
Всем привет! Типичная ситуация сложилась в компании, в которой я работаю. В бухгалтерии вечный аврал, людей не хватает, все занимаются чем-то безусловно важным, но по сути бесполезным. Такое положение дел не устраивало руководство.
Если подробнее, то проблема в том, что ресурсов бухгалтерии не хватает на текущие задачи, а выделять ставки под новых людей никто не хочет. Поэтому сверху приняли решение порезать некоторые задачи и освободить время бухгалтеров для более полезных дел. Под нож попала такая работа как сканирование и распознавание документов, копирование, внесение их в прочие рутинные радости.
Так передо мной, как аналитиком, встала задача: найти решение для распознавания документа типичного для моей компании — счет-фактуры — структурировать его в имеющиеся хранилища, а также в 1С. Решение, которое будет удобным, понятным, и не влетит компании в копеечку.
Опыт получился занятным, решил поделиться тем, что удалось собрать. Возможно я что-то упустил, поэтому велком в комментарии, если есть, что добавить.
Как скопировать текст с фотографии и картинки. Распознавание текста онлайн бесплатно с телефона и пк
Программы сканирования документов, программы распознавания документов — не новое решение на рынке, его можно найти как в бесплатных программах, так и встроенных в системы.
Начал я с бесплатных программ:
- glmageReader
- Paperwork
- VietOCR
- CuneiForm.

- В таких программах как VietOCR, Paperwork, glmageReader можно настроить хранение отсканированных документов в определенные папки, Paperwork умеет их даже сортировать, согласно меткам.
- В основном они хорошо справляются с текстом, а там, где текст распознан некорректно, в некоторых программах можно вручную изменить содержимое, прежде чем экспортировать файл.
Однако есть и проблемы:
- Есть разница между работой с pdf сканами и png. Не всегда удается удачно конвертировать png в pdf.
- Большинство таких программ сложно справляются с распознаванием документов табличного вида, даже самого простого формата. В результате мы получаем распознанный текст без размеченных полей.


Пишем программу на Python для распознавания текста
Технология сработала достаточно хорошо, Учитывая, что программы бесплатные, описанные выше проблемы допустимы. Однако, я искал более упорядоченного решения.
Затем я исследовал распознавание в ABBYY FineReader 15 Corporate
За 7-дневный срок триала я изучил и эту платформу.
- Когда я открыл png файл, он отлично был считан и в результате удачно конвертирован в pdf без потери качества изображения и текста.
- Программа отлично знает, как отсканировать документ для редактирования текста. Причем в режиме редактирования файла формата png текст удается отредактировать без проблем, но иногда слетает разметка.
- Однако то же самое я не могу сказать про редактирование файла-скана pdf. При попытке редактирования летели слои.
- Табличный вид распознается качественно, вся структура сохраняется, меня это порадовало.
- OCR редактор хорошо распознал мой сформированный pdf счет-фактуры. Где-то пару символов требовалось поправить вручную.

Однако, была ситуация, что почти весь подобный документ распознался с меньшей точностью и данных для изменения вручную было уйма. Думаю, здесь можно было бы решить вопрос технически, но это затратило бы больше времени.

От использования этого софта были приятные впечатления. Однако, когда я обратился к ценнику системного решения ABBYY Flexicapture (а мне нужно именно системное), то выяснил, что решение, особенно кастомизированное, обходится в довольно круглую сумму, около 400 тыс. руб./мес. и выше за 10 тыс. страниц.
Я стал искать альтернативу. Как освободить руки сотрудника, получить качественное распознавание документов и не переживать за сохранность и структуру данных.
И тут я решил получше разглядеть ELMA RPA, которую я уже изучал ранее.
Вендор предлагает перекинуть значительную часть работы по экспорту данных в ERP с плеч бухгалтеров на роботов. По сути, именно это решает поставленную передо мной задачу. Чтобы познакомиться с распознаванием в этой системе, я взял у вендора триальную версию системы.
Здесь я обнаружил, что распознавание не преследует цели конвертировать полученные данные в новый документ-файл.
Здесь главная цель — распознавание реквизитов документа и их передача в другие системы/сайты/приложения. Кроме того, роботы складывают всю информацию куда надо: автоматически находят нужные папки и сохраняют в необходимых форматах.
Какие виды распознавания в системе я посмотрел:
Распознавание по шаблону
Нам предлагается на основании шаблона документа распознать подгружаемый документ. Насколько мне известно, этот вид распознавания бесплатный, внутрь зашит движок Tesseract.
- Этот вид распознавания работает именно со сканами формата jpg и png, pdf он пока не рассматривает. Но продукт еще молодой, думаю, все впереди.
- Этот вид распознавания входит в бесплатную версию Community Edition
- Удобно размечен текст по блокам, которые можно сопоставить, согласно переменным, которые мы создали в контексте робота. Таким образом вручную настроить, что именно тянем в распознавание.
- Нашу счет-фактуру он распознал 50/50, некоторые слова подменил как посчитал нужным. 🙂

Однако, вендор на данный кейс сообщил, что этот вид распознавания адаптирован под простые документы, с текстовой структурой или с легкими формами. И посоветовал для распознавания счета-фактуры использовать другой вид распознавания — intellect lab.
Процесс тот же, загружаем шаблон и по нему распознаем. Но здесь шаблон отправляется на облачный сервер.
От сервера получаем ответ (распознает такой тип документа или нет), и если распознается, то передается структура шаблона (переменные для маппинга), для сопоставления переменных, которые необходимо будет записать в RPA процессе.
В процессе воспроизведения мы отправляем уже документ, который хотели бы распознать и получаем ответ от iLab сервера о распознавании.
Что отметил по поводу этого распознавания:
- Здесь уже распознавание работает как программа сканирования документов pdf, и при этом работает и с форматами jpg и png.
- Качество документа не влияет на эффективность распознавания. Даже документы с плохим качеством распознаются корректно.
- Счет-фактура распозналась полностью и без подмен переменных.
- Робот сумел получить скан с почты, распознать его и создать его экземпляр в 1С. То есть автоматически сохранил файл там, где мы ему задали, что, естественно, крайне удобно.
- Входит в бесплатную Community Edition в виде распознавания документа в облаке. Подходит, если используем стандартные типы (СФ, УПД, АВР и др.), и, например до 100 документов в месяц или до 500 в год. (Стоит заметить, что считаем не в страницах, а в документах непосредственно.)
Соответственно, эти же данные робот записывает в 1С, создавая там новый документ:
Что удалось выяснить по ценам: Если мы, например, хотим работать масштабно именно с ilab распознаванием, то за наши 10 000 документов придется выложить:
- примерно 180 000 руб. единовременно,
- плюс, допустим, 400 000 руб. покупка робота с оркестратором
- итого: 580 000 руб.
Что понравилось в распознавании в этой платформе в целом:
- Можно настроить получение документов по событию, а также, например из электронной почты и любых других внешних источников. У меня пока была цель настроить получение с почты.
- Все считанные данные с документа можно спокойно записать в контекстные переменные и далее их передать в необходимые системы, приложения, сайты, ВМ и т д. И я не переписываю уже ничего руками.
- Скорость обработки. 15 секунд и объект распознан, а остальной порядок действий — это счет по минутам. Если заявиться с потоковым сканированием с большим количеством документов, думаю это не составит больших временных затрат.
- Много качественного функционала в свободном доступе, для небольших компаний им можно вполне обойтись.
Итого:
- Бесплатные программы справляются с задачей распознавания документов лучше, чем я предполагал, однако за счет них значительно ускорить работу с большим объемом не удастся
- ABBYY FineReader хорошо справляется с обработкой и распознаванием документов после, однако, чтобы получить системное решение, нужны большие финансовые возможности.
- ELMA RPA удивила по качеству распознавания документов, вариативностью, а также возможностям хранения и передачи после распознавания, но стоит учесть, что продукт молодой.
- rpa
- автоматизация рутины
- распознавание документов
- программа сканирование документов
- сервис распознавания документов
- abbyy распознавание документов
- распознавание реквизитов документа
- Искусственный интеллект
- Финансы в IT
Источник: habr.com
Программы для распознавания текста
онлайн и офлайн

