
Протокол выполнения программы
Пусть дана программа (S, I). Пара и = (1, W), где 1 — метка вершины схемы S, a W — состояние ее памяти, называется конфигурацией данной программы. Выполнение программы можно описать в виде последовательности конфигураций. Эта последовательность называется протоколом выполнения программы.
Протокол строится следующим образом. Пусть дана последовательность конфигураций (uo, иь. , щ, ui+i, . ) для программы (S, I). Будем обозначать i-ю конфигурацию протокола как uj = (кь Wj), где kj — соответствующая данной конфигурации метка вершины, а W; — состояние памяти. Тогда начальному состоянию памяти схемы S при интерпретации I соответствует конфигурация uo = (О, W0).
Рассмотрим некоторую i-ю конфигурацию протокола. Пусть О — оператор схемы S, находящийся в вершине с меткой ks.
Если О — заключительный оператор stop(ib. тп), то протокол конечен, и Uj — последняя его конфигурация. Программа (S, I) останавливается, а последовательность значений 1ц (Wj), т21 (W;). тп1 (Wj) называется результатом выполнения программы.
Как работает интернет? Протоколы HTTP/HTTPS, FTP. Хостинг. Для самых маленьких.
Если О не является заключительным оператором, то в протоколе существует следующая конфигурация: ui+i = (ki+b Wi+i). Здесь возможны следующие варианты:
- 1. О — начальный оператор с выходящей дугой, ведущей к вершине с меткой 1. Тогда kj+i = 1, a Wi+i = Wj.
- 2. О — оператор присваивания х:=т с выходящей дугой, веду-
щей к метке 1. Тогда kj+i = 1, Wj+1 =Wi, Wi+1(x) = Т[ (Wj), т.е. в состоянии
памяти произошло единственное изменение — переменная х получила новое значение.
- 3. О — условный оператор, для которого выполнено щ (Wj) = А (А е ), а соответствующая А выходящая дуга ведет к вершине с меткой 1 (т.е. при данной конфигурации проверка теста к приводит к переходу к вершине с меткой 1). Тогда ki+! = 1, a Wi+I = Wj.
- 4. О — оператор петли. Тогда ki+i = kb Wi+i = Wi? и протокол бесконечен.
Программа останавливается тогда и только тогда, когда протокол ее выполнения конечен. Иначе она зацикливается, и результат ее выполнения не определен.
В качестве примера рассмотрим протокол выполнения программ Pj и Р2 из табл. 6.1.
Вначале зададим интерпретацию для первой программы. Область интерпретации для нее обозначим как Dj. Она будет включать в себя множество целых неотрицательных чисел. Функцию I определим следующим образом:
- 1(х) = 2; 1(п) = 8; 1(у) = 0; 1(a) = 1;
- 1(f) = F, где F : D 2 —» D — функция умножения двух чисел:
I(p) = p, где P : D 2 -> — предикат вида
Г1, если d, d2J
Тогда протокол выполнения программы Pi будет выглядеть так, как это показано в табл. 6.2.
Протокол выполнения программы Р i
Источник: studref.com
ПРОТОКО́Л
ПРОТОКО́Л в информатике, совокупность правил и соглашений, определяющая процесс обмена сообщениями в компьютерной сети либо между разл. программами компьютера. П. служит для преобразования адресов (напр., логич. адреса, подаваемого приложению, в физич. адрес, используемый аппаратурой); маршрутизации сообщений (см. Маршрутизатор ); проверки целостности передаваемой информации; подтверждения приёма; обработки ошибок передачи; восстановления взаимного порядка сообщений и управления потоком информации. Наиболее распространённая система сетевых П. – Базовая эталонная модель взаимосвязи открытых систем (англ. Open Systems Interconnection Basic Reference Model, OSI, 1978), описывающая абстрактную семиуровневую иерархич. модель, в которой П. любого уровня может взаимодействовать с П. либо своего уровня, либо непосредственно соседних уровней.
Как устроен интернет? Протоколы передачи данных TCP/IP/HTTP. DNS и Доменные имена
Источник: bigenc.ru
Протокол работы программы
Программирование на ToyCode и закрепление знаний по отладке программы. Использование знаний из курса «Программирование на ЯВУ».
