
С развитием современных технологий в последние десятилетия 20 века произошла и модернизация доступа к печатному и рукописному тексту. Написанный текст был постепенно заменен печатным, который имеет по сравнению с текстом «на бумаге’ ряд неоспоримых преимуществ (простое редактирование и форматирование)
С распознаванием сканированного текста связано такое понятие, как OCR. OCR является аббревиатурой от английского «Optical Character Recognition» — оптическое распознавание символов. Речь может идти как о механическом, так и об электронном действии. В большинстве случаев, происходит сканирование документа, который затем анализируется компьютерной программой, которая производит распознавание сканированного текста, отдельных его символов и слов.
OCR– технология распознавания сканированного текста
Лучшие программы для распознавания текста. Рейтинг OCR.
Технология OCR нашла применение во многих сферах деятельности
Цель и смысл распознавания с помощью OCR сканированного текста заключается в быстрой и дешевой передаче печатного или рукописного содержимого в электронный файл. Важно отметить, что машинное распознавание текста в 20-25 раз быстрее, чем ручное переписывание. OCR можно также использовать для переноса таблиц с номерами в компьютер, что может стать очень эффективным инструментом в любой профессии.
OCR-приложение не может сканировать, однако, может распознавать символы и изображения сканированного текста, создавать обычный текст, который можно в дальнейшем обрабатывать. Оригинал документа на бумаге загружается с помощью сканера. Программа для оптического распознавания сканированного текста позволяет определить отдельные блоки (графики, текст, абзацы и так далее), с последующим распознаванием слов и букв.
Довольно часто случается так, что не все символы получается определить. Система OCR для распознавания сканированного текста использует языковые базы данных для сравнивания сканируемых слов. В случае сходства со словом в словаре, программа может исправить или добавить недостающие символы. В случае, если OCR не в состоянии распознать один символ в слове, это не значит, что слово будет помечено как неопознанное. Если это просто неизвестное слово, то оно вносится в словарь с дополнительной корректировкой.
Новые OCR-программы для распознавания сканированного текста оснащены дополнительными функциями для проверки орфографии (как в MS Word), что позволяет улучшить процесс распознавания
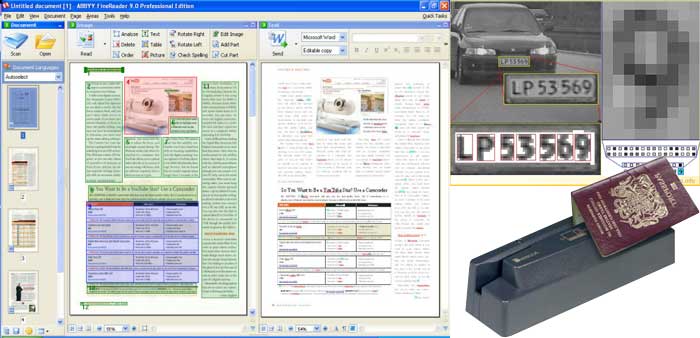
Технология распознавания OCR, как процесс оцифровки, используется как для обычных задач (проверка паспортов), так и при проверке регистрационных знаков транспортных средств. В основном, используется при оцифровке книг и текстов, например, для обеспечения возможности поиска или редактирования. Цифровой контент можно впоследствии редактировать, или же озвучить с помощью преобразования текста в голос. OCR часто используется для распознавания капчи (CAPCHA).
CAPTCHA, как правило, тип цифровой защиты форм, чтобы через них не передавались автоматически генерируемые данные. CAPTCHA представляет собой в основном рисунок, который отображает множество алфавитно-цифровых символов, которые пользователь должен ввести вручную. Многие CAPTCHA требуют от пользователя не только простого ввода данных с картинки, но и выполнения математических операция или манипуляций с объектами.
Современные OCR приложения распознавания сканированного текста могут распознавать даже рукописный текст – это актуально для сенсорных устройств, которые позволяют писать текст с помощью специального пера, а не клавиатуры.
Сам процесс распознавания сканированного текста проходит в три стадии: pre-processing (предварительная), само OCR распознавание, post-processing (последующая обработка).
При предварительной обработке целью является подготовить сканированный документ до наилучшего состояния – поворот, очистка от нежелательных точек и др. – так, чтобы последующий процесс распознавания текста был как можно более точным.
