
Оптическое распознавание символов — это механический или электронный перевод изображений рукописного, машинописного или печатного текста в последовательность кодов, использующихся для представления в текстовом редакторе. Распознавание широко используется для конвертации книг и документов в электронный вид, для автоматизации систем учета в бизнесе или для публикации текста на веб-странице. Оптическое распознавание текста позволяет редактировать текст, осуществлять поиск слова или фразы, хранить его в более компактной форме, демонстрировать или распечатывать материал, не теряя качества, анализировать информацию, а также применять к тесту электронный перевод, форматирование или преобразование в речь. В настоящее время больше всего распространены так называемые «интеллектуальные» системы, с высокой степенью точности распознающие большинство шрифтов. Некоторые системы оптического распознавания текста способны восстанавливать исходное форматирование текста, включая изображения, колонки и другие нетекстовые компоненты.
Распознавание текста
Точное распознавание символов в печатном тексте в настоящее время возможно только если доступны чёткие изображения, такие как сканированные печатные документы. Точность при такой постановке задачи превышает 99%, абсолютная точность может быть достигнута только путем последующего редактирования человеком.
Для решения более сложных проблем в сфере распознавания используются как правило интеллектуальные системы распознавания, такие какискусственные нейронные сети.
На стадии подготовки и обработки информации, особенно при компьютеризации предприятия, автоматизации бухучета, возникает задача ввода большого объема текстовой и графической информации в ПК. Основными устройствами для ввода графической информации являются: сканер, факс-модем и реже цифровая фотокамера. Кроме того, используя программы оптического распознавания текстов, можно вводить в компьютер (оцифровывать) также и текстовую информацию. Современные программно-аппаратные системы позволяют автоматизировать ввод больших объемов информации в компьютер, используя, например, сетевой сканер и параллельное распознавание текстов на нескольких компьютерах одновременно.
Большинство программ оптического распознавания текста (OCR Optical Character Recognition) работают с растровым изображением, которое получено через факс-модем, сканер, цифровую фотокамеру или другое устройство. На первом этапе OCR должен разбить страницу на блоки текста, основываясь на особенностях правого и левого выравнивания и наличия нескольких колонок.
Затем распознанный блок разбивается на строки. Несмотря на кажущуюся простоту, это не такая очевидная задача, так как на практике неизбежны перекос изображения страницы или фрагментов страницы при сгибах. Даже небольшой наклон приводит к тому, что левый край одной строки становится ниже правого края следующей, особенно при маленьком межстрочном интервале. В результате возникает проблема определения строки, к которой относится тот или иной фрагмент изображения. Например, для букв j, Й, ё при небольшом наклоне уже сложно определить, к какой строке относится верхняя (отдельная) часть символа (в некоторых случаях ее можно принять за запятую или точку).
Программа для распознавания текста. Как распознать текст с картинки
Потом строки разбиваются на непрерывные области изображения, которые, как правило, соответствуют отдельным буквам; алгоритм распознавания делает предположения относительно соответствия этих областей символам; а затем делается выбор каждого символа, в результате чего страница восстанавливается в символах текста, причем, как правило, в соответствующем формате. OCR-системы могут достигать наилучшей точности распознавания свыше 99,9% для чистых изображений, составленных из обычных шрифтов.
На первый взгляд такая точность распознавания кажется идеальной, но уровень ошибок все же удручает, потому что, если имеется приблизительно 1500 символов на странице, то даже при коэффициенте успешного распознавания 99,9% получается одна или две ошибки на страницу. В таких случаях на помощь приходит метод проверки по словарю. То есть, если какого-то слова нет в словаре системы, то она по специальным правилам пытается найти похожее. Но это все равно не позволяет исправлять 100% ошибок, что требует человеческого контроля результатов.
Встречающиеся в реальной жизни тексты обычно далеки от совершенства, и процент ошибок распознавания для нечистых текстов часто недопустимо велик. Грязные изображения здесь наиболее очевидная проблема, потому что даже небольшие пятна могут затенять определяющие части символа или преобразовывать один в другой. Еще одной проблемой является неаккуратное сканирование, связанное с человеческим фактором, так как оператор, сидящий за сканером, просто не в состоянии разглаживать каждую сканируемую страницу и точно выравнивать ее по краям сканера.
Если документ был ксерокопирован, нередко возникают разрывы и слияния символов. Любой из этих эффектов может заставлять систему ошибаться, потому что некоторые из OCR-систем полагают, что непрерывная область изображения должна быть одиночным символом.
