
Лексический, синтаксический, семантический анализ — процессы компиляции.
Содержание
Лексический, синтаксический, семантический анализ — процессы компиляции.
Компиляторы преобразуют операторы языка в машинные коды целиком для всей программы. В результате обработки исходного текста программы формируется объектный модуль, который затем может многократно выполняться после его загрузки в оперативную память.
Интерпретаторы осуществляют преобразование операторов в машинные коды во время выполнения программы. После запуска программы в оперативную память одновременно загружаются исходный текст программы, написанный на языке высокого уровня, и интерпретатор, который последовательно транслирует операторы программы и сразу же их выполняет.
В современных ЭВМ одни и те же языки программирования могут быть представлены как компилирующие или интерпретирующие системы программирования.
Интерпретирующие системы программирования эффективны на этапе разработки программ, так как минимизируют время на отладку. Применение режима интерпретации для многократного выполнения отлаженных программ нецелесообразно, так как интерпретатор занимает дополнительный объем оперативной памяти, а также из-за трансляции замедляется выполнение программы.
Фундамент программирования. Урок 3. Ошибки в программировании
Компилирующие СП эффективны при регулярной эксплуатации программ, так как имеется уже готовый к выполнению объектный модуль, что экономит время, затрачиваемое на трансляцию, и место в оперативной памяти. Разработка и отладка программ с использованием компилятора связаны с дополнительными временными затратами на трансляцию всего текста при определении ошибки.
Компиляторы обычно несколько проще в реализации, чем интерпретаторы, кроме того, не каждый язык программирования допускает построение простого интерпретатора. Однако интерпретаторы имеют существенное преимущество перед компиляторами, которое долгое время не принималось во внимание: откомпилированный код всегда привязан к архитектуре вычислительной системы, на которую он ориентирован, в то время как исходный текст программы непосредственно связан только с семантикой языка программирования, которую проще стандартизировать.
В настоящее время с развитием глобальных вычислительных сетей и распространением всемирной сети Интернет вопрос о переносимости программ и их независимости от аппаратной платформы приобретает все большую актуальность. Поскольку в состав сети могут входить ЭВМ различной архитектуры, то требование единообразного выполнения текста исходной программы на каждой из этих ЭВМ становится определяющим. Язык описания гипертекста HTML (Hypertext Markup language), на основе которого функционирует сейчас практически вся структура сети Интернет, является интерпретируемым языком. Трансляторы языков Java и JavaScript сочетают в себе функции компиляции и интерпретации: текст исходной программы компилируется в некоторый промежуточный двоичный код, не зависящий от архитектуры вычислительной системы; этот код передается по сети и выполняется в режиме интерпретации на принимающей стороне.
Уроки С++ / Урок #8 / Синтаксические и семантические ошибки
Обобщенная структура компилятора и основные фазы процесса компиляции:
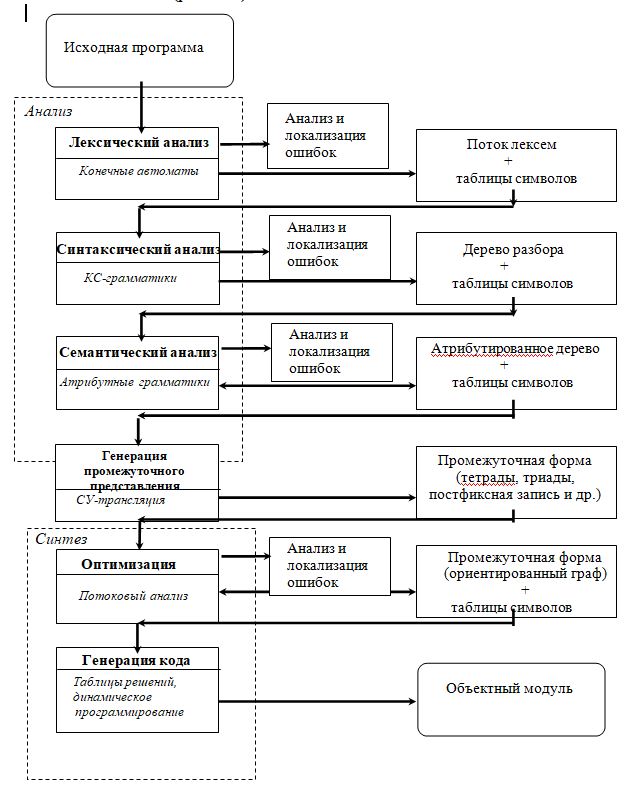
Лексический анализ
Лексический анализ (ЛА) — это первый этап процесса трансляции. Основная задача лексического анализа – разбить входной текст, состоящий из последовательности символов алфавита, на минимально значимые части языка, называемые лексемами. Лексемами естественных языков являются слова. В языках программирования встречаются лексемы различных типов, состав которых определяется синтаксисом конкретного языка программирования.
