
СПАРК, собирая всю доступную информацию о компаниях и извлекая из нее знания, помогает бизнесу снижать риски и эффективно работать с контрагентами.
Пользуясь СПАРКом, вы получаете самые качественные и полные данные о компаниях. Наши технологии превращают информацию в сервисы и аналитику, чтобы вы могли видеть все риски и комплексно оценивать контрагентов, искать между ними связи, управлять дебиторской задолженностью.
1С:СПАРК Риски – безопасность при работе с контрагентами

Аналогичные сервисы по проверки партнеров предлагают многие отечественные компании. Но, программный продукт от СПАРК имеет ряд преимуществ для пользователей 1С:
- клиент может оценить нового контрагента, не выходя из программы;
- сервис позволяет проанализировать платежеспособность потенциального партнера, и не получить безнадежную дебиторскую задолженность;
- мониторинг изменений позволяет оперативно узнать о планируемой ликвидации или реорганизации юридического лица и принять взвешенное решение о подписании контракта;
- в программе формируются подробные справки о предприятии. Для суда или налоговой инспекции такая справка будет служить подтверждением проявления осмотрительности со стороны руководства фирмы.
Как происходит оценка надежности контрагента
Всесторонний анализ деятельности и определение степени надежности предприятия происходит при помощи трех ключевых индексов:
Выборки
- должной осмотрительности (ИДО);
- финансового риска (ИФР);
- платежной дисциплины (ИПД).
Они формируются в 1С:СПАРК Риски и передаются клиентам, пользующимся базой 1С.
ИДО – индекс должной осмотрительности
Первый индекс оценивает степень вероятности создания компании с целью ведения незаконной деятельности и отмывания денег. Устойчивое выражение «отмывание денег» произошло в ХХ веке в Америке, когда преступные группировки открывали прачечные для легализации дохода. Также ИДО способен выявить фирмы-однодневки и друге ненадежные компании.
Уровень индексного риска рассчитывается в балах от 0 до 100. Чем выше балл, тем больше вероятность, что компания ненадежна. И наоборот, минимальное значение индекса указывает на высокий уровень надежности контрагента. Для удобства пользователя после проверки компания подсвечивается одним из цветов, аналогично светофору:
- зеленый 0-40 баллов – высокий уровень надежности, можно смело подписывать договор с таким контрагентом;
- желтый 41-71 балл – средний уровень надежности. Лучше воздержаться от заключения сделки, особенно если значение индекса близко к верхней планке. Но, если необходимо сотрудничать с таким партнером, то лучше провести дополнительные проверки и проявить большую бдительность;
- красный 71-100 баллов – контрагент не надежен, заключать с ним сделку крайне опасно.
В алгоритме исследования надежности поставщика оценивается более 40 параметров деятельности. Точность оценки индекса составляет 93-95%. Данные обновляются ежеквартально.
Онлайн-конференция «Проверка контрагентов в условиях новой реальности»
ИФР – индекс финансового риска
Как работают Spark-приложения в кластере
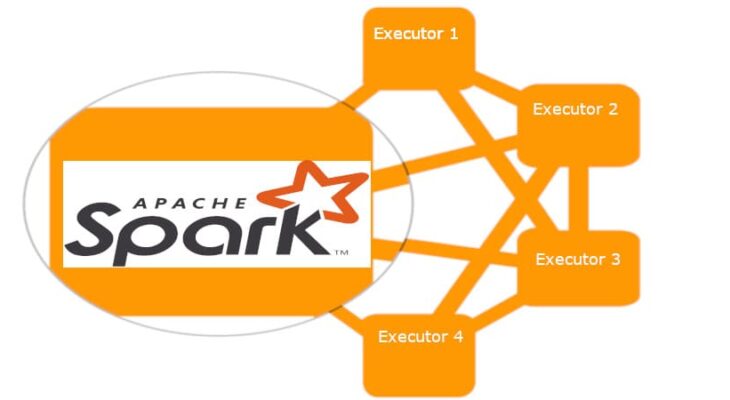
В этой статье мы поговорим о том, как выполняются приложения, которые создавались на базе фреймворка Apache Spark. Читайте далее про архитектуру среды выполнения Spark, а также про компоненты, из которых она состоит.
Как устроены приложения Apache Spark: базовые компоненты архитектуры
Приложения, которые создаются на базе среды Spark, предназначены для выполнения в распределенных системах. Архитектура такой среды включает в себя следующие компоненты:
- драйвер;
- исполнители;
- диспетчер кластера.
Каждый из этих компонентов подробнее мы рассмотрим далее.
