
Государственный регистрационный номер 2047806003595 от 06.02.2004 г.
СПб государственный университет сервиса и экономики
191015, г. Санкт-Петербург, ул. Кавалергардская, 7
Работа в системе STATISTICA начинается с ввода данных. В качестве конкретной области выберем психологический пример.
Исходные данные в системе STATISTICA организованы в виде таблиц. Если у пользователя имеется опыт работы с электронными таблицами (типа MS Excel), то он быстро привыкнет и к таблицам системы STATISTICA. Следует отметить, что табличная структура данных STATISTICA позволяет естественно отобразить большинство реальных данных.
Электронная таблица состоит из строк и столбцов. Столбцы таблицы STATISTICA называются Переменные (Variables), а строки – Наблюдения (Cases).
Например, в психологии наблюдения – это испытуемые, а в качестве переменных могут выступать пол, возраст, название факультета и т. д. Существует два варианта создания таблицы с данными в системе STATISTICA.
Анализ данных в STATISTICA
Вариант 1
1. Запустить программу STATISTICA (загрузочный файл Sta_win.exe либо ярлыкSTATISTICA на рабочем столе).
2. В открывшемся окне Переключатель модулей (Module Switcher) (см. рис. 2.1) выбрать модуль Основные статистики (Basic statistics) и дважды щелкнуть по нему мышью или нажать кнопку Переключиться в (Switch to).

3. В модуле Основные статистики (Basic statistics) можно выбрать любую статистическую процедуру, входящую в этот модуль. Но поскольку наша цель – создать таблицу с данными, то просто нужно щелкнуть мышью по кнопке Выход .
Итак, мы находимся в рабочем окне модуля Основные статистики (Basic statistics ) системы STATISTICA. В основном рабочем окне системы подводим курсор мыши к строке меню Файл (File) и щелкаем левой кнопкой мыши. В выпадающем меню выбираем команду Новые данные (New data. ). На экране компьютера появится окно Новые данные: задать имя файла (New data: Specify File Name ) (рис. 2.6).
В окне File Name вместо имени файла NEW.STA, находящегося в режиме замены, можно ввести свое имя файла, например table_1.sta (файл может быть назван и по-русски, однако по ряду причин целесообразнее использовать латинский шрифт).

Рис. 2.6. Окно Новые данные: задать имя файла (New Data: Specify File Name)

После нажатия клавиши Enter на клавиатуре или кнопки программа создаст пустую таблицу, содержащую 10 строк и 10 столбцов (рис. 2.7).
Рис. 2.7. Вид электронной таблицы системы STATISTICA
При необходимости можно увеличить или уменьшить количество строк и столбцов этой таблицы. Для этого используются кнопки Переменные ( ) и Наблюдения (
) и Наблюдения ( ) на панели инструментов.
) на панели инструментов.
Ввод данных STATISTICA #01 | СТАТИСТИКА STATISTICA

После нажатия на кнопку Наблюдения раскроется меню, предлагающее следующий выбор для наблюдений таблицы: Добавить (Add), Переместить (Move), Копировать (Copy), Удалить (Delete), Имена (Names). Выберем, например, пункт Добавить (Add), щелкнув левой кнопкой мыши. Откроется окно Добавить наблюдения (Add Cases) (рис. 2.8), в котором можно задать число наблюдений (испытуемых), добавляемых в таблицу, например 2.

После нажатия на кнопку количество строк (наблюдений) в таблице увеличится на 2, т. е. станет равным 12.

Аналогичным образом можно изменить число переменных в таблице. Нужно нажать на кнопку Переменные на панели инструментов. С помощью курсора мыши в выпадающем меню выбрать пункт Добавить (Add). На мониторе появится окно Добавить переменные (Add Variables) (рис. 2.9), где надо ввести количество добавляемых переменных, например 1, и номер переменной, после которой будут вставляться добавляемые переменные, например Var 2.

