
Технология распознавания текста — это технология механического или электронного перевода разных текстов в последовательность кодов, используемых для представления в текстовом редакторе.
Введение
Если пользователю необходимо выполнить оцифровку журнальной статьи или распечатанного договора, то он может или провести несколько часов, перепечатывая документ, или же перевести все необходимые материалы в редактируемый формат за короткий интервал времени, задействовав сканер (или цифровую камеру) и программу для оптического распознавания символов, то есть, Optical Character Recognition (OCR).
Оптическим распознаванием символов является технология, позволяющая преобразовать разные виды документов, а именно, отсканированные документы, PDF-файлы или фото с цифровых камер, в редактируемые форматы с возможностью поиска. Передовые системы оптического распознавания символов подразделяются на следующие категории:
Сдай на права пока
учишься в ВУЗе
Вся теория в удобном приложении. Выбери инструктора и начни заниматься!
Программа для распознавания текста на Android
- Классические OCR-системы, призванные решать типовую задачу распознавания печатных символов, которые нанесены на бумагу с помощью принтера, плоттера или пишущей машинки. Причем предполагается, что любая система распознавания использует электронные изображения документов, как правило, полученные при помощи сканера.
- Класс ICR-систем (intelligent character recognition), предназначением которых является обработка документов, заполненных печатными символами и цифрами от руки, то есть, это распознавание рукописей.
В обоих вариантах качественный уровень работы системы распознавания может оцениваться по разным параметрам, но самым важным параметром системы любого вида считается точность распознавания.
Технология распознавания текста: базовые принципы, программы и сервисы
В течение последних лет на мировом рынке предлагаются OCR и ICR-системы, которые построены на основе технологий фирмы ABBYY. На текущий момент они являются хорошо известными и пользующимися постоянным спросом. Например, программное ядро (engine) OCR -системы ABBYY FineReader обладает лицензией и успешно применяется такими популярными корпорациями, как Cardiff Software, Inc., Cobra Technologies, Kofax Image Products, Kurzweil Educational Systems, Inc., Legato Systems, Inc., Notable Solutions Inc., ReadSoft AB, Saperion AG, SER Systems AG, Siemens Nixdorf, Toshiba Corporations.
«Технология распознавания текста: базовые принципы, программы и сервисы»
Готовые курсовые работы и рефераты
Решение учебных вопросов в 2 клика
Помощь в написании учебной работы
Корпорация ABBYY, используя результаты многолетних исследований, смогла реализовать принципы IPA (International Phonetic Alphabet, то есть, международного фонетического алфавита) в компьютерной программе. Система оптического распознавания символов ABBYY FineReader является единственной в мире системой OCR, действующей согласно с описанными выше принципами на каждом этапе обработки документа. Данные принципы обеспечивают программе максимальную гибкость и интеллектуальность, что приближает ее работу к тому, как распознают символы люди.
05 Системы оптического распознавания документов
На начальном этапе распознавания система должна выполнить постраничный анализ изображений, из которых составлен документ, определить структуру страниц, выделить текстовые блоки, таблицы. Помимо этого, современные типы документов могут содержать различные компоненты дизайна, такие как:
- Совокупность иллюстраций.
- Набор колонтитулов.
- Цветной фон или фоновые изображения.
По этой причине мало просто определить и распознать найденный текст, необходимо изначально выяснить устройство обрабатываемого документа, а именно:
- Наличие в нем разделов и подразделов.
- Наличие ссылок и сносок.
- Наличие таблиц и графиков.
- Наличие оглавления.
- Присутствие нумерации страниц и так далее.
Далее в текстовых блоках следует выделить строки, поделить отдельные строки на слова, а слова поделить на символы. Следует заметить, что выделение символов и процесс их распознания также реализован в форме составных частей общей процедуры. Это предоставляет возможность в полном объеме применять преимущества принципов IPA. Выделенные изображения символов должны поступить на рассмотрение механизмов распознавания букв, именуемых классификаторами.
В системе ABBYY FineReader используются классификаторы следующих типов:
- Классификатор растрового типа.
- Классификатор признакового типа.
- Классификатор контурного типа.
