
Обрабатываемые с помощью компьютера данные записываются в специальных запоминающих устройствах, называемых памятью. Двоичное кодирование используется для представления в компьютере как числовой, так и текстовой, графической, звуковой информации. Форматы представления данных в памяти компьютера определяют диапазоны значений, которые эти данные могут принимать, скорость их обработки, объем памяти, который требуется для хранения данных.
Существуют две формы представления числовых данных, предназначенные для целых и действительных чисел соответственно.
Целые числа точно представляются в памяти компьютера и позволяют выполнять операции без погрешностей. Целочисленная арифметика позволяет реализовать операции деления нацело с остатком (причем можно в качестве результата получить как частное от деления, так и остаток). Именно целые числа используются при решении многих экономических задач и задач управления (примерами данных, представленных целочисленными величинами, являются количество акций, сотрудников, транспортных средств, деталей, единиц боевой техники и т.п.; целые числа служат для нумерации элементов в различных наборах данных, для обозначения даты и времени, для кодирования текста, изображения и звука), реализации средств криптографической защиты информации (защиты с помощью шифрования), в программах электронной почты и в средствах навигации в Internet для записи адреса и т.д. Поэтому аппаратурой компьютеров обычно поддерживается несколько форматов представления целочисленных данных и множество операций над ними.
Операционные системы, урок 7: Организация памяти. Виртуальная память.
Целые числа в памяти компьютера всегда хранятся в формате с фиксированной точкой,что, безусловно, ограничивает диапазон чисел, с которыми может работать компьютер, и требует учета особенностей организации выполнения арифметических действий в ограниченном числе разрядов.
Рассмотрим подробнее это представление.
Все числа, которые хранятся в памяти компьютера, занимают определенное количество двоичных разрядов. Это количество определяется форматом числа. Обычно для представления целых чисел используются несколько форматов (например, в IBM-совместимых персональных компьютерах поддерживается три формата: байт (8 разрядов), слово (16 разрядов), двойное слово (32 разряда)). Целые числа вписываются в разрядную сетку, соответствующую формату. Для целых чисел разрядная сетка имеет вид:

где b i – разряды двоичной записи целого числа (запись числа имеет вид b n–2 b n–3. b 1 b 0, разделитель между целой и дробной частью числа зафиксирован после b0, дробной части нет); S – разряд, отведенный для представления знака числа (для положительных чисел знак «+» кодируется цифрой 0, а знак «–» для отрицательных – цифрой 1); n – количество двоичных разрядов в разрядной сетке.
Если двоичная запись числа оказывается короче отведенной для его хранения в памяти компьютера разрядной сетки, то старшие разряды заполняются нулями.
Лекция 2. Оптимизация работы с кеш-памятью процессора
Например, число 1110=10112 в формате байта будет записано так:
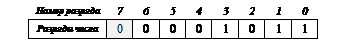
(старший (знаковый) разряд заштрихован). В формате слова (16 разрядов) то же число будет выглядеть так:
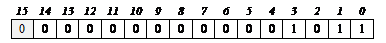
Отрицательные числа для упрощения выполнения операций хранятся в дополнительном коде, который получается путем обращения (инверсии) всех разрядов в двоичной записи числа, вписанной в разрядную сетку, и добавления 1. Например, число –1110 в формате байта в памяти компьютера будет получено следующим образом.
Вычисляется прямой код:
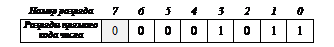
затем выполняется инверсия полученного прямого кода (получается обратный код):

к обратному коду прибавляется 1:
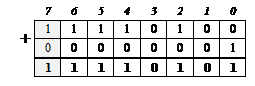
получается дополнительный код – запись отрицательного числа –1110 в памяти компьютера:
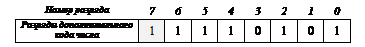
Такая запись чисел ограничивает диапазоны значений, с которыми может работать компьютер. Например, для чисел в формате байта представимы значения от –128 (–2 7 ) до 127 (2 7 –1), для чисел в формате слова – от –32 768 (–2 15 ) до 32 767 (2 15 –1), а длинные целые числа в формате двойного слова могут принимать значения из диапазона от –2 147 483 648 до 2 147 483 647.
Если по условиям задачи используются только положительные значения, то их можно хранить в формате чисел без знака – старший разряд рассматривается как разряд, содержащий двоичную цифру записи числа, а не знак. При этом диапазон представимых положительных чисел увеличивается. Например, в байт можно записать числа от 0 до 255 (2 8 –1), а в слово – значения от 0 до 65535 (2 16 –1).
Особенности представления чисел в памяти компьютера могут привести и к ошибкам при обработке данных.
