
Многие знают что такое тест дизайн, но не все умеют его применять. Чтобы немного прояснить ситуацию, мы решили предложить Вашему вниманию последовательный подход к разработке тестовых случаев (тест кейсов), используя самые простейшие техники тест дизайна:
- Эквивалентное Разделение (Equivalence Partitioning), далее в тексте — EP
- Анализ Граничных Значений (Boundary Value Analysis), далее в тексте — BVA
- Предугадывание ошибки (Error Guessing), далее в тексте — EG
- Причина / Следствие (Cause/Effect), далее в тексте — CE
План разработки тест кейсов предлагается следующий:
- Анализ требований.
- Определение набора тестовых данных на основании EP, BVA, EG.
- Разработка шаблона теста на основании CE.
- Написание тест кейсов на основании первоначальных требований, тестовых данных и шагов теста.
Далее на примере, рассмотрим предложенный подход.
Протестировать функциональность формы приема заявок, требования к которой предоставлены в следующей таблице:
Нет времени на тесты? Все наоборот! Главная хитрость тестирования.
- Консультация
- Проведение тестирования
- Размещение рекламы
- Ошибка на сайте
* — на процесс выполнения операции приема заявок не влияет.
1. Обязательное для заполнения
2. Максимально 25 символов
3. Использование цифр и спец символов не допускается
- Обязательное для заполнения
- Допустимые символы «+» и цифры
- «+» можно использовать только в начале номера
- Допустимые форматы:
- начинается с плюса — 11-15 цифр
+31612361264
+375291438884 - без плюса — 5-10 цифр, например:
0613261264
2925167
1. Обязательное для заполнения
2. Максимальная длина 1024 символа
1. По умолчанию — не активна (Disabled)
2. После заполнения обязательных полей становится активна (Enabled)
Действия после нажатия
1. Если введенные данные корректны — отправка сообщения
2. Если введенные данные НЕ корректны — валидационное сообщение
Вариант использования (иногда его может и не быть):
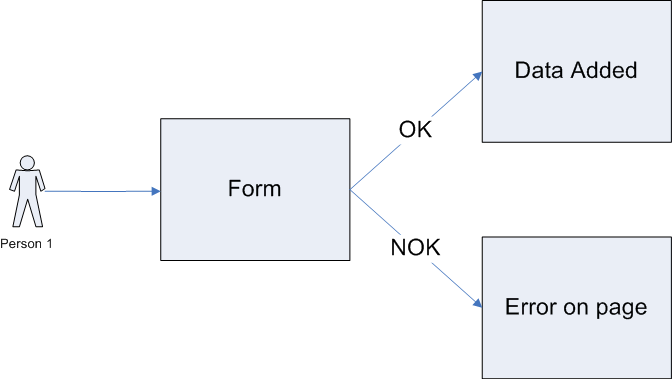
1. Анализ требований
Читаем, анализируем требования и выделяем для себя следующие нюансы:
- какие из полей обязательные для заполнения?
- имеют ли поля ограничения по длине или по размерности (границы)?
- какие из полей имеют специальные форматы?
2.Определение набора тестовых данных
Отталкиваясь от требований к полям, используя техники тест дизайна начинаем определение набора тестовых данных:
- в зависимости от того обязательное поле или нет, определим какие поля необходимо проверить на пустое значение, так как оно может вызывать ошибку (В результирующей таблице оранжевый цвет)
- т.к. исчерпывающее тестирование не представляется возможным из-за огромного числа всевозможных комбинаций значений, в первую очередь необходимо определить минимальный набор данных. Это можно сделать используя такие техники, как EP и BVA. (В результирующей таблице голубой цвет)
- На форме присутствует поле, имеющее составной тип (цифры используются совместно с символами), обладает специальным форматом данных и поэтому выделение тестовых данных для него — это достаточно трудоемкая задача. В пределах данной статьи ограничимся только простой проверкой форматов и основных требований описанных в форме приема заявок.