Лексический анализ разбивает текст программы на указанные элементы. Особенность любой лексики — ее элементы представляют собой регулярные линейные последовательности символов. Например, идентификатор — это произвольная последовательность букв, цифр и символа «_», начинающаяся с буквы или «_». Лексика ЯП анализируется и интерпретируется на фазе лексического анализа при трансляции.
На фазе лексического анализа входная программа, представляющая собой поток литер, разбивается на лексемы – слова в соответствии с определениями языка. Основными формализмами, лежащим в основе реализации лексических анализаторов, являются конечные автоматы и регулярные выражения.
Лексический анализатор может работать в двух основных режимах: либо как подпрограмма, вызываемая синтаксическим анализатором для получения очередной лексемы, либо как полный проход, результатом которого является файл лексем.
В процессе выделения лексем лексический анализатор может как самостоятельно строить таблицы объектов (идентификаторов, строк, чисел и т.д.), так и выдавать значения для каждой лексемы при очередном к нему обращении. В этом случае таблицы объектов строятся в последующих фазах (например, в процессе синтаксического анализа).
На этапе лексического анализа обнаруживаются некоторые (простейшие) ошибки (недопустимые символы, неправильная запись чисел, идентификаторов и др.).
Теоретически лексический анализатор не является обязательной частью транслятора, так как все его функции могут выполняться синтаксическим анализатором. На практике существует ряд причин, по которым лексический анализатор включают в состав почти всех компиляторов как самостоятельный элемент:
- замена в программе идентификаторов, констант, знаков операций, ограничителей и служебных слов лексемами делает представление программы более удобным для дальнейшей обработки;
- лексический анализ уменьшает длину программы, устраняя из ее исходного представления несущественные пробелы и комментарии;
- для решения задач лексического анализа возможно применять простую и эффективную технику анализа, в то время как для синтаксического разбора используются достаточно сложные алгоритмы;
- при изменении версии входного языка достаточно будет перестроить относительно простой лексический анализатор, не затрагивая сложный по конструкции синтаксический анализатор.
Синтаксический анализ
Синтаксический анализ — проверка правильности конструкций, использованных программистом при подготовке текста.
Синтаксический анализатор – это часть компилятора, которая отвечает за выявление и проверку синтаксических конструкций входного языка. Синтаксический анализатор получает строку токенов от лексического анализатора, и проверяет, может ли эта строка токенов порождаться грамматикой входного языка.Ещё одной функцией синтаксического анализатора является генерация сообщений обо всех выявленных ошибках, причём достаточно внятных и полных, а кроме того, синтаксический анализатор должен уметь обрабатывать обычные, часто встречающиеся ошибки и продолжать работу с оставшейся частью программы. В случае корректной программы синтаксический анализатор строит дерево разбора и передаёт его следующей части компилятора для дальнейшей обработки.
Во время выполнения этой фазы используются лексемы, полученные от лексического анализатора, для создания древовидного промежуточного представления программы, которое описывает грамматическую структуру потока лексем. Типичным промежуточным представлением является синтаксическое дерево, в котором каждый внутренний узел представляет операцию, а дочерние узлы – аргументы этой операции.
