
Библиотека Requests:
эффективные и простые
HTTP-запросы в Python
Модуль Requests предоставляет возможность управления HTTP-запросами при помощи языка Python. Инструментарий библиотеки широкий и рассчитан на все случаи взаимодействия с web-приложениями. Код, написанный с применением Requests , не является громоздким, легко читается, а функции и методы наглядно настраиваются под специфические нужды.
Несмотря на то, что в Python встроен модуль urllib3 , обладающий сходным функционалом, практически все применяют Requests , что свидетельствует о его удобстве и простоте.
1. Основные возможности библиотеки Requests
Модуль разработан с учетом потребностей современных web-разработчиков и актуальных технологий. Многие операции автоматизированы, а ручные настройки сведены к минимуму.
Для понимания инструментария библиотеки перечислим ее основные возможности:
– поддержка постоянного HTTP-соединения и его повторное использование;
Парсинг сайтов PYTHON — #1 REQUESTS ЗАПРОСЫ (GET/POST)
– применение международных и национальных доменов;
– использование Cookie : передача и получение значений в формате ключ: значение ;
– автоматическое декодирование контента;
– SSL верификация;
– аутентификация пользователей на большинстве ресурсов с сохранением;
– поддержка proxy при необходимости;
– загрузка и выгрузка файлов;
– стриминговые загрузки и фрагментированные запросы;
– задержки соединений;
– передача требуемых заголовков на web-ресурсы и др.
В целом, практически любая задача, которая возникает у разработчика, нашла свое отражение в коде библиотеки. Важно понимать, что Requests не предназначен для парсинга ответа сервера (для этого применяют другие модули, например, Beautiful Soup ).
Источник: smartiqa.ru
Использование библиотеки Requests в Python
Для начала давайте разберемся, что же вообще такое библиотека Requests.
Requests — это HTTP-библиотека, написанная на Python (под лицензией Apache2). Она спроектирована для взаимодействия людей с эим языком. Это означает, что вам не нужно вручную добавлять строки запроса в URL-адреса или заносить данные в форму для POST -запроса. Если это кажется вам бессмысленным, не волнуйтесь. В нужное время все прояснится.
Что же делает библиотека Requests?
Библиотека Requests дает вам возможность посылать HTTP/1.1-запросы, используя Python. С ее помощью вы можете добавлять контент, например заголовки, формы, многокомпонентные файлы и параметры, используя только простые библиотеки Python. Также вы можете получать доступ к таким данным.
В программировании библиотека — это набор или, точнее сказать, предварительно настроенный набор подпрограмм, функций и операций, которые в дальнейшем может использовать ваша программа. Эти элементы часто называют модулями, которые хранятся в объектном формате.
Программа для моментального скачивания Request
Библиотеки очень важны, потому что вы можете загрузить модуль и использовать все, что он предлагает, без явной связи с вашей программой. Они действительно автономны, так что вы можете создавать свои собственные программы с ними, и все же они остаются отделенными от ваших программ.
Таким образом, о модулях можно думать как о неких шаблонах кода.
Повторимся еще раз, Requests — это библиотека языка Python.
Как установить Requests
Сразу сообщим вам хорошую новость: существует множество способов для установки Requests. С полным списком можно ознакомиться в официальной документации библиотеки Requests.
Вы можете использовать pip, easy_install или tarball.
Если вам нужен исходный код, вы можете найти его на GitHub.
Мы для установки библиотеки воспользуемся менеджером pip.
В интерпретаторе Python введите следующую команду:
pip install requests
Импортирование модуля Requests
Для работы с библиотекой Requests в Python вам необходимо импортировать соответствующий модуль. Вы можете это сделать, просто поместив следующий код в начало вашей программы:
import requests
Разумеется, предварительно этот модуль должен быть установлен и доступен для интерпретатора.
Делаем запрос
Когда вы пингуете веб-сайт или портал для получения информации, то это как раз и называется созданием запроса.
