
Парсер XML
Парсер xml — это по сути програмный анализатор (синтаксический разборщик) xml документа. Задача парсера — прочитать документ с данными и как-то его представить пользователю (например, чтобы его можно было внести в базу данных или модифицировать).
В XML на сегодня есть 2 подхода к разбору документа: SAX и DOM. Дополнительно информацию о них ищите на сайте через форму поиска.
SAX — Simle API of XML, простой api для работы с xml файлами, довольно примитивный, но зато быстрый.
DOM — Document Object Model. На сегодня самый распространенный и продвинутый.
DOM парсер
На входе получает какой-то документ с данными, а на выходе выдает дерево объектов.
Когда мы работаем с xml, к нам в парсер могут приходить совершенно разные документы. И иногда бывает документ не для нас, и просто обработать его dom парсером будет неправильно (документ может быть неполным, не все указано, не та структура, некорректные данные). И нам надо отсеять все это на этапе обработки, т.е. т.н. валидация документа. Т.е. надо определить грамматику входящего xml документа.
Парсинг (скрапинг) веб-страницы с помощью функции ImportXML()
И поэтому разработчики пошли по принципу декларативности: пусть парсер сам проверяет документ. Т.е. парсеру описывается набор правил, как должно быть, а он должен проверять, насколько данный документ похож, как должно быть. Среди таких описаний выделяют DTD. Рассмотрим ниже.
Описания DTD — Document Type Definition (определения типов документов)
DTD — это набор сокращений, некий язык описания (подобно xml), который позволяет указать, какие тэги мы ждем, т.е. какие элементы в нашем документе должны быть, сколько раз они имеют право повторяться, какие атрибуты должны быть у элементов, какие атрибуты обязательные и необязательные, какие сущности могут использоваться.
//вызов этих сущностей Сегодня &today; Информация о &company;
Описание DTD на сегодня устарело, редко где применяется, но поскольку его еще можно встретить, знать его синтаксис лишним не будет:
]> Название Автор 123
В этом примере, мы объяснили анализатору, как должно быть, описали грамматику. Вместо #PCDATA подставляются наши данные по книгам.
Т.е. DTD — это набор правил для вашего анализатора, в котором сообщается, как выглядит ваш документ.
Но как сказать анализатору, что документ нужно проверять по нашему описанию (например, как в листинкг выше)? Есть 2 способа:
- Декларативный — см. пример листинга выше. При этом анализируемый документ называется ‘самодостаточный’ (standalone), т.е. у него есть и DTD, и сами данные. Такие документы используют очень редко, т.к. они много весят.
- Программный. Здесь нет самого DTD, есть только ссылка на него + наши данные. Но в реальности никакой файл по ссылке не загружается, это только команда браузеру переключиться в другой режим работы. Пример:
Название Автор 123
Самое главное назначение DTD — валидация, т.е. проверка документа на соответствие стандарту. Когда документ достаточно сложный, перед преобразованием его надо бы проверить.
Что такое XML? Для чего используют DTD и Schema?
Источник: 1st-network.ru
Руководство по парсингу XML Python: чтение XML-файла
От автора: что такое XML? XML расшифровывается как расширяемый язык разметки. Он был разработан для хранения и передачи небольших и средних объемов данных и широко используется для обмена структурированной информацией.
Python позволяет парсировать и изменять XML-документ. Для парсинга XML-документа вам необходимо иметь в памяти весь XML-документ. В этом руководстве мы рассмотрим, как в Python использовать класс XML minidom для загрузки и парсинга XML-файла.
Как парсить XML с помощью minidom
Как создать XML-узел

Бесплатный курс «Python. Быстрый старт»
Получите курс и узнайте, как создать программу для перевода текстов на Python
Как парсить XML с помощью ElementTree
Как парсить XML с помощью minidom
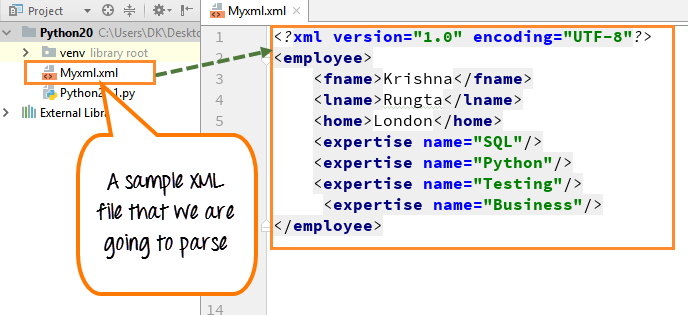
Мы создали образец XML-файла, который мы собираемся парсить.