Страница, расположенная с нарушением границ или перекосом, создает немного искаженные символьные изображения, которые могут быть перепутаны OCR.
Основное назначение OCR-систем состоит в анализе растровой информации (отсканированного символа) и присвоении фрагменту изображения соответствующего символа. После завершения процесса распознавания OCR-системы должны уметь сохранять форматирование исходных документов, присваивать в нужном месте атрибут абзаца, сохранять таблицы, графику ит.д. Современные программы распознавания поддерживают все известные текстовые и графические форматы и форматы электронных таблиц, а некоторые поддерживают такие форматы, как HTML и PDF.
Работа с OCR-системами, как правило, не должна вызывать особых затруднений. Большинство таких систем имеют простейший автоматический режим сканируй и распознавай (Scan редактировать и сохранять результаты в распространенных табличных форматах. Существенно облегчает работу и возможность прямого экспорта результатов в MS Word и MS Excel (для этого теперь не нужно сохранять результат в файл RTF, а затем открывать его с помощью MS Word).
Также программа снабжена возможностями массового ввода возможностью пакетного сканирования, включая круглосуточное, сканирования с удаленных компьютеров локальной сети и организации распределенного параллельного сканирования в локальной сети.
Readiris Pro7 профессиональная программа распознавания текста. Oтличается от аналогов высочайшей точностью преобразования обычных (каждодневных) печатных документов, таких как письма, факсы, журнальные статьи, газетные вырезки, в объекты, доступные для редактирования (включая файлы PDF). Основными достоинствами программы являются: возможность более или менее точного распознавания картинок, сжатых по максимуму (с максимальной потерей качества) методом JPEG, поддержка цифровых камер и автоопределения ориентации страницы. Поддержка до 92 языков (включая русский).
OmniPage11 — программа практически со 100% точностью распознает печатные документы, восстанавливая их форматирование, включая столбцы, таблицы, переносы (в том числе переносы частей слов), заголовки, названия глав, подписи, номера страниц, сноски, параграфы, нумерованные списки, красные строки, графики и картинки. Есть возможность сохранения в форматы Microsoft Office, PDF и в 20 других форматов, распознавания из файлов PDF, редактирование прямо в формате PDF. Система искусственного интеллекта позволяет автоматически обнаруживать и исправлять ошибки после первого исправления вручную. Новый специально разработанный модуль Despeckle позволяет распознавать документы с ухудшенным качеством (факсы, копии, копии копий ит.д.). Преимуществами программы являются возможность распознавания цветного текста и возможность корректировки голосом.
№3.
Понравилась статья? Добавь ее в закладку (CTRL+D) и не забудь поделиться с друзьями:
Источник: studopedia.ru
Программы распознавания текста
Для того, чтобы текст можно было редактировать, мало его отсканировать: надо его еще и распознать. При сканировании лист бумаги превращается в картинку на мониторе. А при распознавании картинка превращается в текст. Так что если нужно еще отредактировать текст в редакторе, необходимо поставить программу распознавания текста при сканировании. Есть платные и бесплатные программы.
Они с разным успехом работают с разными языками. Качественнее всего русский язык распознает ABBYY FineReader. Давайте сравним программы.
| ABBYY FineReader | 5 | В пробной версии 100 страниц на 30 дней бесплатно. Программа качественная, цена 7000р | https://www.abbyy.com/ru-ru/finereader |
| Microsoft OneNote | 4 | https://www.onenote.com | |
| OCR CuneiForm | 3 | Погуглите по каталогам софта | |
| OmniPage 18 | 5 | Пробная версия дается только на корпоративную почту. Качественная, цена $150. | http://www.nuance.com |
| WinScan2PDF | Это просто конвертер картинок в pdf, а не распознаватель | Погуглите по каталогам софта |
Сравнивать будем на примере – есть скан свидетельства ИНН размером 1275×1750 разрешением 150dpi, вот его и распознаем.
ABBYY FineReader
Лучше всех под русский язык заточен ABBYY FineReader . Это и понятно, ведь ABBYY – российская компания. Если вам необходимо работать с текстом постоянно, то придется наверно купить программу, потому что бесплатных сравнимых по качеству программ нет. Судите сами, вот результат сканирования (дальше будет существенно хуже):

Личные данные распознаны, просто замазаны синим
Единственное, почему-то нижнюю часть свидетельства он не распознал – наверно, из-за печати.
Если вам не надо постоянно распознавать картинки, то можно воспользоваться пробной версией – у вас будет 30 дней на распознавание 100 страниц. Еще 10 страниц можно распознать в онлайн-версии программы. Качество десктопной и онлайн-версии одинаково.
