
Вы помните дни, когда вам нужно было расставить точки перед правильным ответом на экзамене? Или как насчет теста на пригодность, который вы дали перед своей первой работой? Я хорошо помню олимпиады и тесты с несколькими вариантами ответов, когда университеты и организации использовали систему оптического распознавания символов (OCR) для массовой оценки листов ответов.
Честно говоря, OCR находит применение в самых разных отраслях и функциях. Таким образом, все, от сканирования документов — банковских выписок, квитанций, рукописных документов, купонов и т. д., до чтения дорожных знаков в автономных транспортных средствах — все это подпадает под эгиду OCR.
Пару десятилетий назад системы OCR были довольно дорогими и громоздкими в изготовлении. Но достижения в области компьютерного зрения и глубокого обучения означают, что мы можем создать собственную систему OCR прямо сейчас!

Но создание системы OCR — непростая задача. Во-первых, он наполнен такими проблемами, как разные шрифты на изображениях, плохой контраст, несколько объектов на изображении и т. д.
Как распознать текст с картинки / уроки Python
Итак, в этой статье мы рассмотрим некоторые очень известные и эффективные подходы к задаче распознавания текста и то, как вы можете реализовать их самостоятельно.
Если вы новичок в области обнаружения объектов и компьютерного зрения, я рекомендую ознакомиться со следующими ресурсами:
- Пошаговое введение в базовые алгоритмы обнаружения объектов
- Курс компьютерного зрения
Оглавление
- Что такое оптическое распознавание символов (OCR)?
- Популярные приложения OCR в реальном мире
- Распознавание текста с Tesseract OCR
- Различные способы обнаружения текста
Что такое оптическое распознавание символов (OCR)?
Давайте сначала разберемся, что такое OCR, если вы еще не сталкивались с этим понятием.
OCR, или оптическое распознавание символов, представляет собой процесс распознавания текста внутри изображений и преобразования его в электронную форму. Это может быть рукописный текст, печатный текст, например документы, квитанции, визитные карточки и т. д., или даже фотография в естественном виде.
OCR состоит из двух частей. Первая часть — это обнаружение текста, где определяется текстовая часть изображения. Эта локализация текста на изображении важна для второй части OCR, распознавания текста, когда текст извлекается из изображения. Используя эти методы вместе, вы можете извлечь текст из любого изображения.
Но нет ничего идеального, и OCR не исключение. Однако с появлением глубокого обучения стало возможным получить лучшие и более обобщенные решения этой проблемы.
Прежде чем мы углубимся в создание собственного OCR, давайте взглянем на некоторые популярные приложения OCR.
Популярные приложения OCR в реальном мире
OCR имеет широкое применение в различных отраслях (в первую очередь с целью сокращения ручного труда человека). Он настолько вошёл в нашу повседневную жизнь, что мы почти никогда этого не замечаем! Но они, безусловно, стремятся улучшить пользовательский опыт.
Распознавание текста с изображения на Python | EasyOCR vs Tesseract | Компьютерное зрение
OCR используется для задач распознавания рукописного ввода для извлечения информации. В этой области ведется большая работа, и мы добились действительно значительных успехов. Microsoft придумала удивительное математическое приложение, которое принимает на вход написанное от руки математическое уравнение и генерирует решение вместе с пошаговым объяснением его работы.
OCR все чаще используется для оцифровки в различных отраслях, чтобы сократить ручную работу. Это позволяет очень легко и эффективно извлекать и хранить информацию из деловых документов, квитанций, счетов-фактур, паспортов и т. д. Кроме того, когда вы загружаете свои документы для KYC (Знай своего клиента), OCR используется для извлечения информации из этих документов и хранения. их для дальнейшего использования.
OCR также используется для сканирования книг, когда необработанные изображения преобразуются в цифровой текстовый формат. Многие крупномасштабные проекты, такие как проект Гутенберга, проект «Миллион книг» и Google Книги, используют OCR для сканирования и оцифровки книг и хранения произведений в виде архива.
Банковская отрасль также все чаще использует OCR для архивирования документов, связанных с клиентами, таких как адаптационные материалы, для упрощения создания репозитория клиентов. Это значительно сокращает время адаптации и тем самым улучшает пользовательский опыт. Кроме того, банки используют OCR для извлечения такой информации, как номер счета, сумма, номер чека, из чеков для более быстрой обработки.

