
Возможность поиска и очистки больших данных имеет важное значение в 21 веке. Правильные инструменты являются обязательным условием для конкуренции с конкурентами и добавления преимуществ для вашего бизнеса. Я делаю список из 30 лучших инструментов для больших данных для вас.
6709 просмотров
Часть 1. Инструменты извлечения данных
Parsehub es un rastreador basado en web (web-based crawler). Puede extraer datos que manejan sitios web dinámicos con AJax, JavaScripts y detrás del inicio de sesión. Tiene una ventana de prueba gratuita de una semana para que los usuarios experimenten sus funcionalidades.
Content Graber — это программное обеспечение для расширенного извлечения. Имеет среду программирования для серверов разработки, тестирования и производства. Вы можете использовать C # или VB.NET для отладки или написания скриптов для управления трекером. Это также позволяет вам добавлять сторонние расширения поверх вашего трекера. Благодаря обширным возможностям Content Grabber чрезвычайно эффективен для пользователей с базовым пониманием технологий.
Все, что нужно знать о профессии аналитика данных
Import.io — это веб-инструмент для извлечения данных. Впервые он был запущен в Лондоне. Теперь import.io меняет свою бизнес-модель с B2C на B2B. В 2019 году Import.io приобрел Connotate и стал платформой для интеграции веб-данных . Import.io — это отличный выбор для бизнес-анализа.
Mozenda — это программное обеспечение для просмотра веб-страниц, которое также предоставляет сервис очистки для извлечения данных на уровне предприятия . Вы можете извлекать обновляемые данные из облачного программного обеспечения и локального программного обеспечения.
Часть 2: Инструменты с открытым исходным кодом
KNIME Analytics Platform — аналитическая платформа. Это может помочь вам обнаружить бизнес-идеи и весь потенциал на рынках. Он предоставляет платформу Eclipse вместе с другими внешними расширениями для интеллектуального анализа данных и машинного обучения. Он предлагает более 2 тысяч модулей для профессионалов-аналитиков, готовых к внедрению.
OpenRefine (ранее Google Refine) — это мощный инструмент для работы с грязными данными : очистки, преобразования и связывания наборов данных. С его групповыми функциями вы можете нормализовать данные, как вам нравится.
Это бесплатное программное обеспечение языка программирования и графики и статистического расчета программного обеспечения. Язык R популярен среди майнеров данных для разработки статистического программного обеспечения и анализа данных. Заработайте кредиты и популярность в последние годы благодаря простоте использования и обширной функциональности.
Помимо интеллектуального анализа данных, он также предоставляет статистические и графические методы, линейное и нелинейное моделирование, классические статистические тесты, анализ временных рядов, классификацию, группирование и многое другое.
Как и KNIME, RapidMiner работает через визуальное программирование и способен манипулировать, анализировать и моделировать . Повышение производительности работы с данными с помощью платформы с открытым исходным кодом, машинного обучения и развертывания моделей. Унифицированная платформа для обработки данных ускоряет аналитические процессы от подготовки данных к внедрению. Значительно повышает эффективность.
Основы программирования для начинающих. Урок 1. Как работают программы.
Это отличное программное обеспечение для бизнес-аналитики, которое помогает компаниям принимать решения на основе данных. Как и большинству компаний, трудно получить ценность из данных. Платформа объединяет источники данных , включая локальную базу данных, Hadoop и NoSQL. В результате вы можете легко анализировать данные и управлять ими.
Это программное обеспечение с открытым исходным кодом, предназначенное для преобразования данных в информацию. Он предоставляет различные услуги и программное обеспечение, включая облачное хранилище, интеграцию бизнес-приложений, управление данными и т. Д. При поддержке обширного сообщества он позволяет всем пользователям и членам Talend обмениваться информацией, опытом, вопросами из любого места.
Weka — это набор алгоритмов машинного обучения для задач интеллектуального анализа данных . Алгоритмы могут быть применены непосредственно к набору данных или вызваны из его собственного кода JAVA. Он также подходит для разработки новых схем машинного обучения. С помощью графического интерфейса вы можете привлечь профессионалов, которым не хватает навыков программирования, в мир наук о данных.
