
В 2011 году Twitter открыл, под лицензией Eclipse Public License, проект распределенных вычислений Storm. Storm был создан в компании BackType и перешел к Twitter после покупки.
Storm это система ориентированная на распределенную обработку больших потоков данных, аналогичная Apache Hadoop, но в реальном времени.
- Масштабируемость. Задачи обработки распределяются по узлам кластера и потокам на каждом узле.
- Гарантированная защита от потери данных.
- Простота развертывания и спровождения.
- Восстановление после сбоев. Если какой либо из обработчиков отказывает, задачи переадресуются на другие обработчики.
- Возможность написания компонентов не только на Java. Простой Multilang protocol с использованием JSON объектов. Есть готовые адаптеры для языков Python, Ruby и Fancy.
Элементы Storm
Tuple
Элемент представления данных. По умолчанию может содержать Long, Integer, Short, Byte, String, Double, Float, Boolean и byte[] поля. Пользовательские типы используемые в Tuple должны быть сериализуемыми.
ОТЧЁТ СТАВОК ЗА 31 МАЯ ! ПОДПИСЫВАЙТЕСЬ НА ТЕЛЕГРАМ КАНАЛ ССЫЛКА В КОММЕНТАРИИ
Stream
Последовательность из Tuple. Содержит схему именования полей в Tuple.
Spout
Поставщик данных для Stream. Получает данные из внешних источников, формирует из них Tuple и отправляет в Stream. Может отправлять Tuple в несколько разных Stream. Есть готовые для популярных систем обмена сообщениями: RabbitMQ / AMQP, Kestrel, JMS, Kafka.
Bolt
Обработчик данных. На вход поступают Tuple. На выход отправляет 0 или более Tuple.
Topology
Совокупность элементов с описанием их взаимосвязи. Аналог MapReduce job в Hadoop. В отличии от MapReduce job — не останавливается после исчерпания входного потока данных. Осуществляет транспорт Tuple между элементами Spout и Bolt. Может запускаться локально или загружаться в Storm кластер.
Пример использования
Задача
Есть поток данных о телефонных вызовах Cdr. На основании source номера определяется id клиента. На основании destination номера и id клиента определяется тариф и считается стоимость звонка. Каждый из этапов должен работать в несколько потоков.
Пример будет запускаться на локальной машине.
Реализация
Для начала просто распечатаем входные данные BasicApp.
Создаем новую Topology:
TopologyBuilder builder = new TopologyBuilder();
Добавляем Spout CdrSpout генерирующий входные данные:
builder.setSpout(«CdrReader», new CdrSpout());
Добавляем Bolt с двумя потоками и указываем что на вход подается выходной поток CdrReader. shuffleGrouping означает что данные из CdrReader подаются на случайно выбранный PrintOutBolt.
builder.setBolt(«PrintOutBolt», new PrintOutBolt(), 2).shuffleGrouping(«CdrReader»);
Конфигурируем и запускам локальный Storm кластер:
Config config = new Config(); // Конфигурация кластера по умолчанию config.setDebug(false); LocalCluster cluster = new LocalCluster(); // Создаем локальный Storm кластер cluster.submitTopology(«T1», config, builder.createTopology()); // Стартуем Topology Thread.sleep(1000*10); cluster.shutdown(); // Останавливаем кластер
Схема бизнес процесса Как нарисовать схему процесса в BPMN за 2 минуты?
На выходе получаем примерно следующее:
Скрытый текст
OUT>> [80]Cdr OUT>> [78]Cdr OUT>> [78]Cdr OUT>> [80]Cdr
Число в квадратных скобках — Thread Id, видно что обработка ведется параллельно.
Для дальнейших экспериментов нужно разобраться с распределением входных данных между несколькими обработчиками.
В примере выше был использован случайный подход. Но в реальном применении Bolt’ы наверняка будут использовать внешние справочные системы и базы данных. В этом случае желательно чтобы каждый Bolt обрабатывал свое подмножество входных данных. Тогда можно будет организовать эффективное кэширование данных из внешних систем.
Для этого в Storm предусмотрен интерфейс CustomStreamGrouping.
