
Apache Spark — фреймворк для работы с Big Data
Впервые термин «большие данные» появился в 2008 году в специальном выпуске журнала «Nature», посвященном ошеломительному росту количества обрабатываемых данных. Спустя год термин «выбрался» из академической среды в журналистику, а затем проник в сферу информационных технологий.
В современном мире множество электронных гаджетов, устройств интернета вещей и просто «умных» датчиков, которые генерируют непрерывные неструктурированные потоки данных. Говорят, что информация — новая нефть, а значит, нужны подходящие инструменты для ее обработки.
Обработка больших данных (Big Data)
Задолго до появления термина Big Data люди желали научить несколько компьютеров эффективно работать над одной задачей. Так появились парадигмы параллельных и распределенных вычислений. Идея распределенных вычислений на словах звучит просто: разбиваем большую задачу на ряд маленьких, отправляем доступным вычислителям и ждем результат.
На практике все сложнее. Большую задачу нужно эффективно разбить на маленькие, а множество серверов в сети, именуемой кластером, должны быть скоординированы. Наконец, обрабатываемые большие данные необходимо где-то хранить, ведь информация, известная любимому поисковику, никак не поместится на один диск.
ВВЕДЕНИЕ В PYSPARK И SPARKSQL / ОЛЕГ АГАПОВ
С поисковиков и началась история проекта Hadoop, который разместился под крылом Apache Software Foundation. История появления фонда проста: в 1993 году разрабатывался HTTP-сервер, ныне известный как Apache HTTP Server. Спустя пять лет группа разработчиков создала фонд для юридической защиты участников проектов с открытым исходным кодом имени Apache.
Фреймворк домена Apache
Появление Apache Spark уходит истоками к проекту Hadoop, о котором мы кратко расскажем.
В начале 2000-годов Дуг Каттинг (Doug Cutting) вдохновился публикацией о вычислительной концепции MapReduce, о которой мы расскажем ниже. Тогда Дуг был автором проекта Nutch — открытого фреймворка построения поисковых систем, написанного на языке программирования Java. Это положило начало проекту Hadoop, фреймворку для построения распределенных приложений.
В январе 2008 года Hadoop становится частью фонда Apache Software Foundation, а спустя полгода устанавливает мировой рекорд в стандартизированной задаче по сортировке большого объема данных. С этого момента проект приобретает известность и применяется в широком спектре задач в сфере информационных технологий.
Принципы работы Hadoop
В основе Hadoop лежит концепция MapReduce, названная в честь двух функций высшего порядка функционального программирования — map() и reduce(). Любая задача в данной концепции решается в два шага:
- Мастер-узел разбивает данные на фрагменты и отправляет их другим узлам кластера.
- Результат работы каждого узла отправляется мастеру, который объединяет данные в итоговый результат.
На деле реализация концепции сложнее, но общая идея сохранена. На текущий момент проект Hadoop состоит из следующих компонентов:
Spark 1: Что такое Big data, Spark и spark консоль
- Hadoop Common — инструменты для работы с файловыми системами hadoop и командный интерпретатор с набором утилит,
- Hadoop Distributed File System (HDFS) — распределенная файловая система, созданная хранить файлы большого размера,
- Yet Another Resource Negotiator (YARN) — планировщик ресурсов и заданий,
- Hadoop MapReduce — программный фреймворк для построения распределенных приложений.
Одна из особенностей Hadoop MapReduce — промежуточные данные вычислений хранятся на накопителях. Это снижает скорость доступа к данным, что неприемлемо для некоторых классов аналитических задач. Apache Spark был призван решить «медлительность» Hadoop.
Что такое Apache Spark
Spark — фреймворк с открытым исходным кодом для обработки большого объема данных, опубликованный в 2010 году румынским ученым Матеем Захария (Matei Zaharia). Спустя три года проект был передан фонду Apache.
Apache Spark предлагает иной архитектурный подход, называемый RDD (resilient distributed dataset). В его основе лежат мультимножества, распределенные между узлами кластера. Кластер представляется как ацикличный направленный граф, где узлы кластера являются мультимножествами, а ребра графа — операциями. Для работы с RDD доступно несколько абстракций: Dataframe API и Dataset API.
Apache Spark не входит в фреймворк Apache Hadoop, однако имеет с ним совместимость. Узлы кластера можно запускать через YARN, а хранить данные на HDFS. Знание Hadoop необязательно: кластер Spark может быть запущен даже вручную, а для разработки и тестов можно выбрать псевдораспределенный режим, в котором каждый узел кластера занимает одно вычислительное ядро процессора.
