
Для того, чтобы ПК успешно выполнял свои функции, ему необходимо программное обеспечение, основу которого составляет именно системное ПО.
Для программирования создали системы программирования.
Для выполнения какого-либо заложенного алгоритма процессором необходимо написать этот алгоритм (программу) на языке машинных команд (ЯМК)
Но написание даже самой простейшей программы на ЯМК очень неудобно и занимает много времени, так как программисту приходится работать с адресами ячеек и равномерно распределять память под программу.
Для этого были созданы более прогрессивные и удобные языки программирования, такие как Паскаль, Бейсик и т.д.
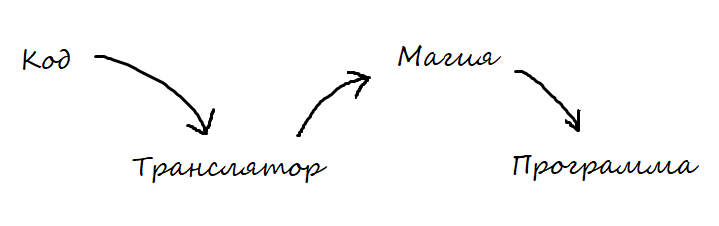
Человек пишет программу на Паскале, а компьютер понимает только ЯМК, для того, чтобы решить возникшую проблему, стали появляться трансляторы (переводчики).
Трансляторы бывают двух видов: компиляторы и интерпретаторы.
Компиляторы после написания программы сразу переводят все операции и не занимают оперативную память, а интерпретаторы переводят каждую операцию отдельно, занимая тем самым оперативную память ПК, что негативно сказывается на скорости выполнения алгоритмов.
Урок 1. Краткая история языков программирования. Трансляторы
Сейчас мы имеем дело не только с отдельными языками программирования, а с целыми системами программирования, в которых заложен какой-либо транслятор, отладчики, редакторы текста и т.д.
Источник: dzen.ru
Пишем свой язык программирования, часть 3: Архитектура транслятора. Разбор языковых структур и математических выражений
Приветствую вас, заинтересованные читающие разработчики на не важно каких языках, на которых я ориентирую эти статьи и чьи поддержку и мнения я ценю.
Для начала, по устоявшимся традициям, я приведу ссылки на предыдущие статьи:
Для формирования в вашей голове полного понимания того, что в этих статьях мы пишем, вам стоит заранее ознакомиться с предыдущими частями.
Также мне стоит разместить сразу ссылку на статью о проекте, который был написан мной ранее и на основе которого идет весь этот разбор полётов: Клац сюды. С ним пожалуй стоит ознакомиться первым делом.
И немного о проекте:
Ну и также скажу сразу, что все написано на Object Pascal, а именно — на FPC.
Принцип работы большинства трансляторов
Первым делом, стоит понимать что я не смог бы ничего путного написать, предварительно не ознакомившись с кучей теоретического материала и рядом статеек. Опишу основное в паре слов.
Задача транслятора первым делом — подготовить код к анализу (например удалить из него комментарии) и разбить код на токены (токен — минимальный значащий для языка набор символов).
Далее нужно путем анализа и преобразований разобрать код в некое промежуточное представление и затем уже собрать готовое к выполнению приложение или… Что там ему в общем нужно собрать.
Winderton / Написал несколько Языков Программирования, вот что я узнал
Да, этой кучей текста я ничего толком то и не сказал, однако — сейчас задача разбита на несколько подзадач.
Пропустим то, как код подготавливается к выполнению, т.к. это слишком скучный для описания процесс. Предположим, что мы имеем уже готовый к анализу набор токенов.
Анализ кода
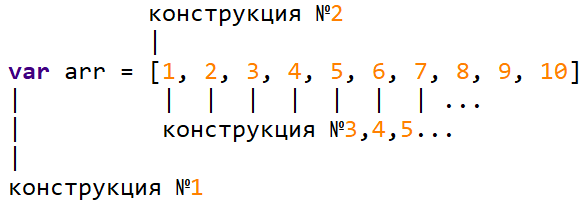
Вы могли слышать о построении дерева кода и его анализа или ещё более заумные вещи. Как всегда — это не более чем загромождение простого страшными терминами. Под анализом кода я понимаю гораздо более простой набор действий. Задача — пробежаться по списку токенов и разобрать код, каждую его конструкцию.