Добавим в проект CdrGrouper. Его задача — отправлять Tuple с одинаковыми source номерами на один и тот же Bolt. Для этого в CustomStreamGrouping предусмотрено два вызова:
prepare — вызывается перед первым использованием:
и chooseTasks — где на вход подается список из Tuple, а возвращается список состоящий из номеров Bolt’ов для каждой позиции в списке Tuple:
Заменим shuffleGrouping на CdrGrouper BasicGroupApp:
builder.setBolt(«PrintOutBolt», new PrintOutBolt(), 2). customGrouping(«CdrReader», new CdrGrouper());
Запустим и убедимся что работает как задумано:
Скрытый текст
OUT>> [80]Cdr OUT>> [80]Cdr
Далее в проект добавляем:
ClientIdBolt — определяет id клиента по source номеру.
ClientIdGrouper — Группирует по id клиента.
RaterBolt — занимается тарификацией.
CalcApp — окончательный вариант программы.
Если тема будет интересна, то в следующей части надеюсь рассказать о механизмах защиты от потери данных и запуске на реальном кластере. Код доступен на GitHub.
PS. Из песни конечно слова не выкинешь, но название обработчика данных «Bolt» несколько смущает 🙂
UPD. Опубликована вторая часть статьи.
- Java
- Параллельное программирование
Источник: habr.com
Storm – распределенная система обмена сообщениями
Apache Storm обрабатывает данные в режиме реального времени и обычно поступает из системы очередей сообщений. Внешняя распределенная система обмена сообщениями предоставит входные данные, необходимые для вычислений в реальном времени. Spout будет считывать данные из системы обмена сообщениями, преобразовывать их в кортежи и вводить в Apache Storm. Интересным фактом является то, что Apache Storm использует собственную распределенную систему обмена сообщениями для связи между нимбом и супервизором.
Что такое распределенная система обмена сообщениями?
Распределенный обмен сообщениями основан на концепции надежной очереди сообщений. Сообщения помещаются в очередь асинхронно между клиентскими приложениями и системами обмена сообщениями. Распределенная система обмена сообщениями обеспечивает преимущества надежности, масштабируемости и постоянства.
Большинство шаблонов обмена сообщениями следуют модели публикации-подписки (просто Pub-Sub ), где отправители сообщений называются издателями, а те, кто хочет получать сообщения, называются подписчиками .
После того как сообщение было опубликовано отправителем, подписчики могут получить выбранное сообщение с помощью опции фильтрации. Обычно у нас есть два типа фильтрации: один – тематическая фильтрация, а другой – контентная фильтрация .
Обратите внимание, что модель pub-sub может общаться только через сообщения. Это очень слабо связанная архитектура; даже отправители не знают, кто их подписчики. Многие шаблоны сообщений позволяют брокеру сообщений обмениваться публикационными сообщениями для своевременного доступа многих подписчиков. Примером из реальной жизни является Dish TV, который публикует различные каналы, такие как спортивные состязания, фильмы, музыка и т. Д., И любой может подписаться на свой собственный набор каналов и получать их, когда доступны их подписанные каналы.
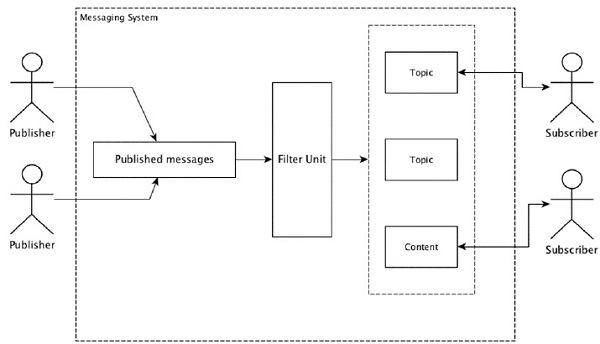
В следующей таблице описаны некоторые популярные системы обмена сообщениями с высокой пропускной способностью.
