

Python часто ругают за то, что он медленный. Однако в нем существует несколько подходов, которые позволяют писать достаточно быстрый код. Сегодня поговорим про обработку списков.
TL;DR Используйте списковые включения (list comprehensions), генераторные выражения (generator expressions) и генераторы везде, где только можно. Это поможет сэкономить память и время выполнения программы.
Списковые включения (List comprehensions)
Например у нас есть большой список словарей (объявления контекстной рекламы):
import timeit import time import itertools import random now = time.time() ads_list = list( for i in range(1000000))
Зададим начальное время выборки и конечное
date_start = now — 60*60*24*7 date_end = now — 60*60*24*3
И попробуем выбрать все объявления, ставка которых выше 600 и дата попадает в выбранный интервал. Затем возьмем первые 1000 элементов полученного списка. Сначала решим задачу «в лоб»:
Как ускорить Python
def many_lists(): expensive_ads = [a for a in ads_list if a[’bid’] > 600] expensive_in_interval = [a for a in expensive_ads if a[’date’] > date_start and a[’date’]
Ок, попробуем немного оптимизировать и сделаем проверку даты там же, где и ставки:
def many_lists_improved(): expensive_ads = [a for a in ads_list if a[’bid’] > 600 and a[’date’] > date_start and a[’date’]
Уже лучше, но не сильно лучше.
Генераторные выражения (generator expressions)
Попробуем использовать генераторные выражения (для получения среза будем использовать функцию islice из itertools, которая возвращает итератор по срезу):
def generators(): expensive_ads = (a for a in ads_list if a[’bid’] > 600) expensive_in_interval = (a for a in expensive_ads if a[’date’] > date_start and a[’date’]
Итог: увеличение производительности более чем в 3 раза.
Генераторные фунции (generator functions)
Если предикатов фильтрации или обработчиков элементов списка много, то удобнее использовать генераторы. Они могут не дать прироста скорости, но помогут сэкономить память.
Генераторной фунцией в python называется функция, которая ведет себя как итератор. Для определения генераторной функции нужно использовать ключевое слово yield:
def count_five(): for i in range(5): yield i
Например у нас есть список кортежей (чтобы не было соблазна менять словарь на месте) с данными объявлений, и мы хотим выбрать все объявления из списка, попадающие в наш интервал, а также протэгировать по условиям ставки.
Попробуем для начала решить задачу в лоб и в каждой функции-обработчике возвращать новый список, а затем решим задачу с помощью генераторов:
import sys import time import random import psutil from timeit import timeit now = time.time() ads_list = list((1000000 — i, now — i, random.randint(1, 1000)) for i in range(1000000)) date_end = now — 60*60*24*3 date_start = now — 60*60*24*7 def below_3days(ad_list): return [a for a in ad_list if a[1] date_start] def tag_bid(ad_list): return [(a[0], a[1], a[2] > 500 and ’expensive’ or ’cheap’) for a in ad_list] def above_7days_gen(ad_list): for a in ad_list: if a[1] > date_start: yield a def below_3days_gen(ad_list): for a in ad_list: if a[1] 500 and ’expensive’ or ’cheap’ yield (a[0], a[1], tag) list_pipeline = lambda ads: below_3days(above_7days(tag_bid(ads))) gen_pipeline = lambda ads: below_3days_gen(above_7days_gen(tag_bid_gen(ads))) pipelines = < ’list’: list_pipeline, ’gen’: gen_pipeline >def run_pipeline(ad_list, pipeline): processed = pipeline(ad_list) return sorted(processed, key=lambda item: item[0]) if __name__ == ’__main__’: try: pipeline = pipelines[sys.argv[1]] except (IndexError, KeyError): print(’invalid arguments, use `list` or `gen` to choose pipeline’) sys.exit(1) process = psutil.Process() mem_before = process.memory_info().rss tm = timeit(lambda: run_pipeline(ads_list, pipeline), number=1) consumption = process.memory_info().rss — mem_before print(’consumption:’, consumption/1024, ’KB, in’, round(tm, 2), ’s’)
Запустим наш скрипт сначала с ключом list:
⚡ УСКОРЯЕМ PYTHON в 20 РАЗ! | Новый способ :3
python run_pipeline.py list consumption: 15568.0 KB, in 0.25 s
А потом с ключом gen:
python run_pipeline.py gen consumption: 6112.0 KB, in 0.25 s
Как можно увидеть, скорость выполнения не изменилась, но мы сэкономили память (почти трехкратная разница), потому что генераторы не создают новых списков, а обрабатывают один элемент за итерацию.