Платформа обработки данных
Подключите инфраструктуру для хранения и обработки больших данных на базе Apache Hadoop, Spark, Airflow, Superset, Kafka, а также Greenplum и ClickHouse.
Новый фреймворк появился не на ровном месте. Hadoop имеет ряд особенностей, которые ограничивают его применимость в различных задачах. Поговорим об улучшениях, которые принес Spark.
Преимущества Apache Spark
Начнем обзор с фундаментальных вещей. Apache Spark использует парадигму резидентных вычислений, то есть обрабатываемые данные хранятся в оперативной памяти, ускоряя многократный доступ к загруженным данным. Благодаря такому подходу Spark можно использовать в задачах, недоступных для Hadoop, — например, в машинном обучении.
Как отмечалось ранее, Spark является самостоятельным приложением, поэтому для тестирования его возможностей нет необходимости настраивать распределенный кластер. Apache Spark состоит из множества модулей, но в отличие от Hadoop модули Spark предоставляют новые способы взаимодействия пользователя с кластером.
Основой Spark является модуль Spark Core, написанный на языке программирования Scala. «Ядро» занимается запуском распределенных вычислений, планированием заданий и базовыми операциями ввода-вывода. Ядро предоставляет Java API для управления с помощью других JVM-совместимых языков программирования. Дополнительно предоставляются интерфейсы для Python, .NET и R.
Как отмечалось ранее, в основе вычислений Spark лежат операции над мультимножествами. Все мультимножества доступны только для чтения, а операции изменения создают новые мультимножества, которые хранят историю действий.
Список действий для получения текущего мультимножества — один из способов достижения отказоустойчивости в кластере. В случае частичной потери данных в кластере остается «инструкция» по восстановлению данных, которая «прозрачна» для конечного пользователя.
Действия над мультимножествами определяются программистом в функциональном стиле при разработке приложения в виде последовательности простых действий над одним или несколькими элементами.
Парадигма функционального программирования подходит не всем, поэтому рассмотрим другие модули для Spark.
Spark SQL
Многие аналитики используют в работе интерактивные запросы. Средства Spark Core не позволяют совершать запросы к хранящимся данным в режиме реального времени, более того, «ядро» требует навыков функционального программирования.
В этом случае поможет модуль Spark SQL, который вводит поддержку языка запросов SQL для структурированных наборов данных. Spark SQL — это диалект SQL, который обладает множеством известных операторов и ключевых слов, свойственных диалектам реляционных баз данных. Тем не менее, в нем есть и уникальные синтаксические конструкции. Например, выражение для загрузки JSON-файла в Spark:
CREATE TEMPORARY TABLE people USING org.apache.spark.sql.json OPTIONS (path ‘/home/selectel/example.json’)
Помимо интерактивного интерфейса командной строки, Spark SQL предоставляет ODBC/JDBC-интерфейсы, позволяющие корпоративным инструментам для анализа данных подключаться к Spark, как к классическим базам данных.
Spark Streaming
Устройства и программы современного мира генерируют огромное количество данных. Некоторые данные необходимо обрабатывать по мере их поступления. Для этого существует модуль Spark Streaming.
Данный модуль отбирает небольшое количество данных из входного потока, создает из них мультимножество и выполняет заданные преобразования. Эти операции повторяются до тех пор, пока модулю предоставляются новые данные. По умолчанию Spark Streaming умеет получать данные из брокеров сообщений, в том числе из Apache Kafka.
Spark MLLib
Spark MLLib — это библиотека, реализующая алгоритмы машинного обучения и статистические алгоритмы на базе кластеров Apache Spark. Как упоминалось ранее, Spark использует парадигму резидентных вычислений, подходящую для задач машинного обучения.
Разработка модуля MLLib началась вместе с разработкой Spark. Предполагалось, что MLLib заменит существующий проект для машинного обучения Apache Mahout. Использование распределенной архитектуры Spark позволило получить почти девятикратный прирост производительности по сравнению с Apache Mahout.
После принятия Spark в проекты верхнего уровня Apache Mahout получил интерфейс для работы с Spark, а MLLib — значительное расширение функциональности.
Graphx
Мы рассмотрели структурированные запросы, потоковую обработку и методы машинного обучения. Осталась теория графов. Модуль Graphx «закрывает» эту область.