Для получения веб-страницы вам нужно написать что-то в таком духе:
r = requests.get(‘https://github.com/timeline.json’)
Работаем с кодом ответа
Перед тем как вы будете что-то делать с веб-сайтом или URL, хорошей идеей будет проверить код ответа, который вернул вам сервер. Это можно сделать следующим образом:
r = requests.get(‘https://github.com/timeline.json’) r.status_code >>200 r.status_code == requests.codes.ok >>> True requests.codes[‘temporary_redirect’] >>> 307 requests.codes.teapot >>> 418 requests.codes[‘o/’] >>> 200
Получаем содержимое страницы
После того как сервер вам ответил, вы можете получить нужный вам контент. Это также делается при помощи функции get библиотеки Requests.
import requests r = requests.get(‘https://github.com/timeline.json’) print(r.text) # Библиотека Requests также имеет встроенный JSON-декодер на # тот случай, если вам понадобятся данные JSON import requests r = requests.get(‘https://github.com/timeline.json’) print(r.json)
Работаем с заголовками
Используя словари Python, вы можете просмотреть заголовки ответа сервера. Особенностью работы библиотеки Requests является то, что для получения доступа к заголовкам вы можете использовать в ключах словаря как заглавные, так и строчные буквы.
Если вызываемого заголовка нет, будет возвращено значение None .
r.headers < ‘status’: ‘200 OK’, ‘content-encoding’: ‘gzip’, ‘transfer-encoding’: ‘chunked’, ‘connection’: ‘close’, ‘server’: ‘nginx/1.0.4’, ‘x-runtime’: ‘148ms’, ‘etag’: ‘»e1ca502697e5c9317743dc078f67693f»‘, ‘content-type’: ‘application/json; charset=utf-8’ >r.headers[‘Content-Type’] >>>’application/json; charset=utf-8′ r.headers.get(‘content-type’) >>>’application/json; charset=utf-8′ r.headers[‘X-Random’] >>>None # Получаем заголовки данного URL resp = requests.head(«http://www.google.com») print resp.status_code, resp.text, resp.headers
Кодирование
Библиотека Requests автоматически декодирует любой контент, извлеченный из сервера. Хотя большинство наборов символов Unicode в любом случае легко декодируются.
Когда вы делаете запрос к серверу, библиотека Requests делает обоснованное предположение о кодировке ответа. Это делается на основании заголовков HTTP. Предполагаемая кодировка будет использоваться при доступе к файлу r.text .
С помощью этого файла вы можете определить, какую кодировку использует библиотека Requests, и при необходимости изменить ее. Это возможно благодаря атрибуту r.encoding , который вы найдете в файле.
Когда вы измените значение кодировки, в дальнейшем библиотека Requests при вызове вами r.text будет использовать новый тип кодировки.
print(r.encoding) >> utf-8 >>> r.encoding = ‘ISO-8859-1’
Пользовательские заголовки
Если вы хотите добавить пользовательские заголовки в HTTP-запрос, вы должны передать их через словарь в параметр заголовков.
import json url = ‘https://api.github.com/some/endpoint’ payload = headers = r = requests.post(url, data=json.dumps(payload), headers=headers)
Переадресация и история
Библиотека Requests автоматически поддерживает переадресацию при выполнении команд GET и OPTION .
Например, GitHub из соображений безопасности автотоматически переадресует все HTTP -запросы на HTTPS .
Вы можете отслеживать статус переадресации при помощи метода history , который реализован для объекта response .
r = requests.get(‘http://github.com’) r.url >>> ‘https://github.com/’ r.status_code >>> 200 r.history >>> []
Осуществление POST-запроса HTTP
Также с помощью библиотеки Requests вы можете работать и с POST -запросами:
r = requests.post(http://httpbin.org/post)
Но вы также можете выполнять и другие HTTP -запросы, такие как PUT , DELETE , HEAD , и OPTIONS .
r = requests.put(«http://httpbin.org/put») r = requests.delete(«http://httpbin.org/delete») r = requests.head(«http://httpbin.org/get») r = requests.options(«http://httpbin.org/get»)
При помощи этих методов можно сделать массу разных вещей. Например, при помощи следующего кода вы можете создать репозиторий GitHub:
import requests, json github_url = «https://api.github.com/user/repos» data = json.dumps() r = requests.post(github_url, data, auth=(‘user’, ‘*****’)) print r.json
Ошибки и исключения
Есть ряд ошибок и исколючений, с которыми вам надо ознакомиться при использовании библиотеки Requests.