В ходе последующей обработки (post-processingu) текст проверяется согласно словарю для данного языка; автоматически, или при помощи пользователя, исправляются ошибки и неправильно распознанные символы.
Краткая история OCR распознавания текста

Вверху — шрифт OCR-A, внизу — OCR-B
Разработка OCR началась около 30 лет назад, тем не менее, эта технология распознавания текста достаточно неизвестная и мало распространенная. В гуманитарных областях, но и точных наук, в большинстве педагогических институтов, практически не используется. В самом начале технология оптического распознавания сканированного текста была связана с двумя крупными компаниями American Bankers Association и Financial Services Idustry, которые стремились к быстрой и качественной обработке финансовых документов, чеков, ценных бумаг. OCR технология была отличным решением, с течением времени, однако, была заменена на более динамичную технику MICR (Magnetic Ink Character Recognition).
В 1966 году в США произошла стандартизация так называемого шрифта OCR-A, который был первым шрифтом, позволяющим машинное чтение. Формы этого шрифта были упрощены, чтобы было само чтение как можно более точным, но шрифт не очень хорошо читается человеческим глазом. Шрифт OCR-A нашел применение в крупных банках. В Европе возникает вскоре после этого (1968) стандартный шрифт OCR-B и его автором был Адриан Фрутигер. Этот стандарт хуже читается машиной, но обеспечивает лучшую читаемость невооруженным глазом.
Первые OCR инструменты распознавания текста были очень медленными, и не давали требуемой точности. В основном, они ограничивались распознаванием специальных шрифтов OCR-A и OCR-B, со временем, однако, произошел их огромный бум. В 90-х годах произошло улучшение этой технологии. Увеличение производительности OCR значительно снизило цены на сканеры, технология стала легко доступной.
OCR программы и онлайн сервисы для распознавания текста

Для OCR распознавания сканированного текста можно использовать несколько различных инструментов. Вы можете воспользоваться как интернет приложениями, так и полноценными программами.
За качество надо платить. Попробовать trial-версии платных OCR программ для распознавания текста уже не так просто, как когда-то — их производители уже дали свой ответ на высокий уровень пиратства своего программного обеспечения выходом модели 30-дневных версий своего продукта, которые выполняют свою работу с ограниченными возможностями. К ним относятся два из лидеров на OCR рынке: OmniPage с поддержкой 123 языков, и Readiris с поддержкой ста двадцати языковых наборов. Одним из немногих приложений, которые в последней версии вы можете попробовать на собственной шкуре, ABBYY Fine Reader.
- FreeOCR . Хотя есть много онлайн инструментов для OCR распознавания текста, лучшим решением всегда остаются прикладные программы. Как вариант, можно попробовать воспользоваться бесплатным приложением FreeOCR. Оно не только приносит полновесные варианты распознавания, сохраняя структуру текста, но и поддерживает широкий спектр входных и выходных форматов.
- TopOCR – OCR программа распознавания текста из фотографий и других документов. Программа, которая может отлично распознавать текст с картинки или фотографии, и конвертировать его в читаемый вид. В результате текст можно конвертировать в другие форматы и редактировать. Текст можно конвертировать в форматы TXT, PDF, RTF и HTML.
- ABBYY FineReader . FineReader представляет собой настоящего профессионала и один из очень немногих действительно применимых решений при передаче фотографий, изображений или сканируемого текста. Его сила основана на действительно вдумчивой системе, которая стоит на трех основных столпах. OCR программа сначала разбивает изображение на области, в соответствии узнаваемых структур, те в свою очередь подразделяются на буквы и слова. После того, как текст разбивается на буквы, происходит их распознавание и сравнение целых слов со словарем. Затем выбирается наиболее подходящее решение. Еще один столп говорит о целесообразности, когда каждый текст имеет свой контекст, и на него нужно тоже обратить внимание. Последним и очень важным элементом является адаптация – OCR программа для распознавания текста должна уметь учиться с собственных действий.
Если вы не хотите устанавливать на компьютере программы, то можете использовать онлайн распознавание OCR.