- По завершению генерации данных используя стандартные техники, можно добавить некоторое количество значений на основании личного опыта (техника EG) — это будет использование спец. символов, очень длинных строк, разных форматов данных, регистров в строках (Upper, Lowwer, Mixed cases), отрицательные и нулевые значения, кейворды Null — NaN — Infinity и т.д. Сюда можно включить все, что вы полагаете может вывести приложение из строя (В результирующей таблице фиолетовый цвет)
Отметим, что количество тестовых данных после окончательной генерации будет достаточно большим, даже при использовании специальных техник тест дизайна. Поэтому ограничимся лишь несколькими значениями для каждого поля, так как цель данной статьи показать именно процесс создания тест кейсов, а не процесс получения конкретных тестовых данных.
Лекция 113: Тестирование программ
2.1 Выбор тестовых данных для каждого отдельно взятого поля
- Поле Тип обращения. Так как все данные входят в 1 класс эквивалентности, то есть не изменяют сам процесс выполнения приема заявки, берем любою (1-ю) позицию в листе с ожидаемым результатом ОК. Но т.к. реализовано поле как лист, имеет также смысл рассмотреть и граничные условия (техника BVA), т.е. берем первый и последний элементы. Итого: 1-я и последняя позиции в листе. Ожидаемый результат при использовании — ОК.
- Поле Контактное лицо. Это обязательное поле размером от 1 до 25 символов (включая границы). Проверка на обязательность добавляет к тестовым данным пустое значение. Проведем анализ граничных условий (BVA), получим набор: 0, 1, 2, 24, 25 и 26 символов. Пустое значение (0 символов) уже было добавлено при анализе обязательности поля для ввода, поэтому при BVA мы не будем добавлять его еще раз. (если его добавить второй раз, произойдет дублирование тестовых данных, которое не приведет к нахождению новых дефектов, а значит повторное добавление в домен не имеет смысла). В связи с тем, что значения 2 и 24 символа являются, с нашей точки зрения, некритичными, их можно не добавлять. В итоге получаем, что минимальный набор данных для тестирования поля — это строки 1 и 25 — ОК, и 0 (пустое значение), 26 символов — NOK.
- поле Контактный телефон состоит из нескольких частей: код страны, код оператора, номер телефон (который может быть составной и разделенный дефисами). Для определения правильного набора тестовых данных необходимо рассматривать каждую составную часть по-отдельности. Применяя BVA и EP, получим:
- для номеров с плюсом
По BVA получим номера с 10, 11, 12 и 14, 15, 16 цифрами, где 10 и 16 — NOK, а 11, 12, 14, 15 — OK
Рассматривая полученные данные с позиции EP выделим, что 11, 12, 14, 15 входят в один класс эквивалентности. Поэтому при тестировании мы можем использовать любое из них, но так как 11 и 15 — это границы интервала, то на наш взгляд их пропускать нельзя. Следовательно мы можем уменьшить набор значений до двух, исключив 12 и 14, а оставив 11 и 15 для проверки граничных условий.
Итого имеем:
11 и 15 цифр — OK, (+12345678901, +123456789012345)
10 и 16 цифр — NOK; (+1234567890, +1234567890123456) - для номеров без плюса:
По BVA получим номера с 4, 5, 6 и 9, 10, 11 цифрами.
Действуя аналогично примеру для номеров телефонов с плюсом, исключим значения 6 и 9, оставив 5 и 10.
Итого имеем:
5 и 10 цифр — OK, (12345, 1234567890)
4 и 11 цифр — NOK; (1234, 12345678901)
Результирующая таблица данных, для использования при последующем составлении тест кейсов
Источник: protesting.ru
Часть 3.3
Хотя при разговоре о процессе разработки ПО мы перевели «New Feature Testing» как «Тестирование новых компонентов», я предлагаю немедленно заменить «компонентов» на «фича», так как это более точный перевод и мы уже знаем, что такое фича. Исполнение тестирования состоит из двух стадий, идущих в следующей очередности:
1. Тестирование новых фича (new feature testing);
После того как код проинтегрирован, тест приемки пройден и код заморожен, мы начинаем тестирование новых фича.
Вопрос: Как мы тестируем новые фича?
Ответ: Все очень просто: берем в зубы тест-кейсы и исполняем их. Попутно заносим баги. Спорим с программистами о приоритетах этих багов. Закрываем эти баги. Одним словом, обычная суета сует.
2. Регрессивное тестирование (regression testing).