2.Порядок выполнения работы:
1. Ознакомиться с теоретическими материалами по теме.
2. Разобрать лекционные примеры.
3. Ознакомиться с заданием согласно варианту.
4. Составить таблицу внешних спецификаций
5. Выполнить проектирование тестов к задачам.
6. Разработать и описать алгоритмы решения в виде блок-схемы или псевдокода.
4. Закодировать алгоритмы на языке ассемблера с необходимыми комментариями.
5. Получить исполняемый файл (.tcp)
7. Отладить и протестировать программу.
Задание 1
3.1. Постановка задачи:

Выполнить вычисления Y по формуле . Значения аргументов вводятся с клавиатуры.
3.2 Система команд TOYCODE:
| КОП в числовой форме | КОП в форме символического имени | Название |
| STOP | Останов | |
| LD | Загрузка в аккумулятор | |
| STO | Запись в память | |
| ADD | Сложение | |
| SUB | Вычитание | |
| MPY | Умножение | |
| DIV | Деление нацело | |
| IN | Ввод | |
| OUT | Вывод | |
| B | Переход безусловный | |
| BGTR | Переход, если больше нуля | |
| BZ | Переход, если равно нулю |
Таблица внешних спецификаций
| № | Имя | Назначение | Тип | ОДЗ |
| a | Переменная | целый | -999..999 | |
| b | Переменная | целый | -999..999 | |
| c | Переменная | целый | -9999..9999 | |
| x | Константа | целый | ||
| y | Искомая переменная | целый | -9999..9999 |
Таблица тестов
| № теста | a | b | c | y | Комментарии |
| -2 | — | Ошибка | |||
| -1 |
Таблица памяти
| Переменные | |
| Имя переменной | Номер ячейки памяти |
| a | |
| с | |
| b | |
| y | |
| R (рабочая ячейка) | |
| Постоянные |
Листинг программы
REM Исходные данные
REM Задаем рабочую ячейку
REM Записываем константу 5 в память
REM Загружаем значение переменной «а» в аккумулятор
REM Вычисляем числитель (а+с)
REM сохраняем результат в рабочую ячейку «r»
REM Записываем 5 в аккумулятор
REM Вычисляем произведение 5a
REM Вычисляем разность 5а-b
REM Делим числитель на содержимое рабочей ячейки
REM Записываем в y результат
REM Выводим результат
Протокол работы программы
Заносим наш код в поле исходного кода в трансляторе языка TOYCODE, и нажимаем кнопку «Трансляция».
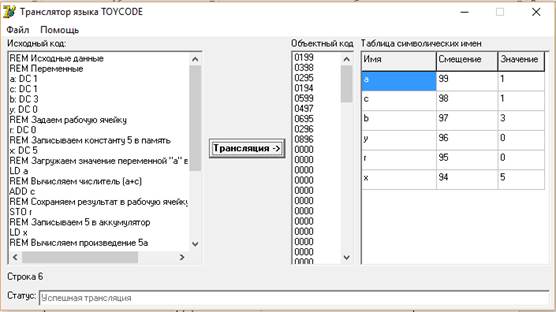
Рисунок 1 –Трансляция TOYCODE
Далле сохраняем обьектный код, и получаем фаил с расширением .tcp.

Рисунок 2 – Сохранение объектного кода
Файл с кодом запускаем на TOYCOMP и проверяем результат выполнения программы. Исходя из таблицы тестов при заданных a=1, b=3, c=1 Y должен получиться равным 1.
