
11.8 – Стек и куча
Память, которую использует программа, обычно делится на несколько разных областей, называемых сегментами:
- Сегмент кода (также называемый текстовым сегментом), в котором скомпилированная программа находится в памяти. Сегмент кода обычно доступен только для чтения.
- Сегмент bss («block started by symbol», также называемый сегментом неинициализированных данных), где хранятся глобальные и статические переменные с нулевой инициализацией.
- Сегмент данных (также называемый сегментом инициализированных данных), где хранятся инициализированные глобальные и статические переменные.
- Куча, где размещаются динамически размещаемые переменные.
- Стек вызовов, в котором хранятся параметры функций, локальные переменные и другая информация, относящаяся к функциям.
В этом уроке мы сосредоточимся в первую очередь на куче и стеке, так как именно там происходит большинство интересных вещей.
Сегмент кучи
Сегмент кучи (также известный как «free store», «свободное хранилище») отслеживает память, используемую для динамического распределения памяти. Мы уже говорили немного о куче в уроке «10.13 – Динамическое распределение памяти с помощью new и delete », поэтому это будет резюме.
С++ с нуля: урок 15 — стек, теория и практика
В C++, когда вы используете оператор new для выделения памяти, эта память выделяется в сегменте кучи приложения.
int *ptr = new int; // ptr присваивается 4 байта в куче int *array = new int[10]; // array присвоено 40 байт в куче
Адрес этой памяти возвращается оператором new и затем может быть сохранен в указателе. Вам не нужно беспокоиться о механизме того, где расположена свободная память, и как она выделяется пользователю. Однако стоит знать, что последовательные запросы памяти могут не привести к выделению последовательных адресов памяти!
int *ptr1 = new int; int *ptr2 = new int; // ptr1 и ptr2 могут не содержать соседних адресов
Когда динамически размещаемая переменная удаляется, память «возвращается» в кучу и затем может быть переназначена по мере получения будущих запросов на выделение. Помните, что удаление указателя не удаляет переменную, а просто возвращает память по соответствующему адресу обратно операционной системе.
У кучи есть достоинства и недостатки:
- Выделение памяти в куче происходит сравнительно медленно.
- Выделенная память остается выделенной до тех пор, пока она не будет специально освобождена (остерегайтесь утечек памяти) или пока приложение не завершит работу (после чего ОС должна ее очистить).
- Доступ к динамически выделяемой памяти должен осуществляться через указатель. Разыменование указателя происходит медленнее, чем прямой доступ к переменной.
- Поскольку куча – это большой пул памяти, здесь могут быть размещены большие массивы, структуры или классы.
Стек вызовов
Стек вызовов (обычно называемый «стеком») играет гораздо более интересную роль. Стек вызовов отслеживает все активные функции (те, которые были вызваны, но еще не завершились) от начала программы до текущей точки выполнения и обрабатывает размещение всех параметров функций и локальных переменных.
КАК РАБОТАЕТ СТЕК | ОСНОВЫ ПРОГРАММИРОВАНИЯ
Стек вызовов реализован в виде структуры данных стек. Итак, прежде чем мы сможем говорить о том, как работает стек вызовов, нам нужно понять, что такое структура данных стек.
Структура данных стек
Структура данных – это программный механизм для организации данных таким образом, чтобы их можно было эффективно использовать. Вы уже видели несколько типов структур данных, таких как массивы и структуры. Обе эти структуры данных предоставляют механизмы для хранения данных и эффективного доступа к ним. Существует множество дополнительных, обычно используемых в программировании структур данных, многие из которых реализованы в стандартной библиотеке, и стек является одной из них.
Представьте себе стопку тарелок в кафетерии. Поскольку каждая тарелка тяжелая и они сложены друг на друга, вы можете сделать только одно из трех:
- посмотреть на поверхность верхней тарелки;
- снять верхнюю тарелку со стопки (открывая нижнюю, если она есть);
- поместить новую тарелку на верх стопки (скрывая нижнюю, если она есть).
В компьютерном программировании стек – это структура контейнера данных, который содержит несколько переменных (как массив). Однако в то время как массив позволяет вам получать доступ к элементам и изменять их в любом порядке (так называемый произвольный доступ), стек более ограничен. Операции, которые могут быть выполнены со стеком, соответствуют трем вещам, упомянутым выше:
- посмотреть верхний элемент в стеке (обычно это делается с помощью функции top() , но иногда называется peek() );
- снять верхний элемент из стека (выполняется с помощью функции pop() );
- поместить новый элемент на верх стека (выполняется с помощью функции push() ).
Стек – это структура типа «последним пришел – первым ушел» (LIFO, «last-in, first-out»). Последний элемент, помещенный в стек, будет первым извлеченным элементом. Если вы положите новую тарелку поверх стопки, первая тарелка, удаленная из стопки, будет тарелкой, которую вы только что положили последней. Последней положена, первой снята. По мере того, как элементы помещаются в стек, стек становится больше – по мере того, как элементы извлекаются, стек становится меньше.
Например, вот короткая последовательность, показывающая, как работает стек при вставке (push) и извлечении (pop) данных:
Стек: пустой Вставка 1 Стек: 1 Вставка 2 Стек: 1 2 Вставка 3 Стек: 1 2 3 Извлечение Стек: 1 2 Извлечение Стек: 1
Аналогия с тарелками – довольно хорошая аналогия того, как работает стек вызовов, но мы можем провести лучшую аналогию. Представьте себе группу почтовых ящиков, сложенных друг на друга.
Каждый почтовый ящик может содержать только один элемент, и все почтовые ящики изначально пустые. Кроме того, каждый почтовый ящик прибивается к почтовому ящику под ним, поэтому количество почтовых ящиков не может быть изменено. Если мы не можем изменить количество почтовых ящиков, как мы можем добиться поведения, подобного стеку?
