
В этом разделе рассматриваются концепции разработки данных (data mining) и то, как эта технология может применяться для реализации потенциальных возможностей хранилищ данных. Особое внимание уделяется характеристикам основных, операций, методов и инструментов разработки данных. Кроме того,рассматривается связь между технологией разработки данных и организацией хранилищ данных.
Простое хранение информации в хранилище данных не дает тех преимуществ, которые организация хотела бы получить. Для реализации потенциала хранилища данных необходимо извлечь знания, скрытые внутри хранилища. Однако, с ростом объема и усложнением структуры помещенных в хранилище данных, бизнес-аналитикам становится чрезвычайно трудно, если вообще возможно, выявлять тенденции и связи, существующие между элементами данных, используя лишь простые инструменты создания запросов и отчетов. Технология разработки данных является одним из наилучших способов извлечения осмысленных тенденций и закономерностей из огромного количества данных. Эта технология помогает отыскать внутри хранилища данных такую информацию, которая не может быть обнаружена ни с помощью запросов, ни посредством создания отчетов.
Информатика 9 Этапы разработки программы Структура простой программы
2.1 Основные понятия технологии разработки данных
Существует несколько определений понятия «разработка данных» — начиная с наиболее широкого определения, относящего к данной категории любые инструменты, предоставляющие пользователям непосредственный доступ к очень большим объемам данных, и заканчивая наиболее специализированными определениями, выделяющими только те инструменты и приложения, которые осуществляют статистический анализ данных. В этом разделе мы воспользуемся достаточно конкретным определением понятия разработки данных, предложенным Симоудисом (Simoudis, I996).
Разработка данных — процесс извлечения из больших баз данных достоверной, предварительно неизвестной, комплексной и значимой информации и использование ее для принятия ответственных бизнес-решений.
Разработка данных связана с анализом данных и использованием программных технологий поиска скрытых и неожиданных закономерностей и взаимосвязей в существующих наборах данных. Основная задача разработки данных заключается в обнаружении именно скрытой и неожиданной информации, поскольку не имеет смысла вести поиск закономерностей и связей, которые и так интуитивно понятны. Закономерности и связи идентифицируются путем обнаружения существующих фундаментальных правил и свойств данных,
Для проведения связанного с разработкой данных анализа обычно используются те данные и методы, которые способны дать наиболее точный и надежный результат, что обычно требует обработки большого объема данных. Процесс анализа начинается с разработки оптимального представления структуры выборки данных, по ходу которой приобретаются исходные знания. Полученные знания затем пополняются за счет использования расширенного набора данных, при условии, что более крупный набор данных имеет ту же структуру, что и полученная ранее выборка денных.
Чем веб-приложения отличаются от веб-сайтов | Иван Петриченко
Значительную отдачу от разработки данных получат те компании, которые вложат существенные инвестиции в создание хранилища данных. Хотя разработка данных все еще остается сравнительно новой технологией, она уже используется во многих отраслях промышленности. В таблице 4 перечислены примеры приложений, в которых используется технология разработки данных и которые предназначены для применения в таких областях, как розничная торговля, маркетинг, банковская сфера, страхование и медицина.
Таблица 4. Примеры приложений технологии разработки данных
Розничная торговля и маркетинг
Обнаружение закономерностей в покупках, сделанных клиентами
Поиск ассоциативных связей среди демографических характеристик клиентов
Прогнозирование реакции на кампанию рассылки почтовых материалов
Анализ потребительской корзины
Обнаружение закономерностей в мошенническом использовании кредитных карточек
Поиск постоянных клиентов
Прогнозирование клиентов, которые, по-видимому, изменят свою принадлежность к кредитной карточной системе
Определение средних трат по кредитный карточкам для разных групп клиентов
Определение тех клиентов, которые купят новые страховые полисы
Определение характеристик поведения пациентов с целью планирования их приемов Поиск успешных терапевтических процедур при различных заболеваниях
Источник: studfile.net
Процесс моделирования данных при разработке приложений
В большинстве источников моделирование данных (в контексте создания приложений) рассматривается как последовательное создание трёх моделей данных — концептуальной, логической и физический. Такого порядка придерживаются, например, DMBOK2 и BABOK, а также многочисленные статьи в сети Интернет.
Рискну предложить несколько дополнений и уточнений к этому процессу — как на основании собственного опыта, так и обобщения опыта коллег, с которыми обсуждал этот вопрос.