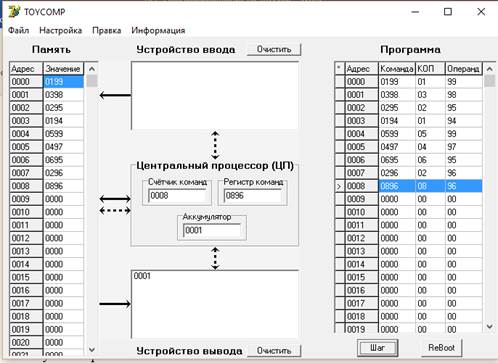
Рисунок 3 – Результат выполнения транслированного TOYCODE
Из рисунка 3 видно, что на устройство вывода пришла 1, что говорить о правильности транслированного TOYCODа. Проведем еще два прогона программы следуя таблице тестов:
| № теста | a | b | c | y | Комментарии |
| -2 | — | Ошибка |

Рисунок 4 – Прогон 2 с выдачей ошибки
Из рисунка 4 видно сообщение об ошибке, как и предполагалось в таблице тестов. Проведем последний 3 прогон:
| № теста | a | b | c | y | Комментарии |
| -1 |
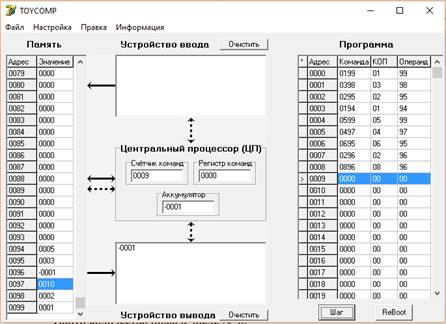
Рисунок 5 – Прогон 3, получение отрицательного числа
Из рисунка 5 видно, что в результате выполнения программы получилось отрицательное число, а именно -1, как и предполагалось нами.
3.8 Заключение о первом задание:
Программа отлажена, тестирование показало, что программа правильно решает поставленную задачу.
Задание 2
4.1 Постановка задачи:
Найти количество цифр в числе N>0;
Таблица внешних спецификаций
Таблица тестов
| № теста | n | k | Комментарии |
| -4 | Завершение программы так, как n | ||
| Завершение программы так, как n=0 |
4.4 Таблица памяти:
| Переменные | |
| Имя переменной | Номер ячейки памяти |
| n | |
| k | |
| R (рабочая ячейка) | |
| Постоянные |
4.5 Алгоритм на языке PASCAL:
4.6 Блок схема:

Листинг программы в TOYCODE
REM Вводим исходные данные
REM Вводим необходимые постоянные
REM Резервируем рабочую ячейку
REM Загружаем в аккумулятор величину n
REM Заносим в память величину n
REM Записываем в аккумулятор значение рабочей ячейки
REM Делаем переход для проверки введеного числа, оно должно быть строго больше 0
REM Выводим на устройство вывода ответ
REM Остановка программы
REM Делаем метку М1, для организации цикла
REM И делим содержимое аккумулятора на 10
REM Записываем содержимое аккумулятора в рабочую ячейку
REM Записываем значение «к» в аккумулятор
REM Прибавляем 1
REM Записываем в память новое значение «k»
REM Снова записываем содержимое рабочей ячейки в аккумулятор
REM Делаем переход на метку М1 если содержимое аккумулятора >0
REM Выводим на устройство вывода ответ
REM Остановка программы
Источник: poisk-ru.ru
Протоколирование: рекомендации по трассировке

В данной статье я хочу поделиться своими мыслями/наблюдениями/рекомендациями относительно реализации такой важной задачи при разработке ПО как протоколирование. В Интернете существует множество статей описывающих инструменты для протоколирования, но очень мало информации о том, какие именно события, и какую информацию, нужно записывать в протокол работы программы.
Введение
Очень часто возникает проблема диагностики дефектов в тестовой или рабочей среде, где нет инструментов разработки и отладки. И единственным способом понять, в чем ошибка – добавление строк кода с отладочной информацией и повторная установка приложения, если такие строки не были добавлены ранее. А можно ли сразу писать код так, чтобы информации, которую протоколирует приложение, было бы достаточно для диагностики проблемы?
В статье я совсем не буду касаться таких вопросов как инструменты для протоколирования. Но в любом случае, нужно понимать, что такие инструменты существуют и позволяют фильтровать записываемые в протокол данные и настраивать запись протокола в различные источники.
