
Оптическое распознавание текста (англ. optical character recognition, OCR) — перевод последовательности изображений символа в последовательность кодов, использующихся для представления в текстовом редакторе. Перевод осуществляется с помощью различных алгоритмов, после преобразования изображения в набор элементарных точек.
Оптическое распознавание текста (optical character recognition, OCR) — это механический или электронный перевод изображений рукописного, машинописного или печатного текста в последовательность кодов, использующихся для представления в текстовом редакторе.
Распознавание широко используется для конвертации книг и документов в электронный вид, для автоматизации систем учета в бизнесе или для публикации текста на веб-странице.
принципы распознавания в OCR
Процесс ввода документа в компьютер можно подразделить на два этапа:
1. Сканирование. На первом этапе сканер играет роль «глаза» Вашего компьютера: «просматривает» изображение и передает его компьютеру. При этом полученное изображение является не чем иным, как набором черных, белых или цветных точек, картинкой, которую невозможно отредактировать ни в одном текстовом редакторе.
HFG: Программа для распознавания текста с фото
2. Распознавание. Обработка изображения OCR-системой.
* Целостность — объект описывается как целое с помощью значимых элементов и отношений между ними.
* Целенаправленность — распознавание строится как процесс выдвижения и целенаправленной проверки гипотез.
* Адаптивность — способность OCR-системы к самообучению.
В соответствии с этими тремя принципами система сначала выдвигает гипотезу об объекте распознавания (символе, части символа или нескольких склеенных символах), а затем подтверждает или опровергает ее, пытаясь последовательно обнаружить все структурные элементы и связывающие их отношения. В каждом структурном элементе выделяются части, значимые для человеческого восприятия: отрезки, дуги, кольца и точки. Следуя принципу адаптивности, программа самостоятельно «настраивается», используя положительный опыт, полученный на первых уверенно распознанных символах. Целенаправленный поиск и учет контекста позволяют распознавать разорванные и искаженные изображения, делая систему устойчивой к возможным дефектам письма.
Большинство систем OCR работают с растровым изображением, которое получено через факс-модем или сканер. Для тех, кто никогда не видел OCR, обозначим скороговоркой этапы распознавания отсканированной страницы с точки зрения манипуляций над изображением текста.
Делая «первый шаг», OCR должен разбить страницу на блоки текста, основанного на особенностях правого и левого выравнивания и наличия нескольких колонок. Потом эти блоки разбиваются в индивидуальные метки чернил (типографской краски и т.п.), которые, как правило, соответствуют отдельным буквам. Алгоритм распознавания делает предположения относительно соответствия чернильных меток символам; а затем делается выбор каждой буквы и цифры. В результате страница восстанавливается в символах текста (причем, в соответствующем оригиналу формате).
Сервис распознавания текста с картинок. Как скопировать текст с изображения
основные методы распознавания символов
Большинство программ оптического распознавания текста (OCR Optical Character Recognition) работают с растровым изображением, которое получено через факс-модем, сканер, цифровую фотокамеру или другое устройство. На первом этапе OCR должен разбить страницу на блоки текста, основываясь на особенностях правого и левого выравнивания и наличия нескольких колонок. Затем распознанный блок разбивается на строки.
Потом строки разбиваются на непрерывные области изображения, которые, как правило, соответствуют отдельным буквам; алгоритм распознавания делает предположения относительно соответствия этих областей символам; а затем делается выбор каждого символа, в результате чего страница восстанавливается в символах текста, причем, как правило, в соответствующем формате. OCR-системы могут достигать наилучшей точности распознавания свыше 99,9% для чистых изображений, составленных из обычных шрифтов.
Если исходный документ имеет типографское качество (достаточно крупный шрифт, отсутствие плохо напечатанных символов или исправлений), то задача распознавания решается методом сравнения с растровым шаблоном. Сначала растровое изображение страницы разделяется на изображения отдельных символов. Затем каждый из них последовательно накладывается на шаблоны символов, имеющихся в памяти системы, и выбирается шаблон с наименьшим количеством отличных от входного изображения точек.
При распознавании документов с низким качеством печати (машинописный текст, факс и так далее) используется метод распознавания символов по наличию в них определенных структурных элементов (отрезков, колец, дуг и др.).
При распознавании структурным методом в искаженном символьном изображении выделяются характерные детали и сравниваются со структурными шаблонами символов. В результате выбирается тот символ, для которого совокупность всех структурных элементов и их расположение больше всего соответствует распознаваемому символу.