И напоследок
Не всегда операторы в python ведут себя так, как мы привыкли. Например сложение списков:
def plus(): list1 = list(range(1000000)) list2 = list(range(1000000)) list1 = list1 + list2 return list1 def plus_eq(): list1 = list(range(1000000)) list2 = list(range(1000000)) list1 += list2 return list1 timeit.timeit(plus, number=10) 0.4108163330001844 timeit.timeit(plus_eq, number=10) 0.3518642500000624
Посмотрим дизассемблером, что происходит внутри этих функций:
import dis dis.dis(plus) 2 0 LOAD_GLOBAL 0 (list) 2 LOAD_GLOBAL 1 (range) 4 LOAD_CONST 1 (1000000) 6 CALL_FUNCTION 1 8 CALL_FUNCTION 1 10 STORE_FAST 0 (list1) 12 LOAD_GLOBAL 0 (list) 14 LOAD_GLOBAL 1 (range) 16 LOAD_CONST 1 (1000000) 18 CALL_FUNCTION 1 20 CALL_FUNCTION 1 22 STORE_FAST 1 (list2) 24 LOAD_FAST 0 (list1) 26 LOAD_FAST 1 (list2) 28 BINARY_ADD 30 STORE_FAST 0 (list1) 32 LOAD_FAST 0 (list1) 34 RETURN_VALUE dis.dis(plus_eq) 2 0 LOAD_GLOBAL 0 (list) 2 LOAD_GLOBAL 1 (range) 4 LOAD_CONST 1 (1000000) 6 CALL_FUNCTION 1 8 CALL_FUNCTION 1 10 STORE_FAST 0 (list1) 12 LOAD_GLOBAL 0 (list) 14 LOAD_GLOBAL 1 (range) 16 LOAD_CONST 1 (1000000) 18 CALL_FUNCTION 1 20 CALL_FUNCTION 1 22 STORE_FAST 1 (list2) 24 LOAD_FAST 0 (list1) 26 LOAD_FAST 1 (list2) 28 INPLACE_ADD 30 STORE_FAST 0 (list1) 32 LOAD_FAST 0 (list1) 34 RETURN_VALUE
Как видно, инструкция 28 в случае `+` простое сложение, а в случае `+=` — сложение на месте, которое не приводит к созданию нового списка. += в данном случае сопоставим по производительности с list.extend:
def extend(): list1 = list(range(1000000)) list2 = list(range(1000000)) list1.extend(list2) return list1 timeit.timeit(extend, number=10) 0.3511457080001037
Заключение
Генераторы и итераторы помогают сэкономить память или время выполнения, но у них есть и особенности, из-за которых они могут не подойти. Например, по генераторам можно итерироваться только один раз, в отличие от списков.
Выводы
На примерах выше мы увидели, что python предоставляет нам некоторую возможность для маневра при обработке списков, главное знать об этих возможностях и использовать их там, где они подходят.
Источник: uproger.com
Как ускорить код на Python в тысячу раз

В любых соревнованиях по скорости выполнения программ Python обычно занимает последние места. Кто-то говорит, что это из-за того, что Python является интерпретируемым языком. Все интерпретируемые языки медленные. Но мы знаем, что Java тоже язык такого типа, её байткод интерпретируется JVM. Как показано, в этом бенчмарке, Java намного быстрее, чем Python.
Вот пример, способный показать медленность Python. Используем традиционный цикл for для получения обратных величин:
import numpy as np np.random.seed(0) values = np.random.randint(1, 100, size=1000000) def get_reciprocal(values): output = np.empty(len(values)) for i in range(len(values)): output[i] = 1.0/values[i] %timeit get_reciprocal(values)
3,37 с ± 582 мс на цикл (среднее значение ± стандартное отклонение после 7 прогонов по 1 циклу)
Ничего себе, на вычисление всего 1 000 000 обратных величин требуется 3,37 с. Та же логика на C выполняется за считанные мгновения: 9 мс; C# требуется 19 мс; Nodejs требуется 26 мс; Java требуется 5 мс(!), а Python требуется аж целых 3,37 СЕКУНДЫ. (Весь код тестов приведён в конце).
