

В практической деятельности часто встречаются ситуаций, когда необходимо перевести в электронный вид документ, напечатанный на бумаге. В этом случае можно просто набрать документ на компьютере, что довольно трудоемко, либо воспользоваться сканером и OCR-системой.
Системы оптического распознавания текста (Optical Character Recognition — OCR-системы) предназначены для автоматического ввода печатных документов в компьютер.
Современные программы распознавания текста не только ошибаются реже, чем живой человек, но и обеспечивают проверку орфографии, автоматическое форматирование текста и массу других дополнительных удобств.
В последние годы ведущие позиции на российском рынке «распознавалок» удерживают программы FineReader и CuneiForm. Несмотря на свои замысловатые названия, обе программы отечественного производства и вполне хорошего качества.
Чаще всего для сканирования используют планшетный сканер, как наиболее доступный для рядового пользователя. При сканировании необходимо соблюдать определенные требования, от которых зависит успешность последующее распознавания текста:
EMGUCV. Распознавание текста с картинки. Урок 6
1. Выбирая оригинал для сканирования необходимо помнить, что чем лучше качество оригинала, тем лучше будут результаты сканирования и последующего распознавания.
2. Сканировать любое изображение (для последующего распознавания) лучше в оттенках серого – цветное изображение при распознавание дает дополнительные погрешности. Глубина цвета большого значения не имеет, лучше выбирать 8bit, так как при большей глубине увеличивается размер файла, а, следовательно, уменьшится скорость обработки изображения программой распознавания.
3. Разрешение должно быть не менее 300dpi
В настоящий момент существует более 20-ти программ, основная функции которых – распознавание текста.
Одной из популярных коммерческих программ оптического распознавания текстов является программа FineReader (http://www.abbyy.ru/finereader/), созданная компанией ABBYY Software House.
FineReader — шрифтонезависимая система оптического распознавания текстов. Это означает, что она позволяет распознавать тексты, набранные практически любыми шрифтами. Особенностями программы FineReader являются высокая точность распознавания и малая чувствительность к дефектам печати, что достигается благодаря применению технологии целостного целенаправленного адаптивного распознавания.
Программа отвечает требованиям совместимости с новыми операционными системами Microsoft, Macintosh, Linux и других ОС.
Таблица 9. Сравнение языковой функциональности продуктов FineReader для разных ОC
| Поддерживаемые ОС | Продукты | Кол-во языков распозна-вания | Кол-во языков, для которых предусмотрена словарная поддержка и проверка орфографии | Языки интер-фейса |
| Windows 8 (и не может быть установлена на операционную систему младше Windows XP | FineReader 11 Professional Edition | |||
| MacOS X10.4-7 (пока не поддерживает последнюю версию X 10.8 Mountain Lion) | FineReader Express Edition | |||
| Fedora 16, Debian/GNU Linux 6 Ubuntu 11.04 LTS, 11.10 | FineReader Engine 9.0 |
Программа для распознавания текста
Программа позволяет распознавать с высокой точностью тексты на 198 языках. Среди них естественные языки (русский, английский и др.), искусственные языки (идо, интерлингва, окциденталь, эсперанто), языки программирования (Basic, JAVA, Pascal, Fortran, C/C++, простые химические формулы). Версия программы для Mac OS не поддерживает искусственные языки и дает наименьшее количество языков для работы. Максимальное число языков дает версия программы для ОС на базе ядра Linux. Программа позволяет выводить на печать исходное изображение и распознанный текст, сохранять отсканированное изображение в различных форматах, настраивать панели инструментов программы.
По мнению разработчиков улучшения, внесенные в одиннадцатую версию ПО позволили увеличить скорость обработки документа на 20%, улучшилось качество обработки отдельных элементов (картинок, графиков, штрих-кодов, таблиц, колонтитулов, заголовок, текста на полях и др.).
Благодаря применению технологии Adaptive Document Recognition Technology (целостного целенаправленного адаптивного распознавания) ABBYY FineReader 11 превосходно сохраняет исходную структуру многостраничных документов, включая расположение текста, таблиц, колонтитулов, примечаний, нумерацию страниц, содержания, оглавления и др.
В новой версии появилась возможность форматировать документы непосредственно в программе. Улучшенный режим проверки результата распознавания позволит быстро исправить ошибки в тексте.
Помимо привычных форматов в новой версии появилась возможность сохранять результаты распознавания в популярные форматы электронных книг (fb2, ePub и др.), что поможет быстро сделать электронную копию для портативного устройства – бук-ридера, планшета, смартфона, и др.
Помимо продукта, требующего установки на компьютер, существует on-line сервис, предоставляемый на сайте разработчика (http://finereader.abbyyonline.com/ru). Требуется регистрация на сайте. На данный момент в день можно распознавать бесплатно по 4 страницы.