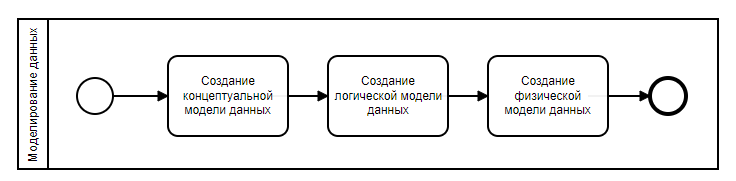
Дополнение 1. Разделение модели данных предметной области и модели данных приложения
При переходе от логической к физической модели происходит революция — меняется объект моделирования.
Концептуальная и логическая модели составляются для предметной области. Сущности данных моделей — это понятия предметной области.
Физическая модель составляется для базы данных приложения. Сущность физической модели — это таблица (или другая структура данных в зависимости от типа СУБД).
Поэтому не совсем корректно рисовать это как единый процесс, более точно будет так:
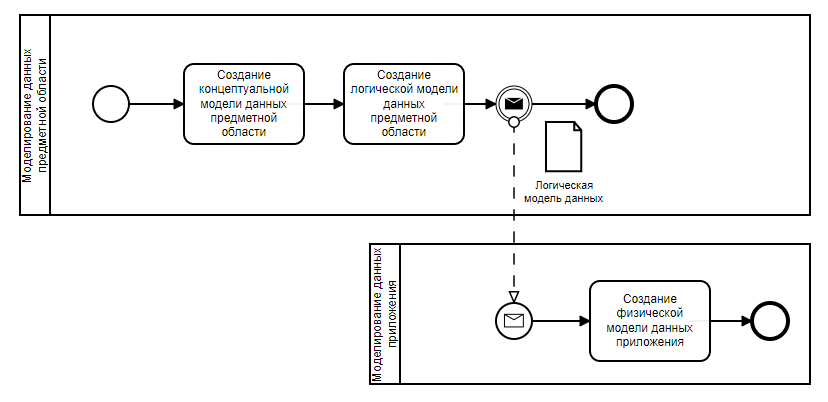
Почему это так важно? Потому что меняется почти всё — и цель, и количество моделей, и участники, и даже зачастую инструмент и нотация.
Всегда лучше уточнять — что именно отражает модель, предметную область или базу данных приложения.
Что именно меняется?
Меняется цель
Модель данных предметной области составляется для (основные цели):
- Чтобы самим разобраться в предметной области.
- Чтобы верифицировать своё понимание предметной области с заказчиком или доменными экспертами.
- В некоторых случаях — чтобы сформировать единый понятийный аппарат. Слово «клиент» неоднозначно, а «сущность логической модели Клиент» имеет вполне конкретную семантику. Но чаще для этого используют глоссарий.
Создание модели данных приложения — это просто часть разработки. Если в приложении есть база данных, то её нужно спроектировать, иначе она ниоткуда не появится.
Меняется кратность
Если концептуальная и логическая модели соотносятся друг с другом как 1:1 (т.к. объект моделирования один и тот же), то связь между логической и физической — скорее many-to-many.
Приложение может иметь несколько БД — например, часть данных хранится в РСУБД, часть в NoSQL. Логично сделать две разные модели данных для двух физически обособленных БД.
Или система может состоять из нескольких приложений, у каждого из которых своя БД. При этом вся система реализует функциональность в одной предметной области. Логично составить одну модель данных предметной области и несколько моделей данных приложений.
Приложение может включать в себя функциональность в разных предметных областях. Это характерно, например, для ведомственных систем организаций с несколькими видами деятельности (ФНС России регистрирует юрлица и собирает налоги — совершенно разные виды деятельности). Например, мне известна одна организация которая занимается поставкой автозапчастей и изготовлением женских сумок, и при этом внедряет единую ERP. Странно рисовать одну модель предметной области для автозапчастей и для сумок — между ними нет ничего общего.
Меняются участники
Модель данных предметной области составляет, как правило, бизнес-аналитик (или фуллстек-аналитик, если эта роль совмещается с системным аналитиком).
Модель данных приложения — архитектор БД, бекенд-разработчик или реже системный аналитик.
Сравнительно редко в одной голове совмещается и знание предметной области, и знание конкретной СУБД на уровне достаточном для качественного проектирования БД.
Меняется нотация
Для создания модели данных предметной области чаще используют те или иные виды ER-диаграмм — например, в нотации Crow’s foot или Min-Max. Иногда используют и UML Class Diagram, хотя о корректности этого можно спорить. Но в любом случае это модель «сущность-связь».
DMBOK2 приводит пример «многоуровневой концептуальной модели данных». — это не сущность-связь. При этом на практике я ни разу с использованием иных видов моделей для концептуального моделирования не сталкивался.
Если у вас есть иной опыт, напишите в комментариях.
Нотация модели данных приложения зависит от типа БД — для документной и для реляционной СУБД используются совершенно разные нотации.