Плюсы:
- Качество
- Интерфейс
- Многообразие форматов файла
Источник: itlang.ru
100 (или почти сто) секретов сканирования, распознавания и редактирования текста с картинки, фото
Возможно ли изменение сканированного текста? Можно ли отредактировать сканированный текст, чтобы потом использовать его с другими целями? Да, дорогие друзья! Сегодня это не только возможно, но и вполне легко делается.
При наличии необходимости, желания, а также некоторых технических возможностей вам легко дастся:
- сканирование рукописного текста (например, конспекта),
- сканирование текста с фотографии или картинки,
- редактирование,
- распознавание текста после сканирования,
- преобразование текста в виде картинки в обычный текст, в котором вы можете изменить сканированный текст (например, в документе pdf) документа и др.
В общем, сделать с текстом на картинке сегодня можно все то же самое, что и с обычным текстом в вордовском документе. А делать это жизненно важно и полезно тем, кто постоянно имеет дела с многочисленной документацией и тратит много времени – то есть и для студентов в том числе. Давайте разбираться, как это делается.
Чем отличается сканирование от распознавания?
Как оказалось, сканирование и распознавание текста – это разные вещи. Сканирование листов документа – это его перевод текста в электронный вид. Делается это через сканер или при помощи обычного фотографирования на смартфон или цифровую камеру.
Распознавание – это преобразование сканированного документа (текста) в электронный вид.
Кстати! Для наших читателей сейчас действует скидка 10% на любой вид работы
Что нам понадобится для сканирования и распознавания текста по фото ?
Для сканирования и распознавания текста нам не обойтись без кое-каких вещей:
- Сканер. Собственно, роль сканера может выполнять не только этот вид техники, но и фотоаппарат (в смартфоне, например). Если вы пользуетесь сканером, убедитесь, что на компьютере установлены системные драйвера и программы, необходимые для его полноценной работы. Если сканера нет, но вы собираетесь его купить, обратите внимание на скорость обработки одного листа. Некоторые приборы обрабатывают лист за 10 секунд, другим для этого понадобится 30 и более. И если работать вам придется с объемными материалами по 300-400 листов, то этот фактор имеет значение.
- Программы для распознавания текста или онлайн-сервисы. Мы уже писали статью по сервисам, которые помогают распознать текст после сканирования документа через сканер. Но сейчас хотели бы посоветовать вам программу ABBYY FineReader. Несмотря на то, что она платная, ее функционал поистине впечатляет. И если вы будете работать с огромными объемами документов, она станет вашим незаменимым помощником. Впрочем, есть и бесплатный ее аналог Cunei Form, которая отлично справляется со сканированием и распознаванием текста онлайн. Правда, ее функционал сильно ограничен по сравнению с предыдущим собратом.
- Документы для сканирования. Студентам часто приходиться сталкиваться со сканированием документа в виде журналов, статей, книг, конспектов, распечаток, откуда потом зачастую нужно скопировать текст. И просто так, в виде совета – перед началом сканирования постарайтесь поискать эти документы в сети. Если до вас этими материалами уже пользовались, существует огромная вероятность, что добрый человек уже проделал всю работу за вас. Атк что вам останется только скопировать текст готового сканированного документа и заняться редактированием текста после сканирования.
Параметры сканирования текста
Итак, сканер купили, документы подготовили, программы установили. Что дальше? Дальше нам нужно будет сделать нужные настройки, которые тоже порой помогают существенно облегчить задачу, например, распознать сканированный текст в определенном формате, редактировать текст после сканирования в определенном режиме и так далее.
В общем, от настроек будет зависеть качество и скорость вашей работы. Итак, разбираемся вместе.
DPI-качество
Это разрешение изображения, которое будет важно при редактировании текста в сканированном документе. Ставьте в настройках качество не меньше 300 DPI, а если возможно — то больше. Чем выше эта величина, тем более четким получится изображение после сканирования.
А от четкости будет зависеть скорость обработки. То есть исправить или изменить сканированный текст, текст сканированного листа будет быстрее, а еще программа сделает меньше ошибок (да-да, программы тоже ошибаются, но обо всем по порядку).
Цветность
Благодаря этому параметру можно влиять на скорость сканирования текста. Как правило, в сканерах есть 3 режима: черно-белый (подходит для листов с обычным печатным текстом), серый (подходит для работы с документами с таблицами и простыми картинками), цветной (для журналов, книг и остальных документов, где цвет играет значение). Чем меньше цвета, тем выше скорость обработки документа.
