
Книга и мини-курс Брайана Кукси
(Brian Cooksey), Zapier.
Содержание
- Глава 1: Введение
- Глава 2: Протоколы
- Глава 3: Форматы данных
- Глава 4: Аутентификация, часть 1
- Глава 5: Аутентификация, часть 2
- Глава 6: Проектирование API
- Глава 7: Связь в реальном времени
- Глава 8: Реализация
Глава 1: Введение
API (application programming interfaces, интерфейсы прикладного программирования) — большая часть интернета. В одном только 2013 году компаниями для открытого использования было опубликовано более 10 000 API. Это в четыре раза больше, чем в 2010 году.
Поскольку так много компаний инвестируют в эту новую область бизнеса, понимание принципов работы API становится всё более актуальным для карьеры в индустрии разработки программного обеспечения. С помощью этого курса мы надеемся дать вам все необходимые знания для начала работы с API. В этой главе мы рассмотрим некоторые фундаментальные концепции API. Мы определим, что такое API, где он находится, и определим общую модель того, как он используется.
#1 | Python Socket | Как Работает Сеть?
Определение контекста
Когда мы говорим об API, большая часть разговоров сосредоточена на абстрактных концепциях. Чтобы внести ясность, давайте начнем с чего-то физического: с сервера. Сервер — это не что иное, как большой компьютер. Он состоит из тех же частей, что и ноутбук или настольный компьютер, который вы используете для работы, только он быстрее и мощнее.
Обычно на серверах нет монитора, клавиатуры или мыши, из-за чего они выглядят недоступными. В реальности же ИТ-специалисты для работы с ними подключаются к ним дистанционно — как к удаленному рабочему столу.
Серверы используются для самых разных вещей. Некоторые хранят данные; другие отправляют электронную почту. Чаще всего люди взаимодействуют с веб-серверами. Это серверы, которые предоставляют вам веб-страницу при посещении веб-сайта. Чтобы лучше понять, как это работает, приведем простую аналогию:
Точно так же, как программа, подобная пасьянсу «Косынка» (Solitaire), ждет, пока вы щёлкнете по карте, чтобы что-то сделать, веб-сервер исполняет программу, которая ждёт, пока человек запросит веб-страницу.
В этом нет ничего волшебного или захватывающего. Разработчик программного обеспечения пишет программу, копирует её на сервер, и сервер выполняет её.
Что такое API и почему он ценен
Веб-сайты созданы с учетом сильных сторон людей. Люди обладают невероятной способностью воспринимать визуальную информацию, комбинировать ее с нашим опытом для извлечения смысла, а затем действовать в соответствии с этим значением. Вот почему вы можете взглянуть на форму веб-сайта и понять, что небольшое поле с надписью «Имя» над ним означает, что вы должны ввести слово, которое вы используете для идентификации себя.
Но что происходит, когда вы сталкиваетесь с очень трудоемкой задачей, например копированием контактной информации тысячи клиентов с одного сайта на другой? Уверен, вы бы предпочли передать эту работу компьютеру, чтобы её можно было выполнить быстро и точно. К сожалению, характеристики, которые делают веб-сайты удобным для использования людьми, делают их трудными для использования компьютерами.
Урок 14. JavaScript. Запросы на сервер. Fetch, XMLHttpRequest (XHR), Ajax
И тут решением выступает API. API — это инструмент, который делает данные веб-сайта удобными для использования компьютером. С его помощью компьютер может просматривать и редактировать данные, точно так же, как человек может загружать страницы и отправлять формы.
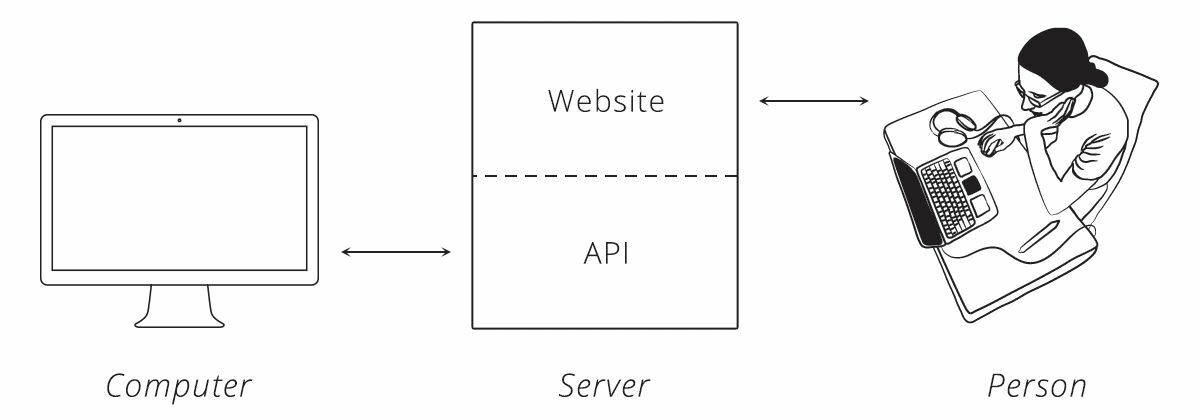
Рисунок 1. Связь с сервером.