Во-первых, мы используем маркер (например, наклейку), чтобы отслеживать, где находится самый нижний пустой почтовый ящик. Вначале это будет самый нижний почтовый ящик (внизу стопки). Когда мы помещаем элемент в наш стек почтовых ящиков, мы помещаем его в отмеченный почтовый ящик (который является первым пустым почтовым ящиком) и перемещаем маркер на один ящик вверх.
Когда мы извлекаем элемент из стека, мы перемещаем маркер на один почтовый ящик вниз так, чтобы он указывал на верхний непустой почтовый ящик, и удаляем элемент из этого почтового ящика. Всё, что ниже маркера, считается «в стеке». Всё, что находится на уровне маркера или над ним, – не в стеке.
Сегмент стека вызовов
Сегмент стека вызовов содержит память, используемую для стека вызовов. Когда приложение запускается, операционная система помещает в стек вызовов функцию main() . Затем программа начинает выполняться.
Когда встречается вызов функции, эта функция помещается в стек вызовов. Когда текущая функция завершается, эта функция удаляется из стека вызовов. Таким образом, глядя на функции, помещенные в стек вызовов, мы можем увидеть все функции, которые были вызваны для перехода к текущей точке выполнения.
Приведенная выше аналогия с почтовыми ящиками в значительной степени похожа на то, как работает стек вызовов. Сам стек представляет собой блок адресов памяти фиксированного размера. Почтовые ящики – это адреса памяти, а «элементы», которые мы помещаем в стек, называются кадрами (фреймами) стека. Кадр стека отслеживает все данные, связанные с одним вызовом функции.
Мы поговорим о стековых кадрах чуть позже. «Маркер» – это регистр (небольшой фрагмент памяти в CPU), известный как указатель стека (иногда сокращенно «SP», «stack pointer»). Указатель стека отслеживает текущее положение вершины стека вызовов.
Мы можем сделать еще одну оптимизацию: когда мы извлекаем элемент из стека вызовов, нам нужно только переместить указатель стека вниз – нам не нужно очищать или обнулять память, используемую извлекаемым кадром стека (эквивалент опустошению почтового ящика). Эта память больше не считается «в стеке» (указатель стека будет по этому адресу или ниже), поэтому к ней не будет доступа. Если мы позже поместим новый кадр стека в ту же самую память, он перезапишет старое значение, которое мы никогда не очищали.
Стек вызовов в действии
Давайте подробнее рассмотрим, как работает стек вызовов. Вот последовательность шагов, которые выполняются при вызове функции:
- Программа обнаруживает вызов функции.
- Кадр стека создается и помещается в стек. Кадр стека состоит из:
- Адрес инструкции, следующей после вызова функции (называемый адресом возврата). Таким образом, CPU запоминает, куда вернуться после выхода из вызываемой функции.
- Все аргументы функции.
- Память для любых локальных переменных.
- Сохраненные копии любых регистров, измененных функцией, которые необходимо восстановить после возврата из функции.
- CPU переходит к начальной точке функции.
- Инструкции внутри функции начинают выполняться.
Когда функция завершается, происходят следующие шаги:
- Регистры восстанавливаются из стека вызовов
- Кадр стека извлекается из стека. Это освобождает память для всех локальных переменных и аргументов.
- Обрабатывается возвращаемое значение.
- CPU возобновляет выполнение по адресу возврата.
Возвращаемые значения могут обрабатываться разными способами в зависимости от архитектуры компьютера. Некоторые архитектуры включают возвращаемое значение как часть кадра стека. Другие используют регистры CPU.
Обычно неважно знать все подробности о том, как работает стек вызовов. Однако понимание того, что функции помещаются в стек при их вызове и удаляются при возврате, дает вам основы, необходимые для понимания рекурсии, а также некоторые другие концепции, полезные при отладке.
Техническое примечание: на некоторых архитектурах стек вызовов при увеличении изменяет адрес памяти в направлении от нуля. На других он при увеличении изменяет адрес в направлении нуля. Как следствие, новые добавленные кадры стека могут иметь более высокий или более низкий адрес памяти, чем предыдущие.
Пример стека вызовов
Рассмотрим следующее простое приложение:
int foo(int x) < // b return x; >// здесь foo извлекается из стека вызовов int main() < // a foo(5); // здесь foo помещается в стек вызовов // c return 0; >
Стек вызовов в отмеченных точках выглядит следующим образом:
main()
foo() (включая параметр x) main()
main()
Переполнение стека
Стек имеет ограниченный размер и, следовательно, может содержать только ограниченный объем информации. В Windows размер стека по умолчанию составляет 1 МБ. На некоторых Unix-машинах он может достигать 8 МБ.
Если программа попытается поместить в стек слишком много информации, произойдет переполнение стека. Переполнение стека происходит, когда вся память в стеке была выделена – в этом случае дальнейшие размещения начинают переполняться в другие разделы памяти.
Переполнение стека обычно является результатом выделения слишком большого количества переменных в стеке и/или выполнения слишком большого количества вызовов вложенных функций (где функция A вызывает функцию B, вызывающую функцию C, вызывающую функцию D и т.д.). В современных операционных системах переполнение стека обычно приводит к тому, что ваша ОС выдаст нарушение прав доступа и завершит программу.
Вот пример программы, которая может вызвать переполнение стека. Вы можете запустить его на своей системе и посмотреть, как она завершится со сбоем:
#include int main()
Эта программа пытается разместить в стеке огромный массив (примерно 40 МБ). Поскольку стек недостаточно велик для обработки этого массива, размещение массива переполняется в части памяти, которые программе не разрешено использовать.
В Windows (Visual Studio) эта программа дает следующий результат:
HelloWorld.exe (process 15916) exited with code -1073741571.
-1073741571 – это c0000005 в шестнадцатеричном формате, что представляет собой код ОС Windows для нарушения прав доступа. Обратите внимание, что «hi» никогда не печатается, потому что программа завершается до этого момента.
