
Как известно, микросервисная архитектура основывается на выделении небольших независимых служб, при этом каждая из них реализует отдельную бизнес-функцию. И если в монолитной архитектуре всё связано (при отказе одной функции могут отказать и остальные), то в случае с микросервисами обеспечивается повышенная гибкость и устойчивость системы. Если же мы говорим о High Load-приложениях, мы говорим о крупных IT-решениях, а они могут иметь в своей архитектуре десятки микросервисов, причём с каждым из них может работать независимая команда.
Реальный пример из практики
Рассмотрим реальный кейс от SimbirSoft на примере создания сервиса для начисления кэшбэка. Одна страховая компания попросила модернизировать своё онлайн-приложение, построенное на микросервисах. Была поставлена задача реализовать кэшбэк (начисление бонусных баллов при покупке страхового полиса).
На словах всё выглядело несложно: 1. За каждый оплаченный либо продлённый полис происходит начисление клиенту определённого кэшбэка через бухгалтерский сервис. Клиент имеет доступ к информации об этом начислении. 2. Когда суммарный кэшбэк достигает определённого значения, происходит автоматический перевод средств пользователю посредством бухгалтерского сервиса. Клиент имеет доступ к истории выплат.
Project Reactor — реактивная Java
В основном проекте применялась очередь сообщений Kafka в виде средства обмена данными между микросервисами, а также в виде единственного реплицированного хранилища данных.
Когда нужна реализация каких-либо функций на микросервисной архитектуре, всегда следует думать о возможности горизонтального масштабирования. Код в этом случае должен функционировать не только в многопоточной среде, но и если запустится несколько контейнеров с микросервисом.
Также добавим, что клиентов у этого приложения неограниченное множество, причём многие из них являются мобильными, а значит, довольно медленными.
Blocking vs Non-blocking
В случае применения стандартной сервлетной архитектуры каждый запрос выполняется в отдельном потоке. В целом этот подход неплох, особенно, если мы вспомним возможности современных серверов, способных обрабатывать сотни соединений одновременно.
Но тут есть пара нюансов: 1) не всегда присутствует возможность купить такой сервер; 2) всегда что-то может пойти не так (и это главный нюанс). Допустим, появятся задержки бэка либо вы столкнётесь с ситуацией «retry storm». В результате число активных потоков и соединений увеличится, и кластерные ноды могут попасть в спираль за счёт того, что резервные копии потоков увеличат нагрузку на сервер и перегрузят кластер. Да, мы можем встроить механизмы регулирования, дабы компенсировать риски и стабилизировать ситуацию, но это не решит всех проблем. Плюс, восстановление бывает долгим и рискованным.
А вот асинхронные системы работают несколько иначе. Как правило, в них одному ядру соответствует один поток, причём сам цикл запроса-ответа обрабатывается посредством событий и коллбэков. Выходит, что в тех местах, где мы «платили» за запрос целым потоком, просто добавится очередное сообщение.
Project Reactor. В чем его идея?
Очевидно, что и восстановление после разных неприятностей будет даваться легче, ведь обработать доп. сообщения в очереди проще, чем складировать множество потоков. А так как все запросы асинхронны, у нас упрощается и масштабируемость системы. И в случае, если видно большое число сообщений в очереди, можно просто временно создать дополнительных потребителей.
То есть устойчивость такой системы достигается благодаря самой природе асинхронного подхода. Какие тут нюансы: 1) мы можем попробовать обрабатывать исключение локально; 2) в асинхронных системах не происходит блокировка компонентов обработкой исключений, т. е. ошибка в одном компоненте на остальные не влияет. Мало того, когда один компонент с обработкой сообщения не справляется, это сообщение можно обработать другим компонентом, который записан на тот же адрес.
Но, как известно, у всего есть своя цена, поэтому у асинхронного подхода существует и минусы. Например, усложняется разработка и отладка. Да и не всегда переход на асинхронный код даёт улучшение в производительности.
Но вернёмся к нашему приложению. У него множество юзеров, осуществляющих доступ с мобильных девайсов. Это и стало причиной применить один из асинхронных фреймворков.
Заказчик хотел, чтобы проект был реализован на Java (это повышало удобство дальнейшей поддержки). Так как вариантов высокоуровневых абстракций было не очень-то много, был выбран Project Reactor.
Работаем с Project Reactor
Reactor — реализация спецификации Reactive Streams. В «реакторе» существуют две основные структуры данных — Mono и Flux. И обе они представляют собой реализации интерфейса Publisher, являясь асинхронным потоком элементов или единичным асинхронным элементом соответственно.