На этапе синтаксического анализа нужно установить, имеет ли цепочка лексем структуру, заданную синтаксисом языка, и зафиксировать эту структуру. Следовательно, снова надо решать задачу разбора: дана цепочка лексем, и надо определить, выводима ли она в грамматике, определяющей синтаксис языка. Однако структура таких конструкций как выражение, описание, оператор и т.п. более сложная, чем структура идентификаторов и чисел. Поэтому для описания синтаксиса языков программирования нужны более мощные грамматики, чем регулярные. Обычно для этого используют укорачивающие контекстно-свободные грамматики (УКС-грамматики).
Семантический анализ
Семантический анализ — выявление несоответствий типов и структур переменных, функций и процедур. Семантический анализ — это проверка смысловой правильности конструкции. Например, если мы в выражении используем переменную, то она должна быть определена ранее по тексту программы, а из этого определения может быть получен ее тип. Исходя из типа переменной, можно говорить о допустимости операции с данной переменной. Семантические ошибки возникают при недопустимом использовании операций, массивов, функций, операторов и пр.
Семантический анализатор выполняет следующие основные действия:
- проверку соблюдения во входной программе семантических соглашений входного языка;
- дополнение внутреннего представления программы в компиляторе операторами и действиями, неявно предусмотренными семантикой входного языка;
- проверку элементарных семантических (смысловых) норм языков программирования, напрямую не связанных со входным языком.
Семантический анализатор использует синтаксическое дерево и информацию из таблицы идентификаторов для проверки входной программы на семантическую согласованность с определением языка программирования. Он также собирает информацию о типах и сохраняет её в синтаксическом дереве или в таблице идентификаторов для последующего использования в процессе генерации промежуточного кода.
После синтаксического и семантического анализа исходной программы компиляторы генерируют низкоуровневое промежуточное представление входной программы, которое можно рассматривать как программу для абстрактной вычислительной машины. Такое промежуточное представление должно обладать двумя важными свойствами: оно должно легко генерироваться и легко транслироваться в целевой машинный язык.
- Голицына О. Л. Языки программирования : учебное пособие / О. Л. Голицына, Т. Л. Партыка, И. И. Попов. — 2-е изд., перераб. и доп. — М. : ФОРУМ, 2010. — 400 с. : ил.
- Серебряков В. А. Основы конструирования компиляторов / В. А. Серебряков, М. П. Галочкин. — 192 с.
- Основы построения трансляторов : курс лекций / СГАУ им. академика М.Ф. Решетнева. — Красноярск, 2010. — 101 с.
- Молдованова О.В. Языки программирования и методы трансляции: Учебное пособие / СибГУТИ, — Новосибирск, 2012. – 134 с.
- Системное программное обеспечение: Учебник для вузов / А. Ю. Молчанов. — СПб.: Питер, 2003. — 396 с.

16.04.2022, 1646 просмотров.
Источник: myfilology.ru
Гайд Перевод Learncpp.com: раздел 3.1 // Синтаксические и семантические ошибки. На русском.
Было решено сделать небольшой скачок до интересной темы: Отладка, которая понадобится начинающим и не очень.
Ошибки ПО распространены. Их легко сделать, и их трудно найти. В этой главе мы рассмотрим темы, связанные с поиском и удалением ошибок в наших программах на языке C++, в том числе научимся использовать встроенный отладчик, который является частью нашей IDE.
Хотя инструменты и методы отладки не являются частью стандарта C++, умение находить и удалять ошибки в программах, которые вы пишете, является чрезвычайно важной частью успешного программиста. Поэтому мы потратим немного времени на освещение таких тем, чтобы по мере усложнения программ, которые вы пишете, ваша способность диагностировать и устранять проблемы развивалась с той же скоростью.
Если у вас есть опыт отладки программ на другом скомпилированном языке программирования, многое из этого будет Вам знакомо.
Синтаксические и семантические ошибки
Программирование может быть сложным, а C++ — это несколько причудливый язык. Сложите эти два понятия вместе, и вы обнаружите множество способов совершать ошибки. Ошибки обычно делятся на две категории: синтаксические ошибки и семантические ошибки (логические ошибки).