Test Estimation (тест-смета)
Как правило, в интернет-компаниях существует расписание релизов. К этому расписанию привязано расписание тестирования (QA Schedule), которое определяет сроки каждой стадии процесса тестирования.
Тестировщик готовит тест-смету (Test Estimation), которая включает:
• предварительную оценку времени, необходимого на подготовку к тестированию;
• предварительную оценку времени, необходимого на тестирование новых фича.
Вот факторы, которые я рекомендую принять во внимание при составлении сметы:
• предполагаемая сложность новых фича. Чем они сложнее, тем больше нюансов всплывет при подготовке и исполнении и тем больше времени понадобится на тестирование;
• есть ли у вас опыт тестирования похожих фича. Например, если вы эксперт в тестировании оплаты, то для вас будет проще и быстрее протестировать добавление еще одного вида кредитной карточки по сравнению с тестировщиком, который никогда кредитных карточек не касался;
• опыт работы на прошлых проектах с теми же продюсе ром и программистом. Например, одни программисты пишут удивительно чистый код, всегда проводят юнит-тестирование и с охотой кооперируются с тестировщиками. Другие же бросают куски кода в проект, как грязь на стену, считают юнит-тестирование вещью, не подобающей для компьютерного гения, и не склонны кооперироваться ни с кем, кроме виртуальных солдат игры Halo. Следовательно, во втором случае мы должны заложить больше времени на наше тестирование;
• будет ли интеграция нашего ПО с ПО наших бизнес-партнеров — вендоров (vendor), например интеграция с ПО платежной системы. Тест-конфигурация выглядит так: наша тест-машина «разговаривает» с их тест-машиной. Соответственно если что-то не в порядке с их тест-машиной, то проблема решается сложнее, чем при локальном тестировании, когда вы заносите баг и наш программист его ремонтирует. В случае с их тест-машиной
• тестировщик связывается с менеджером проекта (с нашей стороны);
• последний должен позвонить вендору;
• человек со стороны вендора должен найти ответственного программиста;
• ответственный программист может быть занят
В общем целая петрушка из-за того, что это другая компания и наши тестировщики не указ «их» программистам. В случае с интеграцией нашего ПО с не нашим ПО оценка должна принимать в расчет подобные задержки в решении проблем, которые при такой интеграции бывают всегда;
• нужны ли тулы для автоматизации тест-кейсов? Тест-тулы, как правило, создаются во время написания тест- кейсов как средство для облегчения исполнения тест-кейса, например:
• генерация данных (например, генерация номера тестировочной кредитной карты),
• автоматизация всех либо части шагов,
• помощь в сравнении фактического и ожидаемого результатов. В одних случаях тестировщик может сам написать такой тул, например, на языках Java или Python. В других случаях написание тула в помощь тестировщикам — это дело программиста.
Entry/Exit Criteria (критерий начала/завершения)
Все очень просто.
Entry Criteria (условие старта) — это условие для начала чего-либо.
Exit Criteria (условие завершения) — это условие для завершения чего-либо.
TestPlan (тест-план)
• тест-кейс нужен для сравнения фактического результата с ожидаемым результатом;
• тест-комплект — это логическая оболочка для хранения тест-кейсов;
• тест-план — это документ, обобщающий и координирующий тестирование.
1. Название тест-плана, имя автора и номер версии. Например «Тест-план проекта «Новые алгоритмы для поиска»». Автор Т. Черемушкин. Версия 2.
2. Оглавление с разделами тест-плана: Например Введение стр. 2 Документация с требованиями к ПО стр. 3 и т. д. 3. Введение, в котором мы приводим информацию о сути и истории тестируемого проекта.
4. Документация с требованиями к ПО — здесь мы перечисляем имена, номера и приоритеты спеков и/или другой документации, определяющей тестируемые фича.
5. Фича, которые будут тестироваться, перечисляем и, если нужно, комментируем. Каждой фича назначается приоритет.
6. Фича, которые НЕ будут тестироваться, перечисляем и объясняем, почему НЕ будут тестироваться. Например, частью спека #9172 «Улучшение безопасности платежных транзакций» являются требования к скорости работы веб-сайта (performance). До- пустим, у нас нет ни специалиста, ни ПО для тестирования скорости работы, и если мы не собираемся их нанять и приобрести, то указываем, что перформанс тестироваться не будет, так как нет ресурсов.