Это программный пакет с открытым исходным кодом для Microsoft Excel. В качестве дополнительного расширения у него нет сервисов и функций интеграции данных. Основное внимание уделяется анализу социальных сетей. Интуитивно понятные сети и описательные отношения облегчают анализ социальных сетей. Являясь одним из лучших статистических инструментов для анализа данных, он включает в себя расширенные сетевые метрики, доступ к импортерам данных из социальных сетей и автоматизацию.
Gephi также представляет собой пакет программного обеспечения с открытым исходным кодом для визуализации и анализа сети, написанный на Java на платформе NetBeans . Подумайте об огромной сети отношений, которые вы видите, которые представляют соединения LinkedIn или Facebook. Gephi идет дальше, предоставляя точные расчеты.
Часть 3: Визуализация данных
Microsoft PowerBI предоставляет локальные и облачные сервисы. Впервые он был представлен как надстройка Excel. Вскоре PowerBI набирает популярность благодаря своим мощным функциям. На данный момент вы воспринимаетесь как лидер в аналитике. Он обеспечивает визуализацию данных и возможности бизнес-аналитики, которые позволяют пользователям творчески и инновационно создавать отчеты и информационные панели с минимальными затратами.
Solver специализируется на программном обеспечении корпоративного управления эффективностью (CPM). Его программное обеспечение BI360 доступно для локального и облачного развертывания, которое сосредоточено на четырех ключевых аналитических областях, включая финансовую отчетность, бюджетирование и информационные панели, а также хранилище данных.
Qlik — это инструмент для визуализации и анализа данных самообслуживания . Визуализированные информационные панели, которые помогают компании с легкостью «понять» эффективность бизнеса.
Tableau — это интерактивный инструмент визуализации данных. «В отличие от» большинства инструментов визуализации, которые требуют сценариев. Tableau помогает новичкам «преодолеть» трудности практической работы. Функции перетаскивания упрощают анализ данных. У них также есть «стартовый комплект» и богатый источник обучения, чтобы помочь пользователям создавать инновационные отчеты.
Fusion Table — это платформа управления данными, предоставляемая Google . Вы можете использовать его для сбора, просмотра и обмена данными. Это похоже на электронную таблицу, но гораздо более мощный и профессиональный. Вы можете сотрудничать с университетами, добавив их CSV, KML и набор данных электронных таблиц. Вы также можете опубликовать свою работу с данными и встроить ее в другие веб-ресурсы.
Infogram предоставляет более 35 интерактивных диаграмм и более 500 карт, которые помогут вам визуализировать данные. В дополнение к различным диаграммам (включая гистограммы, гистограммы, круговые диаграммы или облака слов) существуют инновационные форматы инфографики.
Часть 4: Анализ чувств
Он имеет инструмент обратной связи с клиентами, который собирает отзывы и мнения клиентов. Затем они анализируют языки, используя НЛП, чтобы прояснить положительные и отрицательные намерения. Просмотр результатов с графиками и таблицами на панелях. Также вы можете подключить HubSpot ServiceHub к системе CRM. В результате вы можете связать результаты опроса с конкретным контактом.
Таким образом, вы можете выявлять недовольных клиентов и своевременно предоставлять качественные услуги, чтобы увеличить удержание клиентов.
Semantria — это инструмент, который может собирать сообщения, твиты и комментарии из социальных сетей. Используйте обработку естественного языка для анализа текста и анализа отношения клиентов. Таким образом, компании могут получать полезную информацию и предлагать лучшие идеи для улучшения своих продуктов и услуг.
Инструменты мониторинга социальных сетей Trackur могут отслеживать информацию в Интернете из разных источников. Отслеживайте большое количество веб-страниц, включая видео, блоги, форумы и изображения, чтобы найти связанные сообщения. С его сложными функциями, вы можете получить необходимые данные. Не преследуйте телефон и не отправляйте рекламные письма.
Наиболее сложной частью анализа веб-текста является поиск плохо написанного текста. SAS может легко исправить и сгруппировать его. Благодаря обработке на естественном языке на основе правил SAS может эффективно классифицировать сообщения.
Вы можете анализировать комментарии, сообщения, форумы, новостные сайты и другие источники из более чем 10 миллионов на более чем 50 языках . Кроме того, вы можете классифицировать жанры и места. Это позволяет вам составлять стратегические маркетинговые планы, ориентированные на конкретные группы. Вы также можете получить доступ к данным в реальном времени и извлечь онлайн-разговор.