Рассмотрим пример. Предположим, что программа выполняет функции подсчета каких-либо объектов, и для хранения количества этих объектов используется представление данных в формате целого числа со знаком, записанного в байт. Рассмотрим ситуацию, когда количество объектов уже стало равным 127 и увеличивается еще на 1. Результат должен быть равен 128, но сможем ли мы его получить с помощью компьютера, если работаем со знаковыми числами в формате байта?
Целое число 127 в памяти компьютера будет представлено цепочкой нулей и единиц 01111111. При добавлении единицы будет получено число 10000000:
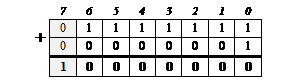
(действия в двоичной системе счисления выполняются так же, как и в десятичной, но используются только две цифры, поэтому, если при сложении разрядов получается значение большее 1, происходит перенос в старший разряд). Но старший разряд является знаковым! Поэтому в результате сложения компьютер получит целое число –128, записанное своим дополнительным кодом. И именно это отрицательное число будет затем использовано во всех вычислениях.
Этот пример демонстрирует возможность появления ошибок при выполнении программ вследствие неправильно выбранных форматов для представления данных.
Таким образом, при выполнении программ может возникнуть ситуация, когда полученные результаты не смогут «вписаться» в отведенную для них разрядную сетку, произойдет ее «переполнение».
Разработчики программ должны отслеживать такие ситуации и предотвращать подобные ошибки, а пользователи должны четко формулировать требования к условиям эксплуатации программ, их входным данным и результатам. Игнорирование этих требований может создать серьезные проблемы.
Поэтому при разработке программного обеспечения очень важно знать, с какими диапазонами значений будет работать программа. Это позволит правильно определить форматы представления чисел и предупредить возможные ошибки при обработке данных.
Каждый раз при вводе данных в компьютер происходит преобразование числовых данных, введенных пользователем с клавиатуры в виде строки символов, представляющей десятичную запись числа, во внутреннее двоичное представление числа. При выводе результатов осуществляются обратные преобразования. Эти преобразования требуют времени. Поэтому для систем, в которых вводится и выводится большой объем информации, осуществляется ее поиск, происходит замедление выполнения программ вследствие постоянных переводов информации из одной формы представления в другую. Для представления данных в таких системах (а именно к ним относится большинство программ для решения экономических задач и задач управления) используется еще одна форма представления данных в памяти компьютера – двоично-десятичные данные.
При использовании двоично-десятичной формы представления данных десятичные числа также представляются с помощью двоичных кодов, но в двоичную систему переводится не все число, а каждая его цифра отдельно. Так как используется всего десять десятичных цифр от 0 до 9, а для представления старшей цифры 9 достаточно четырех двоичных цифр (910=10012), то каждая десятичная цифра в записи числа кодируется четырьмя двоичными цифрами в его двоично-десятичном представлении в памяти компьютера. Например, число 105910 представляется в памяти компьютера следующим образом:
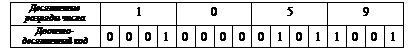
Двоично-десятичные данные могут использоваться не только для представления целых чисел, но и для представления чисел, имеющих дробную часть.
Знак числа и позиция десятичного разделителя в нем кодируются отдельно. Для двоично-десятичных чисел также существуют различные форматы записи чисел в памяти компьютера. Конкретные форматы определяются его архитектурными особенностями.
При использовании двоично-десятичного представления проще выполняется преобразование данных при вводе/выводе, но усложняются алгоритмы выполнения операций. Поэтому такая форма представления применяется там, где данные не подвергаются сложной обработке, где нет объемных вычислений.
Решение проблем математического моделирования в естественных науках, экономике и технике, работа с системами автоматического проектирования, электронными таблицами невозможны без использования вещественных (действительных) чисел.
Для представления этих чисел разработана специальная форма – данные в памяти компьютера хранятся в форме с плавающей точкой. Такое представление основано на записи числа в экспоненциальном виде, где разряды в записи числа представляются мантиссой M, а положение точки определяется указанием порядка p: M ´10 p .
При использовании такой формы представления часть разрядов разрядной сетки, в которую помещается число в памяти компьютера, отводится для хранения порядка числа p, а остальные разряды – для хранения мантиссы M:
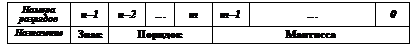
Порядок числа и его мантисса хранятся в двоичном коде, поэтому перед их определением число переводится в двоичную систему.
Точность вычислений зависит от длины мантиссы, а порядок числа определяет допустимый диапазон представления действительных чисел. Например, в IBM-совместимых персональных компьютерах используются три формата представления данных в форме с плавающей точкой (32 разряда, 64 разряда и 80 разрядов), позволяющие представлять три диапазона положительных вещественных чисел: от 1,5´10 ‑45 до 3,4´10 38 , от 5´10 324 до 1,7´10 308 и от 1,9´10 4951 до 1,1´10 4932 . Для представления положительных чисел в знаковый разряд записывается значение 0, а отрицательных чисел – 1. Порядок и мантисса записываются как целые числа.
