
При необходимости предоставления пользователю возможностей манипулирования ходом вычислительного процесса на микооконтроллерной системе (загрузка новых модулей из инструментальной системы, изменение содержимого памяти данных и оперативной памяти программ, запуск модулей на выполнение, управление обменом информацией в мультимикроконтроллерных системах) в состав программного обеспечения микроконтроллерной системы вводятся компоненты, обладающие способностью управления процессом выполнения задач на основе команд оператора. Такие npoграммные системы, называемые операционными системами (ОС), содержат в своем составе: ядро, реализующее общую логику функционирования операционной системы (реакция на прерывания, исполнение команд и др.). модули диалога с пользователем (проведение которого предполагает наличие в составе микропроцессорной системы устройств ввода-вывода информации), модули управления задачами (загрузкой, выгрузкой, переключением между задачами в мультизадачных системах, определением достижения условий останова и др.), а также модули связи с внешними вычислительными системами (в мультимикроконтроллерных системах, в системах с инструментальными ЭВМ и др.) (рис.).
Значение, строение и функционирование нервной системы. Видеоурок по биологии 8 класс
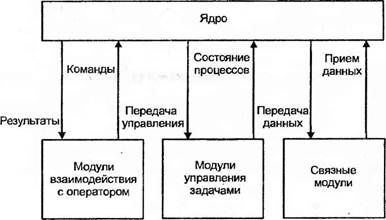
Рис. Структура операционной системы МК
Для осуществления своих функций ядро операционной системы, передача управления на которое осуществляется в соответствии с определенными временными метками, должно использовать высшие приоритеты системы обработки прерываний (рис.). В отличие от операционных систем, библиотеки подпрограмм непосредственно не решают задачи управления вычислительным процессом, однако содержат набор функционально законченных модулей, выполняющих типовые действия по обмену информацией с устройствами ввода-вывода, математические функции и т. п.
Программы диагностики выполняют проверку исправности микроконтроллерной системы и ее составных частей. Проведение диагностических процедур описано в
Структура и функции инструментального ПО
В состав инструментального ПО входят: сервисные программы, трансляторы, размещающие программы и средства отладки.
К сервисным программам относятся редакторы, библиотекари, информационно-обучающие программы и др.
Редакторы предназначены для подготовки исходных текстов программ микроконтроллерной системы. Редакторы принимают исходную программу с некоторого устройства ввода-вывода (клавиатуры, дисковой памяти и пр.) и заносят в оперативную или дисковую память инструментальной ЭВМ. Для подготовки программ в инструментальных системах используются общецелевые редактирующие программы, которые могут использоваться для создания исходных программ на любом языке. Редактор оперирует с исходной программой как с текстом, не учитывая те синтаксические правила, которым должна удовлетворять программа.
Библиотекари предназначены для создания и ведения библиотек подпрограмм, реализующих типовые функции, часто применяемые в разработках. Библиотекари, как правило, имеют команды организации библиотеки, включения и удаления программных модулей, получения информации о еодержа- щихся в библиотеке программных модулях.
Строение клетки за 8 минут (даже меньше)
Информационно-обучающие программы предназначены для начинающих пользователей и позволяют приобрести некоторые навыки применения инструментальных систем.
Трансляторы преобразуют исходную программу, написанную на входном языке (в качестве которого, как правило, применяются ассемблер и ряд языков высокого уровня, в частности язык Си) в результирующую — так называемую объектную программу на языке кодов команд микроконтроллера. Кроме объектной программы трансляторы выдают листинг программы, содержащий распечатку исходной и объектной программ, таблицы идентификаторов, сообщения об ошибках и другие виды диагностической информации. Как правило, трансляторы обладают возможностью формировать объектную программу в перемещаемых адресах и обрабатывать внешние связи между программными модулями.
Размещающие программы преобразуют объектные программы к виду, непосредственно готовому к выполнению на микропроцессорной системе, и заносят полученные программы в память микроконтроллерной системы (МКС). Процесс перевода объектных программ к виду, пригодному для исполнения, включается в преобразовании перемещаемого варианта объектной программы в вариант программы в абсолютных адресах. При необходимости установления связей между отдельными объектными модулями производится дополнительное редактирование внешних ссылок. Отметим, что сам процесс внесения программы в память микропроцессорной системы должен быть поддержан средствами как инструментальной вычислительной системы, так и самой МКС.