Основная задача статьи – дать представление разработчикам, какими способами проводится протоколирование, и дать рекомендации о том, где в программе вставлять строчки кода для протоколирования. В этой статье, в основном, будем говорить о трассировке.
Протоколирование
Я рассматриваю протоколирование намного шире, чем просто запись в лог-файл. Для меня протоколирование — это набор средств и методов, которые решают такие задачи:
- Быть уверенным, что система работает и работает правильно
- Понимать, почему система и ее данные находятся в текущем состоянии
- Иметь возможность быстро найти неисправность
- Узнать, как систему можно усовершенствовать
Подходы к протоколированию
- Разработчик — специалист, который разрабатывает и улучшает приложение
- Тест инженер — специалист, который отвечает за качество приложения, обнаружение и локализацию дефектов в период разработки
- Системный администратор — специалист службы сопровождения, который отвечает за бесперебойную работу приложения в рабочей среде и своевременное обнаружение ошибок.
- Владелец приложения — бизнес-пользователь, который знает и понимает функционал приложения в целом и, по сути, является владельцем данных приложения; сотрудник для которого разрабатывалось это приложение
- Найти место возникновения проблем и исправить их
- Выполнить оптимизацию
- Трассировка
- Счетчики производительности
- Состояние объектов/процессов
- Быть уверенным, что система работает корректно
- Обнаружение дефектов
- Максимально точно определить место и причину возникновения найденных дефектов
- Журнал событий
- Журнал аудита
- Состояние объектов/процессов
- Быть уверенным, что система работает
- Если есть ошибки понять почему (по чьей вине, где исправлять)
- Если работает медленно – понять почему
- Журнал событий
- Счетчики производительности
- Состояние объектов/процессов
- Быть уверенным, что система работает именно так, как нужно
- Журнал аудита
- Состояние объектов/процессов
- Трассировка — инструмент, который обычно называют «логом», по сути, хранилище, куда пишется подробная информация о ходе выполнения программы (последовательно, в порядке возникновения событий). Это обычно текстовый файл или таблица базы данных. Данный инструмент нужен разработчику, тест-инженеру или специалист службы сопровождения для детального анализа того, что происходит в приложении.
- Журнал событий — инструмент, который показывает события в приложении с точки зрения администратора. Т.е. события, по которым системный администратор может сказать в рабочем ли состоянии приложение или нет. Если говорить о разработке ПО для Windows —то это чаще всего Windows Event Log или собственные журналы приложений. Я сторонник того, чтобы не смешивать хранилища для трассировки и журнал событий.
- Журнал аудита — инструмент, который позволяет пользователю приложения понять, кто и какие действия выполнял (или пытался выполнять) в системе
- Счетчики производительности— инструмент системного администратора, который помогает обнаружить узкое место в производительности системы. Примером такого инструмента может быть Performance Monitor, встроенный в операционную систему Windows. Для других ОС существуют аналогичные инструменты
- Состояние объектов/процессов — инструмент, который помогает понять, в каком состоянии (или в какой стадии) находятся в текущий момент объекты или процессы в приложении, и как они в это состояние или стадию обработки они попали.
Например: представим себе приложение, которое обрабатывает входящие почтовые электронные сообщения. Для каждого такого сообщения можно выделить состояния: получено, обработано, удалено. В «журнал состояний объектов/процессов» в таком случае следует записать ключевую информацию по письму, историю смены состояний письма и сообщения при его обработке. Таким образом, полностью отделяется важная информация по процессу обработки письма от «мусора»
Трассировка

* картинка взята из статьи Lazy logger levels
- обо всех ошибках – обработанных и не обработанных
- параметры запуска и загруженную конфигурацию
- а также события, описанные ниже.
- Какие события нужно писать в трассировочный лог
- Как правильно выбрать уровень для события
- Как правильно выбрать категории событий
- Какую информацию нужно записывать при возникновении того или иного события
Какие события нужно вносить в трассировочный лог
- Используется ли модульные тесты при разработке.