![]()
![]() 3.1 Оценок: 126 (Ваша: )
3.1 Оценок: 126 (Ваша: )

Время чтения: 10 минут
При переводе бумажной документации в цифровой формат часто требуется преобразовать сканы в редактируемый формат. Для этого вам потребуется программа для распознавания текста. В этой подборке софта и онлайн-сервисов мы рассмотрим платные и бесплатные варианты для работы на ПК, телефоне и онлайн.
Альтернатива: PDF Commander
Требуется создать документ из отсканированных фото или отредактировать PDF-файл? Скачайте программу PDF Commander – он удобен в работе, подходит для новичков и профессионалов и справится с проектами любого типа сложности.
- Создавайте проекты с нуля, путем склеивание ПДФ-документов или фотографий.
- Встраивайте штампы одобрения или отклонения и ставьте личную подпись.
- Добавляйте новые объекты и работайте со структурой документа.
- Защищайте файл при помощи двухэтапного пароля.
PDF-редактор совместим со старыми и новейшими сборками операционной сестемы Windows и быстро работает на компьютере любой мощности, не нагружая его ресурсы.

Для Windows 11, 10, 8, 7 и XP
 Abbyy FineReader
Abbyy FineReader
Платформа: Windows, iOS, Android, веб
Лицензия: пробная, от 5388 в год
Распознает: JPG, TIF, BMP, PNG, PDF, сигнал со сканера, снимки камеры
Сохраняет: DOC, DOCX, XLS, XLSX, ODT, TXT, RTF, PDF, PDF/A, PPTX, EPUB, FB2
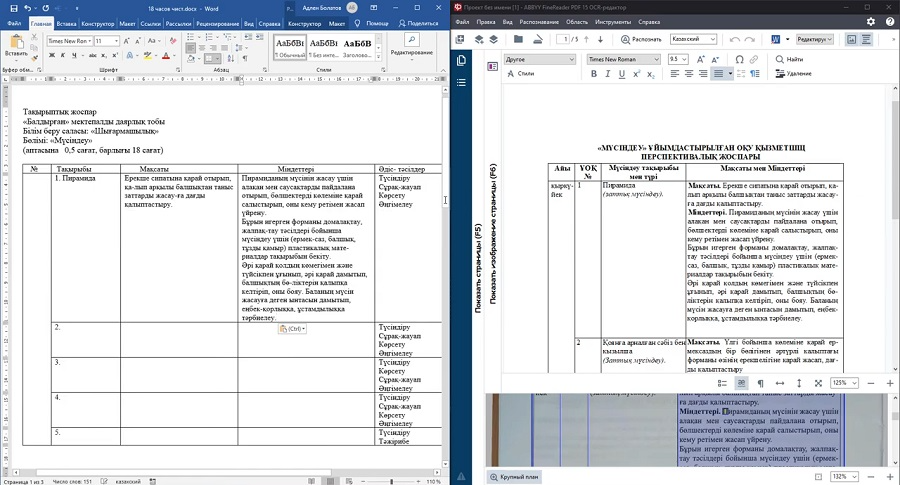
Abbyy FineReader известен своим точным модулем OCR, который позволяет быстро распознать текст с картинки. Приложение можно использовать как оцифровщик бумаг, так как он включает в себя инструмент для прямого перехвата фотографий со сканера. Их можно сразу сохранить в любой из доступных форматов, в том числе текстовые документы, HTML-файлы или PDF. Бесплатная версия накладывает ограничение на количество страниц: не более 10.
Особенности:
- большое количество доступных языков;
- оптимизация размера фотографий с минимальными потерями качества;
- автоматическая проверка орфографии и грамматики;
- работа с многостраничными документами;
- редактирование распознанного текста.
- высокая точность результата даже при невысоком качестве фото.
- способно отличать разные языки в документе;
- доступна для установки на все версии Windows с любой разрядностью.
- обновления приобретаются отдельно;
- требуется регистрация аккаунта на официальном сайте;
- сбивается оригинальное форматирование и стиль документа.
 OCR CuneiForm
OCR CuneiForm
Платформа: Windows, Linux, mac OS
Лицензия: бесплатная
Распознает: JPG, TIFF, BMP, PNG, снимки со сканера
Сохраняет: DOCX
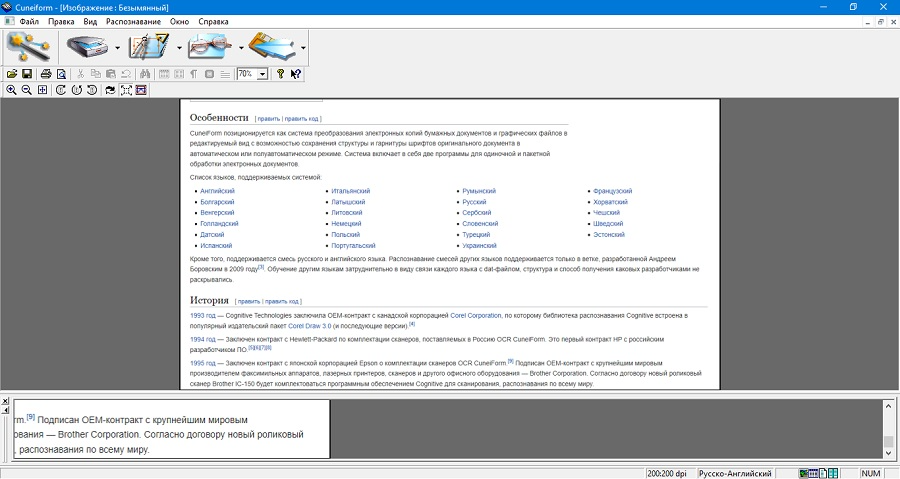
Программа для распознавания текста по фото OCR CUneiForm направлена только на одно действие – перехват со сканера изображений и преобразования содержащейся на них текстовой информации. Также допускается открытие графических файлов с персонального компьютера. После этого работу можно продолжить в любом текстовом редакторе. Разрешается работать в одиночном или пакетном режиме.
Особенности:
- может использоваться вместо стандартного софта для сканирования;
- преобразование графических файлов в редактируемый документ Ворд;
- анализ документа на наличие форм, таблиц, изображений;
- поиск по созданному текстовому файлу;
- распознавание на отдельных выбранных областях.
- сохраняет оригинальную структуру документа и его форматирование;
- можно запускать в автоматическом режиме или настроить параметры;
- специальный режим для матричного принтера.
- допускается разрешение не выше 600;
- показал не очень хорошие результаты с фото плохого качества.
 Office Lens
Office Lens
Платформа: Android, iOS
Лицензия: бесплатная
Распознает: фотографии с камеры
Сохраняет: PDF, PPT, DOCX
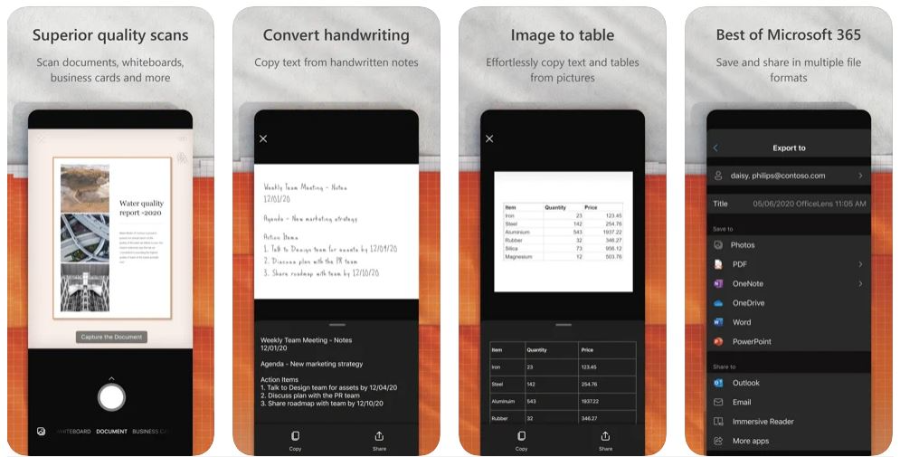
Ранее Office Lens (также известный как Microsoft Lens) был доступен для ПК, но теперь корпорация прекратила поддержку десктопной версии. Приложение превращает ваш телефон в продвинутый сканер, автоматически анализируя окружение и делая снимок документа. Возможна работа в том числе со снимками с неправильным отображением (положенные боком, перевернутые, лежащие на неровной поверхности и т.д.).
Особенности:
- корректировка результата после создания снимка;
- извлечение печатного и рукописного текста на русском и английском языке;
- распознавание таблиц и контактов;
- создание многостраничного документа из фотографий.
- полностью бесплатный;
- есть разные пресеты и настройки для документов (лист, фото, доска, визитка);
- отправка файлов в облачные хранилища.
- для подключения модуля OCR требуется регистрация аккаунта;
- некорректные результаты при извлечении русских букв.

