
Помимо собственно форматирования, простота восприятия кода во многом зависит от способа именования переменных, функций, членов классов и прочих сущностей. Азбучная истина, что имена должны быть «говорящими», знакома всем, но при ее реализации на практике между разработчиками возникают разночтения. Начнем с вопроса: насколько «говорящими» должны быть имена?
На заре программирования, да и на первых порах развития языков высокого уровня, названия давали по возможности короткие. Ведь размеры экранов по горизонтали были ограничены (к слову, ограничение на длину строки кода в 80 символов до сих пор много где встречается), имена эти приходилось вводить вручную, и в целом средства разработки не очень располагали к использованию длинных идентификаторов. Посмотрите для интереса на список функций POSIX [1] – имена большинства из них не превосходят десяти символов, а те, что длиннее, появились в конце XX – начале XXI века.
Однако прогресс не стоит на месте, экраны мониторов у разработчиков теперь обычно вмещают больше 80 символов (даже если вы набираете код на смартфоне), а IDE предоставляют такие удобные возможности, как индексирование и автодополнение. Неудивительно, что и длина имен увеличилась и идентификаторы стали более информативными – сравните уже упомянутый POSIX с именами классов в .NET [2] или Java [3].
10 обязательных правил для начинающего программиста или как писать код, за который не стыдно?
Впрочем, слишком усердствовать не стоит, название не должно превращаться в целую повесть. Часто длину идентификаторов ограничивают двумя-тремя десятками символов. Как правило, имена функций и глобальных переменных получаются длиннее, имена локальных переменных короче.
Следует избегать наличия нескольких длинных имен, различающихся только парой букв в середине, ведь при беглом взгляде на код такие переменные могут оказаться слаборазличимы.
Не стоит забывать и о некоторых классических названиях – например, обычно можно без комментариев использовать «i» в качестве счетчика цикла, называть методы класса, возвращающие или устанавливающие значение некоторого поля Field – getField() и setField() соответственно и так далее.
Если вы посмотрели на примеры по ссылкам выше, то наверняка заметили, что многие имена состоят из нескольких слов. Желание использовать многословные названия вполне логично (особенно для функций и методов), но перед начинающими программистами традиционно встает вопрос: как разделять слова в названии?
Примеры POSIX, .NET и Java показывают наиболее популярные подходы к этому вопросу, а именно использование для разделения слов подчеркивания и так называемого верблюжьего регистра («CamelCase»), когда каждое слово в идентификаторе начинается с заглавной буквы (возможно, кроме первого – соответствующие варианты получили название «UpperCamelCase» и «lowerCamelCase»). Иногда можно встретить в качестве разделителя дефис, но во многих языках этот символ нельзя использовать в имени идентификатора.
Необходимо отметить использование во многих проектах так называемой венгерской нотации, подразумевающей добавление к имени переменной префикса для идентификации ее типа или семантического значения.
Вся суть чистого кода
Например, строки могут предваряться префиксом «s» (sMyName), указатели – префиксом «p» (pMyVariable) и так далее.
Помимо переменных, в большинстве программ используются и константные значения, неизменяемые в ходе работы. Однако использовать их в коде напрямую следует с осторожностью. Вместо этого следует объявить константу с осмысленным именем (если язык программирования не позволяет определять константы явно, то можно обойтись и простой переменной) и использовать это имя.
Ведь у человека, просматривающего код, может возникнуть вопрос: почему используются именно это число, строка или другое выражение и откуда оно взялось? Конечно, можно это указать в комментарии, но если фиксированные значения мелькают во многих местах, то комментировать их все вряд ли разумно.
Одним из веских аргументов, часто приводимых в пользу предопределенных констант, является простота изменения их значений – в случае такой необходимости вам достаточно изменить код только в одном месте, а не лазить по всему проекту и определять места, которые надо обновить. Но даже если вы уверены, что константа никогда не изменится, все равно имеет смысл использовать для нее некоторый предопределенный идентификатор.