Первопричина такой медленности
Обычно мы называем Python языком программирования с динамической типизацией. В программе на Python всё представляет собой объекты; иными словами, каждый раз, когда код на Python обрабатывает данные, ему нужно распаковывать обёртку объекта. Внутри цикла for каждой итерации требуется распаковывать объекты, проверять тип и вычислять обратную величину. Все эти 3 секунды тратятся на проверку типов.
В отличие от традиционных языков наподобие C, где доступ к данным осуществляется напрямую, в Python множество тактов ЦП используется для проверки типа.

Даже простое присвоение числового значения — это долгий процесс.
a = 1
Шаг 1. Задаём a->PyObject_HEAD->typecode тип integer
Шаг 2. Присваиваем a->val =1
Подробнее о том, почему Python медленный, стоит прочитать в чудесной статье Джейка: Why Python is Slow: Looking Under the Hood
Итак, существует ли способ, позволяющий обойти проверку типов, а значит, и повысить производительность?
Решение: универсальные функции NumPy
В отличие list языка Python, массив NumPy — это объект, созданный на основе массива C. Доступ к элементу в NumPy не требует шагов для проверки типов. Это даёт нам намёк на решение, а именно на Universal Functions (универсальные функции) NumPy, или UFunc.

Если вкратце, благодаря UFunc мы можем проделывать арифметические операции непосредственно с целым массивом. Перепишем первый медленный пример на Python в версию на UFunc, она будет выглядеть так:
import numpy as np np.random.seed(0) values = np.random.randint(1, 100, size=1000000) %timeit result = 1.0/values
Это преобразование не только повышает скорость, но и укорачивает код. Отгадаете, сколько теперь времени занимает его выполнение? 2,7 мс — быстрее, чем все упомянутые выше языки:
2,71 мс ± 50,8 мкс на цикл (среднее значение ± стандартное отклонение после =7 прогонов по 100 циклов каждый)
Вернёмся к коду: самое важное здесь — это 1.0/values . values — это не число, а массив NumPy. Наряду с оператором деления есть множество других.
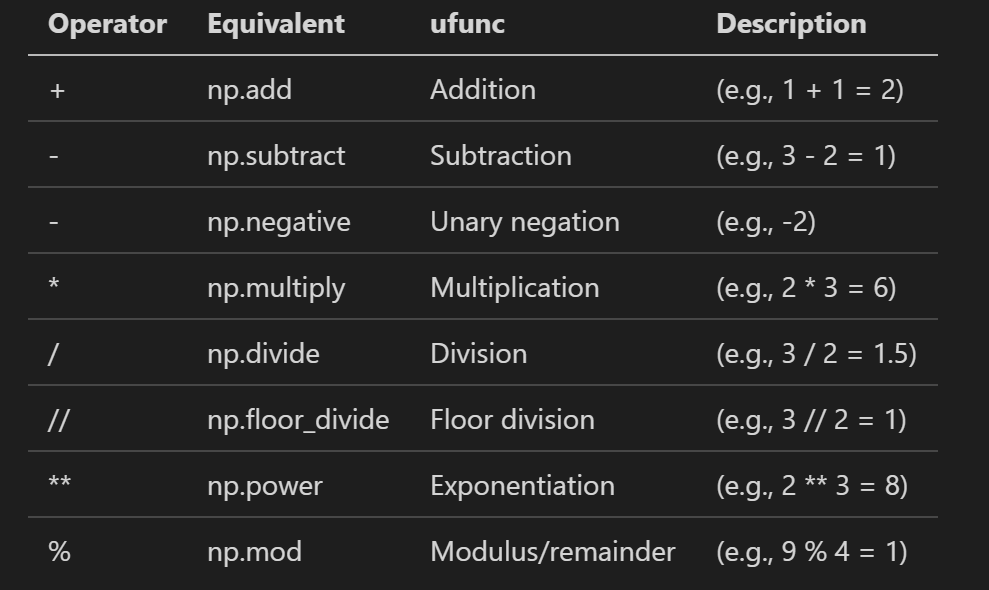
Здесь можно найти все операторы Ufunc.