- Классификатор структурного типа.
- Классификатор дифференциального признакового типа.
- Классификатор структурно-дифференциального типа.
Растровый и признаковый классификаторы призваны анализировать изображение и выдвигать ряд гипотез о том, какой именно символ на нем изображен. В процессе анализа каждой гипотезе должна быть присвоена некоторая оценка, именуемая весом. По результатам проверки формируется перечень гипотез, обладающий ранжированием по весам, а именно, по уровню уверенности в том, что распознан как раз данный символ. Иначе говоря, в этот момент система строит догадки, на что больше похож изучаемый символ.
Затем согласно принципам IPA ABBYY FineReader должен провести проверку имеющихся гипотез. Эта процедура осуществляется при помощи дифференциального признакового классификатора. Необходимо заметить, что ABBYY FineReader способен поддерживать сто девяносто два языка распознавания. Объединение системы распознавания со словарным запасом осуществляет помощь программе при анализе документов, то есть, распознавание выполняется более точно и делает проще последующую проверку итоговых результатов с учетом данных об основном языке документа и словарной проверки отдельных предположений. По завершении подробной обработки огромного количества гипотез программа должна принять решение и предоставить пользователю конечный вариант распознанного текста.
Преобразование документа в электронный формат исполняется OCR-системами поэтапно, в следующем порядке:
- Этап сканирования и предварительной обработки изображения.
- Этап анализа структуры документа.
- Этап распознавания.
- Этап проверки результатов.
- Этап реконструкции (воссоздание исходного вида) документа, и осуществление экспорта.
Источник: spravochnick.ru
Распознавание текста с помощью решений ABBYY — все гениальное просто для бизнеса

Программы для распознавания текста знакомы всем, кто в процессе работы сталкивался с необходимостью перевода печатных символов в электронный формат. Современные решения от лидера отрасли ABBYY давно вышли за рамки массового сегмента: теперь они помогают бизнесу. Разработки в области распознавания текста востребованы в банковском деле, в образовании, энергетике и т. д. В этой статье мы расскажем о том, какие задачи бизнеса позволяют решать технологии ABBYY.
Система оптического распознавания текста ABBYY OCR: пара слов о технологии
В XXI веке программы распознавания текста востребованы не только у частных пользователей, но и в бизнесе. Главным образом они служат для автоматизации ввода и обработки данных из документов, за счет чего помогают экономить время и деньги. Десятки тысяч компаний во всем мире используют решения ABBYY для повышения конкурентоспособности. А начиналось все в 1993 году, когда была создана технология оптического распознавания символов (OCR — Optical Character Recognition) ABBYY. Поясним вкратце, в чем принцип ее работы.
Текст отсканированного документа, его фотографию или PDF-файл можно просматривать с экрана компьютера, но их содержимое нельзя копировать и изменять. Технология оптического распознавания переводит изображение в формат, доступный для редактирования. Программа находит буквы, объединяет их в слова и предложения, воссоздавая текст. Каким образом она это делает?
Сначала система определяет структуру документа: выделяет текстовые блоки, таблицы, графики, сноски, ссылки, колонтитулы, номера страниц и другие элементы оформления. Этот процесс производится постранично. Затем программа делит текст на строки, слова и символы. После этого в работу включаются механизмы распознавания — классификаторы.
Они анализируют каждый символ и предлагают ряд гипотез о том, на какую букву или знак он похож. Из списка предположений классификаторы выбирают то, которому присвоен наибольший вес, и программа выдает распознанный текст.
Отличительные особенности технологии оптического распознавания текста от ABBYY:
- Быстрота и точность распознавания.
- Полное сохранение исходной структуры и форматирования документа. Программа восстанавливает не только сам текст, но и все элементы оформления, включая иллюстрации, гиперссылки, сноски, колонтитулы и т. п.
- Поддержка более 190 языков. Система распознавания текста интегрирована со словарями, и при проверке гипотез учитываются данные о языке документа. Это ускоряет процесс распознавания и сводит к минимуму вероятность ошибок.
- Распознавание символов, набранных любым шрифтом.