Кроме описанных выше действий, можно также вводить имена наблюдений (испытуемых). Для этого надо нажать кнопку Наблюдения и выбрать пункт меню Имена (Names). На экране появится диалоговое окно Диспетчер имени наблюдения (Case Name Manager) (рис. 2.10), в котором можно определить, сколько символов в таблице будет зарезервировано для имен наблюдений.
Поле для имен наблюдений можно раздвинуть с помощью мыши, зафиксировав ее левую кнопку.
Итак, мы имеем электронную таблицу, которая содержит 12 столбцов (переменных) и 10 строк (наблюдений, реализаций, испытуемых), а также место для ввода имен наблюдений (рис. 2.11, левая часть электронной таблицы).
Теперь необходимо ввести наблюдения (значения) и имена переменных. Работать нужно, используя мышь и клавиатуру. Двойной щелчок мыши по полям заголовков открывает диалоговые окна, позволяющие вводить заголовки, описывать переменные, наблюдения (например, имена испытуемых) и т. д.
Рис. 2.11. Вид электронной таблицы системы STATISTICA, содержащей
поле ввода имени наблюдения
Например, чтобы ввести имена наблюдений, необходимо дважды щелкнуть мышью в поле Имя наблюдения (Case Name) и в появившемся окне ввести имена испытуемых (на рис. 2.12 – названия стран). Работа в данном окне заканчивается нажатием кнопки .
Для того чтобы описать переменную, необходимо дважды щелкнуть мышью по ее имени. Например, после щелчка по заголовку переменной 1 (VAR1) откроется окно, в котором можно задать ее имя (или переименовать ее), формат, метку, связь и т. д. (рис. 2.13).
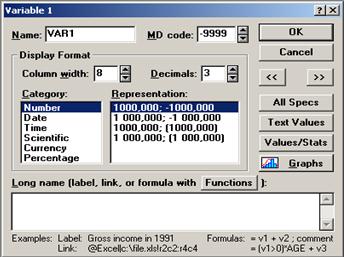
Рис. 2.13. Окно переменной
Работа с данным окном заканчивается нажатием кнопки . Далее можно заполнить созданную таблицу данными, которые вводятся непосредственно с клавиатуры.
Для ввода числовых данных используются мышь, клавиатура и стрелки перемещения курсора. Курсор ставится на нужную ячейку таблицы, куда вводятся числовые данные. Текстовые данные вводятся иначе. Курсор подводят к ячейке переменной с текстовыми данными и дважды щелкают левой кнопкой мыши. В ячейке появится код 9999 – это код пропущенных значений.
Его можно стереть, используя клавишу Удалить (Delete) на клавиатуре. Затем вводится нужное текстовое значение.
Примечание 1.Поскольку система STATISTICA является обычным Windows‑приложением, можно легко и быстро импортировать данные, полученные в системе STATISTICA, в другое Windows-приложение, например в MS Word. Для этого необходимо нажать одновременно кнопки ALT и F3. На экране вместо курсора мыши появится значок «прицел».
Используя мышь, надо поместить «прицел» в верхний левый угол таблицы. Затем нажать левую кнопку мыши, зафиксировав «прицел», и, удерживая кнопку мыши, переместить его в новое место таблицы. Выделенная часть таблицы будет отмечена прямоугольной рамкой. После того как будет отпущена кнопка мыши, отмеченная часть таблицы будет помещена в буфер обмена. Если теперь открыть нужный документ Word и нажать на клавиатуре комбинацию кнопок CTRL и V, то выбранный сегмент таблицы будет скопирован в документ.
Примечание 2. Выше была рассмотрена работа по созданию набора данных в модуле Основные статистики (Basic statistics). Подобным способом можно ввести данные в любом другом модуле системы STATISTICA. С точки зрения общих возможностей по управлению данными модули системы одинаковы.
Вариант 2
В системе STATISTICA имеется специальный модуль Управление данными (Data management/MFM) (см. рис. 2.1), который содержит расширенные возможности, позволяющие быстро создать электронную таблицу, объединить две таблицы, вырезать часть таблицы, отсортировать наблюдения по какому-либо признаку (например, расположить имена испытуемых в алфавитном порядке, упорядочить их по возрасту и т. д.).
Создать электронную таблицу, используя возможности модуля Управление данными (Data management/MFM), можно следующим образом.
Надо выбрать опцию Создать новый файл данных (Create new data file) и нажать кнопку (рис. 2.14). В открывшемся окне (рис. 2.15) в строках Количество переменных (Number of variables) и Количество наблюдений (Number of cases) ввести числовые значения, соответствующие количеству столбцов и строк создаваемой таблицы.
Далее следует нажать кнопку Новое имя файла  и в раскрывшемся окне Новые данные: задать имя файла (New Data: Specify File Name) заменить имя файла NONAME.STA, например, на имя tabl.sta и нажать кнопку
и в раскрывшемся окне Новые данные: задать имя файла (New Data: Specify File Name) заменить имя файла NONAME.STA, например, на имя tabl.sta и нажать кнопку
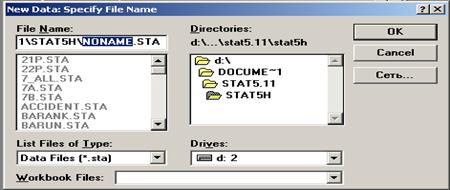
Рис. 2.16. Окно Новые данные: задать имя файла
(New Data: Specify File Name)
Затем надо еще раз нажать кнопку . В основном окне системы STATISTICA появится электронная таблица с именем tabl.sta заданной размерности, в которую можно вводить данные.
Из переключателя модулей системы STATISTICA (STATISTICA Module Switcher) можно запустить любой модуль (рис. 2.17). Например, чтобы запустить модуль Основные статистики (Basic Statistics) нужно выбрать его в меню, щелкнув по нему мышью. Модуль будет выделен синим цветом.
Затем надо подвести курсор мыши к кнопке Переключиться в и нажать ее. На экране появится окно Основные статистики и таблицы (Basic Statistics and Tables) (рис. 2.18).
Примечание. Использование кнопок Переключиться в и  можно заменять двойным щелчком левой кнопки мыши после выбора нужного модуля или опции.
можно заменять двойным щелчком левой кнопки мыши после выбора нужного модуля или опции.