Классическим примером здесь является число Пи – единственным случаем, когда вам может понадобится «переопределить» его значение, является изменение точности (то есть если вы вдруг решите, что «3.14» недостаточно для расчетов и надо «3.14159»). Если же отбросить вероятность возникновения такой ситуации, то число Пи вряд ли изменится.
Тот, кто просматривает программу и понимает, что она производит, скажем, тригонометрические расчеты, наверняка догадается, что скрывается за повсеместно используемым числом «3.14». Однако вот сможет ли он распознать, что за «1.047» скрывается Пи/3? Можно, конечно, писать «3.14/3». Но согласитесь, «Pi» и «Pi/3» короче, удобнее и нагляднее.
Размер структурных блоков
Разработчики давно пришли к выводу, что для лучшей управляемости и понятности код программы лучше разбивать на относительно независимые блоки – например, на процедуры и функции в процедурной парадигме программирования или на классы и их методы в ООП. Но насколько мелкими или крупными должны быть тела функций и методов?
Отчасти ответ на этот вопрос дают сами парадигмы, многие из которых рекомендуют создавать самодостаточные, но в то же время простые модули. Например, философия UNIX подразумевает создание программ, которые делают что-то одно, но делают это хорошо.
Этот же подход вполне применим к функциям и методам классов – каждая функция должна выполнять ровно одну задачу, и при этом ее поведение должно определяться исключительно ее аргументами, а не кучей внешних условий наподобие глобальных переменных.
Традиционная рекомендация с визуальной точки зрения заключается в том, что тело подпрограммы должно умещаться в экран монитора, чтобы ее можно было охватить взглядом. Понятно, что это требование довольно условное – высота экрана у разных программистов различна, да и размер кода с одной и той же функциональностью на разных языках может иметь разный объем.
Например, получивший репутацию «write-only» языка Perl позволяет уместить в пол-экрана такую логику, которая в Java может спокойно превысить вертикальный размер монитора вдвое (это при условии, что вы следуете правилам форматирования и не помещаете по несколько операторов на одну строку), но вот разобраться в коде Perl будет сложнее.
Следует учитывать и другие меры оценки сложности функций и методов. Например, количество локальных переменных – известно, что среднестатистический человек способен удерживать во внимании одновременно около семи сущностей. Так что если функция оперирует парой десятков переменных, то большинство людей вряд ли быстро поймут суть ее работы.
То же относится и к уровню вложенности структурных блоков – при большом количестве вложенных ветвлений функция становится похожа на повернутую на 90 градусов кардиограмму нестабильно работающего сердца, и воспринимать ее довольно сложно.
Широко известно следующее полушуточное утверждение, что хорошо написанный код в комментариях не нуждается – он очевиден сам по себе. Конечно, к такому положению вещей стоит стремиться, но далеко не всегда это получается, и без текстовых подсказок на «человеческом» языке не обойтись.
Впрочем, избыточное комментирование также не является хорошей практикой – согласитесь, не очень удобно изучать код, каждые две строки которого предваряются десятком строк комментариев.
Распространенный принцип при написании комментариев заключается в том, что большинство из них должны описывать, что делает тот или иной участок программы (и, возможно, зачем), а не как он это делает. Как следствие, достаточно подробными комментариями снабжаются высокоуровневые структурные единицы программы – например, функции и методы классов. Внутри функции сложных комментариев быть не должно – если некоторые участки требуют подробного описания, то лучше их оформить в виде отдельных самостоятельных функций.
Отдельно хотелось бы отметить необходимость описания ограничений на входные параметры и окружающую среду, при которых, как вы считаете, должна работать функция. Также обязательно сопровождайте комментариями участки кода, в работе которых при ряде условий вы сомневаетесь. Это может сэкономить уйму усилий вам и вашим коллегам в будущем, когда окажется, что работавший годами код вдруг стал выдавать ошибки.
В современном мире комментарии в коде часто являются основой документации к программе. Широкое распространение получили системы наподобие Javadoc и Doxygen, автоматически генерирующие документацию на основе программного кода и комментариев.