Использование модульных тестов позволяет значительно снизить количество ошибок в бизнес логике методов, не взаимодействующих с внешними системами (внешними по отношению к данному слою приложения). Однако при взаимодействии кода с внешней системой (взаимодействие кода бизнес слоя с базой данных, взаимодействие слоев бизнес логики, расположенных на разных компьютерах и прочее) модульные тесты не эффективны потому, что конфигурация разных слоев может быть разной в разных средах. Исходя из этого, можно сделать вывод, что при использовании модульных тестов логично выполнять только трассировку взаимодействий между слоями и трассировку ошибок (т.к. считаем, что логика каждого слоя в отдельности очень хорошо протестирована). Если же модульных тестов нет — трассировать нужно каждую ветку логики программы (вход в метод, выход, возникновение в методе ошибки, каждую ветку условного оператора) - Тип приложения.
В таблице представлены некоторые типы приложений и события для протоколирования в трассировочный лог (понятно, что есть и другие типы приложений).
Какие данные нужно вносить в трассировочный лог
Кроме простого названия (описания) события, для анализа работы часто нужна еще дополнительная информация. Следующая таблица показывает данные, которые полезно было бы записывать. Понятно, что далеко не всегда нужно писать события настолько подробно. Кроме того, обычно инструменты трассировки позволяют некоторую из указанной ниже информации записывать автоматически.
| Данные | Описание |
| Дата и время | Дата и время возникновения события |
| Сервер | Сервер, на котором событие возникло (полезно при анализе журналов, собранных с различных серверов) |
| Процесс | Название процесса, где возникло событие. Это необходимо, например, в случае если разные процессы используют общие библиотеки. |
| Метод | Название метода, возможно, включающий название класса и библиотеки |
| Категория события | Название слоя или логического модуля |
| Уровень | Уровень детализации события |
| Название | Название события (запуск или завершение метода, ошибка, изменение состояние объекта и прочее) |
| Детальная информация | Например, детальная информация об ошибке (а при критической ошибке может быть и детальная информация о системе), значение параметра(-ов), название объекта или описание действия над объектом |
| Учетная запись, под которой работает процесс | |
| Учетная запись пользователя, который вызвал действие | Учетная запись пользователя, который сделал начальный вызов, что привело к данному событию |
| Стек | Стек вызовов методов, которая привела к данному событию. Может быть полезен при детальном анализе события |
| Корреляционный номер процесса | Если приложение многопользовательское, то важно понимать к какому запросу (пользователю) относится та или иная запись о события |
| Корреляционный номер инициирующего процесса | Если приложение распределенное, то данный номер используется для сопоставления событий на разных серверах (или процессах). Например, можно передавать с клиента на сервер корреляционный номер и сохранять его при трассировке. В дальнейшем можно сопоставлять вызов клиентского приложения с событием на сервере |
Уровни трассировки
Уровни в основном используются для фильтрации событий при записи в журнал. Это нужно для предотвращения записи в журнал данных, которые в данный период времени не нужны.
Например, такой инструмент как NLog, предоставляет по умолчанию 6 уровней событий (от более детального до менее детального): trace, debug, info, warn, error, fatal (более детально см. в документации к NLog)
Далее, в конфигурации можно указать, что, например, в рабочей среде, в журнал трассировки писать события уровня Error и Fatal (а все остальные игнорировать), а при возникновении проблемы изменить конфигурацию так, чтобы записывать все события.
Следующая таблица показывает мои рекомендации по выбору уровней событий при трассировке
| Событие | Уровень |
| Загруженная конфигурация / смена конфигурации | Info |
| Действия пользователя | Info |
| Начало и окончание каждого «публичного» метода (или метода, который реализует логику согласно спецификации), входные/выходные параметры, результат работы такого метода | Info |
| В публичных методах входные/выходные параметры, которые являются наборами данных | Debug |
| Логика (ветки программы) описанная спецификацией | Info |
| Начало и окончание остальных методов, входные/выходные параметры, результат работы | Trace |
| Шаги остальных методов | Trace |
| Доступ к внешним ресурсам (например: БД, web-сервисы) | Info |
| Детальная информация о запросах (командах) доступа к внешним ресурсам и полученном результате | Debug |
| Неожиданные исключения (не критические) | Error |
| Исключение, описанное в спецификации | Warn/Error |
| Обработанные исключения | Warn/Info/ Debug |
| Критическое исключение (обработанное или не обработанное) | Fatal |
Выбор категорий событий
Второй важный параметр, по которому можно настроить фильтрацию записи событий в журнал — это категории событий. Эти категории разработчик должен выбирать сам (т.е. инструменты не предоставляют категории по умолчанию)
Я рекомендую придерживаться таких рекомендаций — для каждого отдельного логического уровня сделать отдельную категорию. Например: уровень интерфейса (UIControls), уровень бизнес-логики (BusinessLogic), уровень доступа к данным (DAL), модуль поиска (Search), программа настройки конфигурации (ConfigManager) и так далее.