Синтаксическая ошибка возникает, когда вы пишете стейтмент, который не является допустимым в соответствии с грамматикой языка C++. Это включает в себя такие ошибки, как пропущенные точки с запятой, использование необъявленных переменных, несоответствующие скобки или фигурные скобки и т. д. Например, следующая программа содержит довольно много синтаксических ошибок:
#include int main() < std::cout < «Hi there»; < < x; // недопустимый оператор (<), лишняя точка с запятой, необъявленная переменная (x) return 0 // отсутствует точка с запятой в конце стейтмента >
К счастью, компилятор обычно ловит синтаксические ошибки и генерирует предупреждения или ошибки, поэтому вы легко определяете и устраняете проблему. Тогда это просто вопрос времени, пока вы не избавитесь от всех ошибок.
Как только ваша программа компилируется правильно, заставить ее действительно выдавать желаемый результат(ы) может быть непросто. Семантическая ошибка возникает, когда стейтмент синтаксически корректен, но не выполняет то, что задумал программист.
Иногда это приведет к сбою вашей программы, например, в случае деления на ноль:
#include int main() < int a = 10; int b = 0; std::cout
Источник: yougame.biz
Причины и типы ошибок
В общем случае ошибки могут возникать на любом этапе разработки программы, причина ошибок может быть связана с недопониманием сути задачи, недостатками проектирования алгоритма, неправильным использованием языковых средств. При выполнении программы ошибки разного типа проявляют себя различным образом, и их принято подразделять на следующие группы:
Синтаксические ошибки– это ошибки, проявляющиеся на этапе компиляции программы и возникающие в связи с нарушением синтаксических правил написания предложений используемого языка программирования (к таким ошибкам относятся пропущенные точки с запятой, ссылки на неописанные переменные, присваивание переменной значений неверного типа и т. д.). Если компилятор встречает в тексте программы оператор или описание, которые он не может интерпретировать, то он позиционирует курсор на место обнаруженной ошибки и в строку статуса выводит сообщение, содержащее номер ошибки и ее краткое описание.
Семантические ошибки– это ошибки, проявляющиеся на этапе выполнения программы при ее попытке вычислить недопустимые значения параметров или выполнить недопустимые действия. Причина возникновения ошибок данного типа связана с нарушением семантических правил написания программ (примером являются ситуации попытки открыть несуществующий файл или выполнить деление на нуль).
Если программа обнаруживает ошибку такого типа, то она завершает свое выполнение и выводит соответствующее сообщение в окне Build, содержащее номер строки с ошибкой и ее возможный характер. Список сообщений можно просмотреть с помощью команды меню View/Debug Windows/EventLog. При выполнении программы из среды Delphi автоматически выбирается соответствующий исходный файл и в нем находится местоположение ошибки. Если же программа выполнялась вне среды и в ней появилась ошибка данного типа, то необходимо запустить среду и найти вызвавший ошибку оператор.
Логические (смысловые) ошибки– самые сложные и трудноуловимые, связанные с неправильным применением тех или иных алгоритмических конструкций. Эти ошибки при выполнении программы могут проявиться явно (выдано сообщение об ошибке, нет результата или выдан неверный результат, программа «зацикливается»), но чаще они проявляют себя только при определенных сочетаниях параметров или вообще не вызывают нарушения работы программы, которая в этом случае выдает правдоподобные, но неверные результаты.
Ошибки первого типа легко выявляются самим компилятором. Обычно устранение синтаксических ошибок не вызывает особых трудностей. Более сложно выявить ошибки второго и особенно третьего типа. Для обнаружения и устранения ошибок второго и третьего типа обычно применяют специальные способы и средства отладки программ.
Выявлению ошибок второго типа часто помогает использование контролирующих режимов компиляции с проверкой допустимых значений тех или иных параметров (границ индексов элементов массивов, значений переменных типа диапазона, ситуаций переполнения, ошибок ввода-вывода). Устанавливаются эти режимы с помощью ключей компилятора, задаваемых либо в программе, либо в меню Project/Options/Compiler среды Delphi, либо в меню Options/Compiler Турбо-среды.
Дата добавления: 2016-05-31 ; просмотров: 2332 ; ЗАКАЗАТЬ НАПИСАНИЕ РАБОТЫ
Источник: poznayka.org