Такая форма представления чисел усложняет функциональную схему компьютера, так как операции над числами с плавающей точкой значительно сложнее. Для ускорения обработки числовых данных в его состав включаются специальные устройства.
Особенности представления вещественных чисел в памяти компьютера определяют свойства машинных чисел: при переводе дробной части десятичного числа в формат с плавающей точкой происходит его округление до количества разрядов, определяемых длиной мантиссы; ограниченная длина мантиссы приводит к погрешности при выполнении операций («лишние» разряды отсекаются или происходит округление); вещественные числа нельзя сравнивать на равенство, их можно только проверять на принадлежность определенным диапазонам.
Текстовые данные рассматриваются как последовательность отдельных символов, каждому из которых ставится в соответствие двоичный код некоторого неотрицательного целого числа.
Существуют разные способы кодирования символов.
Наиболее распространенной до последнего времени была кодировка ASCII (American Standard Code for Information Interchange). При использовании этой кодировки для представления каждого символа используется ровно 8 разрядов (один байт). Таким образом, имеется возможность кодирования 256 символов (они получают коды от 0 до 255). С помощью такой кодировки можно хранить только символы текста (без элементов форматирования или оформления).
Для отображения текстового документа с разбивкой его на строки, с выравниванием и т.п. в него наряду с обычными символами, представляющими буквы, цифры, знаки препинания, разделители, включаются специальные (управляющие) символы (например: «перевод строки», «возврат каретки», «табуляция» и т.д.).
Соответствие символов и их кодов можно установить с помощью специальной таблицы. В России используются элементы таблицы альтернативной модифицированной кодировки, в первой части которой размещены символы ASCII (цифры, буквы латинского алфавита, знаки препинания, управляющие символы), а во второй половине – буквы русского алфавита, символы псевдографики, которые позволяют включить в текст простейшие рисунки и таблицы, составленные из вертикальных и горизонтальных линий).
ASCII позволяет закодировать только 256 символов. Это неудобно, так как существуют языки, где символов больше. Поэтому разрабатываются другие коды (наборы символов), например двухбайтовые наборы символов (DBCS – double-byte character sets). В этом двухбайтовом коде символы представляются одним и двумя байтами, что неудобно для организации обработки такой информации (для каждого символа сначала нужно определить длину его кода, а уж потом сам символ).
Наиболее перспективным для использования является Unicode – стандарт, разработанный несколькими фирмами (сначала – Apple и Xerox). В этом коде все символы состоят из 16 битов. Это позволяет кодировать свыше 65 тыс. символов (2 16 ). В этом коде для каждого алфавита определены свои кодовые позиции (code points), т.е. все 65536 символов (кодов) разбиты на отдельные группы (например: 0100-017F – европейские латинские, 0180-01FF – расширенные латинские, 0250-02AF – стандартные фонетические, 0370-03FF – греческий, 0400-04FF – кириллица и т.д.). Около 29 000 кодовых позиций пока не заняты, но зарезервированы для использования. Таким образом, Unicode допускает обмен данными на разных языках – каждому коду соответствует единственный символ, коды не пересекаются для разных языков.
На Unicode целиком построена операционная система Windows NT. У Windows 95/98 16‑битное «наследство», поэтому вся внутренняя работа в этой ОС построена на использовании ANSI-строк (ANSI – American National Standards Institute), в которых каждый символ записан в один байт.
ANSI-текст (или текст ASCII) – это текст без форматирования (с ним работает, например, приложение «Блокнот» в Windows 9х).
Если для представления информации в разных информационных системах используются разные кодировки, эти программы «не поймут» друг друга, поэтому может оказаться, что данные, подготовленные в одном месте, не смогут прочитать в другом. Например, текст, введенный с помощью программы «Блокнот» в Windows, нельзя будет прочитать в MS‑DOS.
Способ представления графических изображений, отображаемых на экране, называют матричным. При этом экран дисплея ЭВМ рассматривается как двумерный массив отдельных точек (пикселов), состояние каждой из которых (цвет и яркость) кодируется неотрицательным целым двоичным числом.
Звук представляет собой непрерывный сигнал, колебания частиц среды, распространяющиеся в виде волн и воспринимаемые органами слуха. Чтобы закодировать звук, его надо сначала подвергнуть дискретизации.
Этот процесс состоит в измерении и запоминании в памяти компьютера характеристик звуковой волны (амплитуды и периода) в виде двоичного кода, он выполняется аналого-цифровым преобразователем несколько десятков тысяч раз в секунду через равные промежутки времени. При воспроизведении двоичные коды подаются на вход цифро-аналогового преобразователя с той же частотой, что и при дискретизации, преобразуются в электрическое напряжение, а затем с помощью усилителя и динамика – в звук.