Часть 5. Databases
Нет сомнений в том, что Oracle является чемпионом среди баз данных с открытым исходным кодом. Благодаря многочисленным функциям, это лучший вариант для компании . Он также поддерживает интеграцию различных платформ. Простота настройки в AWS делает его надежным выбором для реляционной базы данных. Высокий уровень безопасности для интеграции личных данных, таких как кредитные карты, делает их незаменимыми.
Он превосходит Oracle, MySQL, Microsoft SQL Server и становится четвертой по популярности базой данных. Обладая высокой стабильностью, он может обрабатывать большие объемы данных.
Это облачное программное обеспечение для баз данных, которое имеет широкие возможности таблиц данных для сбора и отображения информации. Он также имеет электронную таблицу и встроенный календарь, чтобы легко отслеживать задачи. Работать с вашими начальными шаблонами легко с помощью Lead Management, Bug Tracking и Lead Tracking.
Это бесплатная база данных с открытым исходным кодом для хранения, вставки, изменения и восстановления данных. Кроме того, Мария поддерживает сильное сообщество с активными членами для обмена информацией и знаниями.
Improvado — это инструмент, созданный для маркетологов, чтобы получать все свои данные в одном месте, в режиме реального времени , с помощью автоматических панелей и отчетов. Вы можете просмотреть свои данные на панели инструментов Improvado или направить их в хранилище данных или инструмент визуализации по вашему выбору, например, Tableau, Looker, Excel и т. Д. Бренды, агентства и университеты любят использовать Improvado, потому что это экономит им тысячи часов ручного отчета и миллионы долларов в маркетинге.
Источник: vc.ru
Программы и данные
Презентация наглядно демонстрирует программный принцип обработки данных. За основу взят материал из учебника Н.Д.Угриновича.
Быкова Юлия Викторовна
Описание разработки
Объяснить учащимся за один раз, как устроен компьютер и как организована его работа, наверное, не удавалось никому. К этому вопросу приходится возвращаться снова и снова, двигаясь по дидактической спирали. И здесь, как может быть ни в какой другой теме наглядность необходима для осознанного усвоения материала.
Меж тем в учебниках и тех презентациях по теме, которые мне удалось найти, для наглядности в лучшем случае есть функциональная схема компьютера с перечислением основных устройств и их назначений. Но, как показывает опыт, изображение такой схемы не достигает своей цели. Она несет слишком много информации для учащихся, и как всегда в таких случаях, воспринимается только часть материала.
Данная презентация предназначена для более глубокого понимания назначения основных устройств компьютера и того, как в нем протекает программная обработка данных. Все эти процессы я попыталась отразить наглядно, используя средства анимации, чтобы продемонстрировать, как они происходят во времени.
Для удобства подготовки к уроку все слайды снабжены заметками для учителей и преподавателей.
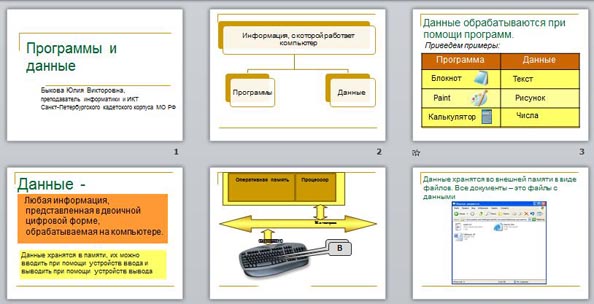
Данные обрабатываются при помощи программ.
Разные программы работают с разными данными. Приведем примеры. С какими данными работает программа Блокнот? Paint? Калькулятор? (для сильных учащихся возможен вопрос, а что является данными для компилятора программ на Паскале?)
Данные — любая информация, представленная в двоичной цифровой форме, обрабатываемая на компьютере.
Данные хранятся в памяти, их можно вводить при помощи устройств ввода и выводить при помощи устройств вывода.
Источник: videouroki.net
Big Data: что такое большие данные и где они применяются
В статье расскажем о характеристиках и классификации больших данных, методах обработки и хранения, областях применения и возможностях работы с Big Data, которые дает Selectel.

Big Data простыми словами — структурированные, частично структурированные или неструктурированные большие массивы данных. В статье мы расскажем о характеристиках и классификации больших данных, методах обработки и хранения, областях применения и возможностях работы с Big Data, которые дает Selectel.