Шаг 1) Внутри файла мы видим имя, фамилию, дом и навыки (SQL, Python, Testing и Business)
Шаг 2) После того, как мы спарсим документ, мы выведем «имя узла» корня документа и «первый дочерний тэг». Tagname и nodename являются стандартными свойствами файла XML.

Импортируйте модуль xml.dom.minidom и объявите файл для парсинга (myxml.xml)
Этот файл содержит основную информацию о сотруднике, такую как имя, фамилия, адрес, навыки и т. д.
Мы используем функцию parse в minidom XML для загрузки и парсинга файла XML
У нас есть переменная doc, doc получает результат функции parse
Мы хотим вывести имя файла и дочерний тэг, поэтому объявляем это в функции print
Запустите код. Он выведет имя узла (#document) из файла XML и первый дочерний тэг (employee) из файла XML.
Примечание: Nodename и tagname являются стандартными именами или свойствами XML dom. В случае, если вы не знакомы с этим типом именования.
Шаг 3) Мы также можем вызвать список тегов XML из документа XML и вывести его. Здесь мы вывели набор навыков, таких как SQL, Python, Testing и Business.

Объявление переменной expertise, из которой мы будем извлекать всю информацию сотрудника
Используем стандартную функцию dom с именем «getElementsByTagName»
Она получит все элементы с именем skill
Объявляем цикл для каждого из тегов skill
Запустите код — он выдаст список из четырех навыков
Как создать XML-узел
Мы можем создать новый атрибут с помощью функции «createElement», а затем добавить этот новый атрибут или тег к существующим тегам XML. Мы добавили новый тег «BigData» в XML-файл.
Вам нужно написать код, чтобы добавить новый атрибут (BigData) в существующий тег XML
Затем вам нужно вывести тег XML с новыми атрибутами, добавленными к существующему тегу XML.

Чтобы добавить новый XML и вставить его в документ, мы используем код «doc.create elements»
Бесплатный курс «Python. Быстрый старт»
Получите курс и узнайте, как создать программу для перевода текстов на Python
Этот код создаст новый тег skill для нашего нового атрибута «Big-data»
Добавьте этот тег в first child документа (employee)
Запустите код — появится новый тег «big data» с другим списком навыков.
Пример XML-парсера
Пример Python 2
Источник: webformyself.com
Программы парсинга xml что это
Я поначалу совсем не хотел останавливаться на том, что такое XML, но все-таки несколько слов сказать придется, чтобы те, кто про него услышали первый раз, прочитав эти строки, были в курсе основных идей.
По сути XML представляет собой обычный текст, который разделяется на логические группы с помощью специальных меток, которые называют “тэг”.
Тэг представляет собой слово, которое заключено в угловые скобки — например вот так:
Для того, чтобы начать группу вы указывает просто слово в скобках — еще раз повторим
Для окончание группы вы указываете такой же тэг, но слово предваряется символом “/”. Вот так:
В итоге группа внутри тэга test выглядит вот так:
Группа символов для тестирования
Тэги могу вкладываться один в другой — например вот так:
Группа символов для тестирования 01
Группа символов для тестирования 02
Группа символов для тестирования 03
Кроме вложений текста в тэгах можно указывать атрибуты — вот так:
Группа символов для тестирования 01
Назначение тэгов очень простое — надо отметить/выделить/сгруппировать какую-то информацию для того, чтобы потом ее можно было использовать. Это может быть список имен, список книг, список фирм, список вакансий и т.д.
Например, я хочу написать список контактов, с указанием имени, фамилии и e-mail. Можно сделать это так (но можно и по-другому — здесь все зависит от вашей фантазии и требований задачи):
Не ищите тайного смысла — я просто сделал строку, в которой выделил нужные мне части — контакт (тэг contact) и внутри определил имя, фамилию и e-mail (тэги firstName, lastName, email). Также с помощью атрибута type я определи тип контакта — друг, коллега, однокурсник. Теперь просматривая строку я могу выделить нужные мне части информации. Это удобно и ничего более. Причем здесь больше удобства даже не для визуального восприятия (это спорно), а для программной обработки — достаточно несложно написать программу, которая найдет конкретные кусочки.
Теперь новичкам надо посмотреть какой-нибудь XML, чтобы увидеть больше примеров и убедиться, что в главном я прав (хотя все в мире относительно).