Источник: systems.education
Ответы на билеты по гос экзаменам Факультет К кафедра 29 / Базы данных / Технология и модели клиент-сервер(1)
Клиент-сервер — это модель взаимодействия компьютеров в сети. Как правило, компьютеры не являются равноправными. Каждый из них имеет свое, отличное от других, назначение, играет свою роль. Некоторые компьютеры в сети владеют и распоряжается информационно-вычислительными ресурсами, такими как процессоры, файловая система, почтовая служба, служба печати, база данных.
Другие же компьютеры имеют возможность обращаться к этим службам, пользуясь услугами первых. Компьютер, управляющий тем или иным ресурсом, принято называть сервером этого ресурса, а компьютер, желающий им воспользоваться — клиентом. Конкретный сервер определяется видом ресурса, которым он владеет. Так, если ресурсом являются базы данных, то речь идет о сервере баз данных, назначение которого — обслуживать запросы клиентов, связанные с обработкой данных; если ресурс — это файловая система, то говорят о файловом сервере, или файл-сервере, и т. д.
В сети один и тот же компьютер может выполнять роль как клиента, так и сервера. Например, в информационной системе, включающей персональные компьютеры, большую ЭВМ и мини-компьютер под управлением UNIX, последний может выступать как в качестве сервера базы данных, обслуживая запросы от клиентов — персональных компьютеров, так и в качестве клиента, направляя запросы большой ЭВМ.
Этот же принцип распространяется и на взаимодействие программ. Если одна из них выполняет некоторые функции, предоставляя другим соответствующий набор услуг, то такая программа выступает в качестве сервера. Программы, которые пользуются этими услугами, принято называть клиентами. Так, ядро реляционной SQL-ориентированной СУБД часто называют сервером базы данных, или SQL-сервером, а программу, обращающуюся к нему за услугами по обработке данных — SQL-клиентом.


Рисунок 1. Системы с централизованной архитектурой.
Первоначально СУБД имели централизованную архитектуру (рис.1). В ней сама СУБД и прикладные программы, которые работали с базами данных, функционировали на центральном компьютере (большая ЭВМ или мини-компьютер). Там же располагались базы данных. К центральному компьютеру были подключены терминалы, выступавшие в качестве рабочих мест пользователей.
Все процессы, связанные с обработкой данных, как то: поддержка ввода, осуществляемого пользователем, формирование, оптимизация и выполнение запросов, обмен с устройствами внешней памяти и т.д., выполнялись на центральном компьютере, что предъявляло жесткие требования к его производительности. Особенности СУБД первого поколения напрямую связаны с архитектурой систем больших ЭВМ и мини-компьютеров и и адекватно отражают все их преимущества и недостатки. Однако нас больше интересует современное состояние многопользовательских СУБД, для которых архитектура клиент-сервер стала фактическим стандартом.
Для более четкого представления об ее особенностях необходимо рассмотреть несколько моделей технологии клиент-сервер, что и будет сделано.
Если предполагается, что проектируемая информационная система (ИС) будет иметь технологию клиент-сервер, то это означает, что прикладные программы, реализованные в ее рамках, будут иметь распределенный характер. Иными словами, часть функций прикладной программы (или, проще, приложения) будет реализована в программе-клиенте, другая — в программе-сервере, причем для их взаимодействия будет определен некоторый протокол.
Основной принцип технологии клиент-сервер заключается в разделении функций стандартного интерактивного приложения на четыре группы, имеющие различную природу. Первая группа — это функции ввода и отображения данных. Вторая группа объединяет чисто прикладные функции, характерные для данной предметной области (например, для банковской системы — открытие счета, перевод денег с одного счета на другой и т.д.). К третьей группе относятся фундаментальные функции хранения и управления информационными ресурсами (базами данных, файловыми системами и т.д.). Наконец, функции четвертой группы — это служебные функции (играющие роль связок между функциями первых трех групп.
В соответствии с этим в любом приложении выделяются следующие логические компоненты:
· компонент представления, реализующий функции первой группы;
· прикладной компонент, поддерживающий функции второй группы;
· компонент доступа к информационным ресурсам, поддерживающий функции третьей групп, а также вводятся и уточняются соглашения о способах их взаимодействия (протокол взаимодействия).
Различия в реализациях технологии клиент-сервер определяются четырьмя факторами. Во-первых, тем, в какие виды программного обеспечения интегрированы каждый из этих компонентов. Во-вторых, тем, какие механизмы программного обеспечения используются для реализации функций всех трех групп. Во-третьих, как логические компоненты распределяются между компьютерами в сети. В-четвертых, какие механизмы используются для связи компонентов между собой.