| Апач Кафка | Кафка была разработана в корпорации LinkedIn и позже стала подпроектом Apache. Apache Kafka основан на устойчивой, распределенной модели публикации и подписки. Кафка быстрая, масштабируемая и высокоэффективная. |
| RabbitMQ | RabbitMQ – это приложение для распределенного надежного обмена сообщениями с открытым исходным кодом. Он прост в использовании и работает на всех платформах. |
| JMS (служба сообщений Java) | JMS – это API с открытым исходным кодом, который поддерживает создание, чтение и отправку сообщений из одного приложения в другое. Он обеспечивает гарантированную доставку сообщений и следует модели публикации и подписки. |
| ActiveMQ | Система обмена сообщениями ActiveMQ – это API JMS с открытым исходным кодом. |
| ZeroMQ | ZeroMQ – это одноранговая обработка сообщений без посредников. Он предоставляет двухтактные шаблоны сообщений маршрутизатора и дилера. |
| Пустельга | Kestrel – это быстрая, надежная и простая распределенная очередь сообщений. |
Комиссионный протокол
Thrift был построен в Facebook для разработки мультиязычных сервисов и удаленного вызова процедур (RPC). Позже это стало проектом Apache с открытым исходным кодом. Apache Thrift является языком определения интерфейса и позволяет легко определять новые типы данных и реализацию сервисов поверх определенных типов данных.
Apache Thrift также является коммуникационной средой, которая поддерживает встроенные системы, мобильные приложения, веб-приложения и многие другие языки программирования. Некоторые из ключевых особенностей, связанных с Apache Thrift, это его модульность, гибкость и высокая производительность. Кроме того, он может выполнять потоковую передачу, обмен сообщениями и RPC в распределенных приложениях.
Storm широко использует Thrift Protocol для внутренней коммуникации и определения данных. Топология шторма – это просто Thrift Structs . Storm Nimbus с топологией в Apache Storm – это сервис Thrift .
Источник: coderlessons.com
Storm
Apache Storm (Сторм, Шторм) – это Big Data фреймворк с открытым исходным кодом для распределенных потоковых вычислений в реальном времени, разработанный на языке программирования Clojure.
Изначально созданный Натаном Марцем и командой из BackType, этот проект был открыт с помощью исходного кода, приобретенного Twitter. Первый релиз состоялся 17 сентября 2011 года, а с сентября 2014 Storm стал проектом верхнего уровня Apache Software Foundation [1].
Как устроен Apache Storm: архитектура и принцип работы
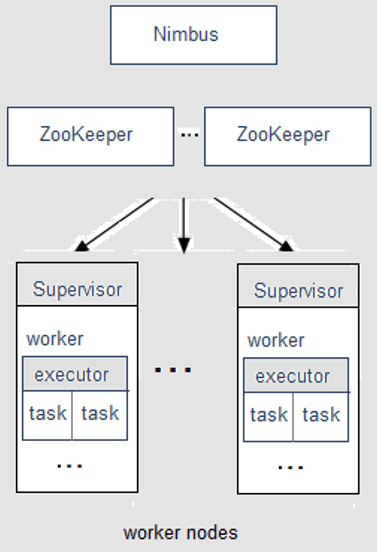
Кластер Apache Storm, работающий по принципу master-slave, состоит из следующих компонентов [1]:
- Ведущий узел (master) с запущенной системной службой (демоном) Nimbus, который назначает задачи машинам и отслеживает их производительность.
- Рабочие узлы (worker nodes), на каждом из которых запущен демон Supervisor (супервизор), который назначает задачи (task) другим рабочим узлам и управляет ими по необходимости.
Storm самостоятельно не отслеживает состояние кластера, поэтому для связи Nimbus с супервизорами и управления кластером используется служба ZooKeeper.
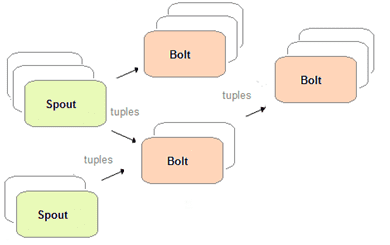
Топология вычислений реального времени в приложениях Storm представляет собой ориентированный ациклический графа (DAG, Directed Acyclic Graph). Узлами (вершинами) графа являются обработчики 2-х типов [2]:
- спаут (spout), который генерирует кортежи (tuple) – потоки данных в виде неизменяемых наборов пар ключ-значение;
- болт (bolt), который выполняет преобразование потока (подсчет, фильтрация, map, reduce и пр.) и передает данные другим болтам для последующей обработки.