Меняются инструменты
Модель данных предметной области составляется в основном в иллюстративных целях. Вполне приемлемо использовать для этого не только специализированные средства моделирования, но и любые другие инструменты — то же Visio или Miro. Выглядеть будет так же, составлять проще.
Физическая модель данных должна в итоге превратиться в структуру БД (например, путем преобразования в DDL-скрипты). Странно сперва рисовать где-то модель (как картинку), а потом руками писать скрипты — двойная работа. Разумно использовать инструмент, не приводящий к двойной работе.
При этом, разумеется, можно использовать инструменты проектирования наподобие Enterprise Architect или Power Designer — которые позволяют взаимосвязанно создавать все три модели в одном инструменты.
Также важно отметить, что эти модели часто составляют разные люди. Сложно найти единый инструмент, одинаково удобный как для бизнес-аналитика, так и для бекенд-разработчика.
Дополнение 2. Существование не только логической модели данных предметной области, но и логической модели данных приложения
Классические источники предполагают, что физическая модель (данных приложения) составляется сразу по логической модели (данных предметной области).
Но есть ряд случаев когда это невозможно либо неэффективно, и возникает промежуточное звено — назовём его «логическая модель данных приложения».
Слово «логический» подразумевает отсутствие привязки к конкретной СУБД. Максимум может быть привязка к типу СУБД — реляционная она или например документная.
Слово «приложения» подразумевает, что сущностями в данной модели являются не понятия предметной области, а будущие таблицы БД (или иные сущности в рамках СУБД приложения, если она не реляционная).
Такая модель данных в нужной степени денормализована, обогащена служебными таблицами и полями, в ней указаны типы данных без привязки к СУБД — т.е. «строка до 500 символов» вместо «nvarchar(500)» и обязательность полей.
Также можно обогатить эту модель указанием полей по которым реализуется поиск (чтобы создать индексы) или бизнес-ключей (чтобы создать уникальные индексы).
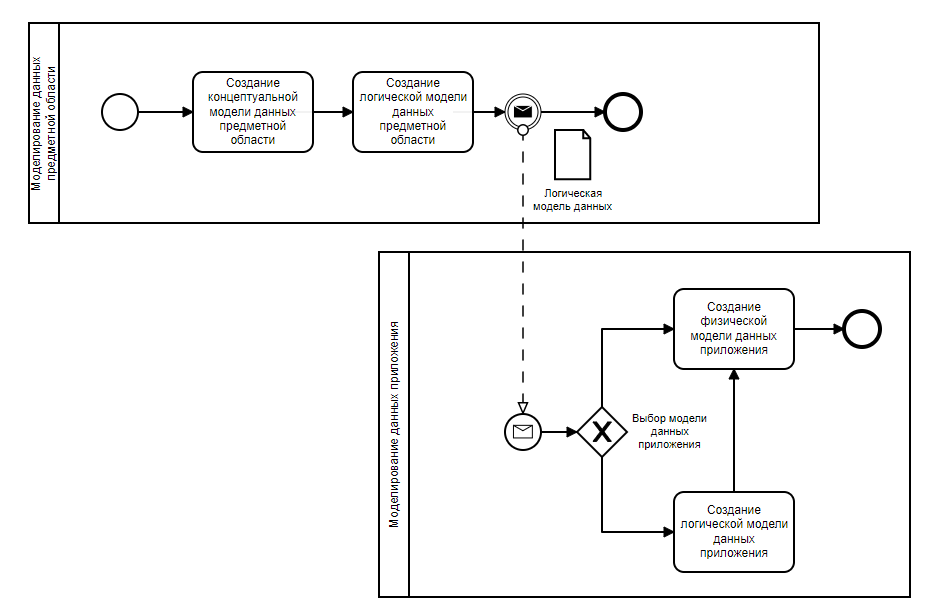
В некоторых случаях при наличии логической модели данных приложения акт проектирования в отношении физической модели данных приложения может быть вырожденным — либо он осуществлялся непосредственно в процессе разработки, либо он тривиален.
При этом на схеме он отражен — потому что тем или иным образом, но физическая структуры базы данных всё равно появляется.
В каких же случаях возникает «логическая модель данных приложения»? Ниже перечислены четыре случая, которые встречались в моей практике.
Случай 1. Специфика команды
В статье Умный аналитик – глупый разработчик vs. глупый аналитик – умный разработчик приведена ситуация, когда системный аналитик практически единолично занимается проектированием. Такое бывает на практике, и чаще чем хотелось бы.
«Глупый разработчик» не надо понимать буквально — как указание на низкий уровень когнитивных способностей.
Здесь может быть много причин — и узкое понимание границы зоны ответственности разработчика (я тут просто кнопки нажимаю, напишите чётко что делать), и команда разработки из джунов с недостаточным опытом, и временно привлеченные разработчики которые через месяц уйдут на другой проект и не хотят погружаться.