OnlineOCR ( www.onlineocr.net ). Вероятно, лучший онлайн OCR конвертер, который вы можете встретить (хотя для раскрытия полного спектра функций вам необходимо бесплатно зарегистрироваться, иначе, вы будете ограничены количеством передаваемых документов, их размером и форматом). OnlineOCR поддерживает 32 языка. Сервис обладает отличной точностью распознавания текста и сохранения структуры документа.
NewOCR ( www.newocr.com ). NewOCR поддерживает 29 языков и анализ структуры текста. Истинное сохранение структуры, однако, не ждите, единственным результатом преобразования является только текст непосредственно в приложении, возможность прямого сохранения в DOC или RTF отсутствует – текст придется копировать вручную. В отличие от OnlineOCR, не нужно регистрироваться, ограничение на размер изображений установлено до 5 МБ. Фундаментальная проблема, однако, возникает при оценке точности транскрипции, тут онлайн распознавание OCR от NewOCR немного хромает.
Free OCR ( www.free-ocr.com ). Другим бесплатным и доступным онлайн OCR сервисом для распознавания текста является Free OCR. Позволяет конвертировать изображения до 2 МБ и одностраничные PDF, максимально 10 в час. Поддерживает 29 языков, наборов, без регистрации и приносит несравненно более высокую точность, чем предыдущий NewOCR. Структура текста, однако, также не сохраняется и позволяет экспортировать только чистый текст (без форматирования).
Спасибо за внимание. Автор блога Владимир Баталий
Советую ещё почитать:
- История календаря и временные промежутки
- Бесплатные программы для поиска дубликатов и одинаковых файлов
- Компьютерные игры и жанр стратегии
- Как восстановить удаленные данные с жесткого диска компьютера или карты памяти, обзор программ
- Делаем фотомонтаж лица онлайн, больше 200 000 шаблонов
Источник: matrixblog.ru
Программы OCR: распознавание текста, списки, разработчики, вес программы, выполняемые функции, характеристики, особенности работы и отзывы пользователей

Бумага как основной носитель информации, постепенно утрачивает свое значение. Вместо бумажных документов используют их электронный вариант, если это возможно. Но как перевести в электронный вид имеющиеся архивы? Для решения этой задачи были созданы специальные программы для распознавания текста.
Что такое OCR-программы и как они работают
Эти программные продукты, использующие технологию ORC (Optical character recognition) или ICR (Intelligence character recognition). На русский язык эти аббревиатуры переводятся как «оптическое» или «интеллектуальное распознавание символов».
Программы, использующие OCR, работают следующим образом. Фотография с текстом, полученная от сканера, разбивается на множество фрагментов. Для каждого из них приложение создает несколько предположений. Проверяя их и сравнивая с эталонами, каждому фрагменту дает оценку, соответствующую степени совпадения. Выбирая наибольшую из них, программа «видит» символ и выводит его в поле встроенного текстового редактора.
IRC работает по тому же принципу, но для обработки символов используются искусственные нейронные сети. Главное преимущество этого способа – компактность программ и непрерывное обучение. Это позволяет эффективно распознавать слова, написанные человеком рукописными буквами. Но эта технология не способна «прочесть» сплошной рукописный текст.
Для каждой из существующих операционных систем разработаны собственные OCR-программы. Наиболее популярными для работы в ОС Windows являются:
- ABBYY FineReader;
- OmniPage;
- Readiris;
- Samsung Scan OCR Program;
Кроме программ для ПК доступно много онлайн-сервисов по распознаванию текста. Среди них наиболее известны FineReader Online, OnlineOCR, FreeOCR.
ABBYY FineReader 14

Этот программный продукт разработан отечественной компанией ABBYY, является одной из лучших среди программ, использующих OCR. Основу программы составляет оригинальный движок под названием Finereader Engine. Он предоставляет следующие возможности:
- Быстрое распознавание печатного текста с точностью выше 98 %. Невосприимчивость к качеству исходного изображения. Это позволяет одинаково распознавать текст на фотографиях, полученных при помощи сканера или фотоаппарата.
- Технология ADRT позволяет распознавать не только текст, но и его форматирование: шрифт, отступы, абзацы, колонки.
- Возможность многопоточной обработки изображения. Это позволяет задействовать все ядра процессора (максимум 4) для ускорения процесса распознавания.