7. Объем тестирования — виды тестирования, которые мы будем проводить, и разъяснения к ним. Например «Системное тестирование будет исполняться для проверки всего флоу оплаты, начиная от добавления книги в корзину и заканчивая про- веркой значений базы данных и подтверждением от тест-машины вендора».
8. Тест-документация — перечисление тест-документации, которая должна быть создана для данного проекта Например «Тест-комплект по тестированию cпека #1288. Тест-комплект по тестированию спека #3411».
9. Тест-тулы — функциональности тест-тулов, которые должны быть созданы для тестирования проекта.
10. Критерий начала/завершения — те самые критерии, о кото рых мы говорили минуту назад:
• критерий начала подготовки к тестированию;
• критерий завершения подготовки к тестированию;
• критерий начала исполнения тестирования;
• критерий завершения исполнения тестирования.
11. Допущения — список допущений, которые мы сделали при составлении данного тест-плана и которые сделаем при тестировании. Например, мы допускаем (предполагаем), что код будет заморожен в срок, без задержки.
12. Зависимости — список вещей (с пояснениями), от которых зависит та или иная часть тестирования. Например, покупка новых тест-машин, лицензия на осуществление платежных операций на территории Великобритании.
13. «Железо» и ПО — список и конфигурации «железа» и ПО, которые будут использоваться при тестировании.
14. Условия приостановки/возобновления тестирования — это условия, при которых тестирование должно быть остановлено/ продолжено. Например, к условию приостановки можно отнести количество П1 багов, при котором (и/или после которого), по мнению автора (-ров) тест-плана, дальнейшее продолжение тестирования не имеет смысла (например, 7 П1). Соответственно условием возобновления должно быть количество оставшихся П1 багов (после ремонта и регрессивного тестирования), которое позволяет возобновить тестирование (например, 2 П1).
15. Ответственные лица — подробный список товарищей (продюсеров, программистов, тестировщиков и пр.), контактная информация и обязанности каждого из них. Такой список может включать лиц со стороны вендора.
16. Тренинг — тренинг, необходимый для данного проекта. Например, при соответствующей ситуации нужно указать, что для создания тест-кейсов тестировщику необходимо прослушать семинар «Банковская система США».
17. Расписание — сроки, имеющие отношение к тестированию данного проекта:
• дата замораживания спеков;
• дата начала подготовки к тестированию;
• дата завершения подготовки к тестированию;
• дата интеграции и замораживания кода;
• дата начала тестирования новых фича;
• дата завершения тестирования новых фича;
• дата начала регрессивного тестирования;
• дата завершения регрессивного тестирования.
18. Оценка риска — предположение о том, как и что может пойти по неправильному пути и что мы в этом случае предпримем. Например, если мы не успеваем закончить тестирование (не выполняем требовfние «Условия завершения», например, «все тест-кейсы исполнены») в срок, то придется задерживаться на работе и приходить в офис в выходные и праздники. Кстати, если народ приходит в выходные и праздники, то компания должна, по крайней мере, кормить его обедом.
19. Прочие положения — вещи, не вошедшие в тест-план, о которых неплохо было бы упомянуть.
20. Утверждения — это подписи лиц, которые утвердили тест-план. Чем больше будет таких подписей, тем лучше. По крайней мере, нужны подписи менеджера тестировщика, составившего план, самого тестировщика, продюсера и программиста. 21.
Приложения — например, расшифровка терминов и аббре- виатур, используемых в тест-плане.
СТАДИЯ 2: РЕГРЕССИВНОЕ ТЕСТИРОВАНИЕ
Регрессивное тестирование как второй этап исполнения тестирования — это проверка того, что изменения, сделанные в ПО (для того, чтобы мир увидел новые фича), не поломали старые фича.
1. Выбор тест-комплектов для регрессивного тестирования.
• к какой части ПО принадлежат новые фича (например, фича из спека #5419 «Новые функциональности для Корзины» принадлежат к «Корзине») и
• какие старые фича напрямую зависят от части ПО с новыми фича (например, компонент «Оплата» использует данные (по ценам книг), которые передаются ей компонентом «Корзины»).