Выделяются четыре подхода, реализованные в моделях:
· модель файлового сервера (File Server — FS);
· модель доступа к удаленным данным (Remote Data Access — RDA);
· модель севера базы данных (DataBase Server — DBS);
· модель сервера приложений (Application Server — AS).
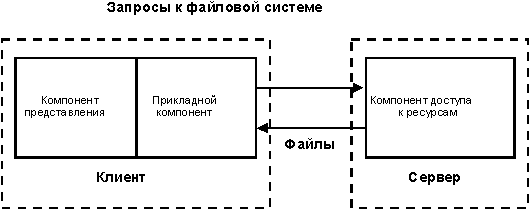

Рисунок 2. Модель файлового сервера.
FS-модель является базовой для локальных сетей персональных компьютеров. Не так давно она была исключительно популярной среди отечественных разработчиков, использовавших такие системы, как FoxPRO, Clipper, Clarion, Paradox и т.д. Суть модели проста и всем известна. Один из компьютеров в сети считается файловым сервером и предоставляет услуги по обработке файлов другим компьютерам.
Файловый сервер работает под управлением сетевой операционной системы (например, Novell NetWare) и играет роль компонента доступа к информационным ресурсам (то есть к файлам). На других компьютерах в сети функционирует приложение, в кодах которого совмещены компонент представления и прикладной компонент (рис.2). Протокол обмена представляет собой набор низкоуровневых вызовов, обеспечивающих приложению доступ к файловой системе на файл-сервере.
FS-модель послужила фундаментом для расширения возможностей персональных СУБД в направлении поддержки многопользовательского режима. В таких системах на нескольких персональных компьютерах выполняется как прикладная программа, так и копия СУБД, а базы данных содержатся в разделяемых файлах, которые находятся на файловом сервере.
Когда прикладная программа обращается к базе данных, СУБД направляет запрос на файловый сервер. В этом запросе указаны файлы, где находятся запрашиваемые данные. В ответ на запрос файловый сервер направляет по сети требуемый блок данных. СУБД, получив его, выполняет над данными действия, которые были декларированы в прикладной программе.
К технологическим недостаткам модели относят высокий сетевой трафик (передача множества файлов, необходимых приложению), узкий спектр операций манипуляции с данными (данные — это файлы), отсутствие адекватных средств безопасности доступа к данным (защита только на уровне файловой системы) и т.д. Собственно, перечисленное не есть недостатки, но — следствие внутренне присущих FS-модели ограничений, определяемых ее характером. Недоразумения возникают, когда FS-модель используют не по назначению, например, пытаются интерпретировать как модель сервера базы данных. Место FS-модели в иерархии моделей клиент-сервер — это место модели файлового сервера, и ничего более. Именно поэтому обречены на провал попытки создания на основе FS-модели крупных корпоративных систем — попытки, которые предпринимались в недавнем прошлом и нередко предпринимаются сейчас.


Рисунок 3. Модель доступа к удаленным данным.
Более технологичная RDA-модель существенно отличается от FS-модели характером компонента доступа к информационным ресурсам. Это, как правило, SQL-сервер. В RDA-модели коды компонента представления и прикладного компонента совмещены и выполняются на компьютере-клиенте. Последний поддерживает как функции ввода и отображения данных, так и чисто прикладные функции. Доступ к информационным ресурсам обеспечивается либо операторами специального языка (языка SQL, например, если речь идет о базах данных), либо вызовами функций специальной библиотеки (если имеется соответствующий интерфейс прикладного программирования — API).
Клиент направляет запросы к информационным ресурсам (например, к базам данных) по сети удаленному компьютеру. На нем функционирует ядро СУБД, которое обрабатывает запросы, выполняя предписанные в них действия, и возвращает клиенту результат, оформленный как блок данных (рис.3). При этом инициатором манипуляций с данными выступают программы, выполняющиеся на компьютерах-клиентах, в то время как ядру СУБД отводится пассивная роль — обслуживание запросов и обработка данных. В Разделе 2 будет показано, что такое распределение обязанностей между клиентами и сервером базы данных не догма — сервер БД может играть более активную роль, чем та, которая предписана ему традиционной парадигмой.
RDA-модель избавляет от недостатков, присущих как системам с централизованной архитектурой, так и системам с файловым сервером.
Прежде всего перенос компонента представления и прикладного компонента на компьютеры-клиенты существенно разгружает сервер БД, сводя к минимуму общее число процессов операционной системы. Сервер БД освобождается от несвойственных ему функций; процессор или процессоры сервера целиком загружаются операциями обработки данных, запросов и транзакций. Это становится возможным благодаря отказу от терминалов и оснащению рабочих мест компьютерами, которые обладают собственными локальными вычислительными ресурсами, полностью используемыми программами переднего плана. С другой стороны, резко уменьшается загрузка сети, так как по ней передаются от клиента к серверу не запросы на ввод-вывод (как в системах с файловым сервером), а запросы на языке SQL, их объем существенно меньше.
