
Оптимизация кода — различные методы преобразования кода ради улучшения его характеристик и повышения эффективности. Среди целей оптимизации можно указать уменьшения объема кода, объема используемой программой оперативной памяти, ускорение работы программы, уменьшение количества операций ввода-вывода.
Главное из требований, которые обычно предъявляются к методу оптимизации — оптимизированная программа должна иметь тот же результат и побочные эффекты на том же наборе входных данных, что и неоптимизированная программа. Впрочем, это требование может и не играть особой роли, если выигрыш за счет использования оптимизации может быть сочтен более важным, чем последствия от изменения поведения программы.
Виды оптимизации
Оптимизация кода может проводиться как и вручную, программистом, так и автоматизированно. В последнем случае оптимизатор может быть как отдельным программным средством, так и быть встроенным в компилятор (т.н. оптимизирующий компилятор). Кроме того, следует отметить, что современные процессоры могут оптимизировать порядок выполнения инструкций кода.
Оптимизация реестра — Мифы и Реальность. Все об оптимизации ПК
Существуют такие понятия как высокоуровневая и низкоуровневая оптимизация. Высокоуровневые оптимизации в большинстве проводятся программистом, который, оперируя абстрактными сущностями (функциями, процедурами, классами и т.д.) и представляя себе общую модель решения задачи, может оптимизировать дизайн системы.
Оптимизации на уровне элементарных структурных блоков исходного кода (циклов, ветвлений и т.д.) тоже обычно относят к высокому уровню; некоторые выделяют их в отдельный («средний») уровень (Н. Вирт?). Низкоуровневая оптимизация производится на этапе превращения исходного кода в набор машинных команд, и зачастую именно этот этап подвергается автоматизации. Впрочем, программисты на ассемблере считают, что никакая машина не превзойдет в этом хорошего программиста (при этом все согласны, что плохой программист сделает еще хуже и машины).
Выбор оптимизируемого участка
При оптимизации кода вручную существует еще одна проблема: нужно знать не только, каким образом проводить оптимизацию, но и в каком месте её применить. Обычно из-за разных факторов (медленные операции ввода, разница в скорости работы человека-оператора и машины и т.д.) лишь 10% кода занимают целых 90% времени выполнения (конечно, утверждение довольно умозрительно, и имеет сомнительное основание в виде закона Парето, однако выглядит довольно убедительно у Э. Таненбаума). Так как на оптимизацию придется расходовать дополнительное время, поэтому вместо попыток оптимизации всей программы лучше будет оптимизировать эти «критичные» ко времени выполнения 10%. Такой фрагмент кода называют узким местом или бутылочным горлышком (bottleneck), и для его определения используют специальные программы — профайлеры, которые позволяют замерять время работы различных частей программы.
На самом деле, на практике оптимизация зачастую проводится после этапа «хаотического» программирования (включающего такие вещи, как «копипаст», «потом разберемся», «и так сойдет»), поэтому представляет собой смесь из собственно оптимизации, рефакторинга и исправления ошибок: упрощение «причудливых» конструкций – вроде strlen(path.c_str()), логических условий (a.x != 0 a.x != 0) и т.п. Для таких оптимизаций профайлеры вряд ли пригодны. Однако для обнаружения таких мест можно использовать программы статического анализа — средства поиска семантических ошибок на основе глубокого анализа исходного кода – ведь, как видно из второго примера, неэффективный код может быть следствием ошибок (как, например, опечатки в данном примере — скорее всего, имелось ввиду a.x != 0 a.y != 0). Хороший статический анализатор обнаружит подобный код, и выведет предупреждающее сообщение.
Удаление программ с компьютера. Все об оптимизации ПК
Вред и польза оптимизаций
Практически ко всему в программировании надо относиться рационально, и оптимизации — не исключение. Считается, что неопытный программист на ассемблере обычно пишет код, который в 3-5 раз медленнее, чем код, сгенерированный компилятором (Зубков). Широко известно выражение по поводу ранних, довольно низкоуровневых (вроде борьбы за лишний оператор или переменную) оптимизаций, сформулированное Кнутом: «Преждевременная оптимизация — это корень всех бед».
К оптимизациям, проводимым оптимизатором, у большинства нет претензий, причем иногда некоторые оптимизации являются практически стандартными и обязательными — например, оптимизация хвостовой рекурсии в функциональных языках (Хвостовая рекурсия — частный вид рекурсии, который может быть приведен к виду цикла).
Однако следует понимать, что многочисленные сложные оптимизации на уровне машинного кода могут сильно замедлить процесс компиляции. Причем выигрыш от них может быть чрезвычайно мал по сравнению с оптимизациями общего дизайна системы (Вирт). Также не следует забывать, что современные, «навороченные» синтаксически и семантически языки имеют множество тонкостей, и программист, который их не учитывает, может быть удивлен последствиями оптимизации.