Такой способ звукозаписи, называемый цифровым, требует большого объема памяти компьютера, у оцифрованного звука трудно менять тональность или тембр. Для кодирования музыки чаще используется не запоминание параметров звуковых волн, а запись последовательности команд, например: какую клавишу нажать, какова сила давления, сколько времени удерживать клавишу нажатой и т.д. Такая MIDI –запись аналогична нотной записи. Она компактна, в ней легко производится смена инструмента или тональность мелодии.
Источник: mydocx.ru
Принципы организации ЭВМ
Принципы организации ЭВМ с фоннеймановской архитектурой
- 1. Название «электронная вычислительная машина» говорит о том, что эта машина предназначена, во-первых, для решения сложных вычислительных задач, и во-вторых, что она должна быть реализована на базе электронных элементов.
- 2. ЭВМ — это машина с хранимой (в памяти ЭВМ) программой, представленной в виде последовательности команд.
- 3. Составляющие выполняемую ЭВМ программу команды и данные, над которыми выполняются задаваемые командами операции, должны быть представлены в ЭВМ в виде двоичного кода.
- 4. Память ЭВМ должна быть организована в виде последовательности запоминающих ячеек, в каждой из которых может храниться (запоминаться) какой-либо двоичный код (код команды, числа, символа алфавита). При этом в конкретный момент времени можно обратиться для записи или чтения к любой одной из этих ячеек независимо от места ее расположения в памяти, указав адрес (порядковый номер) этой ячейки.
- 5. Для хранения кодов команд и кодов данных в ЭВМ используется одна общая память. При этом в двоичных кодах самих команд и данных отсутствуют какие-либо признаки, позволяющие явно отличать команды от данных.
- 6. Предназначение содержащихся в ячейках памяти данных, их тип и способ интерпретации и обработки также явно в их двоичном коде не указываются.
- 7. В классической фоннеймановской ЭВМ используется один центральный процессор.
Обращаясь к предыстории ЭВМ, можно отметить, что большинство из приведенных принципов сами по себе в отдель-
ности не являются оригинальным изобретением создателей первых ЭВМ, а в том или ином контексте уже ранее встречались в вычислительных устройствах. Заслугой первых разработчиков ЭВМ является то, что они отобрали из богатого предшествующего опыта наиболее эффективные решения, собрав их в единый комплекс, что и позволило наконец создать это одно из самых феноменальных изобретений человека.
Рассмотрим приведенные выше принципы более подробно, пытаясь определить мотивацию создателей ЭВМ при выборе этих решений.
ЭВМ — это машина с хранимой (в памяти ЭВМ) программой, представленной в виде последовательности команд.
В этом тезисе содержится два ключевых слова — «программой» и «хранимой».
Первое означает, что в основу способа, с помощью которого ЭВМ становится способной решать какую-либо сложную задачу — а создавалась она для решения сложных вычислительных задач, — должен быть положен принцип программирования. Это означает, что решение сложной задачи должно быть представлено в виде последовательности выполнения достаточно простых действий (другими словами, представлено в виде программы, состоящей из последовательности элементарных опе- раций/команд).
Для создателей ЭВМ тут являлось важным то, что составляющие такую программу операции могли быть настолько простыми, что их становилось возможным практически реализовать с помощью устройств, имевшихся в то время в распоряжении разработчиков ЭВМ. Заметим, что к тому времени стало очевидным, что элементной базой, наиболее подходящей для создания ЭВМ, могут быть не механические, а только электронные элементы, как наиболее быстродействующие физические устройства.
Второе ключевое слово — «хранимой» — означает, что в ЭВМ должно быть специальное устройство, способное запоминать, хранить и, самое главное, быстро выдавать в нужном порядке для исполнения команды, составляющие такую программу. Мы это устройство называем «память ЭВМ».
Следующий принцип посвящен тому, в каком виде должны быть представлены в ЭВМ команды и данные.
Выполняемые ЭВМ команды и данные, над которыми выполняется задаваемая командой операция, должны быть представлены в ней в виде двоичного кода.
Казалось бы, совершенно очевидно, что для представления чисел и произведения вычислений над ними наиболее естественным для человека является десятичное представление. Однако для реализации ЭВМ ее создателями было выбрано именно двоичное представление. И причина этого опять определяется соображениями простоты реализации носителей такого кода с помощью физических (а именно электронных) элементов. Реализовать электронный элемент, способный находиться всего в двух состояниях, принципиально проще, чем элемент с большим числом состояний.
Если выше декларировалось, что в ЭВМ обязательно должно быть запоминающее устройство для запоминания двоичных кодов команд и данных, то в следующем принципе определялась конструкция такого запоминающего устройства.
