
Задали написать программу на шифр Виженера. Подскажите, как сделать, чтобы он выводил зашифрованное слово?
Нашел способ как сложить массив, но нужно чтобы и конечное значение тоже складывалось. Т.е если слово False, а ключ true, то сложение массивов идёт с 0-3, а индекс четвёртого элемента «e» из первого массива складывается с 0.
Что делать?
import string alphabet = a = input(‘Введите текст: ‘) b = input(‘Введите ключ: ‘) k = «» lst_a = [] lst_b = [] for i in a: lst_a.append(alphabet.get(i)) print(lst_a) for i in b: lst_b.append(alphabet.get(i)) print(lst_b)
Отслеживать
33k 2 2 золотых знака 29 29 серебряных знаков 59 59 бронзовых знаков
задан 16 окт 2018 в 22:44
69 1 1 золотой знак 2 2 серебряных знака 11 11 бронзовых знаков
В чем проблема-то? Если нужно сложить, то складывай.
17 окт 2018 в 8:22
Проблема в том , что если ключ: 4 буквы а само слово 5 , то сложение идёт элементов с 0-го до 3-го , а 4 символ как был так и останется: Например: [17,4,5,6,7] + [3,6,5,4] = [20,10, 10, 10, 7]
программирование шифра виженера на C++
17 окт 2018 в 9:07
Я не вижу в коде вообще никакого сложения.
Источник: ru.stackoverflow.com
Шифр Виженера на C#

Здравствуйте, дорогие читатели блога Code-Enjoy.ru! До конца сентября хотелось написать ещё какую-нибудь жирную статью. И конечно же на языке программирования C# !
Сегодня продолжим изучать алгоритмы шифрования данных. И самый простой, примитивный алгоритм — это шифр Цезаря, который я уже рассматривал на страницах своего сайта. Пусть нам нужно зашифровать какое-нибудь текстовое сообщение. Суть метода Цезаря заключается в том, что мы каждой букве назначаем другую букву из алфавита. Например букве «а» -> «г», букве «б»-> «д» и т.д.
Соответствие букв идёт по кольцу, т.е. букве «э» будет соответствовать буква «а».
Таким образом, слово «привет» будет закодировано в «тулезх». Сдвиг букв может быть на любое количество символов. Но данный способ является очень не надёжным. На этом, как известно, и погорел Цезарь !
Во-первых можно перебрать все 32 варианта, чтобы узнать на какое количество символов смещены символы. Во-вторых, известно, что буква «о» встречается чаще, чем другие буквы (9.28%). Из этого следует, что если мы имеем достаточный объем зашифрованного текста, мы можем вычислить часто встречающиеся символы, а затем вычислить остальные.
Более надёжным алгоритмом является шифр Виженера. Идея его заключается в том, что мы даже одной и той же букве можем поставить в соответствие разные буквы. Величина смещения каждой буквы в конкретной позиции определяется с помощью ключа.

В данном случае мы шифруем строку » тестовая строка » с помощью ключа » книга «. Первая идёт буква «т» под ней находится буква ключа «к». Буква «к» имеет номер 11 в алфавите, если считать с нуля. Значит, мы должны сместить букву «т» на 11 позиций. Затем берём следующую букву «е». Под ней находится буква ключа «н». Буква «н» имеет номер 14.
Значит мы должны сместить букву «е» на 14 позиций в алфавите по кольцу и т.д. Ключ повторяется сколько раз, сколько нужно и записывается под сообщением.
Таким образом, шифр Виженера является более защищённым, чем шифр Цезаря, за счет того, что мы всегда смещаем буквы на разное количество символов.
Задача: Написать программу, которая считывает сообщение из файла 1.txt, шифрует это сообщение шифром Виженера (ключ считывается из файла 2.txt) и записывает результат в файл 3.txt. Задачу применить только к буквам русского алфавита нижнего регистра. Если встретятся символы не из русского алфавита, то их оставить без изменений.
Решение: Напишем программу на языке C# (Си шарп) .
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks; using System.IO; namespace ConsoleApp8 < class Program < static void Main(string[] args) < // Cчитываем из файла сообщения string m = File.ReadAllText(«1.txt», Encoding.GetEncoding(1251)); string k = File.ReadAllText(«2.txt», Encoding.GetEncoding(1251)); int nomer; // Номер в алфавите int d; // Смещение string s; //Результат int j,f; // Переменная для циклов int t=0; // Преременная для нумерации символов ключа. char[] massage = m.ToCharArray(); // Превращаем сообщение в массив символов.
char[] key = k.ToCharArray(); // Превращаем ключ в массив символов. char[] alfavit = < ‘а’, ‘б’, ‘в’, ‘г’, ‘д’, ‘е’, ‘ё’, ‘ж’, ‘з’, ‘и’, ‘й’, ‘к’, ‘л’, ‘м’, ‘н’, ‘о’, ‘п’, ‘р’, ‘с’, ‘т’, ‘у’, ‘ф’, ‘х’, ‘ц’, ‘ч’, ‘ш’, ‘щ’, ‘ъ’, ‘ы’, ‘ь’, ‘э’, ‘ю’, ‘я’>; // Перебираем каждый символ сообщения for (int i = 0; i < massage.Length; i++) < // Ищем индекс буквы for (j = 0; j < alfavit.Length; j++) < if (massage[i] == alfavit[j]) < break; > > if (j != 33) // Если j равно 33, значит символ не из алфавита < nomer = j; // Индекс буквы // Ключ закончился — начинаем сначала. if ( t > key.Length — 1) < t = 0; >// Ищем индекс буквы ключа for (f = 0; f < alfavit.Length; f++) < if (key[t] == alfavit[f]) < break; > > t++; if (f != 33) // Если f равно 33, значит символ не из алфавита < d = nomer + f; >else < d = nomer; >// Проверяем, чтобы не вышли за пределы алфавита if (d > 32) < d = d — 33; >massage[i] = alfavit[d]; // Меняем букву > > s = new string(massage); // Собираем символы обратно в строку. File.WriteAllText(«3.txt», s); // Записываем результат в файл. > > >
В файле 1.txt было сообщение:
привет это тестовая строка
Ключ в файле 2.txt:
программирование
Результат в файле 3.txt:
ябчехт йяч гуутькео вбуякм
Источник: code-enjoy.ru
Шифр Виженера. Разбор алгоритма на Python
Недавно захотелось вспомнить свое «шпионское» детство и хотя бы базово изучить разные методы шифрования. И первым выбор пал на шифр Виженера. Сам по себе он не является чрезвычайно сложным, но достаточно долго считался криптоустойчивым. Века эдак с XV и к самому XIX, пока некто Казиски полностью не взломал шифр.
Однако ограничим цитирование Википедии только описанием самого алгоритма.
Метод является усовершенствованным шифром Цезаря, где буквы смещались на определенную позицию.
Шифр Виженера состоит из последовательности нескольких шифров Цезаря с различными значениями сдвига.
Допустим у нас есть некий алфавит, где каждой букве соответствуют цифры:

Тогда если буквы a-z соответствуют числам 0-25, то шифрование Виженера можно записать в виде формулы:

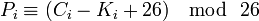
По сути нам больше ничего и не нужно кроме двух этих формул и мы можем приступить к реализации.
Тут хочу сказать, что я постарался реализовать алгоритм не проще и изящнее, а наиболее понятно и развернуто.
Собственно приступим-с.
Закодируем слова ‘Hello world’ с хитрым ключом ‘key’.
Сначала необходимо создать словарь символов, которые будут участвовать в шифровании:
def form_dict(): d = <> iter = 0 for i in range(0,127): d[iter] = chr(i) iter = iter +1 return d
Дальше необходимо сопоставить буквы в нашем слове с буквами в словаре и присвоить им соответствующие числовые индексы
def encode_val(word): list_code = [] lent = len(word) d = form_dict() for w in range(lent): for value in d: if word[w] == d[value]: list_code.append(value) return list_code
И так мы закодировали наше слово и ключ и получили 2 списка индексов:
Value= [72, 101, 108, 108, 111, 32, 119, 111, 114, 108, 100]
Key = [107, 101, 121]
Дальше мы сопоставляем индексы ключа с индексами нашего слова функцией full_encode():
def comparator(value, key): len_key = len(key) dic = <> iter = 0 full = 0 for i in value: dic[full] = [i,key[iter]] full = full + 1 iter = iter +1 if (iter >= len_key): iter = 0 return dic def full_encode(value, key): dic = comparator(value, key) print ‘Compare full encode’, dic lis = [] d = form_dict() for v in dic: go = (dic[v][0]+dic[v][1]) % len(d) lis.append(go) return lis def decode_val(list_in): list_code = [] lent = len(list_in) d = form_dict() for i in range(lent): for value in d: if list_in[i] == value: list_code.append(d[value]) return list_code
Получаем наш индексы шифра и переводим их в строку функцией decode_val():
Индексы: [52, 75, 102, 88, 85, 26, 99, 85, 108, 88, 74]
Получаем закодированное суперсекретное послание: 4KfXUcUlXJ
Раскодировать же все это можно с помощью функции full_decode(), первым аргументом которой есть список числовых индексов шифра, а вторым — список индексов ключа:
def full_decode(value, key): dic = comparator(value, key) print ‘Deshifre=’, dic d = form_dict() lis =[] for v in dic: go = (dic[v][0]-dic[v][1]+len(d)) % len(d) lis.append(go) return lis
Все так же получаем индексы шифра и переводим их в строку уже знакомой функцией decode_val():
[72, 101, 108, 108, 111, 32, 119, 111, 114, 108, 100]
И вуаля! Наше зашифрованное слово: Hello world
Ну и главный вызов
if __name__ == «__main__»: word = ‘Hello world’ key = ‘key’ print ‘Слово: ‘+ word print ‘Ключ: ‘+ key key_encoded = encode_val(key) value_encoded = encode_val(word) print ‘Value= ‘,value_encoded print ‘Key= ‘, key_encoded shifre = full_encode(value_encoded, key_encoded) print ‘Шифр=’, ».join(decode_val(shifre)) decoded = full_decode(shifre, key_encoded) print ‘Decode list=’, decoded decode_word_list = decode_val(decoded) print ‘Word=’,».join(decode_word_list)
В статье постарался все описать так чтобы было максимально понятно даже для самого начинающего в Python. Хотя данный алгоритм шифрования больше не является на 100% надежным, однако он хорошо подойдет для тех кто стал на путь изучения более серьезных вещей, например того же RSA.
Источник: habr.com