- Поддержка более 190 языков, включая те, которые используют алфавит, отличный от латиницы или кириллицы (японский, китайский, арабский).
- Встроенный текстовый редактор позволяет проверить результат распознавания или отредактировать его.
- Взаимодействие с пакетом Office. Оно позволяет экспортировать распознанный текст в Microsoft Word и Exel для дальнейшей обработки.
- Возможность обучения программы. Эта функция позволяет обучить программу «читать» специфические начертания букв. Например, нестандартный шрифт или печатные буквы, написанные рукой.
- Работа с PDF. FineReader позволяет распознавать текст из этого типа файлов и «сшивать» несколько отсканированных изображений в PDF или PDF/A.
Главный недостаток этой программы – цена. Бессрочная лицензия для базовой версии обойдется в 7 тысяч рублей. Версии «Бизнес» и «Энтерпрайз» – в 12 и 39 тысяч рублей, соответственно. Если же предполагается использовать программу только дома, то можно скачать с торрент-трекера взломанную 11-ю или 12-ю версию продукта.
- Процессор: 32- или 64-битный, с тактовой частотой более 1 ГГц и поддержкой набора инструкций SSE 2. (Intel Celeron M и лучше, AMD Athlon 64 и лучше).
- Оперативная память: 1 ГБ. Если процессор имеет более 1 ядра, то для каждого дополнительно требуется 512 МБ.
- Видеокарта: любая, поддерживающая разрешение 1024 х 800.
- Жесткий диск: 3 ГБ – для установки и работы.
- Сканер: поддерживающий драйверы TWAIN и WIA.
- ОС: Windows 7,8,8.1,10.
Мнение пользователей о FineReader 14
Они отзываются о FineReader положительно, выделяя среди достоинств способность продукта распознавать текст с плохих бумажных оригиналов, удобный и простой интерфейс и высокую скорость обработки изображений.
Среди проблем, возникающих при использовании этой OCR-программы, некоторые юзеры отмечают некорректно работающий менеджер изображений. Например: неадекватная работа регулировки яркости отсканированного изображения.
OmniPage 18

Основной конкурент FineReader на российском рынке ORC-программ. По функционалу она очень похожа на оппонента, но имеет несколько отличий:
- Возможность запуска процесса сканирования и распознавания при помощи кнопок сканера.
- Поддержка 4-ядерных процессоров. Это позволяет уменьшить время распознавания и преобразовывать несколько изображений одновременно.
- Создание собственной электронной библиотеки для букридера (электронной книги) Kindle.
- Автоматическое определение распознаваемого языка.
Среди недостатков программы можно отметить низкую скорость работы, сравнимую с 10-й версией FineReader, и цену за лицензионную копию – 150 долларов.
- Процессор: x32- или x64-битный, с тактовой частотой более 1 ГГц, Intel Pentium и лучше, AMD Athlon и лучше.
- Оперативная память: 512 МБ.
- Видеокарта: любая, поддерживающая разрешение 1024 х 800 и глубину цвета 16 бит.
- Жесткий диск: 1,1 ГБ для установки всех компонентов и 100 МБ для работы.
- Сканер: поддерживающий драйверы TWAIN,WIA и ISIS.
- ОС: Windows XP SP3,Vista SP2 x32/x64, 7,8.
Мнение пользователей об OmniPage
Отзываются они о ней резко негативно, т.к. проблемы есть во всех частях программы, начиная от красивого, но непонятного интерфейса, и заканчивая плохой справочной информацией. Продукт не адаптирован к работе в WinXP. Его можно заставить работать, но придется потратить какое-то время.
OmniPage имеет проблемы с распознаванием. Например: он легко распознает простой черный текст на листе бумаги с рисунками или таблицами, полученный со сканера. При использовании изображений с фотоаппарата или мобильного телефона точность распознавания падает до 70 %, а это очень неудобно при обработке больших документов.
Также 18-я версия может не запуститься из-за ошибок в коде. Для устранения этой проблемы нужно установить патч 18.01.
Read Iris Pro 17

Read Iris — это OCR-программа, что за меньшие деньги (8000 против 12 000) способна сравниться по функционалу и производительности с FineReader. Профессиональная версия обладает следующими возможностями:
- Полноценная работа с PDF: распознавание, создание файлов для баз данных, сжатие и озвучивание текста.
