
При размещении БД на персональном компьютере, который не находится в сети, БД всегда используется в монопольном режиме. Даже если БД используют несколько пользователей, они могут работать с ней только последовательно, и поэтому вопросов о поддержании корректной модификации БД в этом случае здесь не стоит, они решаются организационными мерами — то есть определением требуемой последовательности работы конкретных пользователей с соответствующей БД . Однако даже в некоторых настольных БД требуется учитывать последовательность изменения данных при обработке, чтобы получить корректный результат: так, например, при запуске программы балансного бухгалтерского отчета все бухгалтерские проводки — финансовые операции должны быть решены заранее до запуска конечного приложения.
Однако работа на изолированном компьютере с небольшой базой данных в настоящий момент становится уже нехарактерной для большинства приложений. БД отражает информационную модель реальной предметной области , она растет по объему и резко увеличивается количество задач, решаемых с ее использованием, и в соответствии с этим увеличивается количество приложений, работающих с единой базой данных. Компьютеры объединяются в локальные сети , и необходимость распределения приложений, работающих с единой базой данных по сети, является несомненной.
Как решать задачи на программирование во время собеседований
Действительно, даже когда вы строите БД для небольшой торговой фирмы, у вас появляется ряд специфических пользователей БД , которые имеют свои бизнес-функции и территориально могут находиться в разных помещениях, но все они должны работать с единой информационной моделью организации, то есть с единой базой данных.
Параллельный доступ к одной БД нескольких пользователей, в том случае если БД расположена на одной машине, соответствует режиму распределенного доступа к централизованной БД . (Такие системы называются системами распределенной обработки данных.)
Если же БД распределена по нескольким компьютерам, расположенным в сети, и к ней возможен параллельный доступ нескольких пользователей, то мы имеем дело с параллельным доступом к распределенной БД . Подобные системы называются системами распределенных баз данных. В общем случае режимы использования БД можно представить в следующем виде (см. рис. 10.1).
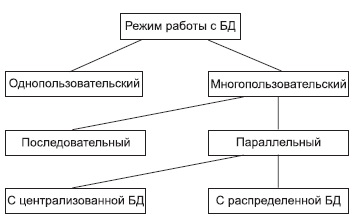
Рис. 10.1. Режимы работы с базой данных
Определим терминологию, которая нам потребуется для дальнейшей работы. Часть терминов нам уже известна, но повторим здесь их дополнительно.
Терминология
Пользователь БД — программа или человек, обращающийся к БД на ЯМД.
Запрос — процесс обращения пользователя к БД с целью ввода, получения или изменения информации в БД .
Транзакция — последовательность операций модификации данных в БД , переводящая БД из одного непротиворечивого состояния в другое непротиворечивое состояние.
Логическая структура БД — определение БД на физически независимом уровне, ближе всего соответствует концептуальной модели БД .
Решение задачи «Проверка пароля» по теме «Определение и вызов функции. Инструкция def»
Топология БД = Структура распределенной БД — схема распределения физической БД по сети.
Локальная автономность — означает, что информация локальной БД и связанные с ней определения данных принадлежат локальному владельцу и им управляются.
Удаленный запрос — запрос , который выполняется с использованием модемной связи.
Возможность реализации удаленной транзакции обработка одной транзакции, состоящей из множества SQL -запросов на одном удаленном узле.
Поддержка распределенной транзакции допускает обработку транзакции, состоящей из нескольких запросов SQL , которые выполняются на нескольких узлах сети (удаленных или локальных), но каждый запрос в этом случае обрабатывается только на одном узле, то есть запросы не являются распределенными. При обработке одной распределенной транзакции разные локальные запросы могут обрабатываться в разных узлах сети.
Распределенный запрос — запрос , при обработке которого используются данные из БД , расположенные в разных узлах сети.
Системы распределенной обработки данных в основном связаны с первым поколением БД , которые строились на мультипрограммных операционных системах и использовали централизованное хранение БД на устройствах внешней памяти центральной ЭВМ и терминальный многопользовательский режим доступа к ней. При этом пользовательские терминалы не имели собственных ресурсов — то есть процессоров и памяти, которые могли бы использоваться для хранения и обработки данных. Первой полностью реляционной системой, работающей в многопользовательском режиме, была СУБД SYSTEM R, разработанная фирмой IBM , именно в ней были реализованы как язык манипулирования данными SQL , так и основные принципы синхронизации, применяемые при распределенной обработке данных, которые до сих пор являются базисными практически во всех коммерческих СУБД .
