
Система управления базами данных (СУБД) – совокупность программных и лингвистических средств общего или специального назначения, обеспечивающих управление созданием и использованием баз данных [16].
Основные функции СУБД:
— управление данными во внешней памяти (на дисках);
— управление данными в оперативной памяти;
— журнализация изменений, резервное копирование и восстановление базы данных после сбоев;
— поддержка языков БД.
Обычно современная СУБД содержит следующие компоненты:
— ядро, которое отвечает за управление данными во внешней и оперативной памяти, и журнализацию,
— процессор языка базы данных, обеспечивающий оптимизацию запросов на извлечение и изменение данных и создание, как правило, машинно-независимого исполняемого внутреннего кода,
— подсистему поддержки времени исполнения, которая интерпретирует программы манипуляции данными, создающие пользовательский интерфейс с СУБД
— сервисные программы (внешние утилиты), обеспечивающие ряд дополнительных возможностей по обслуживанию информационной системы.
Системы управления базами данных
При выборе СУБД немаловажным критерием является стоимость программного обеспечения. В настоящее время на рынке представлены как коммерческие, так и свободные версии СУБД. Среди версий, которые распространяются свободно, необходимо выделить две распространенные СУБД: PostgreSQL и MySQL.
В компании уже установлена СУБД MySQL. По этой причине для реализации информационной подсистемы управления складом была выбрана система управления базой данных MySQL.
MySQL – свободная система управления базами данных, является собственностью компании Oracle Corporation, получившей её вместе с поглощённой Sun Microsystems, осуществляющей разработку и поддержку приложения. Распространяется под GNU General Public License или под собственной коммерческой лицензией.
Помимо этого разработчики создают функциональность по заказу лицензионных пользователей, именно благодаря такому заказу почти в самых ранних версиях появился механизм репликации. MySQL является решением для малых и средних приложений. Входит в состав серверов WAMP, LAMP и в портативные сборки серверов Денвер, XAMPP. Обычно MySQL используется в качестве сервера, к которому обращаются локальные или удалённые клиенты, однако в дистрибутив входит библиотека внутреннего сервера, позволяющая включать MySQL в автономные программы.
Гибкость СУБД обеспечивается поддержкой большого количества типов таблиц: пользователи могут выбрать как таблицы типа MyISAM, поддерживающие полнотекстовый поиск, так и таблицы InnoDB, поддерживающие транзакции на уровне отдельных записей. Более того, СУБД поставляется со специальным типом таблиц EXAMPLE, демонстрирующим принципы создания новых типов таблиц. Благодаря открытой архитектуре и GPL-лицензированию, в СУБД MySQL постоянно появляются новые типы таблиц.
MySQL имеет двойное лицензирование. Может распространяться в соответствии с условиями лицензии GPL. Однако по условиям GPL, если какая-либо программа включает исходные коды MySQL, то она тоже должна распространяться по лицензии GPL. Это может расходиться с планами разработчиков, не желающих открывать исходные тексты своих программ. Для таких случаев предусмотрена коммерческая лицензия, которая также обеспечивает качественную сервисную поддержку [20].
Система управления базами данных
Даталогическое проектирование информационной базы данных
Логическое (даталогическое) проектирование – создание схемы базы данных на основе конкретной модели данных, например, реляционной модели данных. Для реляционной модели данных даталогическая модель – набор схем отношений, обычно с указанием первичных ключей, а также «связей» между отношениями, представляющих собой внешние ключи.
Преобразование концептуальной модели в логическую модель как правило осуществляется по формальным правилам. Этот этап может быть в значительной степени автоматизирован.
На этапе логического проектирования учитывается специфика конкретной модели данных, но может не учитываться специфика конкретной СУБД и требования к нормализации [21].