Внешне стримы в Reactor похожи на стандартные Java-стримы по коллекциям (java.util.stream.Stream). Да, в языке программирования Java, Stream — это не только механизм работы с коллекциями. Но здесь надо вспомнить и то, что Flux — это тоже не коллекция.
В «Джаве» перед началом стрима по коллекции есть все её элементы, то есть мы знаем её размер и так далее. А вот Flux лучше рассматривать в качествен некой отложенной коллекции, число элементов в которой неизвестно в момент выполнения стрима.
Пусть мы и можем сконвертировать Flux в коллекцию стандартными средствами, это будет просто блокирующая операция, которая не даст гарантии выполнения последующих элементов. Обычно (кроме тестов) так делать нельзя, ведь мы желаем минимизировать число блокирующих операций и уменьшить время простоя железа, особенно, когда мы говорим про операции ввода-вывода.
Схема работы
В самом начале работы с проектом надо, основываясь на техническом задании, определить функциональные блоки, которые потом станут отдельными микросервисами.
Можно сразу отметить, что приложение имеет три главных процесса: 1. Получение информации извне (пользователи, оплата, полисы) с последующим начислением кэшбэка на основе полученной информации. Назовём этот сервис «Калькулятор». 2. Общение с пользователем. Наше приложение обращается к хранилищу, дабы найти нужный кэшбэк по конкретному пользователю.
Это 2-й сервис — «Хранилище». 3. Общение с бухгалтерским сервисом. Т. к. начисление кэшбэка и выплаты будут проводится через бухгалтерский сервис, назовём 3-й сервис «Бухгалтер».
Таким образом, у нас получилась вполне себе простая схема:
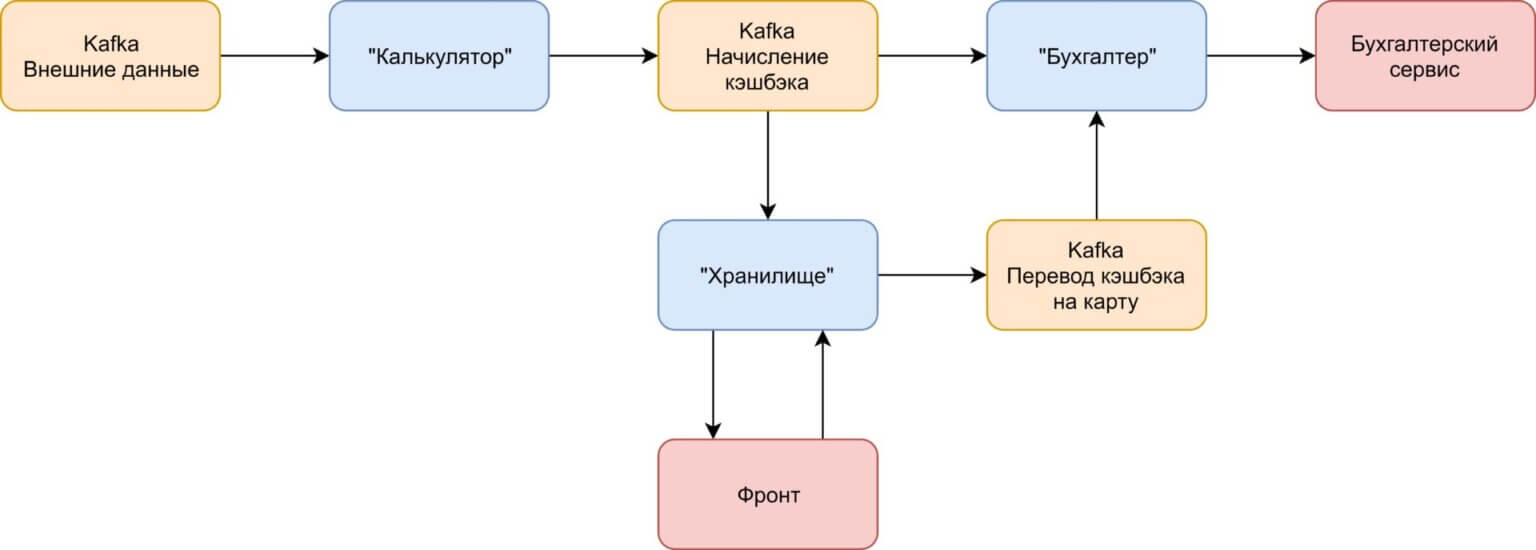
Сервер «Калькулятор» вычисляет кэшбэк по каждому пользователю/полису/факту оплаты, отправляя сообщение в отдельную очередь. Сервисы «Бухгалтер» и «Хранилище» читают сообщения из данной очереди. «Хранилище» выполняет сохранение кэшбэка и показывает его юзеру, а при достижения минимального порога выплаты активирует зачисление средств пользователю на его карту. «Бухгалтер» осуществляет вызов внешнего бухгалтерского сервиса в целях физического начисления бонусов.