Adobe Scan
Платформа: Android, iOS
Лицензия: условно-бесплатная; от 349 рублей
Распознает: фотографии с камеры
Сохраняет: PDF
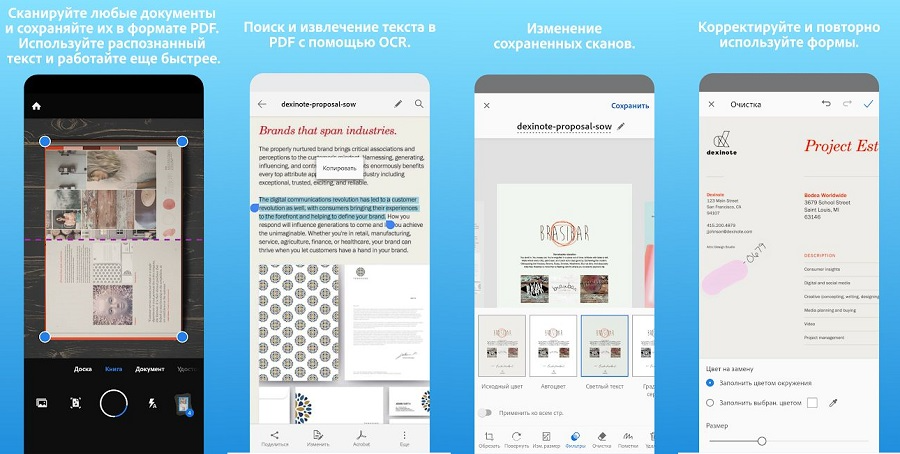
Как и продукт от Microsoft, Adobe Scan также сканирует текстовые данные через мобильную фотокамеру. Результат сохраняется как PDF-документ, оптимизированный для редактирования в программном обеспечении Acrobat. Все результаты сохраняются автоматически в облако Adobe Document Cloud.
Особенности:
- подходит для разного типа информации: книга, доска, удостоверение, визитка;
- автоматическое сканирование окружения на предмет документов;
- редактирование созданных фотографий;
- расшифровка и использование встроенных форм.
- не требует оплаты;
- на файлы можно накладывать защиту;
- корректно работает с русскими буквами.
- нет автоматического сохранения;
- для использования приложения обязательно требуется регистрация.
Online OCR
Платформа: веб
Лицензия: условно-бесплатная
Распознает: JPG, GIF, TIFF, BMP, PNG, PCX, PDF
Сохраняет: TXT, DOC, DOCX, XLSX, PDF
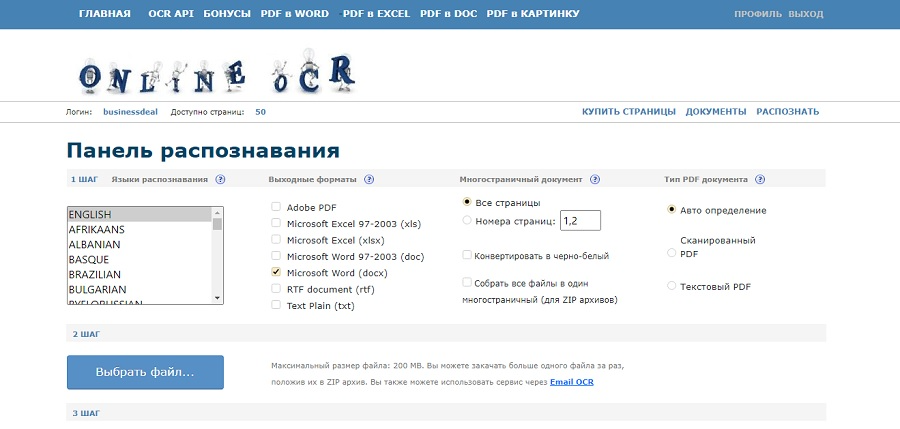
На этом сервисе пользователи могут провести распознавание текста бесплатно и сохранить результат в редактируемые текстовые файлы без установки софта. Поддерживается работа со сканами, популярными форматами графики, сканами и PDF. Без регистрации и оплаты доступно распознование только 15 страниц в час. После авторизации данный лимит повышается до 50, а также увеличивается допустимый размер (200 МБ).
Особенности:
- обработка текста в зависимости от особенностей оригинального языка;
- редактирование результата в режиме прямого времени;
- объединение обрабатываемых файлов в единый проект;
- анализ отдельных страниц документа.
- удобное русскоязычное управление;
- автоматический определитель типа документа;
- ведется история загружаемых файлов.
- загруженные снимки нельзя отредактировать;
- не всегда корректный результат.
img2text
Платформа: веб
Лицензия: бесплатная
Распознает: JPEG, PNG, PDF
Сохраняет: PDF, TXT, DOCX, ODF
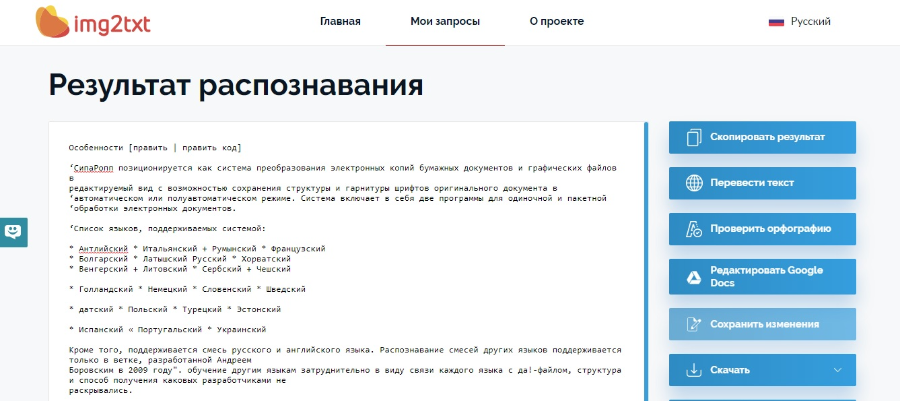
Бесплатный инструмент работает с популярными форматами графики и нередактируемыми документами ПДФ. Сервис ведет журнал ваших действий, поэтому при внезапном прерывании сети можно вернуться к работе без вторичной загрузки. Разработчики постоянно улучшают свой продукт и добавляют новые возможности, на данный момент в ней есть переводящая утилита, также анонсирована опция импорта файла по ссылке.
Особенности:
- изменение преобразованного текста прямо на сайте;
- перевод иностранных документов;
- проверка орфографии;
- копирование результата в буфер обмена.
- работает полностью на бесплатной основе;
- быстрая скорость загрузки и обработки.
- документ не должен содержать картинок, таблиц и колонок;
- некорректно работает с файлами, в которых используется несколько языков.