Как правило, в императивных языках код уже представлен в виде своеобразного дерева из конструкций.
Согласитесь, не приемлемо допустим начинать цикл «A» в теле цикла «B», а заканчивать — вне тела цикла «B». Код представляет собой структуру, состоящую из набора конструкций.
А что есть у каждой конструкции? Правильно — начало и конец (и возможно ещё что-то посередине, но не суть).
Соответственно, разбор кода можно сделать однопроходным, толком без построения дерева.
Для этого нужен цикл, который будет пробегать по коду и большущий switch-case, который будет выполнять основной разбор кода и анализ.
Т.е. пробегаем по токенам, перед нами токен (например пусть будет. ) «if» — очень уж сомневаюсь, что такой токен может стоять в коде просто так -> это начало конструкции if..then[..else]..end!
Выполняем разбор всех последующих токенов, соответствующим образом для конструкции условий в нашем языке.
Немного об ошибках в коде
На этапе разбора конструкций и пробега по коду, на обработку ошибок лучше не забивать. Это полезный функционал транслятора. Если в ходе разбора конструкции возникает ошибка, то логично — конструкция построена не должным образом и следует уведомить об этом разработчика.
Теперь о Mash. Как происходит разбор языковых конструкций?
Выше я описал обобщенный концепт устройства транслятора. Теперь настало время поговорить о моих наработках.
По сути транслятор получился очень даже похожим на описанное выше. Но у меня он не разбивает код на кучу токенов для дальнейшего анализа.
Перед началом разбора код приводится в более красивый вид. Удаляются комментарии и все конструкции соединяются в длинные строки, если они описаны в несколько строк.
Таким образом, в каждой отдельно взятой строке находится языковая конструкция либо её часть. Это классно, теперь мы можем разбирать каждую строку в нашем большом switch-case, вместо поиска этих конструкций в наборе токенов. Также плюсом тут выступает то, что строка имеет конец и значит определять ошибки в конструкции с таким подходом проще.
Соответственно разбор отдельных конструкций происходит отдельными методами, которые возвращают промежуточное представление кода конструкций или её частей.
П.с. в предыдущей статье я описал построение транслятора с промежуточного языка в байткод для ВМ. Собственно — этот промежуточный язык и является промежуточным представлением.
Стоит понимать, что конструкции могут состоять из нескольких более простых конструкций. Т.к. у нас разбор каждой конструкции описан отдельными методами, то мы можем без проблем вызывать их друг из друга при разборе каждой конструкции.
Разминочная пробежка по коду
Для начала транслятору стоит бегло ознакомиться с кодом, пробежавшись по нему и уделив внимание некоторым конструкциям.
На этом этапе можно разобраться с глобальными переменными, uses конструкциями, а также импортами, процедурами interface uses Classes, SysUtils; type TBlockEntryType = (btProc, btFunc, btIf, btFor, btWhile, btUntil, btTry, btClass, btSwitch, btCase); TCodeBlock = class(TObject) public bType: TBlockEntryType; mName, bMeta, bMCode, bEndCode: string; constructor Create(bt: TBlockEntryType; MT, MC, EC: string); end; implementation constructor TCodeBlock.Create(bt: TBlockEntryType; MT, MC, EC: string); begin inherited Create; bType := bt; bMeta := MT; bMCode := MC; bEndCode := EC; end; end.
Ну и стек — простой TList, изобретать велосипед тут просто глупо.