Память ЭВМ должна быть организована в виде последовательности одинаковых запоминающих ячеек, в каждой из которых может храниться (запоминаться) некоторый двоичный код — код команды ЭВМ, код числа или символа алфавита; при этом в конкретный момент времени можно обратиться для записи или чтения к любой одной из этих ячеек независимо от ее расположения в памяти (в начале, в середине, в конце), указав адрес (порядковый номер) этой ячейки.
Запоминающее устройство, организованное таким образом, называется памятью с произвольным доступом.
Хотя сама по себе способность к запоминанию чего-либо хорошо знакома человеку — у каждого из нас есть своя память, конструкция предложенной для ЭВМ памяти ничего общего с нашей собственной человеческой памятью не имеет. И опять создатели ЭВМ исходили из соображений реализуемости такого запоминающего устройства с помощью имевшихся в их распоряжении электронных элементов. Важным также является тот факт, что организация памяти в виде последовательности запоминающих ячеек хорошо согласуется с задачей хранения и быстрой выборки последовательности команд, составляющих выполняемую ЭВМ программу.
Отметим, однако, что память с произвольным доступом, даже применительно к ЭВМ, вообще говоря, является не единственно возможным и практически используемым способом реализации ее запоминающего устройства. В частности, чуть позже в рамках этого курса мы рассмотрим память, организованную в виде стека, в которой понятие адреса ячейки отсутствует; можно упомянуть также так называемую ассоциативную память, в которой обращение осуществляется не по адресу запоминающего элемента, а по его содержимому. Тем не менее в данный момент мы ведем речь именно о памяти с произвольным доступом.
Интересен следующий тезис.
В ЭВМ используется одна общая память как для хранения данных, так и для хранения команд. При этом в двоичных кодах самих данных и команд отсутствуют признаки, позволяющие явно отличать их друг от друга.
Казалось бы, коды команд и коды данных по сути являются совершенно разными сущностями с точки зрения их интерпретации и обработки в ЭВМ. Код команды определяет, какие действия должна выполнить ЭВМ, а данные — это объекты, над которыми эти действия выполняются. И тем не менее мы «складываем» эти объекты в одну общую память и отказываемся даже от того, чтобы как-то пометить их, чтобы различить. Дело в том, что, как будет видно дальше, сформулированные принципы реализации ЭВМ на самом деле позволяют реализовать корректную быструю выборку из памяти и последующую интерпретацию и использование двоичных кодов команд и данных при их размещении в одной общей памяти и отсутствии в их коде признаков, обозначающих тип этих кодов.
При этом существенным выигрышем является гораздо более эффективное использование всегда ограниченного количества ячеек запоминающего устройства (пространства памяти) в условиях, когда заранее не известно, сколько ячеек потребуется для размещения команд, а сколько — для данных.
Справедливости ради отметим, что в конце 1930-х гг. в Гарвардском университете Говардом Эйкеном была предложена иная архитектура запоминающего устройства вычислительной машины. Идея, реализованная Эйкеном, заключалась в физическом разделении устройств хранения и линий передачи команд и данных.
И тем не менее для ЭВМ фоннеймановской архитектуры (ее еще называют принстонской) было выбрано решение с общей памятью для команд и данных. То, что это было не самое плохое решение, подтверждается тем фактом, что и в настоящее время в большинстве компьютеров используется именно общая память для команд и для данных.
Однако не была забыта и гарвардская архитектура с раздельной памятью для команд и данных. В 90-е гг. XX в. она возродилась при создании так называемых процессоров сигналов, то есть процессоров, предназначенных для обработки сигналов в реальном масштабе времени, для которых фактор скорости выполнения операций оказался гораздо более приоритетным, чем оптимизация использования имеющегося объема памяти ЭВМ.
Следующий тезис обсуждаемого перечня фоннеймановских принципов реализации ЭВМ перекликается с предыдущим и гласит, что в двоичном коде данных также не содержится признаков, обозначающих предназначение данных, их тип и способ использования.
То есть даже зная, что данный двоичный код представляет какие-то данные, мы не можем сказать, что это: целое число без знака, число со знаком, число с плавающей точкой, код символа какого-то алфавита. Эти характеристики определяются и различаются в контексте выполняемой ЭВМ программы.
Наконец, последний тезис фоннеймановских принципов говорит о том, что в классической фоннеймановской ЭВМ используется один центральный процессор. Вполне понятно, что при создании первых ЭВМ их разработчики в сторону многопроцессорных вычислительных систем еще не глядели.
Контрольные вопросы
- 1. Объясните, в чем состоит принципиальный смысл формулы «ЭВМ — это машина с хранимой программой».
- 2. Какая система счисления и почему выбрана в фоннеймановской ЭВМ для внутреннего представления чисел?
- 3. Представление в памяти фоннеймановской ЭВМ данных и команд.