Рассмотрим, как можно создать набор данных, который содержит не только числовую, но и текстовую информацию. Создадим рабочий файл данных в модуле Основные статистики (Basic Statistics). Как было рассмотрено выше (см. раздел «Работа в системе STATISTICA», создание таблицы данных согласно Варианту 1), после выбора модуля Основные статистики (Basic Statistics) и открытия окна Основные статистики и таблицы (Basic Statistics and Tables) надо нажать кнопку и выполнить все описанные далее действия.
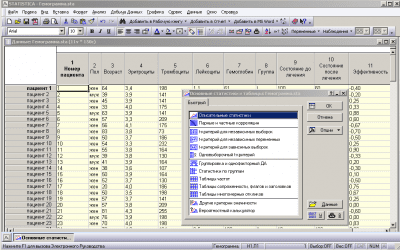
В файле, представленном в виде электронной таблицы (рис. 2.19), содержатся результаты опроса 10 женщин относительно их семейного положения и состояния уровня тревожности. Первая переменная СЕМ_ПОЛ описывает семейное положение женщин. Эта переменная принимает два значения: П_семья – полная семья, Н_семья – неполная семья.
Вторая переменная, ТРЕВОГА, описывает самооценку личностной тревожности женщины. Она принимает два значения: низкая, высокая. Известно, что личностная тревожность характеризуется устойчивой склонностью воспринимать жизненную ситуацию как угрожающую (содержащую в себе тайную угрозу). Как видно из таблицы, первая опрошенная женщина (наблюдение № 1 – первая строка в таблице) имеет полную семью и характеризует свое состояние как высоко тревожное. Вторая опрошенная женщина (наблюдение № 2 – вторая строка таблицы) имеет неполную семью и оценивает уровень своей тревожности как низкий и т. д.
Пусть файл имеет имя WOMEN1.STA. Переменные в этом файле принимают текстовые значения. Ввод текста в таблицу занимает слишком много времени. Для удобства лучше вводить численные значения, а затем использовать кодировку значений переменных. Рассмотрим, как это делается, на примере переменной СЕМ_ПОЛ.
После двойного щелчка левой кнопкой мыши по заголовку указанной переменной на экране отобразится окно Диспетчер текстовых значений (Text Values Manager) и название переменной – СЕМ_ПОЛ (рис. 2.20).
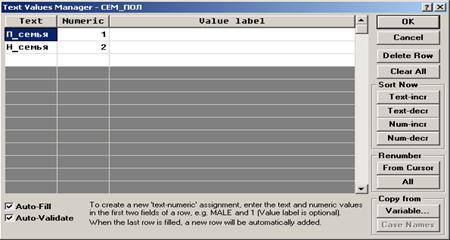
Рис. 2.20. Окно Диспетчер текстовых значений (Text Values Manager)