В качестве примера подобных систем можно привести пакет фирмы 2500 A.D. v4.02, включающий в себя макроассемблер Х8051 для МКС, совместимых с однокристальными микро-ЭВМ семейства МК-51, библиотекарь и редактор связей, формирующий результирующие программы в ряде широко распространенных форматов.
Структура и функции прикладного ПО
Прикладное ПО, реализующее процесс управления объектом, как любая сиожная программная система, строится по модульному принципу, в соответствии с которым каждая функционально законченная программная единица оформляется в виде подпрограммы, обращение к которой возможно из других программных модулей (рис.).
Задающие модули (задатчики) реализуют функцию, описывающую желаемое поведение объекта управления в виде набора ряда программнодоступных переменных управления. Информацию, необходимую для формирования задающей функции (например, выбор типа функции) задатчик может получать от оператора либо генерировать самостоятельно на основе информации об объекте управления. Функция, задающая желаемое поведение объема, может быть реализована либо путем математических вычислений, либо путем обращения к участку памяти, хранящему набор значений данной функции. Критериями выбора одной из методов служат необходимая точность и требуемая скорость вычислений
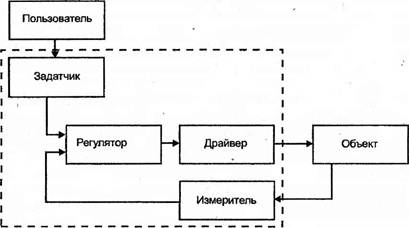
Рис. Организация взаимодействия прикладного ПО
Измерительные модули выполняют взаимодействие с аппаратурой датчиков объекта управления, предоставляя программам информацию о текущем состоянии объекта управления в виде значения ряда программно-доступных переменных.
Регулирующие модули (регуляторы) предназначены для построения выдаваемого на объект воздействия на основе информации о требуемом поведении объекта управления и его реальном поведении. В настоящее время в рамках теории автоматического управления разрабогано достаточно большое количество способов регулирования.
Драйверы объекта предназначены для преобразования информации об управляющем воздействии в управляющее воздействие того типа, которое соответствует объекту управления.
Так, например, для реализации управления частотой вращения шагового двигателя с тахогенератором в роли датчика частоты, задатчик формирует тре- буемое значение частоты вращения (в оборотах в секунду), измеритель опре- деляет текущее значение частоты в тех же единицах, что задатчик, осуществляя пересчет показаний аналого-цифрового преобразователя в количество оборотов в секунду, регулятор определяет уровень воздействия на объект (например, путем вычислений функции пропорционального регулятора), а драйвер преобразует полученный уровень воздействия в сигналы коммутации фазовых обмоток шагового двигателя, следующие с частотой, определяющейся информацией, полученной с регулятора.
Драйвер и измеритель принадлежат к объектно-зависимым компонентам прикладного ПО, а задатчик и регулятор— к объектно-независимым.
При смене объекта управления драйвер объекта также подлежит смене (в описанной системе замена шагового двигателя на двигатель постоянного гока потребует от драйвера объекта реализации управления, например, методом широтно-импульсной модуляции). При смене датчиков объекта замене подлежит измеритель.
Стадии разработки программного обеспечения
При проектировании программного обеспечения микроконтроллерных систем управления техническим объектом разработчику необходимо осуществить продвижение проекта через ряд стадий:
Анализ проблемы и построение математической модели.
Построение алгоритмов решения задачи.
Проектирование программы, решающей поставленную задачу.
Проведение автономной oтладки
Проведение комплексной отладки.
8 Передача в эксплуатацию.
Первый этап предполагает формирование описания (на естественном языке либо на языке специальных символов) условий задачи и желаемого результата. Как правило, постановка задачи представляется в виде технического задания.
На втором этапе осуществляется построение математической модели того физического процесса, который описывается в постановке задачи.
На третьем этапе математическая модель представляется в виде, удобном для числовой оценки, и осуществляется выбор метода решения задачи. На двух первых этапах описывалась сущность, которую необходимо получить в процессе проектирования, начиная с третьего этапа формируется способ реализации этой сущности — алгоритм получения результата на основе исходных данных.
На четвертом этапе осуществляется проектирование программного комплекса, завершающееся разработкой спецификаций требований к составным частям программного комплекса.
На пятом этапе выполняется собственно программирование, т. е. кодирование алгоритма с помощью выбранного языка программирования.
На шестом этапе выполняется автономная отладка каждой программы, входящей в состав программного комплекса, т. е. достижение правильности реализации функции, возложенной на данную программу.