Далее, если у вас есть отдельные компоненты внутри слоя, то можно для их трассировки выбрать отдельные подкатегории, отделяя от основной категории точкой.
Например, визуальный компонент для отображения облака тегов (который располагается в уровне интерфейса)— UIControls.TagsControl.
Таким образом, при возникновении проблемы с компонентом, с одной стороны вы всегда сможете по журналу определить, какой компонент создал то или иное событие, с другой — более гибко настроить фильтрацию записи в журнал событий только по выбранному компоненту.
Заключение
Протоколирование — важная функция в любом приложении и требует внимательного анализа и проектирования. Несмотря на то, что трассировка обычно не описывается в требованиях, правильное ее использование может в значительной степени ускорить процесс обнаружения и исправление дефектов на тестовой и рабочей среде.
Данные выкладки — это мои практика и наблюдения, и, соответственно, у вас могут быть свой опыт и своя методика по использованию протоколирования (и трассировки в частности). С удовольствием выслушаю критические отзывы и замечания для улучшения рекомендаций.
Что еще почитать по трассировке
- Способы отладки приложений: Протоколирование http://dtf.ru/articles/read.php?id=36547
- Каким должен быть правильный лог-файл — http://www.codeart.ru/2011/02/23/kakim-dolzhen-byt-pravilnyj-log-fajl/
- What Goes Into A Trace Log? — http://www.informit.com/guides/content.aspx?g=dotnethttps://habr.com/ru/company/infopulse/blog/150563/» target=»_blank»]habr.com[/mask_link]
Основные принципы протоколирования работы приложения

Цель данной статьи – попытка выделить, обобщить и проанализировать основные критерии программных средств протоколирования, основные механизмы протоколирования, а также конфигурацию протоколирования.
Протоколирование работы приложения – полезный инструмент разработчика. Даже в примитивном варианте он позволяет экономить массу времени на поиск ошибок на стороне клиента. [5]
Средства протоколирования, как правило, пишутся для уже имеющегося приложения, либо для разрабатываемого приложения. То есть носят прикладной характер. Поэтому говорить о правилах или
концепциях их разработки не приходится – архитектурные особенности и
методика протоколирования зависят от конкретно взятой задачи.
Тема протоколирования достаточно широкая и каждый разработчик
ПО сам решает, каким образом ему вести протокол работы программы.
Протоколирование. Общие критерии программных средств протоколирования
Протоколирование (логирование) (англ. logging, tracing) — хронологическая запись с различной (настраиваемой) степенью детализации сведений о происходящих в системе событиях (ошибки, предупреждения, сообщения) куда-либо (файл, приложение мониторинга и т. д.) для последующего анализа. На программистском сленге логами называют протоколы работы, которые ведутся как самой операционной системой, так и самостоятельно многими программами и программными системами. [3]
Тема протоколирования работы программы довольно широко распространена, многие разработчики прибегают к ведению протоколов, журналов, логов работы программы. Впрочем, эти аспекты приложений часто бывают, доступны и полезны не только разработчикам, но и пользователям программных продуктов. Различные системы аудита, ведения истории, предоставления журнала действий – многое содержится
в тех программах, с которыми работают люди, решая различные задачи и пользуясь различными программами.
В UNIX-системах существуют демоны-логгеры, которые собирают информацию и пишут сообщения в системный журнал [2]. Подобные компоненты есть и Windows-системах, там они представлены службами.