Graphx — модуль-исполнитель распределенной обработки графовых структур. Так как в архитектуре Spark мультимножества доступны только для чтения, то Graphx неприменим для изменяющихся графов. Модуль Graphx, как и Spark, начинался в виде научной работы, но впоследствии был передан в фонд Apache.
Заключение
Итак, мы закончили высокоуровневый обзор проекта Apache Spark — его преимуществ, принципа работы, инструментов. В целом, его можно охарактеризовать как «швейцарский нож» из мира распределенных вычислений и больших данных. Совместимость с инструментами Apache Hadoop и наличие модулей обработки специфичных структур данных существенно расширяют область применения Spark.
Источник: selectel.ru
Spark — лучшая альтернатива почтовому клиенту от Apple
Как и многие пользователи, я нечасто заходил в почтовый клиент. Привычного функционала нативного приложения «Почта» на iOS мне вполне хватало. Активно начал читать и писать письма на почту я в университете. И претензий к родному приложению не имел. Ровно до тех пор, пока не смог загрузить файл большего объема, чем могла предложить родная почта.
Уже зная про почтовый клиент Spark из подборок качественного софта на YouTube я сразу скачал его. И файл, который я не мог отправить без труда «улетел» к получателю. Так началась моя карьера вместе со Spark. В данной статье постараюсь описать все преимущества и недостатки стороннего приложения и ответить на вопрос: А стоит ли скачивать для просмотра почты сторонний софт?

Приложение Spark — лучший почтовый клиент для iOS
Альтернативных приложений у родного приложения «Почта» не так много. И первое, на что я бы хотел обратить внимание это на возможность использования почтовых писем, как задач. Это очень удобно, даже если вы не часто пользуетесь почтой. Благодаря этой функции вы сможете назначать каждое, как задачу и оно будет отправлено в тот временной промежуток, который вы зададите сами.
В 2019 году после отмены некоторых сервисов от Google, приложение вышло и на платформе Android. Если вы используете iPad вместе со смартфоном от Huawei, альтернативы приложению Spark для вас я не вижу.
У приложения от компании Readdle существует два подраздела. Первый, так называемый «Inbox» сортирует для вас списки в привычном хронологическом порядке, а раздел «Smart» разделяет всю входящую почту на подгруппы «Личные», «Уведомления», «Закрепленные» и «Просмотренные», что хорошо организует и дисциплинирует рабочий процесс. А раздел «Еще» в левом нижнем углу не оставит равнодушными даже самых требовательных пользователей.
Раздел «Smart» позволяет группировать письма по категориям
Нативное приложение от Apple весьма простое и удобное в использовании, поэтому без расширенного функционала и «пряников» от разработчиков, приложение Spark не смогло бы завоевать такого авторитета. Функция «быстрых ответов» и интеграция с большим количеством приложений «must have фитчи» для пользователей, на которых ежедневно сваливается тонна рабочих писем. А подвязка к календарям внутри операционной системы превращает Spark в машину для продуктивности. Жаль только, что в списке поддерживаемых приложений нет Microsoft To Do, о котором мы писали на AndroidInsider.ru. Думается, что это дело времени.
Приложения, с которыми дружит почтовый клиент от Readdle
У большинства из нас есть несколько разных ящиков и приложение Spark умеет работать не только с почтой на популярных сервисах, но и с рабочими аккаунтами посредством IMAP.
На примере кастомизации наглядно видно, что над приложением трудятся в постоянном режиме. В сети видно, как еще не так давно активные пользователи жаловались на отсутствие темного режима и проблемы с синхронизацией между устройствами. Например, если вы редактировали сообщение на своем iPad изменения приходили на компьютер Mac с запозданием порядка 30 секунд. Сейчас этих проблем в работе приложения я не заметил, а реализация темной темы с двумя возможными вариантами черного пришлась по душе.
Приложение для iPad в темном цветовом решении.
Очень удивляет, что в 2021 году мы сталкиваемся с такими банальными проблемами вроде скорости работы или возможности без проблем пользоваться сразу несколькими аккаунтами. Как вы выходите из положения предлагаю написать в наш Телеграм-чат. Но не стоит расстраиваться!
В следствие того, что приложение написано русскоговорящими инженерами, вероятность, что нас услышат в жалобах в комментариях в магазине приложений AppStore очень велика. Если же вы все-таки решитесь перейти в Spark призываю вас оставить обратную связь. Так мы можем помочь приложению стать лучше.
