
Согласно статистике Gartner, с 2015 по 2019 годы количество предприятий, использующих ИИ, выросло на 270%. А рынок ИИ к концу 2020 года вырастет на 12,3% — до 156,5 млрд долларов, и это несмотря на кризис. Мы расскажем, что такое искусственный интеллект, какой он бывает, а также почему ИИ и машинное обучение — не одно и то же.
Что такое искусственный интеллект
Искусственный интеллект — особая технология разработки компьютерных систем. Она позволяет создавать программы, способные выполнять задачи, требующие человеческого интеллекта: распознавание речи или изображений, принятие решений, анализ информации, перевод с одного языка на другой.
Чтобы лучше понять, чем AI отличается от обычных программ, рассмотрим пример с чат-ботом.
Обычный чат-бот без ИИ. Программист вписывает конкретные реплики и триггеры, на которые чат-бот отвечает заготовленными фразами. Например, на фразу «Хочу заказать пиццу» отвечает: «Какой размер: 30 или 50 см?».
Фразы вроде «Привези мне пиццу, умираю с голоду» или «Хочу пицу 50 сантиметров» введут такого бота в ступор. Предугадать все возможные запросы пользователей программист не сможет.
ИИ, машинное обучение, НЕЙРОСЕТИ, Что есть что? | БОЛЬШОЙ РАЗБОР
Чат бот с ИИ. Такой чат-бот анализирует лексику, сравнивает похожие запросы, улавливает общий контекст фразы. Он поймет, что «пица» — это «пицца», а «привези» — это «хочу заказать». Еще такой бот может учиться, со временем он будет всё лучше понимать пользователей и отвечать на их запросы. Например, предугадывать, какой именно сорт пиццы понравится человеку.
Так выглядит разница в переписке с обычным ботом и с ботом-ИИ. Искусственный интеллект быстрее решает вопрос и лучше понимает собеседника
Есть задачи, с которыми обычные программы вообще не справляются. Например, только искусственный интеллект может распознавать лица и голос, сортировать изображения и решать прочие, более «творческие» задачи.
Искусственный интеллект используют для разных задач. Один из первых широко известных ИИ — Deep Blue, создали в 1992 году, чтобы играть в шахматы — и в 1997 году он обыграл Гарри Каспарова. Позже стали появляться другие такие программы для игры в го, покер или компьютерную игру Dota 2.
Также ИИ разрабатывают для автоматизации производства, прогнозирования спроса на товары или блокировки подозрительных банковских операций. Обычно всё это — конкретные прикладные задачи, которые раньше решали люди.
ИИ часто лучше справляется с рутинными задачами, работает быстрее людей и совершает меньше ошибок. Но он всё еще плохо работает в нестандартных ситуациях и может решать только очень конкретные, прикладные задачи. Полностью заменить людей искусственный интеллект пока не в состоянии.
Какой бывает искусственный интеллект
Сейчас любой существующий искусственный интеллект далек от человеческого. Самые совершенные AL не обладают сознанием и не осознают себя как личность. Они могут обучаться, но это просто алгоритмы, способные только к решению конкретных задач, но не к настоящему творчеству и изобретательству. Такие ИИ называют слабыми.
Есть теория, что когда-нибудь люди разработают сильный ИИ. Он будет близок к человеку: осознает себя как личность, сможет работать в разных условиях, решать нетипичные задачи, творить и создавать что-то совершенно новое. Пока такого не существует.
Некоторые ученые считают, что создать сильный искусственный интеллект невозможно. С другой стороны, раньше невозможными казались ИИ, которые разрабатывают сейчас: они умеют общаться голосом, писать тексты, рисовать и распознавать лица. Пока это всё еще простые алгоритмы, но они совершенствуются с каждым днем.
Слабые ИИ можно поделить еще на две группы:
Ограниченные ИИ. Такие программы способны решать только одну конкретную задачу. Например, чат-бот может общаться с клиентами, но не способен контролировать датчики на производстве или предсказывать спрос.
Универсальные ИИ. Такие ИИ способны решать несколько разных задач. Для этого их не нужно перепрограммировать — достаточно обучить новому делу. Один из таких ИИ — Watson IBM. Он знаменит тем, что выиграл в интеллектуальной викторине Jeopardy, но его используют также для постановки диагнозов, лингвистического анализа, финансовых советов и множества других задач.
На видео Watson IBM обыгрывает знатоков в интеллектуальной викторине.
Чем искусственный интеллект отличается от машинного обучения
Часто между понятиями «искусственный интеллект» и «машинное обучение» ставят знак равенства. На самом деле машинное обучение — это способ создания и обучения искусственного интеллекта.