- Поддержка 140 языков.
- Распознавание бумажных таблиц и текстов с возможностью экспорта в Exel и Word.
- Получение изображений с любой модели сканера.
Также существует корпоративная версия, позволяющая защищать PDF-файлы водяными знаками и работать с документами объемом более 50 страниц.
- Процессор: x86 или x64, с тактовой частотой 1 ГГц или выше.
- Оперативная память: 1 ГБ.
- Видеокарта: любая, поддерживающая разрешение 1024 х 800.
- Жесткий диск:400 МБ для установки.
- Сканер: поддерживающий драйверы TWAIN,WIA.
- ОС: Windows 7,8,10 x32/x64.
Мнение пользователей о ReadIris
Они отзываются об этой OCR-программе распознавания текста как о хорошем и быстром PDF to Word конвертере с рядом проблем:
- Сложный интерфейс, в котором новичку нелегко разобраться.
- Автоматическое пересканирование документа при изменении области сканирования.
- Плохая техническая поддержка.
- Иногда программа не активируется из-за ошибок в коде программы.
Samsung Scan OCR Program – что это за программа?
Это бесплатное программное обеспечение, входящее в комплектацию многофункциональных устройств «3 в 1» (принтер, сканер, копир) от компании «Самсунг». Оно разработано в сотрудничестве с компанией Iris, создавшей ReadIris Pro, и оптимизировано для работы с МФУ этого производителя. От оригинального «Ридирис» Samsung Scan ORC отличается интерфейсом, урезанным функционалом и размерами – на жестком диске она занимает 40 МБ.
Онлайн-сервисы
Они являются альтернативой ресурсоемким стационарным программам для распознавания текста. Например, OCR программе FineReader. Свойства систем подобных проектов позволяют распознавать текст с изображений намного быстрее, чем на автономном ПК. Среди сервисов, занимающихся извлечением текста из фотографий, можно выделить 3 наиболее удобных: FineReaderOnline, FreeOCR, OnlineOCR.
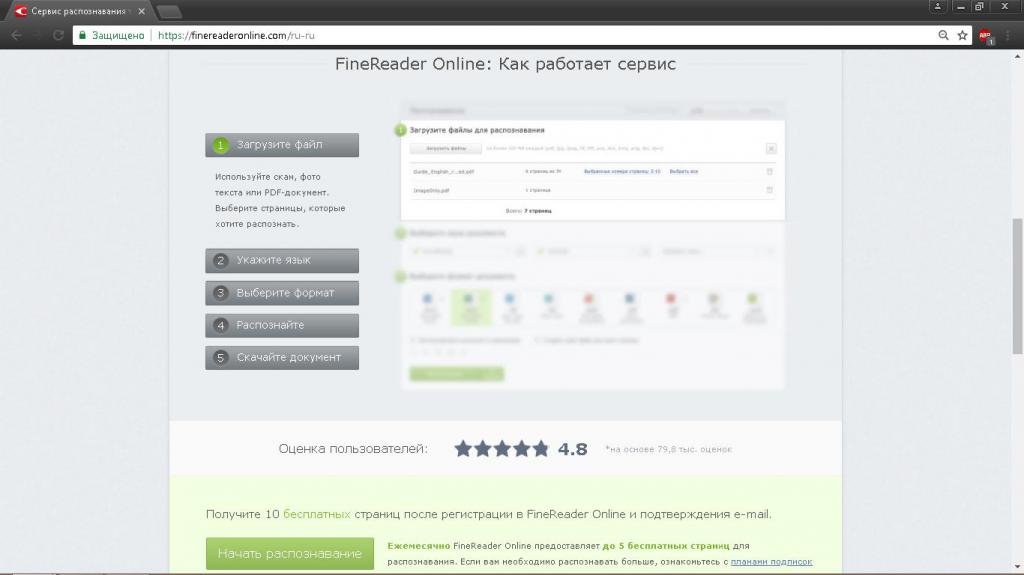
Первый является прямым развитием стационарной версии продукта. При регистрации новому пользователю дается 10 бесплатных страниц для обработки и 5 каждый месяц. Снять это ограничение можно, купив годовую подписку за 3200, 5500, 17800 рублей за 2000, 5000 и 10000 страниц соответственно. Если у пользователя есть лицензия для FineReader 14, то ему достаточно зарегистрироваться и активировать ее для использования в онлайн-версии. В этом случае он получит количество страниц, соответствующее типу приобретенной лицензии: «Стандарт» (2000), «Бизнес» (5000) или «Энтерпрайз» (10000).
