
Помогите с библиотекой Speech Recognition
Обычная функция Speech Recognitition, которая выводит на экран то что вы сказали, но прежде чем она выведет что я сказал, мне надо будет примерно 3 секунды помолчать и только тогда программа поймёт что я уже ничего не говорю и выведет текст, и для моего проекта это совершенно не подходит. Вопрос: Можно ли «завершить» прослушивание программой голоса вручную и убрать эту задержку тишины?
def command(): r = sr.Recognizer() with sr.Microphone() as source: print(«Говорите») audio = r.listen(source) try: zadanie = r.recognize_google(audio, language=»ru-RU»).lower() print(«Вы сказали: » + zadanie) except sr.UnknownValueError: talk(«Я вас не поняла») zadanie = command() return zadanie
Отслеживать
задан 29 дек 2018 в 13:36
43 8 8 бронзовых знаков
1 ответ 1
Сортировка: Сброс на вариант по умолчанию
Возможно, дело не в молчании. Google speech recognize работает online. За эти 3 секунды возможно он посылает вашу аудиозапись на сервер, а потом она идёт с сервера к вам уже в виде текста. Задержка будет всегда. Если нужно, чтобы программа была без задержек, то нужно использовать оффлайн функции распознавания речи. Их много. НО Google speech recognize один из лучших и точных вариантов.
Уроки Python / Распознавание речи
Так что если будете использовать оффлайн распознавание, возможно уменьшится точность.
Отслеживать
ответ дан 5 июн 2020 в 20:27
159 10 10 бронзовых знаков
Источник: ru.stackoverflow.com
Speech recognition что это за программа
И мы можем использовать Google Web Speech API, который поставляется из этой библиотеки.
В этой реализации я записал свой голос, используя собственный микрофон, и SpeechRecognizer получил доступ к микрофону.(Установить Пакет PyAudio чтобы получить доступ к микрофону)и узнал мой голос соответственно.
Посмотрите фрагмент кода ниже, чтобы понять полную реализацию, так как они относительно понятны.

Спасибо за чтение.
Я надеюсь, что теперь у вас есть лучшее понимание того, как распознавание речи работает в целом и, что наиболее важно, как реализовать это с помощью Google Speech Recognition API с Python.
Не стесняйтесь проверить исходный код здесь если тебе интересно.
Я также рекомендую вам попробовать другие API для сравнения точности преобразования текста в текст.
Несмотря на то, что продукты с поддержкой речи не используются широко на предприятиях и в нашей повседневной жизни на данном этапе, я искренне верю, что эта технология нарушит работу многих компаний и то, как потребители будут использовать продукты с функциями распознавания голоса, рано или поздно.
Как всегда, если у вас есть какие-либо вопросы или комментарии, не стесняйтесь оставлять свои отзывы ниже, или вы всегда можете связаться со мной по LinkedIn, До тех пор, до встречи в следующем посте!
об авторе
Адмонд ли известен как один из самых востребованныхученые-данные и консультантыпомогая начинающим учредителям и различным компаниям решать их проблемы, используя данные с большим опытом вконсалтинг по науке о данных и отраслевые знания,
Вы можете связаться с ним на LinkedIn, средний, щебет, а также facebook или забронировать встречу с ним здесь если вы ищете консалтинга для вашей компании.
Источник: machinelearningmastery.ru
Speech recognition что это за программа


- Главная /
- JAVASCRIPT /
- Распознавание javaScript
Распознавание javaScript

Всем доброго времени суток. Сегодня мы познакомимся с Web Speech API с помощью которого мы можем распознавать наш голос. Естественно для работы с данной технологией понадобится активизировать ваш микрофон. Практически во всех ноутбуках он встроен поэтому больших сложностей здесь не должно предвидеться. Еще вам понадобится защищенный протокол https.
Поехали!