Таким образом, разбор конструкции, допустим того же while цикла выглядит так:
function ParseWhile(s: string; varmgr: TVarManager): string; var WhileNum, ExprCode: string; begin Delete(s, 1, 5); //»while» Delete(s, Length(s), 1); //»:» s := Trim(s); //Циклов в коде много, а в промежуточном представлении структуры кода нету. //Нужно точки входа все же отличать как то 🙂 WhileNum := ‘__gen_while_’ + IntToStr(WhileBlCounter); Inc(WhileBlCounter); //Номер очередной конструкции while в коде //Метод проверяет, является ли строка логическим или математическим выражением if IsExpr(s) then ExprCode := PreprocessExpression(s, varmgr) else ExprCode := PushIt(s, varmgr); //Теперь в ExprCode лежит промежуточное представление выражения //Результат после выполнения будет лежать в вершине стека //Проверка условия перед итерацией //(промежуточное представление ставится на место начала конструкции) Result := WhileNum + ‘:’ + sLineBreak + ‘pushcp ‘ + WhileNum + ‘_end’ + sLineBreak + ExprCode + sLineBreak + ‘jz’ + sLineBreak + ‘pop’; //Ну и соответственно генерация кода на завершение конструкции //Последний аргумент — название точки входа на выход из цикла //нужен для генератора break BlockStack.Add(TCodeBlock.Create(btWhile, », ‘pushcp ‘ + WhileNum + sLineBreak + ‘jp’ + sLineBreak + WhileNum + ‘_end:’, WhileNum + ‘_end’)); end;
Про математические выражения
Возможно вы могли этого не замечать, но математические/логические выражения — это тоже структурированный код.
Их разбор я реализовывал стековым путем. Сначала все отдельные элементы выражения ложатся в стек, затем в несколько проходов генерируется код промежуточного представления.
В несколько раз — т.к. есть приоритетные математические операции, такие как умножение.
Код тут приводить не вижу смысла, т.к. его много и он скучный.
П.с. /lang/u_prep_expressions.pas — тут он целиком и полностью выставлен на ваше обозрение.
Итоги
Итак, мы реализовали транслятор, который может преобразовать… Например такой вот код:
А теперь небольшой опрос (чтобы я смотрел на него и радовался значимости своих статей):
Источник: habr.com
Презентация на тему Трансляция языков программирования
Программа, написанная на языке высокого уровня (Object Pascal, Delphi, C++, C#, Java и др.) перед исполнением должна быть преобразована в программу на машинном языке. Трансляция (или компиляция) программы – процесс, в результате которого выполняется разбор кода программы и
- Главная
- Информатика
- Трансляция языков программирования












Слайды и текст этой презентации
Слайд 1 Компилируемые и интерпретируемые языки программирования
Виды трансляторов
3. Фазы трансляции
3.1.
Синтаксис и семантика языков программирования
3.2. Фаза анализа программы
3.3. Фаза
синтеза программы
4. Выполнимые файлы
Слайд 2
Программа, написанная на языке высокого уровня (Object
Pascal, Delphi, C++, C#, Java и др.) перед исполнением
должна быть преобразована в программу на машинном языке.
Трансляция (или компиляция)
программы – процесс, в результате которого выполняется разбор кода программы и формируется выполнимый или интерпретируемый код.
По типу выходных данных существует два основных вида трансляторов:
— компилирующие окончательный выполнимый код;
— компилирующие интерпретируемый код (требуется доп. ПО)
ПРИМЕРЫ:
Окончательный выполнимый код – приложения, реализованные как:
EXE-файлы, DLL-библиотеки, COM-компоненты
Интерпретируемый код:
– байт-код Java-программ, выполняемых на виртуальной машине JVM (Java Virtual Machine);
– код управляемых приложений на C# или С++, использующие среду выполнения CLR (Common Language Runtime);
– JavaScript, LISP, Perl, PROLOG, Smalltalk.
1. Компилируемые и интерпретируемые языки программирования
Слайд 3 Знать к экзамену(!)
соответственно:
Компилируемые языки программирования – язык, исходный
код которого преобразуется компилятором в машинный код и записывается в
файл, с особым заголовком и/или расширением, для последующей идентификации этого
файла операционной системой, формирующей окончательный исполняемый/выполнимый код для непосредственного выполнения центральным процессом компьютера.