Приложения OCR будут неполными, если не упомянуть их использование в самоуправляемых автомобилях. Автономные автомобили широко используют OCR для чтения указателей и дорожных знаков. Эффективное понимание этих знаков делает беспилотные автомобили безопасными для пешеходов и других транспортных средств, курсирующих по дорогам.
Определенно есть еще много приложений OCR, таких как распознавание номерных знаков транспортных средств, преобразование отсканированных документов в редактируемые текстовые документы и многое другое. Я хотел бы услышать ваш опыт использования OCR — сообщите мне об этом в разделе комментариев ниже.
Оцифровка с использованием OCR, очевидно, имеет широко распространенные преимущества, такие как простота хранения и обработки текста, не говоря уже о непостижимом объеме аналитики, которую вы можете применить к этим данным! OCR, безусловно, является одной из самых важных областей компьютерного зрения.
Теперь давайте рассмотрим один из самых известных и широко используемых методов распознавания текста — Tesseract.
Распознавание текста с Tesseract OCR
Tesseract — это механизм оптического распознавания символов с открытым исходным кодом, первоначально разработанный как проприетарное программное обеспечение HP (Hewlett-Packard), но позже в 2005 году он стал открытым исходным кодом. С тех пор Google принял проект и спонсировал его разработку.

На сегодняшний день Tesseract может распознавать более 100 языков и обрабатывать даже текст с написанием справа налево, например арабский или иврит! Неудивительно, что Google использует его для обнаружения текста на мобильных устройствах, в видео и в алгоритме обнаружения спама в изображениях Gmail.
Начиная с версии 4, Google значительно улучшил этот механизм OCR. В Tesseract 4.0 добавлен новый движок OCR, который использует систему нейронных сетей на основе LSTM (долгая кратковременная память), одного из самых эффективных решений для задач прогнозирования последовательности. Хотя его предыдущий механизм OCR, использующий сопоставление с образцом, все еще доступен как устаревший код.
После того, как вы загрузили Tesseract в свою систему, вы легко запустите его из командной строки с помощью следующей команды:
tesseract -l —oem —psm
Вы можете изменить конфигурацию Tesseract для получения результатов, наиболее подходящих для вашего изображения:
- Язык (-l) — с помощью Tesseract можно определить один или несколько языков.
- Режим механизма OCR (-oem). Как вы уже знаете, в Tesseract 4 есть механизмы OCR LSTM и Legacy. Однако существует 4 режима допустимых режимов работы на основе их комбинации.

3.Сегментация страницы (-psm) — можно настроить в соответствии с текстом на изображении для достижения лучших результатов.

Питесеракт
Однако вместо метода командной строки вы также можете использовать Pytesseract — оболочку Python для Tesseract. Используя это, вы можете легко реализовать свой собственный распознаватель текста с помощью Tesseract OCR, написав простой скрипт Python.
Вы можете загрузить Pytesseract с помощью команды pip install pytesseract.
Основная функция в Pytesseract — image_to_text(), которая принимает изображение и параметры командной строки в качестве аргументов:

Какие проблемы с Tesseract?
Ни для кого не секрет, что Tesseract не идеален. Он работает плохо, когда на изображении много шума или если используется шрифт языка, на котором не обучен Tesseract OCR. Другие условия, такие как яркость или асимметрия текста, также влияют на производительность Tesseract. Тем не менее, это хорошая отправная точка для распознавания текста с минимальными усилиями и высокой производительностью.
Различные способы обнаружения текста
Tesseract предполагает, что входное текстовое изображение достаточно чистое. К сожалению, многие входные изображения будут содержать множество объектов, а не только чистый предварительно обработанный текст. Поэтому становится необходимым иметь хорошую систему обнаружения текста, которая может обнаруживать текст, который затем можно легко извлечь.
Есть несколько способов обнаружения текста:
- Традиционный способ использования OpenCV
- Современный способ использования моделей глубокого обучения и
- Создание собственной индивидуальной модели
Обнаружение текста с использованием OpenCV
Обнаружение текста с помощью OpenCV — это классический способ. Вы можете применять различные манипуляции, такие как изменение размера изображения, размытие, пороговое значение, морфологические операции и т. д. для очистки изображения.