Например, подобным образом можно автоматически генерировать документацию на API-библиотеки – из исходного кода вычленяется синтаксис экспортируемых функций, классов и переменных, а соответствующие комментарии становятся их описанием.
Использование подобных инструментов требует оформлять код строго определенным образом (чтобы инструмент мог распознать описания каждого параметра функции, возвращаемого значения и так далее).
Поэтому побочным эффектом их применения является единообразный стиль комментариев, что тоже идет на пользу читаемости.
Наконец, одно из главных требований к комментариям заключается в том, что они должны соответствовать коду. К сожалению, не всегда после серьезного изменения участка программы разработчики удосуживаются соответствующим образом обновить комментарий, его описывающий. И впоследствии у человека, изучающего программу, появляется логичный вопрос: это комментарий устарел или в реализации содержится ошибка?
Разрешить эту дилемму не всегда просто. Так что отсутствие комментария – плохо, но неверный комментарий – еще хуже.
Общепринятые стили оформления кода
Выше мы рассмотрели основные аспекты, которые обычно фиксируются в правилах оформления кода. Для многих аспектов однозначных рекомендаций не существует, но имеется несколько альтернативных подходов. У каждой альтернативы есть свои достоинства и недостатки, и во многом предпочтение того или иного подхода – вопрос эстетический и зависящий от конкретного человека.
Например, венгерская нотация изначально появилась и активно использовалась в Microsoft (в частности, в MFC), а вот создатель ядра Linux Линус Торвальдс считает ее ущербной и избыточной.
Не последнюю роль может играть и используемый язык программирования. Создатели некоторых языков постарались уменьшить количество аспектов, по которым возможны разногласия при форматировании – например, в Python не используются фигурные скобки или другие явные разграничители структурных блоков, а границы блоков определяются исключительно по выравниванию текста. Это снимает часть противоречий и заставляет выравнивать код, но простор для споров все равно остается – например, использовать ли для отступов пробелы или табуляцию?
Авторы многих современных языков сами разрабатывают для своих продуктов рекомендации по оформлению написанных на них программ. Например, существуют официальные рекомендации для Java [4], C# [5], Perl [6] и многих других языков. В рамках этих стандартов возможны некоторые вариации от команды к команде, но такие различия обычно минимальны и к ним можно быстро адаптироваться.
В случае языков с более глубокими корнями (в частности, С) ситуация сложнее – для них тоже существуют выработанные десятилетиями рекомендации по оформлению кода, но для одного языка может существовать несколько альтернативных наборов правил. Так, для того же С активно используется Khttps://samag.ru/archive/article/2628″ target=»_blank»]samag.ru[/mask_link]
Требования к коду программы

Комментарии
Популярные По порядку
Не удалось загрузить комментарии.
ЛУЧШИЕ СТАТЬИ ПО ТЕМЕ
Шаблоны проектирования в Python: для стильного кода
Многие шаблоны проектирования встроены в Python из коробки, а другие очень просто реализовать, используя базовые возможности языка.
Учитесь писать код без If
Зачем писать код с if, если можно этого не делать? Вот почему.
4 лучших книг о шаблонах проектирования
Лучшие книги о шаблонах проектирования, рассчитанные как для новичков, так и для уже более опытных программистов.
- О проекте
- Реклама
- Пользовательское соглашение
- Публичная оферта
- Политика конфиденциальности
- Контакты
Push-уведомления Темная тема
Do good code: 8 правил хорошего кода
Практически всем, кто обучался программированию, известна книга Стива Макконнелла «Совершенный код». Она всегда производит впечатление, прежде всего, внушительной толщиной (около 900 страниц). К сожалению, реальность такова, что иногда впечатления этим и ограничиваются. А зря.
В дальнейшей профессиональной деятельности программисты сталкиваются практически со всеми ситуациями, описанными в книге, и приходят опытным путём к тем же самым выводам. В то время как более тесное знакомство могло бы сэкономить время и силы. Мы в GeekBrains придерживаемся комплексного подхода в обучении, поэтому провели для слушателей вебинар по правилам создания хорошего кода.