Первой группой кандидатов для регрессивного тестирования у нас будут тест-комплекты, проверяющие часть ПО, к которой принадлежат новые фича. Например, при новых фича для «Корзины» в первую группу идут все тест-комплекты, непосредственно тестирующие «Корзину»
Второй группой кандидатов для регрессивного тестирования у нас будут тест-комплекты, проверяющие старые фича, которые зависят от части ПО с новыми фича. Например, при новых фича для «Корзины» во вторую группу мы можем отнести тест-комплекты, проверяющие «Оплату».
Теперь о третьей группе. Как правило, большая часть тест-комплектов не входит ни в первую, ни во вторую группы. Но они тоже нуждаются в регрессивном тестировании, так как изменение ПО может каким-то образом повлиять и на каждую из них, здесь, как говорится, никто не застрахован.
Для того чтобы затронуть все тест-комплекты, для регрессивного тестирования каждого релиза в порядке очереди выделяется по несколько тест-комплектов с расчетом, чтобы все существующие тест-комплекты были исполнены хотя бы один раз в определенный период, например в полгода. При недостатке времени для исполнения тест-комплектов из группы 3 рекомендую исполнять лишь самые приоритетные тест-кейсы каждого тест-комплекта, выбранного для исполнения при регрессивном тестировании данного релиза. Например, если у нас есть 45 тест-комплектов и один релиз в месяц, то, если исполнять по 15 тест-комплектов каждый релиз, за 3 месяца можно исполнить их все.
2. Решение проблемы противоречия между ограниченными ресурсами (например, время на регрессивное тестирование) и перманентно увеличивающимся количеством тест-комплектов.
Проблема противоречия между ограниченными ресурсами (например, время на регрессивное тестирование) и постоянно растущим количеством тест-комплектов решается следующими способами:
а. Приоритезация тест-комплектов и тест-кейсов.
б. Оптимизация тест-комплектов. Многие старые тест-комплекты могут быть оптимизированы в смысле
• уменьшения количества тест-кейсов и/или
• упрощения исполнения тест-кейсов.
Часто имеет смысл пересмотреть, КАК происходит тестирование в старых тест-комплектах: может быть, некоторые из тест-кейсов уже устарели и/или были написаны тулы для упрощения работы некоторых из них и пр.
в. Наем новых тестировщиков. Когда денег много, а ума мало, прибегают к массированному найму новых тестировщиков, что, конечно, лишь отодвинет решение проблемы, но не решит ее, так как нельзя бесконечно нани мать людей. Я против массированного найма (иногда нанимаются десятки. тестировщиков в год) и считаю, что интернет-компании нужен департамент качества, состоящий из немногочисленной группы профессиональных высокооплачиваемых специалистов, которые будут решать проблему регрессивного тестирования подходами а, б и г.
г. Автоматизация регрессивного тестирования.
Автоматизация регрессивного тестирования заключается в создании целой тестировочной инфраструктуры с библиотеками кода, базами данных, системами отчетности и прочими вещами. Создание такой инфраструктуры — дело очень и очень непростое. Иногда менеджмент, желая получить результат быстро и любой ценой, давит на спеца по автоматизации, и даже если последний добросовестно создает инфраструктуру для автоматизации, то он это дело бросает и абы как автоматизирует максимальное количество тест-комплектов, для того чтобы менеджмент мог отчитаться перед вышестоящим менеджментом: «За первый квартал 2005 года было авто- матизировано 12 тест-комплектов, содержащих 174 тест-кейса».
Но допустим, что менеджмент все понимает и дает карт-бланш на создание Инфраструктуры с большой буквы «Ай». ПО — это живое существо. Оно постоянно меняется, и автоматизация, связанная с ПО, должна соответственно меняться одновременно с ним. Таким образом, только поддержание (maintenance) существующих автоскриптов — задача, требующая больших профессиональных усилий, не говоря уже о написании новых автоскриптов.
Профессионализм такого спеца заключается не только в его программистских навыках, но и в том, как четко он представляет:
• ЧТО автоматизировать и
ЧТО: Лучший кандидат для автоматизации — это тест-кейс для тестирования старой, устоявшейся фича. Автоматизируя его, мы, по крайней мере, можем быть уверены, что автоскрипт не нужно будет переписывать из-за изменения фича и соответственно из- менения тест-кейса к ней.