Чтобы понять разницу, представим схему работы:
- Сначала программист создает программу, которая способна обучаться. Пока она еще ничего не умеет.
- Затем программист обучает программу с помощью методов машинного обучения . Это могут быть, например, нейросети или генетические алгоритмы.
- После обучения программа приобретает искусственный интеллект . Можно сказать, что она сама становится искусственным интеллектом.
Сегодня машинное обучение — единственный способ создания искусственного интеллекта. Любая современная технология или алгоритм — это, так или иначе, обучение компьютера.
Когда кто-то говорит, что разработал искусственный интеллект — он обязательно использовал машинное обучение для его создания. А если кто-то говорит, что использует машинное обучение — он по факту использует именно искусственный интеллект, так как само «обучение» не может выполнять никакие задачи.
Но искусственный интеллект — это не только машинное обучение. Для работы ИИ необходимы вычислительные мощности, данные и другие программы и технологии. Поэтому знак равенства между этими терминами не поставить.
Чтобы быстро создавать ИИ на базе машинного обучения, можно арендовать вычислительные мощности в облаке. Например, на платформе Mail.Ru Cloud Solutions есть сервис быстрой разработки приложений на основе машинного обучения .
Возможно, в будущем появятся другие способы создания искусственного интеллекта. Например, люди научатся копировать мозг человека и имитировать биологические процессы. В таком случае машинное обучение может исчезнуть, но искусственный интеллект никуда не денется и, может быть, даже станет более совершенным.
Кратко об искусственном интеллекте
- Искусственный интеллект используют для разных задач, в том числе чтобы принимать бизнес-решения и общаться с клиентами.
- Любой современный ИИ — слабый, потому что не осознает себя, не может действовать в нестандартных ситуациях и довольно далек от человеческого. Возможно, в будущем появится сильный ИИ, который сможет творить и мыслить нестандартно, но пока его не существует.
- Слабый ИИ бывает ограниченным и универсальным. Большинство современных AL — ограниченные, то есть решают одну конкретную задачу. Универсальных ИИ мало, но они способны решать разные задачи в зависимости от обучения.
- Машинное обучение ≠ искусственный интеллект. Машинное обучение — это метод создания ИИ, пока что единственный. Но если когда-то появятся более совершенные методы, ИИ все равно останется.
Источник: dzen.ru
AI для людей: простыми словами о технологиях
Представляем исчерпывающую шпаргалку, где мы простыми словами рассказываем, из чего «делают» искусственный интеллект и как это все работает.
В чем разница между Artificial Intelligence, Machine Learning и Data Science?
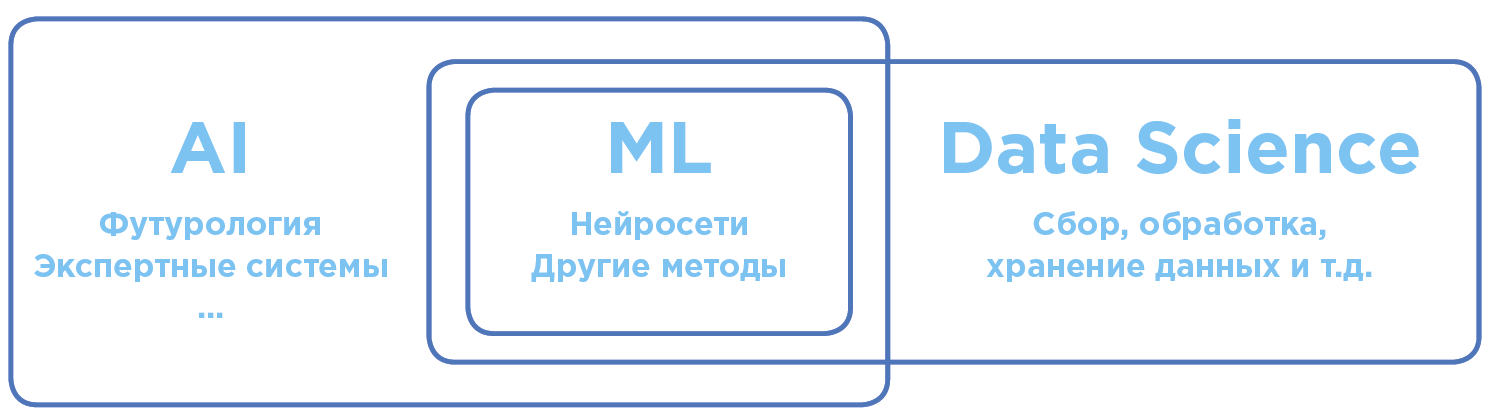
Разграничение понятий в области искусственного интеллекта и анализа данных.