Примеры: C, C++, Pascal, Object Pascal, Delphi, FORTRAN, Ada и мн.др.
Интерпретируемые языки программирования – язык, в котором исходный код программы не преобразуется в машинный код для непосредственного выполнения центральным процессором (как в компилируемых ЯП), а выполняется/исполняется с помощью специальной программы-интерпре-татора, т.е. это язык, реализующий интерпретируемый (управляемый) код .
Примеры: Java, LISP, Perl, PROLOG, C# и мн. др.
Особенность среды программирования Visual Studio:
позволяет создавать на C++, как традиционные приложения с выполнимым кодом, так и приложения интерпретируемого (управляемого) кода.
Вывод: Язык программирования C# является и компилируемым, и интерпретируемым.
1. Компилируемые и интерпретируемые языки программирования
Слайд 4
Исходная программа состоит из нескольких программных модулей.
Программный модуль
– это программный код на языке высокого уровня
( ≡ компиляции) может выполняться в 2-х вариантах:
– как единое
целое – компиляция каждого модуля и редактирования связей;
– как два отдельных этапа (реализован в C и C++):
1) компиляция объектных модулей,
2) вызов редактора связей, создающего окончательный вид.
Объектный код, создаваемый компилятором – область данных и область машинных команд, имеющих адреса, которые в дальнейшем «согласуются» редактором связей.
Редактор связей (≡загрузчик) – по отдельности откомпилированные объектные модули и подключаемые библиотеки размещает в едином адресном пространстве.
2. Виды трансляторов
Трансляторы подразделяют на четыре типа:
1. Ассемблер
2. Компилятор
3. Загрузчик
4. Препроцессор (макропроцессор)
Слайд 5
1. Ассемблер – транслятор, выполняющий перевод с
языка Ассемблер на машинный язык конкретного компьютера.
Основные
положения: 1) одна инструкция на Ассемблере переводится в одну
команду на объектном языке (объектный язык на ассемблере – это машинный язык);
2) команды языка ассемблера соответствуют командам процессора (в т.н. мнемокоде – удобной символьной форме записи команд и аргументов);
3) пример инструкции на ассемблере (записывается в отдельной строке, может иметь метку, комментарий записывается после «;»):
LabelA:
push ebp
mov ebp, esp
add esp, 0FFFFFFF8h ; прибавляется -8 к регистру esp
mov esp, ebp
pop ebp
ret
4) каждая модель процессора имеет свой набор команд, поэтому язык ассемблера всегда привязан к конкретной процессорной архитектуре;
5) существуют языки ассемблера высокого уровня – MASM (Microsoft Macro Assembler). MASM v.8 – в среде программирования Visual Studio .NET.
2. Виды трансляторов
Слайд 6
2. Компилятор – транслятор, выполняющий перевод программы
с языка высокого уровня в выполнимую или интерпретируемую форму.
3. Загрузчик – транслятор, выполняющий редактирование связей уже
откомпилированных модулей.
Основные положения: 1) исходный программный код для загрузчика представляется на машинном языке,
но в «перемещаемой» форме;
2) загрузчик соединяет воедино все программные модули, выполняя согласование их адресов;
4. Препроцессор (или макропроцессор) – транслятор, исходным языком которого является расширение языка высокого уровня, а объектным кодом – программа на языке высокого уровня (ЯВУ).
Основные положения: 1) в большинстве современных языков программирования применяются директивы компиляции, обрабатываемые препроцессором;
2) для трансляции программы в одной ОС с целью выполнения программы на ЯВУ в другой ОС существуют кросс-компиляторы: позволяют получать код для еще только разрабатываемой платформы;
2. Виды трансляторов
Дизассемблирование – процесс преобразования кода с ассемблера на язык более высокого уровня.
Слайд 7
3. Фазы трансляции
Слайд 8
Для любого языка программирования (ЯП) перед разработкой транслятора
должна быть определена спецификация данного ЯП – описание синтаксиса
и семантики ЯП.
Основное назначение синтаксиса языка программирования – формирование системы
обозначений, служащей для обмена информацией между программистом и транслятором.