Приложение Spark было выпущено украинскими разработчиками и это круто! Как ни крути, приятно видеть качественные проекты из СНГ в топе AppStore.
Из неприятного могу отметить:
- Как бы не старались разработчики максимально подогнать по дизайну приложение под Apple, я думаю у них это не вышло. Легкость белых тонов вместе с небесно-голубым выглядело многообещающе, но моих ожиданий не оправдала. Приложение выглядит нагруженным и не тянет на эмблему самолетика, парящего в небесном пространстве.
- Безопасность. При подключении к почтовому клиенту сразу нескольких устройств, надо иметь в виду что вся ваша почтовая база данных будет доступна и на смежных устройствах тоже. Особенно актуально, если у вас имеется несколько Apple устройств. В защиту могу сказать, что приложение на мобильных устройствах защищены Face ID или Touch ID, но на компьютере Mac защита такого рода во многих приложениях просто игнорируется. Учтите это.
- Если оставить приложение без должного контроля, можно проститься с большим количеством свободного пространства. Во всем виноват кэш.
- Многие пользователи жалуются на низкую скорость работы при подключении к 5ти и более почтовым клиентам. Если у вас имеется 5 почтовых ящиков и более, советую рассмотреть альтернативные варианты.
Приложение Spark это не просто почтовый клиент. Spark сочетает в себе огромное количество разных дополнений в виде интеграции с календарем, приложениями вроде Evernote или Todolist и в умелых руках превращается в возможность для качественной работы не только с почтой, но и с качественным распределением времени и продуктивностью.
Источник: appleinsider.ru
Знакомство с Apache Spark
Мы наконец-то приступаем к переводу серьезной книги о фреймворке Spark:

Сегодня мы предлагаем вашему вниманию перевод обзорной статьи о возможностях Spark, которую, полагаем, можно с полным правом назвать слегка потрясающей.
Я впервые услышал о Spark в конце 2013 года, когда заинтересовался Scala – именно на этом языке написан Spark. Несколько позже я принялся ради интереса разрабатывать проект из области Data Science, посвященный прогнозированию выживаемости пассажиров «Титаника». Оказалось, это отличный способ познакомиться с программированием на Spark и его концепциями. Настоятельно рекомендую познакомиться с ним всем начинающим Spark-разработчикам.
Сегодня Spark применяется во многих крупнейших компаниях, таких, как Amazon, eBay и Yahoo! Многие организации эксплуатируют Spark в кластерах, включающих тысячи узлов. Согласно FAQ по Spark, в крупнейшем из таких кластеров насчитывается более 8000 узлов. Действительно, Spark – такая технология, которую стоит взять на заметку и изучить.

В этой статье предлагается знакомство со Spark, приводятся примеры использования и образцы кода.
Что такое Apache Spark? Введение
Spark – это проект Apache, который позиционируется как инструмент для «молниеносных кластерных вычислений». Проект разрабатывается процветающим свободным сообществом, в настоящий момент является наиболее активным из проектов Apache.
Spark предоставляет быструю и универсальную платформу для обработки данных. По сравнению с Hadoop Spark ускоряет работу программ в памяти более чем в 100 раз, а на диске – более чем в 10 раз.
Кроме того, код на Spark пишется быстрее, поскольку здесь в вашем распоряжении будет более 80 высокоуровневых операторов. Чтобы оценить это, давайте рассмотрим аналог “Hello World!” из мира BigData: пример с подсчетом слов (Word Count). Программа, написанная на Java для MapReduce, содержала бы около 50 строк кода, а на Spark (Scala) нам потребуется всего лишь:
sparkContext.textFile(«hdfs://. «) .flatMap(line => line.split(» «)) .map(word => (word, 1)).reduceByKey(_ + _) .saveAsTextFile(«hdfs://. «)
При изучении Apache Spark стоит отметить еще один немаловажный аспект: здесь предоставляется готовая интерактивная оболочка (REPL). При помощи REPL можно протестировать результат выполнения каждой строки кода без необходимости сначала программировать и выполнять все задание целиком. Поэтому написать готовый код удается гораздо быстрее, кроме того, обеспечивается ситуативный анализ данных.
Кроме того, Spark имеет следующие ключевые черты:
- В настоящее время предоставляет API для Scala, Java и Python, также готовится поддержка других языков (например, R)
- Хорошо интегрируется с экосистемой Hadoop и источниками данных (HDFS, Amazon S3, Hive, HBase, Cassandra, etc.)