Например, рассмотрим язык Си++ и т.н. Return-Value Optimization, суть которой в том, что компилятор может не создавать копии возвращаемого функцией временного объекта. Так как в этом случае компилятор «пропускает» копирование, этот прием также называется «Copy elision». Итак, следующий код:
#include struct C < C() <>C(const C std::cout >; C f() < return C(); >int main()
может иметь несколько вариантов вывода:
Hello World! A copy was made. A copy was made. Hello World! A copy was made. Hello World!
Как ни странно, все три варианта являются законными, так как в стандарте языка позволяется пропускать вызов копирующего конструктора в данном случае, даже если у конструктора есть побочные эффекты (§12.8 Копирование объектов класса, пункт 15).
Итог
Таким образом, не стоит забывать проводить оптимизацию кода, по возможности применяя специализированные программные средства, но это следует делать аккуратно и с осторожностью, а иногда и приготовиться к неожиданностям от компилятора.
PVS-Studio
В статическом анализаторе PVS-Studio реализован набор диагностик, позволяющих обнаруживать некоторые ситуации, когда код может быть оптимизирован. Однако PVS-Studio, как и любой статический анализатор, не может выступать в качестве замены инструментов профилирования. Выявить узкие места могут только динамические анализаторы программ. Статические анализаторы не знают, какие входные данные получают программы и как часто выполняется тот или иной участок кода. Поэтому мы и говорим, что анализатор предлагает выполнить некоторые «микро оптимизации» кода, которые вовсе не гарантируют прироста производительности.
Несмотря на рассмотренный недостаток, анализатор PVS-Studio может выступать хорошим дополнением к инструментам профилирования. Более того, при работе с предупреждениями PVS-Studio, касающимися оптимизации, код часто становится проще и короче. Более подробно этот эффект рассмотрен в статье «Поговорим о микрооптимизациях на примере кода Tizen».
Библиографический список
- Э. Таненбаум. Архитектура компьютера.
- Вирт Н. Построение компиляторов.
- Кнут Д. Искусство программирования, том 1. Основные алгоритмы.
- Зубков С.В. Assembler для DOS, Windows и UNIX.
- Wikipedia. Code optimization.
- Wikipedia. Оптимизирующий компилятор.
- Wikipedia. Copy elision.
- Wikipedia. Return value optimization.
Источник: pvs-studio.ru
Оптимизации в компиляторах. Часть 1
Копаясь в дебрях LLVM, я неожиданно обнаружил для себя: насколько всё же интересная штука — оптимизация кода. Поэтому решил поделиться с вами своими наблюдениями в виде серии обзорных статей про оптимизации в компиляторах. В этих статьях я попытаюсь «разжевать» принципы работы оптимизаций и обязательно рассмотреть примеры.
Я попытаюсь выстроить оптимизации в порядке возрастания «сложности понимания», но это исключительно субъективно.
И ещё: некоторые названия и термины не являются устоявшимися и их используют «кто-как», поэтому я буду приводить несколько вариантов, но настоятельно рекомендую использовать именно англоязычные термины.
Вступление
(совсем немного теории о типах оптимизаций, которую можно пропустить)
Прежде чем мы погрузимся в великолепные идеи и алгоритмы давайте немного поскучаем над теорией: разберёмся что такое оптимизации, для чего нужны и какими они бывают или не бывают.
Для начала дадим определение (из википедии):
Оптимизация программного кода — это модификация программ, выполняемая оптимизирующим компилятором или интерпретатором с целью улучшения их характеристик, таких как производительности или компактности, — без изменения функциональности.
Последние три слова в этом определении очень важны: как бы не улучшала оптимизация характеристики программы, она обязательно должна сохранять изначальный смысл программы при любых условиях. Именно поэтому, например, в GCC существуют различные уровни оптимизации (настоятельно рекомендую сходить по этим ссылкам).
Идём дальше: оптимизации бывают машинно-независимыми (высокоуровневыми) и машинно-зависимыми (низкоуровневыми). Смысл классификации понятен из названий, в машинно-зависимых оптимизациях используются особенности конретных архитектур, в высокоуровневых оптимизация происходит на уровне структуры кода.
Оптимизации также могут классифицироваться в зависимости от области их применения на локальные (оператор, последовательность операторов, базовый блок), внутрипроцедурные, межпроцедурные, внутримодульные и глобальные (оптимизация всей программы, «оптимизация при сборке», «Link-time optimization»).
