
ModBus широко применяемый в промышленности протокол для связи электронных устройств. Используется для передачи данных по последовательным интерфейсам передачи RS-232, RS-485, RS-422 и TCP/IP. Первые два интерфейса реализованы в дисплеях DWIN.
Прошлые статьи:
Рассмотрим протокол ModBus:
Протокол Modbus
Slave ID — номер устройства с которым происходит взаимодействие;
Код функции представляет стандартную команду поддерживаемую протоколом Modbus;
Код функции — команда определяющая действия с данными;
Данные — передаваемые данные;
CRC — контрольная сумма для проверки целостности доставленного пакета.
Рассмотрим подобнее код функции поддерживаемые дисплеем:
1 — Чтение DO Read Coil Status
2 — Чтение DI Read Input Status
3 — Чтение AO Read Holding Registers
4 — Чтение AI Read Input Registers
5 — Запись одного DO Force Single Coil
6 — Запись одного AO Preset Single Register
10 — Команда работает когда дисплей настроен в качестве ведущего устройства, данные в этой команде будут отправлены после включения питания для инициализации ведомого устройства.
ALIENTECH KESS V2 & KTAG. Что выбрать — ОРИГИНАЛ или КЛОН? В чем разница MASTER и SLAVE?
Для реализации проекта будет использован дисплей DMG80480C050_03WTC. Обладающий TN матрицей с разрешением 800х480, напряжением питания 5В, интерфейсом UART TTL.
На изображении ниже можно наблюдать что дисплей имеет два интерфейса UART с переключением режимов работы RS-232/TTL. RX2/TX2 относятся к интерфейсу UART2. RX4/TX4 относятся к интерфейсу UART4, данный интерфейс будет задействован для связи по Modbus.
Дисплей поддерживает как работу в качестве ведомого так и в качестве ведущего устройства. Разберем оба режима.
Работа дисплея DWIN в режиме «Slave»
Используем проект из прошлой статьи. Чтобы использовать Modbus, необходимо загрузить файл обновления ядра, для этого переходим в папку загруженную с GitHub, DocsModbus и выбираем подходящий архив с файлами. В нашем случае это «DWIN_T5L_115200_UART4_MODBUS_Slave», дисплей на ядре T5L, с Modbus на UART4 с скоростью 115200 Baud. Из архива нужны файлы:
DWIN_T5L_115200__UART4_ModBus.asm — ассемблерный файл с кодом;
DWINOS_DWIN_T5L_115200__UART4_ModBus.bin бинарный скомпилированный файл.
Рассмотрим файл DWINOS_DWIN_T5L_115200__UART4_ModBus.bin через Notepad++ с плагином hex-editor, также можно воспользоваться UltraEdit-32.
Конфигурационный файл DWINOS_DWIN_T5L_115200__UART4_ModBus
e0 00 — Начальный адрес (слово) первой инструкции в файле 22 = 0xE000
ff 04 — FF — 255 максимальное количество инструкций в файле 22*.bin, 04 — настроен как ведомый, RTU формат.
- ( 0x00 = Сконфигурирован как мастер, RTU формат.
- 0x01 = Сконфигурирован как мастер, , ascii формат (в настоящее время не поддерживается).
- 0x02 = Сконфигурирован как мастер (RTU), ведомый отвечает часами в данных.
- 0x03 = Сконфигурирован как мастер (ascii), ведомый отвечает часами в данных (в настоящее время не поддерживается).
- 0x04 = Сконфигурирован как ведомый, RTU формат.
- 0x05 = Сконфигурирован как ведомый, ascii формат (в настоящее время не поддерживается). )
05 ff — 05 — Количество повторений отправки команды, FF время задержки между командами FF = 255мс.
Подключение световых приборов в режиме master — slave
01 40 — 01 — идентификатор дисплея в режиме ведомого (ID Slave 0x01-0x7F (1 — 127)). 0x40=8N1, 0x41= 8E1, 0x42=8O1,0x43=8N2 (для UART5 значения будут 0x5*).
00 e0 — Делитель скорости порта Modbus 0x00E0 = 224, 25804800/224 = 115 200 Baud.
Если нет необходимости изменять ID slave дисплея и скорость 115200 или 9600 подходит для использования, то просто загружаем подходящий файл без изменений.
Загружаем на uSD карту папку DWIN_SET с прошлого проекта с добавлением файла DWINOS_DWIN_T5L_115200__UART4_ModBus.bin, вставляем в дисплей и обновляем прошивку.
Программа Modbus Poll будет использована как эмулятор для ПК в виде мастера.
ID Slave 1 115200 бод
Modbus Poll настройка
Как видно в таблице имеются значения, считанные с дисплея, кроме считывания значений их можно и изменять, для этого необходимо нажать на интересующий адрес, пусть будет 5002, и в поле Value вписать новое значение.
Modbus Poll команда на запись регистра в дисплее
На дисплее отображается следующая картинка:
DMG80480C050_03WTC отображаемая информация
ID Slave 2 9600 бод
Возьмем готовый файл DWINOS_DWIN_T5L_9600__UART4_ModBus и изменим в нем ID Slave на 02.