На этом же сайте представлен облачный ресурс ABBYY Cloud OCR SDK, предоставляющий возможность распознавания документов на сервере компании. (http://www.ocrsdk.com/). Предоставляется пробный период (90 дней) в течении которого сервисом можно пользоваться бесплатно, однако распознать можно не более 50-ти страниц. В случае необходимости распознать большее количество страниц, то на сайте предлагаются коммерческие пакеты.
Технология распознавания
Сложность машинного распознавания текстов заключается в том, что его невозможно построить по жесткому алгоритму хотя бы потому, что для написания одной и той же буквы существует множество вариантов написания (шрифт, начертание). Для того, чтобы получить корректный результат система должна их «осмыслить». Иными словами, для распознавания текста требуется моделирование рассуждений человека в подобной ситуации, а это принято обозначать термином «искусственный интеллект».
Исходя из принципа целостности распознаваемое изображение рассматривается как единый объект, состоящий из частей, связанных между собой пространственными соотношениями. По принципу целенаправленности распознавание строится как процесс выдвижения и целенаправленной проверки гипотез об объекте, а принцип адаптивности подразумевает способность системы к самообучению.
Для выдвижения гипотез о том, что может представлять собой изображение, применяются так называемые признаковые классификаторы. Они используют ряд признаков, на основе которых программа вычисляет степень близости распознаваемого изображения и известных ей классов изображений, после чего выдает список подходящих классов, т. е. гипотезу о принадлежности объекта к тому или иному классу. Кроме того, признаковые классификаторы применяются также и для повышения точности распознавания изображений с дефектами.
Полученный набор классов последовательно проверяется структурным классификатором, анализирующим каждый символ. Скажем, если FineReader полагает, что на странице изображена буква «Ф», он специально проверяет те признаки, которые должны быть именно у буквы «Ф», а не у какой-либо другой, сравнивая этот символ со структурным эталоном. Структурный эталон описывает символ как комбинацию структурных элементов (отрезок, дуга, кольцо, точка), находящихся в определенных отношениях между собой. Процесс распознавания делится на этапы выделения структурных элементов в изображении и сопоставления их с эталоном.
Если в окончательный список попало более одной гипотезы они попарно сравниваются с помощью дифференциальных классификаторов. Если структурный классификатор при распознавании символов не может однозначно выбрать одну из двух букв с похожим написанием, между этими конкурирующими гипотезами делается дифференциальный выбор. Например, есть две гипотезы: распознаваемый символ представляв собой строчную букву «ъ» или «ь». Чтобы сделать выбор, FineReader целенаправленно проанализирует левый верхний угол буквы, где имеется единственная отличительная деталь между этими буквами.
С завершением работы дифференциального классификатора заканчивается распознавание и начинается этап проверки итогового списка гипотез. Окончательная стадия распознавания осуществляется системой контекста — при наличии некоторого количества распознанных букв из слова программа, используя словарь, может «догадаться», что это за слово.
Базовые принципы целостности, целенаправленности и адаптации остаются неизменными от версии к версии программы FineReader, ведь именно они позволяют компьютеру приблизиться к логике мышления человека.
Помимо описанной выше программы существуют и другие программы.
Microsoft предлагает пользователям ПО, которое может помочь в переводе текста в электронный вариант: Microsoft Office Document Imaging входит в состав пакета Microsoft Office, позволял распознавать отсканированные документы. Не доступен в версии Microsoft Office 2010. ПО может читать небольшие изображения формата TIFF. Точность распознавания невысокая, предъявляет очень высокие требования к качеству и ориентации сканированного документа.
Свободно распространяемая открытая OCR-система CuneiForm (http://www.cuneiform.ru/), которая является предшественницей систем промышленного распознавания и понимания документов. Многие технологические новшества, результаты научных исследований, положенные в основу CuneiForm, успешно применяются и совершенствуются по сей день в коммерческих продуктах Cognitive Technologies. До 2009 года распространялась как коммерческая, с этого момента остановился процесс обновления.
Результаты работы программы можно редактировать в офисных программах и текстовых редакторах и сохранять в популярных форматах, проводить по ним полнотекстовый поиск. Распознавание документов возможно на 20 языках. Для повышения качества распознавания в программе используется словарная проверка. При этом стандартный словарь можно расширить за счет импорта новых слов из текстовых файлов.
Вопросы по теме:
1. Какие требования предъявляются основными OCR-системами к оригиналу и цифровой копии?
2. Что подразумевает принцип целостного, целенаправленного, адаптивного распространения?
3. Как функционально отличаются версии FineReader для различных ОС?
4. Какие другие сервисы и ПО позволяют распознавать тексты?
Источник: megaobuchalka.ru
Системы распознавания текста. Технология обработки текстовой информации