В такой ситуации нельзя просто передать разработчикам на вход логическую модель предметной области и ожидать что она будет корректно имплементирована.
Что делать системному аналитику — если он не является экспертом в СУБД? Можно составить логическую модель данных приложения. «Глупым» разработчикам по ней корректно составить физическую модель гораздо проще.
Случай 2. Использование фреймворка, реализующего принцип «code first»
Как выглядит проектирование физической модели при использовании фреймворка использующего принцип «code first»? Фактически это делает разработчик, когда составляет класс entity и добавляет к нему аннотации. Всё остальное происходит «автомагически».
Подход «code first» — генерация структуры БД по классам.
Такие возможности есть в Entity Framework, JPA2, SQLAlchemy и т.д. На Хабре есть статьи про это, например https://habr.com/ru/post/234827/ и https://habr.com/ru/post/174709/ (случайная выбрал две статьи).
Как системному аналитику участвовать в процессе проектирования модели данных приложения — если исходя из проектной ситуации это необходимо?
Сидеть рядом с разработчиком и вместе с ним проектировать классы и расставлять аннотации? Так себе идея. Да и хочется это сделать заранее, а не прямо во время разработки.
Обсудить заранее с разработчиком и написать большущий комментарий к задаче в Jira? Тоже не очень, несистемно и может потеряться.
Решение — составить логическую модель данных приложения (которая потом практически 1:1 воплотится в классы). Составить её можно как вместе с разработчиком (если он может и готов участвовать в проектировании), так и без него (если он «глупый»).
В этом случае модель данных приложения может быть с равным успехом быть представлена как в виде UML Class Diagram (т.к. первичны именно классы), так и в виде ER-диаграммы (т.к. классы соответствуют таблицам).
Случай 3. Приложение поддерживает разные СУБД
Существуют приложения, которые поддерживают разные СУБД. Как правило, в слое данных (data layer) таких приложений реализован дополнительный уровень абстракции, который изолирует приложение от специфики СУБД.
1С: Предприятие, например, поддерживает 5 СУБД. Получается, что одно приложение может иметь 5 разных физических моделей данных. Напрашивается обобщение этих 5 физических моделей данных в виде одной логической — ведь там по сути одни и те же данные. И это тоже будет «логическая модель данных приложения».
Если в каком-то месте (например, в описании алгоритма формирования отчета) нужно сослаться на поле в БД, то можно не указывать 5 разных вариантов для разных СУБД, а один раз указать поле из логической модели данных приложения.
Если коллеги из 1С случайно прочитают этот пост, прошу их уточнить в комментариях — есть у них такая сущность как «логическая модель данных приложения» или нет.
Случай 4. Большой разрыв между моделью данных предметной области и физической моделью данных приложения
Большой разрыв может возникать, например, в случае реализации приложения путем расширения базового продукта (как примеры — Liferay, Sharepoint, Docushare, Alfresco), который уже имеет структуру БД с предусмотренными точками расширения. Или в случае использования фреймворка, который накладывает ограничения на структуру базы данных.
В этом случае структура базы данных и модель данных предметной области имеют между собой очень мало общего.
Данная ситуация затрудняет разработку, эксплуатацию и модернизацию приложения — например, сложно сопоставить между собой атрибут сущности предметной области и поле таблицы БД. Если требование сформулировано в терминах предметной области, то бывает сложно переложить его на реализацию.
Помочь в этой ситуации также может составление логической модели данных приложения.
С одной стороны, она близка к физической модели данных, и без труда позволит перевести требования сформулированные в терминах логической модели данных приложения на таблицы и поля БД.
С другой стороны, для неё описан мэппинг на модель данных предметной области, она документирована и удобна для использования аналитиком.
Дополнение 3. Обязательность моделей данных предметной области
Насколько обязательным этапом является составление моделей данных предметной области?
Концептуальная модель данных предметной области, с моей точки зрения, должна быть всегда. В отдельных случаях она может не документироваться в виде артефакта и существовать только в голове членов команды — например, если в проектировании участвует только системный аналитик и для него это не первый проект в данной предметной области.
Но такой подход имеет много недостатков — тот же bus factor и т.д. Желательно её документировать.
Необходимость составления логической модели данных предметной области, с моей точки зрения, зависит от уровня детализации документа содержащего требования (как бы он ни назывался — ТЗ, SRS, FRD и т.д.).
Если документ достаточно верхнеуровневый, то достаточно концептуальной модели данных предметной области. Если документ подробный, то нужна также и логическая модель данных предметной области.