Вот еще одна программа, которая вызовет переполнение стека, но по другой причине:
void foo() < foo(); >int main()
В приведенной выше программе кадр стека помещается в стек каждый раз, когда вызывается функция foo() . Поскольку foo() вызывает себя бесконечно, в конечном итоге в стеке закончится память и произойдет переполнение.
У стека есть достоинства и недостатки:
- Выделение памяти в стеке происходит сравнительно быстро.
- Память, выделенная в стеке, остается в области видимости, пока находится в стеке. При извлечении из стека она уничтожается.
- Вся память, выделенная в стеке, известна во время компиляции. Следовательно, к этой памяти можно получить доступ напрямую через переменную.
- Поскольку стек относительно невелик, обычно не рекомендуется в стеке делать что-либо, занимающее много места. Это включает в себя передачу по значению или создание локальных переменных для больших массивов или других структур с интенсивным использованием памяти.
Источник: radioprog.ru
Принципы программирования: стек и куча: что это такое?
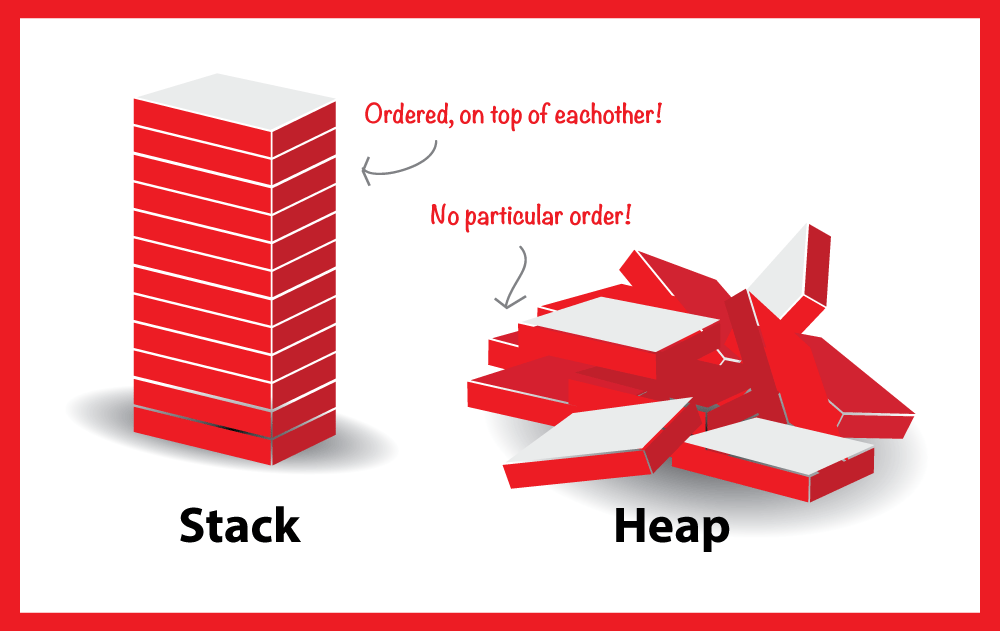
С каждым годом мы применяем для программирования всё более продвинутые языки, позволяющие писать меньше кода, но получать нужные нам результаты. Однако всё это не проходит даром для разработчиков. Так как программисты всё реже занимаются низкоуровневыми вещами, уже никого не удивляет ситуация, когда разработчик не вполне понимает, что означают такие понятия, как куча и стек. Что это такое, как происходит компиляция на самом деле, в чём разница между динамической и статической типизацией.
К сожалению, некоторые программисты, даже будучи «джуниорами» и работая на реальных проектах, не совсем чётко ориентируются в таких, казалось бы, олдскульных вещах. Именно поэтому в нашей сегодняшней статье мы вспомним, что же это такое — стек и куча, для чего они нужны и где применяются. Несмотря на то, что и стек, и куча связаны с управлением памятью, стратегия и принципы управления кардинально различаются.
Стек — что это такое?
Большое число задач, связанных с обработкой информации, поддаются типизированному решению. В результате совсем неудивительно, что многие из них решаются с помощью специально придуманных методов, терминов и описаний. Среди них нередко можно услышать и такое слово, как стек (стэк). Хоть и звучит этот термин, на первый взгляд, странно и даже сложно, всё намного проще, чем кажется.
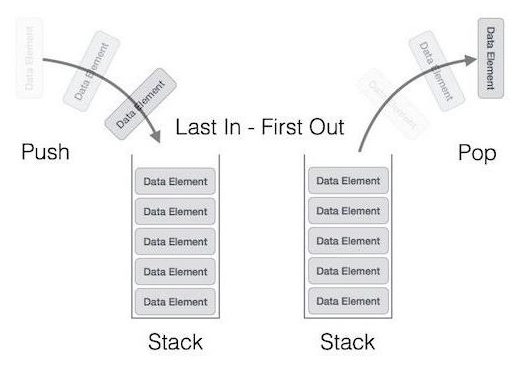
Итак, стек — это метод представления однотипных данных в порядке LIFO (Last In — First Out, то бишь, «первый вошел — последний вышел»). Некоторые ассоциируют стек с оружейным магазином для патронов, так как принцип работы схож, и первый вставленный в магазин патрон будет использоваться в последнюю очередь (у термина стек бывают и другие значения, поэтому, если речь идёт не об информационных технологиях, то смысл лучше уточнить).
Стек и простой жизненный пример
Представьте, что на столе в коробке лежит стопка бумажных листов. Чтобы получить доступ к самому нижнему листу, вам нужно достать самый первый лист, потом второй и так далее, пока не доберётесь до последнего. По схожему принципу и устроен стек: чтобы последний элемент стека стал верхним, нужно сначала вытащить все остальные.