На седьмом этапе проверяется соответствие техническому заданию всего программного комплекса.
На восьмом этапе разработанный программный комплекс передается в эксплуатацию с изготовлением необходимой документации.
Процесс сопровождения (девятый этап) заключается в устранении обнару-, женных ошибок, в модификации и улучшении применяемых подпрограмм.
Следует отметить, что в микроконтроллерных системах заключительная передача в эксплуатацию разработанного программного комплекса требует проведения комплексной отладки аппаратного и программного обеспечения (см. рис.).
Под отладкой понимается процесс поиска, обнаружения и исправления ошибок в разрабатываемой системе.
Отладка микроконтроллерных систем включает в себя стадии отладки аппаратных средств, программных средств, а также комплексную совместную отладку аппаратуры и программного обеспечения.
Источник: studopedia.su
Функции и структура программ
Функции разбивают большие вычислительные задачи на маленькие подзадачи и позволяют использовать в работе то, что уже сделано другими, а не начинать каждый раз с пустого места. Соответствующие функции часто могут скрывать в себе детали проводимых в разных частях программы операций, знать которые нет необходимости, проясняя тем самым всю программу , как целое, и облегчая мучения при внесении изменений.
Язык «C» разрабатывался со стремлением сделать функции эффективными и удобными для использования; «C»- программы обычно состоят из большого числа маленьких функций , а не из нескольких больших. Программа может размещаться в одном или нескольких исходных файлах любым удобным образом; исходные файлы могут компилироваться отдельно и загружаться вместе наряду со скомпилированными ранее функциями из библиотек . Мы здесь не будем вдаваться в детали этого процесса, поскольку они зависят от используемой системы.
Большинство программистов хорошо знакомы с «библиотечными» функциями для ввода и вывода / getchar , putchar / и для численных расчетов / sin , cos , sqrt /. В этой лекции мы сообщим больше о написании новых функций .
4.1. Основные сведения
Для начала давайте разработаем и составим программу печати каждой строки ввода , которая содержит определенную комбинацию символов. /Это — специальный случай утилиты grep системы » UNIX «/. Например, при поиске комбинации «the» в наборе строк
now is the time for all good men to come to the aid of their party
в качестве выхода получим
now is the time men to come to the aid of their party
основная схема выполнения задания четко разделяется на три части:
while (имеется еще строка) if (строка содержит нужную комбинацию) вывод этой строки
Конечно, возможно запрограммировать все действия в виде одной основной процедуры , но лучше использовать естественную структуру задачи и представить каждую часть в виде отдельной функции . С тремя маленькими кусками легче иметь дело, чем с одним большим, потому что отдельные не относящиеся к существу дела детали можно включить в функции и уменьшить возможность нежелательных взаимодействий. Кроме того, эти куски могут оказаться полезными сами по себе.
«Пока имеется еще строка» — это getline , функция , которую мы запрограммировали в «лекции №1″ , а » вывод этой строки» — это функция printf , которую уже кто-то подготовил для нас. Это значит, что нам осталось только написать процедуру для определения , содержит ли строка данную комбинацию символов или нет. Мы можем решить эту проблему, позаимствовав разработку из PL/1: функция index(s,t) возвращает позицию, или индекс, строки s , где начинается строка t , и -1 , если s не содержит t . В качестве начальной позиции мы используем 0 , а не 1 , потому что в языке «C» массивы начинаются с позиции нуль. Когда нам в дальнейшем понадобится проверять на совпадение более сложные конструкции , нам придется заменить только функцию index; остальная часть программы останется той же самой.
После того, как мы потратили столько усилий на разработку, написание программы в деталях не представляет затруднений. ниже приводится целиком вся программа , так что вы можете видеть, как соединяются вместе отдельные части. Комбинация символов, по которой производится поиск, выступает пока в качестве символьной строки в аргументе функции index , что не является самым общим механизмом. Мы скоро вернемся к обсуждению вопроса об инициализации символьных массивов и в «лекции №5» покажем, как сделать комбинацию символов параметром, которому присваивается значение в ходе выполнения программы . Программа также содержит новый вариант функции getline ; вам может оказаться полезным сравнить его с вариантом из «лекции №1» .