В этом окне в колонке Текст (Text) необходимо набрать в первой строке П_семья, а в колонке Число (Numeric) – значение, равное 1. Таким образом, текстовому значению П_семья будет присвоен код 1. Во второй строке колонки Текст (Text) надо набрать Н_семья, а в колонке Число (Numeric) – числовое значение 2. Таким образом, текстовому значению Н_семья будет присвоен код 2. Далее следует нажать кнопку .
После этого можно ввести значения, равные 1, в те ячейки переменной СЕМ_ПОЛ, где должно стоять текстовое значение П_семья,а значения, равные 2, – текстовое значение Н_семья. Таким образом, переменная СЕМ_ПОЛ является номинальной, или, другими словами, значения переменной СЕМ_ПОЛ отнесены к номинальной шкале (рис. 2.21).
Теперь всякий раз при нажатии кнопки на панели инструментов системы STATISTICA в электронной таблице будут отображаться нужные текстовые значения (см. рис. 2.19).
Таким же образом вводятся текстовые значения в ячейку переменной ТРЕВОГА, и после этого рабочийфайл с именем women1.sta будет создан.
Источник: studopedia.su
STATISTICA 13.3 + активатор
STATISTICA — наверное система для статистического разбора этих, включающая просторный комплект аналитических операцй и способов: наиболее 10 000 разных типов графиков, описательные и внутригрупповые статистики, разведывательный тест этих, корреляции, скорые главные статистики и блоковые статистики, интерактивный вероятностный калькулятор, T-аспекты (и остальные аспекты массовых отличий), таблицы частот, сопряженности, флагов и заголовков, тест многомерных отзывов, многократная регрессия, непараметрические статистики, общественная модель дисперсионного и ковариационного разбора, сборка распределений. (Приведено отображение лишь базисного блока. Еще есть доп блоки: линейные/нелинейные модели; многомерные разведочные технологии; тест силы; нейронные козни; data Mining; игра в карты контролирования свойства; тест действий; планирование опытов. и др.
Характеристики
- Размер 852.78 МБ
- Версия 13.3
- Стоимость по запросу
- Разрядность
- Совместимость Windows 7, Windows 10
- Язык Английский
- Дата обновления 30.09.2019
- Разработчик
Похожее