- При проблемах с сетью, например с DNS , или отказе соединения, библиотека Requests вызовет исключение ConnectionError .
- При недопустимом ответе HTTP библиотека Requests вызвоет исключение HTTPError , но это довольно редкий случай.
- Если время запроса истекло, возникнет исключение Timeout .
- Когда при запросе будет превышено заранее заданное количество переадресаций, возникнет исключение TooManyRedirects .
Все исключения, вызываемые библиотекой Requests, наследуются от объекта requests.exceptions.RequestException .
Дополнительные материалы
Более подробно про билиотеку Requests вы можете почитать, пройдя по следующим ссылкам:
- http://docs.python-requests.org/en/latest/api/
- http://pypi.python.org/pypi/requests
- http://docs.python-requests.org/en/latest/user/quickstart/
- http://isbullsh.it/2012/06/Rest-api-in-python/#requests
Источник: pythonist.ru
Самурайские инструменты QA: Python (requests)

Рад приветствовать читателей Хабр. Меня зовут Азамат Акчурин, я QA инженер в Bimeister.
Часто при приемке разного рода фич нам, тестировщикам, не хватает сущностей/данных в тестируемой системе. Тестировать на пустых данных не “comme il faut”, поэтому, чтобы наполнить систему данными, мы можем обратиться к разработчикам, QA automation, добавить данные в БД и т. д. — способов очень много.
И сегодня я расскажу про один из таких способов, который «дешево и сердито» позволит тестировщику самостоятельно, не отвлекая других сотрудников, заполнить систему данными.
Все, что нам нужно
- Установить Python.
- Установить IDE для Python — лично пользуюсь PyCharm.
- Дочитать эту статью, чтобы научиться применять такой способ в решении задач.
N.B.
В данной статье опущу пункты установки Python и IDE — будем считать, что они уже установлены. Перейдем, непосредственно, к практике.
Кейс #1
Представим, что разработали новую таблицу, в которой содержатся объекты со свойством «Строка» — то есть мы можем создать объекты, в которых содержатся любые символы. Нам необходимо проверить фильтрацию объектов, поиск, пагинацию и т. д.
А если таких свойств будет 5/10/15 штук в одном объекте? Какая бы “Самая быстрая рука на Диком Западе” не была у тестировщика, заполнять систему данными он будет неприлично долго.
Пришло время научить машину делать рутинную работу за нас:
- Открываем devtools → networks и создаем один объект руками.
- Ловим запрос, который ушел при создании объекта, и во вкладке Networks запоминаем следующие параметры:
— Request Url «https://[что-то типаgoogle.com]/api/BimExemplars».
— Request Method «post». В этом примере я авторизован под учетной записью в системе, поэтому из Request Headears также фиксирую Bearer Token «Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6….и еще куча символов». - Из вкладки Payload искомого запроса записываем данные для Request Payload.