- Может работать на кластерах под управлением Hadoop YARN или Apache Mesos, а также работать в автономном режиме
Ядро Spark дополняется набором мощных высокоуровневых библиотек, которые бесшовно стыкуются с ним в рамках того же приложения. В настоящее время к таким библиотекам относятся SparkSQL, Spark Streaming, MLlib (для машинного обучения) и GraphX – все они будут подробно рассмотрены в этой статье. Сейчас также разрабатываются другие библиотеки и расширения Spark.
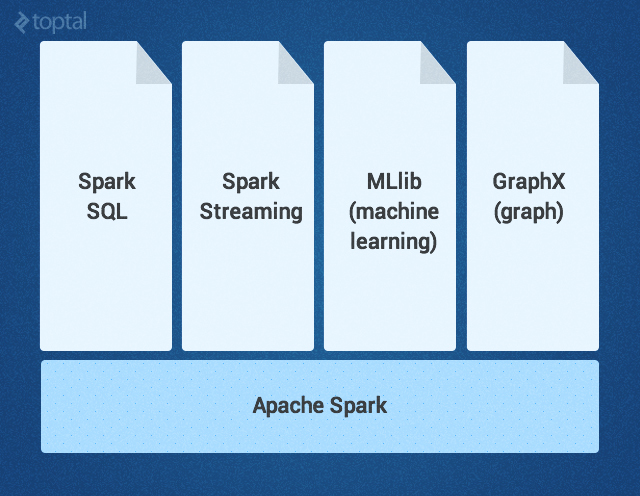
Ядро Spark
Ядро Spark – это базовый движок для крупномасштабной параллельной и распределенной обработки данных. Ядро отвечает за:
- управление памятью и восстановление после отказов
- планирование, распределение и отслеживание заданий кластере
- взаимодействие с системами хранения данных
- Трансформации – это операции (например, отображение, фильтрация, объединение и т.д.), совершаемые над RDD; результатом трансформации становится новый RDD, содержащий ее результат.
- Действия – это операции (например, редукция, подсчет и т.д.), возвращающие значение, получаемое в результате некоторых вычислений в RDD.
Трансформации в Spark осуществляются в «ленивом» режиме — то есть, результат не вычисляется сразу после трансформации. Вместо этого они просто «запоминают» операцию, которую следует произвести, и набор данных (напр., файл), над которым нужно совершить операцию. Вычисление трансформаций происходит только тогда, когда вызывается действие, и его результат возвращается основной программе. Благодаря такому дизайну повышается эффективность Spark. Например, если большой файл был преобразован различными способами и передан первому действию, то Spark обработает и вернет результат лишь для первой строки, а не станет прорабатывать таким образом весь файл.
По умолчанию каждый трансформированный RDD может перевычисляться всякий раз, когда вы выполняете над ним новое действие. Однако RDD также можно долговременно хранить в памяти, используя для этого метод хранения или кэширования; в таком случае Spark будет держать нужные элементы на кластере, и вы сможете запрашивать их гораздо быстрее.
SparkSQL – это компонент Spark, поддерживающий запрашивание данных либо при помощи SQL, либо посредством Hive Query Language. Библиотека возникла как порт Apache Hive для работы поверх Spark (вместо MapReduce), а сейчас уже интегрирована со стеком Spark. Она не только обеспечивает поддержку различных источников данных, но и позволяет переплетать SQL-запросы с трансформациями кода; получается очень мощный инструмент. Ниже приведен пример Hive-совместимого запроса:
// sc – это существующий SparkContext. val sqlContext = new org.apache.spark.sql.hive.HiveContext(sc) sqlContext.sql(«CREATE TABLE IF NOT EXISTS src (key INT, value STRING)») sqlContext.sql(«LOAD DATA LOCAL INPATH ‘examples/src/main/resources/kv1.txt’ INTO TABLE src») // Запросы формулируются на HiveQL sqlContext.sql(«FROM src SELECT key, value»).collect().foreach(println)
Spark Streaming
Spark Streaming поддерживает обработку потоковых данных в реальном времени; такими данными могут быть файлы логов рабочего веб-сервера (напр. Apache Flume и HDFS/S3), информация из соцсетей, например, Twitter, а также различные очереди сообщений вроде Kafka. «Под капотом» Spark Streaming получает входные потоки данных и разбивает данные на пакеты. Далее они обрабатываются движком Spark, после чего генерируется конечный поток данных (также в пакетной форме) как показано ниже.