Если работы по созданию приложения были начаты на основе верхнеуровневых требований (содержащих только концептуальную модель данных), то составление логической модели данных предметной области может быть избыточным: может быть достаточно только логической модели данных приложения.
Получается следующая схема:

Итого
- Необходимо различать модель данных предметной области и модель данных приложения.
- Концептуальная модель данных — всегда для предметной области, физическая модель данных — всегда для приложения, логическая модель данных — может быть как для предметной области, так и для приложения.
- Логическая модель данных приложения зависит от типа СУБД (например, реляционная СУБД и документная СУБД), но не от конкретной СУБД (для PostgreSQL и для Oracle может использоваться одна модель). Физическая модель данных приложения зависит и от типа СУБД, и от конкретной СУБД.
- В зависимости от специфики проекта может составляться различный набор моделей данных.
- Почти всегда должны составляться: концептуальная модель данных предметной области и одна из логических моделей данных (предметной области или приложения).
Мой личный набор, который я использую в большинстве проектов — концептуальная модель данных предметной области и логическая модель данных приложения.
В моих конкретных условиях он оказался оптимальным по отношения «полученная польза / затраченные усилия».
А какие виды моделей данных составляете вы в своих проектах?
P.S. Дополнение 4. Модель данных микросервиса
У меня был всего один кейс, чего недостаточно для каких-либо выводов. Поэтому разместил этот блок после раздела «Итого». Если у вас есть другой опыт, напишите о нём в комментариях — буду рад о нём узнать.
Модель данных предметной области никак не зависит архитектуры, в том числе наличия или отсутствия микросервисов. Но как организован переход от логической модели к физической в случае микросервисной архитектуре?
Как это было у нас. На этапе сбора требований «по классике» были составлены концептуальная и логическая модели данных предметной области.
После того, как на этапе проектирования были выделены микросервисы и определены зоны их ответственности, была сделана «нарезка» логической модели предметной области — какой микросервис будет хранить какие сущности. Это нужно для того, чтобы передать этот кусок модели (вместе с иными требованиями) той подкоманде, которая будет заниматься микросервисом. Приложение было большим, подкоманд много, некоторые из них субподрядные. Давать всем общую модель было избыточно.
Одна и та же сущность предметной области при «нарезке» могла попасть сразу в несколько микросервисов: например, сведения об организациях были нужны практически во всех микросервисах (с разным реквизитным составом).
Как назвать эту модель? С одной стороны, она остаётся логической моделью предметной области — сущности это понятия предметной области, а не таблицы, уровень детализации соответствует логической модели. С другой стороны, она уже частично привязана к реализации — то есть определён микросервис, в котором эта сущность будет имплементирована.
Таким образом, между логической моделью предметной области и моделью данных приложения (неважно, логической или физической) может существовать еще один промежуточный этап — «логическая модель данных предметной области, планируемая к реализации в рамках компонента архитектуры приложения».
- модель данных
- системный анализ
- концептуальная модель
- логическая модель данных
- физическая модель данных
- моделирование данных
- Анализ и проектирование систем
- Терминология IT
- Микросервисы
Источник: habr.com
Разработка приложений и баз данных: точки соприкосновения
Реляционные базы данных проникли практически во все информационные системы, и, казалось бы, стали наиболее устоявшейся областью ИТ, где уже мало что можно изобрести, однако реальное положение дел далеко от идеального.

Реляционные базы данных применяются сегодня практически во всех приложениях, начиная от встроенных в мобильные и специальные устройства, Web-приложений и заканчивая системами управления предприятия. Проникновение баз данных во все виды приложений идет нарастающими темпами, а разработчики получают все более удобные в использовании инструменты и подходы. Может сложиться впечатление, что разработчики приложений для работы с базами данных являются наиболее «обеспеченной» прослойкой программистов, у которых есть инструменты на все случаи жизни, но это далеко не так. Компания Embarcadero Technologies, приобретя в 2008 году подразделение средств разработки CodeGear у компании Borland, объединила профессиональные средства разработки приложений и инструменты проектирования, средства разработки и управления базами данных, что позволило устранить имеющиеся проблемы как со стороны приложений, так и со стороны баз данных.
Хаотическое проектирование баз данных
В современной индустрии разработки программного обеспечения устоялось мнение, что определить требования к продукту перед началом проекта невозможно, и поэтому разработка должна быть адаптирована к их постоянному изменению. В результате появились процессы, основанные на итерациях, учитывающих изменение требований, а рефакторинг исходного кода стал неотъемлемой частью создания ПО. А что происходит в процессе итерационной разработки с базами данных? Изменение требований вынуждает корректировать схему базы данных, причем чаще всего это происходит непрозрачно, без анализа общей картины и зависимостей. Таблицы, поля, внешние ключи и ограничения создаются и изменяются хаотически, за ссылочной целостностью никто не следит, и никто не может точно сказать, чем же база данных на итерации N отличается от ее состояния на итерации N-1.
