
Redis (расшифровывается как Remote Dictionary Server) – это быстрое хранилище данных типа «ключ‑значение» в памяти с открытым исходным кодом. Проект возник, когда Сальваторе Санфилиппо, первоначальный разработчик Redis, захотел улучшить масштабируемость стартапа в Италии. Он создал хранилище Redis, которое теперь используется в качестве базы данных, кэша, брокера сообщений и очереди.
Redis обеспечивает время отклика на уровне долей миллисекунды и позволяет приложениям, работающим в режиме реального времени, выполнять миллионы запросов в секунду. Такие приложения востребованы в сферах игр, рекламных технологий, финансовых сервисов, здравоохранения и IoT. Сегодня Redis – одно из наиболее популярных ядер с открытым исходным кодом, в течение пяти лет подряд называемое «самой любимой» базой данных от Stack Overflow. Благодаря быстрой производительности Redis широко применяется для кэширования, управления сеансами, разработки игр, создания таблиц лидеров, аналитики в режиме реального времени, работы с геопространственными данными, поддержки служб такси, чатов и сервисов обмена сообщениями, потоковой передачи мультимедиа и приложений с отправкой сообщений по модели «издатель – подписчик» (Pub/Sub).
Базы данных. NoSQL. Redis
AWS предлагает два полностью управляемых сервиса для запуска Redis. Amazon MemoryDB for Redis – совместимый с Redis надежный сервис базы данных в памяти, который обеспечивает сверхбыструю производительность. Amazon ElastiCache for Redis – полностью управляемый сервис кэширования, который ускоряет доступ к данным из первичных баз данных и хранилищ с микросекундной задержкой. Более того, ElastiCache также предлагает поддержку Memcached, другой популярной системы кэширования с открытым исходным кодом.
Подробную информацию об ускорении приложений с Amazon ElastiCache for Redis см. в онлайн-вебинаре Tech Talk.
Преимущества Redis
Производительность
Все данные Redis хранятся в памяти, что обеспечивает низкую задержку и высокую пропускную способность доступа к данным. В отличие от традиционных баз данных, хранилища данных в памяти не требуют перемещения на диск, что сокращает задержку ядра до микросекунд. Благодаря этому хранилища данных в памяти могут многократно увеличивать количество выполняемых операций и сокращать время отклика. В результате обеспечивается чрезвычайно высокая производительность. Операции чтения и записи в среднем занимают менее миллисекунды, скорость работы достигает миллионов операций в секунду.
Гибкие структуры данных
В отличие от других хранилищ на основе пар «ключ – значение», которые поддерживают ограниченный набор структур данных, Redis поддерживает огромное разнообразие структур данных, позволяющее удовлетворить потребности разнообразных приложений. Типы данных Redis включают:
- строки – текстовые или двоичные данные размером до 512 МБ;
- списки – коллекции строк, упорядоченные в порядке добавления;
- множества – неупорядоченные коллекции строк с возможностью пересечения, объединения и сравнения с другими типами множеств;
- сортированные множества – множества, упорядоченные по значению;
- хэш‑таблицы – структуры данных для хранения списков полей и значений;
- битовые массивы – тип данных, который дает возможность выполнять операции на уровне битов;
- структуры HyperLogLog – вероятностные структуры данных, служащие для оценки количества уникальных элементов в наборе данных;
- потоки – очереди сообщений со структурой журналов данных;
- пространственные данные – записи карт на основе долготы/широты, «поблизости»
- JSON – полуструктурированный объект со вложенной структурой из именованных значений с поддержкой чисел, строк, булевских значений, массивов и других объектов
REDIS — что и зачем?
Простота и удобство
Redis позволяет писать такой же сложный код с меньшим количеством простых строк. Redis позволяет писать меньше строк для хранения, использования данных и организации доступа к данным в приложениях. Разница в том, что, в отличие от языков запросов традиционных баз данных, с Redis разработчики могут использовать простую структуру команд.
Например, вы можете задействовать структуру хэш-данных Redis, чтобы перемещать данные в хранилище только одной строкой кода. Решение подобной задачи с использованием хранилища данных, не поддерживающего структуры хэш‑таблиц, потребует написания серьезного объема кода для преобразования данных из одного формата в другой. Redis уже оснащен встроенными структурами данных и предоставляет множество возможностей их комбинирования и взаимодействия с данными клиента. Разработчикам под Redis доступны более ста клиентов с открытым исходным кодом. Поддерживаемые языки программирования включают Java, Python, PHP, C, C++, C#, JavaScript, Node.js, Ruby, R, Go и многие другие.
Репликация и постоянное хранение
В Redis применяется архитектура узлов «ведущий‑подчиненный» и поддерживается асинхронная репликация, при которой данные могут копироваться на несколько подчиненных серверов. Это обеспечивает как улучшенные характеристики чтения (так как запросы могут быть распределены между серверами), так и ускоренное восстановление в случае сбоя основного сервера. Для обеспечения постоянного хранения Redis поддерживает снимки состояния на момент времени (копирование наборов данных Redis на диск).
Redis не задуман как надежная и стабильная база данных. Если вам нужна надежная и совместимая с Redis база данных, рассмотрите Amazon MemoryDB for Redi s . Поскольку MemoryDB использует надежный журнал транзакций, в котором хранятся данные нескольких зон доступности (AZ), вы можете задействовать ее в качестве основной базы данных. MemoryDB специально создана для того, чтобы разработчики могли работать с API Redis, не беспокоясь об управлении отдельным кэшем, базой данных или базовой инфраструктурой.