Artificial Intelligence — AI (Искусственный Интеллект)
В глобальном общечеловеческом смысле ИИ — термин максимально широкий. Он включает в себя как научные теории, так и конкретные технологические практики по созданию программ, приближенных к интеллекту человека.
Machine Learning — ML (Машинное обучение)
Раздел AI, активно применяющийся на практике. Сегодня, когда речь заходит об использовании AI в бизнесе или на производстве, чаще всего имеется в виду именно Machine Learning.
ML-алгоритмы, как правило, работают по принципу обучающейся математической модели, которая производит анализ на основе большого объема данных, при этом выводы делаются без следования жестко заданным правилам.
Наиболее частый тип задач в машинном обучении — это обучение с учителем. Для решения такого рода задач используется обучение на массиве данных, по которым ответ заранее известен (см.ниже).
Data Science — DS (Наука о данных)
Наука и практика анализа больших объемов данных с помощью всевозможных математических методов, в том числе машинного обучения, а также решение смежных задач, связанных со сбором, хранением и обработкой массивов данных.
Data Scientists — специалисты по работе с данными, в частности, проводящие анализ при помощи machine learning.

Как работает Machine Learning?
Рассмотрим работу ML на примере задачи банковского скоринга. Банк располагает данными о существующих клиентах. Ему известно, есть ли у кого-то просроченные платежи по кредитам. Задача — определить, будет ли новый потенциальный клиент вовремя вносить платежи.
По каждому клиенту банк обладает совокупностью определенных черт/признаков: пол, возраст, ежемесячный доход, профессия, место проживания, образование и пр. В числе характеристик могут быть и слабоструктурированные параметры, такие как данные из соцсетей или история покупок. Кроме того, данные можно обогатить информацией из внешних источников: курсы валют, данные кредитных бюро и т. п.
Машина видит любого клиента как совокупность признаков: . Где, например, — возраст, — доход, а — количество фотографий дорогих покупок в месяц (на практике в рамках подобной задачи Data Scientist работает с более чем сотней признаков). Каждому клиенту соответствует еще одна переменная — с двумя возможными исходами: 1 (есть просроченные платежи) или 0 (нет просроченных платежей).
Совокупность всех данных и — есть Data Set. Используя эти данные, Data Scientist создает модель , подбирая и дорабатывая алгоритм машинного обучения.
В этом случае модель анализа выглядит так:
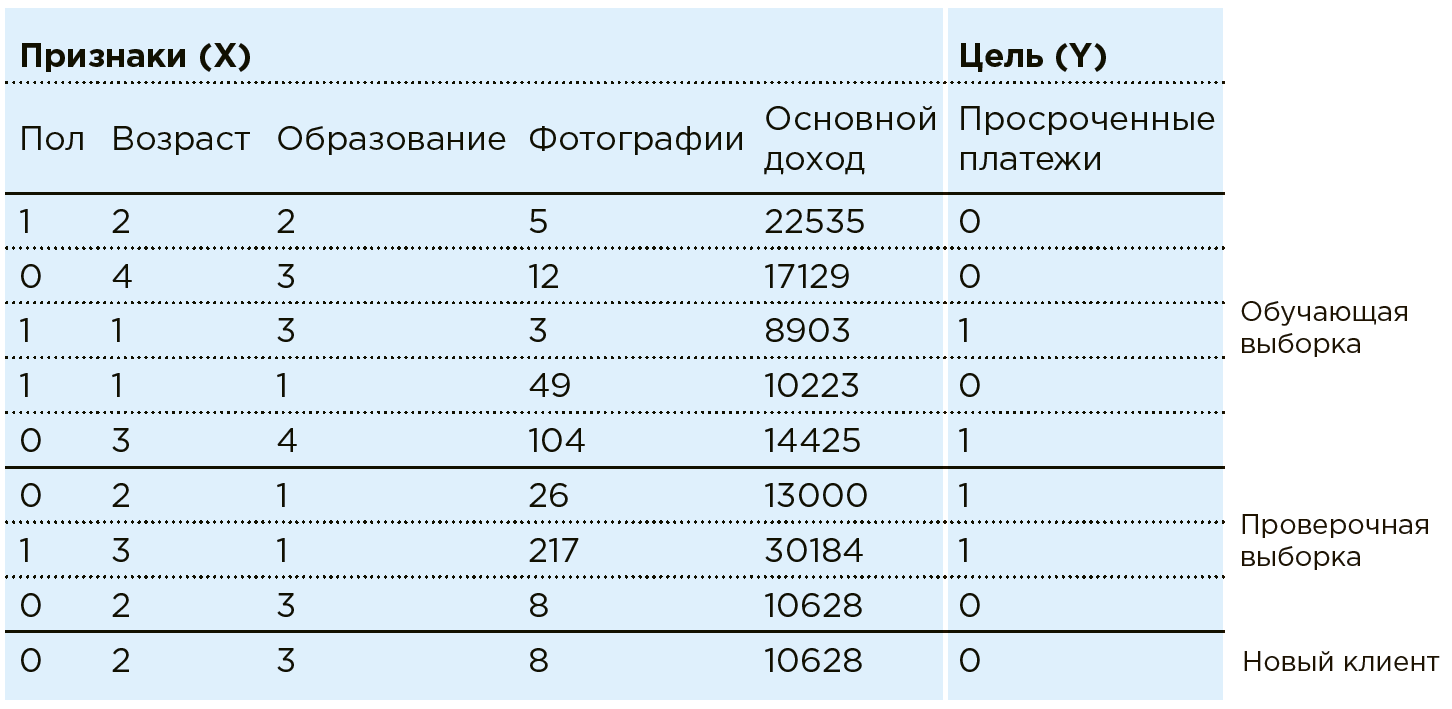
Алгоритмы машинного обучения подразумевают поэтапное приближение ответов модели к истинным ответам (которые в обучающем Data Set известны заранее). Это и есть обучение с учителем на определенной выборке.
