
TextAnalyst разработан в качестве инструмента для анализа содержания текстов, смыслового поиска информации, формирования электронных архивов, и предоставляет пользователю следующие основные возможности:
§ анализ содержания текста с автоматическим формированием семантической сети с гиперссылками — получение смыслового портрета текста в терминах основных понятий и их смысловых связей;
§ анализ содержания текста с автоматическим формированием тематического древа с гиперссылками — выявление семантической структуры текста в виде иерархии тем и подтем;
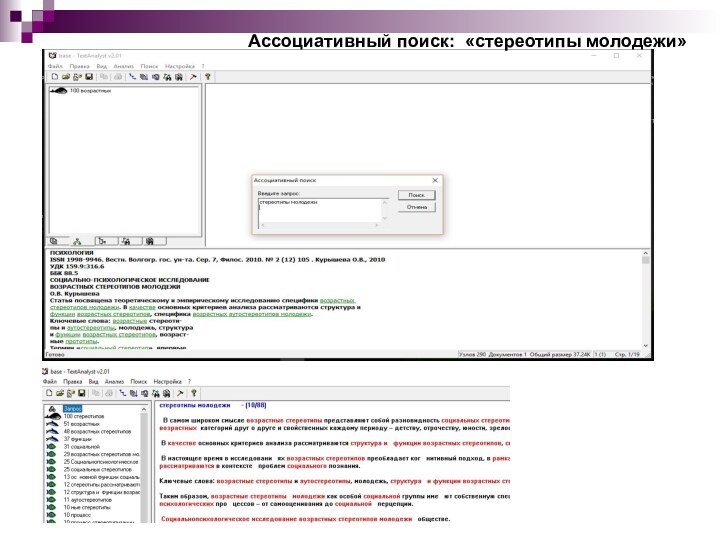
§ смысловой поиск с учетом скрытых смысловых связей слов запроса со словами текста;
§ автоматическое реферирование текста — формирование его смыслового портрета в терминах наиболее информативных фраз;
§ кластеризация информации — анализ распределения материала текстов по тематическим классам;
§ автоматическая индексация текста с преобразованием в гипертекст;
§ ранжирование всех видов информации о семантике текста по «степени значимости» с возможностью варьирования детальности ее исследования;
The Boy Band Con: The Lou Pearlman Story
§ автоматическое/автоматизированное формирование полнотекстовой базы знаний с гипертекстовой структурой и возможностями ассоциативного доступа к информации.
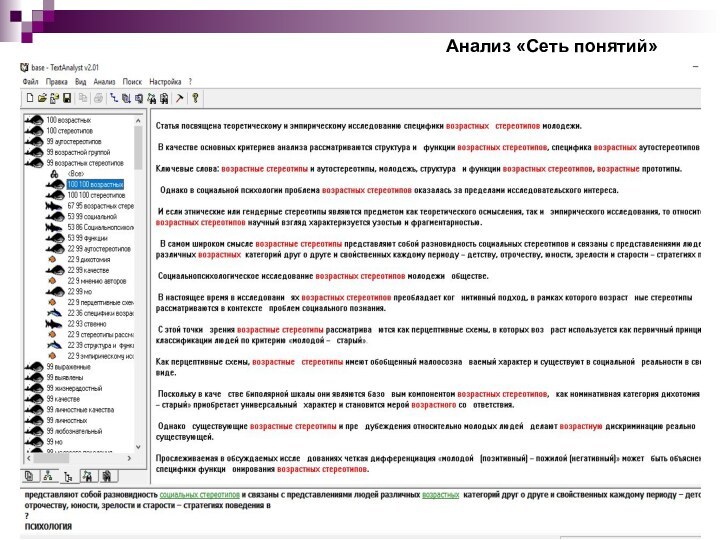
Рассмотрим на нашем примере работу этой программы. После запуска TextAnalyst, необходимо открыть текстовый файл, в котором расположен HTML-документ нашего примера. Программа выполняет анализ предложенного текста и выдает результаты (см. рисунок)

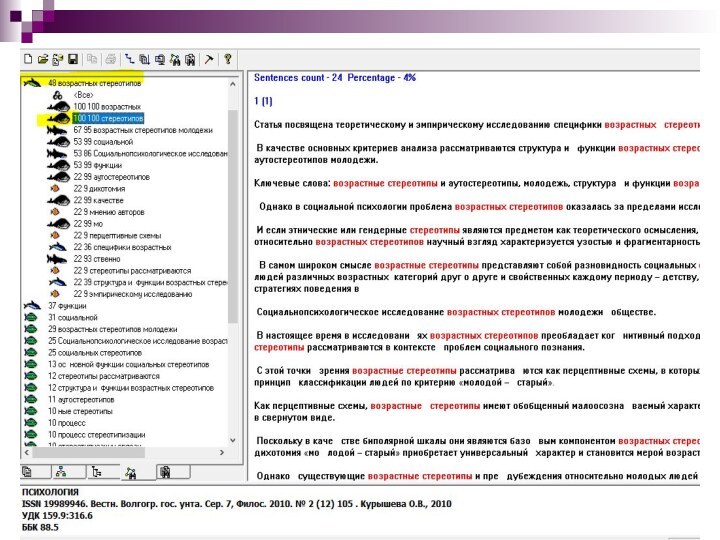
Каждый элемент сети характеризуется числовой оценкой – смысловым весом. Связи между понятиями также характеризуются весами. Значение смыслового веса (от 1 до 100) показывает, насколько важную роль играет понятие для смысла всего текста, т.е. как много информации в тексте касается данного понятия.