Подводим итог
Если вы пользуетесь Python, то высока вероятность того, что вы работаете с данными и числами. Эти данные можно хранить в NumPy или DataFrame библиотеки Pandas, поскольку DataFrame реализован на основе NumPy. То есть с ним тоже работает Ufunc.
UFunc позволяет нам выполнять в Python повторяющиеся операции быстрее на порядки величин. Самый медленный Python может быть даже быстрее языка C. И это здорово.
Приложение — код тестов на C, C#, Java и NodeJS
#include #include #include int main() < struct timeval stop, start; int length = 1000000; int rand_array[length]; float output_array[length]; for(int i = 0; igettimeofday( for(int i = 0; i gettimeofday( printf(«took %lu usn», (stop.tv_sec — start.tv_sec) * 1000000 + stop.tv_usec — start.tv_usec); printf(«donen»); return 0; >
using System; namespace speed_test < class Program< static void Main(string[] args)< int length = 1000000; double[] rand_array =new double[length]; double[] output = new double[length]; var rand = new Random(); for(int i =0; ilong start = DateTimeOffset.Now.ToUnixTimeMilliseconds(); for(int i =0;i long end = DateTimeOffset.Now.ToUnixTimeMilliseconds(); Console.WriteLine(end — start); > > >
import java.util.Random; public class speed_test < public static void main(String[] args)< int length = 1000000; long[] rand_array = new long[length]; double[] output = new double[length]; Random rand = new Random (); for(int i =0; ilong start = System.currentTimeMillis(); for(int i = 0;i long end = System.currentTimeMillis(); System.out.println(end — start); > >
let length = 1000000; let rand_array = []; let output = []; for(var i=0;i let start = (new Date()).getMilliseconds(); for(var i=0;i let end = (new Date()).getMilliseconds(); console.log(end — start);
На правах рекламы
Воплощайте любые идеи и проекты с помощью наших VDS с мгновенной активацией на Linux или Windows. Создавайте собственный конфиг в течение минуты!
Источник: temofeev.ru
Как можно ускорить Python сегодня

2022-12-31 в 10:00, admin , рубрики: cupy, gpgpu, gpu, intel, numba, python, ruvds_перевод, scikit-learn, Блог компании RUVDS.com, многопоточность, ускорители вычислений

Python не перестаёт удивлять многих своей гибкостью и эффективностью. Лично я являюсь приверженцем С и Fortran, а также серьёзно увлекаюсь C++, поскольку эти языки позволяют добиться высокого быстродействия. Python тоже предлагает такие возможности, но дополнительно выделяется удобством, за что я его и люблю.
- Почему столь важно думать о «будущем разнородных вычислений».
- Две ключевых сложности, которые необходимо преодолеть в открытом решении.
- Параллельное выполнение задач для более эффективного задействования CPU.
- Использование ускорителя для дополнительного повышения быстродействия.
Один только третий пункт позволил увеличить быстродействие в 12 раз притом, что четвёртый позволяет добиться ещё большего за счёт ускорителя. Эти простые техники могут оказаться бесценными при работе с Python, когда требуется добиться дополнительного ускорения программы. Описанные здесь приёмы позволяют нам уверенно продвигаться вперёд без длительного ожидания результатов.
Размышляя о будущем разнородных вычислений
Несмотря на то, что понимание разнородности не особо важно, если нас интересует лишь ускорение кода Python, стоит отметить значительный сдвиг, который сейчас наблюдается в сфере вычислительных наук. Компьютеры с каждым годом становятся все быстрее. Поначалу этот прирост производительности обеспечивали грамотные и более сложные архитектуры. Затем где-то в период между 1989 и 2006 годами основным ускоряющим фактором стала растущая тактовая частота. Однако в 2006 её увеличение вдруг перестало иметь смысл, и для повышения скорости снова потребовалось изменение архитектур.