Высокая доступность и масштабируемость
Redis предлагает архитектуру «ведущий‑подчиненный» с одним ведущим узлом или с кластерной топологией. Это позволяет создавать высокодоступные решения, обеспечивающие стабильную производительность и надежность. Если требуется настроить размер кластера, доступны различные варианты вертикального и горизонтального масштабирования. В результате можно наращивать кластер в соответствии с потребностями.
Инструменты с открытым исходным кодом
Redis – проект с открытым исходным кодом, поддерживаемый активным сообществом, включая AWS. Поскольку Redis базируется на открытых стандартах, поддерживает открытые форматы данных и имеет множество клиентов, отсутствует вероятность блокировки поставщиком или технологического тупика.
Источник: aws.amazon.com
Как работает СУБД Redis
Рассказываем, что такое Redis: рассматриваем его применение и преимущества, поддерживаемые типы данных.

В обзоре расскажем, что такое и зачем нужен Redis, рассмотрим его применение и преимущества, поддерживаемые типы данных. Подробно остановимся на конфигурациях, моделях работы, а также примерах использования этой системы управления базами данных.
Что такое и для чего используется СУБД Redis
Простыми словами Redis — система хранения данных в виде структур. Это нереляционная СУБД с открытым исходным кодом, организованная по принципу «ключ – значение». Она является вспомогательной и выполняет функцию хранилища (Redis storage) и кеша для основной, центральной базы данных. В качестве последних могут использоваться, например, PostgreSQL или MySQL.
Название СУБД произошло от аббревиатуры «Remote Dictionary Server» — ReDiS. Разработал продукт итальянский программист С. Санфилиппо, которого не устраивала производительность обычных баз данных при масштабировании. Первая версия вышла в 2009 году, и с тех пор система обновляется регулярно.
Последняя стабильная версия, выложенная на официальном сайте Redis.io на момент написания статьи, — 7.0.5.
Преимущества работы с базами данных Redis
Благодаря тому, что БД не использует язык структурированных запросов SQL, у хранилища Redis есть ряд плюсов.
- Производительность. Поскольку данные хранятся в оперативной памяти сервера, базы NoSQL работают гораздо быстрее в сравнении с реляционными СУБД. Это позволяет снижать нагрузку на главные БД за счет обработки в оперативной памяти постоянных данных, а также тех, которые часто меняются, но не являются важными.
- Гибкость структур данных. Базы NoSQL позволяют работать с неструктурированными данными — они хранятся не в традиционном табличном виде, а по типам. Кроме того, объемы хранимых данных фактически не ограничены, а при необходимости можно добавлять новые типы данных.
Какие типы данных поддерживает Redis DB
Основные типы данных, поддерживаемые по умолчанию:
- строковые (в виде текста или двоичного кода с максимальным размером 512 МБ),
- битовые массивы и поля (дают возможность выполнять побитовые операции),
- хеш-таблицы (в них хранятся списки полей и значений),
- списки (упорядоченные коллекции строковых значений),
- множества, в том числе упорядоченные (коллекции уникальных элементов),
- потоковые (для хранения информации из логов),
- геоданные (географические координаты),
- HyperLogLog (структурированная информация для определения вероятностей нахождения определенных элементов в наборах данных).
Языковая поддержка Redis
Система поддерживает практически все популярные языки программирования, включая Python, Golang, семейство C, Java, Ruby, Perl, а также PHP и JavaScript.
Конфигурации Redis
Развертывание Redis DB можно проводить по-разному. Приведем описание основных решений, или конфигураций Redis.
Единственный экземпляр Redis Database
Такое использование Redis подойдет для тех, кому нужно организовать ограниченное по объему хранилище: как правило, небольшую базу данных для приложения. Развернутый экземпляр Redis в этом случае поможет организовать кеширование, что положительно скажется на производительности приложения. Если ресурсы сервера позволяют, то Redis обычно разворачивают на тех же мощностях, что и приложение.
Из минусов такого подхода можно отметить снижение отказоустойчивости системы (особенно если нет дополнительно реляционной базы данных). При наличии проблем в Redis Database доступ к приложению может быть затруднен.
Redis HA
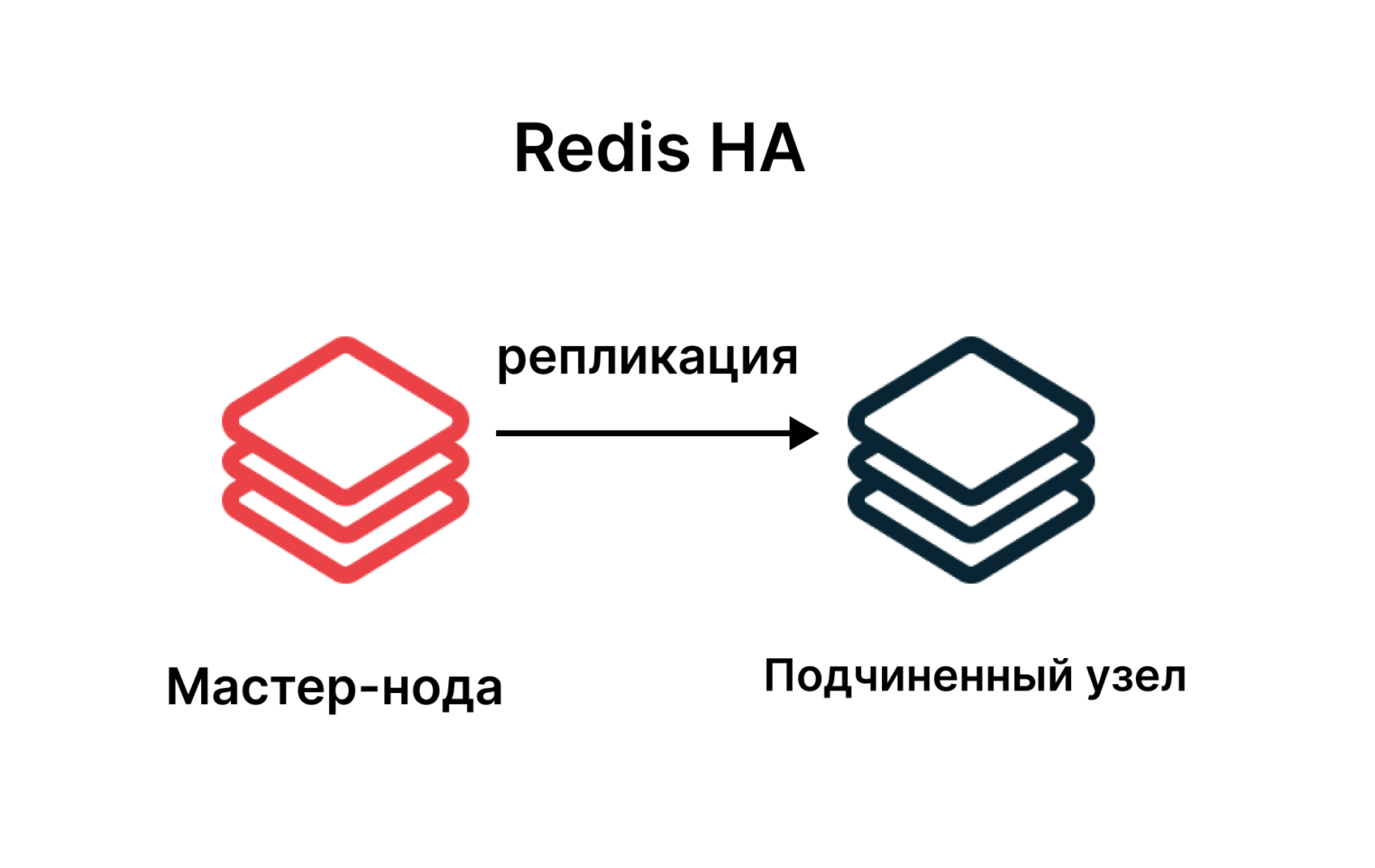
Аббревиатура HA расшифровывается как High Availability, то есть повышенная доступность. В этой схеме задействуется два и более узлов: главный и подчиненные, а их синхронизация реализуется с помощью репликации. Такая система позволяет существенно повысить ее отказоустойчивость, поскольку здесь нет единой точки отказа, как в предыдущем варианте с единственной СУБД.
В результате сбои устраняются очень быстро, в том числе за счет их автоматического обнаружения и схемы восстановления системы. А благодаря надежным каналам связи исключена потеря данных.
О репликации данных в БД Redis
Под репликацией понимается дублирование данных, которые пересылаются и записываются всеми узлами системы, что многократно снижает риски потери данных. Также благодаря репликации увеличивается производительность и скорость работы сервиса, поскольку реплицированные данные доступны для чтения с любого узла системы.
Redis Sentinel
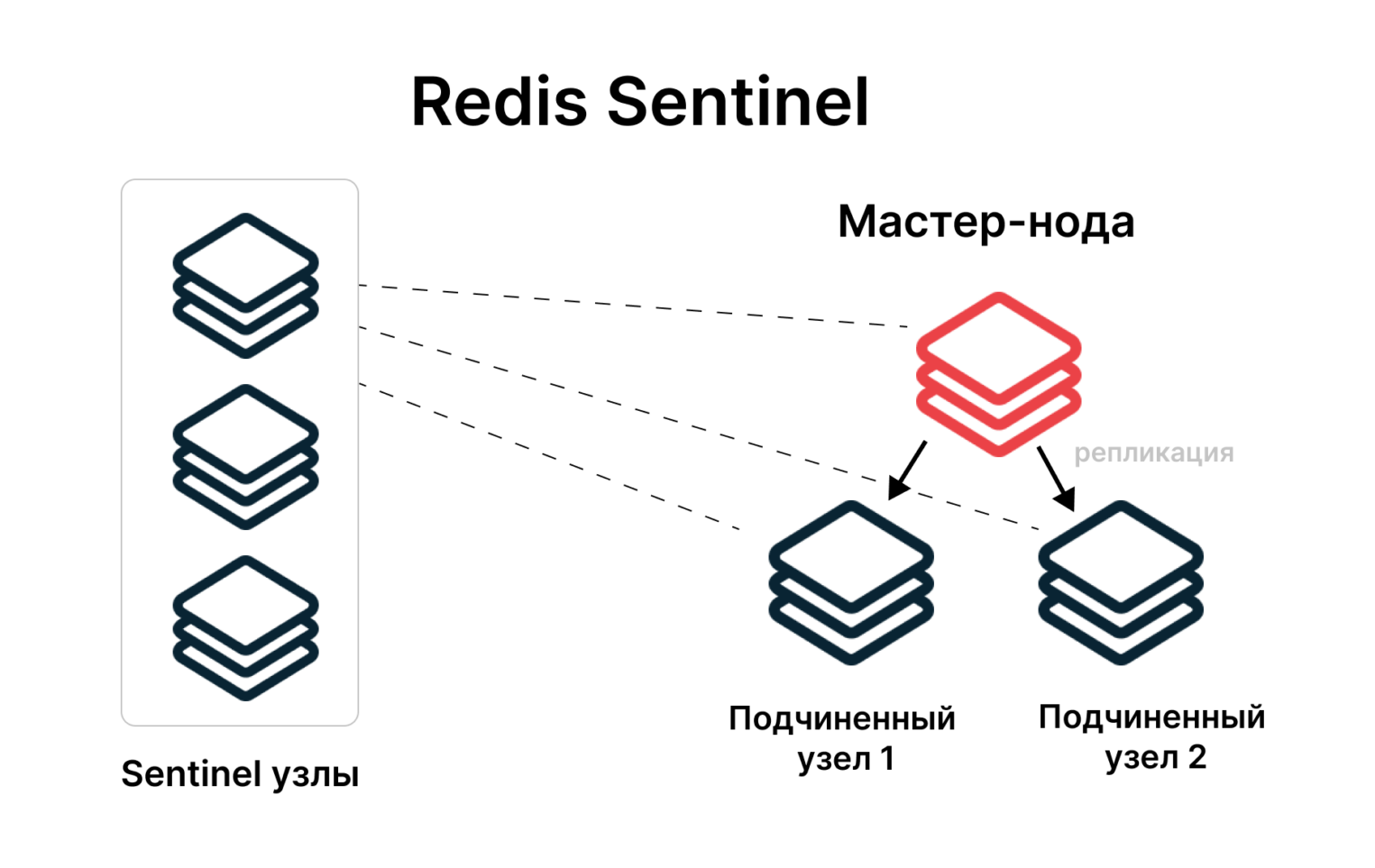
Sentinel, добавленный в СУБД с версии 2.4, представляет собой сервис для создания распределенных систем и мониторинга состояния их узлов. Это решение можно выбрать, когда репликация выполняется при отсутствии полноценного кластера, элементы которого надежно связаны между собой. Sentinel как раз и выступает в роли такой связки.