Здесь у нас есть изображения в оттенках серого, размытые и пороговые, именно в таком порядке.
Как только вы это сделаете, вы можете использовать обнаружение контуров OpenCV для обнаружения контуров для извлечения фрагментов данных:
Наконец, вы можете применить распознавание текста к контурам, которые вы получили для предсказания текста:

Результаты на изображении выше были достигнуты с минимальной предварительной обработкой и обнаружением контуров с последующим распознаванием текста с помощью Pytesseract. Очевидно, контуры не каждый раз обнаруживали текст.
Но, тем не менее, обнаружение текста с помощью OpenCV — утомительная задача, требующая большого количества экспериментов с параметрами. Кроме того, это не очень хорошо с точки зрения обобщения. Лучший способ сделать это — использовать модель обнаружения текста EAST.
Современная модель глубокого обучения — EAST
EAST, или «Эффективный и точный детектор текста сцены», представляет собой модель глубокого обучения для обнаружения текста на изображениях естественной сцены. Он довольно быстрый и точный, поскольку способен обнаруживать изображения 720p со скоростью 13,2 кадра в секунду с F-оценкой 0,7820.
Модель состоит из полностью сверточной сети и этапа немаксимального подавления для прогнозирования слова или строк текста. Модель, однако, не включает некоторые промежуточные шаги, такие как предложение кандидата, формирование текстовой области и разделение слов, которые использовались в других предыдущих моделях, что позволяет оптимизировать модель.
Вы можете посмотреть на изображение ниже, предоставленное авторами в их статье, сравнивающее модель EAST с другими предыдущими моделями:

EAST имеет U-образную сеть. Первая часть сети состоит из сверточных слоев, обученных на наборе данных ImageNet. Следующая часть — это ветвь слияния объектов, которая объединяет текущую карту объектов с картой объектов без объединения с предыдущего этапа.
Затем следуют сверточные слои для сокращения вычислений и создания выходных карт объектов. Наконец, при использовании сверточного слоя на выходе получается карта оценок, показывающая наличие текста, и карта геометрии, которая представляет собой либо повернутый прямоугольник, либо четырехугольник, покрывающий текст. Наглядно это можно понять по изображению архитектуры, которое было включено в исследовательскую работу:

Я настоятельно рекомендую вам самостоятельно изучить бумагу, чтобы лучше понять модель EAST.
OpenCV включает модель текстового детектора EAST начиная с версии 3.4. Это делает очень удобным реализацию собственного текстового детектора. Полученные локализованные текстовые поля можно передать через Tesseract OCR для извлечения текста, и вы получите полную сквозную модель для OCR.

Пользовательская модель с использованием TensorFlow Object API для обнаружения текста
Последний метод создания текстового детектора — использование специально созданной модели текстового детектора с использованием TensorFlow Object API. Это платформа с открытым исходным кодом, используемая для создания моделей глубокого обучения для задач обнаружения объектов. Чтобы разобраться в этом подробно, предлагаю сначала пройтись по этой подробной статье.
Чтобы создать собственный текстовый детектор, вам, очевидно, потребуется набор данных из довольно большого количества изображений, по крайней мере, более 100. Затем вам нужно аннотировать эти изображения, чтобы модель могла знать, где находится целевой объект, и узнать о нем все. Наконец, вы можете выбрать одну из предварительно обученных моделей, в зависимости от компромисса между производительностью и скоростью, из зоопарка моделей обнаружения TensorFlow. Вы можете обратиться к этому обширному блогу, чтобы создать свою собственную модель.
Теперь для обучения могут потребоваться некоторые вычисления, но если вам их действительно не хватает, не волнуйтесь! Вы можете использовать Google Colaboratory для всех ваших требований! Эта статья научит вас эффективно его использовать.
Наконец, если вы хотите сделать шаг вперед и построить современную модель текстового детектора YOLO, эта статья станет ступенькой к пониманию всех ее тонкостей, и вы отправитесь к отличное начало!
Конечные примечания
В этой статье мы рассмотрели проблемы в OCR и различные подходы, которые можно использовать для решения задачи. Мы также обсудили различные недостатки подходов и почему OCR не так прост, как кажется!
Работали ли вы раньше с каким-либо приложением OCR? Какие варианты использования OCR вы планируете использовать после этого? Дайте мне знать ваши идеи и отзывы ниже.
Источник: digitrain.ru
Распознаем текст на изображении с Python Tesseract