Serial Monitor Device Monitoring Studio 8.42.00.9838

WS Handy Keylogger Последняя + keygen
Источник: 3freesoft.ru
Statistica
Система статистического анализа STATISTICA 10 — это высокопроизводительное решение может использоваться для тщательного и высокоточного анализа корпоративных данных, прогнозного моделирования и составления аналитических отчетов. Версия STATISTICA 10 предлагает клиентским организациям оценить целый ряд усовершенствований и новых функций, включая заметно возросшую производительность, улучшенную масштабируемость, более совершенные механизмы визуализации данных и многое другое.
Одним из главных преимуществ предлагаемого решения является поддержка технологий, реализованных в новых линейках многоядерных процессоров от Intel. Для создания новой версии продукта использовались самые современные средства разработки, а благодаря полностью переработанным алгоритмам моделирования, обработки и анализа данных, STATISTICA 10 справляется с большинством задач в три-четыре раза быстрее по сравнению с прошлыми версиями.
Список ключевых усовершенствований, представленных в STATISTICA 10, также включает в себя расширенные возможности моделирования, дополнительные процедуры для моделирования кредитных и страховых рисков. Пользователям также предлагается оценить более гибкие средства графического представления данных, тесную интеграцию с платформой Microsoft SharePoint и возможность прямого подключения к кубам OLAP.
В работе программы STATISTICA 10 применяются уникальные достижения 64-битной компьютерной технологии, а также параллельные процессы. Большинство функций программы STATISTICA, используемых при обработке данных и выполнении анализа, оптимизированы с помощью многопоточной технологии. Таким образом, стало возможным их параллельное использование на многоядерных процессорах и достижение высочайшего быстродействия для многоразмерных задач в экономике, бизнесе, медицине.
Интеграция и совместимость
- Загрузка и выгрузка из STATISTICA 10 теперь использует новые программы обмена и интеграции данных – Microsoft SharePoint. Документы STATISTICA теперь можно удобно передавать и получать из SharePoint с помощью пользовательского интерфейса программы.
- STATISTICA напрямую импортирует файлы Office 2007 и 2010, сохраняя форматирование. Эта новая технология позволила повысить скорость импорта данных из Excel 2007 и 2010 в таблицы программы STATISTICA, а также сделала его более устойчивым к ошибкам выгрузки. Загрузка/выгрузка из Excel 2007/2010 теперь поддерживает текстовый формат ячеек.
- STATISTICA Query может получать данные не только из внешних систем, таких как поставщик данных Microsoft OLE DB, но и из хранилищ бизнес-информации SAP Business Warehouse.
Визуализация данных
Расширенные графические возможности STATISTICA позволяют автоматически определять и использовать преимущества высокоэффективного аппаратного ускорения, которое может быть реализовано не только видеокартами стационарных компьютеров «топ»-уровня, но и графическими ускорителями ноутбуков «среднего» уровня. В результате графики строятся не только быстрей, но и поддерживают более продвинутые настройки изображения. Графические возможности программы STATISTICA были усовершенствованы благодаря новым процедурам расслоения, закрашивания и сглаживания линий, кривых и поверхностей. Кроме того, все графические документы STATISTICA (как отдельные, так и собранные в рабочую книгу) могут изменяться и настраиваться интерактивно (с помощью инструментов, расположенных в нижней части окна графика). Новые возможности STATISTICA 10 позволяют улучшать внешний вид графика, проводить более глубокий визуальный анализ и выявлять скрытые тренды путем постепенного уменьшения насыщенности изображения, а также вращения трехмерных графиков.
- Интерактивное масштабирование позволяет визуально выявить скрытые тренды с помощью растяжения или сжатия интересующей части графика. Пользователь может интерактивно изменять масштаб всех осей графика.
- Интерактивная прокрутка поможет обнаружить тренды, скрытые в массиве данных. С помощью мыши можно интерактивно прокручивать оси графика влево или вправо.
- Прозрачность – новая возможность STATISTICA 10 – позволит выявить тренды, скрытые в плотном массиве данных (особенно при построении диаграмм рассеяния по выборке большого объема). Целью является достижение оптимального уровня плотности точек, при котором можно выявить закономерности, скрытые большим количеством случайных данных (белым шумом), которые создают эффект «чернильного пятна».
- Соединительные линии можно быстро добавлять на график с помощью опции Reference Lines, доступной в диалоге «Все параметры графика».
- Интерактивная правка текста – текст можно изменять напрямую в окне графика, не открывая редактор. *Сам же редактор текста остался доступным и по-прежнему содержит дополнительные опции для форматирования.
Пользовательский интерфейс
Пользовательский интерфейс был существенно переработан с учетом последних достижений эргономики в следующих областях:
- Уменьшение зрительного напряжения.
- Улучшение эффективности работы человека с компьютером.
- STATISTICA 10 упрощает процедуру подгонки и моделирования.
- Обширная и широко масштабируемая реализация модели пропорциональных рисков Кокса (мощная модель для данных, содержащих времена жизни) добавлена в версию 10. Данный модуль имеет приложения в следующих областях: анализ времен жизни пациентов в медицине, анализ оборота клиентов и моделирование и оценка времени эксплуатации механических деталей.
- Модель пропорциональных рисков Кокса позволяет эффективно работать с цензурированными данными, категориальными предикторами и планами, содержащими взаимодействия и/или вложенные эффекты. В качестве техники построения моделей этот модуль использует метод наилучших подмножеств и пошаговую регрессию. Построение функций выживаемости для новых данных можно задать с помощью STATISTICA Rapid Deployment.
2015: Statistica 13
21 октября 2015 года компания Dell представила решение Statistica 13 для работы с Большими данными и аналитикой. Продукт ориентирован на помощь компаниям в быстром и надежном превращении данных в прогнозы для принятия верных решений в кратчайшие сроки.
Продукт может интегрироваться в бизнес-процессы и использоваться на каждом этапе работы для получения более высоких результатов.