- Возможность сохранения текста почти во всех редактируемых форматах (DOC, TXT, RTF, XLS, HTML, PDF), автоматической передачи документа в другие приложения.
- Автоматизация однотипных операций, что позволяет распознавать и обрабатывать документы еще быстрее.
ABBYY OCR: от теории к практике
Какова же прикладная польза от технологий оптического распознавания текста? Процесс оптимизации бизнеса с их помощью идет сразу в нескольких направлениях:
- Уменьшение времени на обработку документов. С программой оптического распознавания текста ручные операции сводятся к минимуму. За счет этого процессы ввода и обработки данных идут быстрее, а сотрудники освобождают рабочее время для более важных задач.
- Повышение качества ввода данных. Автоматизация практически исключает ошибки, неизбежные при выполнении операций вручную.
- Снижение материальных затрат на обработку документов.
- Повышение скорости и качества обслуживания клиентов, что ведет к росту лояльности.
Все это в комплексе влияет на конкурентоспособность компании и помогает бизнесу стать успешнее. Наглядно представить преимущества внедрения программы позволяет статистика:
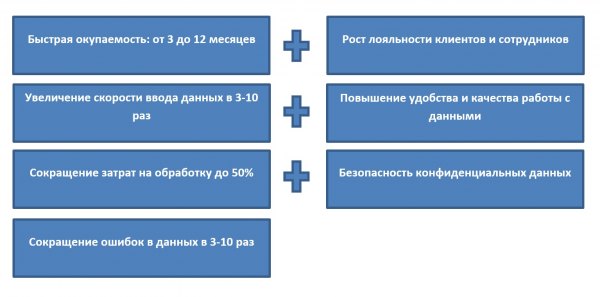
Посмотрим, какие задачи решает программа распознавания текста в конкретных отраслях.
Банковская сфера
Сотрудники банков ежедневно работают с колоссальным объемом бумажной документации. Технологии распознавания текста позволяют экономить массу времени, труда и средств при осуществлении этих операций. Уже 80 российских банков, входящих в топ-100 [1] , оценили решения ABBYY. Вот примерный перечень задач, с которыми справляются решения ABBYY для распознавания текста:
Оптимизация сбора, хранения и обработки клиентских данных
Программа сканирует поступающие документы и автоматически проверяет, правильно ли они заполнены. После этого программа отправляет скан-образы сотруднику банка для верификации. При этом система умеет распознавать ключевые поля в зависимости от типа документа и сравнивать их содержимое с учетными данными. Верифицированные сотрудниками скан-образы автоматически сохраняются в архив. Любые данные из документов можно передавать в информационные системы банка.
Система потокового ввода клиентских данных от ABBYY успешно используется «Россельхозбанком». Решение позволило создать централизованное хранилище документов с онлайн-доступом, минимизировать потерю информации, ускорить взаимодействие между головным офисом и 78 филиалами. Благодаря автоматизированному вводу данных сотрудники банка теперь ежемесячно обрабатывают 4 млн страниц [2] .
Быстрая обработка документов для выдачи кредита
Когда клиент предоставляет документы для получения кредита, система сканирует их и автоматически проверяет правильность оформления. Также программа определяет, все ли необходимые данные имеются. Автоматизация ввода и анализа документов позволяет как минимум в два раза сократить сроки обработки кредитных заявок [3] .
Автоматический ввод данных при открытии счета юрлица
До внедрения технологий распознавания текста сотрудник банка вносил данные для открытия расчетного счета вручную. Для этого было необходимо проверить комплектность документов, удостовериться в корректности заполнения, отсканировать их, извлечь необходимые данные и передать на дальнейшую обработку в информационные системы банка. Программа выполняет все эти операции автоматически.
Автоматизация расчетно-кассовых операций
Чтобы провести платеж, сотрудник банка вводит в систему данные из платежных документов. В организациях, использующих решения ABBYY, этот процесс протекает в 5–10 раз быстрее [4] . Программа сканирует документы, распознает и извлекает необходимые данные, а потом выдает их оператору. При автоматическом вводе устраняется человеческий фактор, и ошибок практически не бывает.