Из этого руководства вы узнаете как распознать текст на изображении с помощью трех строк Python кода.
Шаг 1. Установим оболочку для Tesseract-OCR Engine
pip install pytesseract
Шаг 2. Загрузим и установить Tesseract на Windows по следующей ссылке: https://digi.bib.uni-mannheim.de/tesseract/

Поставим галочку для загрузки дополнительного языка, в нашем случае «Russian».
Шаг 3. Запустим код, и посмотрим результат. Для примера попробуем распознать текст с картинки ниже.

import pytesseract config = r’—tessdata-dir «C:Program FilesTesseract-OCRtessdata» -l rus —oem 1 —psm 3′ result = pytesseract.image_to_string(‘1.jpg’, config=config) print(result)
Таким образом реализация намеченных плановых заданий позволяет оценить значение новых предложений.
Следующее изображение

ДЕРЖИСЬ ПОДАЛЬШЕ ОТ СЕРВЕРНОЙ
Источник: ramziv.com
Распознавание текста на изображении с C# и Tesseract
Технология распознавания символов с изображения в редактируемый текст достаточно непростая задача. Для подобных целей используется технология OCR — Optical Character Recognition(оптическое распознавание символов). Данная технология хорошо реализована в таких фреймворках как FineReader, IronOcr для платформы .NET, Tessarect и др. Мы будем использовать последнюю библиотеку.