возможности современных программ оптического распознавания текста
Современная OCR должна уметь многое: распознавать тексты, набранные не только определенными шрифтами (именно так работали OCR первого поколения), но и самыми экзотическими, вплоть до рукописных. Уметь корректно работать с текстами, содержащими слова на нескольких языках, корректно распознавать таблицы.
И самое главное — корректно распознавать не только четко набранные тексты, но и такие, качество которых, мягко говоря, далеко от идеала. Например, текст с пожелтевшей газетной вырезки или третьей машинописной копии. Само собой, распознать текст — это еще полдела. Не менее важно обеспечить возможность сохранения результата в файле популярного текстового (или табличного) формата — скажем, формата Microsoft Word.
Программы распознавания текста позволяют перевести в текстовый вид копии очень сложных по структуре текстовых документов, включая таблицы, формы, диаграммы, рисунки. После распознавания и перевода копии в текстовый вид программы сохраняют расположение текста на странице, шрифт, размер и цвет шрифта. Для уменьшения возможных ошибок распознавания символов, программы проверяют орфографию текста.
системы распознавания рукописного текста
Распознавание рукописного текста — технология преобразования символов рукописного текста в последовательность кодов.
Cистемы распознавания рукописного текста.
С появлением первого карманного компьютера Newton фирмы Apple в 1990 году начали создаваться системы распознавания рукописного текста. Такие системы преобразуют текст, написанный на экране карманного компьютера специальной ручкой, в текстовый компьютерный документ.
Системы распознавания форм, заполненных печатными буквами отруки, которые применяются во многих областях. Во-вторых, это
распознавание раздельных рукописных букв, написанных особым пером на специальном экране (touch-screen), которое широко применяется в карманных компьютерах и электронных записных книжках. Эти распознающие системы демонстрируют достаточно высокую точность, приближающуюся к точности клавиатуры
Источник: mydocx.ru
Топ 10: Системы распознавания и извлечения данных из документов

Машинное обучение позволяет создать нейросети для автоматической классификации отсканированных документов (например, паспортов, прав, обращений клиентов, резюме соискателей) или электронных документов, а также для извлечения структурированных данных из них. Примеры использования распознавания документов для бизнеса приведены ниже.
Топ 3 лучших Helpdesk
2022. Microsoft представила платформу ИИ-процессинга данных из документов
Два года назад Microsoft представила сервис SharePoint Syntex, который использует искусственный интеллект для автоматизации извлечения и классификации данных из документов на основе существующих сервисов SharePoint. Теперь этот сервис превратился в самостоятельную платформу Microsoft Syntex, которая содержит набор инструментов для автоматизированного распознавания документов, включая аннотирование файлов и извлечение данных. Syntex считывает, помечает и индексирует содержимое документов (будь то цифровые или физические) и делает эти данные доступным для поиска и использования в приложениях Microsoft 365, а также помогает управлять жизненным циклом данных с помощью инструментов безопасности и архивирования.
2022. Основанная россиянами платформа автоматизации политик безопасности Clausematch привлекла $10,8 млн

Стартап Clausematch, развивающий технологии для финансового рынка, поднял раунд финансирования $10,8 млн от фондов Lytical Ventures и Flashpoint. В общей сложности Clausematch уже привлекла около $20 млн. Clausematch в 2012 году основали Евгений Лиходед и Андрей Докучаев.
Компания разрабатывает платформу для организации рабочего процесса и совместной работы, предназначенную для оптимизации управления политиками и нормативными изменениями в организации. Платформа компании использует машинное обучение, чтобы помочь отделам нормативно-правового регулирования, юридическим, финансовым, операционным и отделам рисков в автоматизации оценки воздействия, оптимизации внедрения нормативных изменений и совместной работы над документами, позволяя клиентам стандартизировать и автоматизировать внутренние процессы и рабочие процессы между командами, снизить затраты, ускорить внедрение и обеспечить соответствие требованиям. Сейчас стартап дислоцируется в Лондоне.
2022. В Эльбе появилось распознавание документов в браузере
Теперь пользователи онлайн бухгалтерии Эльба смогут автоматически распознавать входящие документы можно не только в мобильном приложении, но и в браузере. Эльба распознает счета, акты, накладные и УПД в формате документов (PDF, DOC и DOCX) и фотографий (JPEG и PNG). Достаточно загрузить файл в разделе Документы → Входящие. Если документ состоит из нескольких страниц, выберите сразу все и подождите пару минут, пока Эльба его распознает. Когда распознавание закончится, зайдите в документ, проверьте данные и сохраните.