Основное достоинство RDA-модели — унификация интерфейса клиент-сервер в виде языка SQL. Действительно, взаимодействие прикладного компонента с ядром СУБД невозможно без стандартизованного средства общения. Запросы, направляемые программой ядру, должны быть понятны обоим. Для этого их следует сформулировать на специальном языке. Но в СУБД уже существует язык SQL, о котором уже шла речь . Поэтому целесообразно использовать его не только в качестве средства доступа к данным, но и стандарта общения клиента и сервера.
Такое общение можно сравнить с беседой нескольких человек, когда один отвечает на вопросы остальных (вопросы задаются одновременно). Причем делает это он так быстро, что время ожидания ответа приближается к нулю. Высокая скорость общения достигается прежде всего благодаря четкой формулировке вопроса, когда спрашивающему и отвечающему не нужно дополнительных консультаций по сути вопроса. Беседующие обмениваются несколькими короткими однозначными фразами, им ничего не нужно уточнять.
К сожалению, RDA-модель не лишена ряда недостатков. Во-первых, взаимодействие клиента и сервера посредством SQL-запросов существенно загружает сеть. Во-вторых, удовлетворительное администрирование приложений в RDA-модели практически невозможно из-за совмещения в одной программе различных по своей природе функций (функции представления и прикладные). Более подробно о недостатках RDA-модели сказано в п. 2.3.1.
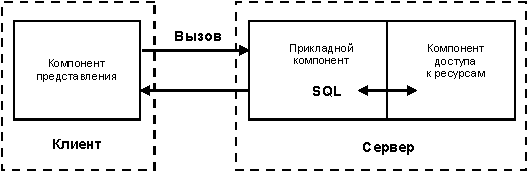

Рисунок 4. Модель сервера базы данных.
Наряду с RDA-моделью все большую популярность приобретает перспективная DBS-модель (рис. 4). Последняя реализована в некоторых реляционных СУБД (Informix, Ingres, Sybase, Oracle). Ее основу составляет механизм хранимых процедур — средство программирования SQL-сервера.
Процедуры хранятся в словаре базы данных, разделяются между несколькими клиентами и выполняются на том же компьютере, где функционирует SQL-сервер. Язык, на котором разрабатываются хранимые процедуры, представляет собой процедурное расширение языка запросов SQL и уникален для каждой конкретной СУБД. Более подробно о хранимых процедурах рассказано в п. 2.3.3.
В DBS-модели компонент представления выполняется на компьютере-клиенте, в то время как прикладной компонент оформлен как набор хранимых процедур и функционирует на компьютере-сервере БД. Там же выполняется компонент доступа к данным, то есть ядро СУБД. Достоинства DBS-модели очевидны: это и возможность централизованного администрирования прикладных функций, и снижение трафика (вместо SQL-запросов по сети направляются вызовы хранимых процедур), и возможность разделения процедуры между несколькими приложениями, и экономия ресурсов компьютера за счет использования единожды созданного плана выполнения процедуры. К недостаткам модели можно отнести ограниченность средств, используемых для написания хранимых процедур, которые представляют собой разнообразные процедурные расширения SQL, не выдерживающие сравнения по изобразительным средствам и функциональным возможностям с языками третьего поколения, такими как C или Pascal. Сфера их использования ограничена конкретной СУБД, в большинстве СУБД отсутствуют возможности отладки и тестирования разработанных хранимых процедур.
На практике часто используется смешанные модели, когда поддержка целостности базы данных и некоторые простейшие прикладные функции поддерживаются хранимыми процедурами (DBS-модель), а более сложные функции реализуются непосредственно в прикладной программе, которая выполняется на компьютере-клиенте (RDA-модель). Так или иначе современные многопользовательские СУБД опираются на RDA- и DBS-модели и при создании ИС, предполагающем использование только СУБД, выбирают одну из этих двух моделей либо их разумное сочетание.


Рисунок 5. Модель сервера приложений.
В AS-модели (рис.5) процесс, выполняющийся на компьютере-клиенте, отвечает, как обычно, за интерфейс с пользователем (то есть осуществляет функции первой группы). Обращаясь за выполнением услуг к прикладному компоненту, этот процесс играет роль клиента приложения (Application Client — AC). Прикладной компонент реализован как группа процессов, выполняющих прикладные функции, и называется сервером приложения (Application Server — AS). Все операции над информационными ресурсами выполняются соответствующим компонентом, по отношению к которому AS играет роль клиента. Из прикладных компонентов доступны ресурсы различных типов — базы данных, очереди, почтовые службы и др.
RDA- и DBS-модели опираются на двухзвенную схему разделения функций. В RDA-модели прикладные функции приданы программе-клиенту, в DBS-модели ответственность за их выполнение берет на себя ядро СУБД. В первом случае прикладной компонент сливается с компонентом представления, во-втором — интегрируется в компонент доступа к информационным ресурсам.