В результате многоядерные процессоры обеспечили повышенное быстродействие за счёт увеличения количества (однородных) ядер в процессоре. В отличие от повышения частот получение дополнительного ускорения за счёт многоядерности потребовало перестройки ПО. Классическая статья Херба Саттера «The Free Lunch Is Over» акцентировала потребность в многопоточности. И хотя этот сдвиг был необходим, он существенно усложнил жизнь разработчикам программного обеспечения.
Затем появились ускорители, способные выполнять вычисления в дополнение к CPU. Наиболее успешными из них пока что являются графические процессоры (GPU). Изначально GPU были разработаны для разгрузки основного процессора путём снятия с него задачи по обработке графики, передаваемой на дисплей компьютера.
Для задействования этой дополнительной вычислительной мощности появилось несколько программных моделей, но вместо отправки на дисплей их результаты передавались программе, выполняющейся на CPU. Сегодня «разнородные» процессоры в одной системе больше не являются равноценными. Тем не менее все популярные языки программирования обычно предполагают одно вычислительное устройство, поэтому, когда мы выбираем часть кода для выполнения на отдельном таком устройстве, то используем термин «разгрузка».
Несколько лет назад два легендарных представителя индустрии, Джон Хеннеси и Дэвид Паттерсон, заявили о вступлении в «A New Golden Age for Computer Architecture» (новый золотой век компьютерной архитектуры). Разнородные вычисления начинают набирать обороты благодаря появлению множества идей для специализированных под разные области процессоров. Некоторые эти тенденции ждёт успех, другие же обречены на провал, но суть в том, что сфера вычислений изменилась бесповоротно, поскольку больше не ориентирована на выполнение всех вычислений на одном устройстве.
Две ключевых сложности, преодолеваемые одним хорошим решением
И хотя сегодня популярна технология CUDA, она относится лишь к GPU Nvidia. Нам же нужны открытые решения для обработки целой волны новых архитектур ускорителей от различных вендоров. Программам, выполняющимся на разнородных платформах, необходим способ определения доступных в среде выполнения устройств. Им также нужен способ снять с этих устройств нагрузку.
CUDA игнорирует возможность обнаружения устройств, предполагая, что доступны только GPU Nvidia. Python-программистам для использования GPU с CUDA (Nvidia) или ROCm (AMD) доступна библиотека CuPy. Но хоть CuPy и является открытым решением, она не повышает быстродействие CPU и не охватывает других производителей или архитектуры. Нам бы больше подошла программа с возможностью использования на устройствах разных вендоров и поддержкой новых аппаратных решений. Однако, прежде чем радоваться разгрузке с помощью ускорителя, давайте убедимся, что получаем максимум от нашего CPU, так как понимание принципов использования параллелизма и скомпилированного кода также поможет разобраться с использованием многопоточности на ускорителях.
Numba является открытым JIT-компилятором кода Python и NumPy, разработанным Anaconda. Он может компилировать всевозможный численный код Python, включая многие функции NumPy. Numba также поддерживает автоматическое распараллеливание циклов, генерацию ускоряемого GPU кода, создание универсальных функций ( ufuncs ) и обратных вызовов Си.
- Неявные распараллеливаемые области, такие как выражения массивов NumPy, NumPy ufunc и функции редукции NumPy.
- Явные циклы параллельных данных, определяемые с помощью выражения numba.prange .
Вот пример простого цикла Python:
def f1(a,b,c,N): for i in range(N): c[i] = a[i] + b[i]
Его можно сделать явно параллельным, изменив последовательный диапазон ( range ) на параллельный ( prange ) и добавив директиву njit :
В итоге время выполнения сократилось с 24.3 до 1.9 секунды, но результаты от системы к системе могут отличаться. Чтобы опробовать этот приём, клонируйте репозиторий с образцами oneAPI (git clone) и откройте блокнот AI-and-Analytics/Jupyter/Numba_DPPY_Essentials_training/Welcome.ipynb. Проще всего сделать это, зарегистрировав бесплатный аккаунт на Intel® DevCloud for oneAPI.
Дополнительное повышение быстродействия с помощью ускорителя
Ускоритель оказывается особенно эффективен, когда приложение загружено достаточным объёмом работы, чтобы её разгрузка оправдала необходимые для этого затраты. Первым шагом мы компилируем выбранные вычисления (фрагмент программы), чтобы их можно было разгрузить на другие устройства. Продолжая предыдущий пример, мы используем расширения Numba (numba-dpex) для обозначения разгружаемого фрагмента программы (подробнее читайте в Jupyter notebook training).