Редактирование конфигурационного файла DWINOS_DWIN_T5L_9600__UART4_ModBus
Файл DWINOS_DWIN_T5L_9600__UART4_ModBus.bin загрузим на дисплей не через uSD карту, а используя UART2. Для этого открываем DGUS и выбираем файл проекта, далее в вкладке «Welcome» находим «UART Download Tool».
DGUS рабочее окно программы
В появившемся окне выбираем Select Files и выбираем файл DWINOS_DWIN_T5L_9600__UART4_ModBus.bin, после чего нажимаем на Start Download, предварительно убедившись, что Serial Port и Baud Rate выбраны правильно.
UART Download Tool
Перезагружаем дисплей и видим, что Modbus Poll теперь не может получить данные.
Настраиваем Modbus Poll на скорость 9600 Baud и Slave ID равным 2 и видим, что информация начала обновляться.
Modbus Poll настройка порта
DMG80480C050_03WTC отображаемая информация
Считанные данные совпадают с отображаемыми данными на дисплее.
Работа дисплея DWIN в режиме «Master»
Для создания проекта также воспользуемся наработками с предыдущей статьи и используем готовый бинарный файл DWIN_T5L_115200_UART4_MODBUS из соответствующего архива. Также в архиве появился дополнительный файл 22*.bin, в который нужно будет записывать команды, которые должен отправлять дисплей к ведомым устройствам. В качестве ведомого устройства будет использоваться эмулятор Modbus Slave.
Пример записанной команды в файле 22*.bin:
5A 01 03 06 02 01 00 02 10 00 00 01
D0: 5A — стартовый байт команды;
D1: 01 — Идентификационный номер ведомого устройства;
D2: 03 — команда (может быть 1,2,3,4,5,6,10);
D3: 06 — длина данных;
D4: 02 — время ожидания приема (2 мс) (2 ~ 255);
D5: 01 — Режим отправки выполнения команды триггера (0-4)
- 0x00 = Безусловное выполнение.
- 0x01 = Выполнить на странице, указанной в D6.D7.
- 0x02 = Выполнить, когда значение ключа, указанное в D6.D7, не равно нулю, значение ключа будет очищено после выполнения инструкции.
- 0x03 = В инструкции 0x06, когда значение переменной, на которую указывает D8.D9, не равно нулю, оно будет отправлено автоматически.
После завершения связи очистите значение переменной, указанной в D8.D9. - 0x04 = В инструкции 0x05,0x06; 0x10 он будет отправлен автоматически при изменении указанной переменной D8.D9.
- D5 = 0, настройка не требуется.
- D5 = 1, он настроен как номер страницы (0x0002).
- D5 = 2, он настраивается как ключевой адрес, запускающий отправку.
- D5 = 3, настройка не требуется.
- D5 = 4, настройка не требуется.
D8, D9: Эта инструкция используется для управления адресом исходной переменной или начальным адресом (0x1000) данных, размещенных на экране DGUS.
D10, D11: таблица адресов подчиненного устройства (0x0001), управляемая этой инструкцией.
D12, D13, D14, D15: Не используются.
Эта команда предназначена для чтения данных из 6 последовательных слов в таблице точек, начиная с 0x0001 ведомого (id = 0x01), когда экран является ведущим, и отображения их по адресу 0x1000_0x1005 экрана.
Запишем 4 команды, 2 команды на считывание данных с ведомого устройства и запись их в ячейки с адресами 5002 и 5004. И 2 команды на запись данных в ведомое устройство из ячеек 5000 и 5006
Команда на чтение:
5A 01 03 01 30 01 00 00 50 02 00 02 00 00 00 00 — чтение из ячейки 0002 Slave устройства(01) и запись в ячейку 5002 дисплея.
5A 01 03 01 30 01 00 00 50 04 00 04 00 00 00 00 — чтение из ячейки 0004 Slave устройства(01) и запись в ячейку 5004 дисплея.
5A 01 06 01 30 04 00 00 50 06 00 06 00 00 00 00 — автоматическая отправка данных на запись из ячейки 5006 при изменении данных, отправление происходит в ячейку памяти 0006 Slave устройства (01).
5A 01 06 01 30 04 00 00 50 00 00 00 00 00 00 00 — автоматическая отправка данных на запись из ячейки 5000 при изменении данных, отправление происходит в ячейку памяти 0000 Slave устройства(01).
Для записи данных команд в файл 22*.bin откроем файл через Notepad++ с плагином hex-editoк или UltraEdit-32. И начнём записывать команды в строки с адреса 0001C000.
Если записывать команды в файл сконфигурированный DGUS то значения инициализации останутся прежними, если файл будет новый то все переменные инициализируются нулями. В данном примере мы будем записать в новый файл без начальных значений переменных.
Редактирование файла 22_Master_Poll.bin
Загрузим проект на uSD карту, обновим прошивку дисплея, включим программу Modbus Slave, выставим настройки порта и подключимся к дисплею.
При изменении полей 5000 и 5006 на дисплее видно что данные в программе обновляются. Если в Modbus Slave изменить поля 0004 и 0002 то изменения отобразятся на дисплее.
Источник: dzen.ru
Python тоже частично отказывается от терминов master/slave

Политкорректность учитывается даже в языках программирования. На прошлой неделе Python-разработчик Виктор Стиннер (Victor Stinner) из Red Hat прислал четыре пул-реквеста на переименование потенциально оскорбительных терминов master/slave (хозяин/раб) в документации и коде Python. Автор предложил заменить их социально нейтральными словами, не оскорбляющими людей, чьи предки были настоящими рабами. В качестве возможной альтернативы есть термины parent/worker.