Общая тенденция движения от отдельных mainframe -систем к открытым распределенным системам, объединяющим компьютеры среднего класса, получила название DownSizing . Этот процесс оказал огромное влияние на развитие архитектур СУБД и поставил перед их разработчиками ряд сложных задач. Главная проблема состояла в технологической сложности перехода от централизованного управления данными на одном компьютере и СУБД , использовавшей собственные модели, форматы представления данных и языки доступа к данным и т. д., к распределенной обработке данных в неоднородной вычислительной среде, состоящей из соединенных в глобальную сеть компьютеров различных моделей и производителей.
В то же время происходил встречный процесс — UpSizing . Бурное развитие персональных компьютеров, появление локальных сетей также оказали серьезное влияние на эволюцию СУБД . Высокие темпы роста производительности и функциональных возможностей PC привлекли внимание разработчиков профессиональных СУБД , что привело к их активному распространению на платформе настольных систем.
Сегодня возобладала тенденция создания информационных систем на такой платформе, которая точно соответствовала бы ее масштабам и задачам. Она получила название RightSizing (помещение ровно в тот размер, который необходим).
Однако и в настоящее время большие ЭВМ сохраняются и сосуществуют с современными открытыми системами. Причина этого проста — в свое время в аппаратное и программное обеспечение больших ЭВМ были вложены огромные средства: в результате многие продолжают их использовать, несмотря на морально устаревшую архитектуру. В то же время перенос данных и программ с больших ЭВМ на компьютеры нового поколения сам по себе представляет сложную техническую проблему и требует значительных затрат.
Модели «клиент-сервер» в технологии баз данных
Вычислительная модель «клиент— сервер » исходно связана с парадигмой открытых систем, которая появилась в 90-х годах и быстро эволюционировала. Сам термин «клиент- сервер » исходно применялся к архитектуре программного обеспечения, которое описывало распределение процесса выполнения по принципу взаимодействия двух программных процессов, один из которых в этой модели назывался «клиентом», а другой — «сервером». Клиентский процесс запрашивал некоторые услуги, а серверный процесс обеспечивал их выполнение. При этом предполагалось, что один серверный процесс может обслужить множество клиентских процессов.
Ранее приложение (пользовательская программа ) не разделялась на части, оно выполнялось некоторым монолитным блоком. Но возникла идея более рационального использования ресурсов сети. Действительно, при монолитном исполнении используются ресурсы только одного компьютера, а остальные компьютеры в сети рассматриваются как терминалы. Но теперь, в отличие от эпохи main-фреймов, все компьютеры в сети обладают собственными ресурсами, и разумно так распределить нагрузку на них, чтобы максимальным образом использовать их ресурсы.
И как в промышленности, здесь возникает древняя как мир идея распределения обязанностей , разделения труда. Конвейеры Форда сделали в свое время прорыв в автомобильной промышленности, показав наивысшую производительность труда именно из-за того, что весь процесс сборки был разбит на мелкие и максимально простые операции и каждый рабочий специализировался на выполнении только одной операции , но эту операцию он выполнял максимально быстро и качественно.
Конечно, в вычислительной технике нельзя было напрямую использовать технологию автомобильного или любого другого механического производства, но идею использовать было можно. Однако для воплощения идеи необходимо было разработать модель разбиения единого монолитного приложения на отдельные части и определить принципы взаимосвязи между этими частями.
Основной принцип технологии «клиент— сервер » применительно к технологии баз данных заключается в разделении функций стандартного интерактивного приложения на 5 групп, имеющих различную природу:
- функции ввода и отображения данных (Presentation Logic);
- прикладные функции, определяющие основные алгоритмы решения задач приложения ( Business Logic );
- функции обработки данных внутри приложения (Database Logic);
- функции управления информационными ресурсами ( Database Manager System);
- служебные функции, играющие роль связок между функциями первых четырех групп.
Структура типового приложения, работающего с базой данных приведена на рис. 10.2.