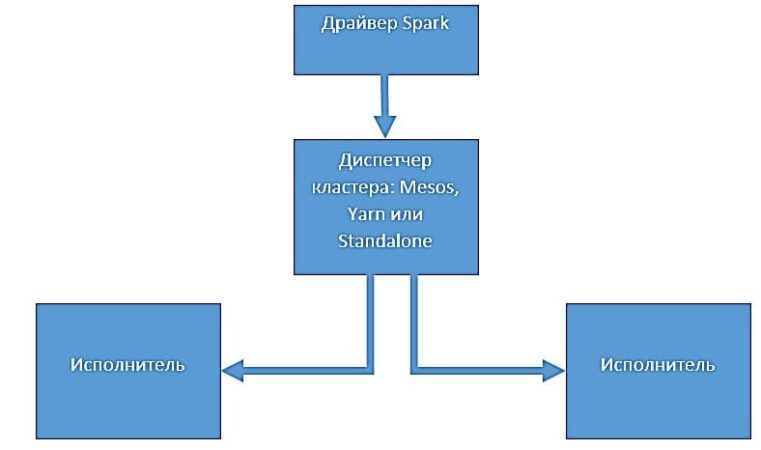
Драйвер Spark
Драйвер Spark представляет собой процесс, который запускает метод main() нашего приложения. Этот процесс запускает код, который создает объект классов SparkContext и SparkConf . Когда запускается интерактивная оболочка Spark, создается экземпляр программы-драйвера:
from pyspark import SparkContext, SparkConf conf = pyspark.SparkConf().setAppName(‘Application1’).setMaster(‘local’) sc = pyspark.SparkContext(conf=conf)
Драйвер Spark преобразует пользовательское приложение на единицы исполнения, которые называются задачами (tasks).
На верхнем уровне все приложения Spark создают наборы RDD на основе исходных данных, тем самым порождая новые RDD с применением некоторых преобразований и выполняют действия для сбора и последующего хранения данных. Таким образом, создается неявный ориентированный ациклический граф (Directed Acyclic Graph, DAG) всех операций.
В процессе выполнения программа-драйвер преобразует этот граф в план выполнения. Драйвер Spark выполняет оптимизации преобразований и преобразует DAG в несколько этапов. Каждый такой этап состоит из нескольких задач. Задача считается наименьшей пользовательской единицей выполнения в Spark.
Приложение может разбиваться на несколько сотен и даже тысяч заданий (в зависимости от функционала). На основе составленного плана со всеми задачами драйвер Spark контролирует передачу этих задач исполнителям. При запуске каждый исполнитель регистрирует себя в драйвере.
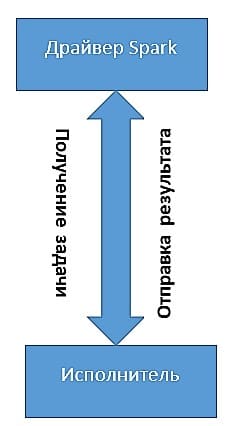
Исполнители
Исполнители в Spark – это рабочие процессы, которые ответственны за выполнение задач, присланных драйвером. Исполнители запускаются только один раз при запуске приложения Spark и продолжают свою работу на протяжении всего жизненного цикла программы. Они выполняют задачи, приходящие от драйвера и возвращают результат обратно драйверу Spark. Исполнители также обеспечивают хранение данных в памяти наборов RDD, которые кэшируются через службу Block Manager, функционирующую внутри каждого из исполнителей.
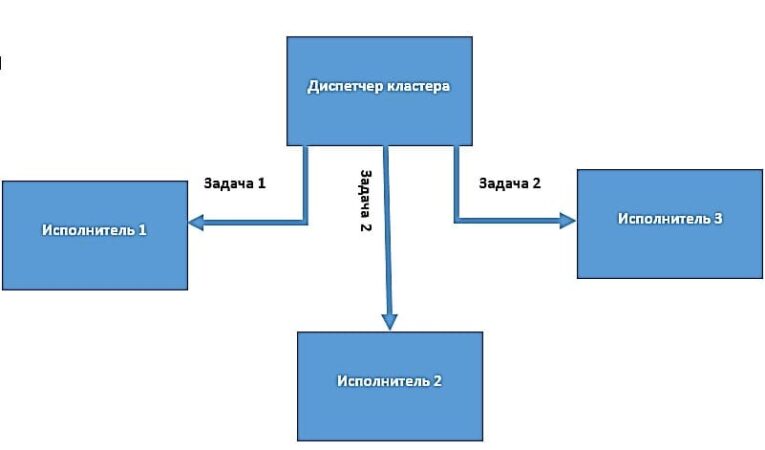
Диспетчеры кластеров
Диспетчеры кластеров – это отдельно подключаемые внешние программы. Они отвечают за масштабирование вычислительных узлов и распределение задач, идущих от драйвера к исполнителям. Когда приложение Spark делает запрос к диспетчеру кластера на предоставление процессов исполнителей, оно может получить доступное количество узлов в зависимости от загруженности кластера. Диспетчеры кластеров могут определять очереди с разными приоритетами или доступными ресурсами. Благодаря диспетчерам кластеров драйвер Spark имеет возможность посылать задачи в эти очереди.
Таким образом, распределенная архитектура приложения Spark позволяет выполнять ему огромные объемы задач благодаря параллельной работе узлов. Все это делает фреймворк Apache Spark весьма полезным средством для Data Scientist’а и разработчика Big Data приложений. В следующей статье мы поговорим про развертывание Spark-приложений.
Более подробно про применение Apache Spark в проектах анализа больших данных, разработки Big Data приложений и прочих прикладных областях Data Science вы узнаете на практических курсах по Spark в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве.
Источник: spark-school.ru