
В данной статье сначала будет объяснено понятие гранулярности доступа к памяти, чтобы мы могли выработать базовое понимание того, как процессор обращается к памяти. Затем мы более подробно рассмотрим концепцию выравнивания данных и исследуем распределение памяти для нескольких примеров структур.
В предыдущей статье о структурах в языке C для встраиваемых систем мы увидели, что перестановка членов в структуре может изменить объем памяти, необходимый для хранения структуры. Мы также видели, что компилятор обладает некоторыми ограничениями при выделении памяти для членов структуры. Эти ограничения, называемые требованиями к выравниванию данных, позволяют процессору более эффективно обращаться к переменным за счет некоторого потраченного впустую пространства памяти (известного как «заполнение»), которое может появиться в распределении памяти.
Стоит отметить, что система памяти компьютера может быть гораздо более сложной, чем представленная здесь. Цель данной статьи – обсудить некоторые основные концепции, которые могут быть полезны при программировании встраиваемых систем.
ОС #3-1. Управление памятью
Гранулярность доступа к памяти
Обычно мы представляем память как совокупность однобайтовых ячеек, как показано на рисунке 1. Каждая из этих ячеек имеет уникальный адрес, который позволяет нам получить доступ к данным по этому адресу.
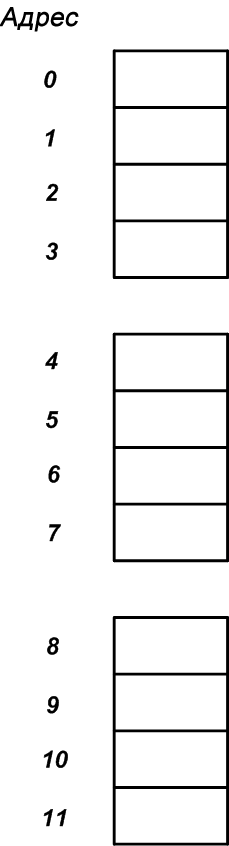
Однако процессор обычно обращается к памяти кусками размером более одного байта. Например, процессор может получать доступ к памяти в виде четырехбайтовых блоков. В этом случае мы можем представить 12 последовательных байтов на рисунке 1, как показано ниже на рисунке 2.
Вы можете задаться вопросом, в чем разница между этими двумя способами обработки памяти. На рисунке 1 процессор читает и записывает в память за раз по одному байту. Обратите внимание, что перед чтением ячейки памяти или записью в нее нам необходимо получить доступ к этой ячейке, и каждая процедура доступа к памяти занимает некоторое время. Предположим, что мы хотим прочитать первые восемь байтов на рисунке 1. Для каждого байта процессор должен получить доступ к памяти и прочитать ее. Следовательно, чтобы прочитать содержимое первых восьми байтов, процессору придется обращаться к памяти восемь раз.
На рисунке 2 процессор читает и записывает в память за раз четыре байта. Следовательно, чтобы прочитать первые четыре байта, процессор обращается к адресу 0 в памяти и считывает четыре последовательных ячейки хранения (адреса с 0 до 3). Точно так же, чтобы прочитать следующий четырехбайтовый фрагмент процессору необходимо получить доступ к памяти еще один раз.
Он идет по адресу 4 и считывает ячейки хранения по адресам с 4 по 7 одновременно. Для блоков размером в байт требуется восемь обращений к памяти, чтобы прочитать восемь последовательных байтов в памяти. Однако для распределения на рисунке 2 требуется только две процедуры доступа к памяти. Как упоминалось выше, каждая процедура доступа к памяти занимает некоторое время. Поскольку конфигурация памяти, показанная на рисунке 2, уменьшает количество обращений, она может привести к большей эффективности обработки.
Распределение памяти между процессами и виртуальная память
Размер данных, который процессор использует при доступе к памяти, называется гранулярностью доступа к памяти. На рисунке 2 показана система с четырехбайтовой гранулярностью доступа к памяти.
Границы доступа к памяти
Существует еще один важный метод, который разработчики аппаратного обеспечения часто используют, чтобы сделать систему обработки более эффективной: они ограничивают процессор так, чтобы он мог обращаться к памяти только на определенных границах. Например, процессор может иметь доступ к памяти, представленной на рисунке 2, только на четырехбайтовых границах, как показано красными стрелками на рисунке 3.