Нормализация – это метод организации реляционной базы данных с целью сокращения избыточности. В ходе этого процесса неоптимальная таблица разбивается на две или более таблиц, между которыми создаются отношения. Нормализация является частью этапа проектирования и выполняется над существующими таблицами.
Нормализация позволяет в полной мере реализовать преимущества реляционной модели. Нормализация заставляет разработчика создавать больше таблиц, равномернее распределяя в них информацию, что приводит к снижению избыточности. Нормализация определяется в виде набора правил, известных как нормальные формы.
После своей статьи, посвященной реляционной алгебре, доктор Кодд в 1972 г. опубликовал работу под названием «Дальнейшая нормализация реляционной модели баз данных» («Further Normalization of the Data Base Relational Model»). В этом документе были описаны первые три нормальные формы. В последующих работах доктора Кодда и других авторов были определены три другие нормальные формы.
Каждая нормальная форма основана на предыдущей, поэтому, например, третья форма более желанна, чем вторая. Устранение избыточности не обязательно означает повышение производительности. Накладные расходы на выполнение операций объединения весьма значительны, поэтому разработчики иногда сознательно идут на нарушение правил нормализации. Это называется денормализацией.
В реляционной базе данных таблицы практически всегда по умолчанию находятся в первой нормальной форме. Проблемы возникают в ситуации, когда необходимо импортировать обычную файловую базу данных в MySQL. В такой базе данных отсутствуют какие бы то ни было отношения, поэтому в ней наверняка есть дублирующаяся информация.
Вторая нормальная форма требует, чтобы все столбцы зависели от полного первичного ключа, а не от его частей. Таблица нарушает данное правило, если первичный ключ является составным и подмножества его столбцов достаточно для идентификации записей. Во второй нормальной форме подразумевается использование составного первичного ключа.
Таблица, в которой первичным ключом является один столбец, автоматически считается имеющей вторую нормальную форму. Вторая нормальная форма устраняет столбцы, зависящие от части первичного ключа. Третья нормальная форма устраняет столбцы, которые зависят от столбца, не являющегося первичным ключом. Это называется транзитивной зависимостью и ведет к ненужному дублированию данных.
С учётом приведенных ранее выкладок, применимо к выбранной СУБД таблицы базы данных будут иметь вид (таблицы 3.2 – 3.10).
Таблица 3.2 – Структура таблицы «Товар»
| Наименование поля | Описание | Тип данных | Размер |
| Код | Счетчик | ||
| ID_класс | Класс товара (Сетевые устройства, комплектующие, расходные материалы) | Текстовый | 5 |
| ID_Тип | Тип товара внутри класса товара | Текстовый | 5 |
| Наименование | Модель оборудования, наименование товара | Текстовый | 20 |
| ID_Производитель | Фирма, являющаяся производителем товара | Текстовый | 5 |
| Стоимость | Цена покупки товара в соответствии с приходной накладной | Текстовый | 20 |
| ID_Сотрудник | Сотрудник, за которым закреплено оборудование или товар, при неиспользуемом оборудовании, оно закрепляется за сотрудником склада | Текстовый | 5 |
| ID_Документ | Номер приходной накладной при получении товара | Текстовый | 5 |
Таблица 3.3 – Структура таблицы «Документ»
| Наименование поля | Описание | Тип данных | Размер |
| Код | Счетчик | ||
| Номер_документа | Номер документа | Текстовый | 20 |
| Дата_составления | Дата документа в длинном формате даты (15 марта 2011г.) | Дата | 20 |
Таблица 3.4 – Структура таблицы «Пользователи»
| Наименование поля | Описание | Тип данных | Размер |
| Код | Счетчик | ||
| ID_Сотрудник | Указатель на сотрудника компании | Текстовый | 5 |
| Логин | Логин для входа пользователя в подсистему управления складом | Текстовый | 20 |