Для начала нужно определить поддерживает ли ваш браузер данную технологию:
if(window.SpeechRecognition || window.webkitSpeechRecognition || window.mozSpeechRecognition || window.msSpeechRecognition)< console.log(‘Браузер поддерживает данную технологию’); >else
Поддержку мы определяем через ключевой объект SpeechRecognition. Сразу скажу что несмотря на проверку данного объекта со всеми вендорными префиксами. Данная технология на момент написания данной статьи поддерживается только в браузерах webkit (google, opera и т. п.), то есть во всех браузерах написанных на движке гугла.
После того как вы определили что ваш браузер поддерживает данную технологию.
var SpeechRecognition = new (window.SpeechRecognition || window.webkitSpeechRecognition || window.mozSpeechRecognition || window.msSpeechRecognition)();
Создаем некий конструктор на выходе которого получаем объект SpeechRecognition. Это главный объект через который мы можем работать со свойствами, методами, событиями Web Speech API .
Рассмотрим на примере:
var SpeechRecognition = new (window.SpeechRecognition || window.webkitSpeechRecognition || window.mozSpeechRecognition || window.msSpeechRecognition)(); SpeechRecognition.lang = «ru-RU»; SpeechRecognition.onresult = function(event)< console.log(event); >; SpeechRecognition.onend = function()< SpeechRecognition.start(); >; SpeechRecognition.start();
Здесь мы активируем Web Speech API.
Рядом с заголовком вкладки должен появится красный маркер. Это означает что ваш микрофон активирован и стоит на прослушке.

Если маркера нет проверьте микрофон и настройки в браузере. Если все хорошо попробуйте произнести что нибудь в микрофон.
В результате каждой голосовой фразы в микрофон у нас в консоли создается объект SpeechRecognition.
Допустим я в микрофон сказал привет:
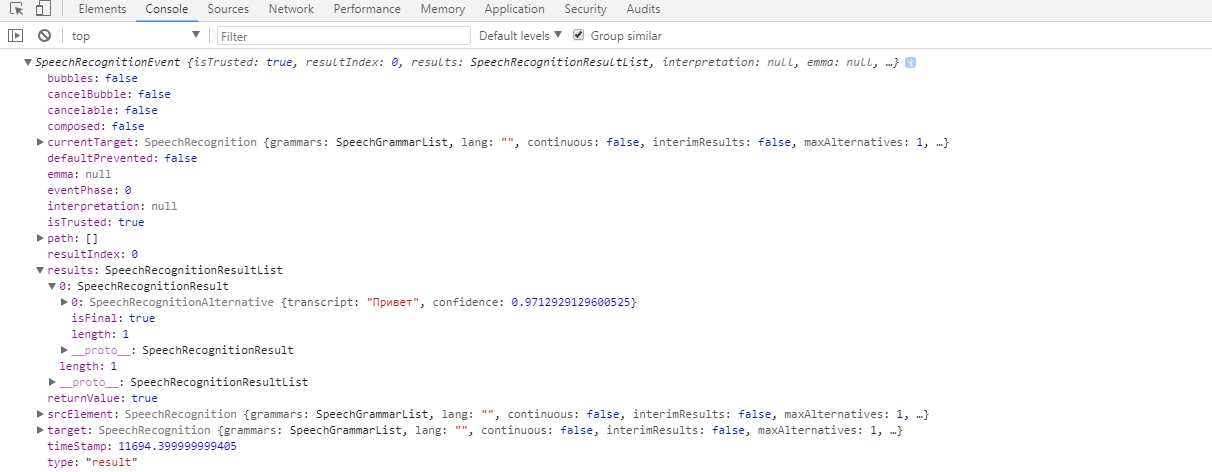
В результате этого у нас в консоли появится объект SpeechRecognition и в его свойстве results мы можем найти фразу которую я сказал в микрофон ‘Привет’.
Причем объект SpeechRecognition выводится в консоль только после завершения голосовой фразы. То есть сколько фраз мы произнесем в микрофон, столько объектов SpeechRecognition мы получим на выходе. Под голосовыми фразами я понимаю фразы произнесенные в микрофон с паузами.
Теперь посмотрим в код.
C помощью свойства lang объекта SpeechRecognition мы определяем язык на который будет делаться акцент при распознавании нашего голоса.