В AS-модели реализована трехзвенная схема разделения функций, где прикладной компонент выделен как важнейший изолированный элемент приложения, для его определения используются универсальные механизмы многозадачной операционной системы, и стандартизованы интерфейсы с двумя другими компонентами. AS-модель является фундаментом для мониторов обработки транзакций (Transaction Processing Monitors — TPM), или, проще, мониторов транзакций, которые выделяются как особый вид программного обеспечения. Мониторы транзакций — предмет Раздела 4.
В заключение отметим, что, часто, говоря о сервере базы данных, подразумевают как компьютер, так и программное обеспечение — ядро СУБД. При описании архитектуры Клиент-сервер под сервером базы данных мы имели в виду компьютер. Далее сервер базы данных будет пониматься как программное обеспечение — ядро СУБД.
Источник: studfile.net
Работающая на сервере программа которая обрабатывает запросы клиентов это
Рассмотрим взаимодействие HttpClient с веб-приложением, которое реализует Web API на примере простейшего веб-приложения ASP.NET Core
Создание сервера
Сначала определим проект веб-приложения. Для этого создадим проект по типу ASP.NET Core Empty :
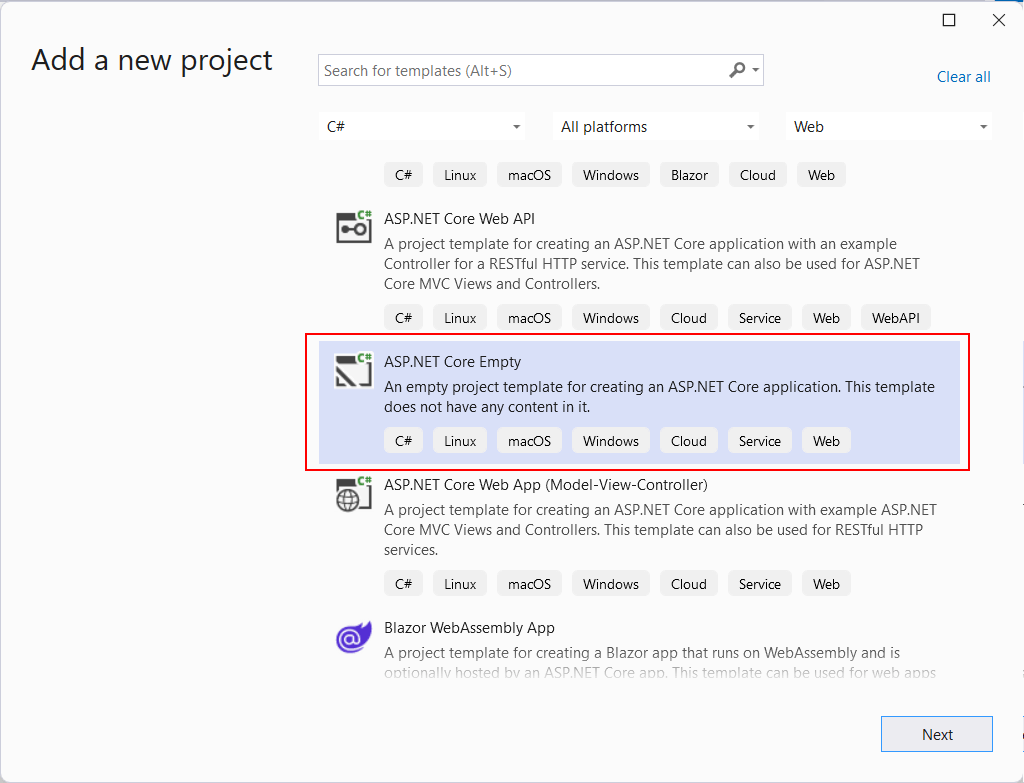
К примеру, в моем случае проект называется HttpClientTestApp . Откроем в этом проекте в файл Program.cs
и определим в нем следующий код:
int // для генерации id объектов // начальные данные List users = new List < new() < Name = «Tom», Age = 37 >, new() < Name = «Bob», Age = 41 >, new() < Name = «Sam», Age = 24 >>; var builder = WebApplication.CreateBuilder(); var app = builder.Build(); app.MapGet(«/api/users», () => users); app.MapGet(«/api/users/», (int id) => < // получаем пользователя по id Person? user = users.FirstOrDefault(u =>u.Id == id); // если не найден, отправляем статусный код и сообщение об ошибке if (user == null) return Results.NotFound(new < message = «Пользователь не найден» >); // если пользователь найден, отправляем его return Results.Json(user); >); app.MapDelete(«/api/users/», (int id) => < // получаем пользователя по id Person? user = users.FirstOrDefault(u =>u.Id == id); // если не найден, отправляем статусный код и сообщение об ошибке if (user == null) return Results.NotFound(new < message = «Пользователь не найден» >); // если пользователь найден, удаляем его users.Remove(user); return Results.Json(user); >); app.MapPost(«/api/users», (Person user) => < // устанавливаем id для нового пользователя user.Id = id++; // добавляем пользователя в список users.Add(user); return user; >); app.MapPut(«/api/users», (Person userData) => < // получаем пользователя по id var user = users.FirstOrDefault(u =>u.Id == userData.Id); // если не найден, отправляем статусный код и сообщение об ошибке if (user == null) return Results.NotFound(new < message = «Пользователь не найден» >); // если пользователь найден, изменяем его данные и отправляем обратно клиенту user.Age = userData.Age; user.Name = userData.Name; return Results.Json(user); >); app.Run(); public class Person < public int Id < get; set; >public string Name < get; set; >= «»; public int Age < get; set; >>
Более подробно создание приложения Web API на ASP.NET рассмотрено в статье Пример приложения Web API на ASP.NET. Сейчас лишь вкратце пройдемся по основным момента данного кода. Вначале определяется переменная для генерации id объектов и создается список объектов Person — те данные, с которыми будет работать пользователь::
int users = new List < new() < Name = «Tom», Age = 37 >, new() < Name = «Bob», Age = 41 >, new() < Name = «Sam», Age = 24 >>;
При создании нового объекта значение переменной id увеличивается на единицу, поэтому каждый новый объект получает id на единицу больше, чем предыдущий. Для упрошения данные определены в виде обычного списка объектов, но в реальной ситуации обычно подобные данные извлекаются из какой-нибудь базы данных.
