
Сервисы для распознавания текста (OCR)
Найдите лучшие программы для распознавания текстов для вашего бизнеса. Сравните отзывы о продукте и функции, чтобы построить свой список.
Что такое программы для распознавания текстов
Программное обеспечение для распознавания текста (OCR, оптическое распознавание символов ) позволяет распознавать текст в отсканированных документах и изображениях и преобразовывать его в формат с возможностью поиска и редактирования.
Похожие категории
6 результатов
6 результатов
Тарифы
Бесплатно
С тестовым периодом
Подписка на месяц
Подписка на год
Разовая покупка
Возможности
Пакетная обработка
Конвертировать в PDF
Cканирование персональных данных
Индексирование
Извлечение метаданных
Многоязычный
Несколько выходных форматов
Текстовой редактор
Операционная система
Windows
Mac
Web-Based, Cloud, SaaS
iPhone / iPad
Android
Сортировать по рекомендациям
рекомендациям
Программы распознавания текста

Directum Ario One
от Directum
Directum Ario One – это российская система интеллектуальной обработки документов и другой информации. Берет на себя рутинные этапы работы, исключает человеческие ошибки, в разы ускоряет и удешевляет бизнес-процессы. Совместима с любой информационной системой. Подробнее о Directum Ario One
Услуги по внедрению продуктов
Выбери IT-компанию исполнителя для своей задачи
Доступно 3 интегратора

VOCO
VOCO — Windows-приложение для преобразования речи в текст. Подробнее о VOCO

Scanitto
от Masters ITC Software
Scanitto — удобная программа для сканирования документов и фотографий для Windows с функцией редактирования изображений Подробнее о Scanitto

RiDoc
от Компания «Риман», ООО
RiDoc — программа для сканирования документов и распознавания текста. Подробнее о RiDoc

OCR CuneiForm
от Cognitive Technologies Ltd.
OCR CuneiForm — программа для распознавания текста в сфотографированных и отсканированных документах. Подробнее о OCR CuneiForm
Распознавание текста. Перевести картинку и пдф в ворд. Лучшие методы

ЕВФРАТ
от Cognitive Technologies
от 27000₽/месяц
Система электронного документооборота и автоматизации бизнес-процессов. Подробнее о ЕВФРАТ
Сравнить 0 продукта категории Сервисы для распознавания текста (OCR)Сервисы для распознавания текста (OCR)
Материалы по теме
Подписывайся на наш блог и следи за последними новостями с сфере программного обеспечения. Мы знаем как работает бизнес не по наслышке и делимся опытом с вами.
Перейти в блог
15 июл, 2021
03 мар, 2022
08 сен, 2022
10 ноя, 2022
Популярные сравнения в категории

ABBYY FineReader

KnowledgeLake

Online OCR
KnowledgeLake

Doc.Convert
KnowledgeLake
Online OCR
ABBYY FineReader
Doc.Convert
ABBYY FineReader
Doc.Convert
Online OCR
Обратитесь к эксперту pickTech , который поможет вам найти подходящий продукт для вашего бизнеса. Всего 15 минут на звонок. Это бесплатно!
О компании
- Наша история
- Юридические документы
Пользователям
115419, г.Москва, ул.Шаболовка, д.34, стр.5
Все сведения, содержащиеся на страницах сайта (информационные материалы, каталоги, статьи и пр.), носят ознакомительный характер. Информация не является исчерпывающей. Информация на сайте не является публичной офертой, определяемой положениями Статьи 437 Гражданского кодекса РФ. Все права интеллектуальной собственности принадлежат компаниям — производителям программного обеспечения, как и товарные знаки и логотипы. Все ссылки на дистрибутивы, а так же выложенные статьи, товарные знаки и логотипы носят в себе только ознакомительный характер и не претендуют на интеллектуальную собственность, а так же ее нарушение
Источник: picktech.ru
Сканирование и распознавание текста
Добрый день.
Наверное, каждый из нас сталкивался с задачей, когда нужно перевести бумажный документ в электронный вид. Особенно это часто нужно делать тем кто учиться, работает с документацией, переводит тексты при помощи электронных словарей и т.д.
В этой статье мне хотелось бы поделиться некоторыми азами этого процесса. Вообще, сканирование и распознавание текста — довольно трудоемко, так, как большинство операций придется делать вручную. Мы попытаемся разобраться по шагам, что, как и почему.