Топ 3 лучших Service Desk

Топ 3 лучших Helpdesk
2021. Directum выпустил облачный AI-сервис по 100%-ному распознаванию документов Inbox
Новый AI-сервис по 100%-ному распознаванию, который входит в состав интеллектуальной системы Directum Ario One, берет обработку входящего документопотока на себя. Сотруднику достаточно отсканировать документы и загрузить их для дальнейшей обработки. На этом его участие в оцифровке завершается.
Интеллектуальные механизмы Directum Ario распознают текст, классифицируют документы по типам и извлекают из содержимого факты. На основании обработанной информации формируется и отправляется задание на проверку верификаторам. Квалифицированные облачные операторы проверяют результаты машинной обработки и при необходимости дозаполняют нераспознанные реквизиты. В целях безопасности они не видят всего объема данных, так как информация передается им частями.
2021. Directum запускает крауд-проект на разработку AI-решения для анализа договоров

Компания Directum приглашает инвесторов в проект разработки полнофункционального интеллектуального инструмента «Цифровой ассистент юриста». Участники получат скидку 20% на готовое решение и бесплатную пользовательскую лицензию. Подать заявку на участие можно до 31 августа 2021 года.
2021. Интеллектуальные сервисы Directum Ario теперь в облаке
Полнофункциональные AI-сервисы для обработки данных Directum Ario стали доступны в облачной поставке. SaaS-модель снижает порог подключения для клиентов, а варианты подписки на дополнительные пакеты по 5, 10, 15, 20 и 25 тысяч документов в месяц позволяют гибко масштабировать мощности под потребности компании. Возможности интеллектуальных сервисов в облаке предусматривают классификацию и извлечение фактов для 6 видов документов (входящие письма, акты выполненных работ, счета на оплату, счета-фактуры, универсальные передаточные документы, товарные накладные) в стандартной поставке с опцией дополнительного обучения Directum Ario на других типах документов.
2021. Directum запустил сервис интеллектуального извлечения данных из документов
Компания Directum еще 2 года назад выпустила систему для извлечения данных из документов Ario — которая с помощью машинного обучения парсит данные из различных сканов (договоров, заявок, обращений. ) и заносит их в ECM систему Directum. Теперь компания представила сервис Directum Ario One, который может заносить извлеченные данные через Web API в любую информационную систему, используемую в вашей компании. Directum Ario One позволяет исключить участие человека даже на этапе верификации данных. При настройке можно задать значения, по которым корректность классификации и точность извлечения будут определяться автоматически. На их основании система верифицирует данные сама, а ответственный получит уведомление об успешной обработке.
2020. На Google Cloud появился ИИ-сервис для извлечения данных из документов и форм

Google запустил на своей облачной платформе новый когнитивный API-сервис Document AI, который позволяет автоматически извлекать информацию, содержащуюся в цифровых и печатных документах, с помощью машинного обучения. Предполагается использование двух процессоров общего назначения, первый — для обычных документов, второй — для анкет/форм. Есть также специализированные процессоры для финансовой документации, например, можно обрабатывать заявки на выдачу ссуд или счета-фактуры. Главными конкурентами Google в этом сегменте являются компания Amazon, которая предлагает подобный сервис Textract на AWS, а также Microsoft со своим инструментом Form Recogniser.
2020. 1С:БизнесСтарт позволяет создавать документы по их фото
Теперь пользователи сервиса 1С:БизнесСтарт могут создавать счета, счета-фактуры, акты и накладные легко и удобно прямо по их фотографии или скану! Для распознавания документа достаточно его отсканировать или сфотографировать специальным мобильным приложением. Сделать это можно в программе 1С:БизнесСтарт в меню Документы (либо Покупки) — Загрузить из скана (фото).
2020. В СБИС появилось ИИ-распознавание первичных документов

В бухгалтерском модуле системы управления бизнесом СБИС появилась функция автоматического ввода/распознавания первичных документов. Она работает на технологии машинного обучения и позволяет распознавать товарные накладные (ТОРГ-12), УПД, счета-фактуры и авансовые отчеты. Достаточно отсканировать документ или сфотографировать с помощью смартфона и добавить картинку в систему. Она сама добавит документ в базу и извлечет из него данные (контагентов, номенклатуру товаров, затраты. ). Разработчики обещают высокую точность распознавания даже на нечетких снимках. Многостраничные документы — тоже поддерживаются.