Фактически разработка баз данных сегодня ведется «заплаточным» методом, как во времена господства «водопадного» процесса, – в начале проекта «рисуется» некая модель базы, основанная на частичных требованиях, известных к данному моменту, затем генерируется физическая база данных, а дальше про модель забывают, производя изменения прямо в базе данных. Минусы такого подхода очевидны: обмен знаниями и понимание общей картины затруднены, а изменения непрозрачны, могут порождать противоречия в логике и схеме базы данных, которые останутся нераскрытыми до момента ввода программной системы в эксплуатацию, что приводит к очень большим убыткам. Современные разработчики приложений баз данных нуждаются в инструментах, приспособленных к итерационной разработке баз данных.
Первым и наиболее важным условием такой приспособленности является наличие полноценных возможностей обратного инжиниринга (reverse engineering, создание модели базы данных на основе анализа ее физической схемы) и прямого инжиниринга (forward engineering; создание и изменение физической схемы базы данных на основе модели). На практике это означает, что с помощью инструмента проектирования можно провести анализ схемы существующей базы данных, создать на ее основе модель базы, поменять модель и немедленно применить изменения, которые должны действительно корректно и непротиворечиво изменить схему базы данных, а не испортить или запутать ее.
Итерационный подход также подталкивает нас к необходимости создания подмоделей, связанных с конкретной итерацией. Выделение любых сущностей и их атрибутов в подмодель помогает разделить области ответственности как между разными разработчиками, так и между разными итерациями, гарантируя в то же время общую целостность модели. Естественно, нужна также возможность сравнения двух моделей, причем не в виде SQL-скриптов, а на уровне сущностей и атрибутов, чтобы видеть и полностью понимать вносимые при итерации изменения и их влияние на всю модель.
Разработчики приложений редко работают в одиночку, поэтому нуждаются в средствах совместной работы, но если на стороне разработки приложений с этим все в порядке, то совместная работа над базой данных обычно никак не поддерживается на уровне инструментальных средств. Совместная работа обязательно предполагает систему контроля версий: все версии моделей и физической схемы базы данных должны сохраняться в едином репозитории, обеспечивая возможности отката и сравнения схем с самого начала процесса разработки.
Разработка баз данных — дело не менее важное, чем разработка приложений, поэтому стратегическим направлением развития является обеспечение процесса разработки баз данных средствами контроля версий и управления требованиями, а также явная привязка этапов моделирования и модифицирования баз данных к итерациям и меняющимся требованиям программного проекта. Для решения перечисленных проблем и поддержки современного итерационного процесса разработки баз данных компания Embarcadero предлагает ER/Studio – инструмент проектирования, анализа, обратного и прямого инжиниринга, позволяющий осуществлять контроль версий моделей на базе собственного репозитория. В качестве средства контроля за изменениями метаданных в физических базах данных может использоваться инструмент Change Manager.
Разобщенность кода
Самой известной проблемой, сильно замедляющей процесс разработки приложений баз данных, является необходимость использовать разные средства для отладки кода приложения и SQL-кода в базе данных.
Рассмотрим простой пример. Предположим, что на Delphi разрабатывается приложение, которое вызывает хранимую процедуру в СУБД Oracle. Используя средства Delphi, разработчик приложения может в режиме отладки пошагово пройти до момента вызова SQL-запроса, увидеть передаваемые хранимой процедуре параметры и результат, который вернет процедура.
Но что происходит внутри процедуры, когда она выполняется на сервере баз данных? Из среды разработки нашего приложения это невозможно определить – для этого надо загружать приложение для разработки SQL, которое имеет возможности для отладки хранимых процедур, а также показывает планы SQL-запросов, статистику их выполнения, позволяет просмотреть и изменить схему базы данных. Однако нельзя передать параметры из среды разработки приложения в среду разработки SQL, и приходится копировать их вручную, переключаясь из одного окна в другое. В средстве разработки приложений также невозможно увидеть детализированные результаты выполнения SQL-кода, такие как план запроса, статистика выполнения и т.д. Появление технологии кросс-языковой отладки позволило решить эти проблемы.
Первым продуктом Embarcadero, поддерживающим кросс-языковую отладку, является RapidSQL Developer (бывший PowerSQL), визуальная часть которого основана на технологии Eclipse и поэтому позволяет встраиваться в любую среду разработки на его базе (в том числе, конечно же, JBuilder) и осуществлять динамическую кросс-языковую отладку. Теперь в момент выполнения хранимой процедуры на сервере разработчик в рамках одного и того же инструмента автоматически переходит в полноценную среду отладки SQL-кода, способную отлаживать как обычные SQL-запросы, так и хранимые процедуры. Разработчик видит актуальные входные параметры запросов и хранимых процедур, получая возможность пошаговой отладки SQL-кода. Интеграция RapidSQL Developer в Eclipse-совместимые средства разработки – первый шаг интеграции разработки приложений и баз данных, на очереди обеспечение аналогичных возможностей для Delphi, C++ Builder и других средств разработки приложений от Embarcadero.