В статье мы опишем создание оконного приложения на C# и Windows Form в программе Visual Studio 2012. Также понадобится установить пакет Tesseract и файл для распознавания символов языка.
И так приступим.
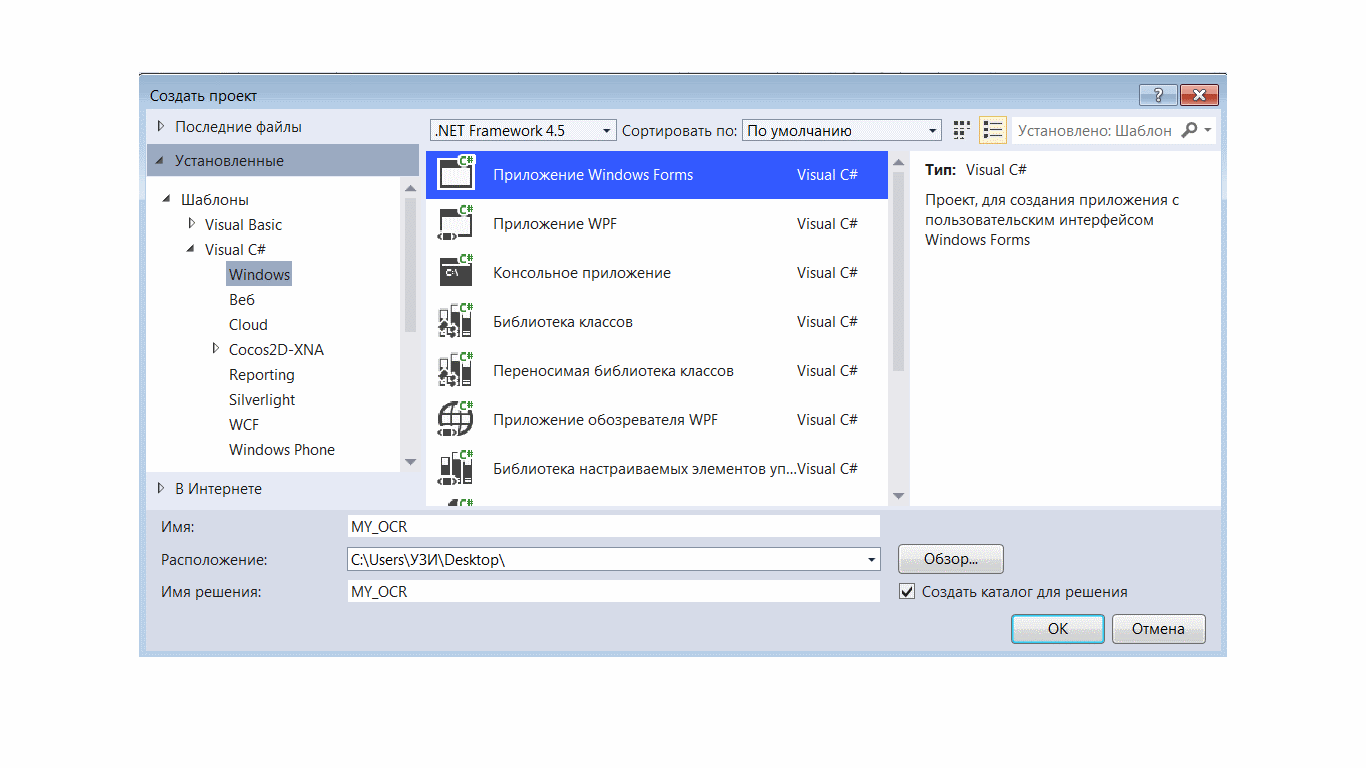
Шаг 1. Откройте программу и создайте новый проект.
Нажмите «Готово». Приложение Windows Form будет создано, как показано ниже.
Шаг 2. Установка пакета Tesseract через менеджер пакетов.
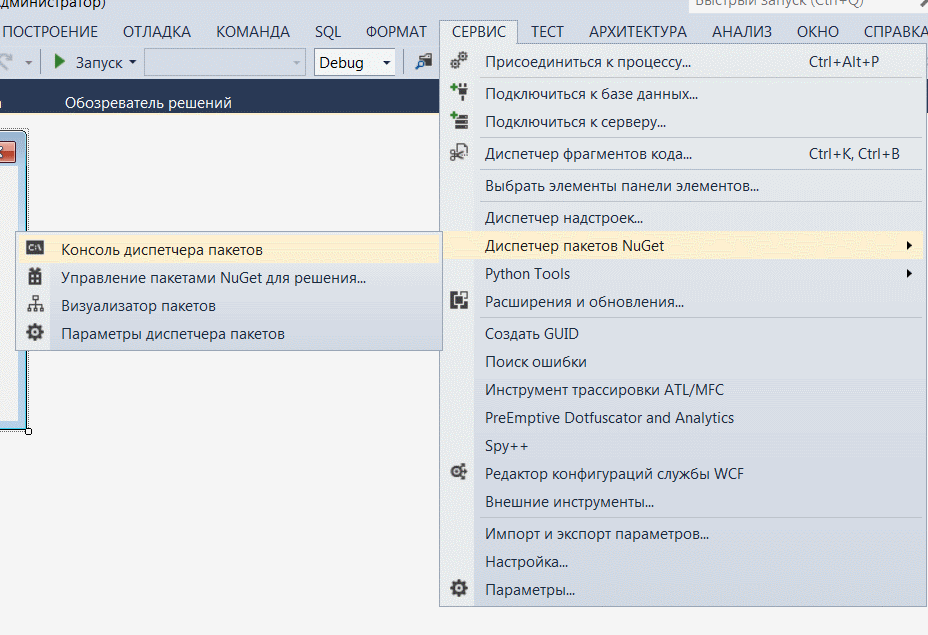
Прежде чем продолжить, нам нужно установить пакет NuGet для Tesseract.
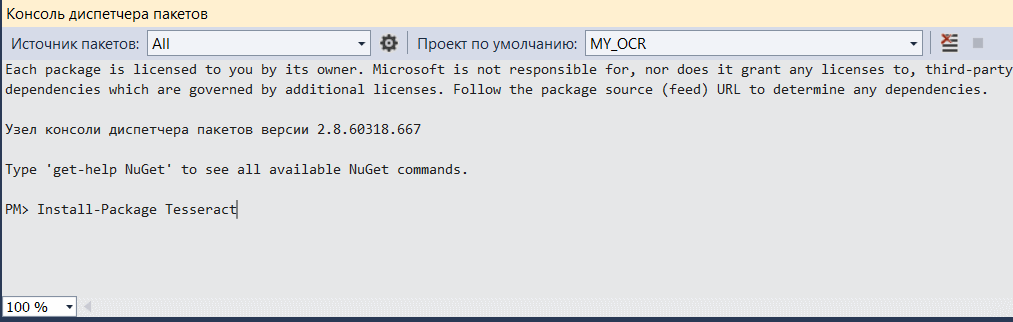
Перейдите во вкладку сервис > диспетчер пакетов NuGet > консоль диспетчера пакетов, в появившемся окне введите Install-Package Tesseract и нажмите Enter. Дождитесь окончания загрузки.
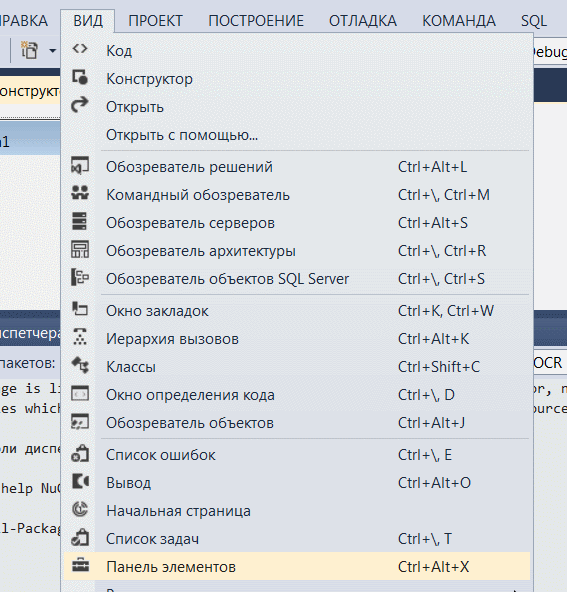
Шаг 3. Проектирование внешнего вида Windows Form Откройте панель элементов во вкладке Вид. Перетащите одну метку lable(для маркировки нашей программы), две кнопки button(одну для выбора изображения и другую для преобразования изображения в текст), одно текстовое поле TextBox для отображения пути к изображению, одно поле изображения для отображения изображения PictureBox, и одно поле Rich Text Box для отображения извлеченного текста.
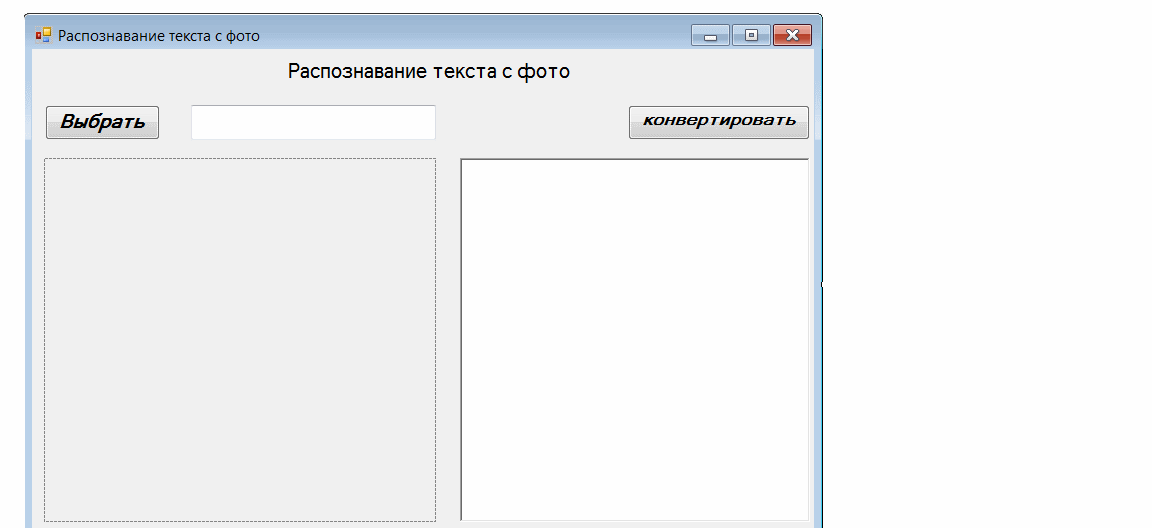
Дизайн формы по вашему выбору. Я разработал его следующим образом:
Шаг 4. Создание логики и привязка ее к кнопкам на экране. После установки пакета Nuget необходимо вручную установить языковые файлы в папку проекта. Можно сказать, что это недостаток именно этой библиотеки. Загрузите языковые файлы по следующей ссылке. Разархивируйте его и скопируйте папку tessdata в папку debug вашего проекта.
Дважды щелкните мышью по кнопке на форме. Visual Studio сгенерирует следующий код:
private void button1_Click(object sender, EventArgs e)
Затем напишите следующий код внутри функции button1_Click:
private void button2_Click(object sender, EventArgs e)
OpenFileDialog open = new OpenFileDialog();
open.Filter = «Image Files(*.jpg; *.jpeg; *.gif; *.bmp; *.png)|*.jpg; *.jpeg; *.gif; *.bmp; *.png»;
if (open.ShowDialog() == DialogResult.OK)
pictureBox1.Image = new Bitmap(open.FileName);
Также щелкните дважды по второй кнопке. В начало кода добавьте пространство имен: using Tesseract;.
private void button2_Click(object sender, EventArgs e)
Шаг 5. Запуск проекта.
Нажмите Ctrl+F5 для запуска:
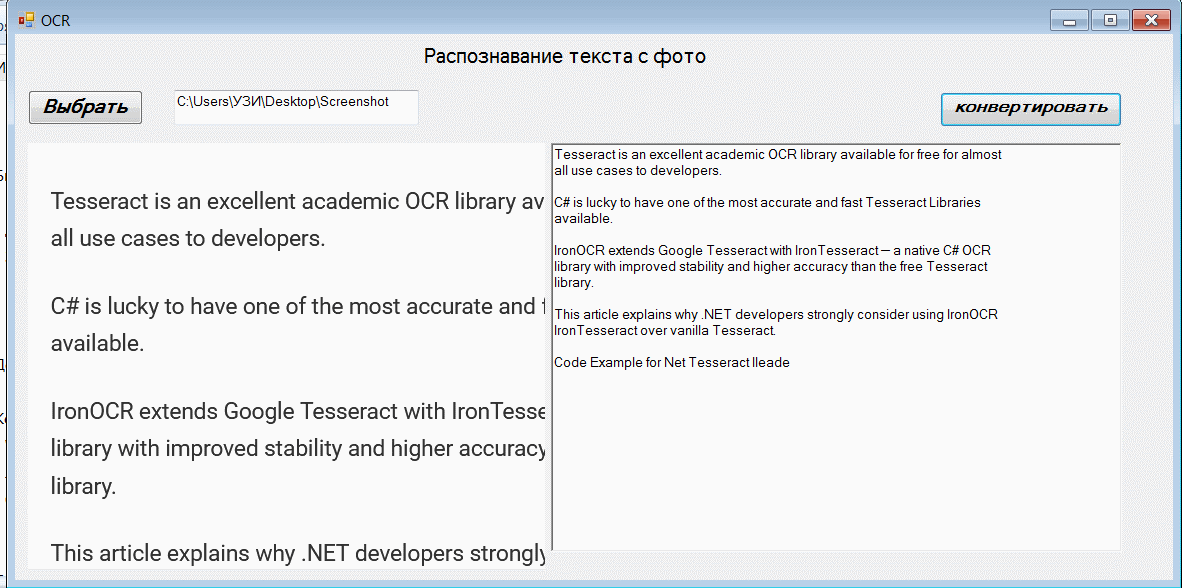
Где это может пригодиться? При сканировании или распечатке документов может понадобиться их редактируемая копия. Например, если вы сканируете бумажный документ или фотографию на принтере, принтер, скорее всего, создаст файл с цифровым изображением. Файл может быть в формате JPG/TIFF или PDF. Затем вы можете загрузить этот отсканированный электронный документ в программу OCR.
