понравилась статья? Добавь ее в закладку (CTRL+D) и не забудь поделиться с друзьями:
Источник: studopedia.ru
Потоки на пользовательском уровне и на уровне ядра
Обычно выделяют две общие категории потоков: потоки на уровне пользователя (user-level threads — ULT) и потоки на уровне ядра (kernel-level threads — KLT). Потоки второго типа в литературе иногда называются потоками, поддерживаемыми ядром, или облегченными процессами.
Потоки на уровне пользователя
В программе, полностью состоящей из ULT-потоков, все действия по управлению потоками выполняются самим приложением; ядро, по сути, и не подозревает о существовании потоков. На рис. 4.6,а проиллюстрирован подход, при котором используются только потоки на уровне пользователя. Чтобы приложение было много поточным, его следует создавать с применением специальной библиотеки, представляющей собой пакет программ для работы с потоками на уровне ядра. Такая библиотека для работы с потоками содержит код, с помощью которого можно создавать и удалять потоки, производить обмен сообщениями и данными между потоками, планировать их выполнение, а также сохранять и восстанавливать их контекст.
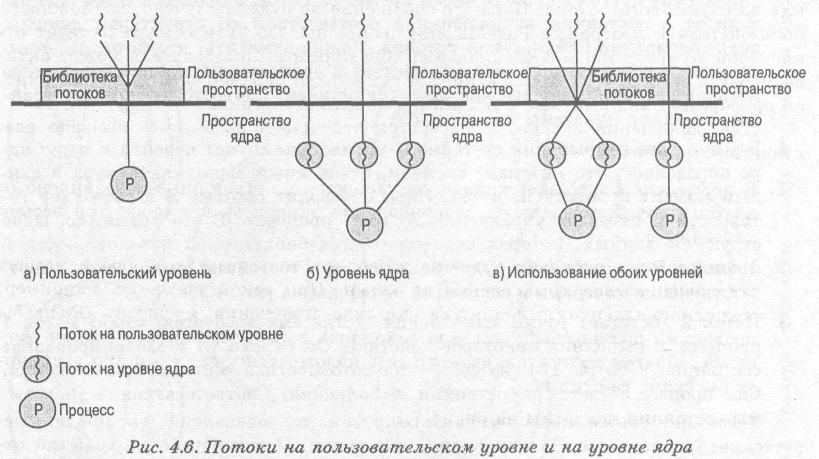
По умолчанию приложение в начале своей работы состоит из одного потока и его выполнение начинается как выполнение этого потока. Такое приложение вместе с составляющим его потоком размещается в едином процессе, который управляется ядром. Выполняющееся приложение в любой момент времени может породить новый поток, который будет выполняться в пределах того же процесса.
Новый поток создается с помощью вызова специальной подпрограммы из библиотеки, предназначенной для работы с потоками. Управление к этой подпрограмме переходит в результате вызова процедуры. Библиотека потоков создает структуру данных для нового потока, а потом передает управление одному из готовых к выполнению потоков данного процесса, руководствуясь некоторым алгоритмом планирования. Когда управление переходит к библиотечной подпрограмме, контекст текущего потока сохраняется, а когда управление возвращается к потоку, его контекст восстанавливается. Этот контекст в основном состоит из содержимого пользовательских регистров, счетчика команд и указателей стека.
Все описанные в предыдущих абзацах события происходят в пользовательском пространстве в рамках одного процесса. Ядро не подозревает об этой деятельности. Оно продолжает осуществлять планирование процесса как единого целого и приписывать ему единое состояние выполнения (состояние готовности, состояние выполняющегося процесса, состояние блокировки и т.д.).
Приведенные ниже примеры должны прояснить взаимосвязь между планированием потоков и планированием процессов. Предположим, что выполняется поток 2, входящий в процесс В (см. рис. 4.7). Состояния этого процесса и составляющих его потоков на пользовательском уровне показаны на рис. 4.7,а.
Впоследствии может произойти одно из следующих событий.