Мультиплатформные приложения баз данных
Особую проблему для разработчиков представляет разработка приложений баз данных, которые должны работать с несколькими СУБД. Например, банки и страховые компании обычно имеют несколько больших офисов и множество маленьких филиалов. Большинство бизнес-процессов, касающихся ввода оперативной информации и повседневного документооборота, совпадают и в головном офисе, и в филиалах, однако масштабы разные. Естественное желание сэкономить на стоимости лицензий промышленной СУБД для применения в филиалах приводит к мысли о том, что хорошо бы выбрать другую СУБД без смены приложения.
Опытные разработчики баз данных хорошо понимают суть возникающих здесь проблем: различие типов данных и диалектов SQL, отсутствие механизмов миграции и репликации между разными СУБД, сложность верификации миграции превращают написание и эксплуатацию приложений для разных СУБД в кошмар. Со стороны средств разработки приложений эту проблему пытаются решить за счет создания библиотек доступа к данным (dbExpress в Delphi и C++ Builder, ADO и ADO.Net от Microsoft), построенным на единых архитектурных принципах и методах доступа, а также путем применения многочисленных объектно-реляционных «оберток» (Object Relation Mapping, ORM) над реляционной логикой и структурой базы данных, генерирующих исходный код для работы с данными на основе анализа схемы базы данных и использующих механизм «адаптеров» для реализации протокола конкретной СУБД. Среди наиболее популярных ORM надо отметить Hibernate для Java и ActiveRecord в RubyOnRails, которые предоставляют объектно-ориентированный интерфейс к хранящимся в СУБД данным. Для Delphi существует аналогичный проект tiOPF, для C# – NHibernate.
Конечно, использование таких универсальных библиотек и наборов компонентов позволяет значительно сократить число рутинных операций в процессе мультиплатформной разработки баз данных. Однако этого недостаточно, когда речь идет о приложениях, использующих более сложные базы данных, в которых активно употребляется логика, заложенная в хранимых процедурах и триггерах, – для ее реализации, отладки и тестирования требуются отдельные инструменты, подчас совершенно разные для разных СУБД. Для разработки кроссплатформных приложений баз данных Embarcadero предлагает инструмент RapidSQL.
Все продукты Embarcadero для работы с базами данных поддерживают несколько платформ и основаны на ядре анализа схемы и статистики баз данных Thunderbolt. Каждая поддерживаемая СУБД и каждая конкретная версия СУБД имеют соответствующие ветки кода в ядре Thunderbolt, что позволяет максимально точно отображать схему базы данных на внутреннее представление в этом ядре и, самое главное, осуществлять корректные преобразования между представлением и реальными базами данных. Именно благодаря ядру Thunderbolt система RapidSQL позволяет разрабатывать качественный SQL-код для всех поддерживаемых платформ (Oracle, MS SQL, Sybase и различные варианты IBM DB2), а ER/Studio может осуществлять точный reverse- и forward-инжиниринг схем баз данных.
Если разрабатывается приложение для двух и более платформ или переносится существующее приложение с одной платформы на другую, то RapidSQL предоставит все необходимые инструменты для миграции схемы, пользователей и разрешений между разными СУБД. Конечно, RapidSQL автоматически не конвертирует процедуры на PL/SQL в T-SQL – для этого все еще требуется программист, однако инструмент обеспечивает единое окно для мультиплатформной разработки, унифицированные редакторы объектов схемы, пользователей и их прав, а также отладку SQL на всех поддерживаемых платформах. По утверждениям пользователей RapidSQL, в результате экономится до 70% времени, которое тратится на миграцию между разными СУБД.
Изменения в данных и схемах
Миграция с одной СУБД на другую невозможна без ее верификации. Кто и каким образом может гарантировать, что данные, перенесенные из одной СУБД в другую, действительно идентичны? Разные клиентские библиотеки, разные типы данных и разные кодировки превращают процесс сравнения данных в нетривиальную задачу.
В реальном мире на развертывании приложения и базы данных работа не заканчивается — идет сопровождение, появляются новые версии исполняемых файлов приложения и патчи к базе данных. Каким образом можно получить гарантии, что все необходимые обновления были применены к базе данных и что весь комплекс ПО заработает правильно?