Программа OCR распознает текст и преобразует документ в редактируемый текстовый файл. Таким образом, вы сможете извлекать текст из изображений с помощью C# в Windows Forms или ASP.Net для веб страницы.

![]()
Создано 24.03.2022 10:21:37
Копирование материалов разрешается только с указанием автора (Михаил Русаков) и индексируемой прямой ссылкой на сайт (http://myrusakov.ru)!
Добавляйтесь ко мне в друзья ВКонтакте: http://vk.com/myrusakov.
Если Вы хотите дать оценку мне и моей работе, то напишите её в моей группе: http://vk.com/rusakovmy.
Если Вы не хотите пропустить новые материалы на сайте,
то Вы можете подписаться на обновления: Подписаться на обновления
Если у Вас остались какие-либо вопросы, либо у Вас есть желание высказаться по поводу этой статьи, то Вы можете оставить свой комментарий внизу страницы.
Порекомендуйте эту статью друзьям:
Если Вам понравился сайт, то разместите ссылку на него (у себя на сайте, на форуме, в контакте):
- Кнопка:
Она выглядит вот так: - Текстовая ссылка:
Она выглядит вот так: Как создать свой сайт - BB-код ссылки для форумов (например, можете поставить её в подписи):
Комментарии ( 0 ):
Для добавления комментариев надо войти в систему.
Если Вы ещё не зарегистрированы на сайте, то сначала зарегистрируйтесь.
Источник: myrusakov.ru