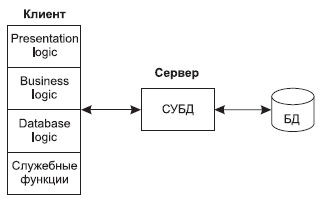
Рис. 10.2. Структура типового интерактивного приложения, работающего с базой данных
Презентационная логика ( Presentation Logic ) как часть приложения определяется тем, что пользователь видит на своем экране, когда работает приложение . Сюда относятся все интерфейсные экранные формы, которые пользователь видит или заполняет в ходе работы приложения, к этой же части относится все то, что выводится пользователю на экран как результаты решения некоторых промежуточных задач либо как справочная информация . Поэтому основными задачами презентационной логики являются:
- формирование экранных изображений;
- чтение и запись в экранные формы информации;
- управление экраном;
- обработка движений мыши и нажатие клавиш клавиатуры.
Некоторые возможности для организации презентационной логики приложений предоставляет знако-ориентированный пользовательский интерфейс , задаваемый моделями CCIS ( Customer Control Information System ) и IMS /DC фирмы IBM и моделью TSO ( Time Sharing Option ) для централизованной main-фреймовой архитектуры. Модель GUI — графического пользовательского интерфейса, поддерживается в операционных средах Microsoft’s Windows , Windows NT, в OS/2 Presentation Manager , X- Windows и OSF / Motif .
Бизнес-логика, или логика собственно приложений (Business processing Logic ), — это часть кода приложения, которая определяет собственно алгоритмы решения конкретных задач приложения. Обычно этот код пишется с использованием различных языков программирования, таких как C, C++, Cobol, SmallTalk, Visual-Basic.
Логика обработки данных ( Data manipulation Logic ) — это часть кода приложения, которая связана с обработкой данных внутри приложения. Данными управляет собственно СУБД ( DBMS ). Для обеспечения доступа к данным используются язык запросов и средства манипулирования данными стандартного языка SQL .
Обычно операторы языка SQL встраиваются в языки 3-го или 4-го поколения ( 3GL , 4GL ), которые используются для написания кода приложения.
Процессор управления данными ( Database Manager System Processing ) — это собственно СУБД , которая обеспечивает хранение и управление базами данных. В идеале функции СУБД должны быть скрыты от бизнес-логики приложения, однако для рассмотрения архитектуры приложения нам надо их выделить в отдельную часть приложения.
В централизованной архитектуре (Host-based processing ) эти части приложения располагаются в единой среде и комбинируются внутри одной исполняемой программы.
В децентрализованной архитектуре эти задачи могут быть по-разному распределены между серверным и клиентским процессами. В зависимости от характера распределения можно выделить следующие модели распределений (см. рис. 10.3):
- распределенная презентация (Distribution presentation, DP);
- удаленная презентация (Remote Presentation, RP );
- распределенная бизнес-логика (Distributed Business Logic, DBL);
- распределенное управление данными (Distributed data management , DDM );
- удаленное управление данными (Remote data management , RDM ).
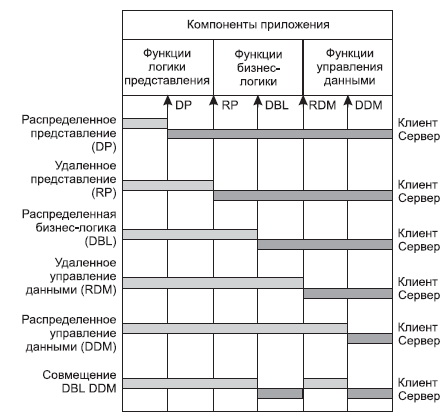
Рис. 10.3. Распределение функций приложения в моделях «клиент—сервер»
Эта условная классификация показывет, как могут быть распределены отдельные задачи между серверным и клиенскими процессами. В этой классификации отсутствует реализация удаленной бизнес-логики. Действительно, считается, что она не может быть удалена сама по себе полностью. Считается, что она может быть распределена между разными процессами, которые в общем-то могут выполняться на разных платформах, но должны корректно кооперироваться (взаимодействовать) друг с другом.
Источник: intuit.ru
Разработка и эксплуатация клиентской части

Основной принцип технологии «клиент-сервер» заключается в
разделении функций приложения на три группы:
• ввод и отображение данных (взаимодействие с пользователем);
• прикладные функции, характерные для данной предметной области;
• функции управления ресурсами (файловой системой, базой даных и т.д.)
Поэтому, в любом приложении выделяются
следующие компоненты:
• компонент представления данных
• прикладной компонент
• компонент управления ресурсом
3.
Компанией Gartner Group, специализирующейся в области
исследования информационных технологий, предложена
следующая классификация двухзвенных моделей
взаимодействия клиент-сервер (двухзвенными эти модели
называются потому, что три компонента приложения
различным образом распределяются между двумя узлами):
4.