Предлагаемое изменение — не какая-то прихоть одного разработчика, а общая тенденция для разных языков программирования и технологий. Стиннер привёл примеры аналогичных изменений в Redis, Drupal, CouchDB и Django. Так, Django и CouchDB заменили термины master/slave на leader/follower.
При этом Стиннер высказал мнение, что «рабовладельческую» терминологию всё-таки можно оставить для некоторых терминов, таких как ветка master в Git, веб-мастер и postmaster.
Развернулась жаркая дискуссия.
Поиск по кодовой базе python/cpython находит многочисленные включения «оскоробительных» терминов master и slave рядом друг с другом, в том числе в библиотеках pty и openpty.
STDIN_FILENO = 0 STDOUT_FILENO = 1 STDERR_FILENO = 2 CHILD = 0 def openpty(): «»»openpty() -> (master_fd, slave_fd) Open a pty master/slave pair, using os.openpty() if possible.»»» try: return os.openpty()
Виктор Стиннер говорит, что «поступали жалобы» на такую терминологию, но они высказывались в частном порядке, а не публично, чтобы избежать ругани.
В обсуждении проблемы коллеги обращают внимание, что документация Python не дублирует документацию Linux — а именно оттуда идёт использование терминов master/slave для многих функций. Таким образом, если согласиться на переименование только для Python, то это приведёт к отклонению от общепринятого стандарта Linux. Грубо говоря, одни и те же функции документация Python и Linux будет описывать разными словами. Коллеги предлагают отказаться от изменений «вторичной» документации Python до тех пор, пока соответствующие изменения не будут внесены в документацию Linux.
Внимание разработчиков привлекают в первую очередь такие участки кода и терминологии, где слова «хозяин» и «раб» встречаются рядом друг с другом. Если же master упоминается изолированно, то эти фрагменты можно оставить в неприкосновенности. Например, в модуле doctest есть обозначение doctest.master:
# For backward compatibility, a global instance of a DocTestRunner # class, updated by testmod. master = None
По мнению Виктора Стиннера, это уже выглядит не слишком оскорбительно.
Автор нашёл множество случаев, где упоминается «унизительная лексика». Например, в nntplib.NNTP() есть метод slave(), который отправляет команду slave на сервер. Данное исправление потребует изменений протокола NNTP, а именно раздела 3.12 (команда SLAVE), пишет Стиннер.
Другой пример — атрибут mbuf.master обект PyMemoryViewObject в программных интерфейсах C API:
typedef struct < PyObject_HEAD int flags; /* state flags */ Py_ssize_t exports; /* number of direct memoryview exports */ Py_buffer master; /* snapshot buffer obtained from the original exporter */ >_PyManagedBufferObject; /* memoryview state flags */ #define _Py_MEMORYVIEW_RELEASED 0x001 /* access to master buffer blocked */ #define _Py_MEMORYVIEW_C 0x002 /* C-contiguous layout */ #define _Py_MEMORYVIEW_FORTRAN 0x004 /* Fortran contiguous layout */ #define _Py_MEMORYVIEW_SCALAR 0x008 /* scalar: ndim = 0 */ #define _Py_MEMORYVIEW_PIL 0x010 /* PIL-style layout */ typedef struct < PyObject_VAR_HEAD _PyManagedBufferObject *mbuf; /* managed buffer */ Py_hash_t hash; /* hash value for read-only views */ int flags; /* state flags */ Py_ssize_t exports; /* number of buffer re-exports */ Py_buffer view; /* private copy of the exporter’s view */ PyObject *weakreflist; Py_ssize_t ob_array[1]; /* shape, strides, suboffsets */ >PyMemoryViewObject;
В общем, master и slave встречаются буквально повсюду. Виктор Стиннер предложил ряд патчей, которые местами исправляют ситуацию. Таким образом, в версии Python 3.8 термины master/slave будут встречаться реже.
Теоретически, в отдельных случаях проблему можно решить, не отказываясь от устоявшейся терминологии. Например, разработчики Redis предложили оригинальный выход из ситуации: с версии 1.0.0 там поддерживается команда SLAVEOF NO ONE, которая превращает сервер-slave в сервер-master. Хуже, если соответствующих изменений в синтаксисе потребуют власти. Предпосылки к этому уже есть. Например, в 2003 году отдел закупок департамента внутренних сервисов округа Лос-Анджелес разослал производителям электроники и бытовой техники уведомление с просьбой избегать терминов master/slave в описании своей продукции.
В 2004 году группа мониторинга Global Language Monitor назвала master/slave самым политически некорректным термином года. В технологической индустрии эти слова употребляются очень давно и стали частью многочисленных стандартов, в том числе RFC 977 от 1986 года.
По поводу пулл-реквестов Виктора Стиннера начались споры, которые полностью отражают аргументы убеждённых противников и сторонников политкорректности — такие споры ведутся на разных форумах. Конец дискуссии положил сам Гвидо ван Россум, который формально уже отошёл от дел, но присматривает за своим детищем Python. Он смерджил три из четырёх предложенных пул-реквеста, а четвёртый отверг, потому что он отражает оригинальную терминологию pty из UNIX.