Чую, что вы сейчас уснёте, давайте закончим на этом порцию теоиии и приступим уже к рассмотрению самих оптимизаций…
Constant folding
(Свёртывание/Свёртка констант)
Самая простейшая, самая известная и самая распространённая оптимизация в компиляторах. Процесс «свёртки констант» включает в себя поиск выражений (или подвыражений), включающих ТОЛЬКО константы. Такие выражения вычисляются на этапе компиляции и в результирующем коде «сворачиваются» в вычисленное значение.
#include int main(int argc, char **argv) < struct point < int x; int y; >p;
int a = 32*32; int b = 32*32*4;
long int c;
// c = (a + b) * (4*4*sizeof(p) — 2 + 32);
return 0; >
#include int main(int argc, char **argv) < struct point < int x; int y; >p;
int a = 1024; // Свёрнуто из 32 * 32 int b = 4096; // Свёрнуто из 32 * 32 * 4
long int c;
// 16 = 4*4, 30 = -2 + 32 c = (a + b) * (16*sizeof(p) + 30);
return 0; >
. c = (a + b) * (16*8 + 30); .
. c = (a + b) * 158; .
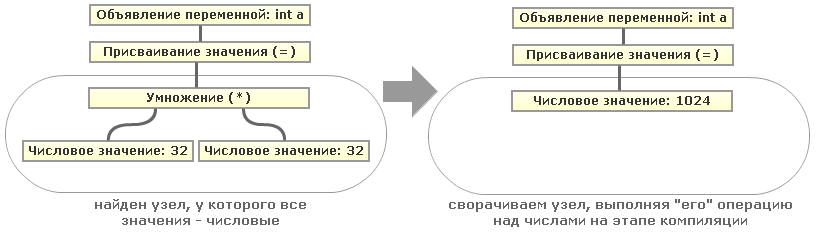
То есть рекурсивным обходом нашего дерева AST мы можем свернуть все подобные константные выражения. Кстати пример с числами опять же упрощён, вместо операций с числами вполне могут быть операции со строками (конкатенация) или операции со строками и числами (аналог python’овского » ‘-‘ * 10 «) или константами любых других типов данных, поддерживаемых исходным языком программирования.
Constant propagation
(Распространение констант)
#include int main(int argc, char **argv) < struct point < int x; int y; >p;
int a = 1024; int b = 4096;
long int c;
// c = (a + b) * 94;
return 0; >
#include int main(int argc, char **argv) < struct point < int x; int y; >p;
int a = 1024; int b = 4096;
long int c;
// c = (1024 + 4096) * 94 c = 481280;
return 0; >
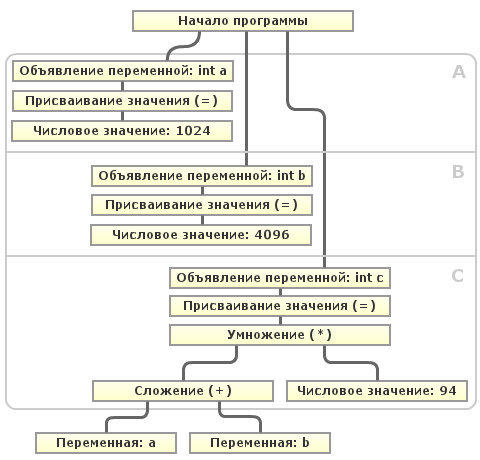
Допустим, что компилятор при очередном проходе оптимизации обнаруживает использование переменных «a» и «b» . Как видно из схемы, после объявления переменной «a» в блоке A и переменной «b» в блоке B, ни одна, ни другая переменная не могут изменить значение в последующих блоках (A,B,C) перед их использованием. Этот случай тривиален, так как вся программа линейна и представляет из себя так называемый Базовый блок (BB).
Но алгоритм определения «изменяемости» переменной в базовом блоке это ещё далеко не всё. Программа может включать условные конструкции, циклы, безусловные переходы и т.д. Тогда для определения «изменяемости» переменной необходимо построить направленный граф с базовыми блоками в вершинах, рёбра — передача управления между базовыми блоками.
Такой граф называется Графом потока управления (CFG) и применяется для осуществления многих оптимизаций. В таком графе можно определить все базовые блоки, которые необходимо пройти от инициализации переменной до её использования и определить для каждого блока, может ли в нём измениться значение переменной. В случае невозможности его изменения, компилятор легко может заменить её значение константой.
«Constant propagation» и «Constant folding» обычно прогоняются несколько раз, пока не перестанут вносить какие-либо изменения в код программы.
Copy propagation
(Распространение копий)
int calc(int x, int y)
int a = x; int b = y; return a * a + b * b;
int calc(int x, int y)
Источник: habr.com