Стек и особенности его работы
Перейдя к компьютерной терминологии, скажем, что стек — это область оперативной памяти, создаваемая для каждого потока. И последний добавленный в стек кусочек памяти и будет первым в очереди, то есть первым на вывод из стека. И каждый раз, когда функцией объявляется переменная, она, прежде всего, добавляется в стек. А когда данная переменная пропадает из нашей области видимости (к примеру, функция заканчивается), эта самая переменная автоматически удаляется из стека. При этом если стековая переменная освобождается, то и область памяти, в свою очередь, становится доступной и свободной для других стековых переменных.
Благодаря природе, которую имеет стек, управление памятью становится весьма простым и логичным для выполнения на центральном процессоре. Это повышает скорость и быстродействие ЦП, и в особенности такое происходит потому, что время цикла обновления байта весьма незначительно (данный байт, скорее всего, привязан к кэшу центрального процессора).
Тем не менее у данной довольно строгой формы управления имеются и свои недостатки. Например, размер стека — это величина фиксированная, в результате чего при превышении лимита памяти, выделенной на стеке, произойдёт переполнение стека. Как правило, размер задаётся во время создания потока, плюс у каждой переменной имеется максимальный размер, который зависит от типа данных. Всё это позволяет ограничивать размеры некоторых переменных (допустим, целочисленных).
Кроме того, это вынуждает объявлять размер более сложных типов данных (к примеру, массивов) заранее, так как стек не позволит потом изменить его. Вдобавок ко всему, переменные, которые расположены на стеке, являются всегда локальными.
Для чего нужен стек?
Главное предназначение стека — решение типовых задач, предусматривающих поддержку последовательности состояний или связанных с инверсионным представлением данных. В компьютерной отрасли стек применяется в аппаратных устройствах (например, в центральном процессоре, как уже было упомянуто выше).
Практически каждый, кто занимался программированием, знает, что без стека невозможна рекурсия, так как при любом повторном входе в функцию требуется сохранение текущего состояния на вершине, причём при каждом выходе из функции, нужно быстро восстанавливать это состояние (как раз наша последовательность LIFO).
Если же копнуть глубже, то можно сказать, что, по сути, весь подход к запуску и выполнению приложений устроен на принципах стека. Не секрет, что прежде чем каждая следующая программа, запущенная из основной, будет выполняться, состояние предыдущей занесётся в стек, чтобы, когда следующая запущенная подпрограмма закончит выполняться, предыдущее приложение продолжило работу с места остановки.
Стеки и операции стека
Если говорить об основных операциях, то стек имеет таковых две: 1. Push — ни что иное, как добавление элемента непосредственно в вершину стека. 2. Pop — извлечение из стека верхнего элемента.
Также, используя стек, иногда выполняют чтение верхнего элемента, не выполняя его извлечение. Для этого предназначена операция peek.
Как организуется стек?
Когда программисты организуют или реализуют стек, они применяют два варианта: 1. Используя массив и переменную, указывающую на ячейку вершины стека. 2. Используя связанные списки.
У этих двух вариантов реализации стека есть и плюсы, и минусы. К примеру, связанные списки считаются более безопасными в плане применения, ведь каждый добавляемый элемент располагается в динамически созданной структуре (раз нет проблем с числом элементов, значит, отсутствуют дырки в безопасности, позволяющие свободно перемещаться в памяти программного приложения). Однако с точки зрения хранения и скорости применения связанные списки не столь эффективны, так как, во-первых, требуют дополнительного места для хранения указателей, во-вторых, разбросаны в памяти и не расположены друг за другом, если сравнивать с массивами.
Подытожим: стек позволяет управлять памятью более эффективно. Однако помните, что если вам потребуется использовать глобальные переменные либо динамические структуры данных, то лучше обратить своё внимание на кучу.
Стек и куча
Куча — хранилище памяти, расположенное в ОЗУ. Оно допускает динамическое выделение памяти и работает не так, как стек. По сути, речь идёт о простом складе для ваших переменных. Когда вы выделяете здесь участок памяти для хранения, к ней можно обращаться как в потоке, так и во всём приложении в целом (именно так и определяются переменные глобального типа). По завершении работы приложения все выделенные участки освобождаются.
Размер кучи задаётся во время запуска приложения, однако, в отличие от того, как работает стек, в куче размер ограничен только физически, что позволяет создавать переменные динамического типа.
Если сравнивать, опять же, с тем, как работает стек, то куча функционирует медленнее, т. к. переменные разбросаны по памяти, а не находятся вверху стека. Тем не менее данный факт не уменьшает важности кучи, и если вам надо работать с глобальными либо динамическими переменными, она больше подходит. Однако управлять памятью тогда должен программист либо сборщик мусора.
Итак, теперь вы знаете и что такое стек, и что такое куча. Это довольно простые знания, больше подходящие для новичков. Если же вас интересуют более серьёзные профессиональные навыки, выбирайте нужный вам курс по программированию в OTUS!
Источник: otus.ru
Принципы программирования: стек и куча: что это такое?
С каждым годом мы применяем для программирования всё более продвинутые языки, позволяющие писать меньше кода, но получать нужные нам результаты. Однако всё это не проходит даром для разработчиков. Так как программисты всё реже занимаются низкоуровневыми вещами, уже никого не удивляет ситуация, когда разработчик не вполне понимает, что означают такие понятия, как куча и стек . Что это такое , как происходит компиляция на самом деле, в чём разница между динамической и статической типизацией.
К сожалению, некоторые программисты, даже будучи «джуниорами» и работая на реальных проектах, не совсем чётко ориентируются в таких, казалось бы, олдскульных вещах. Именно поэтому в нашей сегодняшней статье мы вспомним, что же это такое — стек и куча, для чего они нужны и где применяются. Несмотря на то, что и стек , и куча связаны с управлением памятью , стратегия и принципы управления кардинально различаются.
Стек — что это такое?