Embarcadero разработала инструмент Change Manager, предназначенный для сравнения данных, схем и конфигураций баз данных. Сравнение происходит в рамках одной или нескольких СУБД, с автоматической проверкой соответствия между типами данных и формированием SQL-скриптов отличий, которые можно тут же применить для приведения баз в идентичное состояние. Модуль сравнения метаданных обеспечивает сравнение схем баз данных как между «живыми» базами данных, так и между базой данных и SQL-скриптом и генерирует скрипт отличий метаданных. Эта функциональность может быть использована не только для проверки баз данных на соответствие эталону, но и для организации регулярного процесса обновления баз данных, а также для проверки на неавторизованные изменения, скажем, в удаленных филиалах крупной организации. Аналогичная ситуация с конфигурационными файлами – Change Manager сравнивает конфигурационные файлы и позволяет обеспечить соответствие конфигурации развернутых приложений требованиям для данного ПО.
Производительность приложений баз данных
Как часто мы видим приложения, прекрасно работающие на небольших тестовых объемах данных, но на реальных объемах становящиеся неприемлемо медленными. Просчеты в требованиях, недостаточное тестирование на ранних стадиях, спешка в сдаче проекта — все это знакомые причины некачественной разработки приложений. Теоретики разработки ПО в этом случае предлагают заняться самоусовершенствованием и принципиальным улучшением качества программ, однако все практики знают, что заниматься переписыванием проекта иногда невозможно ни экономически, ни, в некоторых случаях, политически, а задачу оптимизации производительности надо решать любым способом.
Основная причина проблем с производительностью приложений баз данных лежит в неоптимизированных SQL-запросах и хранимых процедурах. Оптимизаторы современных баз данных достаточно мощные, однако и у них есть определенные границы возможностей, и, чтобы добиться хорошей производительности, нужно правильно составлять SQL-запросы, создавать (или удалять) дополнительные индексы, в определенных случаях денормализовывать базу данных, перекладывать часть логики на триггеры и хранимые процедуры.
На этапе разработки оптимизацию запросов можно проводить с помощью RapidSQL, который включает в себя модуль SQL Profiler, способный анализировать планы и генерировать подсказки по улучшению производительности SQL-запросов. Но что делать, если проблема возникает уже в процессе эксплуатации и не локализуется в определенном SQL-запросе? Если производительность падает в определенное время суток или, что еще неприятнее, проблема возникает на удаленной копии системы, в то время как на основном сервере все в порядке? Для таких случаев предназначен DBOptimizer – инструмент профилирования баз данных для Oracle, Microsoft SQL Server, Sybase и IBM DB2.
При запуске режима профилирования DBOptimizer собирает информацию о базе данных и среде выполнения, включая информацию о загрузке центрального процессора и другие параметры операционной системы, записывая ее в сессию профилирования. В результате получается список выполняющихся в любой заданный промежуток времени запросов, отсортированный по потребляемым ресурсам. Для каждого проблемного запроса можно увидеть его план, статистику выполнения и другие подробности. Более того, DBOptimizer также показывает подсказки-рекомендации по улучшению запроса применительно к конкретным СУБД.
Ящик с инструментами
Все упомянутые инструменты, хотя они и позволяют справиться с проблемами, используются на разных этапах жизненного цикла разработки баз данных. Довольно неудобно и накладно держать десяток приложений на все случаи жизни, которые могут понадобиться (а могут и не понадобиться) в процессе проектирования, разработки, миграции, оптимизации и эксплуатации баз данных.
Выпущенный в феврале 2009 года универсальный набор инструментов Emdacadero All-Access включает в себя необходимые инструменты для всех этапов разработки приложений баз данных: от ER/Studio до DBOptimizer, от Delphi и C++ Builder до DBArtisan. Лучше всего для описания All-Access подходит сравнение с ящиком для инструментов, который стоит дома у каждого рачительного хозяина. Возможно, не всеми инструментами пользуются каждый день, но разводной ключ на случай протечки должен быть всегда под рукой.
All-Access не навязывает программистам или архитекторам базы данных чужие роли, но предоставляет универсальный комплект инструментов, подходящий для всех ролей в процессе разработки приложений баз данных, от архитектора до тестировщика; предлагает всем членам команды разработчиков инструменты для всех этапов разработки баз данных, а также набор узкоспециализированных инструментов для оптимизации баз данных (DBOptimizer) и приложений (JOptimizer), позволяющих «расшить» узкие места. Пакет поддерживает несколько СУБД, что обеспечивает экономию средств.
Технические различия между технологиями объектно-ориентированных и реляционных баз данных привели к различию культур, до сих пор разделяющему сообщество управления данными и сообщество разработки. Что с этим делать дальше?
Источник: www.osp.ru