Организуем локальное хранилище
Большое значение придаётся очерёдности вышеописанных процессов. Например, очевидно, что «Калькулятор» функционирует на основании сообщений, поступающих от внешних сервисов. Но бывают ситуации, когда «Калькулятор» не может принять решение об отправке на основании одного входящего сообщения. Допустим, ему надо проверить два внешних топика: оплату и полисы. В данном случае требуется внутреннее хранилище, которое нужно формировать на основе всех внешних сообщений.
Сравнив стандартные SQL-варианты и подход NoSQL, было отдано предпочтение MongoDB, т. к.: 1. Для mongoDB существует готовый фреймворк для работы с Project Reactor — reactive mongo. 2. У нас мало таблиц, как и связей между таблицами. 3. База проста в применении, не надо следить за соответствием моделей таблицам.
Также надо разделить процессы по формированию локального хранилища и принятию решений об отправке. Каким образом это реализовать, если решение об отправке принимается на основании тех же самых сообщений, по которым строится внутреннее хранилище? Один из вариантов — разделение по времени и запуск начисления по внешнему планировщику. Пожалуй, это самый простой и понятный способ реализации.
Репроцессинг
Дабы упростить архитектуру приложения и уменьшить риски, желательно применять микросервисы stateless, без локальных хранилищ. В результате не имеет значения, какая информация у нас на входе, т. к. она просто проходит по цепочке стрима.
Если это по тем либо иным причинам невозможно, стоит попробовать изолировать логику работы с состоянием в отдельном слое. Говоря иначе, надо поставить дополнительный уровень абстракции над логикой с состоянием. В таком случае в приложении присутствует сегмент statefull, однако он изолирован, а другие его части с состоянием не связаны.
Но на деле с этим, бывает, возникают сложности. Допустим, не позволяет архитектура, отсутствует время либо понимание, каким образом это реализовать в конкретном проекте. Могут и не позволять требования репроцессинга. Во время включения и выключения сервиса (и сбросе оффсетов) такой сервис станет повторно выполнять уже выполненные действия.
В нашей ситуации «Калькулятор» станет повторно отбрасывать сообщения о начислениях кэшбэка. Мало того, даже локальное хранилище не будет гарантировать правильную работу, ведь оно не реплицировано и может быть целиком удалено в любой момент и вместе с сервисом.
Для решения вопроса можно использовать специальную очередь отправленных сообщений. Именно эту очередь мы будем читать, записывая в локальное хранилище на старте сервиса, совместно с остальными внешними сообщениями.
Другие особенности
Очередная особенность Project Reactor связана с работой с фронтэндом. Её суть в том, что во многих случаях просто получить какое-нибудь значение нам недостаточно. Гораздо чаще надо получить значение, а потом отслеживать его изменения. Данный вопрос решается просто посредством reactive mongo. У хранилища из библиотеки reactive mongo имеются методы отслеживания и получения, которые вернут как требуемое значение, так и его последующие изменения, если они будут.
Также обратите внимание на сервис «Бухгалтер». Допустим, данный сервис работает с внешним API по REST либо, как у нас, по SOAP. Здесь тоже действуют требования по репроцессингу, плюс требуется отдельная очередь истории. Но возможны и доп. требования по устойчивости системы в целом.
К примеру, что произойдёт, когда внешний API ответит 500-й ошибкой? В нашем случае мы сможем использовать стандартный механизм «Реактора» .retryBackoff() — он попытается отправить сообщение ещё пару раз, увеличивая временную задержку между повторными сообщениями. Также мы можем настроить стрим на отлавливание конкретных ошибок, чтобы реагировать только на них. Если интересуют подробности по этому моменту, вам сюда.
Тестирование
Разумеется, проект не заканчивается созданием рабочих модулей. Требуется проверить его работоспособность, допустим, посредством юнит-тестов. Для рабочих модулей на Project Reactor в юнит-тестах применяют StepVerifier — внутренний компонент, позволяющий верно тестировать функциональность. К тому же, StepVerifier имеет легкодоступную и исчерпывающую документацию.