КАК: Это создание инфраструктуры, позволяющей с легкостью и простотой
• поддерживать существующие автоскрипты;
• создавать новые автоскрипты.
Инфраструктура автоматизации регрессивного тестирования должна
• с одной стороны, быть образцом программистского мастерства;
• с другой — воплощать наиболее эффективные подходы к автоматизации, возможные при данном ПО для автома-тизации (например, силк-тесте);
• с третьей — учитывать нюансы технологий именно этой интернет-компании.
Источник: comanch00.wixsite.com
H Тестировщик ПО. Минимальный пакет знаний для трудоустройства в черновиках Из песочницы

Всем привет. Что нужно знать для того, чтобы устроиться на работу тестировщиком?
I) Прочитать и понять эту книгу Роман Савин. Тестирование Дот Ком;
II) Разобраться с SQL — запросами;
III) Разослать резюме;
IV) Показать свои знания и адекватность на собеседовании.
I) Прочитать и понять книгу
В книге около 300 страниц. За 1-2 дня прочитать несложно. Для тех, у кого нет времени на чтение, попробую изложить коротко основные моменты. Но рекомендую прочитать её полностью.
Участники разработки ПО:
1. Менеджер проекта — специалист, занимающийся вопросами поиска заказчиков проектов и исполнителей
2. QA-инженер — специалист, задача которого организовать процесс разработки таким образом, чтобы работа была выполнена в срок и на надлежащем уровне качества.
3. Продюсер — специалист, задача которого составить спецификацию (spec)
4. Программист — специалист, занимающийся написанием или корректировкой кода программы
5. Тестировщик — специалист, занимающийся поиском багов
Цикл разработки ПО состоит из:
1. Идея.
2. Разработка дизайна продукта и создание документации.
3. Кодирование или создание кода.
4. Исполнение тестирования и ремонт багов.
5. Релиз.
Цикл тестирования ПО состоит из трех этапов:
1. Изучение и анализ предмета тестирования.
2. Планирование тестирования.
3. Исполнение тестирования.
1. Тестирование — это сравнение фактического результата с ожидаемым.
2. Цели тестирования — нахождение багов до того, как их найдут пользователи.
3. Баг (bug) — это отклонение фактического результата от ожидаемого.
4. Спецификация (spec) — это детальное описание того, как должно работать ПО. Так же, это детальное описание ожидаемого результата. (В спецификации тоже могут быть баги, например, двусмысленные предложения).
5. Тест-кейс — это инструмент тестировщика, предназначенный для документирования и проверки одного или более ожидаемых результатов.
6. Тест-комплект — совокупность тест-кейсов находящихся, как правило, в одном документе, которые проверяют какую-то определенную часть нашего проекта.
7. Шаги тест-кейса (procedure) — это часть тест-кейса, ведущая исполнителя тест-кейса к фактическому результату. (Излишняя детализация может осложнить поддержку, а излишнее абстрагирование привести к непониманию того, как исполнить тест-кейс).
8. Front end — это непосредственный интерфейс пользователя (текст, картинки, кнопки, линки и прочие вещи, которые видно в окне приложения)
9. Back end — это то что на заднем фоне приложения (веб-сервер, код приложения, база данных и т.д.).
10. New feature testing — тестирование новых компонентов.
11. Regression testing — исполнение старых тест-кейсов для проверки того, что старые компоненты ПО еще работают.
12. СТБ (Bug Tracking System) — Система в которую заносятся баги.
13. Git — распределённая система управления версиями файлов (для управления коллекцией исправлений, патчей).
1. По знанию внутренностей системы:
• черный ящик (black box testing) — тестирование программы без доступа к коду;
• белый ящик (white box testing) — тестирование программы только по коду;
• серый ящик (grey box testing) — тестирование без кода+тестирование по коду.
2. По объекту тестирования:
• функциональное тестирование (functional testing) — например, проверка выводимого результата;
• тестирование интерфейса пользователя (UI testing) — из названия понятно;
• тестирование локализации (localization testing) — например, проверка шрифтов и другая адаптация приложения для пользователей;
• тестирование скорости и надежности (load/stress/performance testing) — например, проверка скорости загрузки сайта при определенном количестве пользователей;
• тестирование безопасности (security testing) — суть в том, чтобы усложнить условия для кражи данных (например телефонов и др. личной информации);
• тестирование опыта пользователя (usability testing) — суть в том, чтобы интерфейс был интуитивно понятен даже непродвинутым пользователям;
• тестирование совместимости (compatibility testing) — запуск на разных операционках и браузерах.