Исторически первой появилась модель распределенного представления
данных, которая реализовывалась на универсальной ЭВМ с
подключенными к ней неинтеллектуальными терминалами.
Управление данными и взаимодействие с пользователем при этом
объединялись в одной программе, на терминал передавалась только
«картинка», сформированная на центральном компьютере.
Затем, с появлением персональных компьютеров (ПК) и локальных
сетей, были реализованы модели доступа к удаленной базе данных.
Некоторое время базовой для сетей ПК была архитектура файлового
сервера. При этом один из компьютеров является файловым сервером,
на клиентах выполняются приложения, в которых совмещены
компонент представления и прикладной компонент (СУБД и
прикладная программма). Протокол обмена при этом представляет
набор низкоуровненых вызовов операций файловой системы. Такая
архитектура, реализуемая, как правило, с помощью персональных
СУБД, имеет очевидные недостатки — высокий сетевой трафик и
отсутствие унифицированного доступа к ресурсам.
5.
С появлением первых специализированных серверов баз
данных появилась возможность другой реализации модели
доступа к удаленной базе данных. В этом случае ядро СУБД
функционирует на сервере, протокол обмена обеспечивается с
помощью языка SQL. Такой подход по сравнению с файловым
сервером ведет к уменьшению загрузки сети и унификации
интерфейса «клиент-сервер». Однако, сетевой трафик
остается достаточно высоким, кроме того, по прежнему
невозможно удовлетворительное администрирование
приложений, поскольку в одной программе совмещаются
различные функции.
6.
Позже была разработана концепция активного сервера, который
использовал механизм хранимых процедур. Это позволило часть
прикладного компонента перенести на сервер (модель
распределенного приложения). Процедуры хранятся в словаре
базы данных, разделяются между несколькими клиентами и
выполняются на том же компьютере, что и SQL-сервер.
Преимущества такого подхода: возможно централизованное
администрирование прикладных функций, значительно
снижается сетевой трафик (т.к. передаются не SQL-запросы, а
вызовы хранимых процедур). Недостаток — ограниченность
средств разработки хранимых процедур по сравнению с языками
общего назначения (C и Pascal).
7.
На практике сейчас обычно используются смешанный
подход:
• простейшие прикладные функции выполняются
хранимыми процедурами на сервере
• более сложные реализуются на клиенте непосредственно в
прикладной программе
8.
Сейчас ряд поставщиков коммерческих СУБД
объявило о планах реализации механизмов
выполнения хранимых процедур с
использованием языка Java. Это соответствует
концепции «тонкого клиента», функцией
которого остается только отображение данных
(модель удаленного представления данных).
9.
В последнее время также наблюдается тенденция ко все большему
использованию модели распределенного приложения. Характерной
чертой таких приложений является логическое разделение
приложения на две и более частей, каждая из которых может
выполняться на отдельном компьютере. Выделенные части
приложения взаимодействуют друг с другом, обмениваясь
сообщениями в заранее согласованном формате. В этом случае
двухзвенная архитектура клиент-сервер становится трехзвенной, а к
некоторых случаях, она может включать и больше звеньев.
10.
Термин «клиент-сервер» исходно применялся в
архитектуре ПО, которое ориентировало распределение
процесса выполнения по принципу взаимодействия 2-х
программ, процессов, один из которых в этой модели
назывался клиентом, а другой — сервером. При этом
предполагалось, что один серверный процесс может
обслуживать множество клиентских процессов.
11.
Ранее приложение (пользовательская программа)
не разделялось на части, а выполнялось
монолитным блоком, но при рациональном
использовании ресурсов сети данный принцип не
актуален.
12.
Теперь все ПК в сети обладают собственными ресурсами и разумно
так распределить нагрузку на них, чтобы максимальным образом
использовать их ресурсы. Основной принцип технологии «клиентсервер» в БД заключается в разделении функций стандартного
интерактивного приложения на 5 групп:
1. Функция ввода и отображения данных (PL);
2. Прикладные функции, определяющие основные алгоритмы решения
задач приложения (BL);
3. Функции обработки данных внутри приложения (DL);
4. Функции управления информационными ресурсами (DML);
5. Служебные функции, играющие роль связок между функциями 1-х и
4-х групп.
13.