К синтаксическим элементам ЯП относятся (подготовить к экзамену – примеры):
— набор символов (как правило 1-байтовое представление);
— идентификаторы (определяются символы, с которых может начинаться
идентификатор, разрешенные символы в идентификаторах, длина идентификаторов);
— символы операций;
— ключевые и зарезервированные слова;
— необязательные слова (для облегчения читаемости программы, но при этом «утяжеляется» синтаксис языка);
— комментарии;
— пробелы (в ЯП С++ пробелы используются как разделители и их число везде
игнорируется кроме литералов);
— разделители и скобки (синтаксический элемент, определяющий начало или конец синтаксической конструкции; разрешение неоднозначности);
— выражения;
— операторы (синтаксис операторов определяет регулярность языка и удобство записи программы)
Семантика ЯП – совокупность правил, определяющих смысл языковых конструкций и программы в целом. (подготовить к экзамену – примеры)
3.1. Синтаксис и семантика языков программирования
Слайд 9
Фаза анализа программы включает 3 этапа:
1.
Лексический анализ;
2. Синтаксический анализ;
3. Семантический анализ.
При анализе исходной программы
транслятор последовательно просматривает текст программы в виде набора символов, выполняя
разбор структуры программы:
1. Лексический анализ: выделяются основные составляющие программы – лексемы.
Лексемы – ключевые слова, идентификаторы, символы операций, комментарии, пробелы и разделители.
Лексический анализатор не только выделяет, но и определяет тип каждой лексемы. В итоге составляется таблица символов, в которой каждому идентификатору сопоставлен свой адрес, что позволяет при дальнейшем анализе вместо конкретного значения (строки символов) использовать его адрес в таблице символов.
Процесс выделения лексем использует сложные контекстно-зависимые алгоритмы.
3.2. Фаза анализа программы
Слайд 10
2. Синтаксический анализ – разбор полученных лексем с
целью получения семантически понятных синтаксических единиц, которые затем обраба-тываются
семантическим анализатором.
Синтаксические единицы – выражения, объявления, операторы ЯП, вызовы функций
и/или процедур.
3. Семантический анализ – обработка синтаксических единиц и создание промежуточного кода.
В зависимости от наличия или отсутствия Фазы оптимизации результатом семантического анализа является оптимизируемый далее промежуточный код или готовый объектный код.
Для взаимодействия между синтаксическим и семантическим анализаторами может использоваться стек: синтаксический анализатор заносит в стек элементы синтаксической структуры, а семантический анализатор извлекает эти элементы и обрабатывает.
Основные задачи, решаемые семантическим анализатором:
— обнаружение ошибок времени компиляции;
— заполнение таблицы символов, созданной на этапе лексического анализа, конкретными значениями, определяющими дополнительную информацию о каждом элементе таблицы;
— замена макросов (некоторый предварительно определенный код) их определениями;
— выполнение директив времени компиляции (позволяет управлять процессом трансляции).
3.2. Фаза анализа программы
Слайд 11
Фаза синтеза программы включает 2 этапа:
1. Генерация кода
2.
Редактирование связей
1. Генерация кода – преобразование промежуточного кода (или
оптими- зированного кода) в объектный код. В зависимости от конкретного ЯП
получаемый объектный код может быть представлен в выполнимой форме или как объектный модуль, подлежащий дальнейшей обработке редактором связей.
3. Редактирование связей – приведение в соответствие адреса фрагментов кода, расположенных в отдельных объектных модулях: определяются адреса вызываемых внешних функций, адреса внешних переменных, адреса функций и методов каждого модуля. Для редактирования адресов редактор связей использует специальные, создаваемые на этапе транс-ляции, таблицы загрузчика.
После обработки объектных модулей редактором связей генерируется выполнимая форма программы.
3.3. Фаза синтеза программы
Слайд 12
— Изучить самостоятельно:
стр. 20-23 (Баженова
И.Ю. Языки программирования)
4. Выполнимые файлы
Источник: mypreza.com