В большинстве браузеров хранится история посещенных пользователем URL-ов.
В СУБД часто имеются утилиты для ведения протокола всех операций с данными. Например, утилита SQL Trace в MS SQL Server. [4]
Http-сервер ведет протоколы, в которые попадают все обращения к серверу, ошибки и прочая информация.
Таких примеров можно собрать огромное множество.
Как видно, протоколирование работы программы – очень важная часть в работе программы, часто оказывающаяся полезной как для разработчика, так и для пользователя. Подобные средства, как правило,
пишутся для уже имеющегося приложения, либо для разрабатываемого
приложения, то есть они носят прикладной характер. Поэтому говорить о правилах или концепциях разработки системы протоколирования не приходится – ее архитектурные особенности и методика протоколирования зависят от конкретно взятой задачи. Однако можно выделить общие для всех программ-логгеров показатели.
Итак, для всех программных средств протоколирования выделяют следующие критерии:
Цели ведения протокола:
o отладка приложения,
o ведение истории действий пользователя,
o слежение за действиями пользователя в целях безопасности
Формат хранения и представления протокола:
o текстовый файл,
o бинарный файл (с последующей обработкой программой),
Архитектурная организация (относительно протоколируемой программы):
o библиотека dll,
o программный модуль,
o программный агент,
o внешняя программа.
o ведение протокола для одной конкретной программы,
o возможность использования для разных программ.
Конкретизация, подробность протоколов.
Степень влияния на программу.
Типы регистрируемых объектов:
o элементы форм (активизация, ввод данных, модификация деактивация),
o программные модули (пакеты, библиотеки),
o классы, методы, атрибуты.
Сохранение отношений между регистрируемыми объектами:
o иерархическое протоколирование (отношения сохраняются),
o «плоское» протоколирование (отношения не сохраняются).
Механизмы протоколирования информации
1. Самый простой и потому самый распространенный способ — это протоколирование в текстовый файл. Способ, при котором отдельное событие представляет собой отдельною строку. Например, известный Symantec Antivirus или Linux Syslog. Способ хорош как с точки зрения реализации – довольно легко наладить такое протоколирование в коде большинства языков программирования, — так и со стороны использования – читать такой лог можно любым текстовым редактором. [1]
2. Чуть более сложный случай – логи, в которых отдельное событие представляет собой не одну строку, а несколько. С некоторым допущением к этому же типу относятся логи, которые пишутся в формате XML (либо сходных с ним форматах данных). Такой лог гораздо более сложен для анализа, потому что каждое событие может представлять собой набор более мелких записей.
3. Бинарный лог представляет собой самый нечитаемый тип логов.
Для того чтобы с ними работать, нужна специальная программа (обычно от того же производителя, что и приложение, которое пишет такой лог), с помощью которой бинарный лог и анализируется. Обычно бинарный лог — это последовательно сбрасываемые в файл структуры, которые разделяются символомразделителем. Обрабатывать такой лог очень тяжело, впрочем, довольно часто в технической информации, которую предоставляет производитель, есть описание структуры такого лога.
4. Приложения, которые используют базы данных либо сами являются СУБД, довольно часто используют базу данных в качестве хранилища логов. В большинстве своем это отдельная
таблица базы данных, каждая строка которой является отдельным событием. Такое протоколирование часто может отрицательно сказаться на общей производительности базы данных, так как протоколирование в базу данных может быть довольно интенсивным (к примеру, MS SQL Server 2000/2005 успевает в C2
Audit логи писать несколько десятков записей в секунду). Естественно, что все зависит от того, как сконфигурировано приложение.