Если страниц недостаточно, то их можно приобрести в количестве 50-50 000 штук.
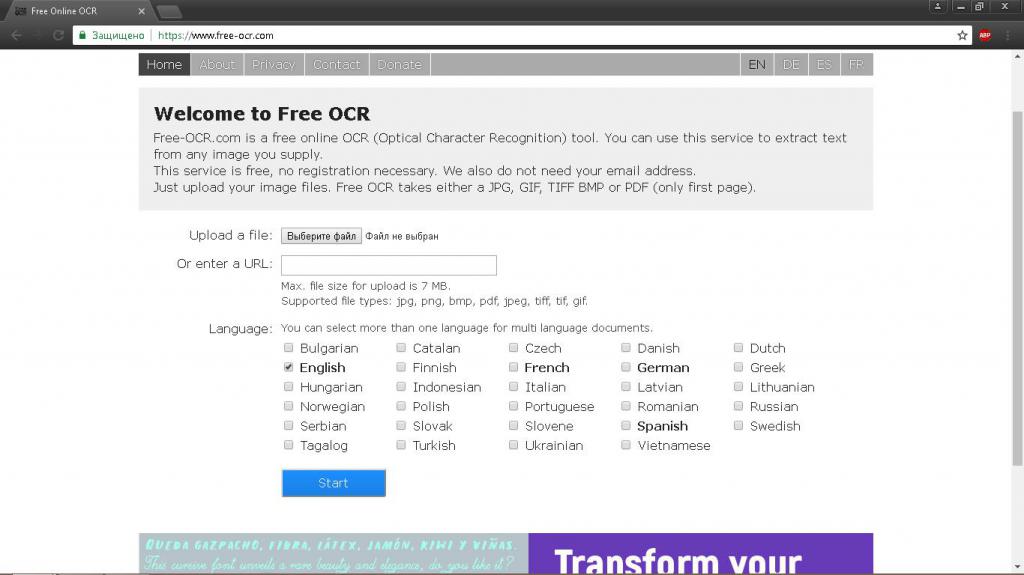
Проект FreeOCR.com отличается от предыдущего своей полной бесплатностью и отсутствием ограничений на количество обрабатываемых страниц. OCR-движок этого сайта поддерживает русский, украинский, турецкий, вьетнамский и все европейские языки – всего 29. Единственным недостатком этого портала является работа только с графическими изображениями, загружаемых последовательно, так как очередь обработки не предусмотрена создателями. Выводится распознанная информация без какого-либо форматирования в формате TXT.
Мнение пользователей об онлайн-OCR-сервисах
Эти сайты необходимы в тех случаях, когда загрузка и установка полноценной ORC-программы нецелесообразна. Например, для вставки в реферат нескольких объемных цитат из книги или журнала. Среди недостатков таких сайтов выделяют условную бесплатность (FineReader) и слабый функционал (FreeOCR,OnlineOCR).
Подводя итог, можно сказать, что OCR-программ распознавания текста с изображением или PDF-файлов создано немало, а в статье приведены лишь самые известные. Поэтому OCR-программу для сканера каждый пользователь сможет себе подобрать в соответствии с требованиями и бюджетом. Либо воспользоваться одним из множества бесплатных OCR-сервисов.
Источник: fb.ru
Самая известная программа оптического распознавания текстов

Выбор
Как же выбрать наиболее подходящую программу, и какие основные особенности имеет такой софт?
Отличаться он может по разным показателям – точности распознавания, способности работать с тем или иным языком, возможности сохранять исходную структуру текста и т. п.
Такой софт может распространяться платно и бесплатно, и быть реализован как онлайн (в виде особых сервисов), так и в форме предустанавливаемых программ.