Microsoft OneNote
Платформа: Windows, macOS
Лицензия: бесплатная
Распознает: JPEG, TIFF, PNG, BMP
Сохраняет: JPEG, TIFF, PNG, BMP
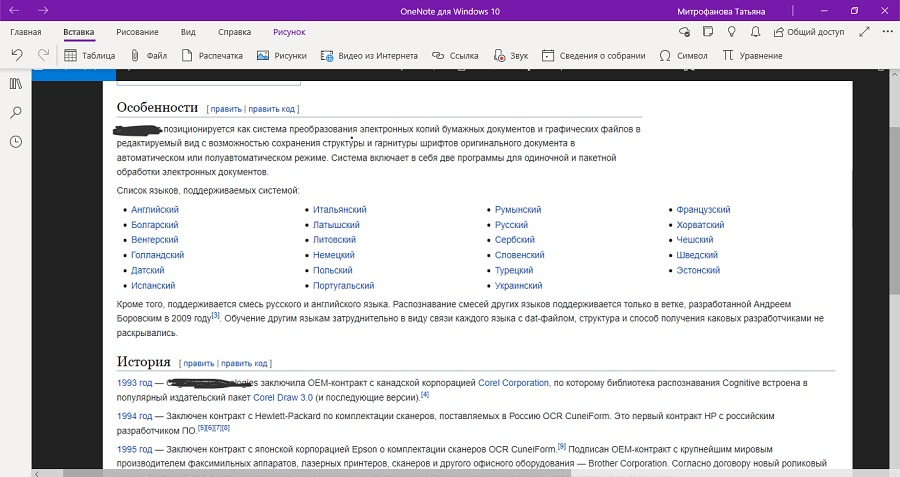
Записная книжка от разработчика Microsoft работает как отдельная программа, также ее можно приобрести в пакете с офисным ПО MS Office. Хотя софт также распространяется как мобильное приложение, распознавание текста с картинки поддерживается только в десктопном варианте на компьютере. Хотя изменять информацию на картинках нельзя, данные можно скопировать и вставить в текстовой редактор.
Особенности:
- загрузка фотографий с жесткого диска или подключенной фотокамеры;
- скрытие выбранных областей фотографии;
- можно добавлять пометки и конвертировать их в редактируемый текст;
- прослушивание открытого текста.
- автоматические бэкап в облако предотвратит потерю важных данных;
- есть опция переводчика текста и проверка орфографии в документе.
- требуется вход с учетной записью Microsoft;
- текст на фотографиях нельзя исправлять.
 Readiris 17
Readiris 17
Платформа: Windows, macOS
Лицензия: пробная; от $129
Распознает: JPEG, TIFF, PNG, BMP, PDF
Сохраняет: PDF, TXT, PPTX, DOCX, XLSX
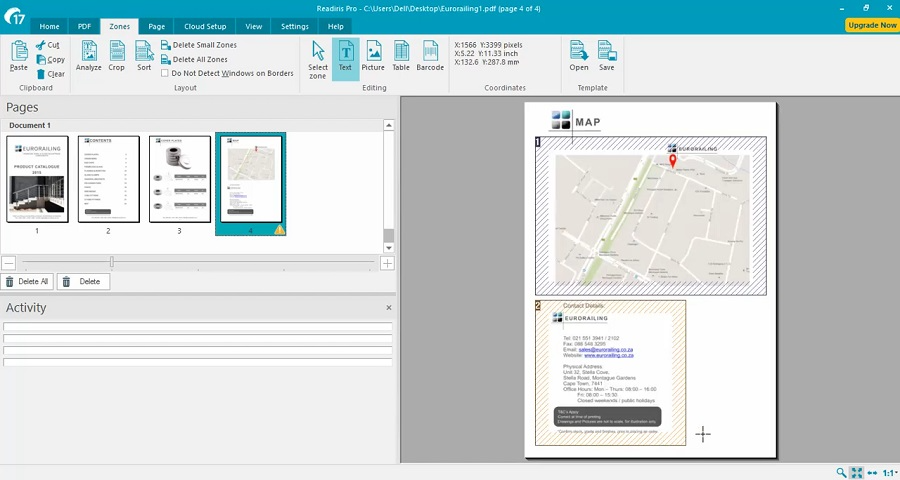
Readiris – один из немногих PDF-редакторов, умеющий различать печатный текст и даже ручной почерк и преобразовать его в стандартный текстовой массив. Программу можно использовать как сканер текста с фото, так как она работает со всеми популярными моделями сканирующих устройство. Софт корректно распознает кириллические символы и показывает высокую точность результатов. Пробная версия доступна в полном функционале в течение 10 дней.
Особенности:
- позволяет перехватывать и оптимизировать картинки со сканера;
- работает с более чем 170 языками и проверяет ошибки;
- сохраняет оригинальное форматирование документа;
- распознает таблицы, штрих-коды, формулы, нестандартные символы.
- имеется пакетный режим;
- присутствуют инструменты редактирования.
- неудобная рабочая панель;
- высокая стоимость полной версии.
 Freemore OCR
Freemore OCR
Платформа: Windows
Лицензия: бесплатная
Распознает: JPEG, TIFF, PNG, BMP, PSD
Сохраняет: DOC, TXT
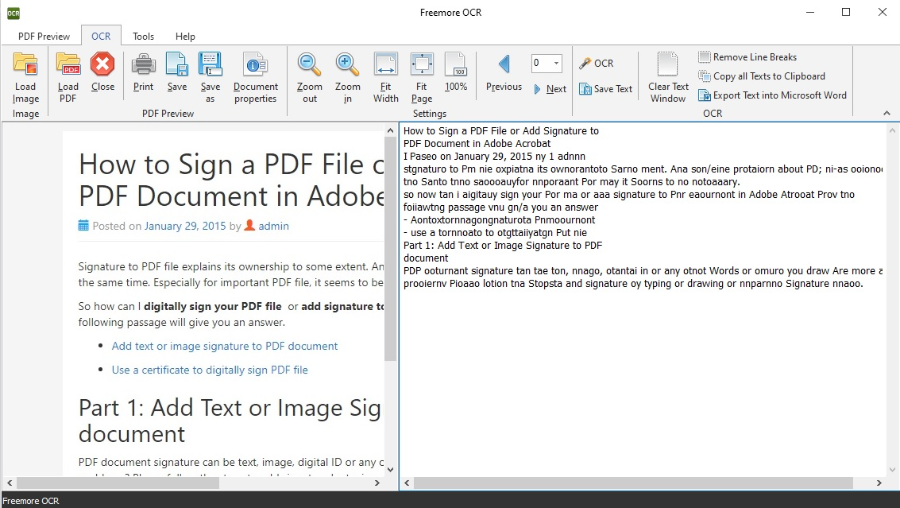
Freemore OCR – простая в управлении программа, считывающая текст с изображений или из нередактируемых ПДФ. Работа проводится в двухоконном режиме, что особенно удобно при проверке точности результатов. Стоит отметить, что при загрузке файл помечается как подозрительный, при установке некоторые антивирусы требуется на время отключить.
Особенности:
- корректно распознает текст, расположенный вокруг графических элементов;
- позволяет встраивать цифровую подпись;
- имеются возможности ручного редактирования результата;
- экспорт как новый файл или копирование всего текста в буфер обмена.
- работает с защищенными паролем файлами;
- очень простое в управлении меню.
- не распознает кириллицу;
- при установке подгружает рекламный софт.
 Scanitto Pro
Scanitto Pro
Платформа: Windows
Лицензия: условно-бесплатная; 499 руб
Распознает: PDF, BMP, JPG, TIFF, JP2, PNG
Сохраняет: DOCX, RTF, TXT, PDF
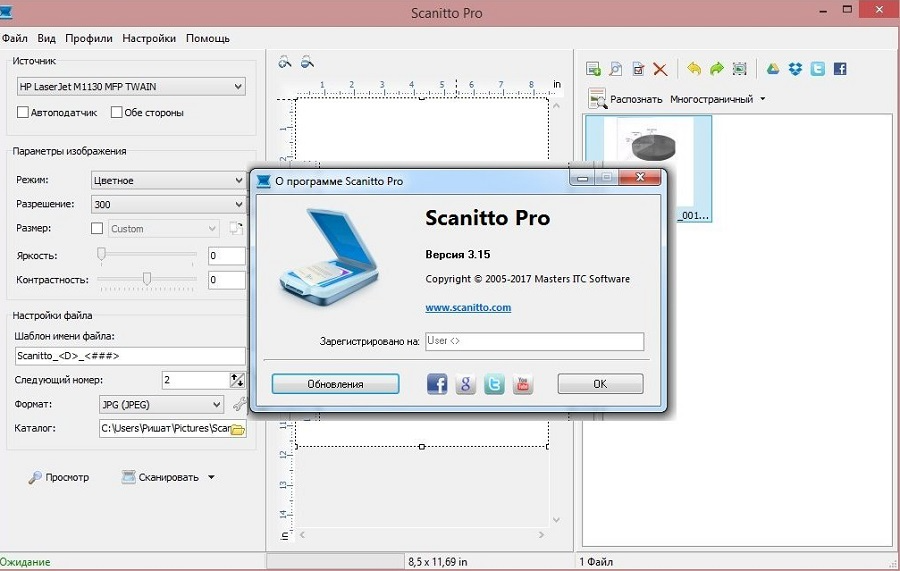
Если нужен сканер с распознаванием текста, выбирайте это простое средство для преобразования ксерокопий в документ. Софт работает с подключенным устройством, подменяя встроенную по умолчанию программу сканирования. Отличается удобными функциями выборочного анализа, разрешая отмечать фрагменты, которые нужно распознать.
Особенности:
- просматривайте результат перед выводом на экспорт;
- объединение изображений в многостраничные документы;
- поворот скана и очистка для шума для более точного анализа;
- оптическое распознавание более 7 языков (включая русский).
- удобный пользовательский интерфейс с минимумом настроек;
- минимальные требования к системе и процессору компьютера.
- нельзя загружать фото с жесткого диска;
- сбивает структуру и удаляет оригинальное форматирование текста.
В заключение
Надеемся, что наш обзор помог вам понять, какая программа для сканирования и распознавания текста подойдет для вашей задачи. Все рассмотренные приложения в целом достойно справились с анализом сложных фото и показали высокую скорость работы. А если вам требуется обработка сохраненного ПДФ-файла, советуем скачать бесплатно PDF Commander. Он поможет создать из распознанного текста полноценный документ и разнообразить его дополнительными элементами.
Источник: free-photo-editors.ru
Лучшие бесплатные OCR-сервисы для распознавания и конвертации PDF
Привет всем! Я расскажу о сервисах для распознавания текста или OCR. Считайте это небольшим рейтингом лучших OCR-утилит.