Аргументами для фрагмента программы могут выступать массивы NumPy или массивы унифицированной разделяемой памяти (USM) (тип массивов, явно помещаемых в унифицированную разделяемую память), в зависимости от того, что больше соответствует нашим потребностям. Этот выбор повлияет на настройку данных и активацию фрагментов программы.
Далее мы задействуем решение C++ для открытого мультивендорного и мультиархитектурного программирования под названием SYCL, используя опенсорсную библиотеку dpctl (подробнее читайте в документации GitHub и «Interfacing SYCL and Python for XPU Programming»). Эта библиотека позволяет программам Python обращаться к устройствам SYCL, очередям и источникам памяти, а также выполнять операции с массивами/тензорами Python. Такой подход позволяет избежать изобретения новых решений, уменьшить потребность в освоении новых техник и повысить совместимость.
Подключение к устройству выполняется просто:
device = dpctl.select_default_device() print(«Using device . «) device.print_device_info()
Дефолтное устройство можно установить с помощью переменной среды SYCL_DEVICE_FILTER , если мы хотим контролировать выбор устройства без изменения этой простой программы. Библиотека dpctl также поддерживает программное управление для анализа и выбора доступного устройства на основе свойств аппаратного обеспечения.
Фрагмент программы также можно активировать (перенести и выполнить) на устройстве буквально парой строк кода:
with dpctl.device_context(device): dpar_add[global_size,dppy.DEFAULT_LOCAL_SIZE](a,b,c)
Использование device_context приводит к тому, что среда выполнения создаёт все необходимые копии данных (наши данные по-прежнему находились в стандартных массивах NumPy). Кроме этого, dpctl предлагает возможность явного выделения USM-памяти для устройств и управления ею. Это особенно пригождается, когда при углублении в оптимизацию возникают сложности с поручением её обработки для стандартных массивов NumPy среде выполнения.
Асинхронность и синхронность
Написание кода в стиле Python легко поддерживается описанными выше синхронными механизмами. При этом, если мы готовы слегка изменить код, перед нами также открываются асинхронные возможности и сопутствующие им преимущества (сокращение или исключение задержек при перемещении данных и активации фрагментов кода). Подробнее об асинхронном выполнении можете узнать из примера кода в dpctl gemv.
А что насчёт CuPy?
Библиотека CuPy является NumPy/SciPy-совместимой библиотекой, позволяющей выполнять их код на платформах Nvidia CUDA или AMD ROCm. Однако серьёзные усилия, необходимые для повторной реализации CuPy под новые платформы, существенно мешают обеспечить мультивендорную поддержку в одной программе Python, так что две вышеупомянутых сложности она не решает. CuPy может выбирать только среди GPU-устройств с CUDA. При этом она не даёт возможности прямого контроля памяти, хотя и может автоматически выполнять её пулинг с целью сокращения числа вызовов cudaMalloc . При переносе выполнения кода она не позволяет выбирать для этого устройство и в случае отсутствия доступного GPU с CUDA даст сбой. Большую универсальность для приложения можно достичь за счёт использования более удобного инструмента, решающего указанные сложности, связанные с разнородностью устройств.
А что насчёт scikit-learn?
В целом программирование на Python отлично подходит для реализации вычислений, направленных на конкретные данные (методика «compute-follows-data»). Библиотека dpctl поддерживает тензоры, которые мы связываем с заданным устройством. Если мы в своей программе можем привести данные к тензору для устройства (например, dpctl.tensor.asarray(data, device=»gpu:0″) ), они будут ассоциированы с этим устройством и помещены на него. При использовании пропатченной версии scikit-learn, способной распознавать эти тензоры, задействующие такой тензор методы вычисляются на связанном устройстве автоматически.
Это прекрасный вариант использования динамической типизации в Python, позволяющий понять, где располагаются данные, и направить вычисления именно туда. Единственное, что изменяется в нашем коде Python – это место, где наши тензоры преобразуются в тензоры для устройства. Судя по текущим отзывам, мы ожидаем, что методика «compute-follows-data» станет наиболее популярной среди Python-программистов.