Затем с помощью методов MapGet/MapPost/MapPut/MapDelete определяется набор конечных точек, которые будут обрабатывать разные типы запросов.
Вначале добавляется конечная точка, которая обрабатывает запрос типа GET по маршруту «api/users»:
app.MapGet(«/api/users», () => users);
Запрос GET предполагает получение объектов, и в данном случае отправляем выше определенный список объектов Person.
Когда клиент обращается к приложению для получения одного объекта по id в запрос типа GET по адресу «api/users/», то срабатывает другая конечная точка:
app.MapGet(«/api/users/», (int id) => < // получаем пользователя по id Person? user = users.FirstOrDefault(u =>u.Id == id); // если не найден, отправляем статусный код и сообщение об ошибке if (user == null) return Results.NotFound(new < message = «Пользователь не найден» >); // если пользователь найден, отправляем его return Results.Json(user); >);
Здесь через параметр id получаем из пути запроса идентификатор объекта Person и по этому идентификатору ищем нужный объект в списке users. Если объект по Id не был найден, то возвращаем с помощью метода Results.NotFound() статусный код 404 с некоторым сообщением в формате JSON. Если объект найден, то с помощью метода Results.Json() отправляет найденный объект клиенту.
При получении запроса типа DELETE по маршруту «/api/users/» срабатывает другая конечная точка:
app.MapDelete(«/api/users/», (int id) => < // получаем пользователя по id Person? user = users.FirstOrDefault(u =>u.Id == id); // если не найден, отправляем статусный код и сообщение об ошибке if (user == null) return Results.NotFound(new < message = «Пользователь не найден» >); // если пользователь найден, удаляем его users.Remove(user); return Results.Json(user); >);
Здесь действует аналогичная логика — если объект по Id не найден, отправляет статусный код 404. Если же объект найден, то удаляем его из списка и посылаем клиенту.
При получении запроса с методом POST по адресу «/api/users» срабатывает следующая конечная точка:
app.MapPost(«/api/users», (Person user)=>< // устанавливаем id для нового пользователя user.Id = id++; // добавляем пользователя в список users.Add(user); return user; >);
Запрос типа POST предполагает передачу приложению отправляемых данных. Причем мы ожидаем, что клиент отправит данные, которые соответствуют определению типа Person. И поэтому инфраструктура ASP.NET Core сможет автоматически собрать из них объект Person. И этот объект мы сможем получить в качестве параметра в обработчике конечной точки.
После получения данных устанавливаем у нового объекта свойство Id, добавляем его в список users и отправляем обратно клиенту.
Если приложению приходит PUT-запрос по адресу «/api/users», то аналогичным образом получаем отправленные клиентом данные в виде объекта Person и пытаемся найти подобный объект в списке users. Если объект не найден, отправляем статусный код 404. Если объект найден, то изменяем его данные и отправляем обратно клиенту:
app.MapPut(«/api/users», (Person userData) => < // получаем пользователя по id var user = users.FirstOrDefault(u =>u.Id == userData.Id); // если не найден, отправляем статусный код и сообщение об ошибке if (user == null) return Results.NotFound(new < message = «Пользователь не найден» >); // если пользователь найден, изменяем его данные и отправляем обратно клиенту user.Age = userData.Age; user.Name = userData.Name; return Results.Json(user); >);
Для теста запустим этот проект и обратимся в браузере по адресу «/api/users» для получения списка данных:
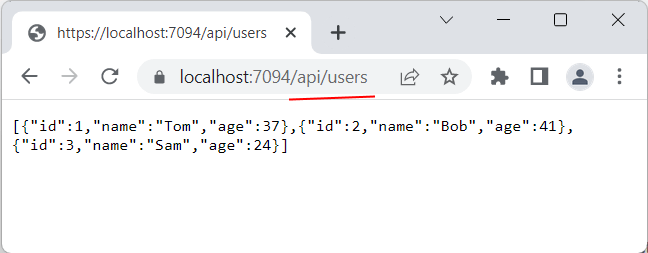
Таким образом, мы определили простейший API. Теперь посмотрим, как мы можем взаимодействовать с этим кодом с помощью класса HttpClient .