PL — это часть приложения, которая определяется тем, что
пользователь видит на экране, когда работает приложение
(интерактивные экранные формы, а также все то, что выводится
пользователю на экран, результаты решения некоторых
промежуточных задач, справочная информация).
Основные задачи PL:
• формирование экранных изображений;
• чтение и запись в экранные формы информации;
• управление экраном;
• обработка движений мыши и нажатий клавиш клавиатуры.
14.
BL — это часть кода приложения, которая определяет алгоритмы
решения конкретных задач приложения. Обычно этот код пишется с
использованием различных языков программирования.
DL — это часть кода приложения, которая связана с обработкой
данных внутри приложения (данными управляет собственно СУБД),
где используется язык запросов и средства манипулирования
данными стандартного языка SQL.
Процессор управления данными (Data Base Manager System
Processing) — это собственно СУБД, которая обеспечивает управление
и хранение данных. В идеале СУБД должна быть скрыта от BLприложения. Однако для рассмотрения архитектуры приложения
нам надо их выделить в отдельную часть приложения.
Источник: ppt-online.org
Модели клиент-сервер в технологии БД
1. Модели клиент- сервер в технологии БД Вычислительная модель клиент-сервер исходно связана с парадигмой открытых систем, которая появилась в 90-х годах и быстро развивалась. Термин клиент-сервер исходно применялся к архитектуре, при которой клиентский процесс запрашивает некоторые услуги, а серверный процесс обеспечивает их выполнение.
Реализация архитектуры клиент — сервер, применительно к разработке БД позволяет более полно использовать ресурсы сети. Нагрузка равномерно распределяется между компьютером сервером и компьютером клиентом, который также как и сервер обладает собственными ресурсами. Основной принцип технологии клиент – сервер применительно к технологии БД заключается в разделении функций стандартного интерактивного приложения на 5 групп, имеющих различную природу: · Функции ввода и отображения данных (Presentation Logic). · Прикладные функции, определяющие основные алгоритмы решения задач приложения (Business Logic). · Функции обработки данных внутри приложения (Database Logic). · Функции управления информационными ресурсами (Database Manager System). · Служебные функции, играющие роль связок между функциями первых 4-х групп.
Рекомендуемые материалы
Ответы на Аттестацию официального партнера amoCRM 2023
Информатика
Тест 2 верен на 95%
Программирование и алгоритмизация
Ответы на экзамен верны на 100%
Программирование и алгоритмизация
Расчетно-графическая работа по курсу «Программирование». Семинар 2. Обработка символьной информации. Вариант 18
Программирование и алгоритмизация
Расчетно-графическая работа по курсу «Программирование». Семинар 2. Обработка символьной информации. Вариант 17
Программирование и алгоритмизация
Вопросы и ответы из теста по 1С Платформе 8.3.
Информатика
Структура типового интерактивного приложения, работающего с БД, приведена на рисунке 2.
Презентационная логика – эта часть приложения, определяющая то, что пользователь видит на экране. Сюда относятся, интерфейсные экранные формы, а также все, что выводится пользователю на экран, как результаты решения промежуточных задач или справочная информация.
Основными задачами презентационной логики являются: · Формирование экранных изображений; · чтение и запись в экранные формы информации; · управление экраном; · обработка движений мыши и нажатия клавиш клавиатуры. Бизнес- логика или логика приложений — это часть кода приложения, которая определяет собственно алгоритмы решения задач приложения.
Обычно этот код пишется с помощью различных языков программирования: С, Соbol, Visual Basic. Логика обработки данных — это часть кода приложения, которая связана с обработкой данных внутри приложения. Данными управляет собственно СУБД. Для обеспечения доступа к данным используются язык запросов и средства манипулирования данными языка SQL.
Процессор управления данными – это собственно СУБД, которая обеспечивает хранение и управление БД. В централизованной архитектуре эти функции располагаются в единой среде и комбинируются внутри исполняемой программы. В децентрализованной архитектуре эти задачи могут быть по-разному распределены между серверным и клиентским процессами.
В зависимости от характера распределения можно выделить следующие модели распределений: · распределенная презентация; (часть представления на клиенте, часть на сервере, на севере – все остальные части) · удаленная презентация; (вся презентация на клиенте – все остальное на сервере) · распределенная бизнес логика; (презентация и часть бизнес-логики на клиенте) · распределенное управление данными; (презентация, бизнес-логика, и часть управления данными на клиенте); · удаленное управление данными (презентационная и бизнес-логика на клиенте, остальное на сервере). · распределенная БД. Эта классификация показывает, как задачи могут быть распределены между серверным и клиентским процессами.