Заметим, что «оскорбительная» терминология по историческим причинам стала частью современного языка и вряд ли от неё можно полностью избавиться. Например, Дэвид Гребер в книге «Долг: первые 5000 лет истории» приводит пример понятий “dominium” (доминиум) и “familia” (семья):
Что касается понятия “dominium”, то оно происходит от слова “dominus”, которое означает «хозяин», или «рабовладелец», но восходит к слову “domus”, т. е. «дом», или «хозяйство». С этим связан английский термин “domestic” («домашний»), который даже сегодня может использоваться в значении «относящийся к частной жизни» или же обозначать слугу, убирающего дом. “Domus” перекликается со словом “familia”, т. е. «семья», но “familia” происходит от слова “famulus”, т. е. «раб». Изначально под семьёй понимались все люди, находившиеся под домашней властью “pater familias”, которая была, по крайней мере в раннем римском праве, абсолютной.
У мужчины не было полной власти над женой, поскольку она до некоторой степени по-прежнему оставалась под защитой своего отца, но с детьми, рабами и другими зависимыми людьми он мог делать все, что ему вздумается, — во всяком случае, в раннем римском праве он был волен их пороть, пытать или продавать. Отец мог даже казнить своих детей, если обнаруживал, что они совершили тяжкое преступление. А если дело касалось рабов, то ему не требовалось и этого предлога.
Создавая понятие “dominium”, которое легло в основу современного принципа частной собственности, римские юристы обратились к принципу домашней власти, полной власти над людьми, определили некоторых из этих людей (рабов) как вещи, а затем распространили логику, которая изначально применялась по отношению к рабам, на гусей, колесницы, амбары, ювелирные шкатулки и т. д., то есть на любую вещь, имеющую отношение к праву.
То есть даже слова «семья», «фамилия» или понятие частной собственности можно считать неполиткорректными по такой логике: все они имеют отношение к рабству. Эти понятия вошли в современные языки со многими словами, о происхождении которых люди обычно не задумываются. Есть повод оскорбиться и у славян.
«Весьма неполиткорректно присваивать типы объектам до момента их создания!
Мы не должны навязывать объектам, кем им быть, а кем — нет.
Объект может сам решить, какого он типа, прямо в рантайме. Более того, он вправе изменить свой тип, если почувствует к этому внутреннюю расположенность.
Сегрегация объектов по их типу должна быть запрещена на законодательном уровне, покуда не станет интернированной социальной нормой каждого кодера.
Всем объектам на уровне операционной системы должны быть гарантированы равные возможности и по первому требованию предоставлены равные права.
Пока системы далеки от совершенства, стоит предусмотреть в них обязательные квоты для объектов каждого типа и следить за их неукоснительным соблюдением».
- Python
- Гвидо ван Россум
- политкорректность
Источник: habr.com
GitHub заменит термин «master» на более нейтральный аналог

Рекомендуем почитать:
Xakep #282. Атака Базарова
- Содержание выпуска
- Подписка на «Хакер» -60%
Нэт Фридман (Nat Friedman), возглавивший GitHub после приобретения компании Microsoft в 2018 году, заявил в Twitter, что в компании уже ведется работа над заменой термина master на более нейтральный аналог, например, main, чтобы избежать ненужных отсылок к рабовладельческим временам.
Если это действительно произойдет, GitHub станет одной из многих ИТ-компаний и опенсорсных проектов, которые в последние годы высказались в пользу отказа от различных терминов, которые могут быть истолкованы как оскорбительные с точки зрения чернокожих разработчиков.
Подобные изменения обычно включают в себя отказ от использования терминов master и slave («хозяин» и «раб») в пользу таких альтернатив как main, default, primary и, соответственно, secondary. Также устоявшиеся понятия whitelist и blacklist, то есть «черный список» и «белый список», заменяют на нейтральные allow list и deny/exclude list («список разрешений» и «список запретов/исключений»).
Под влиянием протестов Black Lives Matter, прокатившихся по всей территории США, ИТ-сообщество вновь вернулось к обсуждению этих вопросов, и в настоящее время многие разработчики прилагают усилия для удаления подобной терминологии из своего исходного кода, приложений и онлайн-сервисов.
К примеру, о намерении подыскать альтернативы для whitelist/blacklist в последнее время сообщили разработчики Android, языка программирования Go, библиотеки PHPUnit и утилиты Curl. В свою очередь, авторы проекта OpenZFS уже работают над заменой терминов master/slave, использующихся для описания связей между средами хранения. Габриэль Чапо (Gabriel Csapo), инженер LinkedIn, и вовсе заявил в Twitter, что он подает запросы на обновление многих внутренних библиотек Microsoft, добиваясь удаления из них любых расистских понятий.
Другие проекты, которые не используют подобные термины напрямую в своем исходном коде или пользовательских интерфейсах, обратили внимание на свои репозитории с исходниками. Дело в том, что большинство этих проектов управляют исходными кодами с помощью Git или GitHub, а Git и GitHub, в частности, используют обозначение master для дефолтного репозитория.