Определение клиента
GET-запрос
Поскольку конечная точка, которая обрабатывает GET-запрос, возвращает список данных в формате JSON, то для его получения у HttpClient удобнее использовать метод GetFromJsonAsync() :
using System.Net.Http.Json; class Program < static HttpClient httpClient = new HttpClient(); static async Task Main() < List? people = await httpClient.GetFromJsonAsync («https://localhost:7094/api/users»); if (people != null) < foreach (var person in people) < Console.WriteLine(person.Name); >> > > public class Person < public int Id < get; set; >public string Name < get; set; >= «»; public int Age < get; set; >>
Как видно из предыдущего скриншота, у меня приложение ASP.NET запущено по адресу «https://localhost:7094/», а адресом ресурса является «api/users», соответственно в моем случае для получения данных я обращаюсь по адресу «https://localhost:7094/api/users». Полученные данные автоматически десериализуются из JSON в список объектов Person, свойство Name которых затем выводится на консоль:
Tom Bob Sam
Получение одного объекта
В ранее определенном сервере для отправки одного объекта применяется конечная точка
app.MapGet(«/api/users/», (int id) => < .
То есть также надо выполнить get-запрос, только в адресную строку нам надо передать id объекта. И в данном случае мы могли бы использовать тот же метод GetFromJsonAsync()
int // получаем объект с person = await httpClient.GetFromJsonAsync($»https://localhost:7094/api/users/»);
Однако, что если мы отправим id несуществующего объекта. В этом случае объект person будет равен null. Однако сервер в этом случае посылает нам соответствующий статусный код и сообщение об ошибке. И было бы неплохо иметь возможность в случае проблемы также использовать эти данные.
В этом случае мы можем отправить запрос с помощью метода GetAsync() и получить ответ в виде HttpResponseMessage. И в зависимости от статусного кода десериализовать ответ в один из типов данных:
using System.Net; using System.Net.Http.Json; class Program < static HttpClient httpClient = new HttpClient(); static async Task Main() < // id первого объекта int using var response = await httpClient.GetAsync($»https://localhost:7094/api/users/»); // если объект на сервере найден, то есть статусный код равен 404 if (response.StatusCode == HttpStatusCode.NotFound) < Error? error = await response.Content.ReadFromJsonAsync(); Console.WriteLine(error?.Message); > else if (response.StatusCode == HttpStatusCode.OK) < // считываем ответ Person? person = await response.Content.ReadFromJsonAsync(); Console.WriteLine($» — «); > > > record Error(string Message); class Person < public int Id < get; set;>public string Name < get; set; >= «»; public int Age < get; set; >>
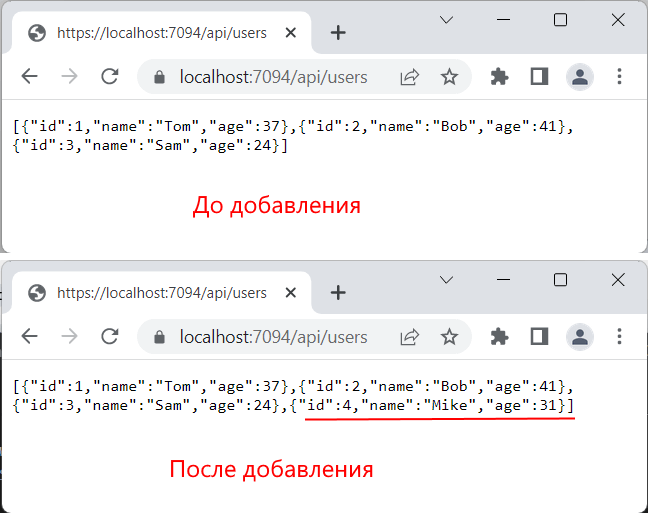
Добавление данных
Добавление данных на сервере обрабатывается конечной точкой
app.MapPost(«/api/users», (Person user) =>
То есть нам надо в запросе POST послать данные, которые соответствуют объекту Person. Для отправки данных на HttpClient можно использовать метод PostAsync() , либо PostAsJsonAsync() , в который передается адрес ресурса и сами добавляемые данные. Поскольку в данном случае веб-приложение ожидает данные в формате JSON, то проще воспользоваться методом PostAsJsonAsync() :