2. Необходимость в системах распознавания символов
С помощью сканера достаточно просто получить
изображение страницы текста в графическом файле.
Однако работать с таким текстом невозможно: как
любое сканированное изображение, страница с
текстом представляет собой графический файл обычную картинку. Текст можно будет читать и
распечатывать, но нельзя будет его редактировать и
форматировать. Для получения документа в формате
текстового файла необходимо провести распознавание
текста, то есть преобразовать элементы графического
изображения в последовательности текстовых
символов.
3. Программы распознавания текста
Преобразованием графического изображения в
текст занимаются специальные программы
распознавания текста (Optical Character
Recognition — OCR).
Наиболее распространенные системы оптического
распознавания символов:
ABBYY FineReader
CuneiForm от Cognitive
4. Получение электронного документа
1.
2.
3.
4.
5.
Отсканировать изображение (с помощью ПО
сканера);
Распознать структуру размещения текста на
странице: выделить колонки, таблицы, изображения
и т.д.
Выделенные текстовые фрагменты графического
изображения страницы необходимо преобразовать в
текст;
Проверка орфографии (если необходимо);
Сохранение в файл или передача текста в другое
приложение, например в Word.
5. Методы распознавания символов
Если исходный документ имеет типографское
качество то задача распознавания решается
методом сравнения с растровым шаблоном.
При распознавании документов с низким
качеством печати используется метод
распознавания символов по наличию в них
определенных структурных элементов
(отрезков, колец, дуг и др.).
6. ABBYY FineReader
FineReader — омнифонтовая система оптического
распознавания текстов. Это означает, что она
позволяет распознавать тексты, набранные
практически любыми шрифтами, без
предварительного обучения. Особенностью
программы FineReader является высокая точность
распознавания и малая чувствительность к
дефектам печати.
FineReader имеет массы дополнительных функций и
удобный интерфес.
7. Оптимальное разрешение при сканировании
Оптимальным разрешением для обычных текстов
является — 300 dpi и 400-600 dpi для текстов, набранных
мелким шрифтом (9 и менее пунктов).
Сканирование в сером является оптимальным режимом
для системы распознавания. В случае сканирования в
сером режиме осуществляется автоматический подбор
яркости. Если Вы хотите, чтобы содержащиеся в
документе цветные элементы (картинки, цвет букв и
фона) были переданы в электронный документ с
сохранением цвета, необходимо выбрать цветной тип
изображения. В других случаях используйте серый тип
изображения.
8. Вопросы:
Зачем нужны программы распознавания текста?
Как происходит распознавание текста?
Какие программы распознания текста вы знаете?
Какими пользовались?
Какое разрешение является оптимальным для
сканирования текста, изображений?
Источник: ppt-online.org
Презентация на тему: Системы распознавания текста

№ слайда 1
Описание слайда:
Системы распознавания текста Технология обработки текстовой информации

№ слайда 2
Описание слайда:
Необходимость в системах распознавания символов С помощью сканера достаточно просто получить изображение страницы текста в графическом файле. Однако работать с таким текстом невозможно: как любое сканированное изображение, страница с текстом представляет собой графический файл — обычную картинку. Текст можно будет читать и распечатывать, но нельзя будет его редактировать и форматировать. Для получения документа в формате текстового файла необходимо провести распознавание текста, то есть преобразовать элементы графического изображения в последовательности текстовых символов.

№ слайда 3
Описание слайда:
Основным методом перевода бумажных документов в электронную форму является сканирование. В результате сканирования получается графическое изображение, состоящее из точек, т.е. растровое изображение. Количество точек определяется как размером изображения, так и разрешением сканера.

№ слайда 4
Описание слайда:
Программы распознавания текста Графический образ, получаемый после сканирования документа, иногда необходимо перевести в текст. Для этого используются специальные программные средства, называемые средствами распознавания образов. Из программ, способных распознавать текст на русском языке наиболее известной является ABBYY Fine Reader.

№ слайда 5
Описание слайда:
Преобразование документа в электронный вид происходит в три основных этапа. Каждый из этих этапов может выполняться программами как автоматически, так и под контролем пользователя. 1. Сканирование. Запускается сканирующий модуль, настраиваются параметры сканирования (разрешение, размер, тип сканирования) и происходит собственно сканирование.
2. Сегментация и распознавание текста. Прежде чем получить готовый текст, необходимо разбить фрагменты документа на блоки (текст, рисунок, таблица и т.д.), для того, чтобы правильно их распознать (преобразовать в текстовый документ). 3. Проверка орфографии и передача текстового документа в нужное приложение для дальнейшей работы или сохранение в файл.