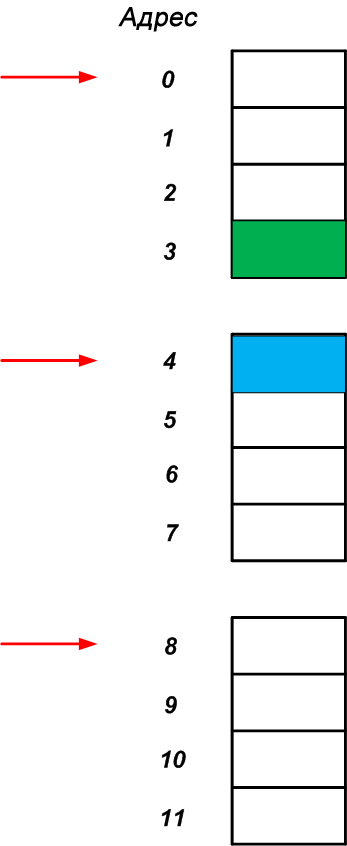
Будет ли это ограничение границами делать систему значительно более эффективной? Давайте рассмотрим подробнее. Предположим, что нам нужно прочитать содержимое областей памяти с адресами 3 и 4 (на рисунке 3 обозначены зеленым и синим прямоугольниками).
Если процессор бы мог прочитать четырехбайтовый фрагмент, начиная с произвольного адреса, мы могли бы получить доступ к адресу 3 и прочитать две нужных ячейки памяти за один раз доступа к памяти. Однако, как упоминалось выше, процессор не может напрямую получить доступ к произвольному адресу; он обращается к памяти только на определенных границах. Итак, как процессор будет считывать содержимое ячеек по адресам 3 и 4, если он может получить доступ только к четырехбайтовым границам?
Из-за ограничений границ доступа к памяти процессор должен получить доступ к ячейке памяти с адресом 0 и прочитать четыре последовательных байта (адреса с 0 по 3). Затем он должен использовать операции сдвига для отделения содержимого адреса 3 от других трех байтов (адреса с 0 по 2). Аналогично процессор может получить доступ к адресу 4 и прочитать другой четырехбайтовый фрагмент по адресам с 4 по 7. Наконец, операции сдвига могут снова использоваться для отделения нужного байта (синего прямоугольника) от других трех байтов.
Если бы не было ограничения границ доступа к памяти, мы могли бы прочитать ячейки по адресам 3 и 4 за одну процедуру доступа к памяти. Однако ограничение границ заставляет процессор обращаться к памяти дважды. Так зачем нам ограничивать доступ к памяти определенными границами, если это усложняет манипулирование данными?
Ограничение доступа к памяти границами существует потому, что определенные предположения об адресе могут упростить конструкцию оборудования. Например, предположим, что для адресации всех байтов в блоке памяти требуется 32 бита. Если мы ограничим адрес четырехбайтовыми границами, то два младших бит 32-битного адреса всегда будут равны нулю (поскольку адрес всегда будет делиться на четыре без остатка). Следовательно, мы сможем использовать 30 бит для адресации памяти с 2 32 байтами
Выравнивание данных
Теперь, когда мы знаем, как базовый процессор обращается к памяти, мы можем обсудить требования к выравниванию данных. Как правило, любой K -байтовый тип данных языка C должен иметь адрес, кратный K . Например, четырехбайтовый тип данных может храниться только по адресам 0, 4, 8, . ; его нельзя хранить по адресам 1, 2, 3, 5, . . Такие ограничения упрощают конструкцию аппаратного интерфейса между процессором и системой памяти.
В качестве примера рассмотрим процессор с четырехбайтовой гранулярностью доступа к памяти, который может обращаться к памяти только на четырехбайтовых границах. Предположим, что четырехбайтовая переменная хранится по адресу 1, как показано на рисунке 4 (четыре байта соответствуют четырем разным цветам). В этом случае нам понадобятся два обращения к памяти и некоторая дополнительная работа для чтения невыровненных четырехбайтовых данных (под «невыровненными» я подразумеваю, что они разбиты на два четырехбайтовых блока). Процедура показана на рисунке.