- 4. Что такое программа ЭВМ? В каком виде и где она должна размещаться для того, чтобы процессор мог ее выполнять?
- 5. Для чего в ЭВМ нужна память? Особенности организации памяти фоннеймановской ЭВМ.
- 6. Что такое память с произвольным доступом? Возможны ли другие способы доступа к ячейкам памяти, другие способы организации памяти?
- 7. Что такое адрес ячейки памяти ЭВМ?
- 8. В ЭВМ с фоннеймановской архитектурой данные и команды хранятся:
- а) раздельно в памяти команд и памяти данных;
- б) в общей памяти;
- в) данные хранятся в памяти ЭВМ, а команды поступают от внешних устройств;
- г) команды находятся в памяти ЭВМ, а данные принимаются из портов внешних устройств;
- д) ваш вариант.
В чем преимущество выбранного вами решения?
- 9. Можно ли по содержимому ячейки памяти фоннеймановской ЭВМ определить, что в ней находится: команда, целое число без знака, число со знаком и т. д.? Если да, то каким образом?
- 10. Каким образом процессор фоннеймановской ЭВМ определяет, из каких ячеек памяти следует выбирать команды, а из каких—данные?
Источник: studme.org
Лекция 5. Концепция машины с хранимой в памяти программой
В процессорах с использованием этой технологии каждый физический процессор может хранить состояние сразу двух потоков, что для операционной системы выглядит как наличие двух логических процессоров (англ. Logical processor). Физически у каждого из логических процессоров есть свой набор регистров и контроллер прерываний (APIC), а остальные элементы процессора являются общими. Когда при исполнении потока одним из логических процессоров возникает пауза (в результате кэш-промаха, ошибки предсказания ветвлений, ожидания результата предыдущей инструкции), то управление передаётся потоку в другом логическом процессоре. Таким образом, пока один процесс ждёт, например, данные из памяти, вычислительные ресурсы физического процессора используются для обработки другого процесса. [1]
Были представлены следующие преимущества Hyper-threading: улучшенная поддержка многопоточного кода, позволяющая запускать потоки одновременно; улучшенная реакция и время отклика; увеличенное количество пользователей, которое может поддерживать сервер.
По словам Intel, первая реализация потребовала всего 5-процентного увеличения площади кристалла, но позволяла увеличить производительность на 15—30 %.
Intel утверждает, что прибавка к скорости составляет 30 % по сравнению с идентичным процессорами Pentium 4 без технологии «Simultaneous multithreading». Однако прибавка к производительности изменяется от приложения к приложению: некоторые программы вообще несколько замедляются при включённой технологии Hyper-threading. Это, в первую очередь, связано с «системой повторения» (англ. replay) процессоров Pentium 4, занимающей необходимые вычислительные ресурсы, отчего и начинают «голодать» другие потоки [2][3] .
Рассмотрим наиболее распространенные определения основных терминов в области ЭВМ и вычислительных систем (ВС).
Согласно ГОСТ 15971-90 введем следующие понятия:
Вычислительная машина (ВМ) — совокупность технических средств, создающая возможность проведения обработки информации (данных) и получение результата в необходимой форме.
Под техническими средствами понимают все оборудование, предназначенное для автоматизированной обработки данных. Как правило, в состав ВМ входит и системное программное обеспечение (ПО).
Электронной вычислительной машиной (ЭВМ) называютвычислительную машину (ВМ), основные функциональные устройства которой выполнены на электронных компонентах.
Вычислительную систему (ВС) стандарт ISO/IEC 2382/1-93 определяет как одну или несколько вычислительных машин, периферийное оборудование и программное обеспечение, которые выполняют обработку данных.
ISO — Международная организация стандартов.
Электронно-вычислительная машина (ЭВМ, Electronic Computer) — программируемое функциональное устройство, состоящее из одного или нескольких взаимосвязанных центральных процессоров, периферийных устройств, управление которыми осуществляется посредством программ, располагающихся в оперативной памяти. Эта машина может производить большой объем вычислений, содержащих большое количество арифметических, логических и других операций без вмешательства пользователя в течение периода выполнения (стандарт ISO 2382/1-84).
Многопроцессорная вычислительная система (Multiprocessor computer system) — система, в состав которой входят два или несколько процессоров.
Рассмотрим определения, касающиеся понятия «архитектура».
Термин « архитектурасистемы » часто употребляется как в узком, так и в широком смысле этого слова.
В узком смысле под архитектурой понимается архитектура набора команд. Архитектура набора команд служит границей между аппаратурой и программным обеспечением (ПО) и представляет ту часть системы, которая видна программисту или разработчику компиляторов. Следует отметить, что это наиболее частое употребление термина.