Характеристики больших данных
Несмотря на актуальность для многих сфер, границы термина размыты и могут отличаться в зависимости от конкретной задачи. Тем не менее существуют три основных признака, определенные еще в 2001 году Meta Group. Они получили аббревиатуру VVV:
Volume. Объем данных чаще всего измеряется терабайтами, петабайтами и даже эксабайтами. Нет точного понимания, с какого объема данные становятся «большими». Существуют задачи, когда информация занимает меньше терабайта, но из-за неоднородной структуры их обработка требует мощности кластера из пяти серверов.
Velocity. Скорость прироста и обработки данных. Яркий пример — новые данные для анализа появляются с каждым сеансом пользователя «ВКонтакте». Подобные потоки информации требуют высокоскоростной обработки. Если для обработки данных достаточно одной машины, это не Big Data.
Число серверов в кластере всегда превышает единицу.
Variety. Разнообразие данных. Даже если информации очень много, но она имеет четкую и ясную структуру — это не Big Data. Возвращаясь к примеру с «ВКонтакте», биографии пользователей соцсети структурированные и легко поддаются анализу. А вот данные о реакциях на посты или времени, проведенном в приложении, не имеют точной структуры.
И еще два V
В дальнейшем появилась интерпретация c «пятью V»:
Viability. Жизнеспособность данных. При большом разнообразии данных и переменных, необходимо проверять их значимость при построении модели прогнозирования. Например, факторы предсказывающие склонность потребителя к покупке: упоминания товара в соцсетях, геолокация, доступность товара, время суток, портрет покупателя.
Value. Ценность данных. После подтверждения жизнеспособности специалисты Big Data изучают взаимосвязи данных. Например, поставщик услуг может попытаться сократить отток клиентов, анализируя продолжительность звонков в колл-центр. После оценки дополнительных переменных прогнозная модель становится сложнее и эффективнее. Пример итогового вывода — повышенную склонность к оттоку в течение 45 дней после своего дня рождения демонстрируют клиенты попадающие в категории:
- геопозиция — юго-запад России с теплой погодой,
- образование — степень бакалавра,
- имущество — владельцы автомобилей 2012 года выпуска или более ранних моделей,
- кредитная история без просрочек.
Классификация данных
Структурированные данные. Как правило, хранятся в реляционных базах данных. Упорядочивают данные на уровне таблиц — например, Excel. От информации, которую можно анализировать в самом Excel, Big Data отличается большим объемом.
Частично структурированные. Данные не подходят для таблиц, но могут быть иерархически систематизированы. Под такую характеристику подходят текстовые документы или файлы с записями о событиях.
Неструктурированные. Не обладают организованной структурой: аудио- и видеоматериалы, фото и другие изображения.
Источники данных
- Генерируемые людьми социальные данные, главные источники которых — соцсети, веб, GPS-данные о перемещениях. Также специалисты Big Data используют статистические показатели городов и стран: рождаемость, смертность, уровень жизни и любую другую информацию, отражающую показатели жизни людей.
- Транзакционная информация появляется при любых денежных операциях и взаимодействии с банкоматами: переводы, покупки, поставки.
- Источником машинных данных служат смартфоны, IoT-гаджеты, автомобили и другая техника, датчики, системы слежения и спутники.
Как данные забирают из источника
Начальная стадия — Data Cleaning — выявление, очистка и исправление ошибок, нерелевантной информации и несоответствий данных. Процесс позволяет оценить косвенные показатели, погрешности, пропущенные значения и отклонения. Как правило, во время извлечения данные преобразуются. Специалисты Big Data добавляют дополнительные метаданные, временные метки или геолокационные данные.
Существует два подхода к извлечению структурированных данных:
- Полное извлечение, при котором нет потребности отслеживать изменения. Процесс проще, но нагрузка на систему выше.
- Инкрементное извлечение. Изменения в исходных данных отслеживают с момента последнего успешного извлечения. Для этого создают таблицы изменений или проверяют временные метки. Многие хранилища имеют встроенную функцию захвата данных об изменениях (CDC), которая позволяет сохранить состояния данных. Логика для инкрементального извлечения более сложная, но нагрузка на систему снижается.
При работе с неструктурированными данными большая часть времени уйдет на подготовку к извлечению. Данные очищают от лишних пробелов и символов, удаляют дубликаты результатов и определяют способ обработки недостающих значений.