#define maxline 1000 main() /* find all lines matching a pattern */ < char line[maxline]; while (getline(line, maxline) >0) if (index(line, «the») >= 0) printf(«%s», line); > getline(s, lim) /* get line into s, return length * char s[]; int lim; < int c, i; i = 0; while(—lim>0 (c=getchar()) != EOF c != ‘n’) s[i++] = c; if (c == ‘n’) s[i++] = c; s[i] = ‘�’; return(i); > index(s,t) /* return index of t in s,-1 if none */ char s[], t[]; < int i, j, k; for (i = 0; s[i] != ‘�’; i++) < for(j=i, k=0; t[k] !=’�’ s[j] == t[k]; j++; k++) ; if (t[k] == ‘�’) return(i); >return(-1); >
Каждая функция имеет вид имя ( список аргументов , если они имеются) описания аргументов , если они имеются
Источник: intuit.ru
Name already in use
A tag already exists with the provided branch name. Many Git commands accept both tag and branch names, so creating this branch may cause unexpected behavior. Are you sure you want to create this branch?
Cancel Create
lectures / 3. функции и структура программы.md
- Go to file T
- Go to line L
- Copy path
- Copy permalink
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Cannot retrieve contributors at this time
389 lines (293 sloc) 25.5 KB
- Open with Desktop
- View raw
- Copy raw contents Copy raw contents Copy raw contents
Copy raw contents
# 3. Функции и структура программы
Функции разбивают большие вычислительные задачи на более мелкие и позволяют воспользоваться тем, что уже сделано другими разработчиками, а не начинать создание программы каждый раз «с нуля». В выбранных должным образом функциях «упрятаны» несущественные для других частей программы детали их функционирования, что делает программу в целом более ясной и облегчает внесение в нее изменений.
## Основные сведения о функциях
Определение любой функции имеет следующий вид:
тип-результата имя-функции (объявления аргументов)
//функция генерации псевдослучайного числа. //входные параметры: prev — предыдущее случайное число; // seed — зерно для создания последовательности. //возвращает число типа int. int random (int prev, int seed) < prev = prev * 1103515245L + seed; return (prev >> 16); >
Этим создается некий внешний интерфейс пользователя. Отдельные части определения могут отсутствовать, как, например, в определении «минимальной» функции foo()<> . В исходном файле функции могут располагаться в любом порядке; исходную программу можно разбивать на любое число файлов, но так, чтобы ни одна из функций не оказалась разрезанной.
Функцию можно рассматривать как 4-х полюсник. На вход которого поступают данные в виде аргументов и внешних переменных, которые преобразуются функцией, и на выходе получается результат.
вход: В блоке «объявления аргументов» необходимо через запятую указать типы и имена всех переменныех которые нужны данной функции. Если у функции нет аргументов, используйте слово void . Внешние переменные объявленные до функции впринципе тоже будут видны в теле функции и их можно читатьписать. Но подобные неявные связи лучше минимизировать.
(int mass, float v) (char str[]) (void)
имя: для вызова функции ей нужно придумать уникальное в пределах вашей программы имя. правила создания имен функций аналогичны правилам для имен переменных. желательно делать их осмысленными и достаточно короткими.
copyfile — копирует файл getname — получает имя
выход: Механизм возврата результата реализует через инструкцию return . За словом return может следовать любое выражение. Функция вернет результат вычисления этого выражения.
return imp; return sin(pi/2);
При этом тип возвращаемых данных должен совпадать с типом-результата в объявлении функции. Выражение после return может отсутствовать, и тогда произойдет выход в вызывающую функцию. Вызывающая функция вправе проигнорировать возвращаемое значение.
//задача: //напечатать строки, содержащие некий образец. // //решения: //while (существует еще строка) //получение строки // if (строка содержит образец) //поиск образца // печать строки //печать //разобъем задачу на подзадачи с помощью функций. //опишем внешние интерфейсы для работы с каждой из них: //——————————- //получает строку //и пишет ее в строку s //возвращает длину //——————————- int getline (char s[], int lim) //——————————- //ищет строку //возвращает место строки t в строке s //если не находит, возвращает -1 //——————————- int strindex (char s[], char t[]) //——————————- //печатает строку s //ничего не возвращает //——————————- void print(char s[])
Прилагательное «внешний» ( external ) противоположно прилагательному «внутренний» ( internal ), которое относится к аргументам и переменным, определяемым внутри функций. Внешние переменные определяются вне функций и потенциально доступны для многих функций. Поскольку внешние переменные доступны всюду, их можно использовать в качестве связующих данных между функциями как альтернативу связей через аргументы и возвращаемые значения. Для любой функции внешняя переменная доступна по ее имени, если это имя было должным образом объявлено.
int a; void check (void) < if (a == 1) . >void set (void) < a = 1; >main ()
Если число переменных, совместно используемых функциями, велико, связи между последними через внешние переменные могут оказаться более удобными и эффективными, чем длинные списки аргументов. Но такая практика ухудшает структуру программы и приводит к слишком большому числу связей между функциями по данным.