API Spark Streaming точно соответствует API Spark Core, поэтому программисты без труда могут одновременно работать и с пакетными, и с потоковыми данными.
MLlib – это библиотека для машинного обучения, предоставляющая различные алгоритмы, разработанные для горизонтального масштабирования на кластере в целях классификации, регрессии, кластеризации, совместной фильтрации и т.д. Некоторые из этих алгоритмов работают и с потоковыми данными — например, линейная регрессия с использованием обычного метода наименьших квадратов или кластеризация по методу k-средних (список вскоре расширится). Apache Mahout (библиотека машинного обучения для Hadoop) уже ушла от MapReduce, теперь ее разработка ведется совместно с Spark MLlib.
GraphX – это библиотека для манипуляций над графами и выполнения с ними параллельных операций. Библиотека предоставляет универсальный инструмент для ETL, исследовательского анализа и итерационных вычислений на основе графов. Кроме встроенных операций для манипуляций над графами здесь также предоставляется библиотека обычных алгоритмов для работы с графами, например, PageRank.
Как использовать Apache Spark: пример с обнаружением событий
Теперь, когда мы разобрались, что такое Apache Spark, давайте подумаем, какие задачи и проблемы будут решаться с его помощью наиболее эффективно.
Недавно мне попалась статья об эксперименте по регистрации землетрясений путем анализа потока Twitter. Кстати, в статье было продемонстрировано, что этот метод позволяет узнать о землетрясении более оперативно, чем по сводкам Японского Метеорологического Агентства. Хотя технология, описанная в статье, и не похожа на Spark, этот пример кажется мне интересным именно в контексте Spark: он показывает, как можно работать с упрощенными фрагментами кода и без кода-клея.
Во-первых, потребуется отфильтровать те твиты, которые кажутся нам релевантными – например, с упоминанием «землетрясения» или «толчков». Это можно легко сделать при помощи Spark Streaming, вот так:
TwitterUtils.createStream(. ) .filter(_.getText.contains(«earthquake») || _.getText.contains(«shaking»))
Затем нам потребуется произвести определенный семантический анализ твитов, чтобы определить, актуальны ли те толчки, о которых в них говорится. Вероятно, такие твиты, как «Землетрясение!» или «Сейчас трясет» будут считаться положительными результатами, а «Я на сейсмологической конференции» или «Вчера ужасно трясло» — отрицательными. Авторы статьи использовали для этой цели метод опорных векторов (SVM). Мы поступим также, только реализуем еще и потоковую версию. Полученный в результате образец кода из MLlib выглядел бы примерно так:
// Готовим данные о твитах, касающихся землетрясения, и загружаем их в формате LIBSVM val data = MLUtils.loadLibSVMFile(sc, «sample_earthquate_tweets.txt») // Разбиваем данные на тренировочные (60%) и тестовые (40%). val splits = data.randomSplit(Array(0.6, 0.4), seed = 11L) val training = splits(0).cache() val test = splits(1) // Запускаем тренировочный алгоритм, чтобы построить модель val numIterations = 100 val model = SVMWithSGD.train(training, numIterations) // Очищаем пороговое значение, заданное по умолчанию model.clearThreshold() // Вычисляем приблизительные показатели по тестовому множеству val scoreAndLabels = test.map < point =>val score = model.predict(point.features) (score, point.label) > // Получаем параметры вычислений val metrics = new BinaryClassificationMetrics(scoreAndLabels) val auROC = metrics.areaUnderROC() println(«Area under ROC scala»>// sc – это имеющийся SparkContext. val sqlContext = new org.apache.spark.sql.hive.HiveContext(sc) // sendEmail – это пользовательскаяфункция sqlContext.sql(«FROM earthquake_warning_users SELECT firstName, lastName, city, email») .collect().foreach(sendEmail)
Другие варианты использования Apache Spark
Потенциально сфера применения Spark, разумеется, далеко не ограничивается сейсмологией.
Вот ориентировочная (то есть, ни в коем случае не исчерпывающая) подборка других практических ситуаций, где требуется скоростная, разноплановая и объемная обработка больших данных, для которой столь хорошо подходит Spark:
В игровой индустрии: обработка и обнаружение закономерностей, описывающих игровые события, поступающие сплошным потоком в реальном времени; в результате мы можем немедленно на них реагировать и делать на этом хорошие деньги, применяя удержание игроков, целевую рекламу, автокоррекцию уровня сложности и т.д.