3. По субъекту тестирования:
• альфа-тестировщик (alpha tester) — тестирование сотрудниками фирмы;
• бета-тестировщик (beta tester) — тестирование пользователями.
4. По важности тестирования:
• сначала тестирование новых функциональностей (new feature testing) — тестирование новых функциональностей;
• потом регрессивное тестирование (regression testing) — повторное тестирование старых функций.
5. По критерию «позитивности»сценариев:
• позитивное тестирование (positive testing) — тестируем ожидаемыми методами;
• негативное тестирование (negative testing) — тестируем нестандартными методами(например вводим вместо 9 цифр — 11 букв).
6. По степени изолированности тестируемых компонентов:
• компонентное тестирование (component testing) — это тестирование одного логического компонента;
• интеграционное тестирование (integration testing) — это тестирование на уровне двух или больше логических компонентов;
• системное тестирование (system or end- to-end testing) — это проверка всей системы от начала до конца.
7. По степени автоматизированности тестирования:
• ручное тестирование (manual testing) — это исполнение тест-кейсов без помощи каких-либо программ, автоматизирующих вашу работу (например, создаем аккаунт вручную);
• автоматизированное тестирование (automated testing)- акаунт создается программой автоматически;
• смешанное/полуавтоматизированное тестирование (semi automated testing) — создаем акаунт вручную, но закупки сделаются автоматически.
8. По степени подготовки к тестированию:
• тестирование по документации (formal/documented testing) — тестирование по тест-кейсам;
• эд хок-тестирование (ad hoc testing) — интуитивное тестирование без документации (например, когда что-то нужно быстро проверить).

Также по документам существует:
• Тест-смета (Test Estimation) — документ, включающий в себя предварительную оценку времени, необходимого на подготовку к тестированию и на тестирование новых фича (new feature testing);
• Тест-план (test-plan) — документ, обобщающий и координирующий тестирование (подробнее об этом документе можно узнать в книге Савина).
II) Разобраться с SQL запросами
SQL (structured query language) — структурированный язык запросов.
С помощью SQL- запросов можно создавать и работать с реляционными базами данных.
Реляционная база данных — это таблица, в которой в качестве столбцов выступают поля данных, а каждая строка хранит данные.
SQL определяется Американским Национальным Институтом Стандартов и Международной Организацией по стандартизации (ISO)
Несмотря на это, некоторые производители баз данных вносят изменения и дополнения в этот язык. Эти изменения незначительны и основа остаётся совместимой со стандартом. (например ms sql, my sql, postgreSQL).
В каждой таблице должно быть одно уникальное поле, которое однозначно будет идентифицировать строку. Это поле назовем ключевым (Key1, Key2..).
В качестве ключа обычно используют численный тип и если позволяет база данных, то он будет типа «autoincrement» (автоматически увеличивающееся).
Столбцы в базе данных, также должны быть уникальными, но в этом случае не обязательно числовыми. Их можно называть как угодно, лишь бы было уникально и понятно.
SQL может быть двух типов: интерактивный и вложенный. Интерактивный — это отдельный язык, он сам выполняет запросы и сразу показывает результат работы. Второй — это когда SQL язык вложен в другой, например в С++ или Delphi.
Так как мы формируем минимальный список знаний трудоустройства, мы рассмотрим интерактивный SQL.
Представим, что у нас есть две таблицы:
Prog.db
Key1 / ProgName / Cost
1 / Windows 95 / 100
2 / Windows 98 / 120
User.db
Key1 / Key2 / LastName
1 / 1 / Иванов
2 / 1 / Петров
3 / 2 / Сидоров
Рассмотрим первый запрос:
SELECT *
FROM Prog, User
WHERE Prog.Key1= Key2
AND ProgName LIKE ‘Windows 95’
Выбрать (SELECT) все поля (*) из (FROM) баз данных Prog и User, где (WHERE) есть связь(Prog.Key1 и Key2) Prog.Key1= Key2 и ProgName LIKE ‘Windows 95’.