Подходы к хранению Big Data
Для хранения обычно организуют хранилища данных (Data Warehouse) или озера (Data Lake). Data Warehouse использует принцип ETL (Extract, Transform, Load) — сначала идет извлечение, далее преобразование, потом загрузка. Data Lake отличается методом ELT (Extract, Load, Transform) — сначала загрузка, следом преобразование данных.
Существуют три главных принципа хранения Big Data:
Горизонтальное масштабирование. Система должна иметь возможность расширяться. Если объем данных вырос — необходимо увеличить мощность кластера путем добавления серверов.
Отказоустойчивость. Для обработки требуются большие вычислительные мощности, что повышает вероятность сбоев. Большие данные должны обрабатываться непрерывно в режиме реального времени.
Локальность. В кластерах применяется принцип локальности данных — обработка и хранение происходит на одной машине. Такой подход минимизирует расходы мощностей на передачу информации между серверами.
Анализ больших данных: от web mining до визуализации аналитики
Интеллектуальный анализ данных представляет из себя совокупность подходов к классификации, моделированию и прогнозированию.
Анализ может включать в себя добычу различных видов информации, будь то текст, изображения, аудио- и видеоданные. Отдельно выделяют web mining и social media mining, работающие с интернетом и соцсетями. Для работы с реляционными базами данных используется язык программирования SQL, подходящий для создания, изменения и извлечения хранимых данных.
Нейронные сети. Обученная нейросеть может обрабатывать огромные объемы данных с большой скоростью и точностью. Чтобы использовать нейросеть в анализе, ее необходимо обучить.
Машинное обучение — наука о том, как обучить ИИ самостоятельной работе и расширению своих знаний и возможностей. Сфера ML изучает, как создавать системы, которые автономно улучшаются с приобретением опыта. Алгоритмы машинного обучения обобщают уже имеющиеся примеры для выполнения более сложных задач. С помощью этой технологии искусственный интеллект проводит анализ, строит прогнозы, воспроизводит и улучшает модели.
После анализа данные представляют в виде аналитического отчета с предложениями о возможных решениях. Методы перевода больших данных в читаемую форму называются Business intelligence. Главный инструмент BI — дашборды, интерпретация и визуализация аналитики в виде изображений и диаграмм. Дашборды помогают фокусировать внимание на KPI, создавать бизнес-модели и отслеживать результаты принятых решений.
Эта обратная связь и дает возможности для роста бизнеса, которые можно получить с помощью Big Data. Неочевидные раньше закономерности способствуют улучшению бизнес-процессов и росту прибыли.
Работайте с Big Data на инфраструктуре Selectel
От серверов с мощными GPU до полноценной платформы обработки данных.
Инструменты для обработки больших данных
Один из способов распределенных вычислений — разработанный Google метод параллельной обработки MapReduce. Фреймворк организовывает данные в виде записей. Функции работают независимо и параллельно, что обеспечивает соблюдение принципа горизонтальной масштабируемости. Обработка происходит в три стадии:
- Map. Функцию определяет пользователь, map служит начальной обработке и фильтрации. Функция применима к одной входной записи, она выдает множество пар ключ-значение. Применяется на том же сервере, на котором хранятся данные, что соответствует принципу локальности.
- Shuffle. Вывод map разбирается по «корзинам». Каждая соответствует одному ключу вывода первой стадии, происходит параллельная сортировка. «Корзины» служат входом для третьей стадии.
- Reduce. Каждая «корзина» со значениями попадает на вход функции reduce. Ее задает пользователь и вычисляет финальный результат для каждой «корзины». Множество всех значений функции reduce становится финальным результатом.
Для разработки и выполнения программ, работающих на кластерах любых размеров, используется набор утилит, библиотек и фреймворк Hadoop. ПО Apache Software Foundation работает с открытым исходным кодом и служит для хранения, планирования и совместной работы с данными. Об истории и структуре проекта Hadoop можно почитать в отдельном материале.
Apache Spark — open-source фреймворк, входящий в экосистему Hadoop, используется для кластерных вычислений. Набор библиотек Apache Spark выполняет вычисления в оперативной памяти, что заметно ускоряет решение многих задач и подходит для машинного обучения.
NoSQL — тип нереляционных СУБД. Хранение и поиск данных моделируется отличными от табличных отношений средствами. Для хранения информации не требуется заранее заданная схема данных. Главное преимущество подобного подхода — любые данные можно быстро помещать и извлекать из хранилища. Термин расшифровывается как «Not Only SQL».