Не все сразу понимают одну вещь. После сканирования (пригона всех листов на сканере) у вас будут картинки формата BMP, JPG, PNG, GIF (могут быть и другие форматы). Так вот с этой картинки нужно получить текст — это процедура называется распознаванием. В таком порядке и будет изложение ниже.
1. Что нужно для сканирования и распознавания?
Для перевода печатных документов в текстовый вид, вам для начала нужен сканер и соответственно, «родные» программы и драйверы, которые с ним шли. При помощи них можно будет сканировать документ и сохранить его для дальнейшей обработки.
Можно воспользоваться и другими аналогами, но софт, который шел со сканером в комплекте, обычно работает быстрее и имеет больше опций.
В зависимости от того, какой у вас сканер — скорость работы может существенно различаться. Есть сканеры, которые могут получить картинку с листа за 10 сек., есть которые будут получать за 30 сек. Если сканируете книгу на 200-300 листов — думаю, не трудно подсчитать во сколько раз будет разница во времени?
2) Программа для распознавания
В нашей статье я буду показывать вам работу в одной из лучших программ для сканирования и распознавания абсолютно любых документов — ABBYY FineReader. Т.к. программа платная, то сразу дам ссылку и на другую — ее бесплатный аналог Cunei Form. Правда, я бы не стал их сравнивать, ввиду того, что FineReader выигрывает по всем параметрам, рекомендую все же попробовать именно ее.

ABBYY FineReader 11
Одна из лучших программ в своем роде. Она предназначена для того, чтобы распознать текст на картинке. Встроено множество опций и функций. Может разобрать кучу шрифтов, поддерживает даже рукописные варианты (правда, лично не пробовал, думаю, хорошо вряд ли будет распознавать рукописный вариант, если только у вас не идеальный каллиграфический почерк).
Более подробно о работе с ней будет рассказано ниже. Здесь же отметим, что в статье будет рассказано о работе в программе 11 версии.
Как правило, разные версии ABBYY FineReader не сильно отличаются друг от друга. Вы без труда сделаете то же самое и в другой. Главные отличия могут быть в удобстве, быстроте работы программы и ее возможностях. Например, более ранние версии отказываются открывать документ PDF и DJVU…
3) Документы для сканирования
Да, вот так вот, решил вынести документы отдельной графой. В большинстве случаев сканируют какие-нибудь учебники, газеты, статьи, журналы и пр. Т.е. те книги и ту литературу которая пользуется спросом. Я это к чему веду? Из личного опыта могу сказать, что многое, что вы захотите сканировать — возможно уже есть в сети!
Сколько раз лично я экономил время, когда находил ту или иную книгу уже сканированную в сети. Мне оставалось только скопировать текст в документ и продолжить с ним работу.
Из этого простой совет — прежде чем что-то сканировать, проверьте, может уже кто-то отсканировал и вам не нужно терять свое время.
2. Параметры сканирования текста
Здесь я не будут рассказывать о ваших драйверах для сканера, программах, которые вместе с ним шли, ибо все модели сканеров разные, ПО тоже везде разное и угадать и тем более показать наглядно как выполнять операцию — нереально.
Но во всех сканерах есть одни и те же настройки, которые сильно могут повлиять на скорость и качество вашей работы. Вот о них таки как раз и поговорим здесь. Буду перечислять по порядку.
1) Качество сканирования — DPI
Во-первых, качество сканирования поставьте в опциях не ниже 300 DPI. Желательно даже выставить побольше, если это возможно. Чем выше показатель DPI — тем четче получиться ваша картинка, ну и тем самым, быстрее пройдет дальнейшая обработка. К тому же чем выше качество сканирования — тем меньше ошибок вам в последствии придется исправлять.
Оптимальный вариант обеспечивает, обычно, 300-400 DPI.
Этот параметр очень сильно влияет на время сканирования (кстати, DPI тоже влияет, но те так сильно, и только когда пользователь ставит высокие значения).
Обычно выделяют три режима:
— черно-белый (отлично подойдет для простого текста);
— серый ( подойдет для текста с таблицами и картинками);
— цветной (для цветных журналов, книг, в общем, документов, где важна цветность).