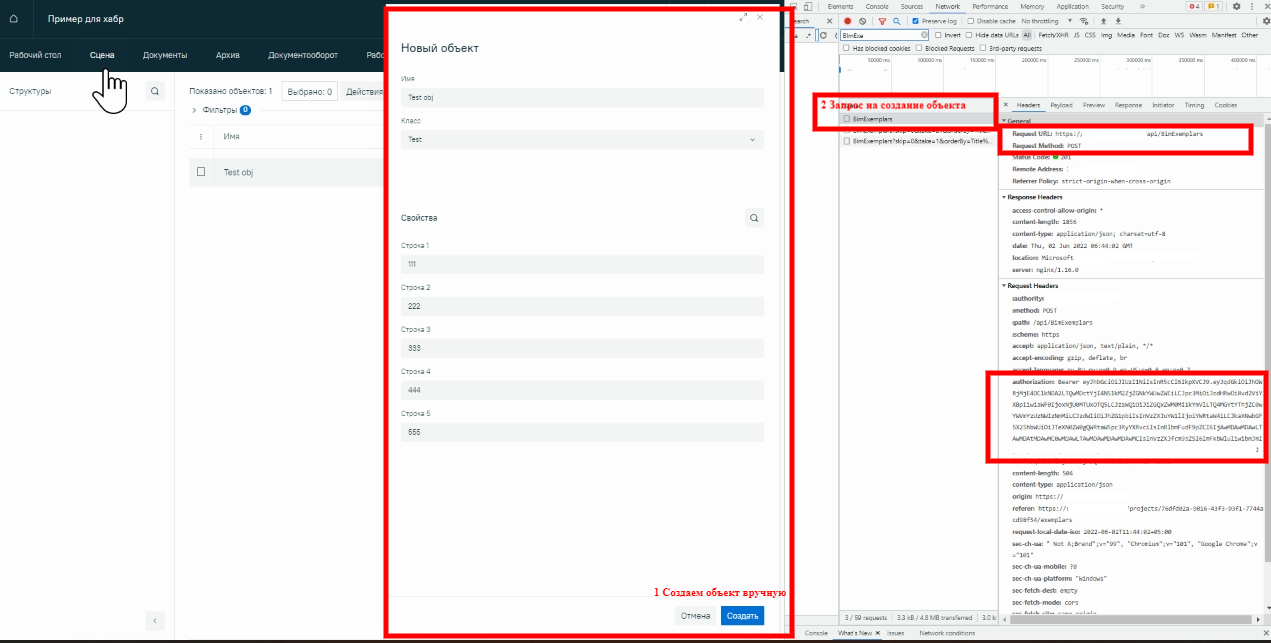

Все исходные данные мы собрали. Теперь перейдем к написанию скрипта:
import requests as r # Для импорта библиотеки requests, с помощью этой библиотеки будем отправлять запросы. import random # Данная библиотека нужна для формирования рандомных значений. url = ‘https://[что-то типа google.com]/api/BimExemplars’ # В переменную url сохранили значение Request Url (см. п2). bearer = ‘Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJqdGkiOiJmYmMyMzRhZC01NjQ1LTQ3MTktODFmNC0zZDQyNzliMTMxYWEiLCJpc3. еще много символов’ # В переменную bearer сохранили значение Bearer Token (см. п2). for i in range(15): # Создаем цикл, в данном случае код — под этим циклом исполнится 15 раз. Почему 15?
Да просто пример из головы. Если нам нужно 100 объектов, просто делаем цикл на 100 повторений. payload = < # В переменную payload сохраняем значение из Requests Payload (см. п3). Но, если оставить в таком виде и запустить код, в системе будет 15 совершенно одинаковых объектов.
Давайте подумаем, что можно изменить? «projectId»: «76dfd02a-9016-43f3-93f1-7744acd98f54», # ID проекта оставляем неизменным, так как именно в этом проекте мне необходимы созданные объекты. «title»: «Test obj», # Поле отвечающее за наименование объекта. Отличное поле для рандомных значений. Заменим значение «Test obj» на f»Test obj «. Что это нам даст?
Будет создан Объект «Test obj «. «bimClassId»: «94e9f5ff-1afa-47ec-beb0-59109cc3d9dd», # bimClassId и ниже bimPropertyId отвечают за поля свойств у объекта, поэтому оставим их неизменными. «bimExemplarProperties»: [ < «bimPropertyId»: «8f2a6659-feb4-42d6-899d-8e7ebc99d5e4», «value»: «111» # Поле, отвечающее за значения в поле Свойства. Тоже отличное поле для рандомных значений. Идем по протоптанной дорожке и заменяем «123» на f»random.randint(1, 100)». Что здесь происходит?
Думаю, уже понятно. >, < «bimPropertyId»: «391fb437-8771-4d80-a22e-af86ce0fd6a8», «value»: «222» # Аналогично заменим здесь. >, < «bimPropertyId»: «65f144fa-56d2-4bf1-88f3-452242f03a68», «value»: «333» # Здесь. >, < «bimPropertyId»: «0d80ff51-5771-4d4d-9a1b-645faaac8c25», «value»: «444» # И здесь. >, < «bimPropertyId»: «9d64cfc4-bcfc-44d2-88b0-8f8d511db06c», «value»: «555» # И здесь. >] > requests = r.post(url, headers=, json=payload) # Что происходит: r.post(url, headers=, json=payload) — говорим системе сделать Post запрос (см. п2 Requests Method «post»); url — запрос, который добавляет объекты; headers= — хедеры, которые отправляются вместе с запросом, тут как бы говорим системе, что пользователь авторизован; json=payload — здесь передаем тело запроса. print(requests.status_code) # После запуска кода выведет статус код каждого запроса. Сугубо личная вещь, сделано для удобства.