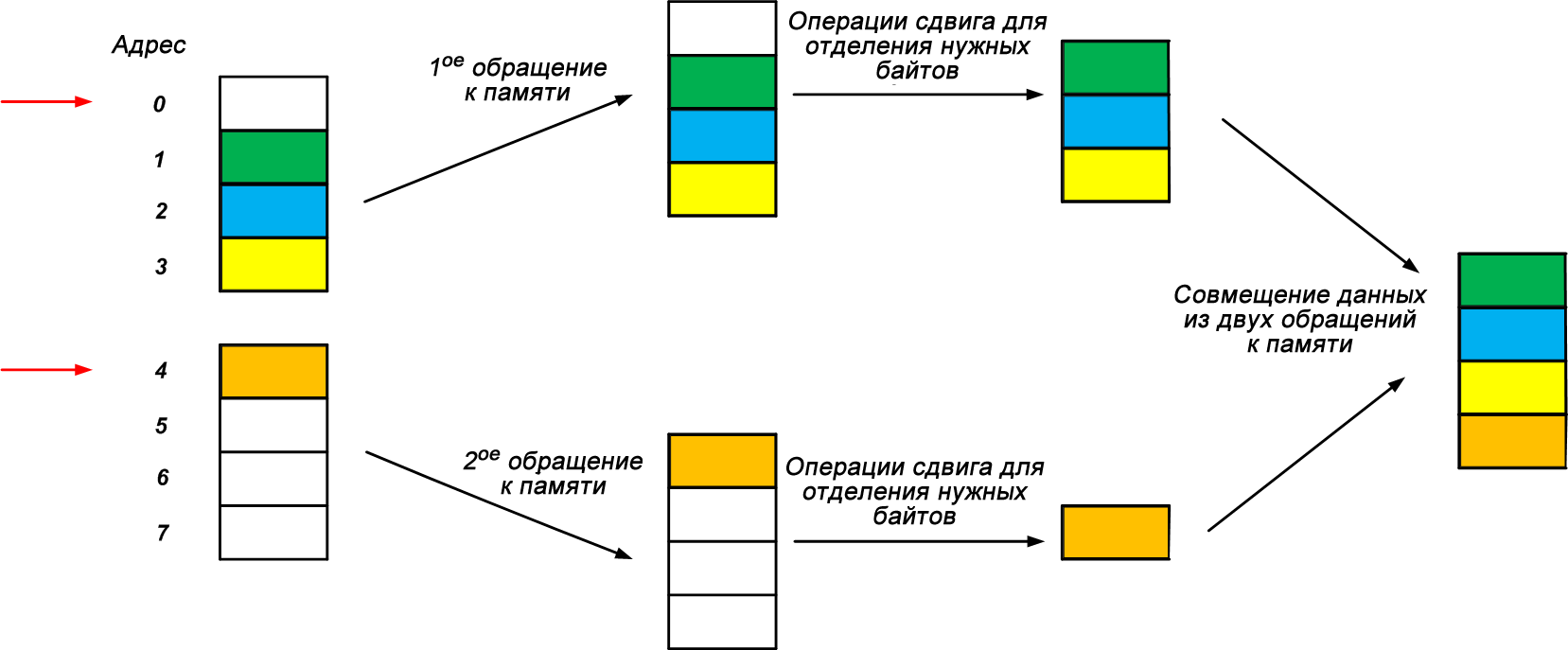
Однако, если мы храним четырехбайтовую переменную по любому адресу, кратному 4, нам потребуется только одна процедура доступа к памяти, чтобы изменить данные или прочитать их.
Вот почему хранение K -байтовых типов данных по адресу, кратному K , может сделать систему более эффективной. Следовательно, переменные » char » языка C (которые требуют только одного байта) могут храниться по любому байтовому адресу, но двухбайтовая переменная должна храниться по четным адресам. Четырехбайтовые типы должны начинаться с адресов, которые делятся на 4 без остатка, а восьмибайтовые типы данных должны храниться по адресам, которые делятся без остатка на 8. Например, предположим, что на конкретной машине переменным » short » требуется два байта, типы » int » и » float » занимают четыре байта, а » long «, » double » и указатели занимают восемь байтов. Каждый из этих типов данных обычно должен иметь адрес, кратный K , где K задается в следующей таблице.
| char | 1 |
| short | 2 |
| int , float | 4 |
| long , double , char* | 8 |
Обратите внимание, что размер разных типов данных может варьироваться в зависимости от компилятора и архитектуры машины. Оператор sizeof() будет лучшим способом для определения фактического размера типа данных.