Обычно от выбора цветности зависит время сканирования. Ведь если документ у вас большой, то даже лишние 5-10 секунд на странице в целом выльются в приличное время…
Документ вы можете получить не только сканированием, но и сфотографировав его. Как правило, в этом случае у вас будут некоторые другие проблемы: искажение картинки, смазанность. Из-за этого может потребоваться более длительная дальнейшая правка и обработка полученного текста. Лично я не рекомендую пользоваться фотоаппаратами для этого дела.
Важно отметить, что не каждый такой документ получится распознать, т.к. качество сканирования у него может быть крайне низким…
3. Распознавание текста документа
Будем считать, что заветные сканированные страницы вы получили. Чаще всего они представляют собой форматы: tif, bmb, jpg, png. В общем-то, для ABBYY FineReader — это не сильно важно…
После открытия в ABBYY FineReader картинки, программа, как правило, на автомате начинает выделять области и распознавать их. Но иногда она делает это не правильно. Для этого-то мы и рассмотрим выделение нужных областей вручную.
Важно! Не все сразу понимают, что после открытия документа в программе, слева в окне отображается исходный документ, в котором вы и выделяете различные области. После нажатия на кнопку «распознавания» программа в окне справа выведет вам готовый текст. После распознавания, кстати, целесообразно проверить текст на ошибки в том же самом FineReader.
3.1 Текст
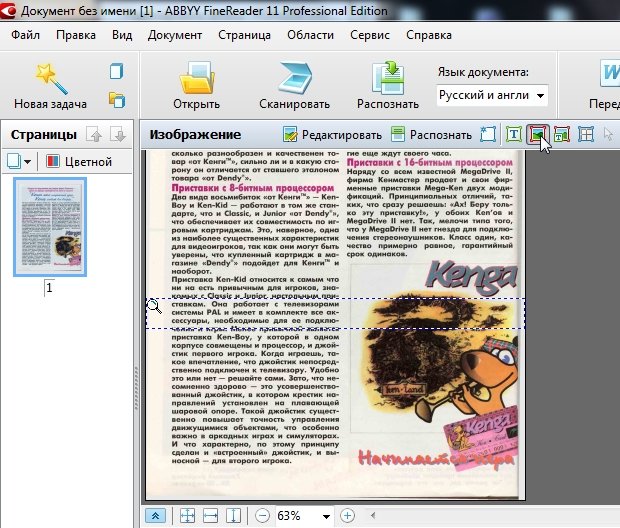
Эта область используется для выделения текста. Картинки и таблицы нужно исключать из нее. Редкие и необычный шрифты придется вводить вручную…
Для выделения текстовой области, обратите внимание на панель в верхней части FineReader. Там есть кнопка «Т» (см. скриншот ниже, указатель мышки как раз на этой кнопке). Щелкаете по ней, затем на картинке ниже выделяете аккуратно прямоугольную область, в которой располагается текст. Кстати, в некоторых случаях нужно создавать текстовых блоков по 2-3, а иногда по 10-12 на страницу, т.к. форматирование текста может быть разным и одним прямоугольником всю область не выделить.
Важно отметить, что в текстовую область не должны попадать картинки! В дальнейшем это вам сэкономит кучу времени…
![Документ без имени [1] - ABBYY FineReader 11 Professional Edition_2013-11-03_10-07-33](https://pcpro100.info/wp-content/uploads/2013/11/Dokument-bez-imeni-1-ABBYY-FineReader-11-Professional-Edition_2013-11-03_10-07-33.jpg)
3.2 Картинки
Используется для выделения картинок и тех областей, которые тяжело распознать из-за плохого качества, или необычности шрифта.
На скриншоте ниже указатель мышки находится на кнопке, используемой для выделения области «картинка». Кстати, в эту область можно выделить абсолютно любую часть страницы, а FineReader вставит ее потом в документ как обычную картинку. Т.е. просто «тупо» скопирует…
Обычно эту область используют для выделения плохо отсканированных таблиц, для выделения нестандартного текста и шрифта, само-собой картинок.
3.3 Таблицы
На скриншоте ниже показана кнопка для выделения таблиц. Вообще, лично я ее использую крайне редко. Дело в том, что вам придется довольно рутинно рисовать (фактически) каждую линию на таблице и показывать что и как программе. Если таблица небольшая и в не очень хорошем качестве, я рекомендую для этих целей использовать область «картинка». Тем самым сэкономите кучу времени, а таблицу можно потом в Word сделать быстренько на основе картинки.