В электронной коммерции информация о транзакциях, поступающая в реальном времени, может передаваться в потоковый алгоритм кластеризации, например, по k-средним или подвергаться совместной фильтрации, как в случае ALS. Затем результаты даже можно комбинировать с информацией из других неструктутрированных источников данных — например, с отзывами покупателей или рецензиями. Постепенно эту информацию можно применять для совершенствования рекомендаций с учетом новых тенденций.
В финансовой сфере или при обеспечении безопасности стек Spark может применяться для обнаружения мошенничества или вторжений, либо для аутентификации с учетом анализа рисков. Таким образом можно получать первоклассные результаты, собирая огромные объемы архивированных логов, комбинируя их с внешними источниками данных, например, с информацией об утечках данных или о взломанных аккаунтах (см., например, https://haveibeenpwned.com/), а также использовать информацию о соединениях/запросах, ориентируясь, например, на геолокацию по IP или на данные о времени
Итак, Spark помогает упростить нетривиальные задачи, связанные с большой вычислительной нагрузкой, обработкой больших объемов данных (как в реальном времени, так и архивированных), как структурированных, так и неструктурированных. Spark обеспечивает бесшовную интеграцию сложных возможностей – например, машинного обучения и алгоритмов для работы с графами. Spark несет обработку Big Data в массы. Попробуйте – не пожалеете!
- Блог компании Издательский дом «Питер»
- Big Data
Источник: habr.com
ТОП-7 причин использовать Apache Spark для анализа больших данных и разработки распределенных приложений

В этой статье поговорим про Apache Spark – популярный Big Data фреймворк с открытым исходным кодом для обработки больших массивов данных. Он входит в экосистему проектов Apache Hadoop, однако выгодно отличается от ее других компонентов. Читайте далее, какие ключевые особенности Apache Spark делают его настолько привлекательным для практического применения в Data Science.
Чем хорош Apache Spark: главные преимущества
Одним из наиболее значимых достоинств Apache Spark является его скорость – в отличие от классического Hadoop MapReduce, он позволяет обрабатывать данные непосредственно в оперативной памяти. За счет этого многие задачи по обработке больших данных выполняются быстрее, что особенно важно в машинном обучении (Machine Learning). Однако, это далеко не единственный плюс рассматриваемого фреймворка. С практической точки зрения весьма полезны следующие его свойства, каждое из которых мы подробнее рассмотрим далее:
- богатый API;
- широкие функциональные возможности за счет многокомпонентного состава в виде модулей Spark SQL, Spark Streaming, MLLib;
- отложенные или ленивые вычисления (lazy evaluation);
- распределенная обработка данных;
- простые вращения данных при матричных и векторных операциях;
- легкие преобразования одних структур данных в другие;
- статус динамично развивающегося open-source проекта с активным профессиональным сообществом.
Богатый API
Apache Spark предоставляет разработчику довольно обширный API, позволяя работать с разными языками программирования: Python, R, Scala и Java. Spark предлагает пользователю абстракцию датафрейма (dataframe), для которых используются объектно-ориентированные методы преобразований, объединения данных, их фильтрации, а также много других полезных возможностей. Также объектный подход позволяет разработчику создавать настраиваемый и повторно используемый код, который можно тестировать с помощью различных специализированных методов и средств, например, отправка параметризованных запросов и создание разных окружений для одних и тех же запросов.
Также возможна интеграция Spark с такими BigData фреймворками, как Apache Kafka и Apache KUDU, а также с СУБД MySQL посредством компонента Spark SQL.
Широкий функционал
Spark обладает довольно широкими функциональными возможностями за счет следующих компонентов:
- Spark SQL – модуль, который служит для аналитической обработки данных с помощью SQL-запросов;
- Spark Streaming – модуль, обеспечивающий надстройку для обработки потоковых данных в режиме онлайн;
- MLib – модуль, предоставляющий набор библиотек машинного обучения.
Ленивые вычисления
Ленивые вычисления (lazy evaluations) позволяют снизить общий объем вычислений и повысить производительность программы за счет снижений требований к памяти. Такие вычисления весьма полезны, поскольку позволяют определять сложную структуру преобразований, представленных в виде объектов. Также можно проверить структуру конечного результата, не выполняя какие-либо промежуточные шаги. Еще Spark автоматически проверяет план выполнения запросов или программы на наличие ошибок. Это позволяет быстро отловить баги и отладить их.