- Приложение, в котором выполняется поток 2, может произвести системный вызов, например запрос ввода-вывода, который блокирует процесс В. В результате этого вызова управление перейдет к ядру. Ядро вызывает процедуру ввода-вывода, переводит процесс В в состояние блокировки и передает управление другому процессу. Тем временем поток 2 процесса В все еще находится в состоянии выполнения в соответствии со структурой данных, поддерживаемой библиотекой потоков. Важно отметить, что поток 2 не выполняется в том смысле, что он работает с процессором; однако библиотека потоков воспринимает его как выполняющийся. Соответствующие диаграммы состояний показаны на рис. 4.7,6.
- В результате прерывания по таймеру управление может перейти к ядру; ядро определяет, что интервал времени, отведенный выполняющемуся в данный момент процессу В, истек. Ядро переводит процесс В в состояние готовности и передает управление другому процессу. В это время, согласно структуре данных, которая поддерживается библиотекой потоков, поток 2процесса В по-прежнему будет находиться в состоянии выполнения. Соответствующие диаграммы состояний показаны на рис. 4.7,в.
- Поток 2 достигает точки выполнения, когда ему требуется, чтобы поток 1процесса В выполнил некоторое действие. Он переходит в заблокированное состояние, а поток 1 — из состояния готовности в состояние выполнения. Сам процесс остается в состоянии выполнения. Соответствующие диаграммы состояний показаны на рис. 4.7,г
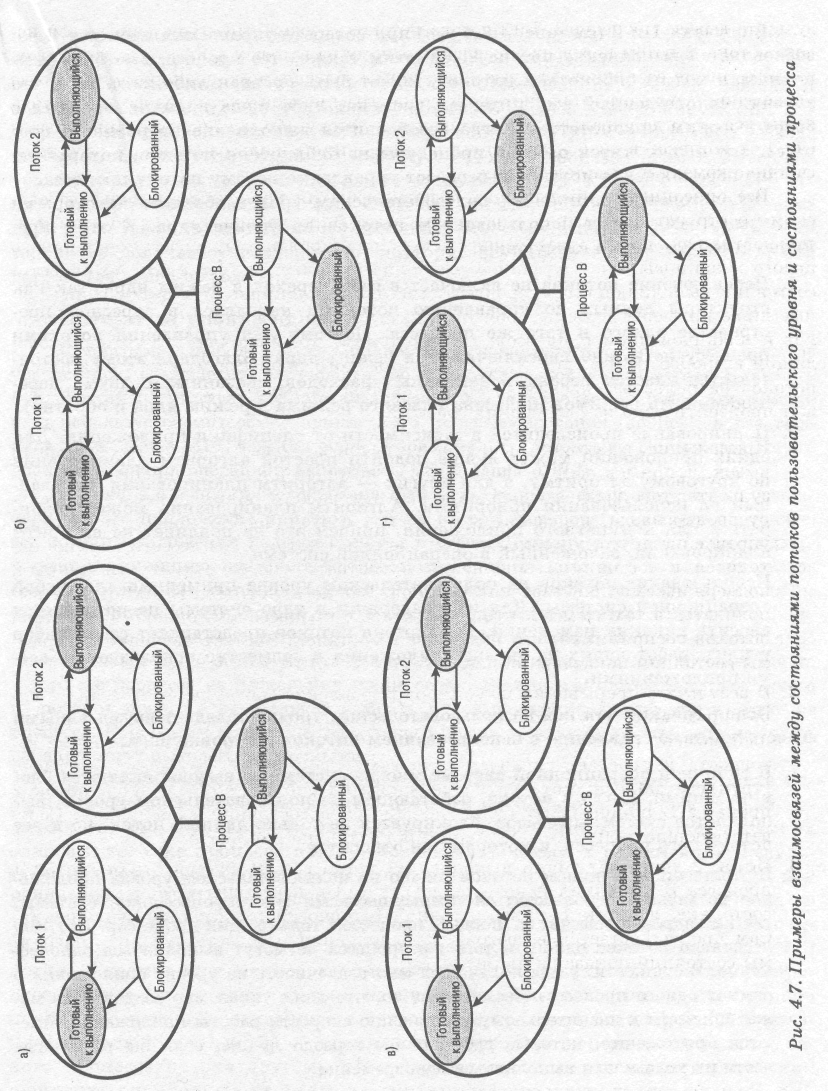 В случаях 1 и 2 (см. рис. 4.7,6 и в) при возврате управления процессу В возобновляется выполнение потока 2. Заметим также, что процесс, в котором выполняется код из библиотеки потоков, может быть прерван либо из-за того, что закончится отведенный ему интервал времени, либо из-за наличия процесса с более высоким приоритетом. Когда возобновится выполнение прерванного процесса, оно продолжится работой процедуры из библиотеки потоков, которая завершит переключение потоков и передаст управление новому потоку процесса. Использование потоков на пользовательском уровне обладает некоторыми преимуществами перед использованием потоков на уровне ядра. К этим преимуществам относятся следующие.