На практике чаще всего машина обучается лишь на части массива (80 %), применяя остаток (20 %) для проверки правильности выбранного алгоритма. Например, система может обучаться на массиве, из которого исключены данные пары регионов, на которых сверяется точность модели после.
Теперь, когда в банк приходит новый клиент, по которому еще не известен банку, система подскажет надежность плательщика, основываясь на известных о нем данных .
Однако, обучение с учителем — не единственный класс задач, которые способна решать ML.
Другой спектр задач — кластеризация, способная разделять объекты по признакам, например, выявлять разные категории клиентов для составления им индивидуальных предложений.
Также с помощью ML-алгоритмов решаются такие задачи, как моделирование общения специалиста поддержки или создание художественных произведений, неотличимых от сотворенных человеком (например, нейросети рисуют картины).
Новый и популярный класс задач — обучение с подкреплением, которое проходит в ограниченной среде, оценивающей действия агентов (например, с помощью такого алгоритма удалось создать AlphaGo, победившую человека в Го).

Нейронная сеть
Один из методов Machine Learning. Алгоритм, вдохновленный структурой человеческого мозга, в основе которой лежат нейроны и связи между ними. В процессе обучения происходит подстройка связей между нейронами таким образом, чтобы минимизировать ошибки всей сети.
Особенностью нейронных сетей является наличие архитектур, подходящих практически под любой формат данных: сверточные нейросети для анализа картинок, рекуррентные нейросети для анализа текстов и последовательностей, автоэнкодеры для сжатия данных, генеративные нейросети для создания новых объектов и т. д.
В то же время практически все нейросети обладают существенным ограничением — для их обучения нужно большое количество данных (на порядки большее, чем число связей между нейронами в этой сети). Благодаря тому, что в последнее время объемы готовых для анализа данных значительно выросли, растет и сфера применения. С помощью нейросетей сегодня, например, решаются задачи распознавания изображений, такие как определение по видео возраста и пола человека, или наличие каски на рабочем.
Интерпретация результата
Раздел Data Science, позволяющий понять причины выбора ML-моделью того или иного решения.
Существует два основных направления исследований:
- Изучение модели как «черного ящика». Анализируя загруженные в него примеры, алгоритм сравнивает признаки этих примеров и выводы алгоритма, делая выводы о приоритете каких-либо из них. В случае с нейросетями обычно применяют именно черный ящик.
- Изучение свойств самой модели. Изучение признаков, которые использует модель, для определения степени их важности. Чаще всего применяется к алгоритмам, основанным на методе решающих деревьев.
Естественно, производство интересует не только прогноз самого брака, но и интерпретация результата, т. е. причины брака для их последующего устранения. Это может быть долгое отсутствие тех.обслуживания станка, качество сырья, или просто аномальные показания некоторых датчиков, на которые технологу стоит обратить внимание.
Потому в рамках проекта прогноза брака на производстве должна быть не просто создана ML-модель, но и проделана работа по её интерпретации, т. е. по выявлению факторов, влияющих на брак.

Когда эффективно применение машинного обучения?
Когда есть большой набор статистических данных, но найти в них зависимости экспертными или классическими математическими методами невозможно или очень трудоемко. Так, если на входе есть более тысячи параметров (среди которых как числовые, так и текстовые, а также видео, аудио и картинки), то найти зависимость результата от них без машины невозможно.