В таком виде мы создадим 15 одинаковых объектов, содержащих одинаковую информацию, соответствующую payload.
Добавим уникальности объектам через random.randint(1, 100)
import requests as r import random url = ‘https://[что-то типа google.com]/api/BimExemplars’ bearer = ‘Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJqdGkiOiJmYmMyMzRhZC01NjQ1LTQ3MTktODFmNC0zZDQyNzliMTMxYWEiLCJpc3. еще много символов’ for i in range(15): payload = < «projectId»: «76dfd02a-9016-43f3-93f1-7744acd98f54», «title»: f»Test obj «, # Подставит любое целое число от 1 до 100 «bimClassId»: «94e9f5ff-1afa-47ec-beb0-59109cc3d9dd», «bimExemplarProperties»: [ < «bimPropertyId»: «8f2a6659-feb4-42d6-899d-8e7ebc99d5e4», «value»: f»» >, < «bimPropertyId»: «391fb437-8771-4d80-a22e-af86ce0fd6a8», «value»: f»» >, < «bimPropertyId»: «65f144fa-56d2-4bf1-88f3-452242f03a68», «value»: f»» >, < «bimPropertyId»: «0d80ff51-5771-4d4d-9a1b-645faaac8c25», «value»: f»» >, < «bimPropertyId»: «9d64cfc4-bcfc-44d2-88b0-8f8d511db06c», «value»: f»» > ] > requests = r.post(url, headers=, json=payload) print(requests.status_code)
Теперь запустим код и посмотрим, что произойдет в системе:

- Запускаем код.
- Смотрим, что все запросы вернулись с кодом 201.
- Смотрим, что в системе создалось 15 объектов, и все они имеют рандомные наименования.
Кейс #2
Чтобы закрепить материал, рассмотрим другой пример. Если открыть любой из созданных объектов и изменить какие-либо значения свойств, то можно сохранить новую версию объекта:

Затем, после сохранения «как новой версии» пользователю доступен список всех версий

В практике столкнулся с тем, что необходимо было проверить открытие (до 1 сек.) и отображение дропдауна с 1000 версий. И тут снова пригодился Python. Повторим, знакомые нам, шаги:

- Открываем devtools → networks.
- Создаем новую версию объектами руками.
- Ловим запрос, который сохраняет версию и фиксируем параметры:
Request Url «https://[что-то типаgoogle.com]/api/BimExemplarVersions»,
Request Method «Post». Из Request Headears запоминаем Bearer Token «Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6Ikp. и еще много символов».
- Из вкладки Payload скопируем значение Request Payload:
< «bimExemplarId»: «92ea9b30-a097-4a7e-a472-48d020eecc13», «title»: «Test obj 893», «bimExemplarProperties»: [ < «bimPropertyId»: «57c5ae3d-3aa2-40c4-a77b-bc90b3cf84f7», «value»: «73» >, < «bimPropertyId»: «4a23533f-1757-4a0c-931b-57e28a45c1bd», «value»: «162 значение изменено для сохранения новой версии» >, < «bimPropertyId»: «588b3da1-73bc-4ea6-95d2-035f6082216d», «value»: «987 значение изменено для сохранения новой версии» >, < «bimPropertyId»: «8740ae93-2a9e-4a17-8e56-5bede7405554», «value»: «51» >, < «bimPropertyId»: «521ca3e8-64ef-4d3a-af2d-d8facdaf37df», «value»: «608» >, < «bimPropertyId»: «fc4a6ce2-eb55-4543-9913-fc4238ce739e», «value»: «593» >, < «bimPropertyId»: «d18c9d75-2298-45d7-9542-1644b900ed45», «value»: «535» >], «bimExemplarVersionId»: «f813654e-43b9-437b-930a-4882f1d71d73» >
Нужные данные для скрипта мы записали. Перейдем к финальному скрипту. Рандомные значение проставили только для полей Объекта, так как, меняя только поля объекта, можно сохранить новую версию:
import requests as r import random url = ‘https://[что-то типа google.com]/api/BimExemplarVersions’ bearer = ‘Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJqdGkiOiJiNmZjYThmYi1iYjgwLTQzZGItYmY4NC02MDk3NzM5ZGEzZ. и еще много символов’ for i in range(1000): payload = < «bimExemplarId»: «92ea9b30-a097-4a7e-a472-48d020eecc13», «title»: «Test obj 893», «bimExemplarProperties»: [ < «bimPropertyId»: «57c5ae3d-3aa2-40c4-a77b-bc90b3cf84f7», «value»: f»» # Меняем значение свойства. >, < «bimPropertyId»: «4a23533f-1757-4a0c-931b-57e28a45c1bd», «value»: f»» # Меняем значение свойства. >, < «bimPropertyId»: «588b3da1-73bc-4ea6-95d2-035f6082216d», «value»: f»» # Меняем значение свойства. >, < «bimPropertyId»: «8740ae93-2a9e-4a17-8e56-5bede7405554», «value»: f»» # Меняем значение свойства. >, < «bimPropertyId»: «521ca3e8-64ef-4d3a-af2d-d8facdaf37df», «value»: f»» # Меняем значение свойства. >, < «bimPropertyId»: «fc4a6ce2-eb55-4543-9913-fc4238ce739e», «value»: f»» # Меняем значение свойства. >, < «bimPropertyId»: «d18c9d75-2298-45d7-9542-1644b900ed45», «value»: f»» # Меняем значение свойства. > ], «bimExemplarVersionId»: «f813654e-43b9-437b-930a-4882f1d71d73» > requests = r.post(url, headers=, json=payload) print(requests.status_code)
В этом примере хватило 5 минут, чтобы создать 1000 версий для дальнейших тестов:

В заключение
Мы разобрали два простых кейса из опыта, в которых буквально за 5-10 минут сгенерировали данные для тестирования. Этот способ, на мой взгляд, поможет тестировщику без каких-либо фундаментальных знаний программирования решать рутинные задач подобного рода. Если данная тема будет актуальна для читателей, то в следующей статье разберу более сложные примеры, в которых используются несколько запросов и параметры из одного запроса прокидываются в другой запрос.
Прошу подсказать читателей, интересна ли тема и каким инструментом пользуйтесь при решении таких задач?
P.S.
Данная инструкция не является призывом к действию, эталоном и панацеей. Это всего лишь один из способов для решения вопросов «одному.здесь.сейчас», который возможно принесет пользу и вам.
Источник: habr.com
Знакомство с Python библиотекой requests

Подробное руководство по Python библиотеке requests с примерами использования.
Введение
Большая часть интернет-ресурсов взаимодействует с помощью HTTP-запросов. Эти HTTP-запросы выполняются устройствами или браузерами (клиентами) при обращении к веб-сервису.
В Python библиотека requests позволяет делать HTTP-запросы в нашем коде, и это очень востребовано, так как многие современные приложения используют данные сторонних сервисов с помощью API.
Python requests — отличная библиотека. Она позволяет выполнять GET и POST запросы с возможностью передачи параметров URL, добавления заголовков, размещения данных в форме и многое другое.
С помощью библиотеки можно делать запросы практически на каждый сайт/веб-страницу, но ее сила заключается в доступе к API для получения данных в виде JSON, с которыми можно работать в своем коде, приложениях и скриптах.
Установка библиотеки
Чтобы установить библиотеку requests, запустите команду:
pip install requests
Будет установлен модуль и зависимости, если таковые имеются.
Создание простого запроса
Давайте попробуем сделать простой запрос на мой сайт, https://egorovegor.ru (вы можете использовать любой сайт):
import requests r = requests.get(«https://egorovegor.ru»)
Для начала импортируем модуль requests. Из него мы используем функцию get() с переданным URL нашего сайта. В этой строке кода делается запрос на https://egorovegor.ru, а ответ сохраняется в переменную r.
Для выполнения запроса к удаленному ресурсу требуется подключение к сети интернет.
Теперь у нас есть объект ответа (response), присвоенный переменной r. Мы можем получить всю необходимую информацию из этого объекта.