Журналисты издания ZDNet обратили внимание, что ряд опенсорсных проектов уже поддержали Black Lives Matter и сменили названия своих репозиториев с master по умолчанию на различные альтернативы (такие как main, default, primary, root и так далее). В их числе OpenSSL, Ansible, PowerShell, JavaScript-библиотека P5.js и многие другие.
Эти действия породили в опенсорсном сообществе весьма бурную дискуссию, и дело дошло до того, что над подобными изменениями теперь задумались и разработчики Git (хотя обсуждения в рассылке и на GitHub Issues по-прежнему далеки от завершения).
Но что бы ни решили разработчики Git, похоже, представители GitHub решили идти своим путем, невзирая на это. Так, в конце минувшей недели инженер Chrome Уна Кравец сообщила в Twitter, что команда разработки Chrome рассматривает возможность аналогичного шага по переименованию дефолтной ветки исходников браузера с master на более нейтральное main.
В своем сообщении Кравец попросила GitHub обратить внимание на эту проблему и помочь изменить ситуацию в отрасли. И, как можно увидеть выше, на твит ответил сам глава GitHub Нэт Фридман. Он заявил, что это отличная идея, и в GitHub уже работают над проблемой.
Стоит сказать, что разработчики прилагают усилия по искоренению некорректных и потенциально оскорбительных терминов не только в последнее время. Все началось еще в 2014 году, когда проект Drupal отказался от терминов master/slave в пользу primary/replica. Тогда примеру Drupal последовали и другие, включая Python, Chromium, Microsoft Roslyn .NET, а также PostgreSQL и Redis.
Однако, несмотря на то, что подобные перемены явно одобряют разработчики многих крупных проектов, пока все это не получило широкого распространения. К примеру, большинство противников подобных изменений часто объясняют в дискуссиях, что такие термины, как master/slave в наши дни чаще используются для описания технических сценариев, а не как отсылка к фактическому рабству, а слово blacklist, то есть «черный список» вообще не имеет никакого отношения к темнокожим людям. Оно появилось еще в средневековой Англии, когда, например, имена проблемных наемных рабочих заносили в специальные книги, которые назывались «черными» (причем речь шла о позоре, порицании и наказании, а не о цвете кожи).
Источник: xakep.ru
Что такое репликация данных
Репликация — одна из техник масштабирования баз данных.
Состоит эта техника в том, что данные с одного сервера базы данных постоянно копируются (реплицируются) на один или несколько других (называемые репликами). Для приложения появляется возможность использовать не один сервер для обработки всех запросов, а несколько. Таким образом появляется возможность распределить нагрузку с одного сервера на несколько.
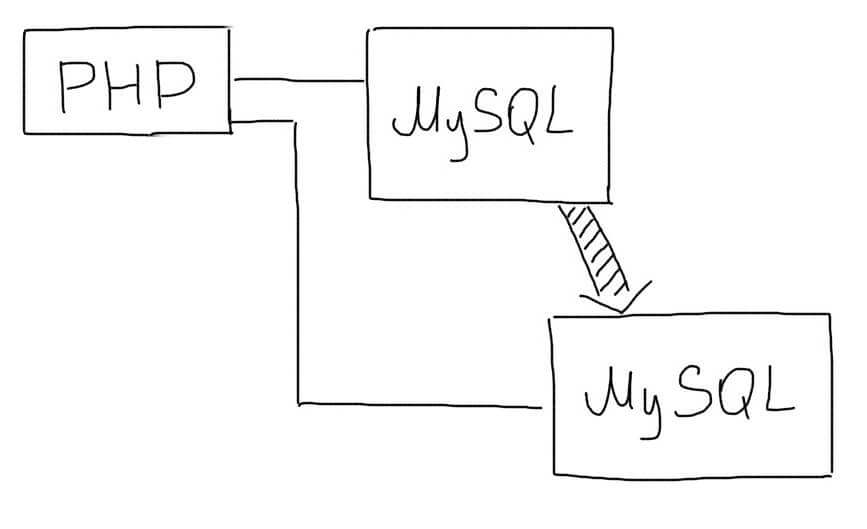
Существует два основных подхода при работе с репликацией данных:
Master-Slave репликация
В этом подходе выделяется один основной сервер базы данных, который называется Master. На нем происходят все изменения в данных (любые запросы INSERT/UPDATE/DELETE ).
Slave сервер постоянно копирует все изменения с Master. С приложения на Slave-сервер отправляются запросы чтения данных (запросы SELECT ). Таким образом Master-сервер отвечает за изменения данных, а Slave за чтение.