SpeechRecognition.lang = «ru-RU»;
Я выбрал Русский язык. Помимо свойства lang объект SpeechRecognition содержит следующие свойства:
grammars — устанавливает коллекцию объектов грамматики которые будут понятны текущему SpeechRecognition.
interimResults — данное свойство принимает true или false (по умолчанию false) если мы зададим ему значение true. Результаты распознавания будут выводится в процессе произношения фразы. В итоге на одну фразу будут выводится несколько объектов SpeechRecognition содержащие различные варианты определения фразы.
maxAlternatives — определяет максимальное количество предоставляемых результатов на одну фразу(по умолчанию 1)
Далее по коду у нас идет обработка события onresult:
SpeechRecognition.onresult = function(event)< console.log(event); >;
Именно с помощью данного события мы при успешном распознавании нашей фразы получаем в консоль объект SpeechRecognition. Помимо данного события у SpeechRecognition есть следующие события:
onaudiostart — срабатывает когда SpeechRecognition готов к принятию новой голосовой фразы
onaudioend- срабатывает когда SpeechRecognition принял новую голосовую фразу
onend — вызывается когда служба распознавания речи отключилась
onerror — вызывается при ошибке распознавания речи
onspeechend — вызывается когда прекращается распознавание речи
onstart — вызывается с намерением распознать заданную грамматику связанную с текущим распознаванием речи
Как вы наверное могли заметить помимо события onresult мы используем еще onend которое срабатывает при отключении службы распознавания речи. Зачем это было нужно?
Дело в том что служба распознавания речи в браузере работает ограниченное количество времени. У меня к примеру она работала 5-6 секунд, а затем отключалась. И именно через это событие с помощью метода start() я запускаю ее снова как только она отключается.
В результате служба распознавания речи работает беспрерывно. Напоследок нам остается разобрать строчку:
SpeechRecognition.start();
Здесь мы с помощью метода start() объекта SpeechRecognition запускаем службу распознавания речи. Если ее не запустить ничего работать не будет. Помимо данного метода к объекту SpeechRecognition можно применять следующие:
abort() — завершает службу распознавания речи без возвращения результата SpeechRecognitionResult.
stop() — завершает службу распознавания речи и возвращает результат. SpeechRecognitionResult используя уже записанный звук.
В конце хочу вас предупредить что Web Speech API может работать только в одной вкладке браузера.
Если вы откроете две вкладки в которых идет работа с данным api, то не в одной из них не будет работать служба распознавания речи. Даже если эти две вкладки расположены в разных окнах браузера. Помните про это!
К дополнению к данной статье вы можете посмотреть видео на моем канале youtube:
где я рассказываю как используя Web Speech API написать расширение которое осуществляет голосовой поиск в браузере google.
В итоге мы сегодня познакомились с замечательным Web Speech API который позволяет в режиме реального времени распознавать ваш голос. Конечно данная технология еще слабо поддерживается. Но технологический процесс развивается с бешеной скоростью и возможно в самом ближайшем будующем данная технология станет повсеместной.
На этом дорогие друзья у меня на сегодня все.
Желаю вам успехов и удачи! Пока!
Оцените статью:
Статьи
- Теги текста HTML
- база данных php
- Ветки GIT
- Grid CSS
- sms php
- Уведомления javascript
- css zoom
- Общий чат на python
Комментарии
Внимание. Комментарий теперь перед публикацией проходит модерацию
gartes
09:09 29-04-2019
Прикол Конечно . Ни когда не думал что браузер столько мозгов имеет !! Спасибо !!
Запись экрана
Данное расширение позволяет записывать экран и выводит видео в формате webm
Добавить приложение на рабочий стол
Источник: webfanat.com
ИИ на Python для распознавания голоса и выполнения команд

На Python можно строить как простые программы, так и сложные ИИ системы. В данной статье мы покажем как реализовать распознавание голоса и выполнение различных команд.
Перед стартом работы, вам стоит убедиться в нескольких вещах:
- у вас установлен Python на вашем компьютере;
- у вас установлен текстовый редактор, к примеру PyCharm ;
- у вас установлен пакетный менеджер Pip .