После того, как запрос сделан, мы получаем ответ от веб-сервера на котором расположен сайт и можем прочитать его код:
r.status_code
Если ваш код состояния равен 200, это означает что запрос был выполнен успешно. С полным списком кодов состояния HTTP можно ознакомится на странице в Википедии. Вы можете получить доступ к исходному коду веб-страницы с помощью свойства .text:
print(r.text)
Весь исходный код веб-страницы будет распечатан в вашей консоли.
Это полезно при выполнении сбора данных с веб страниц.
Выполнение запросов к API
Максимально раскрыться библиотеке позволяет взаимодействие с внешними API. В данном руководстве мы будем использовать API, который доступен на движке моего сайте. Мы выполним запрос, который должен вернуть информацию о сайте.
import requests r = requests.get(«https://egorovegor.ru/wp-json/») print(r.status_code)
Теперь у нас есть объект response, сохраненный в переменную r. Мы можем получить из него всю необходимую информацию.
Содержимое ответа
Мы можем читать содержимое различными способами, используя атрибуты и функции, предоставляемые модулем requests.
r.status_code # 200 r.encoding # utf-8 r.url # https://egorovegor.ru/wp-json/ r.json() # возвращает содержимое в формате json r.text # возвращает содержимое в текстовом формате r.content # возвращает содержимое ответа в байтах
r.status_code возвращает код, указывающий, был ли запрос успешным или нет. 200 означает успешный. Общие коды статусов, которые вы, вероятно, видели — 200, 404 и 500. 404 означает ошибку клиента, а 500 означает ошибку сервера.
r.encoding возвращает кодировку ответа, основанную на HTTP заголовках.
r.url возвращает запрошенный URL.
r.json возвращает разобранные JSON данные из ответа.
r.text возвращает ответ в текстовом формате
r.content возвращает ответ, отформатированный в байтах
Работа с JSON ответами
JSON-данные, полученные по ссылке https://egorovegor.ru/wp-json/, содержат много информации о сайте, давайте попробуем с ней поработать.
import requests r = requests.get(«https://egorovegor.ru/wp-json/») print (r.json())
Ответ сервера:
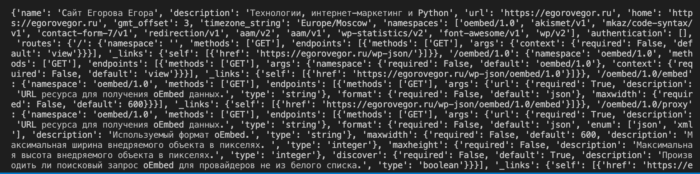
Обратите внимание, я сократил ответ сервера из за большого количества информации в json.
r.json() разбирает ответ в Python-совместимый тип данных, т.е. словарь или список. Разберем на примере как использовать полученные JSON данные.
import requests r = requests.get(«https://egorovegor.ru/wp-json/») data = r.json() name = data[«name»] description = data[«description»] url = data[«url»] timezone = data[«timezone_string»] print(f»Информация о сайте: «) print(f»Название: «) print(f»Описание: «) print(f»Часовой пояс: «)
Выполнив данный сценарий мы получим результат указанный ниже.
Информация о сайте: https://egorovegor.ru Название: Cайт Егорова Егора Описание: Технологии, интернет-маркетинг и Python Часовой пояс: Europe/Moscow
Использование параметров в URL
При работе с запросами можно передавать параметры в строке запроса URL. Параметры URL — распространенный способ передачи данных, их часто можно увидеть после вопросительного знака в URL. Пример: https://egorovegor.ru/?s=Python — это URL для поиска статей с ключевым словом Python, получается что s=Python — это его параметр.
Чтобы передать параметры в URL, их нужно указать как словарь в аргумент ключевого слова params. Например; ?s=Python будет записан как .
import requests r = requests.get(«https://egorovegor.ru/», params=) print(r.url) # https://egorovegor.ru/?s=Python
Наверняка вы заметили, что в r.url сохранился URL, который автоматически добавил к нему параметр; ?s=Python.
Заключение
Мы рассмотрели как использовать библиотеку requests в Python и научились парсить данные с сайтов.
Для более глубокого изучения библиотеки requests можно обратиться к официальной документации.
Источник: egorovegor.ru