Автоматизация валютного контроля
Финансовые операции с использованием иностранной валюты относятся к особо трудоемким и сложным банковским процессам, поскольку их осуществление требует строгого соблюдения норм валютного законодательства. Сотрудник банка должен проявлять особое внимание при вводе и проверке данных. Решения от ABBYY позволяют автоматизировать обработку документов валютного контроля, ускорить операции и практически полностью исключить ошибки.
Энергетика
Возможности технологий распознавания текстов востребованы и в энергетической отрасли. Прежде всего они используются для автоматизации обработки бумажных и электронных документов.
Автоматизированный ввод данных с приборов
Показания приборов используются и при коммерческом учете потребления электроэнергии, и при техническом обслуживании оборудования (результаты проведения испытаний). Данные чаще всего поступают на бумажных носителях. Показания приборов учета и измерительных устройств вводятся в информационную систему для обработки. Благодаря решениям ABBYY этот процесс происходит автоматически. Программа позволяет сократить сроки обработки документов, исключить ошибки ввода, уменьшить затраты труда персонала.
Автоматизация бухгалтерских операций
Через отделы бухгалтерии электросетевых компаний ежедневно проходит огромное количество финансовых документов. Каким бы внимательным ни был сотрудник, при таком объеме данных неизбежно возникают ошибки. Это приводит к потерям времени и средств, особенно при несвоевременном обнаружении. Не говоря уже о длительности самого процесса ручного ввода.
Внедрение решения по распознаванию текста на 50% сокращает затраты при обработке счетов-фактур [5] , минимизирует ошибки ввода, предотвращает потерю данных. Программа сканирует, распознает и проверяет документы, автоматически извлекает из них нужную информацию и вводит ее в систему. Бухгалтеру остается только подтвердить, правильно ли распознаны данные.
Компания КЭС-Энергостройсервис, занимающаяся ремонтом объектов энергетики, столкнулась с проблемой чрезмерных затрат на документооборот. Чтобы получить нужные запчасти, приходилось ждать 3–7 дней: именно столько времени занимал процесс обработки и согласования документов. После внедрения платформы ABBYY FlexiCapture бухгалтеры стали выполнять эту работу за 1–3 часа [6] .
Быстрая обработка заявок по технологическому присоединению физических и юридических лиц к электросетям
Прежде чем заключить с потребителем договор на технологическое присоединение к электросетям, сотрудники энергетической компании принимают и обрабатывают заявку. Несмотря на то что этот документ разрешается подавать в электронном виде, многие заявители по-прежнему предпочитают традиционные бумажные носители. Персоналу приходится вводить данные вручную, затрачивая лишнее время и труд.
С внедрением решения ABBYY все упрощается: бумажная заявка сканируется, затем программа помещает скан-копию в электронное хранилище, а распознанные данные передает в информационную систему, где они автоматически обрабатываются. Рутинная работа сотрудников сводится к минимуму, и они могут уделять время другим задачам.
Нефтегазовая отрасль
Нефтегазовые компании в своей работе тоже сталкиваются с большим объемом бумажной документации. Данные нужно оперативно и точно вносить в систему и обрабатывать. При этом необходимо, чтобы сотрудники имели к ним быстрый доступ. Понимая, что от этих процессов зависит эффективность бизнеса, руководители компаний стремятся автоматизировать обработку и хранение документов.
Наиболее практичным решением представляется создание удобного электронного архива с широким спектром функциональных возможностей. ABBYY уже реализовала несколько таких проектов в нефтегазовой отрасли.
Например, в ОАО «Востокгазпром» удалось за короткое время оптимизировать ввод учетных и финансовых документов с помощью платформы ABBYY FlexiCapture. Перед разработчиками стояла задача обеспечить точность внесения данных, быстрый доступ к нужной информации. С этой целью было создано 25 шаблонов для обработки актов, накладных, кассовых ордеров и других стандартных типов документов предприятия.
Система автоматически вписывает реквизиты документа в его архивную карточку, прикрепляет скан-копию и результат распознавания в доступном для полнотекстового поиска формате. Текстовые данные программа вносит в нужные поля, проверяет их в соответствии с заданными правилами, подсвечивает возможные ошибки. В результате работа сотрудника сводится к итоговому контролю и подтверждению экспорта документа.