2019. В СЭД Кодекс:Документооборот появился модуль искусственного интеллекта
АО «Центр компьютерных разработок» представил модуль искусственного интеллекта для СЭД Кодекс: Документооборот. Он служит для автоматической классификации обращений согласно Справочнику ОТК. Данное решение базируется на технологиях машинного обучения и нейросетях, анализирует текст документа, ранее поданные аналогичные обращения, территорию с которой прислано обращение, какие вопросы содержит письмо и т.д. На основании такого анализа строится предположение, что письмо принадлежит определённой тематической категории, должно быть рассмотрено специалистом, ответственным за данное направление или переправлено в соответствующее ведомство.
2019. ABBYY запустила сервис распознавания документов в мобильном браузере
Компания ABBYY создала сервис для распознавания изображений документов в мобильном браузере Mobile Web Capture. Он пригодится компаниям, которые используют онлайн формы для получения заявок и заказов от клиентов. Сервис позволяет сэкономить им время — вместо заполнения многочисленных полей, клиент может быстро сосканировать права или паспорт, и сервис распознает данные и заполнит поля самостоятельно. Причем, он легко интегрируется с онлайн формой и работает в мобильном браузере, т.е. пользователю не нужно устанавливать дополнительное приложение.
2019. Amazon выпустила ИИ-альтернативу Abbyy FineReader
Ровно 10 лет назад компания ABBYY запустила онлайн сервис распознавания текста FineReader Online. Теперь подобный сервис есть и у Amazon — Amazon Textract. Однако, прогресс не стоит на месте, и амазоновский сервис уже умеет не только распознавать текст, но и понимать структуру документа (с помощью ИИ).
Например, он учитывает и корректно обрабатывает колонтитулы, колонки, таблицы, заполненные формы и даже определяет некоторые форматы данных (имя, номер паспорта, номер социального страхования). Конечно, компанию ABBYY этим не удивить. Они сами собаку съели на технологиях искусственного интеллекта. Их движок уже умеет даже извлекать смысл из документов.
2019. Microsoft представила сервисы для распознавания рукописного текста и заполненных форм
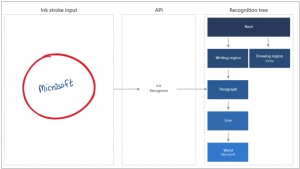
Microsoft представила несколько новых когнитивных сервисов на своей облачной платформе Azure Machine Learning. Во-первых, это подарки для компаний, имеющих дело с документами, формами и служебными записками с рукописным текстом. Сервисы Ink Recognizer и Form Recognizer позволяют переводить все эти бумажки в цифровой текст и данные.
Сервис Conversation Transcription — переводит в текст диалоги по телефону с распознаванием автора каждой фразы. К сожалению, это все пока только на английском. Еще один новый сервис Personalizer позволяет подбирать персонализированные рекомендации для посетителей сайта или интернет-магазина на основании поведенческих факторов.
Кроме того, Microsoft представила новый визуальный конструктор для создания моделей машинного обучения. Теперь даже маркетологи смогут поиграться. Нужно всего лишь загрузить базу данных и указать, какой параметр требуется спрогнозировать.
2018. Abbyy Finereader научился распознавать смысл документов при помощи ИИ

Компания Abbyy сделала шаг от распознавания буковок и слов к распознаванию смысла сканируемых документов. Зачем это нужно? Чтобы автоматизировать процессы ввода бумажных документов в информационные системы (авто-классификации документов, распознавания полей и таблиц, переноса данных из этих полей в структурированную базу данных). Новый движок ABBYY FineReader Engine 12 умеет это делать с помощью технологий обработки естественного языка и машинного обучения. Конечно, для реализации интеллектуального ввода документов не достаточно просто купить программу FineReader — нужно заказать у Abbyy индивидуальный проект.
Источник: www.doc-online.ru
Как нейросети и люди распознают документы с точностью 99% и в 2–3 раза дешевле штатных сотрудников
Самые крутые нейросети распознают до 96% полей в документе. Если текст рукописный, точность может упасть до 20%: нейросети не сильны в военных билетах, трудовых книжках и извещениях о ДТП.