Работа с XML
В первую очередь я хотел бы высказать свою позицию по поводу самого XML и уже на основе этого продолжать повествование.
Для меня XML — очень мощная технология, которая позволяет хранить, передавать и обрабатывать сложноструктурированные данные. Т.е. если я хочу иметь: список фирм с их телефонами и счетами, каталог книг с авторами и отзывами, описание структуры страниц сайта с комментариями, состояние всех автобусов в городе с их координатами, водителями, номерами и прочая — все это может быть удобно сохранено в виде XML и, что крайне важно и удобно, может быть передано в любую систему, которая написана на любой платформе — на .NET, PHP, Object C, Delphi, C++.
Проведите мысленный эксперимент — попробуйте написать строку, в которой передать информацию о своих контактах (где у одной персоны может быть несколько телефонов, e-mail, любимые книги, места работы, места учебы и … да хватит пока). Что важно — это должна быть обычная строка (несколько строк), которая позволяет разбирать эту информацию в ту структуру, которую я описал — класс Java. Там надо предусмотреть какие-то разделители, информацию об именах полей (группах полей). Попробуйте — и вы придете к чему-то подобному XML.
Также я вам советую очень серьезно подойти к изучение самого XML, т.к. на сегодня эта технология используется в очень широком спектре всевозможных пакетов, библиотек, платформ и вам никуда от нее не скрыться.
Итак, после всего вышесказанного мы видим, что нам приходит строковое представление чего-то важного в какой-то определенной структуре, которая требует наличия достаточно важных функций — нам же надо как-то работать с этой информацией. Не лежать же ей мертвым грузом. Функции достаточно очевидны:
- Разбор. Надо уметь разобрать строку на что-то более удобное для обработки — пытаться вставить внутрь строки или находить какое-то поле определенной записи из строки — это достаточно неудобно. Значит нам надо иметь некоторый набор классов для представления нашей строки в виде структуры объектов.
- Поиск. По структуре данных надо уметь что-то искать. Причем не подстроку, а какую-то группу полей, которые относятся к определенному объекту — например полная информация о книге — наименование, авторы, отзывы. Или список контактов с фамилией “Сидоров”.
- Проверка. Данные должны быть корректными, т.е. там должны быть только определенные поля, с определенным наполнением и они должны быть правильно скомпанованы в нашей строке.
- Преобразование. Хоть XML достаточно удобно описывает структурированные данные, это не значит, что его удобно просматривать обычному человеку или всегда удобно обрабатывать. Нередко для решения этого вопроса требуется преобразовать XML в какое-либо другое текстовое представление — например в тот же HTML (который является частным воплощением XML). Или даже в обычный текст.
В общем-то это все, что на мой взгляд наиболее важно. Нам надо уметь работать с информацией, которая записана в формате XML. Приступим к рассмотрению каждого пункта.
Разбор — Parsing
В слэнге программистов часто используется слова “парсинг”, который и обозначает разбор строки (или еще чего-нибудь) в какую-то структуру. Здесь надо выделить два момента:
- Разбор строки определенным алгоритмом
- Сохранение результатов разбора в какую-то структуру вместо строки — ибо со строкой многие операции делать просто неудобно.
Что касается второго пункта, то на сегодня существует по сути одна унифицированная структура, которая называется Document Object Model (DOM).
DOM представляет собой набор интерфейсов (и их реализаций), которые являются специализированными объектами для хранения “узлов” (node) XML-документа. По сути каждый тэг — это “узел” (нода — я буду использовать этот термин, т.к. очень привык). Информация внутри тэга — тоже нода. По сути любой разобранный XML — это набор элементов типа Node и еще более специализированных, построенных в дерево.
Почему дерево ? Да потому что у каждой ноды может быть список дочерних нод и у каждой из них тоже может быть “детки”. Так и строится дерево. Если вам сложно это увидеть, то советую посмотреть какую-либо классическую книгу по алгоритмам и структурам данных — можно старого доброго Никлауса Вирта «Алгоритмы и структуры данных». Книгу можно найти в интернете, ну или купить.
DOM
Давайте рассмотрим загрузку файла и редактирование построенного дерева на примере. Наша программа считывает XML-файл со списком книг и печатает их свойства. Сам XML-файл выглядит вот так:
Источник: java-course.ru
Парсеры PHP XML
В этом уроке вы узнаете, как получить ограниченное количество записей из таблицы базы данных MySQL с помощью условия LIMIT.