![]()
3.4 Ненужные элементы
Важно отметить. Иногда на странице есть ненужные элементы, которые мешают распознать текст, или вообще не дают вам выделить нужную область. Их можно при помощи «ластика» удалить вовсе.
Для этого переходим в режим редактирования изображения.
![Документ без имени [1] - ABBYY FineReader 11 Professional Edition_2013-11-03_10-14-11](https://pcpro100.info/wp-content/uploads/2013/11/Dokument-bez-imeni-1-ABBYY-FineReader-11-Professional-Edition_2013-11-03_10-14-11.jpg)
Выбираем инструмент «ластик» и выделяем ненужную область. Она сотрется и на ее месте будет белый лист бумаги.
![Документ без имени [1] - ABBYY FineReader 11 Professional Edition_2013-11-03_10-14-21](https://pcpro100.info/wp-content/uploads/2013/11/Dokument-bez-imeni-1-ABBYY-FineReader-11-Professional-Edition_2013-11-03_10-14-21.jpg)
Кстати, рекомендую использовать вам эту опцию как можно чаще. Старайтесь все текстовые области которые вы выделили, где вам не нужен кусок текста, или присутствуют любые ненужные точки, размытости, искажения — удалять ластиком. Благодаря этому распознавание будет быстрее!
4. Распознавание файлов PDF/DJVU
Вообще, этот формат распознавания не будет отличаться ничем другим от остальных — т.е. работать с ним можно так же как с картинками. Единственное, программа не должна быть слишком старой версии, если файлы PDF/DJVU у вас не открываются — обновите версию до 11.
Небольшой совет. После открытия документа в FineReader — он автоматически начнет распознавать документ. Часто в файлах PDF/DJVU определенная область страницы не нужна во всем документе! Чтобы удалить такую область на всех страницах сделайте следующее:
1. Зайдите в раздел редактирования изображения.
2. Включите опция «обрезки».
3. Выделите область, нужную вам на всех страницах.
4. Нажмите применить ко всем страницам и обрежьте.
![Документ без имени [1] - ABBYY FineReader 11 Professional Edition_2013-11-03_10-19-21](https://pcpro100.info/wp-content/uploads/2013/11/Dokument-bez-imeni-1-ABBYY-FineReader-11-Professional-Edition_2013-11-03_10-19-21.jpg)
5. Проверка ошибок и сохранение результатов работы
Казалось бы, какие еще могут быть проблемы, когда все области были выделены, затем распознаны — бери да сохраняй… Не тут то было!
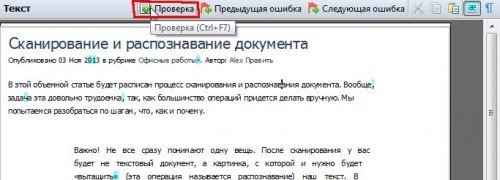
Во-первых, нужна проверка документа!
Чтобы ее включить, после распознавания, в окне справа, будет кнопка «проверка», см. скриншот ниже. После ее нажатия программа FineReader будет автоматически показывать вам те области, где у программы возникли ошибки и она не смогла достоверно определить тот или иной символ. Вам останется только выбирать, либо вы согласны с мнением программы, либо вводите свой символ.
Кстати, в половине случаев, примерно, программа будет вам предлагать готовое правильное слово — вам останется толкьо мышкой выбрать нужный вариант.
Во-вторых, после проверки вам нужно выбрать формат, в который вы сохраните результат своей работы.
Здесь FineReader дает вам развернуться на полную катушку: можно просто передать информацию в Word один в один, а можно сохранить ее в одном из десятков форматов. Но хотелось бы выделить другой важный аспект. Какой формат бы не выбрали, более важно выбрать тип копии! Рассмотрим самые интересные варианты…
![Документ без имени [1] - ABBYY FineReader 11 Professional Edition_2013-11-03_10-24-08](https://pcpro100.info/wp-content/uploads/2013/11/Dokument-bez-imeni-1-ABBYY-FineReader-11-Professional-Edition_2013-11-03_10-24-08.jpg)
Все области, которые вы выделяли на странице в распознанном документе будут соответствовать точь в точь исходному документу. Очень удобный вариант, когда вам важно не потерять форматирование текста. Кстати, шрифты так же будут очень похожи на оригинал. Рекомендую при таком варианте передавать документ в Word, чтобы уже там продолжить дальнейшую работу.