№ слайда 6
Описание слайда:
Методы распознавания символов Если исходный документ имеет типографское качество то задача распознавания решается методом сравнения с растровым шаблоном. При распознавании документов с низким качеством печати используется метод распознавания символов по наличию в них определенных структурных элементов (отрезков, колец, дуг и др.).

№ слайда 7
Описание слайда:
Сканер Сканер (англ. scanner) — устройство, которое создаёт цифровое изображение сканируемого объекта. Полученное изображение может быть сохранено как графический файл, или, если оригинал содержал текст, распознано посредством программы распознавания текста и сохранено как текстовый файл.

№ слайда 8
Описание слайда:
В зависимости от способа сканирования объекта и самих объектов сканирования существуют следующие виды сканеров: Планшетные — наиболее распространённые, поскольку обеспечивают максимальное удобство для пользователя — высокое качество и приемлемую скорость сканирования. Представляет собой планшет, внутри которого под прозрачным стеклом расположен механизм сканирования. Барабанные — применяются в полиграфии, имеют большое разрешение (около 10 тысяч точек на дюйм). Оригинал располагается на внутренней или внешней стенке прозрачного цилиндра (барабана).

№ слайда 9
Описание слайда:
следовательно, объект приходится сканировать вручную, единственным его плюсом является дешевизна и мобильность, при этом он имеет массу недостатков — низкое разрешение, малую скорость работы, узкая полоса сканирования, возможны перекосы изображения, поскольку пользователю будет трудно перемещать сканер с постоянной скоростью. Сканеры штрих-кода — небольшие, компактные модели для сканирования штрих-кодов товара в магазинах.
№ слайда 10
Описание слайда:
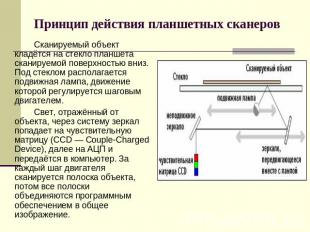
Принцип действия планшетных сканеров Сканируемый объект кладётся на стекло планшета сканируемой поверхностью вниз. Под стеклом располагается подвижная лампа, движение которой регулируется шаговым двигателем. Свет, отражённый от объекта, через систему зеркал попадает на чувствительную матрицу (CCD — Couple-Charged Device), далее на АЦП и передаётся в компьютер. За каждый шаг двигателя сканируется полоска объекта, потом все полоски объединяются программным обеспечением в общее изображение.

№ слайда 11
Описание слайда:
Характеристики сканеров Формата сканируемой поверхности: А4 (стандартный печатный лист), A3, слайд-сканеры под формат пленки 13х18 и 18х24… Оптическое разрешение. Разрешение измеряется в точках на дюйм (dots per inch — dpi). Указывается два значения, например 600×1200 dpi, горизонтальное — определяется матрицей CCD, вертикальное — определяется количеством шагов двигателя на дюйм.
Интерполированное разрешение. Искусственное разрешение сканера достигается при помощи программного обеспечения. Его практически не применяют, потому что лучшие результаты можно получить, увеличив разрешение с помощью графических программ после сканирования. Используется производителями в рекламных целях. Скорость работы.
Измеряется в страницах в минуту, при этом имеются в виду страницы определенного формата и определенное разрешение сканнера, из числа возможных. Глубина цвета. Определяется качеством матрицы CCD и разрядностью АЦП. Измеряется количеством оттенков, которые устройство способно распознать. 24 бита соответствует 16777216 оттенков.
Современные сканеры выпускают с глубиной цвета 24, 30, 36 бит. Несмотря на то, что графические адаптеры пока не могут работать с глубиной цвета больше 24 бит, такая избыточность позволяет сохранить больше оттенков при преобразованиях картинки в графических редакторах.

№ слайда 12
Описание слайда:
Оптимальное разрешение при сканировании Оптимальным разрешением для обычных текстов является — 300 dpi и 400-600 dpi для текстов, набранных мелким шрифтом (9 и менее пунктов). Сканирование в сером является оптимальным режимом для системы распознавания. В случае сканирования в сером режиме осуществляется автоматический подбор яркости. Если Вы хотите, чтобы содержащиеся в документе цветные элементы (картинки, цвет букв и фона) были переданы в электронный документ с сохранением цвета, необходимо выбрать цветной тип изображения. В других случаях используйте серый тип изображения.

№ слайда 13
Описание слайда:
ABBYY FineReader FineReader — омнифонтовая система оптического распознавания текстов. Это означает, что она позволяет распознавать тексты, набранные практически любыми шрифтами, без предварительного обучения. Особенностью программы FineReader является высокая точность распознавания и малая чувствительность к дефектам печати. FineReader имеет массы дополнительных функций и удобный интерфейс.

№ слайда 14
Описание слайда:

№ слайда 15
Источник: ppt4web.ru