Что такое XML?
XML (eXtensible Markup Language, расширяемый язык разметки) используется для структурирования, хранения и передачи данных из одной системы в другую.
Он очень похож на HTML, только в XML разрешены свои собственные теги и атрибуты.
Примером совместно используемых xmls являются RSS-каналы.
Что такое DOM?
DOM — это аббревиатура от Document Object Model (Объектная Модель Документа).
Объектная Модель Документа (DOM) – это программный интерфейс (API) для HTML и XML документов.
XML-документы имеют иерархию информационных единиц, называемых узлами. DOM — это способ описания этих узлов и отношений между ними.
Документ DOM — это набор узлов или фрагментов информации, организованных в иерархию. Эта иерархия позволяет разработчику перемещаться по дереву в поисках конкретной информации. Поскольку она основана на иерархии информации, модель DOM называется древовидной.
XML DOM, с другой стороны, также предоставляет API, который позволяет разработчику добавлять, редактировать, перемещать или удалять узлы в дереве в любой момент для создания приложения.
Что такое API? Это набор функций, с помощью которых мы можем сделать запрос сайту и получать нужный ответ. Вот этот ответ чаще всего приходит в формате XML.
Что такое CDATA?
Термин CDATA означает символьные данные. CDATA определяется как блоки текста, которые не анализируются анализатором, но в остальном распознаются как разметка.
Предопределенные объекты, такие как , и требуют набора текста и, как правило, плохо читаются в разметке. В таких случаях можно использовать раздел CDATA. Используя раздел CDATA, вы даете команду синтаксическому анализатору, чтобы конкретный раздел документа не содержал разметки и обрабатывался как обычный текст.
Что такое парсер XML?
Парсер XML — это программа, которая переводит документ XML в объект объектной модели документа XML (DOM).
Затем объектом XML DOM можно управлять с помощью JavaScript, Python, PHP и т.д.
XML-парсер нам понадобится для чтения и обновления, создания и управления XML-документом.
И хотя в последнее время все большее число веб-сервисов возвращают данные в формате JSON, все же большинство, на данный момент, использует XML, поэтому важно изучить парсинг XML, если вы хотите использовать весь спектр доступных интерфейсов API.
В PHP есть два основных типа парсеров XML:
- Древовидные парсеры
- Парсеры на основе событий
Древовидные парсеры
Древовидные парсеры (DOM) обеспечивают представление XML, ориентированное на документы. При синтаксическом анализе на основе дерева парсеры хранят весь документ в памяти и преобразуют XML-документ в древовидную структуру, что для больших документов требует очень больших затрат памяти.
Все элементы и атрибуты доступны сразу, но не раньше, чем будет проанализирован весь документ. Этот метод полезен, если вам нужно перемещаться по документу и, возможно, изменять различные фрагменты документа, именно поэтому он полезен для объектной модели документа (DOM), целью которой является управление документами с помощью языков сценариев или Java.
Этот тип синтаксического парсера является лучшим вариантом только для небольших XML-документов, поскольку он вызывает серьезные проблемы с производительностью при обработке больших XML-документов.
К древовидным парсерам относятся:
Парсеры на основе событий
Парсеры на основе событий (SAX) обеспечивают представление XML, ориентированное на данные.
Вместо того, чтобы PHP анализировал XML-файл, сохраняя его все в своей памяти и считывая сразу несколько узлов, анализатор на основе событий считывает один узел всякий раз, когда это требуется. При переходе на другой узел старый удаляется.
Из-за своей природы доступа только к необходимым частям XML-документа, синтаксические анализаторы этого типа, как правило, более легкие (используют меньше памяти и меньше кода). Следовательно, эти парсеры — лучший выбор для XML-анализа больших документов.
Вот два наиболее популярных анализатора XML на основе событий:
- XMLReader
- XML Expat Parser
Парсеры на основе событий
- Язык XML используется для структурирования данных и имеет синтаксис, аналогичный HTML. Данными в этом формате можно легко обмениваться между веб-сайтами, поэтому эта технология часто используется для RSS-каналов, подкастов и т. п.
- Чтобы превратить файлы XML в доступные и читаемые данные, вам понадобится анализатор XML. Это может быть расширение или независимая программа, позволяющая PHP анализировать XML-документы.
- В PHP синтаксические анализаторы XML делятся на две группы: основанные на событиях (лучше для больших документов) и основанные на деревьях (лучше для небольших документов).
Источник: www.wm-school.ru