В комментариях к нашему первому посту на Хабре пользователи активно обсуждали каналы восприятия информации. Мы подумали и решили, что тему «совершенного кода» стоит развить и изложить ещё и письменно — ведь базовые принципы хорошего кода едины для программистов, пишущих на любом языке.
Зачем нужен хороший код, когда всё и так работает?
Несмотря на то, что программа исполняется машиной, программный код пишется людьми и для людей — неслучайно высокоуровневые языки программирования имеют человекопонятные синтаксис и команды. Современные программные проекты разрабатываются группами программистов, порой разделённых не только офисным пространством, но и материками и океанами. Благо, уровень развития технологий позволяет использовать навыки лучших разработчиков, вне зависимости от места нахождения их работодателей. Такой подход к разработке предъявляет серьёзные требования к качеству кода, в частности, к его читабельности и понятности.
Существует множество известных подходов к критериям качества кода, о которых рано или поздно узнаёт практически любой разработчик. Например, есть программисты, которые придерживаются принципа проектирования KISS (Keep It Simple, Stupid! — Делай это проще, тупица!).
Этот метод разработки вполне справедлив и заслуживает уважения, к тому же отражает универсальное правило хорошего кода — простоту и ясность. Однако простота должна иметь границы — порядок в программе и читабельность кода не должны быть результатом упрощения. Кроме простоты, существует ещё несколько несложных правил. И они решают ряд задач.
-
Обеспечивать лёгкое покрытие кода тестами и отладку. Unit тестирование — это процесс тестирования модулей, то есть функций и классов, являющихся частью программы. Создавая программу, разработчик должен учитывать возможности тестирования с самого начала работы над написанием кода.
8 правил хорошего кода по версии GeekBrains
Соблюдайте единый Code style. Если программист приходит работать в организацию, особенно крупную, то чаще всего его знакомят с правилами оформления кода в конкретном проекте (соглашение по code style). Это не случайный каприз работодателя, а свидетельство серьёзного подхода.
Вот несколько общих правил, с которыми вы можете столкнуться:
соблюдайте переносы фигурных скобок и отступы — это значительно улучшает восприятие отдельных блоков кода
соблюдайте правило вертикали — части одного запроса или условия должны находиться на одном отступе
if (typeof a ! == «undefined» typeof b ! == «undefined» typeof c === «string») < //your stuff >
соблюдайте разрядку — ставьте пробелы там, где они улучшают читабельность кода; особенно это важно в составных условиях, например, условиях цикла.
for (var i = 0; i
В некоторых средах разработки можно изначально задать правила форматирования кода, загрузив настройки отдельным файлом (доступно в Visual Studio). Таким образом, у всех программистов проекта автоматически получается однотипный код, что значительно улучшает восприятие. Известно, что достаточно трудно переучиваться после долгих лет практики и привыкать к новым правилам. Однако в любой компании code style — это закон, которому нужно следовать неукоснительно.
Не используйте «магические числа». Магические числа не случайно относят к анти-паттернам программирования, проще говоря, правилам того, как не надо писать программный код. Чаще всего магическое число как анти-паттерн представляет собой используемую в коде константу, смысл которой неясен без комментария. Такие числа не только усложняют понимание кода и ухудшают его читабельность, но и приносят проблемы во время рефакторинга.