Теперь скажем пару слов про интеграционные тесты. Во многих случаях они предполагают запуск микросервисов в контейнерах, поэтому при проектировании нужно подумать о полноценном логировании. Если это не выполнено, существует риск долгого поиска причин падения каждый раз.
После выполнения модульных и интеграционных тестов стало ясно, что приложение к асинхронной работе готово. А также покрыто тестами и готово и к горизонтальному масштабированию, плюс устойчиво к неожиданным отключениям. В целом разработка заняла порядка 3-х недель с отладкой и ревью заказчика.
Итог
Если вы имеете дело с высоконагруженными приложениями с большим числом внешних пользователей, рассмотрите вариант асинхронной работы с использованием реактивного подхода.
Хоть реактивная реализация и не всегда повышает быстродействие системы, зато она существенно повышает её устойчивость и масштабируемость.
Применение Reactor даёт возможность относительно просто реализовать асинхронную работу, сделав решение наглядным и понятным для последующей поддержки. Также работа с Project Reactor потребует особенного внимания при написании кода, в частности, при выстраивании стримов Mono и Flux. Вдобавок к этому, нужно постоянно сверяться с документацией и выполнять промежуточные тесты.
В этой статье были рассмотрены: — асинхронная работа; — репроцессинг; — организация хранилищ; — вызов внешних сервисов; — тестирование и прочие особенности, о которых нельзя забывать, если вы реализуете проект с микросервисами и Reactor.
Возможно, этот опыт команды SimbirSoft, пригодится и вам. Успехов в построении высоконагруженных приложений!
Источник: otus.ru
Реактивное программирование со Spring, часть 2 Project Reactor
Это вторая часть серии заметок о реактивном программировании, в которой представлен обзор Project Reactor, реактивной библиотеки, основанной на спецификации Reactive Streams.
1. ВВЕДЕНИЕ В PROJECT REACTOR
Реактивное программирование поддерживается Spring Framework, начиная с версии 5. Эта поддержка построена на основе Project Reactor.
Project Reactor (или просто Reactor) — это библиотека Reactive для создания неблокирующих приложений на JVM, основанная на спецификации Reactive Streams. Reactor — это основа реактивного стека в экосистеме Spring, и он разрабатывается в тесном сотрудничестве со Spring. WebFlux, веб-фреймворк с реактивным стеком Spring, использует Reactor в качестве базовой зависимости.
1.1 МОДУЛИ REACTOR
Проект Reactor состоит из набора модулей, перечисленных в документации Reactor. Модули встраиваемы и совместимы. Основным артефактом является Reactor Core, который содержит реактивные типы Flux и Mono, которые реализуют интерфейс Publisher Reactive Stream (подробности см. в первом сообщении этой серии) и набор операторов, которые могут применяться к ним.
Некоторые другие модули:
- Reactor Test — предоставляет некоторые утилиты для тестирования реактивных потоков
- Reactor Extra — предоставляет некоторые дополнительные операторы Flux
- Reactor Netty — неблокирующие клиенты и серверы TCP, HTTP и UDP с поддержкой обратного давления — на основе инфраструктуры Netty
- Reactor Adapter — адаптер для других реактивных библиотек, таких как RxJava2 и Akka Streams
- Reactor Kafka — реактивный API для Kafka, который позволяет публиковать и получать сообщения в Kafka.
1.2 НАСТРОйКА ПРОЕКТА
Прежде чем мы продолжим, если вы хотите настроить проект и запустить некоторые из приведенных ниже примеров кода, сгенерируйте новое приложение Spring Boot с помощью Spring Initializr. В качестве зависимости выберите Spring Reactive Web. После импорта проекта в вашу среду IDE взгляните на файл POM, и вы увидите, что добавлена зависимость spring-boot-starter-webflux, которая также внесет зависимость ядра-реактора. Также в качестве зависимости добавлен тест-реактор. Теперь вы готовы к запуску следующих примеров кода.
. org.springframework.boot spring-boot-starter-webflux org.springframework.boot spring-boot-starter-test test org.junit.vintage junit-vintage-engine io.projectreactor reactor-test test .
2. ВОЗМОЖНОСТИ REACTOR CORE
Reactor Core определяет реактивные типы Flux и Mono.
2.1 FLUX И MONO
Flux — это Publisher, который может испускать от 0 до N элементов, а Mono может испускать от 0 до 1 элемента. Оба они завершаются либо сигналом завершения, либо ошибкой, и они вызывают методы onNext, onComplete и onError нижестоящего подписчика. Помимо реализации функций, описанных в спецификации Reactive Streams, Flux и Mono предоставляют набор операторов для поддержки преобразований, фильтрации и обработки ошибок.