Например, на химическую реакцию кроме самих вступающих во взаимодействие веществ влияет множество параметров: температура, влажность, материал емкости, в которой она происходит, и т. д. Химику сложно учесть все эти признаки, чтобы точно рассчитать время реакции. Скорее всего, он учтет несколько ключевых параметров и будет основываться на своем опыте. В то же время на основании данных предыдущих реакций машинное обучение сможет учесть все признаки и дать более точный прогноз.
Как связаны Big Data и машинное обучение?
Для построения моделей машинного обучения требуются в разных случаях числовые, текстовые, фото, видео, аудио и иные данные. Для того чтобы эту информацию хранить и анализировать существует целая область технологий — Big Data. Для оптимального накопления данных и их анализа создают «озера данных» (Data Lake) — специальные распределенные хранилища для больших объемов слабоструктированной информации на базе технологий Big Data.
Цифровой двойник как электронный паспорт
Цифровой двойник — виртуальная копия реального материального объекта, процесса или организации, которая позволяет моделировать поведение изучаемого объекта/процесса. Например, можно предварительно увидеть результаты изменения химического состава на производстве после изменений настроек производственных линий, изменений продаж после проведения рекламной кампании с теми или иными характеристиками и т. д. При этом прогнозы строятся цифровым двойником на основе накопленных данных, а сценарии и будущие ситуации моделируются в том числе методами машинного обучения.
Что нужно для качественного машинного обучения?
Data Scientiest’ы! Именно они создают алгоритм прогноза: изучают имеющиеся данные, выдвигают гипотезы, строят модели на основе Data Set. Они должны обладать тремя основными группами навыков: IT-грамотностью, математическими и статистическими знаниями и содержательным опытом в конкретной области.
Машинное обучение стоит на трех китах
Получение данных
Могут быть использованы данные из смежных систем: график работ, план продаж. Данные могут быть также обогащены внешними источниками: курсы валют, погода, календарь праздников и т. д. Необходимо разработать методику работы с каждым типом данных и продумать конвейер их преобразования в формат модели машинного обучения (набор чисел).
Построение признаков
Проводится вместе с экспертами из необходимой области. Это помогает вычислить данные, которые хорошо подходят для прогнозирования целей: статистика и изменение количества продаж за последний месяц для прогноза рынка.
Модель машинного обучения
Метод решения поставленной бизнес-задачи выбирает data scientist самостоятельно на основании своего опыта и возможностей различных моделей. Под каждую конкретную задачу необходимо подобрать отдельный алгоритм. От выбранного метода напрямую зависят скорость и точность результата обработки исходных данных.
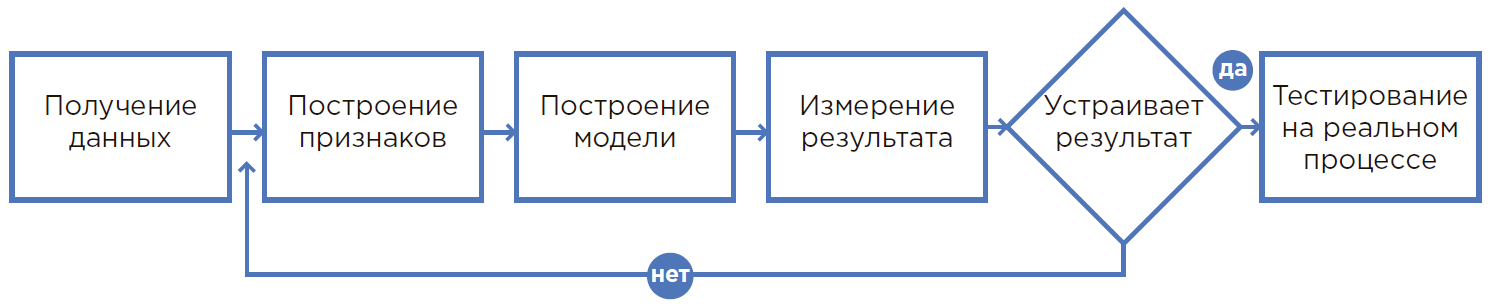
Процесс создания ML-модели.
От гипотезы до результата
1. Всё начинается с гипотезы
Гипотеза рождается при анализе проблемного процесса, опыта сотрудников или при свежем взгляде на производство. Как правило, гипотеза затрагивает такой процесс, где человек физически не может учесть множество факторов и пользуется округлениями, допущениями или просто делает так, как всегда делал.