Этот вариант хорош тем, что вы получите уже форматированный вариант текста. Т.е. отступов с «километр», которые возможно были в исходном документе — вы не встретите. Полезная опция, когда вы будете значительно редактировать информацию.
Правда, не стоит выбирать, если вам важно сохранить стилистику оформления, шрифты, отступы. Иногда, если распознавание прошло не очень успешно — ваш документ может «перекосить» из-за измененного форматирования. В этом случае целесообразно выбрать точную копию.
Вариант для тех, кому нужен просто текст со странице без всего остального. Подойдет для документов без картинок и таблиц.
На этом статья по сканированию и распознаванию документа подошла к концу. Надеюсь, что при помощи этих простых советов вы сможете решить свои задачи…
Источник: pcpro100.info
Системы распознавания текста
Программы и системы распознавания текста (СРТ, англ. Text Recognition Systems, TRS) предназначены для сканирования текстовых данных, обработки графических данных и извлечения полезной информации из документов различных видов. С помощью данных программных продуктов часто, обрабатываются счета-фактуры, акты, накладные, квитанции, клиентские формы, опросные листы и документы сотрудников.
Читать далее
Сравнение Системы распознавания текста
Выбрать по критериям:
Подходит для
Специалист
Малый бизнес
Средний бизнес
Корпорация
Администрирование
Импорт/экспорт данных
Многопользовательский доступ
Наличие API
Отчётность и аналитика
Тарификация
Ежемесячная оплата
Ежегодная оплата
Единовременная оплата
Оплата потребления
По запросу
Развёртывание
Сервер предприятия
Мобильное устройство
Персональный компьютер
Облако (SaaS)
Графический интерфейс
Веб-браузер
Поддержка языков
Азербайджанский
Белорусский
Бенгальский
Болгарский
Венгерский
Вьетнамский
Грузинский
Индонезийский
Итальянский
Каталонский
Латвийский
Монгольский
Нидерландский
Норвежский
Персидский
Португальский
Украинский
Французский
Хорватский
Английский
Сортировать: по алфавиту по полноте сведений
Tesseract OCR от Google
Tesseract – это программный движок с открытым исходным кодом, позволяющий распознавать символы с поддержкой кодировки Unicode и возможностью распознавания более 130 языков, а также с возможностью дополнения для распознавания других языков. Узнать больше про Tesseract OCR
ABBYY FineReader от ABBYY
ABBYY FineReader – это универсальное программное приложение для распознавания текста, предназначенное для повышения производительности бизнеса, быстрого захвата документов на бумажных носителях и получения на выходе оцифрованных файлв в форматах PDF, DOC и прочих. Узнать больше про ABBYY FineReader
Yandex Vision от Яндекс.Облако
Yandex Vision – это онлайн-сервис визуальной аналитики, позволяющий реализовывать распознавание текста и объектов на изображениях с помощью программных моделей машинного обучения. Сервис используется на базе программного интерфейса (API). Узнать больше про Yandex Vision
Руководство по покупке Системы распознавания текста
1. Что такое Системы распознавания текста
Программы и системы распознавания текста (СРТ, англ. Text Recognition Systems, TRS) предназначены для сканирования текстовых данных, обработки графических данных и извлечения полезной информации из документов различных видов. С помощью данных программных продуктов часто, обрабатываются счета-фактуры, акты, накладные, квитанции, клиентские формы, опросные листы и документы сотрудников.
2. Обзор основных функций и возможностей Системы распознавания текста
Администрирование Возможность администрирования позволяет осуществлять настройку и управление функциональностью системы, а также управление учётными записями и правами доступа к системе. Импорт/экспорт данных Возможность импорта и/или экспорта данных в продукте позволяет загрузить данные из наиболее популярных файловых форматов или выгрузить рабочие данные в файл для дальнейшего использования в другом ПО.
Многопользовательский доступ Возможность многопользовательской доступа в программную систему обеспечивает одновременную работу нескольких пользователей на одной базе данных под собственными учётными записями. Пользователи в этом случае могут иметь отличающиеся права доступа к данным и функциям программного обеспечения.
Наличие API Часто при использовании современного делового программного обеспечения возникает потребность автоматической передачи данных из одного ПО в другое. Например, может быть полезно автоматически передавать данные из Системы управления взаимоотношениями с клиентами (CRM) в Систему бухгалтерского учёта (БУ).