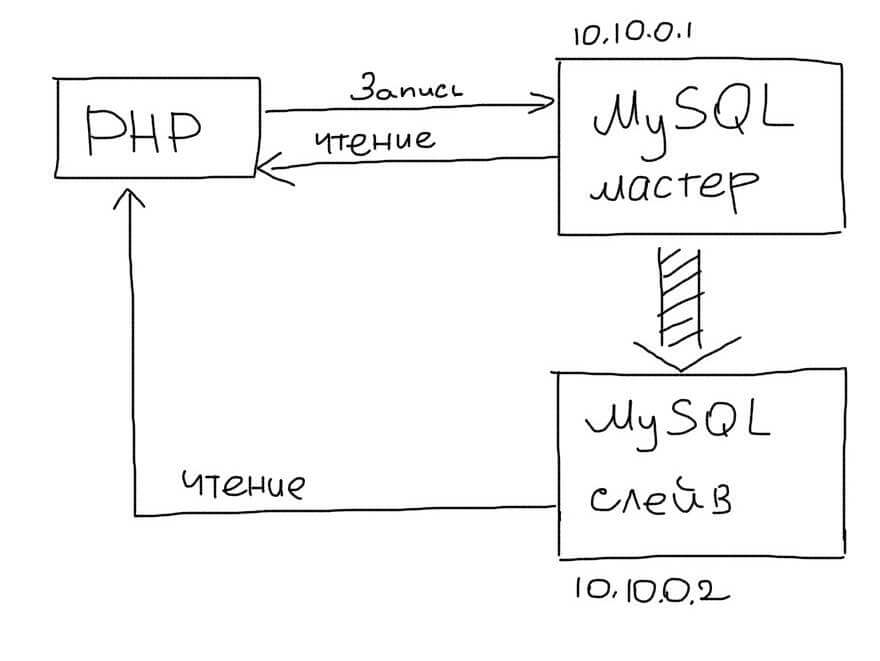
В приложении нужно использовать два соединения — одно для Master, второе — для Slave:
(Используем два соединения — для Master и Slave — для записи и чтения соответственно)
$master = mysql_connect(‘10.10.0.1’, ‘root’, ‘pwd’);
$slave = mysql_connect(‘10.10.0.2’, ‘root’, ‘pwd’);
# .
mysql_query(‘INSERT INTO users . ‘, $master);
# .
$q = mysql_query(‘SELECT * FROM photos . ‘, $slave);
Несколько Slave серверов
Преимущество этого типа репликации в том, что мы можем использовать более одного Slave сервера. Обычно следует использовать не более 20 Slave серверов при работе с одним Master.
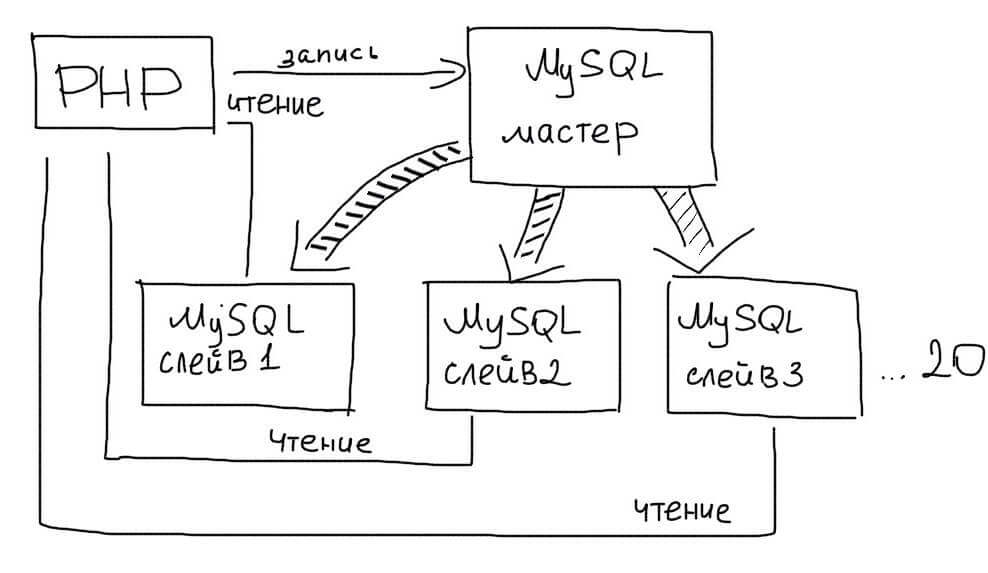
Тогда приложение выбирает случайным образом один из Slave серверов для обработки запросов:
$master = mysql_connect(‘10.10.0.1’, ‘root’, ‘pwd’);
$slaves = [
‘10.10.0.2’,
‘10.10.0.3’,
‘10.10.0.4’,
];
$slave = mysql_connect($slaves[array_rand($slaves)], ‘root’, ‘pwd’);
# .
mysql_query(‘INSERT INTO users . ‘, $master);
# .
$q = mysql_query(‘SELECT * FROM photos . ‘, $slave);
Задержка репликации
Асинхронность репликации означает, что данные на Slave могут появиться с небольшой задержкой. Поэтому, в последовательных операциях необходимо использовать чтение с Master, чтобы получить актуальные данные:
(При обращении к изменяемым данным, необходимо использовать Master-соединение)
$master = mysql_connect(‘10.10.0.1’, ‘root’, ‘pwd’);
$slave = mysql_connect(‘10.10.0.2’, ‘root’, ‘pwd’);
# .
mysql_query(‘UPDATE users SET age = 25 WHERE id = 7’, $master);
$q = mysql_query(‘SELECT * FROM users WHERE id = 7’, $master);
# .
$q = mysql_query(‘SELECT * FROM photos . ‘, $slave);
Выход из строя
При выходе из строя Slave, достаточно просто переключить все приложение на работу с Master. После этого восстановить репликацию на Slave и снова его запустить.
Если выходит из строя Master, нужно переключить все операции (и чтения и записи) на Slave. Таким образом он станет новым Master. После восстановления старого Master, настроить на нем реплику, и он станет новым Slave.