Примеры подобных СУБД
Все базы данных относятся к «семейству» Amazon:
- DynamoDB — управляемая бессерверная БД на основе пар «ключ-значение», созданная для запуска высокопроизводительных приложений в любом масштабе, подходит для IoT, игровых и рекламных приложений.
- DocumentDB — документная БД, создана для работы в каталогах, пользовательских профилях и системах управления контентом, где каждый документ уникален и изменяется со временем.
- Neptune — управляемый сервис графовых баз данных. Упрощает разработку приложений, работающих с наборами сложносвязанных данных. Подходит для работы с рекомендательными сервисами, соцсетями, системами выявления мошенничества.
Самые популярные языки программирования для работы с Big Data
- R. Язык используется для обработки данных, сбора статистики и работы с графикой. Загружаемые модули связывают R с GUI-фреймворками и позволяют разрабатывать утилиты анализа с графическим интерфейсом. Графика может быть экспортирована в популярные форматы и использована для презентаций. Статистика отображается в виде графиков и диаграмм.
- Scala. Нативный язык для Apache Spark, используется для анализа данных. Проекты Apache Software Foundation, Spark и Kafka, написаны в основном на Scala.
- Python. Обладает готовыми библиотеками для работы с AI, ML и другими методами статистических вычислений: TensorFlow, PyTorch, SKlearn, Matplotlib, Scipy, Pandas. Для обработки и хранения данных существуют API в большинстве фреймворков: Apache Kafka, Spark, Hadoop.
Про то, как устроен и работает брокер сообщений Apache Kafka мы писали в отдельной статье.
Примеры использования аналитики на основе Big Data: бизнес, IT, медиа
Большие данные используют для разработки IT-продуктов. Например, в Netflix прогнозируют потребительский спрос с помощью предиктивных моделей для новых функций онлайн-кинотеатра. Специалисты стриминговой платформы классифицируют ключевые атрибуты популярности фильмов и сериалов, анализируют коммерческий успех продуктов и фич. На этом построена ключевая особенность подобных сервисов — рекомендательные системы, предсказывающие интересы пользователей.
В геймдеве используют большие данные для вычисления предпочтений игроков и анализа поведения в видеоиграх. Подобные исследования помогают совершенствовать игровой опыт и схемы монетизации.
Для любого крупного производства Big Data позволяет анализировать доходы и обратную связь от заказчиков, детализировать сведения о цепочках производства и логистике. Подобные факторы улучшают прогноз спроса, сокращают расходы и простои.
Big Data помогает со слабоструктурированными данными о запчастях и оборудовании. Записи в журналах и сведения с датчиков могут быть индикаторами скорой поломки. Если ее вовремя предсказать, это повысит функциональность, срок работы и эффективность обслуживания техники.
В сфере торговли анализ больших данных дает глубокие знания о моделях поведения клиентов. Аналитика информации из соцсетей и веб-сайтов улучшает качество сервиса, повышает лояльность и решает проблему оттока покупателей.
В медицине Big Data поможет с анализом статистики использования лекарств, эффективности предоставляемых услуг, с организацией работы с пациентами.
В банках используют распределенные вычисления для работы с транзакционной информацией, что полезно для выявления мошенничества и улучшения работы сервисов.
Госструктуры анализируют большие данные для повышения безопасности граждан и совершенствования городской инфраструктуры, улучшения работы сфер ЖКХ и общественного транспорта.
Это лишь часть сфер, где растет востребованность аналитики больших данных. В интересантах не только технические направления, но и медиа, маркетинг, социология, сфера найма, недвижимость.
Управление большими данными — кто занимается
Люди, работающие с большими данными, разделяются по многим специальностям:
- аналитик Big Data,
- дата-инженер,
- Data Scientist,
- ML-специалист и др.
Учитывая высокий спрос, для работы в сфере требуются специалисты разных компетенций. Например, существует направление data storytelling — умение эффективно донести до аудитории информацию из набора данных с помощью повествования и визуализации. Для понимания контекста используются сюжетные линии и персонажи, графики и диаграммы, изображения и видео.
Рассказы о данных используют внутри компании, чтобы на основе представленной информации донести до сотрудников необходимость улучшения продукта. Другое применение — презентация потенциальным клиентам аргументов в пользу покупки продукта.
Источник: selectel.ru