| Пароль | Пароль для входа пользователя в подсистему управления складом. Назначается пользователем с правами администратора | Текстовый | 20 |
| ID_Права_доступа | Статус пользователя при работе с программой (Пользователь, администратор) | Текстовый | 20 |
Таблица 3.5 – Структура таблицы «Поставщики»
| Наименование поля | Описание | Тип данных | Размер |
| Код | Счетчик | ||
| Наименование | Наименование фирмы или лица, выполняющего роль поставщика оборудования или иных товаров | Текстовый | 20 |
| ИНН | Идентификационный номер | Текстовый | 20 |
| Город | Город поставщика | Текстовый | 20 |
| Адрес | Адрес поставщика | Текстовый | 20 |
| Представитель | Представитель фирмы или лица, выполняющего роль поставщика | Текстовый | 20 |
| Телефон | Контактный телефон представитель фирмы или лица, выполняющего роль поставщика. Обычно отдел продаж фирмы поставщика или секретарь. | Текстовый | 20 |
| Почтовый адрес компании или представителя | Текстовый | 20 | |
| Описание | Прочие характеристики компании, род деятельности, заметки | Текстовый | 200 |
Таблица 3.6 – Структура таблицы «Сотрудники»
| Наименование поля | Описание | Тип данных | Размер |
| Код | Счетчик | ||
| Фамилия | Текстовый | 20 | |
| Имя | Текстовый | 20 | |
| Отчество | Текстовый | 20 | |
| ID_Должность | Занимаемая должность в соответствии со справочником должностей | Текстовый | 5 |
| Дата рождения | Дата рождения сотрудника в длинном формате даты (15 марта 2011г.) | Дата | 20 |
| Почтовый адрес | Текстовый | 50 |
Таблица 3.7 – Структура справочника «СП_Должности»
| Наименование поля | Тип данных | Размер |
| Код | Счетчик | |
| Должность | Текстовый | 20 |
Таблица 3.8 – Структура справочника «СП_Классы»
| Наименование поля | Тип данных | Размер |
| Код | Счетчик | |
| Класс | Текстовый | 20 |
Таблица 3.9 – Структура справочника «СП_Типы»
| Наименование поля | Тип данных | Размер |
| Код | Счетчик | |
| ID_Класс | Текстовый | 5 |
| Тип | Текстовый | 20 |
Таблица 3.10 – Структура справочника «СП_Производители»
| Наименование поля | Тип данных | Размер |
| Код | Счетчик | |
| Производитель | Текстовый | 20 |
Представленные таблицы находятся в третьей нормальной форме так как содержат первичный ключ, который однозначно определяет значения столбцов. Любой атрибут, не входящий в состав потенциального ключа, функционально полно зависит от каждого возможного ключа, в любом допустимом значении отношения каждый его кортеж содержит только одно значение для каждого из атрибутов. Опираясь на состав таблиц базы данных и связи между этими данными, можно построить датологическую модель проектируемой базы данных (рисунок 3.4).
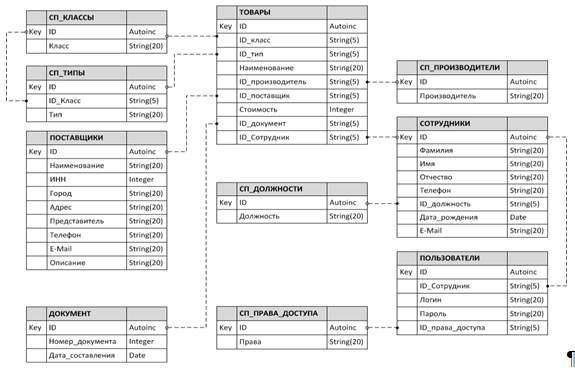
Рисунок 3.4 – Даталогическая модель базы данных
Дата добавления: 2018-10-25 ; просмотров: 661 ; Мы поможем в написании вашей работы!
Источник: studopedia.net
Тема 1. Техническое обеспечение асу.
в) описание алгоритма на языке, понятном исполнителю.
43. Технологии баз данных предназначены для …
а) обработки больших объемов структурированной информации;
б) обработки текстовой информации;
в) решения вычислительных задач и обеспечения экономической деятельности;
г) обработки реальных изображений и звука;
д) создания инструментальных программных средств информационных технологий.
Установите соответствие между учётной формой ВУ и технологической операцией.
| а) Уведомление на ремонт вагона | ВУ-23 |
| б) Сопроводительный листок на пересылку вагона в ремонт | ВУ-26 |
| в) Дефектная ведомость | ВУ-22 |
| г) Уведомление о выпуске вагона из ремонта | ВУ-36 |
| д) | ВУ-31 |
| е) | ДО-2 |
На каждый вагон, выявленный как неисправные в техническом отношении, оформляется уведомление формы
Система ДИСПАРК охватывает следующие уровни управления
Тема 5. Функциональные возможности системы ДИСПАРК.
Тема 1. Техническое обеспечение АСУ.
1. Для обмена данными между подсистемами в АСУВ используется сетевой протокол …
2. Право доступа пользователя к ЛВС ВЧД обеспечивает …
б) системный администратор
Источник: infopedia.su
Системы управления базами данных (СУБД)