Резервирование
Намного чаще репликацию Master-Slave используют не для масштабирования, а для резервирования. В этом случае, Master сервер обрабатывает все запросы от приложения. Slave сервер работает в пассивном режиме. Но в случае выхода из строя Master, все операции переключаются на Slave.
Master-Master репликация
В этой схеме, любой из серверов может использоваться как для чтения так и для записи:
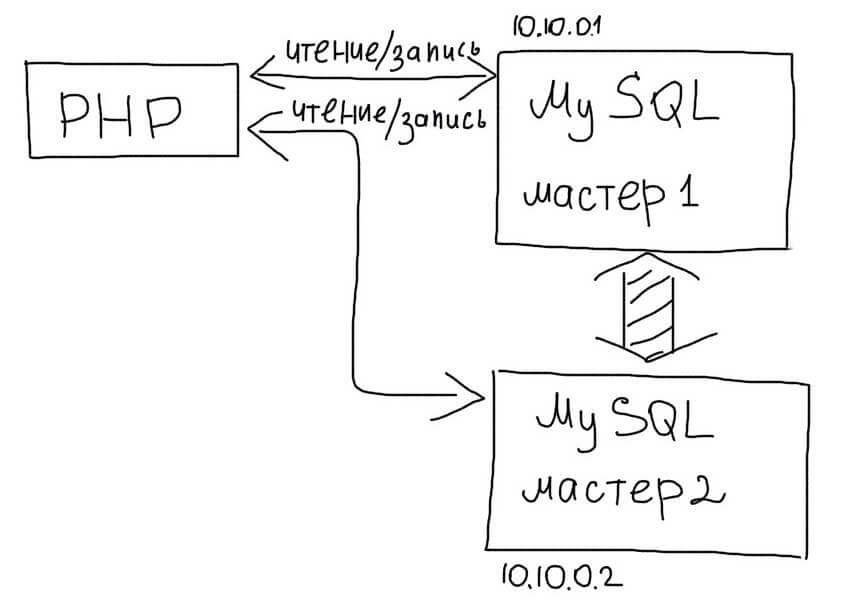
При использовании такого типа репликации достаточно выбирать случайное соединение из доступных Master серверов:
(Выбор случайного Master для обработки соединений)
$masters = [
‘10.10.0.1’,
‘10.10.0.2’,
‘10.10.0.3’,
];
$master = mysql_connect($masters[array_rand($masters)], ‘root’, ‘pwd’);
# .
mysql_query(‘INSERT INTO users . ‘, $master);
Выход из строя
Вероятные поломки делают Master-Master репликацию непривлекательной. Выход из строя одного из серверов практически всегда приводит к потере каких-то данных. Последующее восстановление также сильно затрудняется необходимостью ручного анализа данных, которые успели либо не успели скопироваться.
Используйте Master-Master репликацию только в крайнем случае. Вместо нее лучше пользоваться техникой “ручной” репликации, описанной ниже.
Асинхронность репликации
В MySQL репликация работает в асинхронном режиме. Это значит, что приложение не знает, как быстро данные появятся на Slave.
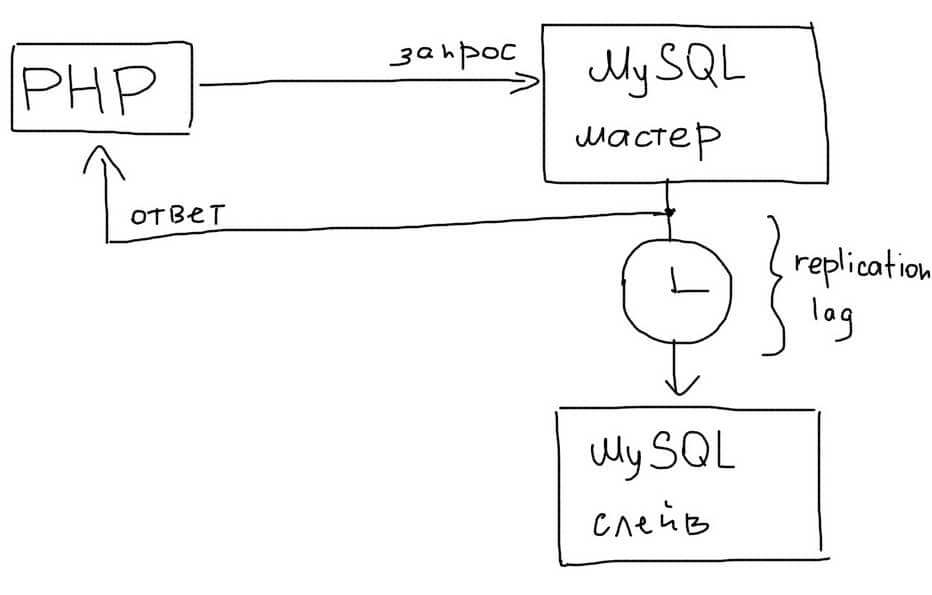
Задержка в репликации (replication lag) может быть как очень маленькой, так и очень большой. Обычно рост задержки говорит о том, что сервера не справляются с текущей нагрузкой и их необходимо масштабировать дальше, например техниками горизонтального и вертикального шардинга.