Максимальное значение, равное 100, говорит о том, что понятие является ключевым и представляет важнейшую тему текста. Маленькое, близкое к единице значение показывает, что соответствующая тема лишь вскользь упомянута в тексте и в нем очень мало информации, относящейся к данному понятию. Второе число, стоящее перед смысловым весом, ближе к раскрытому узлу, представляет вес связи от понятия в вершине раскрытого списка к данному. Большое значение веса связи (близкое к 100) указывает на то, что подавляющая часть информации в тексте, касающаяся первого, касается в то же время и второго понятия. Малое (близкое к 1) значение означает, что первое понятие слабо связано со вторым и очень мало информации по первой теме касается в тоже время и второй.
По умолчанию на экране отображаются понятия с весом не менее 5. Вид сети на экране можно настраивать, изменяя количество отображаемых понятий и связей, а также способ их сортировки.
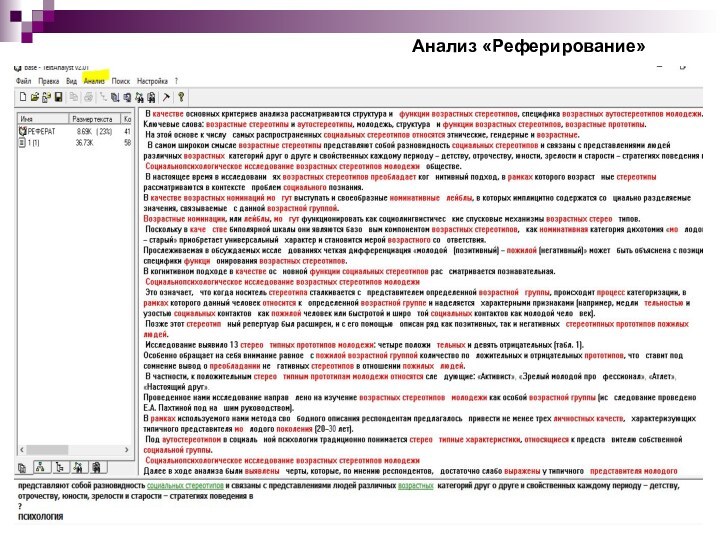
В нашем примере реферат выглядит таким образом:
98 анализа содержания текста с автоматическим формированием семантической сети с гиперссылками — получения смыслового портрета текста в терминах основных понятий и их смысловых связей;
Что такое API?
Цифры показывают степень значимости предложений в тексте. Значение веса, близкое к 100, означает, что данное предложение представляет важнейшую информацию, касающуюся главных понятий текста. Эти понятия в реферате выделяются цветом.
По умолчанию на экране отображаются предложения реферата с весами не менее 90.
Для рассматриваемого выше примераHTML-текста описания страницы Analyst.ru фрагменты семантической сети выглядят следующим образом:
Источник: poisk-ru.ru
Презентация на тему TextAnalyst 2.0. Персональная система автоматического анализа текста







использования указаны ограничения на модификацию, передачу, публикацию, загрузку контента на сторонние ресурсы и т.д. Все подобные действия возможны исключительно с письменного разрешения компании Microsystems, Ltd.
Слайд 5 Основные возможности ПО:
анализ содержания текста с автоматическим формированием
семантической сети с гиперссылками — получения смыслового портрета текста
в терминах основных понятий и их смысловых связей;
анализа содержания текста с автоматическим формированием тематического древа с гиперссылками — выявления семантической структуры текста в виде иерархии тем и подтем;
смыслового поиска с учетом скрытых смысловых связей слов запроса со словами текста;
автоматического реферирования текста — формирования его смыслового портрета в терминах наиболее информативных фраз;
кластеризации информации — анализа распределения материала текстов по тематическим классам;
автоматической индексации текста с преобразованием в гипертекст;
ранжирования всех видов информации о семантике текста по «степени значимости» с возможностью варьирования детальности ее исследования;
автоматического/автоматизированного формирования полнотекстовой базы знаний с гипертекстовой структурой и возможностями ассоциативного доступа к информации;
Источник: findtheslide.com