Большое число задач, связанных с обработкой информации, поддаются типизированному решению. В результате совсем неудивительно, что многие из них решаются с помощью специально придуманных методов, терминов и описаний. Среди них нередко можно услышать и такое слово, как стек (стэк). Хоть и звучит этот термин, на первый взгляд, странно и даже сложно, всё намного проще, чем кажется.
Итак, стек — это метод представления однотипных данных в порядке LIFO (Last In — First Out, то бишь, «первый вошел — последний вышел»). Некоторые ассоциируют стек с оружейным магазином для патронов, так как принцип работы схож, и первый вставленный в магазин патрон будет использоваться в последнюю очередь (у термина стек бывают и другие значения, поэтому, если речь идёт не об информационных технологиях, то смысл лучше уточнить).
Стек и простой жизненный пример
Представьте, что на столе в коробке лежит стопка бумажных листов. Чтобы получить доступ к самому нижнему листу, вам нужно достать самый первый лист, потом второй и так далее, пока не доберётесь до последнего . По схожему принципу и устроен стек : чтобы последний элемент стека стал верхним, нужно сначала вытащить все остальные.
Стек и особенности его работы
Перейдя к компьютерной терминологии, скажем, что стек — это область оперативной памяти, создаваемая для каждого потока. И последний добавленный в стек кусочек памяти и будет первым в очереди, то есть первым на вывод из стека. И каждый раз, когда функцией объявляется переменная, она, прежде всего, добавляется в стек . А когда данная переменная пропадает из нашей области видимости (к примеру, функция заканчивается), эта самая переменная автоматически удаляется из стека. При этом если стековая переменная освобождается, то и область памяти, в свою очередь, становится доступной и свободной для других стековых переменных.
Благодаря природе, которую имеет стек , управление памятью становится весьма простым и логичным для выполнения на центральном процессоре. Это повышает скорость и быстродействие ЦП, и в особенности такое происходит потому, что время цикла обновления байта весьма незначительно (данный байт, скорее всего, привязан к кэшу центрального процессора).
Тем не менее у данной довольно строгой формы управления имеются и свои недостатки. Например, размер стека — это величина фиксированная , в результате чего при превышении лимита памяти, выделенной на стеке, произойдёт переполнение стека . Как правило, размер задаётся во время создания потока, плюс у каждой переменной имеется максимальный размер, который зависит от типа данных. Всё это позволяет ограничивать размеры некоторых переменных (допустим, целочисленных).
Кроме того, это вынуждает объявлять размер более сложных типов данных (к примеру, массивов) заранее, так как стек не позволит потом изменить его. Вдобавок ко всему, переменные, которые расположены на стеке, являются всегда локальными.
Для чего нужен стек?
Главное предназначение стека — решение типовых задач, предусматривающих поддержку последовательности состояний или связанных с инверсионным представлением данных. В компьютерной отрасли стек применяется в аппаратных устройствах (например, в центральном процессоре, как уже было упомянуто выше).
Практически каждый, кто занимался программированием, знает, что без стека невозможна рекурсия , так как при любом повторном входе в функцию требуется сохранение текущего состояния на вершине, причём при каждом выходе из функции, нужно быстро восстанавливать это состояние (как раз наша последовательность LIFO).
Если же копнуть глубже, то можно сказать, что, по сути, весь подход к запуску и выполнению приложений устроен на принципах стека . Не секрет, что прежде чем каждая следующая программа, запущенная из основной, будет выполняться, состояние предыдущей занесётся в стек, чтобы, когда следующая запущенная подпрограмма закончит выполняться, предыдущее приложение продолжило работу с места остановки.
Стеки и операции стека
Если говорить об основных операциях, то стек имеет таковых две:
1. Push — ни что иное, как добавление элемента непосредственно в вершину стека.
2. Pop — извлечение из стека верхнего элемента.
Также, используя стек , иногда выполняют чтение верхнего элемента, не выполняя его извлечение. Для этого предназначена операция peek .
Как организуется стек?
Когда программисты организуют или реализуют стек , они применяют два варианта:
1. Используя массив и переменную, указывающую на ячейку вершины стека.
2. Используя связанные списки.
У этих двух вариантов реализации стека есть и плюсы, и минусы. К примеру, связанные списки считаются более безопасными в плане применения, ведь каждый добавляемый элемент располагается в динамически созданной структуре (раз нет проблем с числом элементов, значит, отсутствуют дырки в безопасности, позволяющие свободно перемещаться в памяти программного приложения). Однако с точки зрения хранения и скорости применения связанные списки не столь эффективны, так как, во-первых, требуют дополнительного места для хранения указателей, во-вторых, разбросаны в памяти и не расположены друг за другом, если сравнивать с массивами.
Подытожим : стек позволяет управлять памятью более эффективно. Однако помните, что если вам потребуется использовать глобальные переменные либо динамические структуры данных, то лучше обратить своё внимание на кучу.
Стек и куча
Куча — хранилище памяти, расположенное в ОЗУ. Оно допускает динамическое выделение памяти и работает не так, как стек . По сути, речь идёт о простом складе для ваших переменных. Когда вы выделяете здесь участок памяти для хранения, к ней можно обращаться как в потоке, так и во всём приложении в целом (именно так и определяются переменные глобального типа). По завершении работы приложения все выделенные участки освобождаются.
Размер кучи задаётся во время запуска приложения, однако, в отличие от того, как работает стек , в куче размер ограничен только физически, что позволяет создавать переменные динамического типа .
Если сравнивать, опять же, с тем, как работает стек , то куча функционирует медленнее, т. к. переменные разбросаны по памяти, а не находятся вверху стека. Тем не менее данный факт не уменьшает важности кучи, и если вам надо работать с глобальными либо динамическими переменными , она больше подходит. Однако управлять памятью тогда должен программист либо сборщик мусора.