В случаях 1 и 2 (см. рис. 4.7,6 и в) при возврате управления процессу В возобновляется выполнение потока 2. Заметим также, что процесс, в котором выполняется код из библиотеки потоков, может быть прерван либо из-за того, что закончится отведенный ему интервал времени, либо из-за наличия процесса с более высоким приоритетом. Когда возобновится выполнение прерванного процесса, оно продолжится работой процедуры из библиотеки потоков, которая завершит переключение потоков и передаст управление новому потоку процесса. Использование потоков на пользовательском уровне обладает некоторыми преимуществами перед использованием потоков на уровне ядра. К этим преимуществам относятся следующие.
- Переключение потоков не включает в себя переход в режим ядра, так как структуры данных по управлению потоками находятся в адресном пространстве одного и того же процесса. Поэтому для управления потоками процессу не нужно переключаться в режим ядра. Благодаря этому обстоятельству удается избежать накладных расходов, связанных с двумя переключениями режимов (пользовательского режима в режим ядра и обратно).
- Планирование производится в зависимости от специфики приложения. Для одних приложений может лучше подойти простой алгоритм планирования по круговому алгоритму, а для других — алгоритм планирования, основанный на использовании приоритета. Алгоритм планирования может подбираться для конкретного приложения, причем это не повлияет на алгоритм планирования, заложенный в операционной системе.
- Использование потоков на пользовательском уровне применимо для любой операционной системы. Для их поддержки в ядро системы не потребуется вносить никаких изменений. Библиотека потоков представляет собой набор утилит, работающих на уровне приложения и совместно используемых всеми приложениями.
Использование потоков на пользовательском уровне обладает двумя явными недостатками по сравнению с использованием потоков на уровне ядра.
- В типичной операционной системе многие системные вызовы являются блокирующими. Когда в потоке, работающем на пользовательском уровне, выполняется системный вызов, блокируется не только данный поток, но и все потоки того процесса, к которому он относится.
- В стратегии с наличием потоков только на пользовательском уровне приложение не может воспользоваться преимуществами многопроцессорной системы, так как ядро закрепляет за каждым процессом только один процессор. Поэтому несколько потоков одного и того же процесса не могут выполняться одновременно. В сущности, у нас получается многозадачность на уровне приложения в рамках одного процесса. Несмотря на то, что даже такая многозадачность может привести к значительному увеличению скорости работы приложения, имеются приложения, которые работали бы гораздо лучше, если бы различные части их кода могли выполняться одновременно.