Фото
Как мы уже говорили, для сканирования можно использовать не только сканер, но и фотографирование. Но здесь будьте осторожны – любое смазывание, нечеткость и прочие искажения изображения могут повлиять на дальнейшее распознавание и редактирование текста в сканированном документе.
Распознавание
Итак, отсканировали и получили странички в электронном виде. Затем открываем программу для распознавания (например, FineReader) и начинаем распознавать текст. Некоторые программы (в том числе и наша) делают этот процесс с ошибками. Тогда область с ошибкой нужно будет выделять вручную.
Работа с текстом
В области Текст можно будет выделить текст. Любые таблицы и изображения можно будет удалить. А вот для работы с необычными и редкими символами придется поработать ручками. Вот как это выглядит в программе:
Картинки
Эта область в программе используется для работы с изображениями и с теми областями текста, которые плохо поддались распознаванию.
Таблицы
Кнопка выделения таблиц помогает работать с таблицами. Однако эта функция не очень хорошо развита. Иногда проще использовать редактор Картинка для работы с таблицами. Это сэкономит кучу времени и нервов, а доработать все потом можно в обычном ворде.

Лишние элементы
Если на странице остались элементы, которые вам совершенно не нужны или бесполезны, выделите ненужную область и удалите ее с помощью ластика. Достаточно перейти в режим редактирования и провести работу. Причем чем больше ненужных элементов вы уберете, тем быстрее будет происходить процесс распознавания текста.
Проверка ошибок и сохранение результатов работы
Как мы уже говорили, ошибки могут возникать тогда, когда вы используете некачественные, смазанные, нечеткие изображения или документы с редкими символами. Поэтому всегда проверяйте документ после процесса распознавания.
Нашли? Замечательно – просто введите нужный символ. Кстати, в программе есть режим проверки, который поможет быстро и без вашего участия проверить документ на наличие ошибок программы. И сразу же после окончания проверки можете прямо из программы импортировать документ (сохранить его в формате) в ворд или любую другую программу.
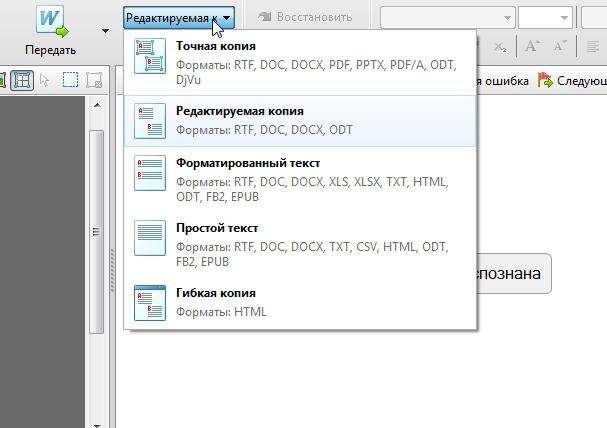
Тип копии
При сохранении документа (в режиме редактирования) вам предложат сохранить его в трех видах копии. Точная копия – это полная копия сканированного документа со всем произведенным форматированием. Если вы потом планируете редактировать текст после сканирования в ворде, то лучше всего выбрать именно этот вариант.
Редактируемая копия помогает сохранить уже отредактированный текст. Хорошо подходит, если вам предстоит обильное последующее редактирование. Простой текст – идеально подходит для тех, кто хочет получить в итоге обычный текст без всех остальных элементов страницы.
Вот, собственно и все. Сложно, долго и нудно, но гораздо быстрее сканировать и распознать текст (даже рукописный) программой, чем переписывать 100500 документов вручную. Ну а если вам и этим некогда заниматься – обращайтесь за помощью в студенческий сервис. Тут вам быстро, дешево и качественно выполнят все, что нужно.
Мы поможем сдать на отлично и без пересдач
- Контрольная работа от 1 дня / от 120 р. Узнать стоимость
- Дипломная работа от 7 дней / от 9540 р. Узнать стоимость
- Курсовая работа от 5 дней / от 2160 р. Узнать стоимость
- Реферат от 1 дня / от 840 р. Узнать стоимость
Наталья – контент-маркетолог и блогер, но все это не мешает ей оставаться адекватным человеком. Верит во все цвета радуги и не верит в теорию всемирного заговора. Увлекается «нейрохиромантией» и тайно мечтает воссоздать дома Александрийскую библиотеку.
Источник: zaochnik.ru