В таком процессе применение машинного обучения позволяет использовать существенно больше информации при принятии решений, поэтому, возможно, удается достичь существенно лучших результатов. Плюс ко всему, автоматизация процессов с помощью ML и снижение зависимости от конкретного человека существенно минимизируют человеческий фактор (болезнь, низкая концентрация и т. д.).
2. Оценка гипотезы
На основании сформулированной гипотезы выбираются данные, необходимые для разработки модели машинного обучения. Осуществляется поиск соответствующих данных и оценка их пригодности для встраивания модели в текущие процессы, определяется, кто будет ее пользователями и за счет чего достигается эффект. При необходимости вносятся организационные и любые другие изменения.
3. Расчет экономического эффекта и возврата инвестиций (ROI)
Оценка экономического эффекта внедряемого решения производится специалистами совместно с соответствующими департаментами: эффективности, финансов и т. д. На данном этапе необходимо понять, что именно является метрикой (количество верно выявленных клиентов / увеличение выпуска продукции / экономия расходных материалов и т. п.) и четко сформулировать измеряемую цель.
4. Математическая постановка задачи
После понимания бизнес-результата его необходимо переложить в математическую плоскость — определить метрики измерений и ограничения, которые нельзя нарушать. Данные этапы data
scientist выполняет совместно с бизнес-заказчиком.
5. Сбор и анализ данных
Необходимо собрать данные в одном месте, проанализировать их, рассматривая различные статистики, понять структуру и скрытые взаимосвязи этих данных для формирования признаков.
6. Создание прототипа
Является, по сути, проверкой гипотезы. Это возможность построения модели на текущих данных и первичной проверки результатов ее работы. Обычно прототип делается на имеющихся данных без разработки интеграций и работы с потоком в реальном времени.
Создание прототипа — быстрый и недорогой способ проверить, решаема ли задача. Это весьма полезно в том случае, когда невозможно заранее понять, получится ли достичь нужного экономического эффекта. К тому же процесс создания прототипа позволяет лучше оценить объем и подробности проекта по внедрению решения, подготовить экономическое обоснование такого внедрения.
DevOps и DataOps
В процессе эксплуатации может появится новый тип данных (например, появится ещё один датчик на станке или же на складе появится новый тип товаров) тогда модель нужно дообучить. DevOps и DataOps — методологии, которые помогают настроить совместную работу и сквозные процессы между командами Data Science, инженерами по подготовке данных, службами разработки и эксплуатации ИТ-систем, и помогают сделать такие дополнения частью текущего процесса быстро, без ошибок и без решения каждый раз уникальных проблем.
7. Создание решения
В тот момент, когда результаты работы прототипа демонстрируют уверенное достижение показателей, создается полноценное решение, где модель машинного обучения является лишь составляющей изучаемых процессов. Далее производится интеграция, установка необходимого оборудования, обучение персонала, изменение процессов принятия решений и т. Д.
8. Опытная и промышленная эксплуатация
Во время опытной эксплуатации система работает в режиме советов, в то время как специалист еще повторяет привычные действия, каждый раз давая обратную связь о необходимых улучшениях системы и увеличении точности прогнозов.
Финальная часть — промышленная эксплуатация, когда налаженные процессы переходят на полностью автоматическое обслуживание.
Шпаргалку можно скачать по ссылке.
Завтра на форуме по системам искусственного интеллекта RAIF 2019 в 09:30 — 10:45 состоится панельная дискуссия: «AI для людей: разбираемся простыми словами».
В этой секции в формате дебатов спикеры объяснят простыми словами на жизненных примерах сложные технологии. А также подискутируют на следующие темы:
- В чем разница между Artificial Intelligence, Machine Learning и Data Science?
- Как работает машинное обучение?
- Как работают нейронные сети?
- Что нужно для качественного машинного обучения?
- Что такое разметка, маркировка данных?
- Что такое цифровой двойник и как работать с виртуальными копиями реальных материальных объектов?
- В чем суть гипотезы? Как пройти путь от её постановки до оценки и интерпретации результата?
Николай Марин, директор по технологиям, IBM в России и СНГ
Алексей Натекин, основатель, Open Data Science x Data Souls
Алексей Хахунов, технический директор, Dbrain
Евгений Колесников, директор Центра машинного обучения, Инфосистемы Джет
Павел Доронин, CEO, AI Today
Дискуссия будет доступна на канале YouTube «Инфосистемы Джет» в конце октября.
- Artificial Intelligence
- Machine Learning
- Data Science
- Блог компании Инфосистемы Джет
- Алгоритмы
- Машинное обучение
- Искусственный интеллект
Источник: habr.com
Системы искусственного интеллекта — их развитие и области применения
Термин искусственный интеллект (ИИ) в 1956 году ввел Джон Маккарти на международной конференции в Дартмутском университете.