Sentinel-процессы запускаются в момент потери связи между узлами. Кроме того, узлы Sentinel выполняют и такие функции, как восстановление сервиса после отказа, отправка уведомлений, а также конфигурирование системы: они сообщают, какой экземпляр Redis в данный момент является ведущим.
Redis Cluster
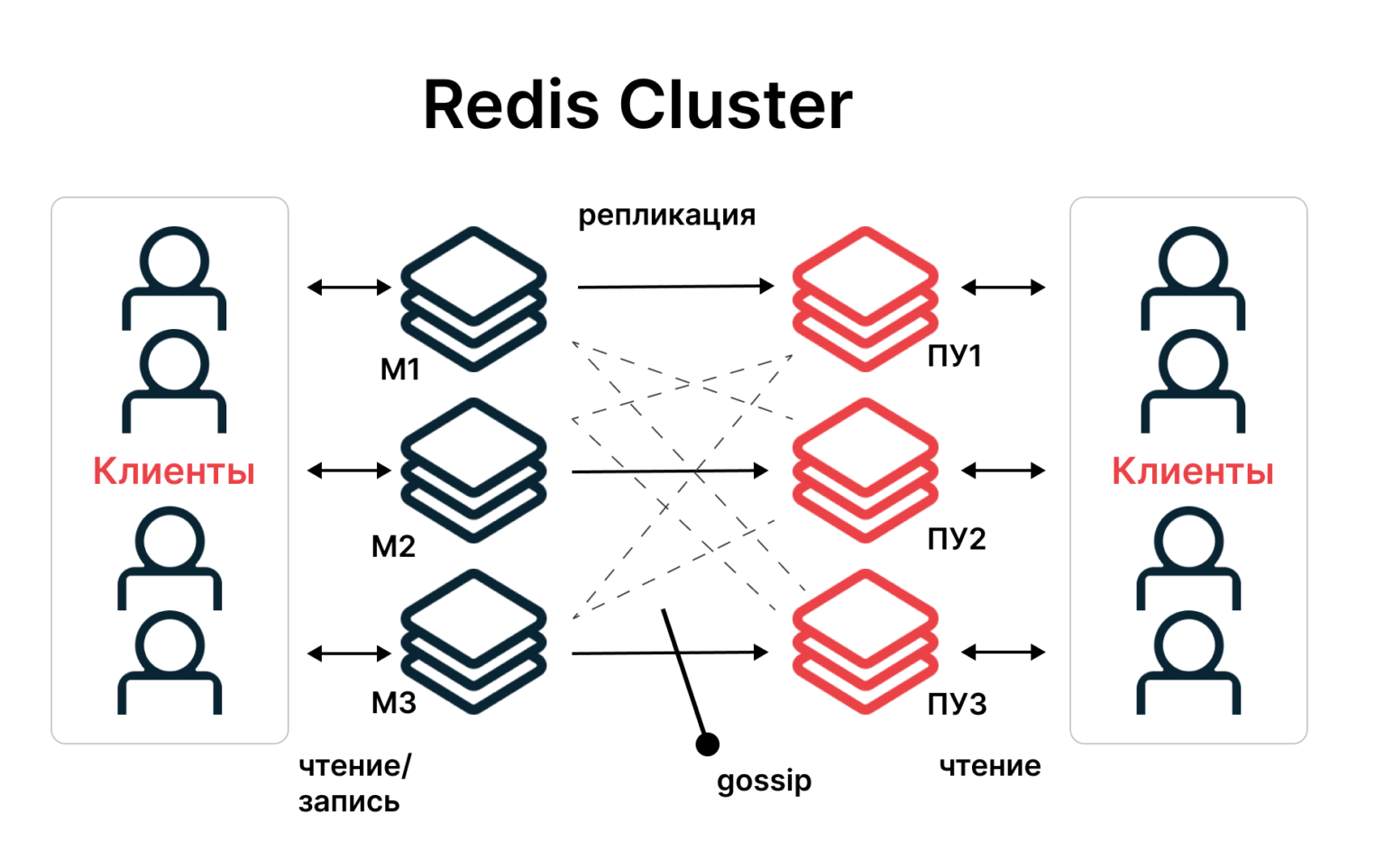
Добавленный в Redis 3.0 Cluster предназначен для горизонтального масштабирования системы, когда нагрузка равномерно распределяется по всему хранилищу. Классическая схема на основе Cluster представляет собой несколько ведущих и несколько подчиненных узлов с распределением данных между всеми узлами системы. А для мониторинга состояния системы обычно используют протокол Gossip.