Итак, теперь вы знаете и что такое стек , и что такое куча. Это довольно простые знания, больше подходящие для новичков. Если же вас интересуют более серьёзные профессиональные навыки, выбирайте нужный вам курс по программированию в OTUS!
Хотите начать свою карьеру в IT в качестве разработчика на C++?
Приглашаем вас 22 марта в 20:00 (мск) на открытый вебинар «Настройка VSCode для повседневной работы и отладки кода» . Вместе с Сергеем Кольцовым, Senior Developer С++ в VisionLabs, поговорим о перспективах языка C++, его особенностях и посмотрим примеры использования.
Источник: dzen.ru
Применяемый стек технологий
Стек (англ. stack – стопка) технологий — это набор инструментов, применяющийся при работе в проектах и включающий языки программирования, фрэймворки, системы управления базами данных, компиляторы и т. д.
От выбранного разработчиком стека технологий зависят производительность работы, требования к аппаратным ресурсам, надежность работы программного обеспечения (ПО). В итоге для сложных процессов и высоконагруженных систем им определяется насколько финансово доступно будет развернуть систему и эксплуатировать ее, а также насколько она будет соответствовать требованиям, предъявляемым заказчиком.

При разработке ПО наша компания использует такие языки программирования как Go (Golang), PHP, PowerScript, C/C++, JavaScript, Python. В новых проектах PHP, PowerScript, C/C++ не используются, основным языком программирования является Go.
Go — компилируемый многопоточный язык программирования, разработанный компанией Google. Go имеет обширную стандартную библиотеку и большое количество пакетов разработанных golang-сообществом. Он отлично подходит для создания высоконагруженных backend приложений. Мы используем GO с MVC фреймворком revel.
На стороне frontend мы используем кроссбраузерный js-фреймворк Webix, который позволяет быстро создавать мобильные и настольные веб-приложения. Также во frontend используется JQuery, нативные html и js. Наши приложения используют такие СУБД как PostgreSQL, Oracle, MySQL и SQLite.
Внутренние процессы автоматизируются скриптами на Python и Perl. Для создания инсталляторов под Windows используем InnoSetup. Приложения, разработанные нашей компанией создаются с поддержкой Windows и Linux.
Преимущества выбранного стека технологий заключаются в высокой надежности, в разы, а иногда и на порядки более высокой производительности и меньших требованиях к ресурсам, чем у других популярных представителей, таких как Java, Ruby и т. д. Также важным фактором является открытость исходного кода самих компиляторов языка, что особенно актуально для проектов с госзаказчиками.
Проектные группы работают с системой контроля версий Git в связке с Gerrit. Для учета задач используется система учета задач и проектов RedMine. Разработка ПО ведется в соответствии с методологией SCRUM.

А теперь давайте подробнее рассмотрим что именно, как и почему мы используем.
Эрнесту Резерфорду, «отцу» ядерной физики, приписывается высказывание — «Если учёный не может объяснить уборщице, которая убирается у него в лаборатории, смысл своей работы, то он сам не понимает, что он делает.». Следуя этому утверждению, мы постараемся рассказать, чем занимается отдел разработки в RBS таким образом, чтобы рассказ был достаточно точным технически, но в то же время понятен даже далеким от разработки программного обеспечения людям. Надеемся, что после прочтения статьи ни у кого, а особенно у кандидатов на должность инженера-разработчика, не останется вопросов «чем вы занимаетесь», «какие инструменты применяете» и «почему именно их».
Итак, без лишних слов: отдел разработки ПО трудится пять дней в неделю на пользу общества, в самом широком смысле, работая над улучшением безопасности дорожного движения и развитием системы образования. Для решения этих, безусловно, важных задач, наша компания создает специализированные программы, которые помогают сотрудникам многих коммерческих организаций и государственных учреждений обеспечивать соблюдение жизненно важных правил всеми участниками дорожного движения.
Эти программы представляют собой информационные системы с удобным для пользователя графическим интерфейсом, базами данных для хранения информации, и серверами, которые обрабатывают, вычисляют, сохраняют и анализируют данные. В общем-то, они делают то же самое, что и рядовые сотрудники различных компаний, ГИБДД, МРЭО, Гостехнадзора и Автошкол, только автоматически, быстро и точно.

Каждой задаче требуется свой инструмент, и когда перед нами встала задача автоматизации бизнес-процессов вышеупомянутых организаций, мы выбрали инструментарий, обычно используемый при разработке web-приложений. Это клиент-серверные технологии, когда часть программы выполняется на централизованном сервере, а часть — на компьютере пользователя.
Такая архитектура позволяет очень четко отделить пользовательский интерфейс от сложных вычислительных процессов над данными. Обычно данные обрабатываются и хранятся на сервере, это называется «backend», а выводятся у пользователя, на «клиенте», и это называется «frontend». Это очень похоже на работу типичного сайта — пользователь читает новости в своем браузере, не задумываясь, каким образом эти новости были получены, а получены они были от сервера, где хранились в базе данных, и были извлечены из нее серверным приложением («backend’ом»). Как и у сайта из примера, у нас применяются базы данных для хранения огромных массивов информации, и именно им будет посвящен следующий абзац.

Одна из задач, которую мы решаем, это обработка данных о нарушениях правил ПДД, поступающих с огромного количества камер фотовидеофиксации, со всего города. Это очень большой объем данных, и мало эти данные обработать, их необходимо где-то хранить. Для хранения мы применяем системы управления базами данных, такие как PostgreSQL, Oracle.
Причем, все новые проекты, как правило, разрабатываются с использованием именно PostgreSQL, так как, во-первых, она достаточно функциональна для работы с большим объемом данных, а, во-вторых, не ограничивается коммерческими лицензиями, и это дает уверенность в свободе этой системы от политических или деловых решений владельцев СУБД. В ранних проектах компании RBS для работы с данными применялась СУБД Oracle, и это означает, что разработчик должен уметь работать с ней, чтобы мы могли поддерживать всех наших клиентов. О необходимости владения языком запросов SQL говорить молодому разработчику нет смысла, это должно быть очевидно.