Например, в коде есть строка:
DrawWindow( 50, 70, 1000, 500 );
Очевидно, она не вызовет ошибок в работе кода, но и её смысл не всем понятен. Гораздо лучше не полениться и сразу написать таким образом:
int left = 50; int top = 70; int width = 1000; int height = 500; DrawWindow( left, top, width, height );
Иногда магические числа возникают при использовании общепринятых констант, например, при записи числа π. Допустим, в проекте было внесено:
SquareCircle = 3.14*rad*rad
Что тут плохого? А плохое есть. Например, если в ходе работы понадобится сделать расчёт с высокой точностью, придётся искать все вхождения константы в коде, а это трата трудового ресурса. Поэтому лучше записать так:
const float pi = 3.14; SquareCircle = pi*rad*rad
Кстати, иногда коллеги-программисты могут не помнить на память значение использованной вами константы — тогда они просто не узнают её в коде. Поэтому лучше избегать написания чисел без объявления в переменных и даже постоянные величины лучше объявлять. Кстати, эти константы практически всегда есть во встроенных библиотеках, поэтому проблема решается сама собой.

Используйте осмысленные имена для переменных, функций, классов. Всем программистам известен термин “обфускация кода” — сознательное запутывание программного года с помощью приложения-обфускатора. Она делается с целью скрыть реализацию и превращает код в невнятный набор символов, переименовывает переменные, меняет имена методов, функций и проч… К сожалению, случается так, что код и без обфускации выглядит запутанно — именно за счёт бессмысленных имён переменных и функций: var_3698, myBestClass, NewMethodFinal и т.д… Это не только мешает разработчикам, которые участвуют в проекте, но и приводит к бесконечному количеству комментариев. Между тем, переименовав функцию, можно избавиться от комментариев — её имя будет само говорить о том, что она делает.

Получится так называемый самодокументируемый код — ситуация, при которой переменные и функции именуются таким образом, что при взгляде на код понятно, как он работает. У идеи самодокументируемого кода есть много сторонников и противников, к аргументам которых стоит прислушаться. Мы рекомендуем в целом соблюдать баланс и разумно использовать и комментарии, и «говорящие» имена переменных, и возможности самодокументируемого кода там, где это оправданно.
Например, возьмём код такого вида:
// находим лист, записываем в r if ( x != null ) < while ( x.a != null ) < x = x.a; r = x.n; >> else
Из комментария должно быть понятно, что именно делает код. Но совершенно неясно, что обозначают x.a и x.n. Попробуем внести изменения таким образом:
// находим лист, записываем имя в leafName if ( node != null ) < while ( node.next != null ) < node = node.next; leafName = node.name; >> else
В этом пункте следует отдельно сказать про комментарии, так как слушатели всегда задают очень много вопросов о целесообразности и необходимости их использования. Когда комментариев много, они приводят к низкой читабельности кода. Почти всегда есть возможность внести в код такие изменения, чтобы исчезла потребность в комментарии. В крупных проектах комментарии оправданы в случае использования API, обозначения подключения кода сторонних модулей, обозначения спорных моментов или моментов, требующих дальнейшей переработки.
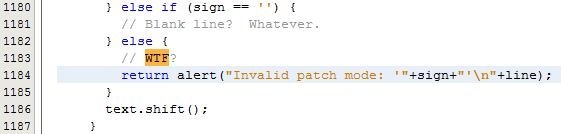
Объединим в одно разъяснение ещё два важных правила. Создавайте методы как новый уровень абстракции с осмысленными именами и делайте методы компактными. Вообще, сегодня модульность кода доступна каждому программисту, а это значит, что нужно стремиться создавать абстракции там, где это возможно.
Абстракция — это один из способов сокрытия деталей реализации функциональности. Создавая отдельные небольшие методы, программист получает хороший код, разделённый на блоки, в которых содержится реализация каждой из функций. При таком подходе нередко увеличивается количество строк кода. Есть даже определённые рекомендации, которые указывают длину метода не более 10 строк.
Конечно, размер каждого метода остаётся целиком на усмотрении разработчика и зависит от многих факторов. Наш совет: всё просто, делайте метод компактным так, чтобы один метод выполнял одну задачу. Отдельные вынесенные сущности проще улучшить, например, вставить проверку входных данных прямо в начале метода.