Для обеспечения такого и подобных сопряжений программные системы оснащаются специальными Прикладными программными интерфейсами (англ. API, Application Programming Interface). С помощью таких API любые компетентные программисты смогут связать два программных продукта между собой для автоматического обмена информацией. Отчётность и аналитика Наличие у продукта функций подготовки отчётности и/или аналитики позволяют получать систематизированные и визуализированные данные из системы для последующего анализа и принятия решений на основе данных.
Источник: soware.ru
Лучшие программы для распознавания и сканирования текста
Представляем вашему вниманию программы для распознавания и сканирования текста, с помощью которых можно оптимизировать процесс оцифровки документов, рукописных или бумажных книг.

Рассматриваемые нами приложения легко переводят png, jpg, pdf и «бумажные файлы» в удобный для редактуры в Word формат и другие офисные ПО, редактируют распечатанный или сфотографированный материал в полноценный текст.
Рейтинг программ для распознавания текста со сканера
Обработка текста
ABBYY FineReader скачать
Приложение легко распознает печатные символы и преобразовывает отсканированные документы в цифровые форматы. Считается лидером в своей категории, поскольку выполняет свои задачи качественно и быстро, в отличие от подобных аналогов. Эбби ФайнРидер имеет свою OCR технологию обработки материала, функции для захвата данных на разных источниках, а также инструменты для обработки PDF-объектов, их редактирования и комментирования. Также доступна автоматизированная конвертация, сохранение разметок, обработка текста на разных языках, поддержка подключаемых устройств и интегрированный редактор. Бесплатная версия ограничивает работу софта после 15 дней использования.
OCR CuneiForm скачать
Программа специализируется на идентификации сканированного или сфотографированного текста, сохраняя его структурирование и гарнитуру шрифта. Понимает любой печатный шрифт, отправляет распознанный результат во встроенный редактор текста, переделывает электронные копии и графические файлы в удобный вид для редактуры. В состав комплекса входят два программных обеспечения для пакетной и одиночной обработок. Распознанные документы легко сохранить в удобном формате или отыскать их в поиске. Дополнительно прога может определять таблицы, текстовые блоки и графические картинки вне зависимости от сложности, объема и четкости текста.
Adobe Reader скачать
Популярный просмотрщик всех видов PDF-файлов с базовыми функциями работы с документацией. Позволяет просматривать, копировать, менять ориентацию или отправлять на печать документы. Для слабовидящих юзеров доступна опция масштабирования, увеличивающая размер шрифта до нужных параметров.
Также можно воспользоваться функцией трёхмерного изображения и воспроизведения интегрированных в мультимедийный контент объектов. Доступен поиск в PDF картах, портфолио и файлах, а также комментирование файлов, присоединение электронных подписей и настройка плагинов для веб-навигаторов. Из минусов бесплатной версии отметим ограниченный только просмотром функционал.
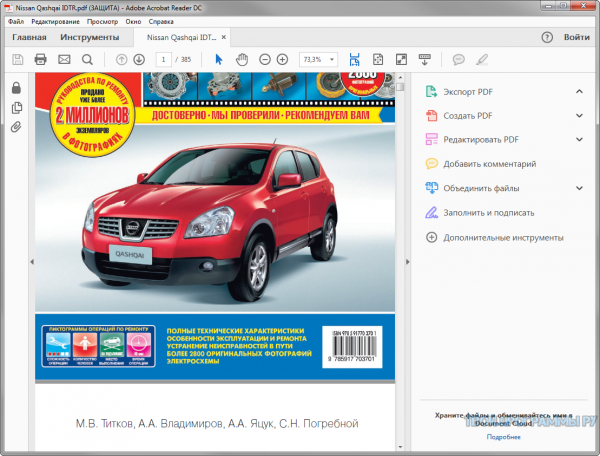
WinScan2PDF скачать
Портативная утилита для считывания данных со сканеров и сохранения материала в PDF. Софт переводит содержимое документов в цифровые форматы, одновременно обрабатывает несколько книг с последующим сохранением в один файл с соответствующим количеством страниц. В настройках можно выбирать качество сохраняемой работы, создавать много страниц в одном документе, менять язык интерфейса. ВинСкан2ПДФ позволит быстро отсканировать бумажную документацию, обработать сразу несколько страниц и создать многостраничный ПДФ.