Распределение памяти для структуры
Теперь давайте рассмотрим распределение памяти для структуры. Рассмотрим компилирование следующей структуры для 32-разрядной машины:
struct Test2 < uint8_t c; uint32_t d; uint8_t e; uint16_t f; >MyStruct;
Размещение данных и программ в памяти ПЭВМ
Данные и программы во время работы ПЭВМ размещаются в оперативной памяти, которая представляет собой последовательность пронумерованных ячеек. По указанному номеру процессор находит нужную ячейку, поэтому номер ячейки называется ее адресом. Минимальная адресованная ячейка (согласно стандарту IBM), с точки зрения программиста, состоит из 8 двоичных позиций, т.е. в каждую позицию могут быть записаны либо 0, либо 1. Объем информации, который помещается в одну двоичную позицию, называется битом. Объем информации, равный 8 битам, называется байтом.
Таким образом, в одной ячейке из 8 двоичных разрядов помещается объем информации в один байт. Поэтому объем памяти принято оценивать количеством байт (2 10 байт = 1024 байт = 1 Кб, 2 10 Кб = 1048576 байт = 1 Мб).
Для помещения данных в такие ячейки производится их запись с помощью нулей и единиц (кодирование). При кодировании каждый символ, введенный с клавиатуры, заменяется последовательностью из 8 двоичных разрядов в соответствии со стандартной кодовой таблицей, т.е. символ занимает один байт. Например, в соответствии с таблицей кодов ASCII D ® 01000100; F ® 00100110; 4 ® 00110100; ? ® 0011110.
При кодировании числа преобразуются в двоичное представление. Например,
2 = 1×2 1 + 0×2 0 = 102; 5 = 1×2 2 + 0×2 1 + 1×2 0 = 1012; 256 = 1×2 8 = 1000000002.
При работе с числами различают:
1) целые: ±n;
2) вещественные:
— с фиксированной десятичной точкой: ±n.m;
— с плавающей десятичной точкой (экспоненциальная форма): ±n.mE±p, где n, m — целая и дробная части числа, р — порядок; ±0.xxxE±p — нормализованный вид.
С увеличением числа количество разрядов для его представления в двоичной системе резко возрастает, поэтому для размещения большого числа выделяется несколько подряд расположенных однобайтных ячеек. В этом случае адресом такой расширенной ячейки является адрес первого байта. Один бит такой ячейки выделяется под знак числа. Числа, размещенные таким образом — целые.
Для хранения вещественных чисел их предварительно приводят к нормализованному виду. Например, 35,6 = 0.356×10 +2 , где 0.356 – мантисса, +2 – порядок. После этого переводят порядок и мантиссу в двоичную систему. Такое число запоминается в комбинированной ячейке, один байт которой содержит порядок, несколько других содержат мантиссу. Числа, размещенные таким образом — вещественные.
Программа – это последовательность команд (инструкций), которые помещаются в памяти и выполняются процессором в указанном порядке.
Команда размещается в комбинированной ячейке следующим образом. Первый байт содержит код операции (КОП) (например + или – или *), которую необходимо выполнить над содержимым ячеек памяти. В одной, двух или трех ячейках (операндах команды) по 2 или 4 байта содержатся адреса ячеек (А1, А2, А3), над которыми нужно выполнить указанную операцию.
Номер первого байта команды называется ее адресом. Последовательность из этих команд называется программой в машинных кодах (рис. 2).
Программные модули
Программист пишет программу на языке высокого уровня, т.е. наиболее удобном для записи алгоритма решения определенного класса задач. Исходный текст программы, введенный с помощью клавиатуры в память компьютера — исходный модуль (sourse code, в языке Си имеет расширение *.cpp).
Транслятор — программа, осуществляющая перевод текстов с одного языка на другой, т.е. транслятор переводит программу с входного языка системы программирования на машинный язык ЭВМ, на которой функционирует данная система или будет функционировать разрабатываемая программа; либо на промежуточный язык программирования, уже реализованный или подлежащий реализации. Одной из разновидностей транслятора является компилятор, обеспечивающий перевод программ с языка высокого уровня (приближенного к человеку) на язык более низкого уровня (близкий к ЭВМ), или машинозависимый язык.