Эти две проблемы разрешимы. Например, их можно преодолеть, если писать приложение не в виде нескольких потоков, а в виде нескольких процессов. Однако при таком подходе основные преимущества потоков сводятся на нет: каждое переключение становится не переключением потоков, а переключением процессов, что приведет к значительно большим накладным затратам. Другим методом преодоления проблемы блокирования является использование преобразования блокирующего системного вызова в не блокирующий. Например, вместо непосредственного вызова системной процедуры ввода-вывода поток вызывает подпрограмму-оболочку, которая производит ввод-вывод на уровне приложения. В этой программе содержится код, который проверяет, занято ли устройство ввода-вывода. Если оно занято, поток передает управление другому потоку (что происходит с помощью библиотеки потоков). Когда наш поток вновь получает управление, он повторно осуществляет проверку занятости устройства ввода-вывода. Потоки на уровне ядра В программе, работа которой полностью основана на потоках, работающих на уровне ядра, все действия по управлению потоками выполняются ядром. В области приложений отсутствует код, предназначенный для управления потоками. Вместо него используется интерфейс прикладного программирования (application programming interface — API) средств ядра, управляющих потоками. Примерами такого подхода являются операционные системы OS/2, Linux и W2K. На рис. 4.6,6 проиллюстрирована стратегия использования потоков на уровне ядра. Любое приложение при этом можно запрограммировать как многопоточное; все потоки приложения поддерживаются в рамках единого процесса. Ядро поддерживает информацию контекста процесса как единого целого, а также контекстов каждого отдельного потока процесса. Планирование выполняется ядром исходя из состояния потоков. С помощью такого подхода удается избавиться от двух упомянутых ранее основных недостатков потоков пользовательского уровня. Во-первых, ядро может одновременно осуществлять планирование работы нескольких потоков одного и того же процесса на нескольких процессорах. Во-вторых, при блокировке одного из потоков процесса ядро может выбрать для выполнения другой поток этого же процесса. Еще одним преимуществом такого подхода является то, что сами процедуры ядра могут быть многопоточными. Основным недостатком подхода с использованием потоков на уровне ядра по сравнению с использованием потоков на пользовательском уровне является то, что для передачи управления от одного потока другому в рамках одного и того же процесса приходится переключаться в режим ядра. Результаты исследований, проведенных на однопроцессорной машине VAX под управлением UNIX-подобной операционной системы, представленные в табл. 4.1, иллюстрируют различие между этими двумя подходами. Сравнивалось время выполнения таких двух задач, как (1) нулевое ветвление (Null Fork) — время, затраченное на создание, планирование и выполнение процесса/потока, состоящего только из нулевой процедуры (измеряются только накладные расходы, связанные с ветвлением процесса/потока), и (2) ожидание сигнала (Signal-Wait) — время, затраченное на передачу сигнала от одного процесса/потока другому процессу/потоку, находящемуся в состоянии ожидания (накладные расходы на синхронизацию двух процессов/потоков). Чтобы было легче сравнивать полученные значения, заметим, что вызов процедуры на машине VAX, используемой в этом исследовании, длится 7 us, а системное прерывание — 17 us. Мы видим, что различие во времени выполнения потоков на уровне ядра и потоков на пользовательском уровне более чем на порядок превосходит по величине различие во времени выполнения потоков на уровне ядра и процессов. Таблица 4.1. Время задержек потоков (μs) [ANDE92]
| Операция | Потоки на пользовательском уровне | Потоки на уровне ядра | Процессы |
| Нулевое ветвление | 34 | 948 | 11300 |
| Ожидание сигнала | 37 | 441 | 1840 |
Таким образом, создается впечатление, что как применение многопоточности на уровне ядра дает выигрыш по сравнению с процессами, так и многопоточность на пользовательском уровне дает выигрыш по сравнению с многопоточностью на пользовательском уровне. Однако на деле возможность этого дополнительного выигрыша зависит от характера приложений. Если для большинства переключений потоков приложения необходим доступ к ядру, то схема с потоками на пользовательском уровне может работать не намного лучше, чем схема с потоками на уровне ядра. Комбинированные подходы В некоторых операционных системах применяется комбинирование потоков обоих видов (рис. 4.6,в). Ярким примером такого подхода может служить операционная система Solaris. В комбинированных системах создание потоков выполняется в пользовательском пространстве, там же, где и код планирования и синхронизации потоков в приложениях. Несколько потоков на пользовательском уровне, входящих в состав приложения, отображаются в такое же или меньшее число потоков на уровне ядра. Программист может изменять число потоков на уровне ядра, подбирая его таким, которое позволяет достичь наилучших результатов. При комбинированном подходе несколько потоков одного и того же приложения могут выполняться одновременно на нескольких процессорах, а блокирующие системные вызовы не приводят к блокировке всего процесса. При надлежащей реализации такой подход будет сочетать в себе преимущества подходов, в которых применяются только потоки на пользовательском уровне или только потоки на уровне ядра, сводя недостатки каждого из этих подходов к минимуму.
Источник: studfile.net