Открытость, мультивендорность и мультиархитектурность
Python может выполнять роль инструмента, объединяющего мощность аппаратного разнообразия и позволяющего задействовать потенциал надвигающегося «Кембрийского взрыва» в сфере ускорителей. Здесь стоит иметь ввиду использование распараллеливания данных через Numba совместно с dpctl и техниками «compute-follows-data» из scikit-learn, поскольку все эти решения не ограничены какими-либо вендорами или архитектурами.
При том, что Numba предоставляет отличную поддержку для NumPy, в перспективе будет нелишним рассмотреть дополнительные возможности для SciPy и прочих направлений программирования на Python. Фрагментация API массивов в Python подтолкнула к стандартизации этих API (подробнее читайте здесь) на фоне возникшего стремления разработчиков разделять рабочие нагрузки с устройствами, помимо CPU. Стандарт API массивов во многом помогает расширить область применения Numba и dpctl, а также их влияние. В NumPy и CuPy поддержка API массивов уже внедрена, и на очереди стоят dpctl с PyTorch. По мере охвата всё большего числа библиотек, реализация поддержки разнородных вычислений (ускорителей всех типов) становится всё доступнее.
Простого использования dpctl.device_context оказывается недостаточно в более сложном коде Python со множеством потоков или асинхронных задач (вот соответствующая тема на GitHub). Здесь будет лучше следовать политике «compute-follows-data», по крайней мере в сложном многопоточном коде Python. Этот подход может стать предпочтительным в сравнении с использованием device_context .
Перед нами есть масса возможностей по оптимизации способов повышения быстродействия Python. Все эти решения являются опенсорсными и на сегодня работают очень хорошо.
Дополнительные материалы
Самое лучшее обучение – это практика. Ну а чтобы было проще начать, ниже я привожу некоторые полезные вспомогательные источники информации.
Для Numba и dpctl есть 90-минутное видео, в котором разбираются описанные выше принципы: «Data Parallel Essentials for Python».
Ещё есть прекрасное видео «Losing your Loops Fast Numerical Computing with NumPy» от Джейка Вандерпласа (автора «Python Data Science Handbook»), где он рассказывает о способах эффективного использования NumPy.
Все описанные в данной статье решения для использования Python в сфере разнородных вычислений являются опенсорсными и по умолчанию включены в наборы инструментов Intel® oneAPI Base и Intel® AI Analytics. NumPy с поддержкой SYCL размещена на GitHub. Расширения компилятора Numba для выделения фрагмента программы и автоматического переноса соответствующей вычислительной нагрузки также находятся на GitHub. Что касается открытых инструментов для управления распараллеливанием данных, то по этой теме доступна документация на GitHub и исследовательская работа «Interfacing SYCL and Python for XPU Programming». Они позволяют программам Python обращаться к устройствам SYCL, очередям, памяти, а также выполнять операции с массивами/тензорами, используя ресурсы SYCL.
Помимо этого, в них реализована обработка исключений, включая асинхронные ошибки в коде устройств. Эти ошибки перехватываются при повторном выбрасывании в виде синхронных исключений соответствующими функциями-обработчиками. Это поведение обеспечивается генераторами расширений Python и хорошо описано в документации сообщества: Cython и Pybind11.
▍ P.S. от переводчика
Уважаемые читатели, поздравляю вас с наступающим Новым годом! По всей видимости, он будет не менее ярким, чем уходящий, и с учётом такого положения дел хочется пожелать всем конструктивной оптимизации жизни и успешной адаптации под быстроменяющиеся реалии. Пусть спутниками в этом процессе для вас станут стойкость, оптимизм и простая взаимная человеческая любовь, которой в нашей чувственной палитре мира стало явно нехватать. Балансируя на правильной смеси этих трёх компонентов, будет куда проще как преодолевать сложности, так и покорять новые вершины.
Отдельно хочу выразить признательность всем постоянным читателям, в особенности тем, кто помогает повышать качество публикуемых мной материалов с помощью объективной критики, рекомендаций и банального указания на ошибки. Я осознаю неполноту своих знаний и стремлюсь при каждой возможности их расширить. Спасибо вам и Всех Благ!
Источник: www.pvsm.ru