Одна из главных особенностей Redis Cluster заключается в его механизме работы: он радикально отличается от того, который используется в схемах HA и Sentinel. Если там это репликация, то здесь — шардирование, или шардинг. Шардинг — сегментирование данных, которые в таком виде равномерно распределяются по элементам кластера. Это позволяет существенно снизить нагрузку на хранилище.
Протокол Gossip
При помощи протокола осуществляется мониторинг состояния узлов системы, работающих по механизму шардинга. Если какой-то из основных узлов перестает отвечать на запросы, Gossip передает его права одному из подчиненных узлов. За счет этого существенно повышается отказоустойчивость системы в целом.
Постоянное хранение данных в Redis
СУБД Redis не рассчитана на постоянное хранение данных. Дело в том, что приоритетными задачами Redis являются не надежность хранения, а организация скоростного и бесперебойного доступа к данным. Поэтому для надежного хранения данных рассмотрите решения, совместимые с Redis. Это могут быть классические реляционные базы — PostgreSQL, MySQL или Oracle.
Модели резервирования данных для Redis: файлы RDB и AOF
Пользователи Redis советуют использовать в production как бэкапы данных, так и встроенные инструменты/модели резервирования СУБД.
Таких моделей три:
- Файлы RDB. Подразумевает использование снапшотов — регулярных снимков состояния хранилища (временные интервалы задаются в конфигурации). Главный недостаток этой схемы: если сбой Redis произошел в интервале между созданием снапшотов, то данные потеряются.
- Файлы AOF (Append Only File). Более надежный способ организации хранения данных, поскольку файлы AOF представляют собой независимые журналы для записи команд на восстановление. По умолчанию Redis пишет данные на диск каждую секунду, что позволяет терять минимум информации в случае сбоев.
- RDB и AOF. Комбинирование двух моделей — самое надежное решение, однако в качестве платы за стабильность здесь придется несколько пожертвовать скоростью. Также учтите, что при перезагрузке системы Redis будет использовать файлы AOF.
Попробуйте готовые базы данных Redis в облаке
— 30% на облачные БД — экономьте время и деньги.
Как устроено хранение данных в Redis: создание форков процессов
Форком называется создание нового процесса в системе путем копирования родительского. И эти процессы затем могут взаимодействовать между собой. Перегрузки системы удается избежать благодаря совместному использованию памяти по принципу Copy-On-Write. В результате дополнительная память выделяется только при каких-либо изменениях процесса, но объемы этой памяти незначительны.
Сравнение Redis с хранилищем Memcached
Главным конкурентом Redis является СУБД Memcached, которая появилась на 6 лет раньше.
«Почтенный» возраст — основная причина ограничений Memcached. В отличие от Redis это хранилище не поддерживает продвинутые структуры данных, снапшоты, репликацию, некоторые типы данных (например, геоданных) и имеет ряд других ограничений.
С другой стороны, Memcached — многопоточное хранилище, а Redis — нет, что дает первому некоторые преимущества в производительности. Тем не менее, наличие продвинутых инструментов работы с данными делает Redis предпочтительнее, чем использование Memcached, для большинства проектов.
Примеры использования базы данных Redis
Благодаря новым моделям хранения данных сфера применения Redis широка. Вот несколько областей, где востребовано это хранилище:
- Machine Learning. Современные модели машинного обучения работают с большими объемами данных, должны быстро создаваться и развертываться. Redis обеспечивает хранилище данных непосредственно в памяти, что обеспечивает высокую скорость работы моделей Machine Learning.
- Аналитика в режиме реального времени. Примерами такой аналитики могут служить таргетированная реклама, системы рекомендаций в социальных сетях, а также данные, собираемые с устройств IoT. Redis совместим с различными системами потоковой передачи (например, Apache Kafka, Amazon Kinesis) и обеспечивает высокую скорость обработки данных (задержка не более нескольких мсек).
- Кэширование. Создаваемый в памяти кэш значительно увеличивает скорость работы и производительность любой базы данных (как SQL, так и NoSQL) или приложения. Redis обеспечивает высокую скорость доступа к кэшированным данным без необходимости увеличения серверных мощностей.
- Хранилище сессий. Сессионные данные, включающие пользовательские профили, настройки, состояния, могут снижать скорость работы приложения. Redis решает эту проблему за счет хранения этих данных в кэшированном виде в памяти.
- Системы очередей в мессенджерах и чатах. Redis является однопоточной БД, поэтому команды обрабатываются только в определенной последовательности. Это делает его удобным для выстраивания системы очередей.
- Потоковая передача мультимедиа. Благодаря возможностям передачи данных в режиме реального времени Redis расширяет возможности сетей CDN по трансляции медиаконтента. В результате сети доставки контента реализуют одновременную передачу потоков видео миллионам пользователей.
Также Redis используют для работы с геопространственными данными, анализа продаж и поведения покупателей и клиентов, фильтрации контента. Кроме того, это хранилище задействуется в социальных сетях для потоков сообщений и для связи данных с профилями пользователей.
Redis в облачных базах данных Selectel
В числе готовых кластеров баз данных, которые поддерживает Selectel, есть и Redis. Вы можете создать кластер Redis версии 6 за несколько минут.