11 401 просмотров
Рассказываю, как работают два гибридных решения, Dbrain и «Биорг», где часть работы по распознаванию достается людям, кому они будут полезны и что там с безопасностью.
Так начинается типичное заявление на ипотеку, в котором заемщику надо заполнить десятки полей не нескольких страницах:
Анкету нужно распечатать, расписаться, сфотографировать или отсканировать. Потом отправить в банк вместе с согласием об обработке персональных данных, справками с работы и другими документами. Это десятки страниц с данными, которые каким-то образом должны попасть в систему банка.
В 2020 году российские банки выдали больше 1,7 млн ипотечных кредитов, потребительских — на порядок больше. Страховые компании оформили миллионы полисов, по одному только ОСАГО они отработали примерно 2 млн заявлений на возмещение ущерба. Белый бизнес официально оформил на работу миллионы сотрудников с их паспортами, ИНН, трудовыми книжками, СНИЛС, дипломами и свидетельствами. Ритейл разбирался с миллионами бумажных счетов, накладных и поручений. В магазинах заполнили миллионы анкет в обмен на карту лояльности.
Каждый случай — это масса полей с текстом, которые нужно перенести в систему компании: имя, город, марка автомобиля, адрес регистрации, название поставщика, предложения по улучшению обслуживания в свободной форме . Надеюсь, вы представили масштаб проблемы.
Как компании переносят данные из сканов и бумаги в свои системы
Есть разные варианты импорта данные от клиентов, контрагентов и сотрудников.
1. Ручная классика. Большие компании содержат сто, двести, триста человек, чья работа — восемь часов в день перебивать цифры и слова в базы компании. Допустим, оператор обрабатывает комплект документов одного клиента за 40 минут — компании это обойдется примерно в 200 рублей с учетом всех расходов. Если компания растет, придется нанимать больше операторов и расширять офис.
Импорт бухгалтерских документов — отдельная история. Для многих бухгалтерий конец отчетного периода — время жестких переработок, потому что не все контрагенты работают через электронный документооборот (ЭДО).
2. ИИ + сотрудники компании. Нейросети с компьютерным зрением (OCR) распознают и импортируют данные. Сотрудникам остается сканировать бумажные документы для нейросетей и разбираться со сложными случаями. Хорошее IT-решение распознает до 96% полей в документах, пока это вроде потолка. Если нужно распознать текст от руки, идеал — 70–75% точности.
В исключительных случаях 80%.
То есть сотрудники берут на себя всего 5–30% рутины. Это в среднем по больнице, но в любом случае компании уже нет смысла содержать такой большой штат, как при 100-процентном ручном вводе. И офис нужен не такой большой. Проблема в том, что сотрудники не всегда могут моментально отреагировать, когда нужно вмешаться, ведь их теперь мало. Это значит, к примеру, что компания не может гарантировать клиентам: «мы примем решение по вашему страховому случаю всего за 15 минут».
Возможно, в первый раз разбираться, что такое «Шруслер», придется сотруднику страховой компании. Потом нейросеть дообучится и справится сама — в базу попадет единственно возможный вариант Chrysler (фото: car72.ru)
3. ИИ + люди как часть IT-решения. В этом случае компания полностью передает распознавание изображений на аутсорсинг — чаще всего нужен только сканировщик, если есть бумажные документы. Точность распознавания выше 99%, независимо от того, печатный текст или рукописный. Скорость занесения данных из документов в системы компании — от 5 секунд до получаса.
На рынке есть несколько решений, обрабатывающих документы по такой схеме. На примере двух из них покажу, как это работает. В первом случае разметчики данных (будем называть их операторами) находятся в огромной внешней краудсорсинговой платформе, во втором — почти в штате разработчика и их в 100 раз меньше.
Dbrain: работает с Яндекс.Толокой
Общая схема работы решения на сайте Dbrain.io
Кто такие? Dbrain автоматизирует работу с документами с 2017 года. За плечами команды несколько продуктов на основе нейросетей — от чат-бота Icon8, моментально обрабатывающего фотографии, до приложения, контролирующего качество выпекания додо-пиццы. Год назад стартап прошел в Y Combinator, и основатели рассказали читателям VC.ru, как им это удалось.
Проект с распознаванием документов начался, когда команда поняла, что на рынке не хватает ИИ-решений, которые решают проблему импорта данных. А главная беда существующих решений — низкая точность распознавания сканов и фотографий плохого качества.