В качестве первого упражнения перейдите к классу тестирования, созданному в вашем новом проекте, добавьте следующий пример и запустите его:
Метод just создает поток, который испускает предоставленные элементы, а затем завершается. Ничего не передается, пока кто-нибудь на это не подпишется. Чтобы подписаться на него, мы вызываем метод subscribe и в этом случае просто распечатываем отправленные элементы. Создание Mono также может быть выполнено с помощью метода just, с той лишь разницей, что разрешен только один параметр.
2.2 ОБЪЕДИНЕНИЕ ОПЕРАТОРОВ
Взгляните на Flux API, и вы увидите, что почти все методы возвращают Flux или Mono, что означает, что операторы могут быть связаны. Каждый оператор добавляет поведение к Publisher (Flux или Mono) и переносит Publisher предыдущего шага в новый экземпляр. Данные поступают от первого издателя и перемещаются по цепочке, трансформируясь каждым оператором. В конце концов, подписчик завершает процесс. Обратите внимание, что ничего не происходит, пока подписчик не подпишется на издателя.
Существует оператор log(), который обеспечивает регистрацию всех сигналов Reactive Streams, происходящих за кулисами. Просто измените последнюю строку приведенного выше примера на
fluxColors.log().subscribe(System.out::println);
и перезапустите тест. Теперь вы увидите, что к выходным данным добавляется следующее:
2020-09-12 16:16:39.779 INFO 6252 — [ main] reactor.Flux.Array.1 : | onSubscribe([Synchronous Fuseable] FluxArray.ArraySubscription) 2020-09-12 16:16:39.781 INFO 6252 — [ main] reactor.Flux.Array.1 : | request(unbounded) 2020-09-12 16:16:39.781 INFO 6252 — [ main] reactor.Flux.Array.1 : | onNext(red) red 2020-09-12 16:16:39.781 INFO 6252 — [ main] reactor.Flux.Array.1 : | onNext(green) green 2020-09-12 16:16:39.781 INFO 6252 — [ main] reactor.Flux.Array.1 : | onNext(blue) blue 2020-09-12 16:16:39.782 INFO 6252 — [ main] reactor.Flux.Array.1 : | onComplete()
Теперь, чтобы увидеть, что произойдет, если вы исключите вызов subscribe(), снова измените последнюю строку кода на следующую и повторно запустите тест:
fluxColors.log();
Как вы увидите из выходных данных журнала, сейчас никакие элементы не отправляются — поскольку нет подписчика, инициирующего процесс.
2.3 ПОИСК ПОДХОДЯЩЕГО ОПЕРАТОРА
Reactor предоставляет длинный список операторов, и в качестве помощи в поиске подходящего оператора для конкретного варианта использования есть специальное приложение в справочной документации Reactor. Он разделен на различные категории, как показано в таблице ниже.
КАТЕГОРИЯ ОПЕРАТОРА
ПРИМЕРЫ
Создание новой последовательности
just, fromArray, fromIterable, fromStream
Преобразование существующей последовательности
map, flatMap, startWith, concatWith
Заглядывать в последовательность
doOnNext, doOnComplete, doOnError, doOnCancel
filter, ignoreElements, distinct, elementAt, takeLast
onErrorReturn, onErrorResume, retry
Работаем со временем
elapsed, interval, timestamp, timeout
buffer, groupBy, window
Возвращаясь к синхронному миру
block, blockFirst, blockLast, toIterable, toStream
Многоадресная рассылка потока нескольким подписчикам
publish, cache, replay
Теперь не стесняйтесь создать несколько небольших примеров, в которых используются некоторые из этих операторов, и посмотреть, что произойдет, когда вы их запустите. Например, с помощью оператора map (который преобразует элементы, создаваемые путем применения синхронной функции к каждому элементу):
Или оператор zip, который объединяет несколько источников вместе (ожидая, пока все источники испускают один элемент, и объединяет их в кортеж):
3. ОБРАБОТКА ОШИБОК
Как описано в предыдущем сообщении в блоге, в Reactive Streams ошибки — это терминальные события. При возникновении ошибки вся последовательность останавливается, и ошибка передается методу onError подписчика, который всегда должен быть определен. Если не определено, onError вызовет исключение UnsupportedOperationException.