Скриншот окна приложения (2014)
Версия программной платформы углубленной аналитики Dell Statistica 13 помогает упростить и улучшить процесс внедрения предиктивных моделей непосредственно в источники данных внутри брандмауэра, в облаке и в экосистеме партнера. Решение простое в эксплуатации, не требует написания кода и интегрируется с открытым языком R.
В составе Dell Statistica ряд инструментов для обнаружения и объединения данных и предиктивной аналитики. Система помогает организациям учитывать всю имеющуюся информацию для предсказывания тенденций будущего, идентификации новых клиентов и прогноза объемов продаж, испытывать сценарии вида «что, если», снижать вероятность мошенничества и других рисков для бизнеса.
Среди функций платформы Statistica 13:
- модернизированный графический интерфейс, упрощающий использование продукта и делающий данные более наглядными;
- углубленная интеграция с движком Statistica Interactive Visualization and Dashboard;
- интеграция с открытым языком R, упрощающая обмен и управление R-скриптами;
- инструмент поэтапной рекомендации оптимальных моделей для пользователей;
- расширенные возможности инструмента Native Distributed Analytics (NDA), позволяющие пользователям запускать анализ непосредственно в базах данных и работать более эффективно с крупными и растущими массивами данных.
Инструмент NDA помещает алгоритмы построения предиктивных моделей и функции подсчета непосредственно в источники данных. Это устраняет задержки и ограничения, которые имеют место вследствие наличия промежуточного сервера или настольной системы. Вся обработка выполняется в базе данных.
Такой подход позволяет организациям пользоваться преимуществами кластеров Hadoop, аппаратных средств и прочих высокопроизводительных платформ. Изначально в платформу Statistica 13 будут встроены функции NDA для баз данных Microsoft SQL Server. Согласно заявлению компании, поддержка других баз данных будет добавлена в последующих обновлениях.
| — Интер РАО ЕЭС, ПАО | StatSoft Russia | 2011.01 | BI |
Источник: www.tadviser.ru