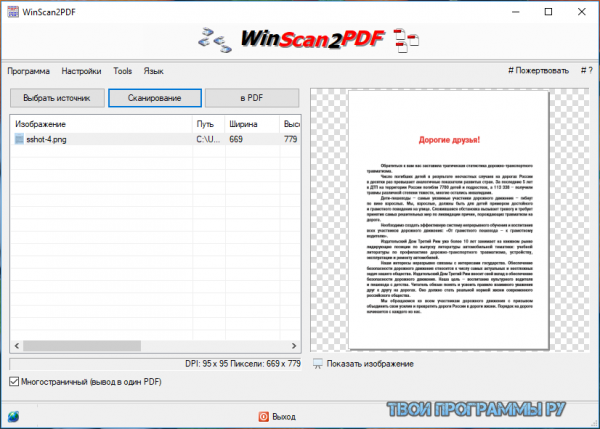
VueScan скачать
Программа-имитатор работы драйвера для расширения функциональных возможностей разнообразных моделей сканеров. Быстро подключается к устройствам сканирования, работает с негативами, старыми фотоснимками и слайдами без потери качества. В пользовательских настройках можно настраивать все этапы сканирования, сохранять отсканированную документацию в TIFF, JPEG и PDF форматах, распознавать тексты, использовать глубокую настройку готовой работы и применять множество установок. Фри-версия накладывает водяные знаки на работу.
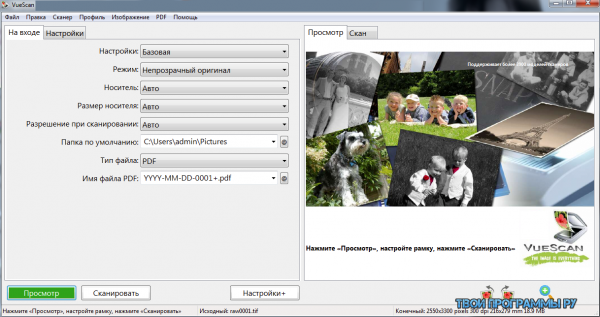
SimpleOCR скачать
Утилита распознает рукописный и машинный текст на датском, английском и французском языках, имеет интегрированный редактор и большой словарный запас. СимплеОЦР считывает данные со сканеров и проводит конвертацию материала в TXT, TIFF и DOC форматы, переводит напечатанный на бумаге текст и рукопись в цифровой формат, идентифицирует картинки и шрифты. Также доступно сравнение отсканированного ранее текста с полученным, а также внесение изменений. Бесплатная версия предоставляет только 14 дней распознавания текстов.
Readiris Pro скачать
Один из лидеров в категории OCR программ, который сканирует и распознает бумажную и рукописную документацию, работает с более 100 языками и имеет интегрированный редактор. Позволяет отсканировать и оцифровать материал, а с помощью редактора внести изменения. Реадирис конвертирует в формат изображения, таблицы и документа, работает с облачными хранилищами и ftp-папками, экспортирует в DJVU. В настройках можно улучшать качество документа, поворачивать его или сохранять в виртуальном хранилище. Ознакомительная версия активна 10 дней и дает на обработку только 100 страниц.
Microsoft OneNote скачать
Является дополнением к Office Mobile пакету и предоставляет расширения для создания списков задач, покупок или заметок. В функционале доступно создание маркированных списков, отметка галочкой выполненных пунктов, ввод рукописных примечаний сенсорным нажатием или цифровым пером, добавление графических картинок. Немаловажным плюсом утилиты является работа мобильной версии с OneDrive для хранения всех правок заметок, их просмотра или редактуры. Понятный русскоязычный интерфейс и бесплатное распространение станут приятными плюсами в работе с этой удобной прогой.
Freemore OCR Features скачать
Качественное ПО для оптического распознавания текста из изображений и ПДФ-документации. Доступно извлечение текста из картинки, которая получена с цифровой камеры, сканера или мобильного телефона, дешифровка и зашифровка символов, сохранение материала в TXT и Word, редактура метаданных, предпросмотр документации, применение пароля или цифровой подписи. Софт имеет методику сверхскоростной обработки и передовой кодировки, пресеты с оптимальной настройкой, поддерживает многоядерные процессоры. Продукт совместим со многими известными фирмами сканеров, открывает картинки разных форматов, защищает работу паролем и в реальном времени быстро обрабатывает материал.