Для иллюстрации этих правил возьмём пример из предыдущего пункта и создадим метод, код которого не требует комментариев:
string GetLeafName ( Node node ) < if ( node != null ) < while ( node.next != null ) < node = node.next; >return node.name; > return ””; >
И, наконец, скроем реализацию метода:
. leafName = GetLeafName( node ); …
В начале методов проверяйте входные данные. На уровне кода нужно обязательно делать проверки входных данных во всех или практически во всех методах. Это связано с пользовательским поведением: будущие пользователи могут вводить любые данные, которые могут вызвать сбои в работе программы.
В любом методе, даже в том, который использовался всего один раз, обязательно нужно организовывать проверку данных и создавать обработку ошибок. Это стоит сделать, поскольку метод не только выступает как уровень абстракции, но и необходим для переиспользования. В принципе, возможно разделить методы на те, в которых нужно делать проверку, и те, в которых её делать необязательно, но для полной уверенности и защиты от «хитрого пользователя» лучше проверять все входные данные.
В примере ниже вставляем проверку на то, чтобы на входе не получить null.
List GetEvenItems( List items ) < Assert( items != null); Listresult = new List(); foreach ( int i in items ) < if ( i % 2 == 0 ) < result.add(i); >> return result; >
Реализуйте при помощи наследования только отношение «является». В остальных случаях – композиция. Композиция является одним из ключевых паттернов, нацеленных на облегчение восприятия кода и, в отличие от наследования, не нарушает принцип инкапсуляции.
Допустим, у вас есть класс Руль и класс Колесо. Класс Автомобиль можно реализовать как наследник класса-предка Руль, но ведь Автомобилю нужны и свойства класса Колесо.
Соответственно, программист начинает плодить наследование. А ведь даже с точки зрения обывательской логики класс Автомобиль — это композиция элементов. Допустим, есть такой код, когда новый класс создаётся с использованием наследования (класс ScreenElement наследует поля и методы класса Coordinate и расширяет этот класс):
сlass Coordinate < public int x; public int y; >class ScreenElement : Coordinate
Используем композицию:
сlass Coordinate < public int x; public int y; >class ScreenElement
Композиция — неплохая замена наследованию, этот паттерн более простой для дальнейшего понимания написанного кода. Можно придерживаться такого правила: выбирать наследование, только если нужный класс схож с классом-предком и не будет использовать методы других классов. К тому же, композиция избавляет программиста ещё от одной проблемы — исключает конфликт имён, который случается при наследовании. Есть у композиции и недостаток: размножение количества объектов может оказывать влияние на производительность. Но опять же, это зависит от масштаба проекта и должно оцениваться разработчиком в каждом случае отдельно.
Отделяйте интерфейс от реализации. Любой используемый в программе класс состоит из интерфейса (того, что доступно при использовании класса извне) и реализации (методы). В коде интерфейс должен быть отделён от реализации как для соблюдения одного из принципов ООП, инкапсуляции, так и для улучшения читабельности кода.
class Square
Ещё один класс:
class Square
Второй случай предпочтительнее, так как он скрывает реализацию с помощью модификатора доступа private. Кроме улучшения читабельности кода, отделение интерфейса от реализации в сочетании с соблюдением правила создания небольшого интерфейса даёт ещё одно важное преимущество: в случае нарушений в работе программы для поиска причины сбоя потребуется проверить лишь несколько функций. Чем больше открытых функций и данных — тем сложнее отследить источник ошибки. Однако интерфейс должен быть полным и должен позволять делать всё, что необходимо, иначе он бесполезен.
В ходе вебинара был задан вопрос: «А можно писать сразу хорошо и не рефакторить?» Вероятно, через несколько лет или даже десятков лет программирования это будет возможно, особенно если есть изначальное видение архитектуры программы. Но никогда нельзя предвидеть конечное состояние проекта через несколько релизов и итераций доработки. Именно поэтому важно всегда помнить о перечисленных правилах, которые гарантируют устойчивость и способность вашей программы к развитию.
Для тех, кто воспринимает информацию через видео и хочет услышать детали вебинара — видеоверсия:
Другие наши вебинары можно посмотреть здесь.
Источник: habr.com