В широком смысле архитектура охватывает понятие организации системы, включающее такие высокоуровневые аспекты разработки компьютера, как систему памяти, структуру системной шины, организацию ввода-вывода и т. п.
По ГОСТ 15971-90 под архитектурой вычислительной машины (ВМ) понимается концептуальная структура ВМ, определяющая проведение обработки информации и включающая методы преобразования информации в данные и принципы взаимодействия технических средств и программного обеспечения.
Архитектура ЭВМ — абстрактное представление ЭВМ, которое отражает ее структурную, схемотехническую и логическую организацию. Понятие «архитектура ЭВМ» является комплексным и включает в себя целый ряд элементов, основные из них следующие:
1. структурная схема ЭВМ;
2. средства и способы доступа к элементам структурной схемы, включая обмен с внешней средой;
3. организация и разрядность интерфейсов в ЭВМ;
4. набор и доступность регистров;
5. организация и способы адресации памяти;
6. способы представления и форматы данных ЭВМ;
7. набор машинных команд;
8. форматы машинных команд;
9. обработка нештатных ситуаций (прерывания, особые ситуации, ловушки и т. д.);
10. топология связи отдельных устройств и модулей.
Таким образом, при разработке архитектуры ЭВМ условно можно выделить вопросы:
· общей структуры, организации вычислительного процесса и общения с машиной;
· логической организации представления, хранения и преобразования информации;
· логической организации совместной работы различных устройств;
· связанные с аппаратными и программными средствами машин.
К настоящему времени среди ЭВМ последовательного типа наибольшее распространение получили два типа архитектур:
Концепция вычислительной машины, изложенная в статье фон Неймана, предполагает единую память для хранения команд и данных. Такой подход был принят в вычислительных машинах, создававшихся в Принстонском университете, из-за чего и получил название принстонской архитектуры.
Практически одновременно в Гарвардском университете предложили иную модель, в которой ВМ имела отдельную память команд и отдельную память данных. Этот вид архитектуры называют гарвардской архитектурой.
Долгие годы преобладающей была и остается принстонская архитектура, хотя она порождает проблемы пропускной способности тракта «процессор-память». В последнее время, в связи с широким использованием кэш-памяти, разработчики ВМ все чаще обращаются к гарвардской архитектуре.
Вычислительная сеть ( или сеть ЭВМ, от англ. Computer Network) — территориально рассредоточенная многомашинная система, состоящая из взаимодействующих ЭВМ, связанных между собой каналами передачи данных.
Система взаимодействует с внешним миром через набор интерфейсов.
Интерфейс (Interface) — совокупность средств и правил, обеспечивающих взаимодействие устройств ЭВМ или ВС, программ, а также пользователей (ГОСТ 15971-90).
Примечание: Интерфейсы могут разграничивать определенные уровни внутри программного обеспечения. Например, уровень управления логическими ресурсами может включать реализацию таких функций, как управление базой данных, файлами, виртуальной памятью, сетевой телеобработкой.
К уровню управления физическими ресурсами относятся функции управления внешней и оперативной памятью, управления процессами, выполняющимися в системе.
Следующий уровень отражает основную линию разграничения системы, а именно границу между системным программным обеспечением и аппаратурой. Эту идею можно развить и дальше и говорить о распределении функций между отдельными частями физической системы.
Например, некоторый интерфейс определяет, какие функции реализуют центральные процессоры, а какие — контроллеры системных шин и магистралей передачи данных.
Интерфейс следующего уровня определяет разграничение функции между контроллерами системных шин и контроллерами внешних устройств.
В свою очередь, можно разграничить функции, реализуемые контроллерами и самими устройствами ввода-вывода (терминалами, модемами, накопителями на магнитных и оптических дисках, сетевыми адаптерами). Архитектура таких уровней часто называется архитектурой физического ввода-вывода.
В соответствии с ГОСТ 15971-84 под архитектурой ВС (Computing Architecture) понимается логическая организация цифровой вычислительной системы, определяющая процесс обработки данных в конкретной ВС и включающая методы кодирования данных, состав, назначение, принципы взаимодействия технических средств и программного обеспечения. В повседневной практике под архитектурой ВС понимают ее состав и схему функциональных и управляющих связей между ее элементами.
Введем определение термина «вычислительная машина», исходя из целей данного параграфа.
Вычислительная машина представляет собой совокупности технических средств, служащих для автоматизированной обработки дискретных данных по заданному алгоритму.
Алгоритм — одно из фундаментальных понятий математики и вычислительной техники.
Согласно ISO 2382/1-93 алгоритм — это конечный упорядоченный набор четко определенных правил для решения проблемы.