Клиенты редко присылают идеальные фотографии документов. Блики, тени, размытости, не тот угол, обрезанные края, плохой почерк (особенно в извещениях о ДТП) мешают нейросетям распознать документ, и приходится подключать сотрудников. Вроде польза от решения есть, но ожидание с реальностью не совпадают. Dbrain решил сделать продукт, который минимизирует участие клиента в процессе оцифровки документов.
Что обрабатывают? Основной документ Dbrain — паспорт России и стран ближнего зарубежья. Плюс еще три десятка документов, включая СНИЛС, патент на работу, счет-фактуру (вот полный список документов). Решение работает как в IT-контуре заказчика, так и в облаке.
Для кого? Будет полезно, если нужно:
- ускорить регистрацию заявок клиентов. Например, при открытии банковского счета или подключении абонентов.
- исключить опечатки при ручном вводе данных в систему.
- радикально сократить время на решение по заявке клиента. Например, в крупной страховой компании с ручным вводом данных на урегулирование убытка уходило 3 дня, сейчас — 15 минут.
- быстрее оформлять на работу, в том числе мигрантов. Особенно актуально для торговых сетей с высокой текучкой линейного персонала. Или для сервисов доставки, которые массово нанимают курьеров.
Какие фишки?
- высокая точность распознавания некачественных изображений в разных форматах: сканы, фотографии с дешевых смартфонов, jpg.
- может одновременно обрабатывать 500 пакетов документов без потери скорости и качества.
- проверяет документы на подлинность, вычисляет фотошоп и сверяет фотографию в паспорте с селфи клиента.
Как работает решение?
1. Документ в электронном виде попадает в каскад нейросетей. Первая нейросеть определяет границы документа и его положение. Если нужно, выравнивает и вырезает по границе.
2. Вторая нейросеть классифицирует тип документа: паспорт, водительское удостоверение или просто картинка из интернета. Последнее отбраковывается.
3. Нейросеть находит поля с атрибутами, которые надо извлечь из документа: ФИО, место жительства, образование, адрес регистрации, марка автомобиля и так далее.
4. Нейросеть распознает («читает») данные из этих полей. Это ключевая процедура — до этого нейросети готовили документ к прочтению. Если сложностей с прочтением нет, пакет документов проходит весь каскад за секунды.
5. Если данные в поле не удалось распознать, поле отправляется в Яндекс.Толоку в виде задания. Обычно это рукописный текст. За задание параллельно берутся два человека, это нужно для повышения точности.
Оператору в Яндекс.Толоке достаточно ввести несколько букв и выбрать подсказку
Если оба распознали текст с одинаковым результатом, дело сделано. Когда есть разночтения, доступ к заданию получает еще один человек — и так до тех пор, пока не будет консенсуса. Нейросеть обучается на основе решений людей, через какое-то время она сама справится с аналогичным текстом.
В Яндекс.Толоке пакет документов находится от 3 до 15 минут.
6. Все распознанные поля склеиваются в единый документ, который поступает в систему клиента либо благодаря API (чаще всего), либо с помощью RPA от вендоров UiPath, Robin или PIX.
Что с безопасностью? В Яндекс.Толоку поступают разрозненные данные: кому-то достанется только имя, кому-то — только госномер автомобиля. Склеить их вместе пользователи Яндекс.Толоки не смогут. Когда распознанный документ поступает в систему заказчика, каждое поле этого документа удаляется из облака.
Все данные передаются по протоколам с криптозащитой, обрабатываются на серверах Selectel, отвечающим требованиям 152-ФЗ.
«Биорг»: используют собственный краудсорсинговый сервис
Кто такие? Позиционируют себя в качестве лидера оцифровки и распознавания персональных данных на российском рынке. За 2019 год обработали 30 млн документов. Первый проект — в 2017 году.
Работают с тяжелыми кастомными проектами. Берутся за то, от чего другие скорее всего вежливо откажутся. Например, оцифровали архивы ЗАГСов нескольких регионов, расшифровывая записи времен Великой Отечественной, сделанные химическим карандашом на газетах (бумага была дефицитной), а на Сахалине пришлось работать с документами на японском языке. Для «Теле2» за 2,5 месяца оцифровали бумажный 15-тонный архив.