Как вы видите, запустив следующий пример, третье значение никогда не генерируется, поскольку второе значение приводит к ошибке:
Результат будет выглядеть так:
Next: 10 / -1 = -10 Error: java.lang.ArithmeticException: / by zero
Также можно обрабатывать ошибки в середине реактивной цепочки, используя операторы обработки ошибок:
Метод onErrorReturn будет выдавать резервное значение, когда наблюдается ошибка указанного типа. Это можно сравнить с перехватом исключения и возвратом статического запасного значения в императивном программировании. См. Пример ниже:
Next: 10 / -1 = -10 Next: Division by 0 not allowed
Как видите, использование оператора обработки ошибок таким образом все еще не позволяет продолжить исходную реактивную последовательность (третье значение здесь также не генерируется), а скорее заменяет ее. Если недостаточно просто вернуть какое-то значение по умолчанию, вы можете использовать этот onErrorResume метод, чтобы подписаться на резервного издателя при возникновении ошибки. Это можно сравнить с перехватом исключения и вызовом резервного метода в императивном программировании. Если, например, вызов внешней службы завершается неудачно, реализация onErrorResume может быть связана с извлечением данных из локального кеша.
4. ТЕСТИРОВАНИЕ
Модуль Reactor Test предоставляет служебные программы, которые могут помочь в тестировании поведения вашего Flux или Mono. В этом помогает API StepVerifier. Вы создаете StepVerifier и передаете его издателю для тестирования. StepVerifier подписывается на Publisher при вызове метода verify, а затем сравнивает выданные значения с вашими определенными ожиданиями.
См. следующий пример:
Взглянув на вывод (показан ниже), вы можете увидеть, что первая и вторая операции map выполняются в потоке из планировщика A, поскольку первый subscribeOn в цепочке переключается на этот планировщик, и это влияет на всю цепочку. Перед третьей операцией map выполняется publishOn, переключающий контекст выполнения на Scheduler B, в результате чего третья и четвертая операции map выполняются в этом контексте (поскольку вторая subscribeOn не будет иметь никакого эффекта). И, наконец, есть новый метод publishOn, который переключает обратно на Планировщик A перед последней операцией map.
First map: Scheduler A-4 Second map: Scheduler A-4 Third map: Scheduler B-3 Fourth map: Scheduler B-3 Fifth map: Scheduler A-1
6. BACKPRESSURE (ПРОТИВОДАВЛЕНИЕ)
Как вы могли вспомнить из первой части этой серии блогов, противодавление — это способность потребителя сигнализировать производителю, с какой скоростью выброса он может справиться, чтобы он не перегружался.
В приведенном ниже примере показано, как подписчик может контролировать скорость передачи, вызывая request(n) метод в Subscription.
Запустите его, и вы увидите, что по запросу одновременно генерируются два значения:
onSubscribe Requesting 2 emissions onNext 1 onNext 2 Requesting 2 emissions onNext 3 onNext 4 Requesting 2 emissions onNext 5 onComplete
В Subscription также есть cancel метод, позволяющий запросить Издателя остановить эмиссию и очистить ресурсы.
7. ХОЛОДНЫЕ И ГОРЯЧИЕ PUBLISHER
Доступны два типа Publisher — cold и hot (холодные и горячие). Пока что мы сосредоточились на холодных Publisher. Как мы заявляли ранее, ничего не происходит, пока мы не подпишемся — но на самом деле это верно только для холодных издателей.
Холодный Publisher генерирует новые данные для каждой подписки. Если подписки нет, данные никогда не генерируются. Напротив, hot издатель не зависит от подписчиков. Он может начать публикацию данных без подписчиков. Если подписчик подписывается после того, как издатель начал передавать значения, он получит только значения, выпущенные после его подписки.
Publisher в Reactor по умолчанию не работают. Один из способов создания горячего Publisher — это вызвать publish() метод в Flux. Это вернет ConnectableFlux , у которого есть метод connect() для запуска передачи значений. Подписчики должны затем подписаться на этот ConnectableFlux вместо исходного Flux.
Давайте посмотрим на простой холодный и горячий Publisher, чтобы увидеть различное поведение. В приведенном ниже примере coldPublisherExample оператор interval используется для создания потока, который генерирует значения long, начинающиеся с 0.
При запуске будет получен следующий результат:
Subscriber A, value: 0 Subscriber A, value: 1 Subscriber A, value: 2 Subscriber B, value: 0 Subscriber A, value: 3 Subscriber B, value: 1 Subscriber A, value: 4 Subscriber B, value: 2
Теперь вы можете задаться вопросом, почему что-то происходит, когда основной поток спит, но это потому, что оператор интервала по умолчанию выполняется в планировщике Schedulers.parallel(). Как видите, оба подписчика получат значения, начинающиеся с 0.