Синхронный режим
Синхронный режим репликации позволит гарантировать копирование данных на Slave.
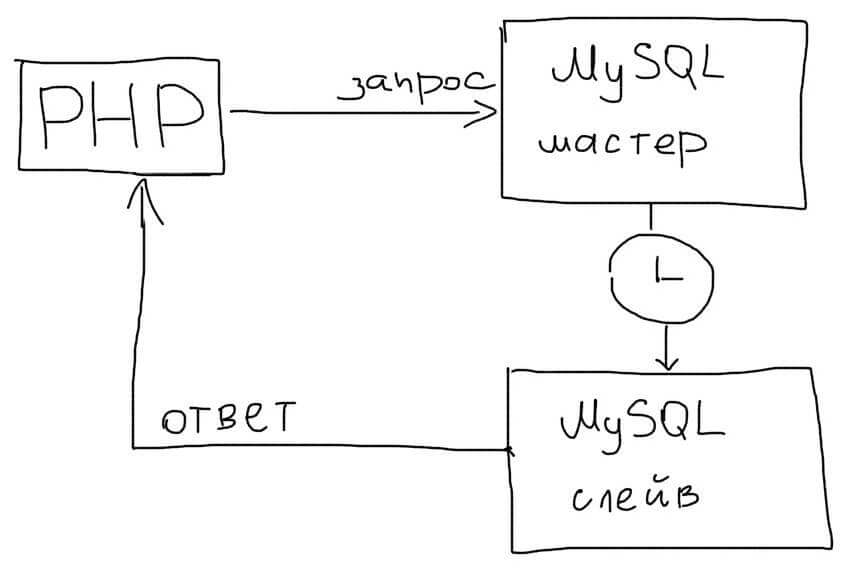
Это упростит работу в приложении, т.к. все операции чтения можно будет всегда отправлять на Slave. Однако это может значительно уменьшить скорость работы MySQL. Синхронный режим не следует использовать в Web приложениях.
“Ручная” репликация
Следует помнить, что репликация — это не технология, а методика. Встроенные механизмы репликации могут принести ненужные усложнения либо не иметь какой-то нужной функции. Некоторые технологии вообще не имеют встроенной репликации.
В таких случаях, следует использовать самостоятельную реализацию репликации. В самом простом случае, приложение будет дублировать все запросы сразу на несколько серверов базы данных:
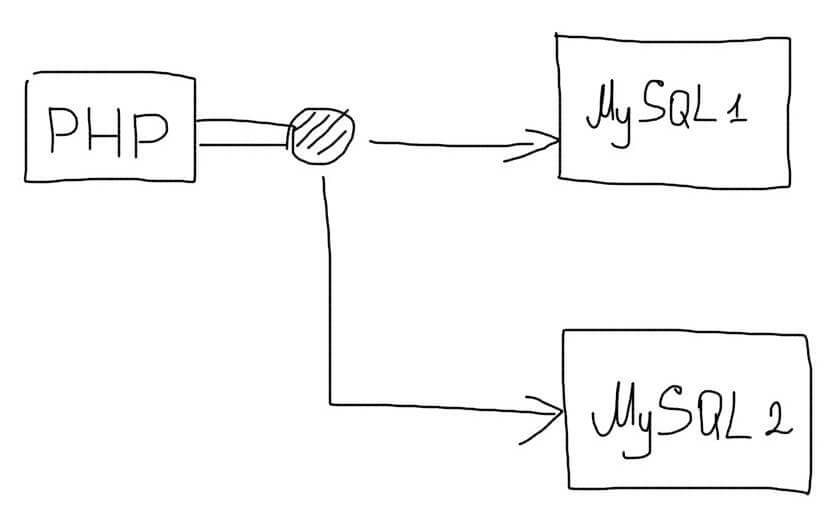
При записи данных, все запросы будут отправляться на несколько серверов. Зато операции чтения можно будет отправлять на любой сервер. Нагрузка при этом будет распределяться по всем доступным серверам:
(Все операции изменения данных происходят на нескольких серверах, а чтения — на одном случайном)
$dbs = [
‘10.10.0.1’,
‘10.10.0.2’
];
foreach ( $dbs as $db )
{
$connection = mysql_connect($db, ‘root’, ‘pwd’);
mysql_query(‘INSERT INTO users . ‘, $connection);
}
# .
$connection_read = mysql_connect($dbs[array_rand($dbs)], ‘root’, ‘pwd’);
mysql_query(‘SELECT * FROM users WHERE . ‘, $connection_read);
Это позволит использовать преимущества репликации даже если сама технология ее не поддерживает.
Выход из строя
При поломке одного из серверов в такой схеме необходимо сделать следующее:
- Исключить сервер из списка используемых.
- Настроить репликацию Master-Slave на новом сервере, используя один из рабочих серверов в качестве Master.
- Когда все данные репликации будут синхронизированы, включить сервер обратно в список используемых и остановить репликацию.
Самое важное
Репликация используется в большей мере для резервирования баз данных и в меньшей для масштабирования. Master-Slave репликация удобна для распределения запросов чтения по нескольким серверам. Подход ручной репликации позволит использовать преимущества репликации для технологий, которые ее не поддерживают. Зачастую репликация используется вместе с шардингом при решении вопросов масштабирования.
Источник: bogachev.biz