Внешние переменные полезны, так как они имеют большую область действия и время жизни. Автоматические переменные существуют только внутри функции, они возникают в момент входа в функцию и исчезают при выходе из нее. Внешние переменные, напротив, существуют постоянно, так что их значения сохраняются и между обращениями к функциям.
Исходный текст может быть довольно протяженным, или храниться в нескольких файлах, библиотеках. В связи с этим возникает вопрос: как функции находят необходимые им переменныефункции? Ответ: по именам. Но у каждого имени есть своя область видимости.
Областью видимости имени считается часть программы, в которой это имя можно использовать. Для автоматических переменных, объявленных в начале функции, областью видимости является функция, в которой они объявлены. Локальные переменные разных функций, имеющие, однако, одинаковые имена, никак не связаны друг с другом. Параметры функции, тоже фактически являются локальными переменными.
int func (char s) < int i; //s,i — локальные переменные, не видны за пределами функции >
Область действия внешней переменной или функции простирается от точки программы, где она объявлена, до конца файла. Однако, если на внешнюю переменную нужно сослаться до того, как она определена, или если она определена в другом файле, то ее объявление должно быть помечено словом extern.
func (a); //ошибка, переменная не найдена char a; func (a);
Важно отличать объявление внешней переменной от ее определения. Объявление объявляет свойства переменной (прежде всего ее тип), а определение, кроме того, приводит к выделению для нее памяти. До выделения памяти переменной физически не существуют.
Объявление должно быть только одно, определений может быть сколько угодно. В определениях массивов необходимо указывать их размеры, что в объявлениях extern не обязательно.
int sp; //создаем переменную sp double val[MAXVAL]; extern int sp; //говорим, что где-то существует переменная sp extern double val[];
Если программа состоит из множества файлов, или подключаются библиотеки, то объявления отделяют от определений, распологая их в разных файлах. Файлы с определениями называются заголовочными и похожи скорее на сожержание книги. где показывается что где имеется и как к этому обратиться. Заголовочные файлы обычно имеют расширение h.
//файл math.h extern float pi; float cos (float); //файл match.c float pi = 3.14; float cos (float a) < . >//файл main.c #include main () < float a; a = cos (pi/2); >
Указание static, примененное к внешней переменной или функции, ограничивает область видимости соответствующего объекта концом файла. Это способ скрыть имена. Как следствие этими именами можно свободно пользоваться в других файлах для совсем иных целей.
static char buf[BUFSIZE]; //входной буфер, скрытый от посторонних глаз int getchar(void) < . >//функция чтения буфера
Указание static чаще всего используется для переменных, но с равным успехом его можно применять и к функциям. Обычно имена функций глобальны и видимы из любого места программы. Если же функция помечена словом static, то ее имя становится невидимым вне файла, в котором она определена.
Объявление static можно использовать и для внутренних переменных. Как и автоматические переменные, внутренние статические переменные локальны в функциях, но в отличие от автоматических они не возникают только на период работы функции, а существуют постоянно. Это значит, что внутренние статические переменные обеспечивают постоянное сохранение данных внутри функции.
int in_count (void) < //подсчитывает сколько раз ее запускали static int i=0; return i++; >
Внешние статические переменные и функции предоставляют способ организовывать данные и работающие с ними внутренние процедуры таким образом, что другие процедуры и данные не могут прийти с ними в конфликт даже по недоразумению.
Объявление register сообщает компилятору, что данная переменная будет интенсивно использоваться. Идея состоит в том, чтобы переменные, объявленные register, разместить на регистрах машины, благодаря чему программа, возможно, станет более короткой и быстрой. Однако компилятор имеет право проигнорировать это указание. Объявление register может применяться только к автоматическим переменным и к формальным параметрам функций
int func (register long id)
Поскольку функции в Си нельзя определять внутри других функций, он не является языком, допускающим блочную структуру программы в том смысле, как это допускается в Паскале и подобных ему языках. Но переменные внутри функций можно определять в блочно-структурной манере.
Объявления переменных (вместе с инициализацией) разрешено помещать не только в начале функции, но и после любой левой фигурной скобки, открывающей составную инструкцию. Переменная, описанная таким способом, «затеняет» переменные с тем же именем, расположенные в объемлющих блоках, и существует вплоть до соответствующей правой фигурной скобки.