Установка библиотек
Для распознавания голоса вам необходимо установить библиотеки:
- SpeechRecognition — команда pip install SpeechRecognition ;
- gTTS — команда pip install gTTS ;
- PyAudio — команда pip install PyAudio .
Все библиотеки стоит устанавливать через терминал в ваш проект через программу PyCharm:

После установки всех библиотек начните прописывать код самой программы. Ниже мы приведем весь код программы с комментариями, дабы вам было проще в нём разобраться:
# Подключение всех необходимых библиотек # Нам нужно: speech_recognition, os, sys, webbrowser # Для первой бибилотеки прописываем также псевдоним import speech_recognition as sr import os import sys import webbrowser # Функция, позволяющая проговаривать слова # Принимает параметр «Слова» и прогроваривает их def talk(words): print(words) # Дополнительно выводим на экран os.system(«say » + words) # Проговариваем слова # Вызов функции и передача строки # именно эта строка будет проговорена компьютером talk(«Привет, чем я могу помочь вам?») «»» Функция command() служит для отслеживания микрофона. Вызывая функцию мы будет слушать что скажет пользователь, при этом для прослушивания будет использован микрофон.
Получение данные будут сконвертированы в строку и далее будет происходить их проверка. «»» def command(): # Создаем объект на основе библиотеки # speech_recognition и вызываем метод для определения данных r = sr.Recognizer() # Начинаем прослушивать микрофон и записываем данные в source with sr.Microphone() as source: # Просто вывод, чтобы мы знали когда говорить print(«Говорите») # Устанавливаем паузу, чтобы прослушивание # началось лишь по прошествию 1 секунды r.pause_threshold = 1 # используем adjust_for_ambient_noise для удаления # посторонних шумов из аудио дорожки r.adjust_for_ambient_noise(source, duration=1) # Полученные данные записываем в переменную audio # пока мы получили лишь mp3 звук audio = r.listen(source) try: # Обрабатываем все при помощи исключений «»» Распознаем данные из mp3 дорожки. Указываем что отслеживаемый язык русский.
Благодаря lower() приводим все в нижний регистр. Теперь мы получили данные в формате строки, которые спокойно можем проверить в условиях «»» zadanie = r.recognize_google(audio, language=»ru-RU»).lower() # Просто отображаем текст что сказал пользователь print(«Вы сказали: » + zadanie) # Если не смогли распознать текст, то будет вызвана эта ошибка except sr.UnknownValueError: # Здесь просто проговариваем слова «Я вас не поняла» # и вызываем снова функцию command() для # получения текста от пользователя talk(«Я вас не поняла») zadanie = command() # В конце функции возвращаем текст задания # или же повторный вызов функции return zadanie # Данная функция служит для проверки текста, # что сказал пользователь (zadanie — текст от пользователя) def makeSomething(zadanie): # Попросту проверяем текст на соответствие # Если в тексте что сказал пользователь есть слова # «открыть сайт», то выполняем команду if ‘открыть сайт’ in zadanie: # Проговариваем текст talk(«Уже открываю») # Указываем сайт для открытия url = ‘https://itproger.com’ # Открываем сайт webbrowser.open(url) # если было сказано «стоп», то останавливаем прогу elif ‘стоп’ in zadanie: # Проговариваем текст talk(«Да, конечно, без проблем») # Выходим из программы sys.exit() # Аналогично elif ‘имя’ in zadanie: talk(«Меня зовут Сири») # Вызов функции для проверки текста будет # осуществляться постоянно, поэтому здесь # прописан бесконечный цикл while while True: makeSomething(command())
Как видите, программа простая и не требует гигантского количества строчек кода. Сам код можете подстраивать в любую программу, дабы добавить в неё функционал прослушивания речи.
Также предлагаем посмотреть видео, где все описано еще более детально:
Полезные ссылки из видео:
- Скачать редактор PyCharm ;
- Скачать пакетный менеджер Pip ;
- Скачать Homebrew для установки PyAudio;
- Пример установки библиотеки PyAudio ;
- Поддержка различных языков .
Источник: itproger.com