Что обрабатывают? Проще сказать, что не обрабатывают, но в общем объеме негосударственных проектов лидируют анкеты клиентов, кадровая и бухгалтерская документация. Научили нейросети распознавать рукописный текст с точностью до 75%.
Работают со сложными для нейросетей документами — трудовой книжкой и военным билетом, где нормальному распознаванию мешают штампы поверх текста и звезды.
Пятиконечные звезды, которые почти на каждой странице, «слепят» нейросети. Точность автоматического распознавания военного билета обычно не выше 20–30% (фото: «Тинькофф-журнал»)
Для кого? Решение нужно компаниям, которые имеют дело с большим объемом первички, анкет от клиентов и документов от новых сотрудников. Например, будет полезно, когда нужно оформлять тысячи новых сотрудников — система в разы быстрее обрабатывает комплекты документов, делает это точнее и дешевле людей.
Похожий расчет экономического эффекта и у Dbrain: затраты на обработку документов, не только кадровых, снижаются в 2–3 раза (источник: beorg.ru)
Наиболее популярная услуга, если судить по проектам, — обработка анкетных данных в рамках программ лояльности и исследований рынка. За этим обращались, в частности, S7, IKEA, «Вкусивилл», «Пятерочка», «Лента», «Окей», «Адамас», «Детский мир», Natura Siberica, «Якитория».
Какие фишки?
- высокая производительность: способны обработать до 5 млн документов в сутки.
- собственная краудсорсинговая платформа, объединяющая 60 тысяч операторов, которые работают по ГПХ или в качестве самозанятых. Компания часто отмечает, что ведет социально ответственный бизнес.
- все задачи у операторов узкоспециализированные. Для каждого проекта формируется команда, ее обучают с учетом специфики задач клиента.
- «Биорг» гарантирует не более одной ошибки на 100 полей с данными и фиксирует это в договоре. За каждую ошибку вне гарантии выплачивает фиксированную сумму или процент от стоимости распознавания документа.
Как это работает?
1. От заказчика в систему поступает скан документа. Или клиент заказчика напрямую загружает фотографию документа через приложение на Android.
2. Дальше за дело берутся 4 нейросети. Они определяет вид документа, выравнивают, нарезают на поля с текстом и распознают этот текст.
3. Если нет 99% уверенности в том, что поле распознано верно, его отправляют минимум двум операторам, которые должны прийти к единому мнению. Если консенсуса нет, подключается модератор, который выбирает один из предложенных вариантов или пишет третий.
В среднем операторы получают 4 млн заданий ежедневно. Одно задание — одно поле. Данные, которые проверили и распознали операторы, используются для дообучения нейросети.
4. Распознанный документ поступает заказчику в 1С, SAP, MS Dynamics и другие системы. Максимальное время обработки комплекта документов — 20 минут, но обычно 10–15 минут.
Что с безопасностью? «Биорг» использует облачные хранилища на территории России, от Mail.ru и Яндекса. Есть лицензии ФСТЭК и ФСБ на обработку и хранение информации.
Лицензия ФСТЭК действует бессрочно
Компания страхует свою ответственность перед клиентами в «Росгосстрахе». Если будет претензия от третьих лиц за разглашение персональных данных — заказчик получит компенсацию 0,5 млн рублей. Пока таких случаев не было.
Главное про гибридные решения для распознавания
1. Полезны крупным компаниям, которые обрабатывают тысячи документов в сутки: бухгалтерские, кадровые, банковские, страховые, анкеты.
2. Подходят для ускоренной оцифровки бумажных архивов.
3. В 2–3 раза снижают стоимость импорта данных из бумаги, сканов и фотографий в учетные и другие системы.
4. Работают круглосуточно и без выходных, производительность в 5–7 раз выше, чем у штатных операторов.
5. Умеют распознавать печатный, рукопечатный и рукописный текст.
6. Ошибаются реже штатных сотрудников: точность распознавания выше 99% независимо от качества документа.
Автор — руководитель Центра корпоративных инноваций компании «Первый Бит».
Показать ещё
67 комментариев
Написать комментарий.
А какое ценообразование? Особенно интересно в сравнении с abby. И начиная с какого объема документов имеет смысл использовать сервис?
Развернуть ветку
Добрый день! Модель ценообразования — за документ. По объему документов — в зависимости от типа. Рационально использовать если на процессе работы с документами задействовано более 2-х человек.