Теперь давайте посмотрим, что происходит, когда мы используем ConnectableFlux:
На этот раз мы получаем следующий результат:
Subscriber A, value: 2 Subscriber A, value: 3 Subscriber A, value: 4 Subscriber B, value: 4 Subscriber A, value: 5 Subscriber B, value: 5 Subscriber A, value: 6 Subscriber B, value: 6
Как мы видим, на этот раз ни один из подписчиков не получает исходные значения 0 и 1. Они получают значения, которые отправляются после подписки. Вместо того, чтобы вручную запускать публикацию, с помощью этого autoConnect(n) метода также можно настроить ConnectableFlux так, чтобы он запускался после n подписок.
8. ПРОЧИЕ ВОЗМОЖНОСТИ
8.1 ЗАВЕРШЕНИЕ СИНХРОННОГО, БЛОКИРУЮЩЕГО ВЫЗОВА
Когда необходимо использовать источник информации, который является синхронным и блокирующим, в Reactor рекомендуется использовать следующий шаблон:
Mono blockingWrapper = Mono.fromCallable(() -> < return /* make a remote synchronous call */ >); blockingWrapper = blockingWrapper.subscribeOn(Schedulers.boundedElastic());
Метод fromCallable создает Mono, который производит его значение с помощью прилагаемого Callable. Используя Schedulers.boundedElastic(), мы гарантируем, что каждая подписка выполняется на выделенном однопоточном работнике, не влияя на другую неблокирующую обработку.
8.2 КОНТЕКСТ
Иногда возникает необходимость передать некоторые дополнительные, обычно технические данные, через реактивный конвейер. Сравните это с привязкой некоторого состояния к потоку с помощью ThreadLocal в императивном мире.
Reactor имеет функцию, которая в некоторой степени сравнима с ThreadLocal, но может применяться к Flux или Mono вместо Thread, называемая a Context . Это интерфейс, похожий на Map, где вы можете хранить пары ключ-значение и получать значение по его ключу. Контекст прозрачно распространяется по всему реактивному конвейеру и может быть легко доступен в любой момент, вызвав метод Mono.subscriberContext().
Контекст может быть заполнен во время подписки путем добавления вызова метода subscriberContext(Function) или subscriberContext(Context) метода в конце вашего реактивного конвейера, как показано в методе тестирования ниже..
8.3 SINKS
Rector также предлагает возможность создавать Flux или Mono, программно определяя события onNext, onError и onComplete. Для этого предоставляется так называемый API-интерфейс приемника, запускающий события. Существуют несколько различных вариантов раковин, чтобы узнать больше об этом, читайте далее в справочной документации: Программное создание последовательности
8.4 ОТЛАДКА
Отладка реактивного кода может стать проблемой из-за его функционального декларативного стиля, в котором фактическое объявление (или «assembly ») и обработка сигнала («execution») не происходят одновременно. Обычная трассировка стека Java, генерируемая приложением Reactor, не будет включать никаких ссылок на ассемблерный код, что затрудняет определение фактической основной причины распространенной ошибки.
Чтобы получить более значимую трассировку стека, которая включает информацию о сборке (также называемую трассировкой), вы можете добавить вызов Hooks.onOperatorDebug() в свое приложение. Однако это нельзя использовать в производственной среде, потому что это связано с перемещением тяжелого стека и может отрицательно повлиять на производительность.
Для использования в производственной среде Project Reactor предоставляет отдельный Java-агент, который инструментирует ваш код и добавляет отладочную информацию, не требуя больших ресурсов для захвата трассировки стека при каждом вызове оператора. Чтобы использовать его, вам нужно добавить reactor-tools артефакт в свои зависимости и инициализировать его при запуске приложения Spring Boot:
public static void main(String[] args)
8.5 МЕТРИКИ
Reactor предоставляет встроенную поддержку для включения и отображения показателей как для планировщиков (Schedulers), так и для издателей (Publishers). Дополнительные сведения см. в разделе «Метрики» Справочного руководства.
9. ПОДВОДЯ ИТОГ…
В этом сообщении в блоге представлен обзор Project Reactor, в основном сосредоточенный на функциях Reactor Core. Следующий блог в этой серии будет о WebFlux — реактивном фреймворке Spring, который использует Reactor в качестве реактивной библиотеки!
ССЫЛКИ
Spring Web Reactive Framework
Reactor Debugging Experience
Flight of the Flux 1 — Assembly vs Subscription
Источник: temofeev.ru
Reactor: новый сервис, позволяющий создавать мобильные приложения
Люди, разработавшие AppPresser, первый фреймворк для разработки мобильных приложений, наделали шума на WordCamp San Francisco, представив лайв-демо своего будущего продукта Reactor.