Оптическое распознавание символов (OCR — Optical Character Recognition) — механизм электронного или механического конвертирования изображения или печатного текста, например, с отсканированного документа, фотографии и т.д.
Я испытаю следующие программы и сервисы:
- PDF — Adobe Acrobat Pro — эталон всех распознавателей.
- PDF24 tools — богатый инструментарий для работы с PDF-документами, включает OCR.
- NewOCR — заявляют себя как сервис конвертации в текст форматов: JPEG, PNG, GIF, BMP, TIFF, PDF, DjVu.
- Img2txt — сервис отличается красивым интерфейсом, но спасёт ли его это?
- Free Online OCR — простецкий онлайн-сервис для распознавания.
Чтобы результат был наглядным и достоверным, нужно протестировать. Для этого я подготовил специальные документы:
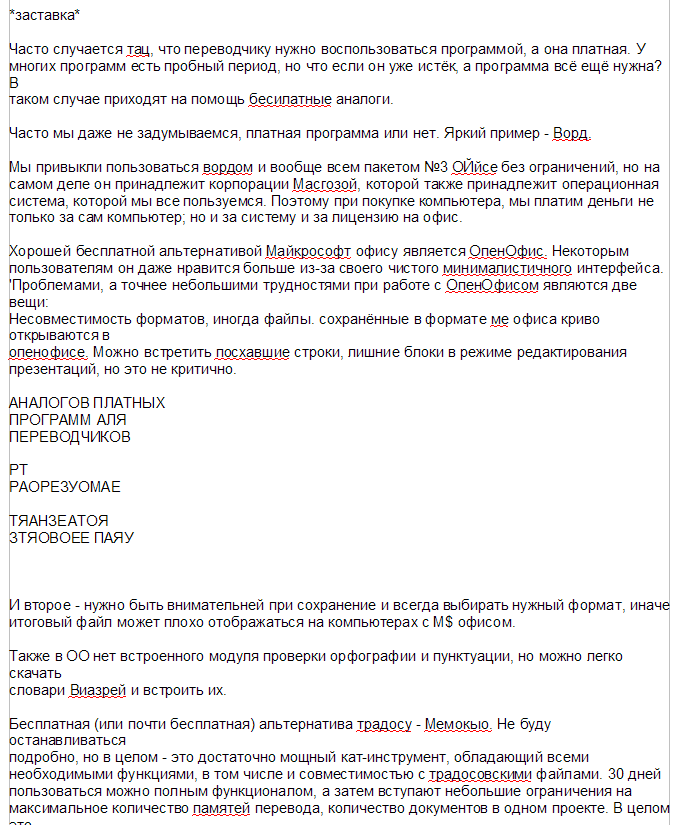
- Фрагмент статьи “8 бесплатных аналогов платных программ для переводчиков”. Текст был написан в ворде, затем переведён в PDF. Сложность может представлять надпись нестандартным шрифтом, мелкие буквы, а также текст на эмблеме, но в целом документ простой и имеет текстовый слой.
- Тот же фрагмент, но без текстового слоя — скрин, завёрнутый в PDF. Базовые сложности те же, только к ним ещё добавляется необходимость распознавания всего остального текста и необходимость сохранить форматирование.
- Рекламная брошюра масел. Сложное и разное форматирование, местами текстовый слой есть, местами его нет. Отнюдь не простой документ. Посмотрим, справятся ли конкурсанты.
Adobe Acrobat Pro
Я попробую сравнить качество распознавания при конвертировании в редактируемый формат между бесплатными сервисами и эталоном — Adobe Acrobat DC.
Adobe Acrobat DC идёт первым как эталон, созданный для одной задачи — для работы с pdf-файлами.
Простой файл с текстовым слоем:

Ожидаемо. Никаких трудностей. Полная конвертация в редактируемый формат. Изображение по центре осталось нетронутым, но это невеликая проблема, можно подписать или обработать в Paint.
Простой файл без текстового слоя:

Нестандартный шрифт не распознался, но мелкий шрифт под звёздочкой распознался достаточно хорошо. Ещё пару букв пропустил, но допустимая погрешность для последующего ручного редактирования.
Сложный файл с непостоянным текстовым слоем:

Как сказать. Результат ожидаемо плохой, потому что файл очень сложный. Впрочем, отредактировать всё равно можно, лучше, чем ничего.
Почему я не взял на тест больше программ для ПК? А их нет. Существует несколько простых программ, которые распознают только изображения или устанавливают на компьютер мусор. Я пробовал: Free OCR, Simple OCR, CuneiForm OCR, Freemore OCR. Вторая категория — это титаны вроде Abbyy или Adobe, которых мы стараемся избежать в этой статье.
Итак, перейдём к онлайн-сервисам.
PDF24 tools
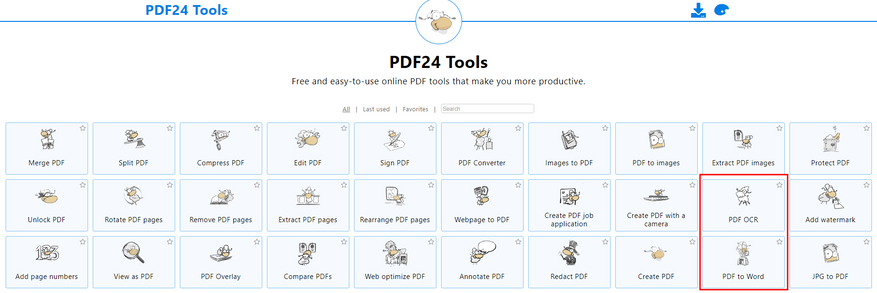
PDF24 tools — многогранный сервис. Он может распознать текст в PDF, но в результате всё равно выдаст PDF. На наше счастье среди утилит этого сайта есть и конвертер в Word. Они даже расположены рядом.
Простой файл с текстовым слоем:

Получилось очень плохо, но текст типа сохранён полностью. Изображение вырезано и половина страницы пустая. Ладно, сочтём, что так и должно быть.
Простой файл без текстового слоя:
С задачей сервис не справился. После распознавания и конвертации в ворд, я увидел пустой лист.
Сложный файл с непостоянным текстовым слоем:
Результат оказался таким же — пустой лист. Но сервис предлагает три режима конвертации:
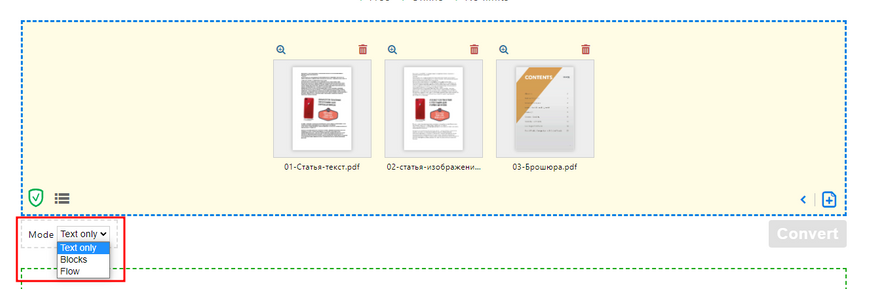
Я попробовал все три, лучший результат выдал третий режим «только текст»:

Распознался даже сложный шрифт!
Брошюра тоже распозналась, но легче мне от этого не стало:

Спорный сервис. Конвертирует и распознаёт быстро и удобно, много разных утилит. Пусть будет, конечно, на крайняк покатит.
NewOCR
NewOCR — нашёл в одной из статей про лучшие сервисы распознавания символов на просторах интернета. Говорят, что сервис хороший.
Простой файл с текстовым слоем:
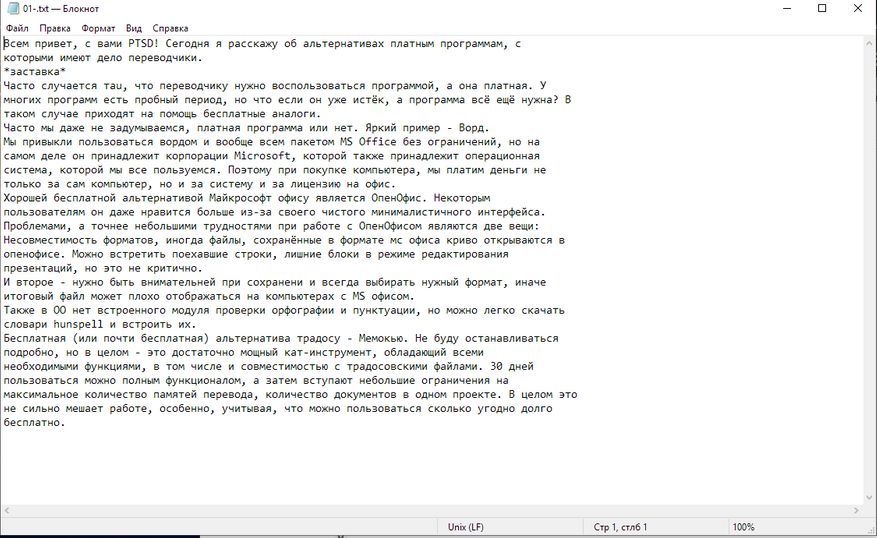
Текст распозанёт хорошо, но предлагает выбрать только формат .txt, не распознаёт картинку и даже не пытается сохранить форматирование.
Простой файл без текстового слоя:

Неплохо распознал основной язык — русский, но ужасно справился с английским. Вся латиница превратилась в какую-то кашу. С другой стороны распознать получилось даже нестандартный шрифт с картинки. Не без ошибок, нор всё же. А ещё удалось получить формат Word.
От чего это зависит — не знаю.
Сложный файл с непостоянным текстовым слоем:
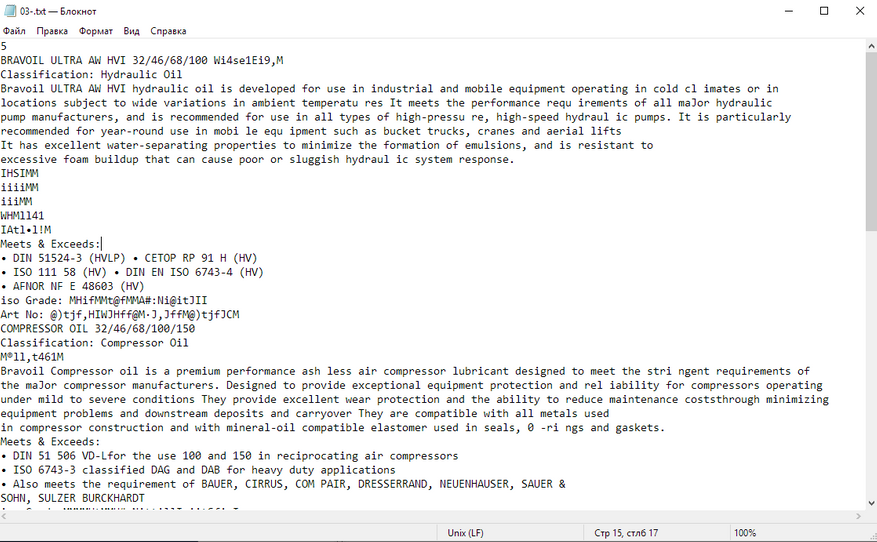
Брошюра тоже распозналась косячно. Вместо многих символов ужасные кракозябры, слова собрались в кашу, формат только .txt. Зачем мне нужно вот это? Легче отредактировать скриншоты в paint, чем так.
Сервис неплохо справляется с распознаванием текста, но что-нибудь сложнее, чем абзацы текста ему не под силу. Если в тексте встречается несколько языков, то один из них обязательно будет воспринят неправильно. Даже если указать два языка в поле перед распознанием. Про форматирование можно забыть, его здесь не будет.
А ещё мне не понравилось, что каждую страницу многостраничного документа придётся распознавать и скачивать отдельно. Документ на 50 страниц? Простите, но придётся выкачивать по одной странице за раз. А ещё придётся подождать 5 секунд перед распознанием очередной страницы. Не больше ни меньше. Если попытаетесь распознать быстрее, получите ошибку.
А ещё не всегда с первого раза точно прицеливается в страницу, иногда выхватывает маленький фрагмент страницы и пытается его распознать.
Img2txt
Сервис Img2txt. Нашёл его где-то на просторах интернета в комментариях к статье о лучших сервисах.
Простой файл с текстовым слоем:
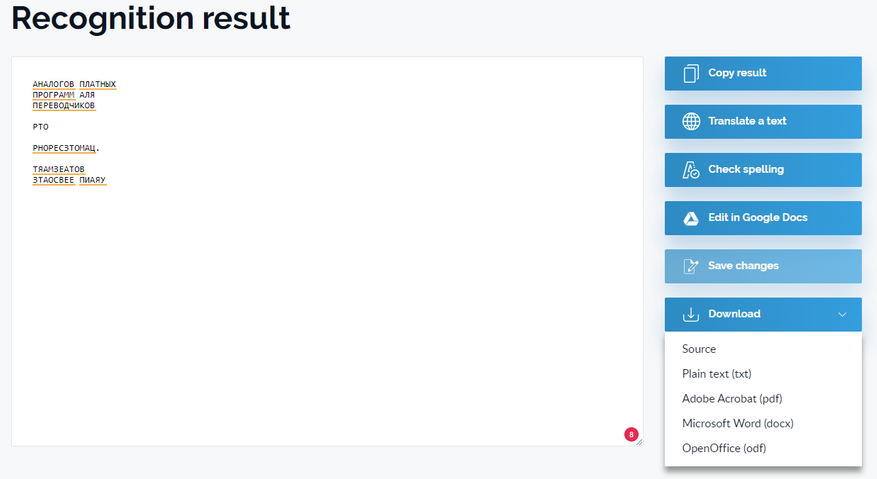
Крупный текст распознал, мелкий превратил в кашу. Решил, забить на текстовый слой и распознал только картинку. Странное решение. Зато предлагает много форматов.
Простой файл без текстового слоя:
Не сказать, что плохо, но и не сказать, что хорошо. Некоторые буквы перепутал, латиницу не распознал. Но по крайней мере можно скачать в вордовском формате.
Сложный файл с непостоянным текстовым слоем:
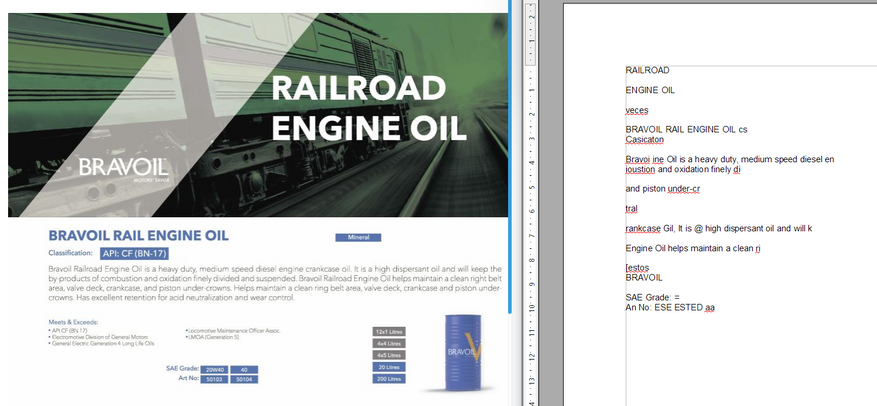
Куцый результат. Распозналось плохо, большая часть текста пропущена, слова в кашу превратились. Получилась бесполезная белиберда.
Ещё один сервис, который распознаёт неплохо простые документы с большими абзацами текста. Раздражает, что сначала нужно загрузить файл, выбрать для него язык, потом файл обработается сервером, нужно снова выбрать для него язык и запустить распознавание. Я как-то ожидал, что загружая я уже достаточно чётко выражаю намерение распознать файл.
Ещё одна беда — это постраничное распознавание. Как и в случае с NewOCR каждая страница распознаётся отдельно, скачивается отдельным документом. Только тут ещё необходимо для каждой новой страницы повторно выбирать язык.
А ещё это единственный сервис с ограничением размера файла. Максимум — 8 мб.
Online OCR
Online OCR — сервис с самым непримечательным названием. Я упоминал этот сервис в статье про 8 бесплатных аналогов платных программ.
Простой файл с текстовым слоем:

Ого. Результат удивляет. Почти идеальный. Мало того, что распознание прошло почти мгновенно, так ещё и латиница распозналась там, где надо. Даже мои опечатки были распознаны правильно. То что текст вокруг картинки — это ерунда.
Чуть-чуть не дотянул до уровня Adobe.
Простой файл без текстового слоя:

Снова в яблочко! В этот раз побольше промахов, но результат достойный. Хотя бы картинка сохранилась и часть мелкого текста с неё удалось распознать.
Сложный файл с непостоянным текстовым слоем:

Ух ты! Сервис справился с распознаванием и этого документа! Удивительно, но факт. Есть некоторые недочёты, но это очень хороший результат. С редактированием такого файла в ворде придётся очень сильно помучиться, зато распознаны все таблички, большинство надписей.
Если в ваши обязанности не входит вёрстка, то это именно то, что нужно.
Я бы назвал это самым большим успехом. Даже Adobe по сравнению с этим меркнет:

Это лучший сервис! К сожалению, без регистрации он не даст распознать PDF больше 15 страниц, большие изображения, ZIP-архивы и ещё что-то. Но после регистрации сервис даёт только 50 бесплатных страниц.
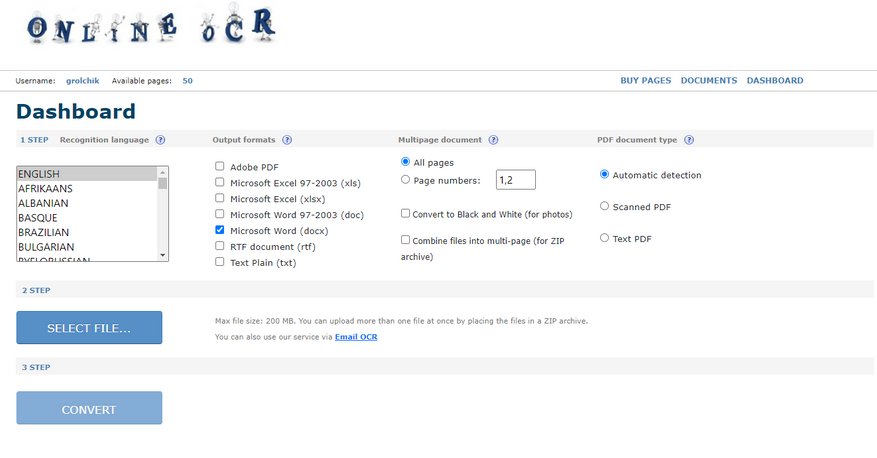
Я слышу слово «абьюз» или мне кажется? Раскрою секрет, как сделать сервис абсолютно бесплатным. Создатели сайта не придумали подтверждение почты при регистрации. Можно указать любой вымышленный адрес. Как только заканчиваются страницы, переезжаем на новый аккаунт и пользуемся 50 бесплатными.
Забавно получается.
Читайте другие статьи переводческого цикла:
Автор не входит в состав редакции iXBT.com (подробнее »)
Об авторе
Люблю Snowrunner, Volvo, царство грибов, пиво, Петроградскую сторону, а также порой очень странные вещи.
Вступайте в мой секретный телеграм. Бесплатный ранний доступ и участие в престижном закрытом клубе гарантировано.
Источник: www.ixbt.com