Чаще всего протоколирование — процесс тихий и незаметный. Система пишет логи, тихо используя некоторую конфигурацию, которая предусмотрена производителем. Обычно конфигурация протоколирования подбирается так, чтобы это не вызывало какой-то проблемы у пользователя. Проблемы могут быть самые разные: от понижения производительности из-за постоянной записи информации в логи (на жесткий диск) до проблем со свободным местом на жестком диске. [1]
Довольно часто либо протоколирование выключено полностью, либо инсталляционная программа потребует точных указаний о том, что делать с протоколированием. Если есть подозрение, что протоколирование будет
довольно интенсивным, то следует заранее задуматься о том воздействии,
которое оно будет оказывать на систему. Кроме самого простейшего случая, когда протоколирование может быть или включено, или выключено, приложения часто предоставляют куда более настраиваемые и удобные средства управления. Типичные функции таковы:
1. Имя файла, директория или полный путь к тому файлу, в который пишется лог. Это очень полезно, если протоколирование необходимо и есть возможность или необходимость организовать
запись логов на отдельный жесткий диск, сетевой диск и т. п.
Такой способ удобен, если логи будут интерпретироваться сторонним приложением, которое находится на отдельном компьютере и каким-либо образом может повлиять на работу основной системы.
2. Критерий замены лога (Log Rotation). Рано или поздно логи становятся большими или их становится слишком много. Чтобы избежать проблем, которые с этим связаны (постоянная работа с огромным файлом отрицательно сказывается на производительности системы), программы, осуществляющие протоколирование, обычно используют что-нибудь из следующего списка возможностей управления логами:
Каждый день (неделю, месяц и т. д.) система использует новый лог-файл.
Смена файла происходит по достижении им определенного размера.
Смена файла происходит одновременно с перезапуском сервиса, который пишет лог.
3. Набор событий, которые будут протоколироваться. Довольно часто важно иметь возможность настроить протоколирование только тех
событий, которые реально необходимы. К примеру, часто нет
необходимости протоколировать информацию обо всех транзакциях в базе данных, особенно если это куча select-запросов, которые, вероятно, не содержат угрозы с точки зрения безопасности. В таком случае можно изрядно снизить нагрузку на сервер, выключив протоколирование транзакций, но оставив учет только реально необходимых событий: попыток авторизации, попыток доступа к файлам, изменения системных настроек и т. п.
Были рассмотрены основные принципы протоколирования работы приложения, однако, следует отметить, что указанные основные принципы очень часто расширяются разработчиками под свои конкретные нужды. Разрабатываются новые форматы хранения данных, новые методы и стандарты представления данных. Улучшаются производительность и универсальность систем протоколирования.
ИСПОЛЬЗОВАНИЕ XML ПРЕДСТАВЛЕНИЯ ДАННЫХ ДЛЯ ОПИСАНИЯ ГРАФИКО-ТЕКСТОВОЙ ИНФОРМАЦИИ ВО ВСТРАИВАЕМЫХ СИСТЕМАХ
Выбор способа представления входных данных
При выборе способа представления нужно учитывать следующие особенности, связанные со спецификой полётных инструкций и авиационной области применения:
Данные могут быть разнородных типов (текстовые, табличные,
Применение в бортовых системах предъявляет жёсткие требования по быстродействию.
Данные имеют изменяющуюся структуру.
XML формат предоставляет возможности для реализации базы данных полётных инструкций, позволяет учесть выше приведённые особенности. Язык XML и некоторые другие стандарты основанной на нем платформы уже, несомненно, стали стандартами де-факто. Все ведущие поставщики программного обеспечения не только Web, но и систем баз данных, включают в свои программные продукты поддержку языка XML или даже создают специализированные основанные на нем системы.
В настоящее время создано множество успешных подмножеств языка
XML, применяемые в специальных областях и описывающие различные данные. К ним можно отнести SVG (Scalable Vector Graphics), VML (англ. Vector Markup Language — язык векторной разметки), CML (Chemical Markup Language – описание молекулярных структур) и т. д. Элементы этих языков можно использовать в области отображения на индикаторах полётных инструкций. В частности, в основу может лечь язык описания графики SVG, который необходимо оптимизировать для встраиваемого применения.
Генерация XML базы данных на основе графического представления
- Основные термодинамические принципы работы холодильной машины
- Анализ и роль работы тестировщика приложения в командной разработке
- Основные принципы бюджетного процесса
- Основные принципы стандартизации и сертификации
- Основные цели, задачи и принципы Программы
Источник: studik.net