В 60-ых годах прошлого столетия разработками заинтересовалось министерство обороны США — проектировались компьютеры, имитирующие человеческие рассуждения. Эти работы легли в основу современных решений. Сегодня под ИИ подразумевают особые свойства программ, которые могут выполнять сложные функции, схожие с человеческой деятельностью.

Directum Ario One
Набор интеллектуальных сервисов и решений для роботизации процессов обработки любой текстовой информации.
Гарантия 100%-ного распознавания документов.
Разберемся с основными понятиями:
Искусственный интеллект (англ. Artificial intelligence (AI)) — под этим термином понимается область информатики, в рамках которой разрабатываются компьютерные программы для выполнения задач, способных имитировать человеческий подход — обнаруживать смысл, обобщать и делать выводы, выявлять взаимосвязи и обучаться с учетом накопленного опыта.
Искусственный интеллект никого не заменяет, цель его применения — расширение и дополнение возможностей человека.
Машинное обучение — одно из направлений искусственного интеллекта, благодаря которому воплощается ключевое свойство — самообучение на основе получаемых данных. Чем больше объем информации и ее разнообразие, тем проще ИИ найти закономерности и тем точнее будет выдаваемый результат.
Нейронная сеть (нейросеть) в контексте этой тематики — один из видов машинного обучения — особая математическая модель и ее программная реализация, которая в упрощенном виде воссоздает принципы строения и работы биологической нейронной сети.
Ключевое свойство нейросети — использование опыта для самообучения, т.е. чем больше данных в распоряжении ИИ, тем меньше совершается ошибок.
Обработка естественного языка (англ. Natural Language Processing, NLP) — способность программного решения или компьютера распознавать, понимать и воспроизводить привычный язык человека. Система искусственного интеллекта — пользовательское ИИ-приложение или их комплекс для решения бизнес-задач, выполнение которых традиционно оставалось за человеком.
Развитие искусственного интеллекта как направления связывают с необходимостью решать конкретные задачи, которые зачастую трудоемки для людей. Однако пока каждая разработка закрывает свой узкий круг задач: для медицинских целей, для автоматизации и оптимизации рутинных процессов, умный глобальный поиск информации и т.д.
Почему технологии искусственного интеллекта набирают популярность именно сейчас?
С середины XX века писатели-фантасты и режиссеры неустанно создают произведения на тему ИИ и роботов. Однако реальное применение высоких технологий стало возможно лишь недавно — 10-15 лет назад, этому способствовало несколько факторов:
- стали доступнее вычислительные ресурсы высокой мощности (производительности). Речь идет не только о самом наличии таких машин, но и о ценовой политике. А с развитием облачных технологий пропала необходимость размещать все локально — еще один пункт, на котором экономятся средства.
- накопились достаточные объемы информации для обучения ИИ. Во-первых, человечество стало активно использовать компьютеры в работе, что со временем позволило собрать необходимые данные в цифровом виде. Во-вторых, мы научились обрабатывать структурированную и неструктурированную информацию.
- компании опробовали и увидели эффект от применения технологий искусственного интеллекта —быстрое распознавание документов и дальнейшая обработка, выдача рекомендаций на основе анализа, сокращение трудоемкости ручных операций и моментальное выявление рисков.
- всеобщий курс крупных организаций на цифровую трансформацию, что подразумевает не только внедрение передовых технологий для усиления конкурентных преимуществ, но и смену подхода к привычным процессам в целом.
Применение искусственного интеллекта
Спрос на передовые технологии растет в каждой отрасли. Например, в здравоохранении нужны «умные» личные помощники, которые вовремя напомнят о приеме лекарств, проследят за физической активностью человека, а в перспективе помогут выбрать тактику лечения, в торговле ИИ помогает прогнозировать обороты товара, а в финансовых операциях — выявлять мошенничество.
Прикладных задач для программ искусственного интеллекта много, но все они базируются на нескольких ключевых свойствах:
- ИИ — программное решение, которое используется для автоматизации ручных задач человека, часто выполняемых и в большом объеме.
- программы искусственного интеллекта чаще всего работают вкупе с другими прикладными приложениями и заметно повышают их эффективность: например, голосовые помощники в смартфонах, боты в интернет-магазинах, автоматические обработчики документов у секретаря.
- прогрессивные алгоритмы обучения и постоянная адаптация: ИИ находит закономерности в больших объемах данных, поэтому способен давать рекомендации и прогнозировать показатели.
- объемы данных, которые может анализировать и использовать в работе ИИ, огромны. С появлением достаточно мощных (производительных) компьютеров стало возможно хранить и обрабатывать множество информации.