Легкие преобразования
Для поддержки языка Python сообщество Apache Spark выпустило инструмент PySpark, который предлагает модуль Pyspark Shell, связывающий Python API и контекст Spark. Поэтому разработчик Big Data приложения может применять метод toPandas для беспрепятственного преобразования Spark DataFrame в Pandas. Это нужно для того, чтобы более эффективно сохранять обработанные файлы в csv-формат, а также ускорять обработку небольших массивов данных. Приведем пример такого преобразования:
import findspark findspark.init() findspark.find() import pyspark findspark.find() from pyspark.sql import SparkSession import pandas as pd from pyspark.sql.types import * conf = pyspark.SparkConf().setAppName(‘appName’).setMaster(‘local’) sc = pyspark.SparkContext(conf=conf) spark = SparkSession(sc) data = [] mySchema_3 = StructType([ StructField(«col1», StringType(), True), StructField(«col2», StringType(), True), StructField(«col3», DoubleType(), True)]) data_1 = spark.createDataFrame(data,schema=mySchema_3) data_1.toPandas()
Метод toPandas позволяет вести работу в памяти после того, как Спарк разбил данные на более мелкие наборы данных. SparkSession.createDataFrame, в свою очередь, позволяет сделать наоборот:
spark = SparkSession.builder.appName(‘pandasToSparkDF’).getOrCreate() pandas_df = pd.read_csv(«test.csv») mySchema = StructType([ StructField(«col1», LongType(), True) ,StructField(«col2», IntegerType(), True) ,StructField(«col3», IntegerType(), True)]) df = spark.createDataFrame(pandas_df,schema=mySchema)
Таким образом, PySpark расширяет функциональность языка Python до операций с массивными наборами данных, ускоряя цикл разработки.
Простые вращения данных
Вращение данных (data pivoting) считается проблемой для многих фреймворков, работающих с большими данными, например, Apache Kaflka или Flink. Как правило, такие операции требуют множества операторов case. Спарк же имеет в своем арсенале простой и интуитивно понятный способ поворота Datafame. Пользователю необходимо всего лишь выполнить операцию groupBy для столбцов с целевым индексом, поворачивая целевое поле для дальнейшего использования в качестве столбцов. Далее можно приступать непосредственно к самому агрегированию. В качестве примера приведем нахождение среднего значения в колонке:
test_data = spark.read.option(‘header’,’True’).csv(‘test.csv’,sep=’;’) test_data test_data.groupby([‘col1’, ‘col2’]).agg().withColumnRenamed(«avg(col3)», «col3»)
Метод groupBy позволил использовать колонки col1 и col2 в качестве индексов для последующего агрегирования методом agg .
Apache Spark – это фреймворк с открытым исходным кодом
Входя в линейку проектов Apache Software Foundation, Спарк продолжает активно развиваться за счет сообщества разработчиков. Энтузиасты open-source улучшают основной софт и предлагают дополнительные пакеты. Например, в октябре 2017 года была опубликована библиотека обработки нативного языка для Spark. Это избавило пользователя от необходимости применять другие библиотеки или полагаться на медленные пользовательские функции для таких пакетов Python, как Natural Language Toolkit.
Реализация распределенной обработки данных
Наконец, что особенно важно в разработке Big Data приложений, Apache Spark предусматривает распределенную обработку данных, включая концепцию RDD (resilient distributed dataset) – это распределенная структура данных размещаемая в оперативной памяти. Каждый RDD содержит фрагмент данных, распределенных по узлам кластера. За счет этого он является отказоустойчивым: если раздел теряется в результате сбоя узла, он может быть восстановлен из исходных источников. Таким образом, Спарк сам раскидывает код по всем узлам кластера, разбивает его на подзадачи, создает план выполнения и отслеживает успешность выполнения. В случае сбоя на каком-нибудь из узлов или неуспешном завершении подзадачи, она будет перезапущена автоматически.
В следующей статье мы продолжим разговор про Apache Spark и рассмотрим основные компоненты этого фреймворка.
Освоить Apache Spark на профессиональном уровне для практического использования в своих проектах анализа больших данных, разработки Big Data приложений и прочих прикладных областях Data Science вы сможете на практических курсах по Apache Spark в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве.
Источник: spark-school.ru