Другие отрасли
Применение программ распознавания текста не исчерпывается перечисленными сферами. Решения от ABBYY востребованы и во многих других отраслях экономики, в частности в образовании, государственном секторе, производстве, логистике и транспорте, ритейле, телекоммуникациях и др.
Возможности программы по распознаванию текста позволяют оптимизировать бизнес-процессы и за счет этого повысить конкурентоспособность компании. Автоматизированная обработка документов экономит время сотрудников и снижает затраты на обработку данных. Удобство и функциональность решений ABBYY уже оценили многие предприятия из разных сфер бизнеса.
P.S. ABBYY — мировой лидер в области технологий интеллектуальной обработки информации. С продуктами и отраслевыми решениями компании можно ознакомиться на сайте www.abbyy.com.
Источник: www.kp.ru
Системы распознавания текста
Программы и системы распознавания текста (СРТ, англ. Text Recognition Systems, TRS) предназначены для сканирования текстовых данных, обработки графических данных и извлечения полезной информации из документов различных видов. С помощью данных программных продуктов часто, обрабатываются счета-фактуры, акты, накладные, квитанции, клиентские формы, опросные листы и документы сотрудников.
Читать далее
Сравнение Системы распознавания текста
Выбрать по критериям:
Подходит для
Специалист
Малый бизнес
Средний бизнес
Корпорация
Администрирование
Импорт/экспорт данных
Многопользовательский доступ
Наличие API
Отчётность и аналитика
Тарификация
Ежемесячная оплата
Ежегодная оплата
Единовременная оплата
Оплата потребления
По запросу
Развёртывание
Сервер предприятия
Мобильное устройство
Персональный компьютер
Облако (SaaS)
Графический интерфейс
Веб-браузер
Поддержка языков
Азербайджанский
Белорусский
Бенгальский
Болгарский
Венгерский
Вьетнамский
Грузинский
Индонезийский
Итальянский
Каталонский
Латвийский
Монгольский
Нидерландский
Норвежский
Персидский
Португальский
Украинский
Французский
Хорватский
Английский
Нет продуктов
Руководство по покупке Системы распознавания текста
1. Что такое Системы распознавания текста
Программы и системы распознавания текста (СРТ, англ. Text Recognition Systems, TRS) предназначены для сканирования текстовых данных, обработки графических данных и извлечения полезной информации из документов различных видов. С помощью данных программных продуктов часто, обрабатываются счета-фактуры, акты, накладные, квитанции, клиентские формы, опросные листы и документы сотрудников.
2. Обзор основных функций и возможностей Системы распознавания текста
Администрирование Возможность администрирования позволяет осуществлять настройку и управление функциональностью системы, а также управление учётными записями и правами доступа к системе. Импорт/экспорт данных Возможность импорта и/или экспорта данных в продукте позволяет загрузить данные из наиболее популярных файловых форматов или выгрузить рабочие данные в файл для дальнейшего использования в другом ПО.
Многопользовательский доступ Возможность многопользовательской доступа в программную систему обеспечивает одновременную работу нескольких пользователей на одной базе данных под собственными учётными записями. Пользователи в этом случае могут иметь отличающиеся права доступа к данным и функциям программного обеспечения.
Наличие API Часто при использовании современного делового программного обеспечения возникает потребность автоматической передачи данных из одного ПО в другое. Например, может быть полезно автоматически передавать данные из Системы управления взаимоотношениями с клиентами (CRM) в Систему бухгалтерского учёта (БУ).
Для обеспечения такого и подобных сопряжений программные системы оснащаются специальными Прикладными программными интерфейсами (англ. API, Application Programming Interface). С помощью таких API любые компетентные программисты смогут связать два программных продукта между собой для автоматического обмена информацией. Отчётность и аналитика Наличие у продукта функций подготовки отчётности и/или аналитики позволяют получать систематизированные и визуализированные данные из системы для последующего анализа и принятия решений на основе данных.
Источник: soware.ru