AppPresser, выпущенный в январе, являлся инновационным в том плане, что он демонстрировал мощь WordPress как платформы для создания приложений. Однако он не оправдал надежд команды, поскольку оказался не таким дружественным к пользователям – для него требовалось устанавливать массу плагинов, а также пересылать приложение для тестирования его на мобильных устройствах. Настройка приложения через AppPresser зачастую оставляла пользователей, особенно не являющихся разработчиками, в некотором замешательстве – и они очень часто прибегали к поддержке.
После просмотра демо Reactor можно сказать, что этот новый продукт когда-нибудь станет официальным преемником AppPresser. Создание приложений в Reactor осуществляется гораздо проще.
Reactor предлагает сервис создания приложений на базе WP JSON REST API
Райан Фугейт, разработчик AppPresser, принимающий участие в создании Reactor, отметил, что предстоящий выпуск WP JSON REST API поспособствовал решению создать Reactor. «API позволяет вам реализовать лучший опыт взаимодействия в ваших приложениях вместе с оффлайн-возможностями». Контент, созданный в Reactor, кэшируется, сохраняется в вашем приложении и доступен оффлайн.
Любой плагин, создающий свои собственные конечные точки для WP API, может легко передавать свои данные и интегрироваться с Reactor. В случае с AppPresser для каждого плагина надо было создавать сложные дополнения. В Reactor плагины могут самостоятельно взаимодействовать с сервисом через новый WP API.
«В данный момент мы работаем над поддержкой WooCommerce и будем постепенно добавлять разные плагины, как только в них появится поддержка нового API», отметил Фугейт.
Поскольку создание приложений с помощью Reactor поставляется как веб-сервис, команда может предложить связный опыт взаимодействия для своих клиентов. «Создание собственного опыта взаимодействия очень удобно для пользователей», отметил Фугейт. «Это позволило нам интегрировать разные вещи, такие как различные уведомления, что нельзя было реализовать другим способом».
Тестирование Reactor показало, что в нем особенно выделяется одна полезная возможность – лайв превью приложения. Вы можете видеть это в демо-видео ниже. Вместо отправки вам приложения, созданного в Phonegap, вы можете просто автоматически создать приложение и просканировать QR-код для загрузки его на свой телефон с целью тестирования.
Будет ли AppPresser остановлен в будущем?
Основываясь на лайв-демо Reactor, которое я видел, можно сделать вывод, что его функции заметно обходят AppPresser. Есть столько явных преимуществ использования Reactor, что этот сервис делает AppPresser устаревшим. Reactor включает в себя:
- Предварительно созданные шаблоны страниц
- Настройки дизайна
- Создание и просмотр вашего приложения, не трогая его файлов
- Связанный и не связанный с WP контент
- Интегрированные push-уведомления
- Автоматическое создание приложения
- Статистика приложения
- Быстрая производительность
- Оффлайн-возможности
Те, кто приобрели оригинальный продукт AppPresser, хотят знать, станет ли Reactor в ближайшее время его заменой. Команда AppPresser продолжит поддержку оригинального продукта, и не будет удалять его в ближайшее время, как утверждает Фугейт:
«Классический AppPresser – это по-прежнему очень полезный продукт для определенных проектов. К примеру, интеграция с BuddyPress является очень мощной, и некоторые пользователи, возможно, хотят загрузить произвольный контент, который недоступен через WP API. Проекты, такие как приложение Dallas Museum of Art от Webdev studios – яркий пример проекта для классического AppPresser.
Reactor имеет массу преимуществ, поэтому мы рекомендуем пользователям сначала ознакомиться с ним. Мы по-прежнему будем продавать и поддерживать классический AppPresser в обозримом будущем».
Доступ к Reactor будет осуществляться за ежемесячную плату. Новый сервис может стать более выгодным в плане цены для клиентов, которым требуется интеграция push-уведомлений в своих приложениях, поскольку многие из них в настоящее время платят по 50 долларов в месяц за сторонние сервисы. Reactor имеет свои собственные push-уведомления, что позволяет снизить цену для разработчиков приложений, которым нужна такая возможность.
Новый сервис создания приложений на WordPress – это прекрасный пример того, как можно использовать предстоящий WP JSON REST API. Команда AppPresser продолжает вносить новшества в пространство приложений, где фактически нет конкуренции со стороны других компаний, однако это может быстро поменяться, когда другие тоже откроют для себя мощь нового API. Команда надеется выпустить Reactor в конце этого года.
Источник: wordpressify.ru