Помимо этой стандартизированной формулировки существуют и другие определения. Приведем наиболее распространенные из них. Алгоритм — это:
· способ преобразования информации, задаваемый с помощью конечной системы правил;
· совокупность правил, определяющих эффективную процедуру решения любой задачи из некоторого заданного класса задач;
· точно определенное правило действий, для которого задано указание, как и в какой последовательности это правило необходимо применять к исходным данным задачи, чтобы получить ее решение;
Основными свойствами алгоритма являются:
Дискретность выражается в том, что алгоритм описывает действия над дискретной информацией (например, числовой или символьной), причем сами эти действия также дискретны.
Свойство определенности означает, что в алгоритме указано все, что должно быть сделано, причем ни одно из действий не должно трактоваться двояко.
Массовость алгоритма подразумевает его применимость к множеству значений исходных данных, а не только к каким-то уникальным значениям.
Результативность алгоритма заключается в возможности получения результата за конечное число шагов.
Рассмотренные свойства алгоритмов предопределяют возможность их реализации на ВМ, при этом процесс, порождаемый алгоритмом, называют вычислительным процессом.
В основе архитектуры современных ВМ лежит представление алгоритма решения задачи в виде программы. Согласно стандарту ISO 2382/1-93, программа для ВМ состоит из команд, необходимых для выполнения функций, задач. Причем эти команды соответствуют правилам конкретного языка программирования.
Вычислительная машина(ВМ), где определенным образом закодированные команды программы хранятся в памяти, известна под названием вычислительной машины с хранимой в памяти программой.
Этаидея принадлежит создателям вычислителя ENIAC Эккерту, Мочли и фон Нейману. Еще до завершения работ над ENIAC они приступили к новому проекту — EDVAC, главной особенностью которого стала концепция хранимой в памяти программы, на долгие годы определившая базовые принципы построения последующих поколений вычислительных машин.
Относительно авторства существует несколько версий, но поскольку в законченном виде идея впервые была изложена в 1945 году в статье фон Неймана, именно его фамилия фигурирует в обозначении архитектуры подобных машин, составляющих подавляющую часть современного парка ВМ и ВС.
Сущность фон-неймановской концепции вычислительной машины можно свести к четырем принципам:
Рассмотрим эти принципы подробнее.
ü Принцип двоичного кодирования
Согласно этому принципу, вся информация, как данные, так и команды, кодируется двоичными цифрами 0 и 1. Каждый тип информации представляется в двоичном виде и имеет свой формат.
Последовательность битов в формате, имеющая определенный смысл, называется полем.
В формате числа обычно выделяют поле знака и поле значащих разрядов.
В формате команды можно выделить два поля (рис. 1):
· поле кода операции (КОП);
· поле адресов (адресную часть — АЧ).

Рис. 1. Структура команды
Код операции представляет собой указание, какая операция должна быть выполнена, и задается с помощью r- разрядной двоичной комбинации.
Вид адресной части и число составляющих ее адресов зависят от типа команды: в командах преобразования данных АЧ содержит адреса объектов обработки (операндов) и результата; в командах изменения порядка вычислений — адрес следующей команды программы; в командах ввода/вывода — номер устройства ввода/ вывода. Адресная часть также представляется двоичным кодом, длину которого обозначим через р. Таким образом, команда в вычислительной машине имеет вид (r + р) — разрядной двоичной комбинации.
ü Принцип программного управления
Все вычисления, предусмотренные алгоритмом решения задачи, должны быть представлены в виде программы, состоящей из последовательности управляющих слов — команд.
Каждая команда предписывает некоторую операцию из набора операций, реализуемых вычислительной машиной.
Команды программы хранятся в последовательности смежных ячеек памяти вычислительной машины и выполняются в естественном порядке, то есть в порядке их расположения в программе. При необходимости, с помощью специальных команд, естественный порядок выполнения может быть изменен. Решение об изменении порядка выполнения команд программы принимается либо на основании анализа результатов предшествующих вычислений, либо безусловно.
ü Принцип однородности памяти
Команды и данные хранятся в одной и той же памяти и внешне в памяти неразличимы. Распознать их можно только по способу использования. Это позволяет производить над командами те же операции, что и над числами, и, соответственно, открывает ряд возможностей.
Так, циклически изменяя адресную часть команды, можно обеспечить обращение к последовательности смежных элементов массива данных. Такой прием носит название модификации команд и с позиций современного программирования не приветствуется. Более полезным является другое следствие принципа однородности, когда команды одной программы могут быть получены как результат исполнения другой программы. Эта возможность лежит в основе трансляции — перевода текста программы с языка высокого уровня на машинный язык конкретной ВМ.
ü Принцип адресуемости памяти
Структурно основная память состоит из пронумерованных ячеек, причем процессору в произвольный момент доступна любая ячейка. Двоичные коды команд и данных разделяются на единицы информации, называемые словами, и хранятся в ячейках памяти, а для доступа к ним используются номера соответствующих ячеек — адреса.
Источник: studopedia.su