LIKE это тоже самое что равно(=) только для строк
Результатом этого запроса будет:
Prog.db User.db
Key1 / ProgName / Cost / Key1 / Key2 / LastName
1 / Windows 95 / 100 / 1 / 1 / Иванов
1 / Windows 95 / 100 / 2 / 1 / Петров
Отредактируем немного запрос:
SELECT Prog.Key1, Prog.ProgName, Prog.Cost*2 ‘руб’,
Cost.Key1, Cost.Key2, Cost.LastName
FROM Prog, User
WHERE Prog.Key1= Key2
Prog.Cost*2 ‘руб’ — эта запись говорит, что к каждое значение надо умножить на 2 и прибавить строку ‘руб’.
Результат:
Prog.db User.db
Key1 / ProgName / Cost / Key1 / Key2 / LastName
1 / Windows 95 / 200 руб / 1 / 1 / Иванов
1 / Windows 95 / 200 руб / 2 / 1 / Петров
Для сортировки используется команда ORDER BY. После этого пишутся поля, по которым надо отсортировать. В самом конце нужно поставить АSC (сортировать в порядке возрастания) или DESC (в порядке убывания). Если ты не ставишь АSC или DESC, то таблица сортируется по возрастанию и подразумевается параметр АSC.
Например:
SELECT *
FROM Prog
ORDER BY ProgName DESC
Результатом будет таблица Prog, отсортированная по полю ProgNamе в порядке убывания.
SQL калькулятор:
Вот несколько функций:
• COUNT — подсчёт количества строк;
• SUM — подсчёт суммы;
• AVG — подсчёт среднего значения;
• MAX — поиск максимального значения;
• MIN — поиск минимального значения.
Этот запрос просто подсчитывает количество строк в базе:
SELECT COUNT(LecNumber)
FROM User
Этот запрос опять подсчитывает количество строк, но теперь результатом будет количество народу, у которых поле LecNumber = 1:
SELECT COUNT(LecNumber)
FROM User
WHERE LecNumber=1
Этот запрос выводит количество лицензий и единицу измерения в одном столбце. Здесь к числу прибавляется текст:
SELECT LecNumber+’шт.’
FROM User
Работа с полями:
NSERT (вставить), UPDATE (модифицировать), DELETE (удалить).
После оператора VALUES идёт перечисление всех полей строки. Теперь рассмотрим пример:
INSERT INTO User1
VALUES (‘Иванов’, ‘Сергей’, 34);
Этой командой мы вставили строку и присвоили значения полям. В таблице три поля: первые два поля строковые (Фамилия и Имя), последнее поле — целое число (возраст). Типы данных обязаны совпадать с теми, что установлены в таблице.
Если не надо задавать все поля, тогда можно оставить их пустыми с помощью NULL:
INSERT INTO User1
VALUES (‘Иванов’, NULL, 34);
Если таблица с большим количеством полей и нужно заполнить только два из них?
Решение:
INSERT INTO User1 (Family, Age)
VALUES (‘Иванов’, 35);
После конструкции INSERT INTO и имени базы стоят скобки, где перечислены поля, которые необходимо заполнить (Фамилия и Возраст). В скобках после слова VALUES перечисляем эти поля в той же последовательности, в которой перечислил перед этим (сначала фамилия, а потом возраст).
Теперь представь, что мы хотим сохранить результат запроса SELECT в отдельной таблице. Для этого в SQL всё уже предусмотрено. Нужно только написать:
INSERT INTO User1
SELECT *
FROM User2
WHERE Age=10
В этом примере сначала выполнится запрос SELECT:
SELECT *
FROM User2
WHERE Age=10
После его выполнения результат будет занесён в таблицу User1. Важно, что количество столбцов в запросе и результирующей таблицы должно быть одинаково. А самое главное — это чтобы тип данных совпадал
Теперь рассмотрим такой запрос:
INSERT INTO User1(Name,Age)
SELECT Name,Age
FROM User2
WHERE Age=10
Теперь в таблицу User1 будут перенесены только два столбца (имя и возраст). Поля должны быть перечислены в таком порядке, чтобы типы и длина полей совпадали.