- высокая точность в решении задач, при этом точность возрастает с увеличением объема данных, доступных для анализа и обучения. Кроме того, машина не устает — ошибки, которые допускает человек в силу усталости, невнимательности, неправильных расчетов исключаются.
Ближе к реальности — ИИ в бизнес-процессах современного офиса
Крупные современные организации в большинстве своем прошли этап цифровизации основных деловых процессов — делопроизводство, управление совещаниями, работа с контрактами, обращениями граждан и организаций и т.п. Дальнейшее развитие проектов происходит в двух направлениях: первое — охват новых областей, таких как кадровое делопроизводство, управление командировками, второе — снижение трудоемкости выполнения ежедневных задач.
Снизить трудоемкость и избавить от рутины как раз помогает применение интеллектуальных сервисов, таких как Directum Ario.
1 минута
среднее время обработки одного письма
Делопроизводство. Исключается ручной перенос информации из поступившей корреспонденции в систему электронного документооборота (СЭД):
- документы подхватываются со сканера или электронной почты, а затем сортируются по комплектам
- сервисы Ario также распознают текст и извлекают необходимую информацию
- все экземпляры классифицируются и заносятся в СЭД с автоматическим заполнением карточек.
Умный поиск Directum Smart Search поможет быстро найти информацию, даже если не заданы точные критерии, а запрос введен в свободной форме и отражен лишь приблизительный смысл.
более 95%
точность определения счета и статьи затрат
Бухгалтерия. Упрощается обработка входящих комплектов, а корректность их заполнения проверяется автоматически:
- поступающие первичные учетные документы распознаются с помощью Ario и распределяются так, что бухгалтер получает их в виде готовых комплектов на проверку;
- программа искусственного интеллекта проверяет полноту комплекта, правильность указанных сумм, сопоставляем с заказом, спецификациями и номенклатурой. Максимально точно определяется счет и статья затрат.
В платежных документах система с применением ИИ определяет бухгалтерский счет и статью затрат по назначению платежа и контрагенту.
Также упрощается подготовка авансовых отчетов — документы создаются автоматически на основании электронных билетов и фотографий чеков. Сервисы Ario заполняют поля отчета и отправляют на согласование.
5 минут
обработка договора и выявление изменений
1-2 минуты
среднее время обработки обращения
Работа с обращениями. Сервисы Ario определяют поступающие запросы по содержанию и классифицируют обращения по типам, например, заявки в службу поддержки и обращения от юридических и физических лиц.
Регистрационные карточки заполняются автоматически, в т.ч. определяется ответственный. Регистратору остается проверить правильность заполнения.
более 92%
корректность извлечения данных из документов
Кадровые процессы. Сервисы Ario помогают распознавать личные документы (паспорт, справки, дипломы и т.п.), полученные со сканера или почты. Специалист HR-службы получает документы по кандидату с уже заполненными карточками в системе.
Вендоры, в том числе Directum предлагают не просто сервисы, а целый набор решений, чтобы закрывалась целая область задач. Более того, флагманский продукт компании — интеллектуальная система управления процессами и документами Directum RX.
Что мешает эффективному использованию ИИ-технологий?
Какими бы доступными ни были сегодня возможности программы искусственного интеллекта, остается крайне весомое препятствие на пути к раскрытию их полного потенциала. Как ни удивительно, главная трудность — сам человек, его доверие и глубина знаний.
Первое, с чем приходит сталкивать — недоверие к технологии. Пользователи зачастую не понимают, как все это работает, поэтому не могут до конца «довериться» машине и постоянно перепроверяют результаты. Так и должно быть на первых порах работы с новой технологией, но спустя полгода корректность действий ИИ не должна вызывать вопросы. Крайняя степень недоверия — откровенный саботаж использования решений или отказ предоставлять полные и актуальные данные для обучения ИИ.
Второе ограничение связано с компетенциями ИТ-специалистов, которые внедряют и сопровождают такие решения. Не секрет, что ИИ — это сложные технологии, трудоемкие в реализации.
Подводя итог, нужно сказать, что применение искусственного интеллекта — это уже иной подход к работе. Сотрудникам важно самим непрерывно учиться, осваивать технологии. То, что в новинку сегодня, завтра будет привычным делом и в конечном счете сэкономит ресурсы, позволит заняться задачами более высокого уровня — стратегии, разработка, творчество и т.п.
Поделитесь новостью
Планируете внедрять цифровые инструменты?
Узнайте, чем будут полезны решения Directum для вашей компании! Оставьте заявку, и мы свяжемся с вами в течение рабочего дня — определим ваши интересы и подготовим индивидуальную презентацию.
Источник: www.directum.ru