Таким образом, поток представляет собой неограниченный конвейер кортежей, а Spout является источником потоков, который преобразует данные в кортеж потоков и отправляет их на обработку в Bolt. В итоге топология действует как конвейер преобразования данных. На поверхностном уровне общая структура топологии аналогична задаче MapReduce в Apache Hadoop, однако в Storm данные обрабатываются в режиме реального времени, а не в отдельных пакетах. Также, в отличие от классического Hadoop, топологии Storm работают неопределенно долго (пока не будут уничтожены), а DAG-задача MapReduce имеет ограниченный срок существования [1].
Преимущества и недостатки Сторм
Ключевыми достоинствами Apache Storm можно назвать следующие [3]:
- интеграция с любыми системами управления очередью и брокерами сообщений (Kestrel, RabbitMQ, Kafka, JMS, Amazon Kinesis), а также базами данных;
- масштабируемость – вычислительные топологии Storm изначально параллельны и предназначены для кластерной работы с технологиями Big Data. Различные части топологии можно масштабировать по отдельности, изменяя их параллелизм и регулируя параллельность запуска на лету;
- вычислительная мощность – благодаря распределенному параллелизму Сторм может обрабатывать очень большое количество сообщений с очень низкой задержкой;
- отказоустойчивость — когда фоновые задачи перестают работать, Storm автоматически перезапустит их на этом же узле кластера или на другом, в случае его сбоя. Фреймворк самостоятельно обрабатывает параллелелизм, разделение данных и повтор действий в случае ошибок.
- гарантия обработки данных – Сторм обеспечивает обработку каждого кортежа данных за счет семантики минимум однократной доставки (at least once) или в точности однократной доставки (exactly once) с использованием высокоуровневого API-интерфейса Trident;
- поддержка множества языков программирования — Storm использует Apache Thrift – язык описания интерфейсов, который используется для определения и создания служб под разные языки программирования, а также является фреймворком к удалённому вызову процедур. Благодаря этому можно создавать программные топологии на любом языке программирования: Java, Scala, Python, C#, Ruby и пр. [2];
- наличие собственнойRPC-подсистемы – за счет инструмента распределенного удаленного вызова процедур Сторм позволяет выполнять кластерные вычисления по требованию, когда клиент синхронно ожидает результат [2];
- низкая задержка (latency) – Storm обеспечивает обработку потоковых данных в реальном времени с задержкой менее 1 секунды, показывая лучшие результаты по сравнению с Apache Spark, другим популярным Big Data фреймворком потоковой обработки;
- простота развертывания и поддержки – Шторм обладает стандартным набором конфигураций для развертывания кластера, а при работе с вычислительным облаком Amazon Elastic Compute Cloud (Amazon EC2), проект со Storm можно подготовить, настроить и установить с нуля нажатием одной кнопки.
При всех вышеуказанных достоинствах, Шторм отличается следующими недостатками [4]:
- отсутствие возможностей гибкой обработки событий в различных периодах, например, временные и сеансовые окна, как в Apache Kafka Streams и Flink;
- не поддерживает управление состоянием приложений (stateful);
- поддержка минимум однократной доставки сообщений (at least once).
Впрочем, последние 2 проблемы решаются с помощью высокоуровневого API-интерфейса Trident. Storm с помощью высокоуровневого API Trident сохраняет состояние в памяти и периодически отправляет его в удаленную базу данных (например, Cassandra), поэтому стоимость удаленного вызова базы данных амортизируется по нескольким обработанным кортежам. Поддерживая метаданные вместе с состоянием, Trident может достичь семантики обработки ровно один раз (exact only), что обеспечивает, например, корректность счетчиков событий, даже в случае сбоя кластерных узлов и перезапуска кортежей. Впрочем, при больших объемах состояния в каждом обработчике типа Bolt (более 100 КБ) этот подход становится неэффективен, поскольку возрастают потери производительности при вызовах базы данных для каждого обработанного кортежа. Однако, для простых случаев, например, отслеживание счетчиков и метрик (минимальных, максимальных и средних значений) Шторм с Trident вполне справятся [5].
А где используется Apache Storm и с какими другими Big Data системами потоковой обработки конкурирует этот фреймворк, мы рассказываем в отдельной статье.
Источники
Источник: bigdataschool.ru