БАЗЫ ДАННЫХ Системы управления базами данных (СУБД)
Системы управления базами данных (СУБД)
MS Access
Информационная система (ИС) — это система, реализующая автоматизированный сбор, обработку и манипулирование данными и включающая технические средства обработки данных, программное обеспечение и соответствующий персонал

Информационная система (ИС)
— это система, реализующая автоматизированный сбор, обработку и манипулирование данными и включающая технические средства обработки данных, программное обеспечение и соответствующий персонал
Современные ИС, основанные на концепции интеграции данных, характеризуются огромными объёмами хранимых данных, сложной организацией, необходимостью удовлетворять разнообразные потребности многочисленных пользователей
Цель любой ИС – обработка данных от объектах реального мира

Цель любой ИС – обработка данных от объектах реального мира
Основой ИС является
База данных — это (широком смысле слова) совокупность определенным образом организованной на какую-либо тему (в рамках некоторой предметной области) — это поименованная совокупность данных, отражающая…

— это (широком смысле слова) совокупность определенным образом организованной на какую-либо тему (в рамках некоторой предметной области)
— это поименованная совокупность данных, отражающая состояние объектов и их отношений в рассматриваемой предметной области
Под предметной областью принято понимать часть реального мира, подлежащего изучению для организации управления и в конечном счете автоматизации, например предприятие, ВУЗ и т.д.
БД книжного фонда библиотеки БД кадрового состава учреждения

БД книжного фонда библиотеки
БД кадрового состава учреждения
БД законодательных актов в области уголовного права
Информационные системы по продаже и резервированию авиа- и железнодорожных билетов
Электронные энциклопедии со сведениями, например: о муз. инструментах, шедеврах Эрмитажа, кулинарных рецептах, химических элементах и соединениях
Объект БД — это элемент предметной области, информацию о которой мы сохраняем

— это элемент предметной области, информацию о которой мы сохраняем
Пример № 2. Объекты могут быть:
реальными (человек, изделие, населенный пункт)
абстрактные (событие, счёт покупателя, изучаемый студентами курс) и т.д.
Структурирование данных — это введение соглашений о способах представления данных

— это введение соглашений о способах представления данных
Пример:
неструктурированные данные – это, например, данные записанные в текстовом файле (сплошным текстом);
структурирование данных
— таблицы
Классификация БД По технологии обработки

По технологии обработки
По способу доступа к данным
По технологии обработки (хранятся в памяти одной вычислительной системы) (состоят из нескольких пересекающихся или дублирующих частей, хранимых в различных
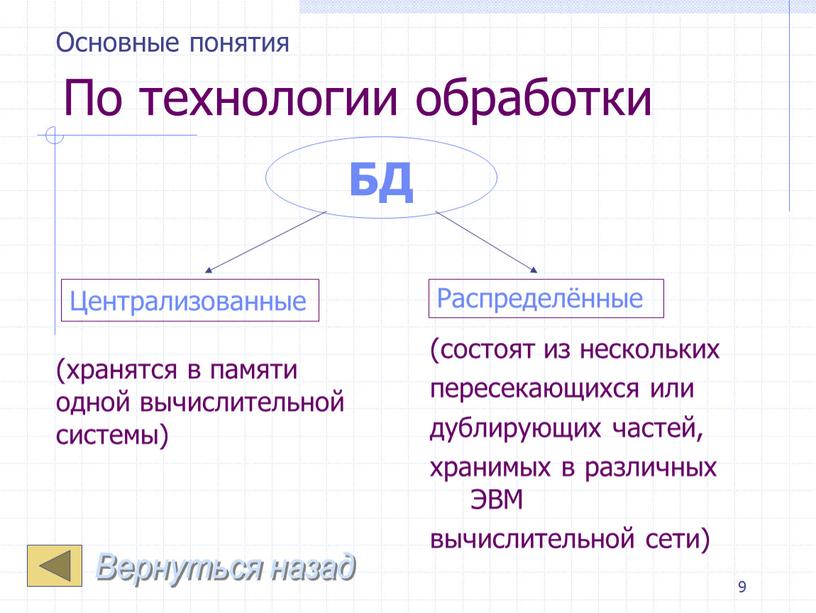
По технологии обработки
(хранятся в памяти одной вычислительной системы)
(состоят из нескольких
пересекающихся или
дублирующих частей,
хранимых в различных ЭВМ
вычислительной сети)
По способу доступа Одна из машин выделяется как центральная (сервер файлов)

По способу доступа
Одна из машин выделяется как центральная (сервер файлов). На ней хранится центральная БД. Все другие машины выполняют функцию рабочих станций, осуществляют доступ пользовательской системы к ЦБД. Обработка файлов БД осуществляется в основном на рабочих станциях.
Недостаток: при большой интенсивности доступа к одним и тем же данным производительность ИС падает. Пользователи могут создавать на рабочих станциях свои локальные БД, но используются такие БД монопольно.
Центральная машина (сервер БД) помимо хранения ЦБД выполняет обработку основного объёма информации. Рабочая станция (клиент) делает запрос на данные, после чего сервер данных производит поиск и извлечение этих данных. Извлеченные данные (но не файлы) транспортируются по сети от сервера к клиенту (используется специальный язык запросов SQL)
С локальным доступом
С сетевым (удаленным) доступом
[по своей архитектуре делятся на:]
Источник: znanio.ru