Подробнее о том, как работают облачные базы данных и кому нужен Redis:
- Как использовать облачные базы Redis
- Redis: как работать, где применять, какие ограничения (видео)
- Облачные базы данных: что это такое
- Старт работы с облачными базами данных
Заключение
Redis предлагает высокую скорость обработки данных благодаря их хранению в ОЗУ. Это делает эту СУБД одним из лучших решений для систем и приложений с большими объемами данных при необходимости непрерывного доступа к ним.
Источник: selectel.ru
Разбираемся с Redis
Этот материал представляет собой глубокое исследование всего, что связано с Redis. В частности — речь пойдёт о различных способах организации хранилищ Redis, о постоянном хранении данных, о форках процессов.

Что такое Redis?
Redis (Remote Dictionary Service) — это опенсорсный сервер баз данных типа ключ-значение.
Точнее всего описать Redis можно, сказав, что это — сервер структур данных. Уникальные особенности сервера Redis стали основной причиной его популярности и того, что он применяется во множестве реальных проектов.
Вместо того чтобы работать со строками базы данных, перебирать, сортировать, упорядочивать их, что если информация с самого начала будет находиться в структурах данных, которые нужны программисту? Первое время Redis использовали практически так же, как Memcached. Но, по мере развития Redis, эта система управления базами данных (СУБД) нашла применение и во многих других ситуациях. В частности — в реализациях механизма издатель/подписчик, в задачах потоковой обработки данных, в системах, где нужно работать с очередями.
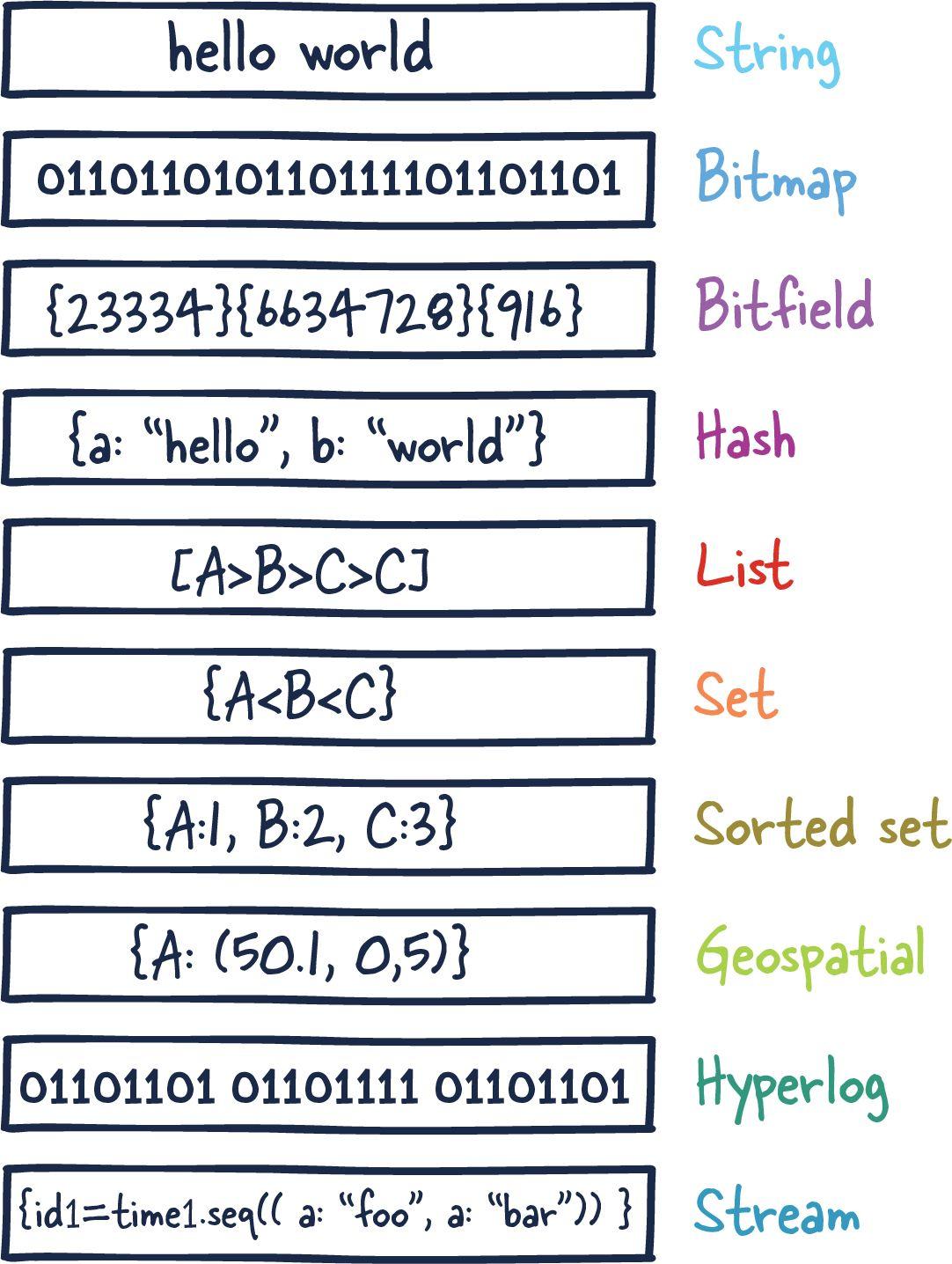
Вот какие типы данных поддерживает Redis:
- Строка (String)
- Битовый массив (Bitmap)
- Битовое поле (Bitfield)
- Хеш-таблица (Hash)
- Список (List)
- Множество (Set)
- Упорядоченное множество (Sorted set)
- Геопространственные данные (Geospatial)
- Структура HyperLogLog (HyperLogLog)
- Поток (Stream)
Redis — это база данных, размещаемая в памяти, которая используется, в основном, в роли кеша, находящегося перед другой, «настоящей» базой данных, вроде MySQL или PostgreSQL. Кеш, основанный на Redis, помогает улучшить производительность приложений. Он эффективно использует скорость работы с данными, характерную для памяти, и смягчает нагрузку центральной базы данных приложения, связанную с обработкой следующих данных:
- Данные, которые редко меняются, к которым часто обращается приложение.