using System.Net.Http.Json; class Program < static HttpClient httpClient = new HttpClient(); static async Task Main() < // отправляемый объект var mike = new Person < Name = «Mike», Age = 31 >; using var response = await httpClient.PostAsJsonAsync(«https://localhost:7094/api/users/», mike); // считываем ответ и десериализуем данные в объект Person Person? person = await response.Content.ReadFromJsonAsync(); Console.WriteLine($» — «); > > class Person < public int Id < get; set;>public string Name < get; set; >= «»; public int Age < get; set; >>
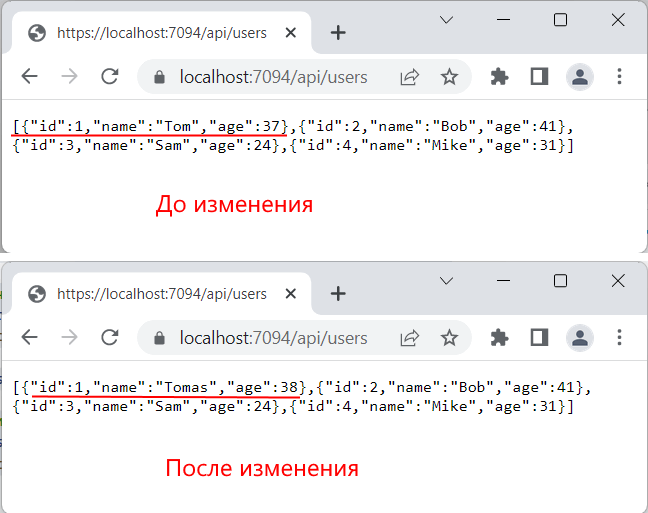
Изменение данных
Для изменения данных мы должны отправить данные следующей конечной точке:
app.MapPut(«/api/users», (Person userData) => < .
Для отправки измененных данных в запросе типа PUT можно использовать метод PutAsync() , либо PutAsJsonAsync() , в которые передаются адрес ресурса и сами добавляемые данные. Поскольку в данном случае веб-приложение ожидает данные в формате JSON, то проще воспользоваться методом PutAsJsonAsync() :
using System.Net.Http.Json; class Program < static HttpClient httpClient = new HttpClient(); static async Task Main() < // id изменяемого объекта int // отправляемый объект var tom = new Person < Name = «Tomas», Age = 38 >; using var response = await httpClient.PutAsJsonAsync(«https://localhost:7094/api/users/», tom); if (response.StatusCode == System.Net.HttpStatusCode.NotFound) < // если возникла ошибка, считываем сообщение об ошибке Error? error = await response.Content.ReadFromJsonAsync(); Console.WriteLine(error?.Message); > else if (response.StatusCode == System.Net.HttpStatusCode.OK) < // десериализуем ответ в объект Person Person? person = await response.Content.ReadFromJsonAsync(); Console.WriteLine($» — ()»); > > > record Error(string Message); class Person < public int Id < get; set;>public string Name < get; set; >= «»; public int Age < get; set; >>
Удаление данных
За удаление данных на сервере отвечает конечная точка
app.MapDelete(«/api/users/», (string id) => ..
То есть в Delete-запросе нам надо передать id удаляемого объекта. Для этого у HttpClient можно использовать метод DeleteFromJsonAsync() , который тиизируется типом удаляемого объекта, получает адрес удаляемого ресурса и возвращает удаленный объект:
using System.Net.Http.Json; class Program < static HttpClient httpClient = new HttpClient(); static async Task Main() < // id удаляемого объекта int Person? person = await httpClient.DeleteFromJsonAsync($»https://localhost:7094/api/users/»); Console.WriteLine($» — ()»); > > class Person < public int Id < get; set;>public string Name < get; set; >= «»; public int Age < get; set; >>
Однако если объекта с переданным id не окажется на сервере, веб-приложение возвратит статусный код 404 и сообщение об ошибке. Чтобы отловить эту ситуацию, можно использовать метод DeleteAsync() , который возвращает объект HttpResponseMessage:
using System.Net.Http.Json; class Program < static HttpClient httpClient = new HttpClient(); static async Task Main() < // id удаляемого объекта int using var response = await httpClient.DeleteAsync($»https://localhost:7094/api/users/»); if (response.StatusCode == System.Net.HttpStatusCode.NotFound) < // если возникла ошибка, считываем сообщение об ошибке Error? error = await response.Content.ReadFromJsonAsync(); Console.WriteLine(error?.Message); > else if (response.StatusCode == System.Net.HttpStatusCode.OK) < // десериализуем ответ в объект Person Person? person = await response.Content.ReadFromJsonAsync(); Console.WriteLine($» — ()»); > > > record Error(string Message); class Person < public int Id < get; set;>public string Name < get; set; >= «»; public int Age < get; set; >>
Источник: metanit.com