Двухуровневые модели Двухуровневая модель предполагает распределение всех указанных функций между 2-мя процессами, которые выполняются на 2-х платформах – клиенте и сервере. В чистом виде почти никакая модель не существует. 2. Модель удаленного доступа к данным В этой модели презентационная логика и бизнес-логика располагаются на клиенте. На сервере располагается база данных и ядро СУБД (см. рис.3).
Обращение за сервисом управления данными происходит с помощью языка SQL. Достоинство модели – наличие большого числа готовых СУБД, имеющих SQL — интерфейсы и набор инструментальных средств, обеспечивающих создание клиентских приложений. В этой модели по сети передаются SQL-запросы, в ответ на запросы клиент получает не блоки файлов, а только данные, релевантные запросу.
Основное достоинство – унификация интерфейса клиент- сервер, стандартом при общении клиента и сервера становится язык SQL. Недостатки: достаточно высокая загрузка системы передачи данных, вследствие того, что вся логика сосредоточена в приложении, а обрабатываемые данные расположены на удаленном узле. Эти системы неудобны с точки зрения модификации и сопровождения.
Даже при незначительном изменении функций системы требуется переделка всей прикладной части. Так как на клиенте расположена и презентационная логика и бизнес-логика приложения, то при повторении аналогичных функций в разных приложениях код соответствующей бизнес-логики должен быть повторен для каждого клиентского приложения.
Сервер в этой модели играет пассивную роль, поэтому функции информационного управления должны выполняться на клиенте. Например, если необходимо выполнять контроль страховых запасов на складе, то каждое приложение, которое связано с изменением состояния склада, после выполнения операций модификации данных, имитирующих продажу или удаления товара со склада, должно выполнять проверку на объем остатка. В случае если он меньше страхового запаса, необходимо формировать соответствующую заявку на поставку требуемого товара. Это может вызвать необоснованный заказ дополнительных товаров несколькими приложениями. 3. Удаленная презентация (Модель сервера БД) Модель сервера БД приведена на рисунке 4.
Рисунок 4 Модель сервера БД отличается тем, что функции компьютера клиента ограничиваются представлением информации, в то время как прикладные функции обеспечиваются приложением, находящимся на компьютере-сервере. Эта модель является более технологичной, чем модель удаленного доступа.
Для того чтобы избавиться от недостатков модели удаленного доступа, должны быть соблюдены следующие условия: · Необходимо, чтобы БД, в каждый момент отражала текущее состояние предметной области. · БД должна отражать некоторые правила предметной области, законы, по которым она функционирует. Например, завод может нормально функционировать только в том случае, когда имеется достаточный запас деталей определенной номенклатуры, деталь может быть запущена в производство только в том случае, если на складе имеется достаточно материала для ее изготовления и т.д. · Необходим постоянный контроль над состоянием БД, отслеживание всех изменений и адекватная реакция на них.
Например, при уменьшении товарного запаса ниже критического уровня должна быть сформирована заявка на поставку соответствующего товара. Такую модель поддерживают большинство современных СУБД: Informix, Oracle, Sybase, MS SQL Server.
Основу данной модели составляет механизм хранимых процедур как средство программирования SQL сервера, механизм триггеров как механизм отслеживания текущего состояния информационного хранилища и механизм ограничений на пользовательские типы данных, который называется механизмом поддержки доменной структуры. Процедуры обычно хранятся в словаре БД и разделяются несколькими клиентами.
Хранимые процедуры могут выполняться в режимах интерпретации и компиляции. Клиентское приложение обращается серверу с командой запуска хранимой процедуры, а сервер выполняет эту процедуру и регистрирует все изменения в БД, которые в ней предусмотрены.
Сервер возвращает клиенту данные, соответствующие его запросу, которые требуются либо для вывода на экран, либо для выполнения части бизнес-логики, которая расположена на клиенте. Трафик обмена информацией между клиентом и сервером заметно уменьшается. Централизованный контроль целостности данных в модели сервера БД выполняется с использованием механизма триггеров.
Триггеры также являются частью БД. Термин триггер взят из электроники и семантически точно отражает механизм отслеживания специальных событий, которые связаны с состоянием БД. Ядро СУБД проводит мониторинг всех событий, которые вызывают созданные и описанные триггеры в БД, и при наступлении соответствующего события сервер запускает соответствующий триггер.