Интерпретатор представляет собой программный продукт, выполняющий созданную программу путем одновременного анализа и реализации предписанных действий. При использовании интерпретатора отсутствует разделение на две стадии — перевод и выполнение.
Большинство трансляторов языка Си, с которыми мы будем работать — компиляторы.
Результат обработки исходного модуля компилятором — объектный модуль (object code, в языке Си имеет расширение *.obj). Он не может быть выполнен, т.е. это незавершенный вариант машинной программы, т.к., например, к нему должны быть присоединены модули стандартных библиотек. Здесь компилятор (compiler) — вид транслятора, представляющего программу-переводчик исходного модуля в язык машинных команд.
Исполняемый (абсолютный, загрузочный) модуль создает вторая специальная программа — «компоновщик». Ее еще называют редактором связей (Linker). Она и создает модуль, пригодный для выполнения на основе одного или нескольких объектных модулей.
Загрузочный модуль (Load module, расширение *.exe) – это программный модуль, представленный в форме, пригодной для загрузки его в память и выполнения.
Ошибки
Ошибки, допускаемые при написании программ, разделяют на синтаксические и логические.
Синтаксические ошибки — нарушение формальных правил написания программы на конкретном языке, обнаруживаются на этапе трансляции и могут быть легко исправлены.
Логические ошибки делят на ошибки алгоритма и семантические ошибки — могут быть найдены и исправлены только разработчиком программы.
Причина ошибки алгоритма — несоответствие построенного алгоритма ходу получения конечного результата сформулированной задачи.
Причина семантической ошибки — неправильное понимание смысла (семантики) операторов языка.
Дата добавления: 2016-09-26 ; просмотров: 2594 ; ЗАКАЗАТЬ НАПИСАНИЕ РАБОТЫ
Источник: poznayka.org
Образ программы в памяти
Образ программы в памяти начинается с сегмента префикса программы (Program Segment Prefics, PSP), образуемого и заполняемого системой. PSP всегда имеет размер 256 байт; он содержит таблицы и поля данных, используемые системой в процессе выполнения программы. Вслед за PSP располагаются сегменты программы в том порядке, как они объявлены в программе.
Сегментные регистры автоматически инициализируются следующим образом:
· ES и DS указывают на начало PSP (что дает возможность, сохранив их содержимое, обращаться затем в программе к PSP),
· CS — на начало сегмента команд,
· SS — на начало сегмента стека.
В указатель команд IP загружается относительный адрес точки входа в программу (из операнда директивы end), а в указатель стека SP — величина, равная объявленному размеру стека, в результате чего указатель стека указывает на конец стека (точнее, на первое слово за его пределами).
Таким образом, после загрузки программы в память адресуемыми оказываются все сегменты, кроме сегмента данных. Инициализация регистра DS в первых строках программы позволяет сделать адресуемым и этот сегмент.
Важнейшая особенность архитектуры процессоров Intel — адрес любой ячейки памяти состоит из двух слов, одно из которых определяет расположение в памяти соответствующего сегмента, а другое — смещение в пределах этого сегмента.
Сегмент всегда начинается с адреса, кратного 16, т.е. на границе 16-байтового блока памяти (параграфа). Сегментный адрес можно рассматривать, как номер параграфа, с которого начинается данный сегмент. Размер сегмента определяется объемом содержащихся в нем данных, но никогда не может превышать величину 64 Кбайт, что определяется максимально возможной величиной смещения.
Сегментный адрес сегмента команд хранится в регистре CS, а смещение к адресуемому байту — в указателе команд IP. Как уже отмечалось, после загрузки программы в IP заносится смещение первой команды программы; процессор, считав ее из памяти, увеличивает содержимое IP точно на длину этой команды (команды процессоров Intel могут иметь длину от 1 до 6 байт), в результате чего IP указывает на вторую команду программы. Выполнив первую команду, процессор считывает из памяти вторую, опять увеличивая значение IP. В результате в IP всегда находится смещение очередной команды, т. е. команды, следующей за выполняемой. Описанный алгоритм нарушается только при выполнении команд переходов, вызовов подпрограмм и обслуживания прерываний.
Сегментный адрес сегмента данных обычно хранится в регистре DS, a смещение может находится в одном из регистров общего назначения, например, в ВХ или SI.
Понравилась статья? Добавь ее в закладку (CTRL+D) и не забудь поделиться с друзьями:
Источник: studopedia.ru