- Данные, не относящиеся к критически важным, которые часто меняются.
Примеры таких данных могут включать в себя сессионные кеши или кеши данных, а так же содержимое панелей управления — вроде списков лидеров и отчётов, включающих в себя данные, агрегированные из разных источников.
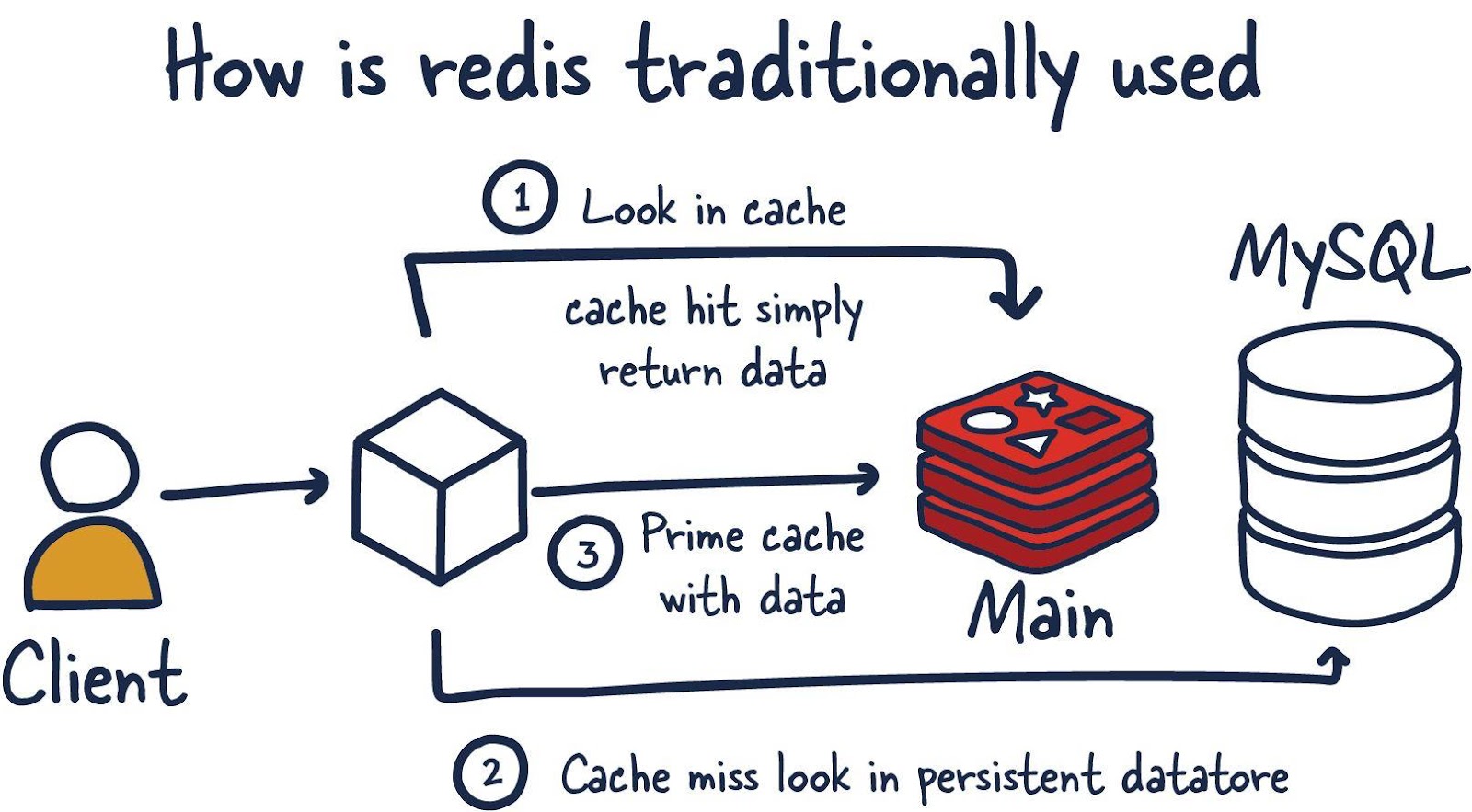
Но во многих случаях Redis гарантирует достаточно высокий уровень сохранности данных, что позволяет использовать эту СУБД в роли настоящей основной базы данных. А добавление в систему плагинов Redis и различных конфигураций высокой доступности (High Availability, HA) делает базу данных Redis крайне интересной для определённых сценариев использования и рабочих нагрузок.
Ещё одна важная особенность Redis заключается в том, что эта СУБД размывает границы между кешем и хранилищем данных. Тут важно понять то, что чтение данных из памяти и работа с данными, находящимися в памяти, гораздо быстрее чем те же операции, выполняемые традиционными СУБД, использующими обычные жёсткие диски (HDD) или твердотельные накопители (SSD).