Триггер представляет собой некоторую программу, которая выполняется над БД. Триггеры могут вызывать хранимые процедуры. В данной модели сервер является активным, потому что не только клиент, но и сам сервер, используя механизм триггеров, может быть инициатором обработки данных в БД.
И хранимые процедуры, и триггеры хранятся в словаре БД, они могут быть использованы несколькими клиентами, что существенно уменьшает дублирование алгоритмов обработки данных в разных клиентских приложениях. Для написания хранимых процедур и триггеров используется расширения стандартного языка SQL.
Достоинства модели — возможность хорошего централизованного администрирования приложений на этапах разработки, сопровождения и модификации, а также эффективное использование вычислительных и коммуникационных ресурсов. Один из недостатков модели связан с ограничениями средств разработки хранимых процедур.
Основное ограничение — сильная привязка операторов хранимых процедур к используемой СУБД. Язык написания хранимых процедур, по сути, является процедурным расширением языка SQL и не может соперничать по функциональным возможностям с традиционными языками, такими как С или Паскаль. Другой недостаток — очень большая загрузка сервера.
Если мы переложили большую часть бизнес логики приложения на сервер, то требования к клиентам в этой модели резко уменьшаются. Иногда такую модель называют моделью с тонким клиентом, в отличие от предыдущих, где на клиента возлагались гораздо более серьезные задачи.
Возможна модель распределенной бизнес-функции, в которой общая часть бизнес-функций реализована на сервере, а специфические функции обработки информации находятся на клиенте. Функции общего характера могут включать в себя стандартное обеспечение целостности данных, например, в виде хранимых процедур, а оставшиеся прикладные функции реализуют специальную прикладную обработку.
4. Модель распределенной БД Эта модель предполагает использование мощного компьютера клиента, причем данные хранятся и на компьютере-клиенте и на компьютере-сервере. Взаимосвязь обеих БД может быть 2-х разновидностей: а) в локальной и удаленной базах хранятся отдельные части единой БД; б) локальная и удаленная БД являются синхронизируемыми друг с другом копиями.
Достоинство – гибкость разрабатываемых ИС позволяющих компьютеру клиенту обрабатывать и локальные и удаленные БД. Недостаток – высокие затраты при выполнении большого числа одинаковых приложений на компьютерах клиентах. 5. Модель сервера приложений Эта модель является расширением 2-хуровневой модели и в ней вводится дополнительный промежуточный уровень между клиентом и сервером. Этот промежуточный уровень содержит один или несколько серверов приложений.
В этой модели компоненты делятся между тремя исполнителями: 6. Клиент обеспечивает логику представления, включая графический пользовательский интерфейс; клиент может запускать локальный код приложения клиента, который может содержать обращения к локальной БД, находящейся на компьютере- клиенте. Клиент исполняет коммуникационные функции, которые обеспечивают доступ клиенту в локальную или глобальную сеть.
7. Серверы приложений представляет собой новый дополнительный уровень архитектуры. На сервере приложений реализуется несколько прикладных функций, каждая из которых оформлена как служба предоставления услуг всем требующим этого программам. Серверов приложений может быть несколько, причем каждый из них предоставляет свой вид сервиса.
Любая программа, запрашивающая услугу у сервера приложений, является для него клиентом. Поступающие к серверам от клиентов запросы помещаются в очередь. 8. Серверы БД в этой модели занимаются исключительно функциями СУБД: обеспечивают создания и ведения БД, обеспечивают функции хранилищ БД, кроме того, на них возлагаются функции создания резервных копий, восстановления БД после сбоев, управления выполнением транзакций. Эта модель обладает большей гибкостью, чем двухуровневая модель.
9. КОНТРОЛЬНЫЕ ВОПРОСЫ 1. Перечислите основные функции стандартного интерактивного приложения, связанного с обработкой баз данных. 8. Вскрытие штольней — лекция, которая пользуется популярностью у тех, кто читал эту лекцию. 2. Перечислите основные задачи презентационной логики. 3. Что включает в себя бизнес-логика приложения?
4. Перечислите варианты распределения функций стандартного интерактивного приложения в архитектуре клиент-сервер. 5. Назовите основные двухуровневые модели архитектуры клиент-сервер. 6. В чем заключаются особенности модели удаленного доступа к данным? 7. Какими средствами реализуется бизнес-логика при использовании модели удаленной презентации?
Источник: studizba.com