Для того, чтобы данные, задействованные в некотором бизнес-процессе, сохранить в базу данных после предварительной обработки и некоторых вычислений, необходимо серверное приложение, которое должно отвечать перечисленным далее требованиям. Во-первых, оно должно быть очень быстрым. Во-вторых, оно должно поддерживать параллельную обработку данных, ведь их так много.
В-третьих, оно должно быть надежным. И, наконец, оно должно быть достаточно простым, чтобы множество разработчиков разного уровня компетенции и опыта, смогли работать над новым функционалом. В поисках языка программирования, соответствующего этим требованиям, мы нашли Golang. Это многопоточный (параллельность обработки данных), компилируемый (скорость и надежность) язык программирования общего назначения (подходит для разных задач), разработанный в недрах компании Google, и свободно распространяемый среди разработчиков, в том числе для коммерческого использования. У этого языка достаточно низкий порог вхождения, чтобы даже junior-программисты, после краткой практики, смогли полноценно работать над созданием серверных приложений.

Ранее в статье мы рассказали, что наши информационные системы — это клиент-серверные web-приложения, и раз мы уже разобрали базы данных и серверы, значит пришло время клиентской части приложения — frontend. Frontend, он же «клиентское приложение», это та часть программы, которая работает на стороне пользователя, и, как правило, отвечает за отрисовку графического интерфейса, ввод данных в формы, а также за взаимодействие с сервером (по протоколу HTTP, асинхронно, если кому-либо интересно).
В этой области де-факто стандартом является связка JavaScript + HTML + CSS. Первый — это язык программирования, выполняемый прямо в браузере — он отвечает за всю логику клиентского приложения и отправку данных на сервер или обработку данных с сервера. Два последних — это типичные для сайтостроения средства верстки графического интерфейса. Стажеру, едва только устроившемуся в наш отдел разработки, следует особое внимание уделить именно этим технологиям — с них начнется его путь к должности старшего разработчика. И пусть он не обманывается низким порогом вхождения в JavaScript – он легок в самом начале, и значительно усложняется пропорционально увеличению опыта, когда стажер переходит от простеньких скриптов, и приступает к разработке клиентского приложения для большой информационной системы.
Каждый программист может подтвердить, что разработчики — «ленивые» люди. Они всеми силами стараются избежать выполнения одной и той же работы, автоматизируя ее и используя уже готовые решения, образно говоря, «не изобретая велосипед». Это в том числе означает, что, начиная разработку новой информационной системы, мы ищем библиотеки и фреймворки, которые решают типовые задачи, возникающие в процессе создания клиент-серверных программ. Например, для создания HTTP-сервера, и в качестве каркаса серверного приложения с RESTful интерфейсом, мы используем MVC фреймворк Revel, написанный на Golang, а для создания графического интерфейса — виджетный фреймворк Webix, написанный на JavaScript. Список можно продолжить библиотеками JQuery, JQueryUI, Angular, Bootstrap, Yii (это для поддержки ранних проектов на PHP), и многими другими.
А еще, отчасти из-за нежелания заниматься рутинными задачами, но главное, для создания надежных программ, мы применяем средства автоматизированного тестирования приложений, то есть юнит-тесты и функциональные тесты. Кроме того, каждая строчка кода, написанная разработчиками, проверяется более опытными товарищами с помощью системы контроля версий Git и системой review Gerrit.

Кстати, раз уж пошла речь о надежности программ и проверке результатов, стоит упомянуть о том, как проектируется и разрабатывается приложение. Обычно некий старший разработчик, тимлид или архитектор, после постановки задачи от системного аналитика, описывает будущую программу на понятном специалистам техническом языке — в виде моделей и диаграмм.
Мы применяем реляционные модели баз данных, диаграммы в нотации UML и модели процессов в нотации BPMN. После этого задача разработки программы дробится на небольшие подзадачи, которые назначаются исполнителям. Для каждой функциональной возможности сначала создается автоматизированный тест, а уже после программный код, который должен «пройти» этот тест.
Это называется «разработка через тестирование», а в англоязычной литературе «TDD». Такой подход кажется странным, но его легко понять с помощью аналогии: представьте, что вы создаете новый автомобиль. У автомобиля есть определенные требования по безопасности, и зная их, вы с самого начала строите тестовую площадку для краш-тестов в соответствие с этими требованиями, и будете проводить на ней испытания для каждой новой версии автомобиля, пока не убедитесь, что он готов к массовой продаже. Так и мы, зная требования клиентов, строим полигоны для «краш-тестов» функционала, и пишем код до тех пор, пока он не будет соответствовать этим требованиям. И уже убедившись, что программа готова к выпуску «в свет», мы передаем ее в отдел тестирования, который проверяет программу «глазами пользователя».

Рассказав о применяемых в отделе разработки технологиях и подходах, мы надеемся, что ответили на вопросы, поставленные в начале статьи, и в заключение кратко перечислим, что должен уметь разработчик, чтобы работать программистом в нашей компании:
- Работать с базами данных, владея SQL, и имея знания о специфике PostgreSQL и Oracle.
- Создавать высоконагруженные серверные MVC-приложения на языке Golang, используя в качестве каркаса фреймворк Revel.
- Создавать клиентские приложения, с помощью JavaScript. Здесь же верстка графического интерфейса на HTML и CSS, применяя фреймворк Webix и другие необходимые библиотеки.
- Проектировать программное обеспечение, описывая будущее приложение на UML и BPMN, применяя аналитику, системный подход и воображение.
- Создавать автоматические тесты.
- Работать в команде, обмениваясь кодом через систему контроля версий, и применяя коммуникативные навыки.
- Составлять техническую и пользовательскую документацию.
- Трудолюбиво и ответственно работать на благо общества.