При отсутствии явной инициализации для внешних и статических переменных гарантируется их обнуление; автоматические и регистровые переменные имеют неопределенные начальные значения («мусор»). Скалярные переменные можно инициализировать в их определениях, помещая после имени знак = и соответствующее выражение:
int x = 1; char squote = »’; long day = 1000L * 60L * 60L * 24L;
Для внешних и статических переменных инициализирующие выражения должны быть константными, при этом инициализация осуществляется только один раз до начала выполнения программы. Инициализация автоматических и регистровых переменных выполняется каждый раз при входе в функцию или блок. Для таких переменных инициализирующее выражение — не обязательно константное. Это может быть любое выражение, использующее ранее определенные значения, включая даже и вызовы функций.
int func (int n)
Массив можно инициализировать в его определении с помощью заключенного в фигурные скобки списка инициализаторов, разделенных запятыми. Если размер массива не указан, то длину массива компилятор вычисляет по числу заданных инициализаторов;
int days[] = ;
Инициализация символьных массивов — особый случай: вместо конструкции с фигурными скобками и запятыми можно использовать строку символов.
char text[] = «abc»; char text[] = ;
В Си допускается рекурсивное обращение к функциям, т.е. функция может обращаться сама к себе, прямо или косвенно. Когда функция рекурсивно обращается сама к себе, каждое следующее обращение сопровождается получением ею нового полного набора автоматических переменных, независимых от предыдущих наборов.
//функция считывания файлов из директории. //Если она считывает что в папке есть папка //то рекурсивно считывает файлы и из неё //и так далее в самую глубину рекурсивное чтение есть папки? зайти в папку рекурсивное чтение чтение файлов выход
Если процедура вызывает сама себя, то, по сути, это приводит к повторному выполнению содержащихся в ней инструкций, что аналогично работе цикла.
//функция выполнит некий код n раз void mywhile (int n) < if (n) < //какой-то код здесь n—; mywhile(n); >else return; >
## Препроцессор языка Си
Некоторые возможности языка Си обеспечиваются препроцессором, который работает на первом шаге компиляции. Наиболее часто используются две возможности: #include , вставляющая содержимое некоторого файла во время компиляции, и #define , заменяющая одни текстовые последовательности на другие. В этом параграфе обсуждаются условная компиляция и макроподстановка с аргументами.
Любая строка вида
#include «имя-файла» #include
заменяется содержимым файла с именем имя-файла. Если имя-файла заключено в двойные кавычки, то, как правило, файл ищется среди исходных файлов программы; если такового не оказалось или имя-файла заключено в угловые скобки < и >, то поиск осуществляется по определенным в реализации правилам. Включаемый файл сам может содержать в себе строки #include .
Средство #include — хороший способ собрать вместе объявления большой программы. Он гарантирует, что все исходные файлы будут пользоваться одними и теми же определениями и объявлениями переменных, благодаря чему предотвращаются особенно неприятные ошибки. Естественно, при внесении изменений во включаемый файл все зависимые от него файлы должны перекомпилироваться.
Определение макроподстановки имеет вид:
#define имя замещающий-текст
Макроподстановка используется для простейшей замены: во всех местах, где встречается лексема имя, вместо нее будет помещен замещающий-текст. Имена в #define задаются по тем же правилам, что и имена обычных переменных. Замещающий текст может быть произвольным.
Область видимости имени, определенного в #define , простирается от данного определения до конца файла. В определении макроподстановки могут фигурировать более ранние #define -определения.
Подстановка осуществляется только для тех имен, которые расположены вне текстов, заключенных в кавычки. Например, если YES определено с помощью #define , то никакой подстановки в printf(«YES») или в YESMAN выполнено не будет. Любое имя можно определить с произвольным замещающим текстом
#define forever for(;;) #define max(A, В) ((А)>(В) ? (А):(В))
Действие #define можно отменить с помощью #undef
Самим ходом препроцессирования можно управлять с помощью условных инструкций. Они представляют собой средство для выборочного включения того или иного текста программы в зависимости от значения условия, вычисляемого во время компиляции.
Если выражение имеет ненулевое значение, то будут включены все последующие строки вплоть до #endif , или #elif , или #else .
#if выражение .. #elseif выражение .. #else .. #endif
#if !defined(HDR) #define HDR /* здесь содержимое hdr.h */ .. #endif
[[след. лекция](4. указатели.md)] [в начало]
Источник: github.com