TopOCR скачать
Программа легко оптически распознает, редактирует и читает текстовую документацию. Благодаря своей многофункциональности может распознать и отсканировать материал, а также внести изменения с помощью опций графического редактора и электронного переводчика. Приложение озвучивает текст на 11 языках, быстро переводит документацию и создает аудиокниги. Поддерживает многие распространенные форматы, работает напрямую со сканером и озвучивает текст. Из минусов отметим отсутствие русскоязычной поддержки.
 PDF Commander скачать
PDF Commander скачать
PDF Commander – отличный программный комплекс для редактирования, конвертации и объединения PDF-документов.Новый мощный редактор является лучшим решением для работы, бизнеса и учёбы, позволяя за считанные минуты создать с нуля, открыть, прочитать, отредактировать и внести корректировки в материалы ПДФ, а также использовать дополнительные возможности и проводить необходимые настройки.
Источник: tvoiprogrammy.ru
1. Программы оптического распознавания документов
Для быстрого перевода текста с бумажных носителей в электронный вид используют сканеры и программы распознавания символов .
После обработки документа сканером получается графическое изображение документа (графический образ). Но графический образ еще не является текстовым документом. Человеку достаточно взглянуть на лист бумаги с текстом, чтобы понять, что на нем написано. С точки зрения компьютера, документ после сканирования превращается в набор разноцветных точек, а вовсе не в текстовый документ.
Проблема распознавания текста в составе точечного графического изображения является весьма сложной. Подобные задачи решают с помощью специальных программных средств, называемых средствами распознавания образов.
Наиболее широко известна и распространена такая программа отечественных производителей — ABBYY FineReader .
Эта программа предназначена для распознавания текстов на русском, английском, немецком, украинском, французском и многих других языках (на 179 языках), а также для распознавания смешанных двуязычных текстов.
Возможности программы ABBYY FineReader:
- Работает с разными моделями сканеров.
- Позволяет из бумажных документов, PDF-файлов и цифровых фото сделать редактируемый текст.
- Позволяет объединять сканирование и распознавание в одну операцию, работать с пакетами документов (многостраничными документами) и с бланками.
- Позволяет редактировать распознанный текст и проверять его орфографию.
- Сохраняет внешний вид документа, а также его структуру, то есть, расположение слов, абзацев, таблиц, изображений, заголовков и нумерация страниц останутся такими же, как и в оригинале.
- Экспортирует тексты в Word, Excel, PowerPoint или Outlook.
Преобразование бумажного документа в электронный вид происходит в пять этапов. Каждый из этих этапов программа FineReader может выполнять как автоматически, так и под контролем пользователя. Если все этапы проводятся автоматически, то преобразование документа происходит за один прием.
Пять этапов процесса обработки документа с помощью программы ABBYY FineReader:
- Сканирование документа (кнопка Сканировать).
- Сегментация документа (кнопка Сегментировать).
- Распознавание документа (кнопка Распознать).
- Редактирование и проверка результата (кнопка Проверить).
- Сохранение документа (кнопка Сохранить).
1) На этапе сканирования производится получение изображений при помощи сканера и сохранение их в виде, удобном для последующей обработки. Чтобы начать сканирование, надо включить сканер и щелкнуть на кнопке Сканировать.
2) Второй этап работы — сегментация , разбиение страницы на блоки текста. Если страница содержит колонки, иллюстрации, врезки, подрисуночные подписи или таблицы, то порядок распознавания требует коррекции. Содержимое страницы разбивается на блоки, внутри каждого из которых распознавание осуществляется в естественном порядке.
Блоки нумеруются, исходя из порядка включения их в документ. При автоматической сегментации (кнопка Сегментировать) определение границ блоков осуществляется автоматически. При этом учитываются поля документа, просветы между колонками, рамки.
3) Процесс распознавания текста после сегментации начинается с щелчка на кнопке Распознать и полностью автоматизирован.
4) Когда распознавание данной страницы завершается, полученный текстовый документ отображается в окне Текст. Заключительные этапы работы позволяют отредактировать полученный текст с помощью средств, напоминающих текстовый редактор WordPad. Провести проверку орфографии с учетом трудностей распознавания позволяет кнопка Проверить.
5) По щелчку на кнопке Сохранить запускается Мастер сохранения результатов. Он позволяет сохранить распознанный текст или передать его в другую программу (например, в Microsoft Word) для последующей обработки полученный текст можно сохранить в виде форматированного или неформатированного документа.
Источник: www.yaklass.ru