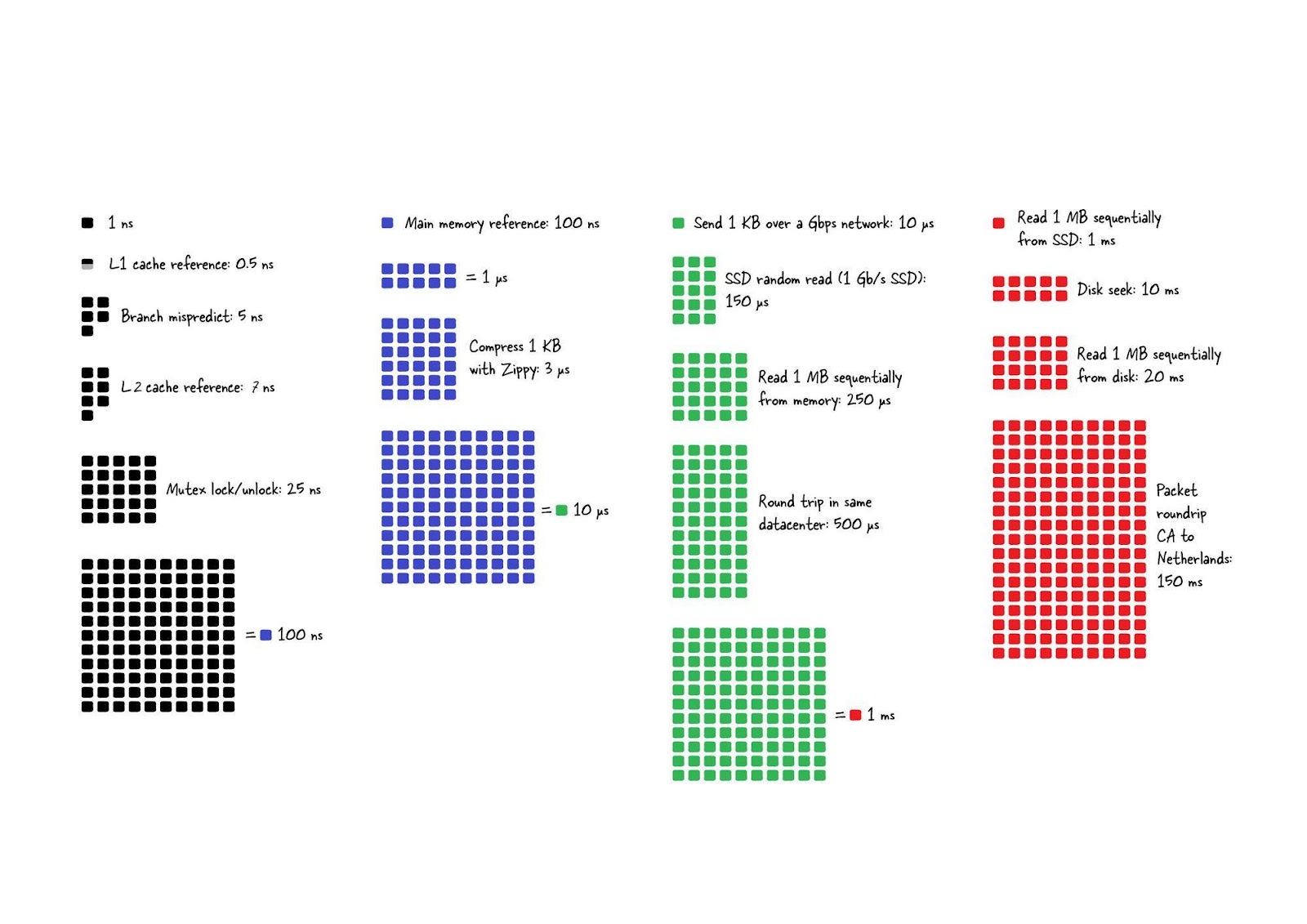
Изначально Redis чаще всего сравнивали с Memcached, с системой, в которой тогда не было и намёка на долговременное хранение данных.
Хранилище Memcached создал в 2003 году Брэд Фицпатрик. Оно появилось на 6 лет раньше Redis. Сначала это был Perl-проект, а позже его переписали на C. В своё время Memcached был стандартным инструментом кеширования. Главные различия между ним и Redis заключаются в том, что в Memcached имеется меньше типов данных, и в ограничениях, связанных с политикой вытеснения ключей. Memcached поддерживает лишь политику LRU (Least Recently Used), когда первыми вытесняются данные, которые не использовались дольше всех.
Ещё одно отличие этих хранилищ заключается в том, что Redis — это однопоточная система, а Memcached — многопоточная. Memcached может показывать отличные результаты производительности в ограниченных окружениях кеширования. А при использовании этой системы в распределённом кластере нужны дополнительные настройки. Redis же поддерживает подобные сценарии работы сразу после установки.
В следующей таблице приведены сведения об актуальных в наши дни различиях между Memcached и Redis.
Характеристика
Memcached
Redis
Задержки менее миллисекунды
Простота использования для разработчиков
Поддержка широкого набора языков программирования
Продвинутые структуры данных
Поддержка модели «издатель/подписчик»
Поддержка геопространственных данных
В наши дни Redis поддерживает настройку того, как именно данные сохраняются на диск. А в самом начале эта система использовала снепшоты, когда асинхронные копии данных, находящихся в памяти, отправляли на диск для долговременного хранения. К сожалению, у этого механизма имеется недостаток, выражающийся в возможной потере данных, изменённых или добавленных в хранилище на временных интервалах между снепшотами.
Хранилище Redis, с момента его появления в 2009 году, серьёзно развилось. Мы рассмотрим большую часть архитектурных и топологических решений, характерных для Redis, что позволит вам, изучив эту систему, включить её в состав своего арсенала систем хранения данных.
Архитектура Redis
Прежде чем мы начнём разговор о внутренних механизмах Redis — рассмотрим различные варианты развёртывания этого хранилища и обсудим компромиссы, на которые приходится идти тем, кто выбирает тот или иной вариант.