Развернуть ветку
12 комментариев
Екатерина, если сравнивать с Abbyy, то нет оплаты за лицензии, нет длительного и дорогостоящего заведения шаблонов новых документов, а также нет необходимости в роли верификатора на стороне заказчика, чтобы исправлять ошибки, т.к. гарантированное качество распознавания выше 99%.
Развернуть ветку
1 комментарий
Екатерина, добрый день!
У Dbrain стоимость зависит от объема документов, которые требуется обрабатывать. Как правило, мы рекомендуем начинать с 2 000 страниц в месяц. Связаться со мной и обсудить вашу задачу можно по почте [email protected] или оставив заявку на https://dbrain.io/
Переводим документы в цифровые данные
Развернуть ветку
И начиная с какого объема документов имеет смысл использовать сервис?
Это как просить у продавца на рынке совета, что купить
Такие расчеты все же лучше самим провести и дешевле и надежнее взять готовые ocr библиотеки и доработать под себя
Странно доверять данные своего бизнеса сторонним компаниям
Развернуть ветку
1 комментарий
Круто. Скоро понадобится. Но цифры экономии в два раза как-то не впечатлили. Я честно рассчитывал, что меняя полностью ручной ввод на 95% нейросеть получу экономию в 4-10 раз. Мне кажется если бы нейросети гугла распознавали объекты в два раза дешевле чем вручную Гугл фото бы к примеру ничего бы не распознавал — слишком дорого
Развернуть ветку
Виктор, сокращение расходов в два раза — ориентир, на который можно ориентироваться, когда большая часть потока документов рукописные и требуют проверки с помощью людей. Полностью автоматическое решение может дать еще большую экономию, которая зависит от масштаба бизнеса. Но для большинства бизнесов сократить расходы в 2 раза, при этом предоставив клиенту быстрый и удобный сервис – отличная возможность!
Развернуть ветку
Аккаунт удален
Развернуть ветку
Согласна с вами.
Развернуть ветку
Фигня всё это , пробовали использовать в бухгалтерии , но как оказалось нейросеть умеет только распознавать и ничего не смыслет в бухгалтерии . Мы даже сотрудничали с одним из стартапов в этой области , консультировали по бухгалтерии. Но в итоге оказалось что ручной труд дешевле и быстрее. Например обработать одну фактуру руками 10-30 секунд, а нейросеть распознавать только будет минуту , я уже молчу про весь массив , потом все фактуры нужно отредактировать , в здесь нужно, чтобы на экране был и оригинал фактуры и распознаные данные . Потом всё это нужно соединить с банком , и импортировать в бухгалтерский софт . Причём банк не импортируется , а фактуры криво . Опять правим . В итоге вместо того чтобы вбитьф актуру и потом првоерить по выписке вы делаете одну и туже работу (контроль) несколько раз , да ещё и настройка каждоый фактуры занимает в бухсофте много времени . Я уже молчу , что никто не хочет брать на себя штрафы за ошибки автоматизации . короче этот стартап попытался несмотря на мою им помощь впарить мне нераббочий сервис . И мы расстались .
Развернуть ветку
Игорь, вы описываете ситуацию при применении коробочных решений, например Abbyy, когда на стороне заказчика действительно нужно править данные руками, потому что % распознавания около 90-92. Компания Биорг предоставляет сервис при котором вы получает обработанные данные с качеством распознавания выше 99%, распознанные данные передавать в систему заказчика в удобном для загрузки формате, а также обеспечить непрерывность в обработке, когда документы можно загружать пачками. Ну и конечно же, готовы брать на себя риски в виде штрафов, если они действительно привели нашего заказчика к финансовым потерям. Можем связаться и обсудить конкретную задачу. Спасибо
Развернуть ветку
5 комментариев
Как назывался тот неудачный сервис и стартап?
Развернуть ветку
1 комментарий
Тот случай, когда нейросеть действительно может сделать за человека рутинную работу и автоматизировать простую нудную операция по дешифровке рукописного текста и ввода его в цифровой формат ! Очень нужное решение .
Развернуть ветку
Спасибо, за высокую оценку! Рады слышать.
Развернуть ветку
У меня есть одно большое желание, чтобы те, кто сидели на госзарплате, говорили, что им все гуд и не шевелили жопой, наконец-то ею зашевелили. Скоро тырнут вас всех нахер и будет счастье, по крайней мере мое, личное Бюрократы
Развернуть ветку
Пять раз перечитал. Кто бюрократы, нейросети?
Источник: vc.ru