Алгоритм работы заключается в том, что для каждой буквы алфавита составляется база вариантов того, как она может выглядеть на фото, выделяются и сохраняются ее основные элементы. Как только такие элементы обнаруживаются на фото, программа распознает соответствующую букву. В зависимости от того, насколько качественно и подробно была составлена такая база, зависит качество распознавания материала в итоге.
Потому важно, чтобы софт был рассчитан на работу именно с русским языком (некоторые программы могут работать с текстом, написанным сразу на двух языках, другие – нет).
Кроме того, некоторые утилиты и сервисы способны сохранять даже изначальную структуру текста (таблицы, списки), тип его оформления (отступы и т. п.) и даже шрифт.
В каких же случаях такой софт необходим?
- При создании документов, когда имеется только распечатанный вариант;
- При составлении рефератов, докладов и необходимости процитировать в них большой отрывок текста из книги;
- Для редакторских работ, когда текст имеется лишь в формате фото и т. д.
На самом деле сфера использования софта очень велика, и правильно выбранный, он способен облегчить и ускорить работу с текстом.


Это наиболее качественный и многофункциональный софт в данном ТОПе. Он отличается высокой точностью распознавания и имеет целый ряд преимуществ, распространяется платно.
Программа успешно работает со множеством языков, в ходе распознавания способна сохранять структуру текста и тип его форматирования.
Предназначена для профессионалов, потому, по мнению большинства пользователей, своих денет стоит.
- Высокое качество распознавания;
- Большое количество поддерживаемых языков;
- Способность сохранять стиль форматирования и особенности структуры документа достаточно точно;
- Наличие бесплатной пробной версии на 10 дней;
- Отсутствие снижения качества работы даже при больших объемах текста (что нередко наблюдается у других программ, которые хуже и хуже распознают текст с каждой последующей загруженной фотографии, и проблема устраняется только после перезапуска).
- Довольно значительная нагрузка на аппаратные ресурсы компьютера;
- Платное распространение по высокой стоимости при довольно коротком пробном периоде (всего на 10 дней);
- Замедление работы устройства при работе программы.
Отзывы о данном софте различны: «Хорошая программа, очень помогает в работе», «Не стоит своих денег – есть и бесплатные программы с таким же качеством распознавания».
OCR Cunei Form
4 года назад
Верю на слово, хотя эти программы мне теперь нафиг не нужны.
Лет 15 назад дочке на диплом сканировал тексты.
Так вот кроме Abbyy Fine Reader ничего путного не нашел.
Причем ни платные, ни бесплатные толком кириллицу распознавать не хотели.
Нет, с латинницей все было более менее. А вот с кириллицей только Abbyy Fine Reader.
Пришлось на торрентах искать и качать.
4 года назад
Кстати, уважаемые коллеги и уважаемые читатели форума данной тематики.
Хотите я Вас удивлю, не проводя даже предварительного опроса.
Особенно это касается обычных читателей, которые находятся в процессе изучения компьютерных премудростей.
Прошу в ответном комментарии поставить «1», кто понимает, зачем вообще нужны подобные программы. И «0», кто не понимает.
Не стесняйтесь. Рубите правду матку смелее.
P.S. 15 лет назад 95% обычных пользователей компьютера вообще не понимало, о чем идет речь.
P.P.S. Заодно вместе сравним.
4 года назад
Ещё со времён ХР и эффории улучьшалок , гаджетов , оптимизов и пр. красивостей , то и дело нарывался на глюки компа с сообщениями на пиндосском . А набирать текст в яндо-гугель переводчиках долго и нудно . Вот и нянькался с офлай-переводчиками и словарями , да скан-утилитами . Одно время остановился на ScreenTranslator , с возможностью сразу переводить текст с таблички сообщения или фотки , но намаялся я с её неудобо-пользованием и враньём , да ещё не все сообщения можно сканировать . Сейчас пользую исключительно удобного Abbyy Screenshot Reader — скан сразу в текст превращает и буфер обмена отправляет . Оттуда в янд-переводчик .А недавно узнал что янд-переводчик распознает текст в скрин-фотках и переводит , даже с дубоватого штатного в ПК скриншотера .
4 года назад
григорий, ну неплохо.
А качество распознавания и перевода вас устраивает? Просто я такого не пробовал.