Если вы начинающий программист, и хотите устроиться в качестве разработчика в нашу компанию, но не обладаете всеми перечисленными навыками — не беда, мы вас всему научим в процессе. Главное иметь сильное желание научиться и достаточное упорство. Ну, и по-мелочи — базовые навыки программирования и знание по крайней мере одного языка программирования будут не лишними, конечно. Так что можете смело приходить на регулярно проводимые собеседования, но предварительно подготовившись, конечно, чтобы выделяться на фоне других кандидатов.
Удачи вам, и спасибо за внимание.
Соответствует фразе: применяемые технологии разработки
- 22400 просмотров
Источник: rainbowsoft.ru
Стек — что это такое и как он устроен? Какие виды стеков бывают
Продолжаю объяснять сложные компьютерные термины простыми словами. Сегодня расскажу, что такое стек в программировании, как он устроен и каких видов бывает.
Это будет полезно для тех, кто в будущем планирует серьезно работать в сфере IT, ведь это одна из основополагающих концепций программирования, влияющих на качество кода, но не касающихся конкретного языка.

Что такое стек простыми словами
По традиции рассказ начну с определения. Термин пришел из английского языка: слово stack переводится как «пробка».
Стек — это один из способов организации и хранения информации в программировании. Если говорить профессиональным языком, это одна из структур данных.
Википедия дает определение стеку как абстрактному типу данных, представленному в виде организованного по принципу LIFO списка элементов. В свою очередь, аббревиатура LIFO расшифровывается как last in — first out, то есть «пришел последним, а вышел первым».
Термин появился в середине XX века благодаря Алану Тьюрингу. В таких языках программирования как Python и Lisp стеком называют любой список, потому что для них доступны операции выталкивания (pop на английском) и проталкивания (push). Для стека характерна еще одна операция — чтение головного элемента (по-английски — peek).
Как устроен стек
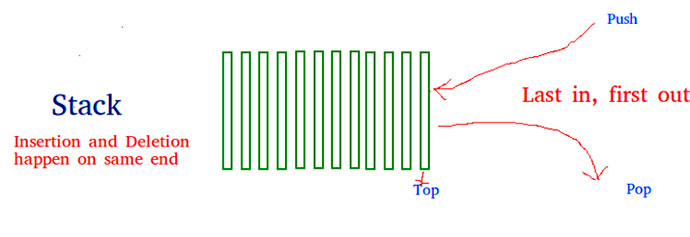
Программисты часто сравнивают стек со стопкой одинаковых тарелок, ведь он работает по схожему принципу: поставленная позже всех тарелка будет использоваться первой. Вряд ли кто-то будет пытаться вытягивать тарелку из середины или низа стопки. А чтобы взять вторую тарелку сверху, нужно в обязательном порядке сначала снять первую.
В стеке важна последовательность данных и здесь применима линейная связь:
Данные следуют друг за другом, брать их из произвольного места нельзя.
Добавление или проталкивание (на английском — push) элемента возможно только в вершину стека. Как только элемент стека использован, он удаляется (процесс называется выталкиванием, или pop на английском), а верхним элементом (top) становится следующий.
Исходя из вышесказанного, выделю главный принцип работы стека: данные, которые попали последними, используются первыми. А если информация попала первой, то она должна использоваться последней.
Похожим образом реализована другая структура данных — очередь (queue на английском). Но разница лишь в том, что в очереди первым используется раньше всех попавший в нее элемент, а последним — тот, что позже всех. Для наглядности представьте очередь на кассе супермаркета: кто первым занял место, тот первым и расплатился. Все, как и в реальной жизни.
Виды стеков
Различают две разновидности стеков:
- стек вызовов;
- стек данных.
Расскажу подробнее о каждом из них.
Стек вызовов
Стек вызовов — это область памяти, в которой хранится информация о точках перехода между фрагментами программного кода.
Этот вид используется, когда в программе есть подпрограммы и компьютеру нужно запомнить место, где программный код прерывался для выполнения подпрограммы, чтобы потом вернуться к выполнению основного кода. Если подпрограмма вдобавок вернула определенную информацию, компьютер должен запомнить и ее, а потом еще и передать в код основной программы.
Стек практически всегда хранится в оперативной памяти. Так как каждый стек занимает в ОЗУ определенное место, в случае слишком большого количества подобных элементов может случиться такая ситуация как переполнение. Почему это плохо? Потому что в этом случае данные могут попасть в область памяти другого элемента и перезаписать себя вместо той информации, которая там должна быть.
Это чревато следующими проблемами:
- сбоем в работе других программ;
- сбоем в работе ПК;
- внедрением вредоносного кода в оперативную память.
Стек данных
Стек данных очень схож со стеком вызовов и работает с ним по тому же принципу: первым используется последний добавленный в него элемент, а последним — тот элемент, который попал туда раньше других.
Стек данных обычно используется для работы со сложными типами информации:
- быстрого обхода деревьев;
- поиска возможных маршрутов по графу;
- анализа разветвленных однотипных данных;
- и так далее.
Вот и все, дорогие друзья. Теперь вы имеете представление о таком понятии, как стек, как он устроен и каковы его разновидности существуют. Надеюсь, что вам все было понятно и после прочтения статьи вопросы отпадут сами собой. Если нет, то спускайтесь в комментарии к публикации, спрашивайте, что было непонятно, а другие читатели блога KtoNaNovenkogo.ru помогут найти ответы.
Я вернусь к вам с новой статьей уже совсем скоро. Не забудьте также посмотреть полезное видео по теме, которое вы найдете под этой статьей.
Удачи вам! До скорых встреч на страницах блога KtoNaNovenkogo.ru
Эта статья относится к рубрикам:
Дмитрий, к какой рубрики относиться данная статья. Заранее благодарю!
Ваш комментарий или отзыв
Источник: ktonanovenkogo.ru