Но, думаю это тоже на латиницу ориентировано. Ну и судя по волшебному «Screen» объемы текстов тоже небольшие? Хотя от с крина большего и не требуется.
4 года назад
Олег, За последние 10 лет Янд-переводчик стал очень качественно адаптировать англоские кракозябры в правильные русские понятки . По сравнению с ручным переводом со словарём , даже техническим , с результатом как в смешных китайских инструкциях на русском , у янда вполне понятен смысл всплывающих сообщений . А при сомнениях отдельных слов , выделив их в янде , выдаёт несколько вариантов . А то в опробованых сканер-переводчиках и оф- и онлайновых , частенько выданную галиматью никаким тусованием смысла не понять было . Мне надобности нет многостраничных переводов , потому вполне подходит этот двух-шаговый вариант , даже для десятки-строчковых текстов.
4 года назад
Делайте нормальные ссылки на ресурсы, где можно скачать программы.
4 года назад
Я наверно тоже достаточно архаичен. Abbyy Fine Reader использовал начиная с 4 версии. Ничего другого в то время более менее приличного тоже не нашел. Последнее время применял это ПО не для сканирования, а для конвертации PDF в WORD. Очень удобно. загружаешь PDF и распознаешь. как графику.
Если хорошо настроить, то почти 100% распознавание.
4 года назад
4 года назад
Спасибо. Может, и пригодятся. Лет 10 как приходится заниматься редакцией и коррекцией (причём вычитывать как жёсткую корректуру, т.е. с красным карандашом по распечатке, так и опусы в жидком виде, т.е. в окне InDesign).
В целом же отношение такое, что всего уметь невозможно, — и пускай один занимается набором и превращениями в редактируемый текст твёрдых оригиналов, фоток и скриншотов, т.е. хорошо делает техническую часть, а другой — вычиткой и правками, но тоже с профи-качеством.
4 года назад
Дмитрий! Но ведь если на работе инженер — электроник, а дома не может лампочку вкрутить, то это тоже не дело. Все это инструменты для повседневной работы и на твердую четверку их надо знать. Я не думаю что это будет плохо, когда вот горько надо в PDF внести правку какую-то, а не можешь.
4 года назад
Александр, это если (редко на практике) PDF-«изображение». А так-то для внесения изменений (исправления опечаток) и создания примечаний в обычном файле PDF/A-mode используются Adobe Acrobat и опция «доступ к рецензированию/редактированию» (не нужно распознавать и конвертировать в Word, а затем после правки опять делать PDF). Честно говоря, от коррекции распознанных-из-графики текстов (например, старую книгу сканировали в Word) всегда наотрез отказывался — слишком много «неверностей», ерунда завсегда — по внутренним полям (область к переплёту редко ложится плоско на зеркало сканера).
Что мужчина в повседневной жизни должен уметь то и другое и третье — звучит и выглядит красиво, — не спорю. А я вот на практике и «на тройку с минусом» не разбираюсь ни в автомобиле, ни в смартфоне, ни в стиральной машине, не говоря уже про «умный дом», и (как эксперт по биоразнообразию) рассуждаю так — феномен разнообразия с диапазоном (разбросом характеристик) наблюдается и тут: 80% удовлетворительно справляются с самостоятельным ремонтом-настройкой девайсов и соотв.софта, 10% разбираются как профи, 10% чайниками и останутся, и не каждому дано во всём быть успевающим. Век живи — век учись, это верно, причём «тяжело в учении» (даже если учиться любишь), а пожить в удовольствие времени осталось уже немного.
Да, и думаю, что скоро (пятилетка +/-) появятся намного более совершенные мобильные приложения для распознания графики в текст (и речь) и речи в текст с переводом. Сейчас, пока, увы, — наведёшь смартфон на уличную вывеску, а он теряется — то ли словенский язык, то ли греческий, и с мультиязычной речью также «удивляет» результатами. Китайские разработчики в этом определённо хороши.
4 года назад
P.S. Александр, «плюс» Вам за ответ мне — это раз. Второе — Ваш оборот «когда вот горько надо» так и не «распознал» (чутьём-то догадываюсь, о чём речь, но. ).
Источник: pomogaemkompu.temaretik.com